 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fine-grained Cross-modal Fusion based Refinement for Text-to-Image Synthesis
Feb 20, 2023
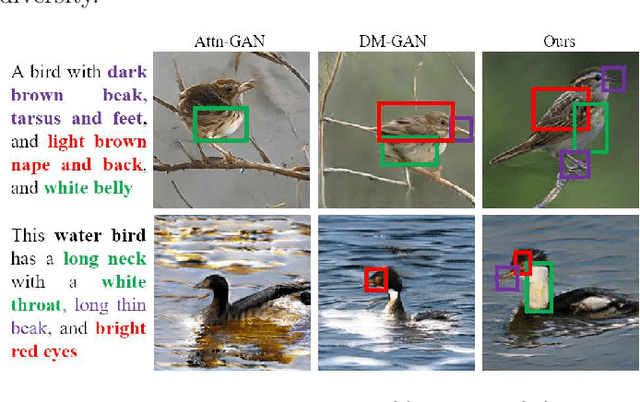
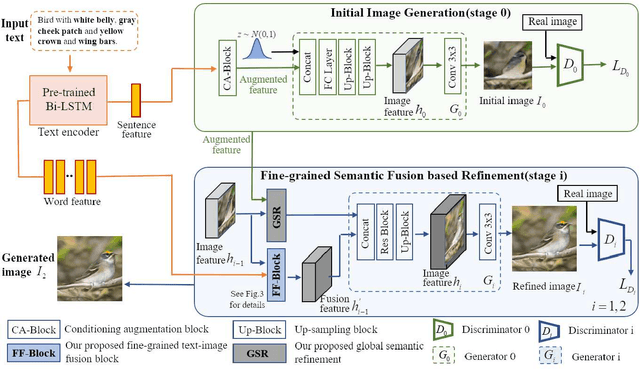
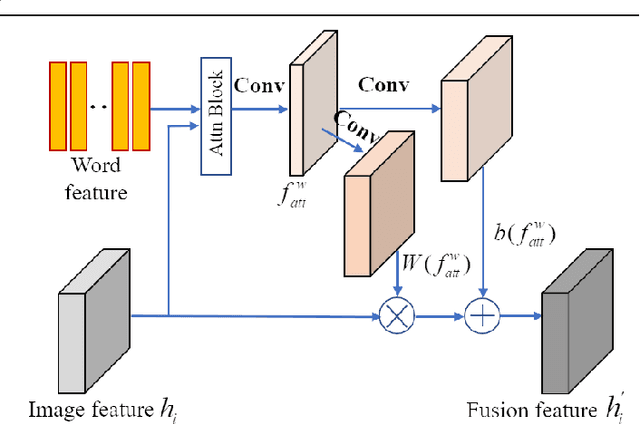

Text-to-image synthesis refers to generating visual-realistic and semantically consistent images from given textual descriptions. Previous approaches generate an initial low-resolution image and then refine it to be high-resolution. Despite the remarkable progress, these methods are limited in fully utilizing the given texts and could generate text-mismatched images, especially when the text description is complex. We propose a novel Fine-grained text-image Fusion based Generative Adversarial Networks, dubbed FF-GAN, which consists of two modules: Fine-grained text-image Fusion Block (FF-Block) and Global Semantic Refinement (GSR). The proposed FF-Block integrates an attention block and several convolution layers to effectively fuse the fine-grained word-context features into the corresponding visual features, in which the text information is fully used to refine the initial image with more details. And the GSR is proposed to improve the global semantic consistency between linguistic and visual features during the refinement process. Extensive experiments on CUB-200 and COCO datasets demonstrate the superiority of FF-GAN over other state-of-the-art approaches in generating images with semantic consistency to the given texts.Code is available at https://github.com/haoranhfut/FF-GAN.
LANCE: Stress-testing Visual Models by Generating Language-guided Counterfactual Images
May 30, 2023
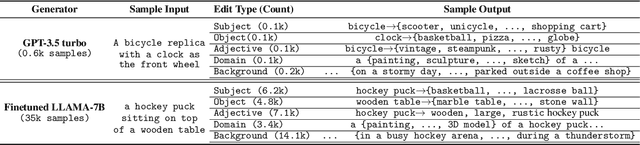
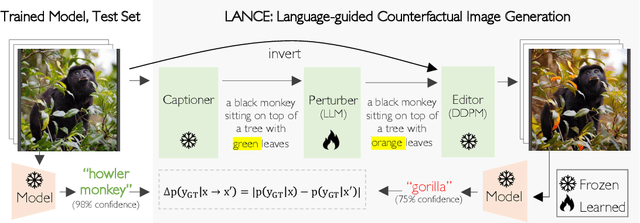
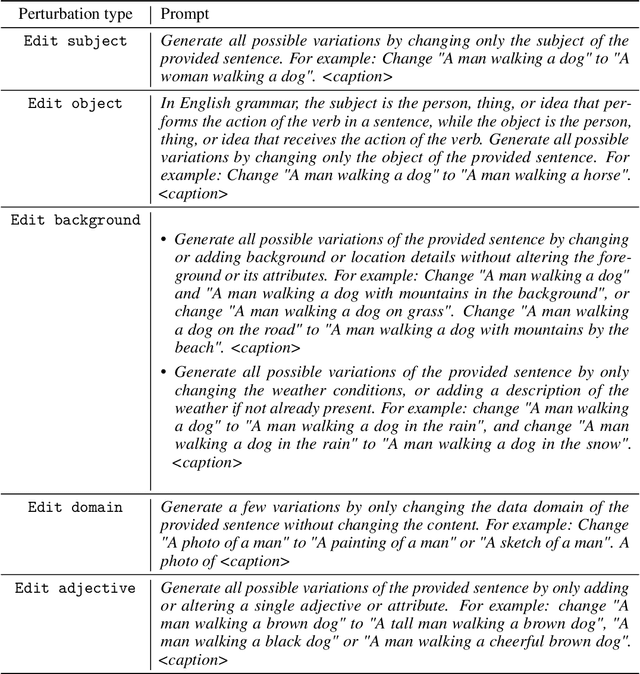
We propose an automated algorithm to stress-test a trained visual model by generating language-guided counterfactual test images (LANCE). Our method leverages recent progress in large language modeling and text-based image editing to augment an IID test set with a suite of diverse, realistic, and challenging test images without altering model weights. We benchmark the performance of a diverse set of pretrained models on our generated data and observe significant and consistent performance drops. We further analyze model sensitivity across different types of edits, and demonstrate its applicability at surfacing previously unknown class-level model biases in ImageNet.
Towards Arbitrary-scale Histopathology Image Super-resolution: An Efficient Dual-branch Framework based on Implicit Self-texture Enhancement
Apr 09, 2023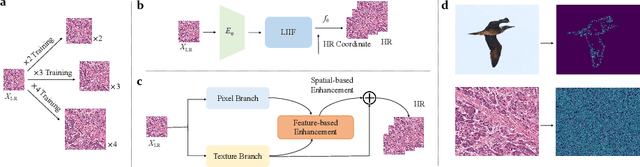
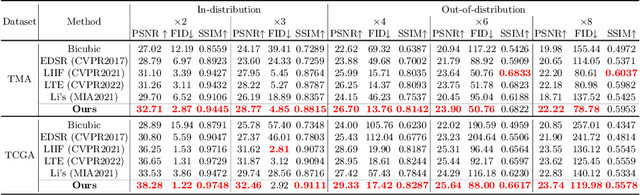
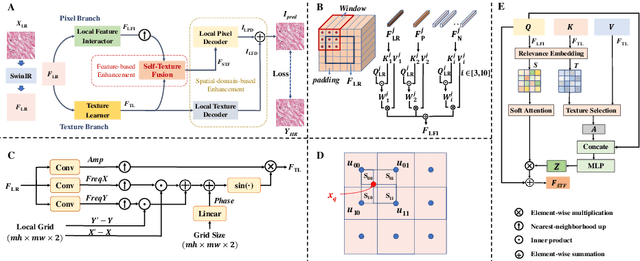

Existing super-resolution models for pathology images can only work in fixed integer magnifications and have limited performance. Though implicit neural network-based methods have shown promising results in arbitrary-scale super-resolution of natural images, it is not effective to directly apply them in pathology images, because pathology images have special fine-grained image textures different from natural images. To address this challenge, we propose a dual-branch framework with an efficient self-texture enhancement mechanism for arbitrary-scale super-resolution of pathology images. Extensive experiments on two public datasets show that our method outperforms both existing fixed-scale and arbitrary-scale algorithms. To the best of our knowledge, this is the first work to achieve arbitrary-scale super-resolution in the field of pathology images. Codes will be available.
Image Restoration with Mean-Reverting Stochastic Differential Equations
Jan 30, 2023
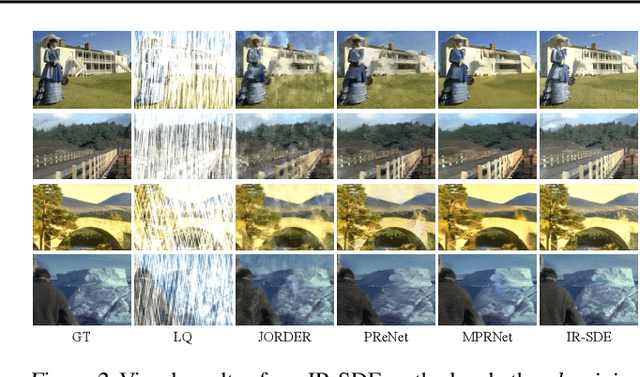
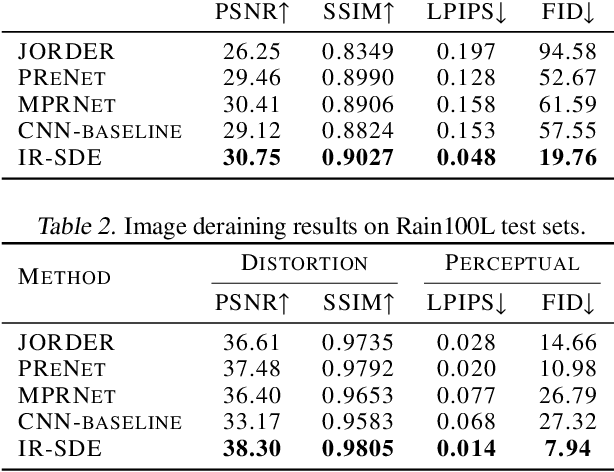
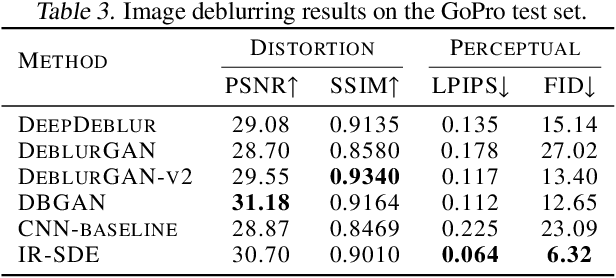
This paper presents a stochastic differential equation (SDE) approach for general-purpose image restoration. The key construction consists in a mean-reverting SDE that transforms a high-quality image into a degraded counterpart as a mean state with fixed Gaussian noise. Then, by simulating the corresponding reverse-time SDE, we are able to restore the origin of the low-quality image without relying on any task-specific prior knowledge. Crucially, the proposed mean-reverting SDE has a closed-form solution, allowing us to compute the ground truth time-dependent score and learn it with a neural network. Moreover, we propose a maximum likelihood objective to learn an optimal reverse trajectory which stabilizes the training and improves the restoration results. In the experiments, we show that our proposed method achieves highly competitive performance in quantitative comparisons on image deraining, deblurring, and denoising, setting a new state-of-the-art on two deraining datasets. Finally, the general applicability of our approach is further demonstrated via qualitative results on image super-resolution, inpainting, and dehazing. Code is available at https://github.com/Algolzw/image-restoration-sde.
Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement
Feb 23, 2023

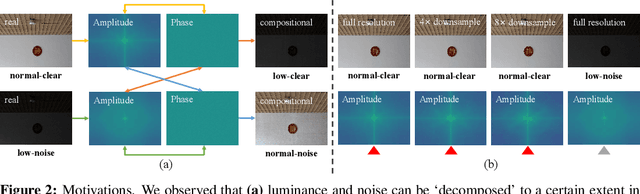
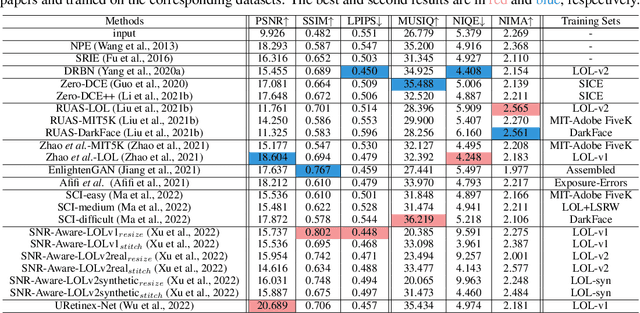
Ultra-High-Definition (UHD) photo has gradually become the standard configuration in advanced imaging devices. The new standard unveils many issues in existing approaches for low-light image enhancement (LLIE), especially in dealing with the intricate issue of joint luminance enhancement and noise removal while remaining efficient. Unlike existing methods that address the problem in the spatial domain, we propose a new solution, UHDFour, that embeds Fourier transform into a cascaded network. Our approach is motivated by a few unique characteristics in the Fourier domain: 1) most luminance information concentrates on amplitudes while noise is closely related to phases, and 2) a high-resolution image and its low-resolution version share similar amplitude patterns.Through embedding Fourier into our network, the amplitude and phase of a low-light image are separately processed to avoid amplifying noise when enhancing luminance. Besides, UHDFour is scalable to UHD images by implementing amplitude and phase enhancement under the low-resolution regime and then adjusting the high-resolution scale with few computations. We also contribute the first real UHD LLIE dataset, \textbf{UHD-LL}, that contains 2,150 low-noise/normal-clear 4K image pairs with diverse darkness and noise levels captured in different scenarios. With this dataset, we systematically analyze the performance of existing LLIE methods for processing UHD images and demonstrate the advantage of our solution. We believe our new framework, coupled with the dataset, would push the frontier of LLIE towards UHD. The code and dataset are available at https://li-chongyi.github.io/UHDFour.
* Porject page: https://li-chongyi.github.io/UHDFour
Graph-based methods coupled with specific distributional distances for adversarial attack detection
May 31, 2023
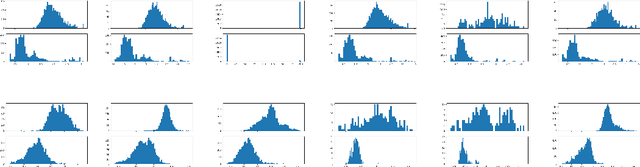

Artificial neural networks are prone to being fooled by carefully perturbed inputs which cause an egregious misclassification. These \textit{adversarial} attacks have been the focus of extensive research. Likewise, there has been an abundance of research in ways to detect and defend against them. We introduce a novel approach of detection and interpretation of adversarial attacks from a graph perspective. For an image, benign or adversarial, we study how a neural network's architecture can induce an associated graph. We study this graph and introduce specific measures used to predict and interpret adversarial attacks. We show that graphs-based approaches help to investigate the inner workings of adversarial attacks.
Towards More Transparent and Accurate Cancer Diagnosis with an Unsupervised CAE Approach
May 19, 2023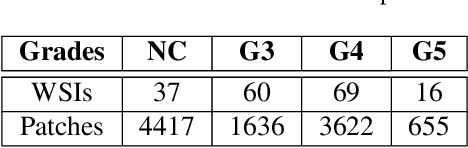
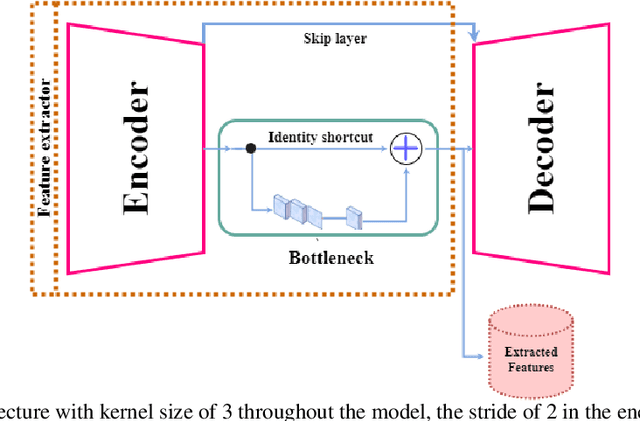
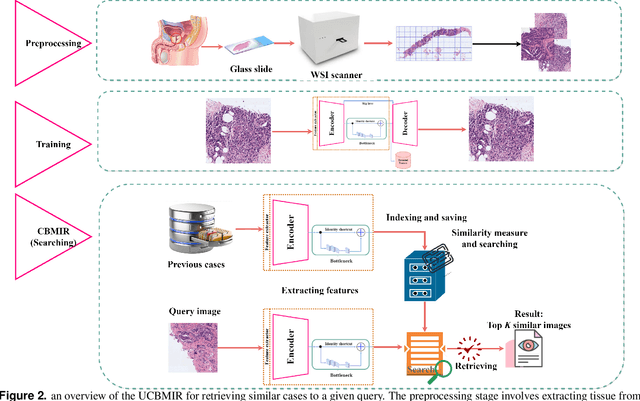
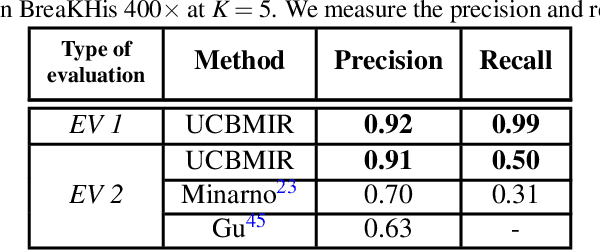
Digital pathology has revolutionized cancer diagnosis by leveraging Content-Based Medical Image Retrieval (CBMIR) for analyzing histopathological Whole Slide Images (WSIs). CBMIR enables searching for similar content, enhancing diagnostic reliability and accuracy. In 2020, breast and prostate cancer constituted 11.7% and 14.1% of cases, respectively, as reported by the Global Cancer Observatory (GCO). The proposed Unsupervised CBMIR (UCBMIR) replicates the traditional cancer diagnosis workflow, offering a dependable method to support pathologists in WSI-based diagnostic conclusions. This approach alleviates pathologists' workload, potentially enhancing diagnostic efficiency. To address the challenge of the lack of labeled histopathological images in CBMIR, a customized unsupervised Convolutional Auto Encoder (CAE) was developed, extracting 200 features per image for the search engine component. UCBMIR was evaluated using widely-used numerical techniques in CBMIR, alongside visual evaluation and comparison with a classifier. The validation involved three distinct datasets, with an external evaluation demonstrating its effectiveness. UCBMIR outperformed previous studies, achieving a top 5 recall of 99% and 80% on BreaKHis and SICAPv2, respectively, using the first evaluation technique. Precision rates of 91% and 70% were achieved for BreaKHis and SICAPv2, respectively, using the second evaluation technique. Furthermore, UCBMIR demonstrated the capability to identify various patterns in patches, achieving an 81% accuracy in the top 5 when tested on an external image from Arvaniti.
An End-to-End Multi-Task Learning Model for Image-based Table Recognition
Mar 15, 2023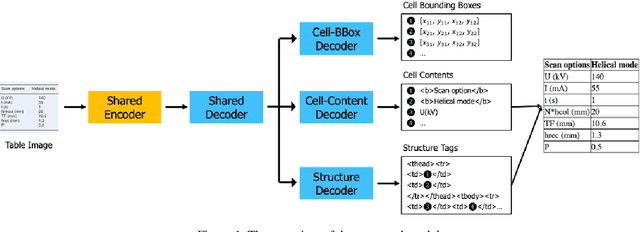
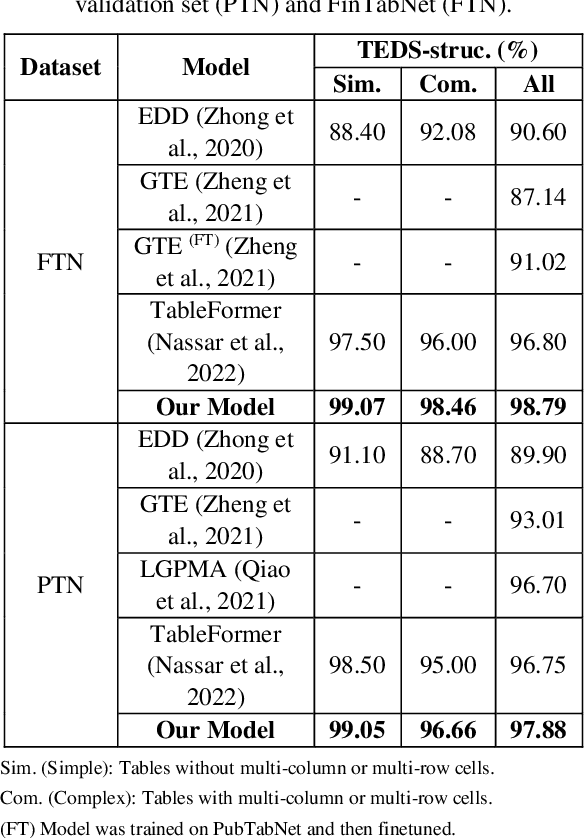
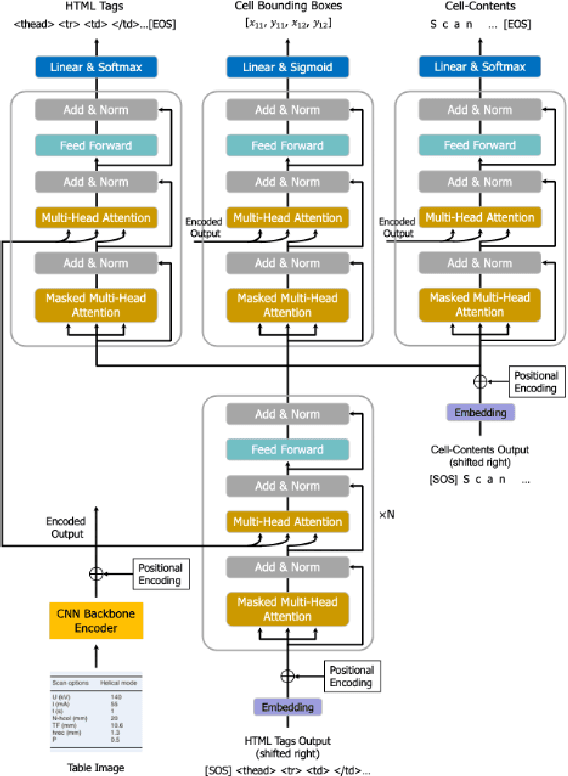
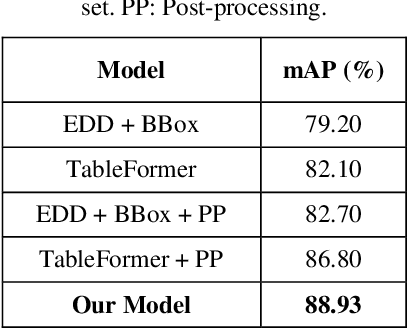
Image-based table recognition is a challenging task due to the diversity of table styles and the complexity of table structures. Most of the previous methods focus on a non-end-to-end approach which divides the problem into two separate sub-problems: table structure recognition; and cell-content recognition and then attempts to solve each sub-problem independently using two separate systems. In this paper, we propose an end-to-end multi-task learning model for image-based table recognition. The proposed model consists of one shared encoder, one shared decoder, and three separate decoders which are used for learning three sub-tasks of table recognition: table structure recognition, cell detection, and cell-content recognition. The whole system can be easily trained and inferred in an end-to-end approach. In the experiments, we evaluate the performance of the proposed model on two large-scale datasets: FinTabNet and PubTabNet. The experiment results show that the proposed model outperforms the state-of-the-art methods in all benchmark datasets.
* 10 pages, VISAPP2023. arXiv admin note: substantial text overlap with arXiv:2303.07641
LDM3D: Latent Diffusion Model for 3D
May 21, 2023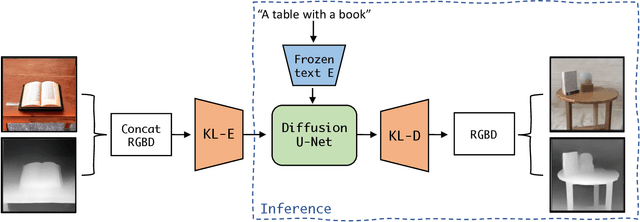
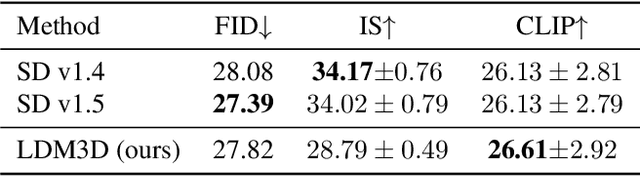
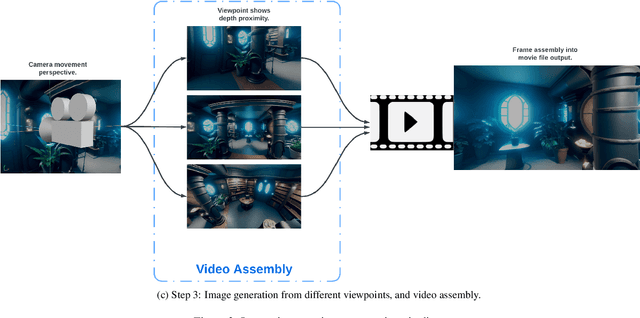
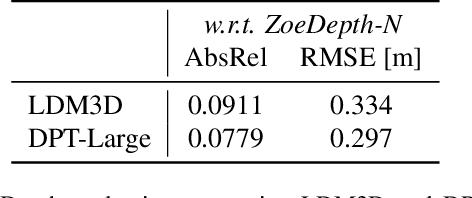
This research paper proposes a Latent Diffusion Model for 3D (LDM3D) that generates both image and depth map data from a given text prompt, allowing users to generate RGBD images from text prompts. The LDM3D model is fine-tuned on a dataset of tuples containing an RGB image, depth map and caption, and validated through extensive experiments. We also develop an application called DepthFusion, which uses the generated RGB images and depth maps to create immersive and interactive 360-degree-view experiences using TouchDesigner. This technology has the potential to transform a wide range of industries, from entertainment and gaming to architecture and design. Overall, this paper presents a significant contribution to the field of generative AI and computer vision, and showcases the potential of LDM3D and DepthFusion to revolutionize content creation and digital experiences. A short video summarizing the approach can be found at https://t.ly/tdi2.
DeepfakeArt Challenge: A Benchmark Dataset for Generative AI Art Forgery and Data Poisoning Detection
Jun 11, 2023



The tremendous recent advances in generative artificial intelligence techniques have led to significant successes and promise in a wide range of different applications ranging from conversational agents and textual content generation to voice and visual synthesis. Amid the rise in generative AI and its increasing widespread adoption, there has been significant growing concern over the use of generative AI for malicious purposes. In the realm of visual content synthesis using generative AI, key areas of significant concern has been image forgery (e.g., generation of images containing or derived from copyright content), and data poisoning (i.e., generation of adversarially contaminated images). Motivated to address these key concerns to encourage responsible generative AI, we introduce the DeepfakeArt Challenge, a large-scale challenge benchmark dataset designed specifically to aid in the building of machine learning algorithms for generative AI art forgery and data poisoning detection. Comprising of over 32,000 records across a variety of generative forgery and data poisoning techniques, each entry consists of a pair of images that are either forgeries / adversarially contaminated or not. Each of the generated images in the DeepfakeArt Challenge benchmark dataset has been quality checked in a comprehensive manner. The DeepfakeArt Challenge is a core part of GenAI4Good, a global open source initiative for accelerating machine learning for promoting responsible creation and deployment of generative AI for good.