 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MMC: Multi-Modal Colorization of Images using Textual Descriptions
Apr 24, 2023

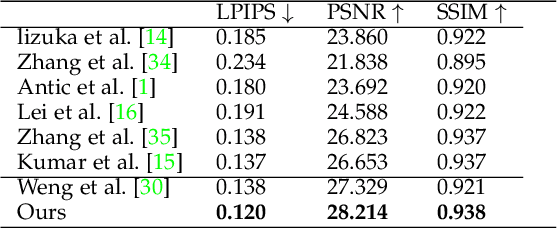
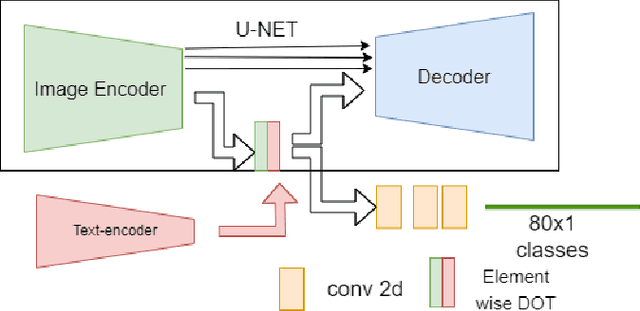
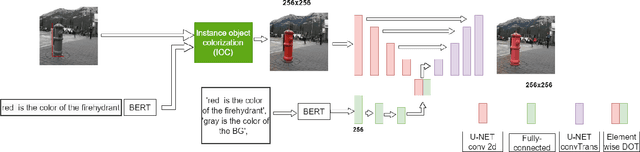
Handling various objects with different colors is a significant challenge for image colorization techniques. Thus, for complex real-world scenes, the existing image colorization algorithms often fail to maintain color consistency. In this work, we attempt to integrate textual descriptions as an auxiliary condition, along with the grayscale image that is to be colorized, to improve the fidelity of the colorization process. To do so, we have proposed a deep network that takes two inputs (grayscale image and the respective encoded text description) and tries to predict the relevant color components. Also, we have predicted each object in the image and have colorized them with their individual description to incorporate their specific attributes in the colorization process. After that, a fusion model fuses all the image objects (segments) to generate the final colorized image. As the respective textual descriptions contain color information of the objects present in the image, text encoding helps to improve the overall quality of predicted colors. In terms of performance, the proposed method outperforms existing colorization techniques in terms of LPIPS, PSNR and SSIM metrics.
k-NNN: Nearest Neighbors of Neighbors for Anomaly Detection
May 28, 2023
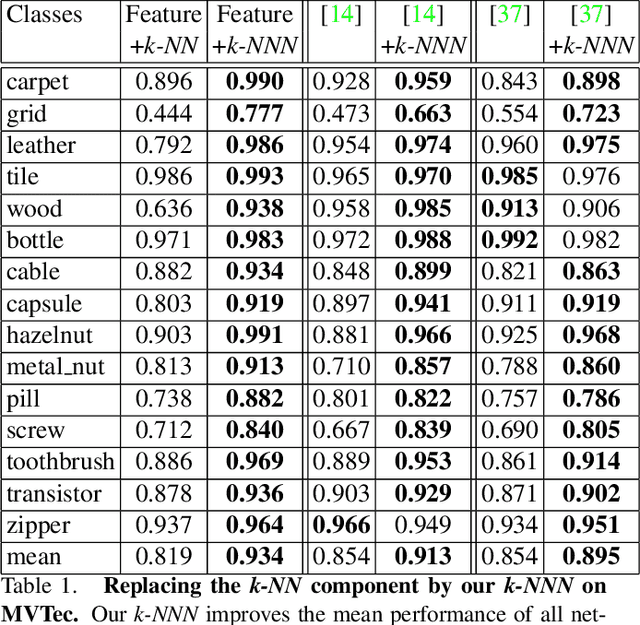
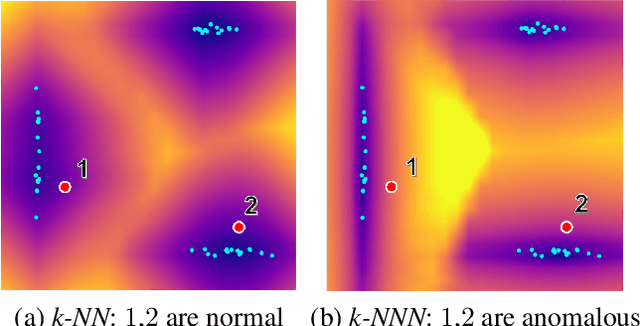
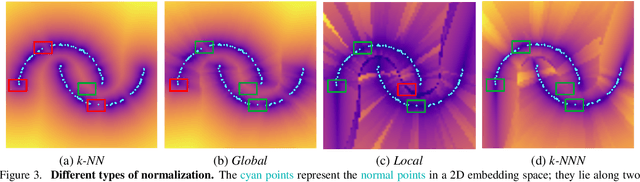
Anomaly detection aims at identifying images that deviate significantly from the norm. We focus on algorithms that embed the normal training examples in space and when given a test image, detect anomalies based on the features distance to the k-nearest training neighbors. We propose a new operator that takes into account the varying structure & importance of the features in the embedding space. Interestingly, this is done by taking into account not only the nearest neighbors, but also the neighbors of these neighbors (k-NNN). We show that by simply replacing the nearest neighbor component in existing algorithms by our k-NNN operator, while leaving the rest of the algorithms untouched, each algorithms own results are improved. This is the case both for common homogeneous datasets, such as flowers or nuts of a specific type, as well as for more diverse datasets
Visual Affordance Prediction for Guiding Robot Exploration
May 28, 2023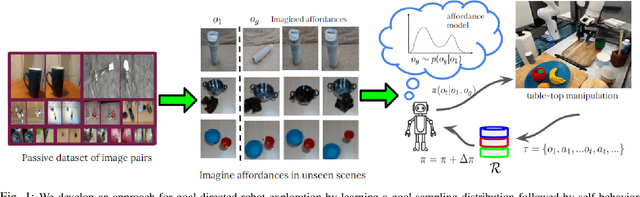
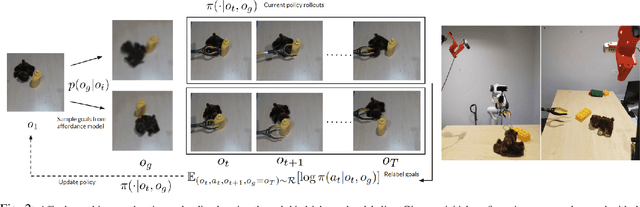
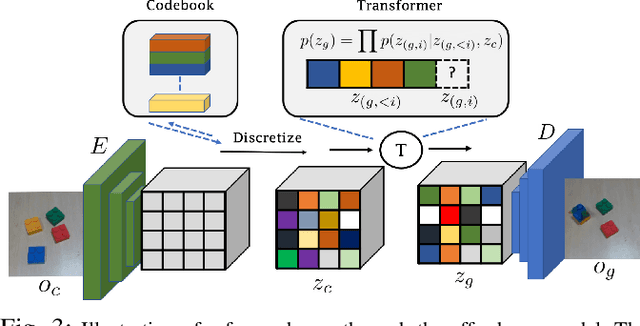

Motivated by the intuitive understanding humans have about the space of possible interactions, and the ease with which they can generalize this understanding to previously unseen scenes, we develop an approach for learning visual affordances for guiding robot exploration. Given an input image of a scene, we infer a distribution over plausible future states that can be achieved via interactions with it. We use a Transformer-based model to learn a conditional distribution in the latent embedding space of a VQ-VAE and show that these models can be trained using large-scale and diverse passive data, and that the learned models exhibit compositional generalization to diverse objects beyond the training distribution. We show how the trained affordance model can be used for guiding exploration by acting as a goal-sampling distribution, during visual goal-conditioned policy learning in robotic manipulation.
Topology-Aware Focal Loss for 3D Image Segmentation
Apr 27, 2023The efficacy of segmentation algorithms is frequently compromised by topological errors like overlapping regions, disrupted connections, and voids. To tackle this problem, we introduce a novel loss function, namely Topology-Aware Focal Loss (TAFL), that incorporates the conventional Focal Loss with a topological constraint term based on the Wasserstein distance between the ground truth and predicted segmentation masks' persistence diagrams. By enforcing identical topology as the ground truth, the topological constraint can effectively resolve topological errors, while Focal Loss tackles class imbalance. We begin by constructing persistence diagrams from filtered cubical complexes of the ground truth and predicted segmentation masks. We subsequently utilize the Sinkhorn-Knopp algorithm to determine the optimal transport plan between the two persistence diagrams. The resultant transport plan minimizes the cost of transporting mass from one distribution to the other and provides a mapping between the points in the two persistence diagrams. We then compute the Wasserstein distance based on this travel plan to measure the topological dissimilarity between the ground truth and predicted masks. We evaluate our approach by training a 3D U-Net with the MICCAI Brain Tumor Segmentation (BraTS) challenge validation dataset, which requires accurate segmentation of 3D MRI scans that integrate various modalities for the precise identification and tracking of malignant brain tumors. Then, we demonstrate that the quality of segmentation performance is enhanced by regularizing the focal loss through the addition of a topological constraint as a penalty term.
Joint ANN-SNN Co-training for Object Localization and Image Segmentation
Mar 10, 2023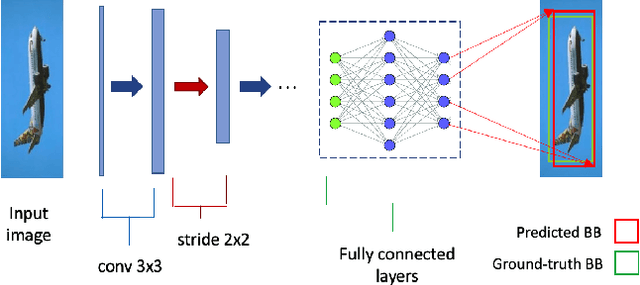
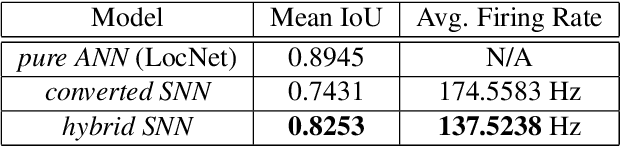
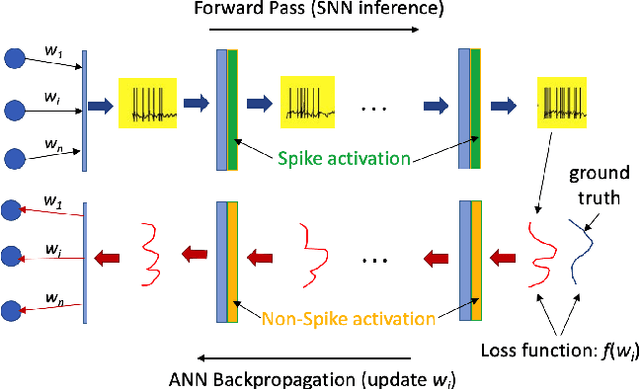
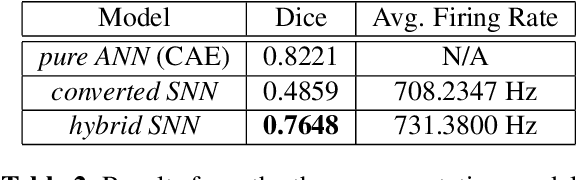
The field of machine learning has been greatly transformed with the advancement of deep artificial neural networks (ANNs) and the increased availability of annotated data. Spiking neural networks (SNNs) have recently emerged as a low-power alternative to ANNs due to their sparsity nature. In this work, we propose a novel hybrid ANN-SNN co-training framework to improve the performance of converted SNNs. Our approach is a fine-tuning scheme, conducted through an alternating, forward-backward training procedure. We apply our framework to object detection and image segmentation tasks. Experiments demonstrate the effectiveness of our approach in achieving the design goals.
Understanding Label Bias in Single Positive Multi-Label Learning
May 24, 2023
Annotating data for multi-label classification is prohibitively expensive because every category of interest must be confirmed to be present or absent. Recent work on single positive multi-label (SPML) learning shows that it is possible to train effective multi-label classifiers using only one positive label per image. However, the standard benchmarks for SPML are derived from traditional multi-label classification datasets by retaining one positive label for each training example (chosen uniformly at random) and discarding all other labels. In realistic settings it is not likely that positive labels are chosen uniformly at random. This work introduces protocols for studying label bias in SPML and provides new empirical results.
StyleHumanCLIP: Text-guided Garment Manipulation for StyleGAN-Human
May 26, 2023
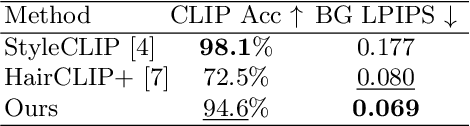
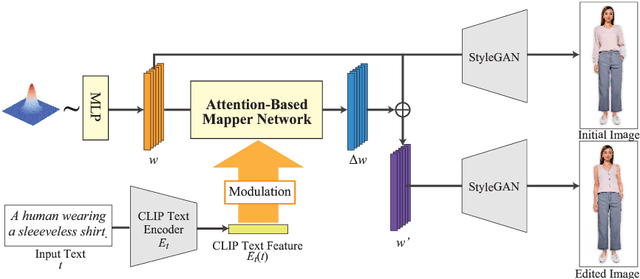
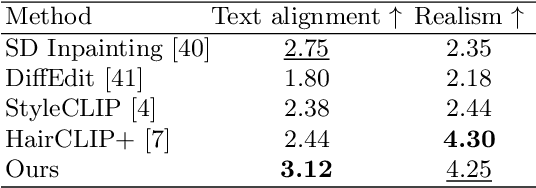
This paper tackles text-guided control of StyleGAN for editing garments in full-body human images. Existing StyleGAN-based methods suffer from handling the rich diversity of garments and body shapes and poses. We propose a framework for text-guided full-body human image synthesis via an attention-based latent code mapper, which enables more disentangled control of StyleGAN than existing mappers. Our latent code mapper adopts an attention mechanism that adaptively manipulates individual latent codes on different StyleGAN layers under text guidance. In addition, we introduce feature-space masking at inference time to avoid unwanted changes caused by text inputs. Our quantitative and qualitative evaluations reveal that our method can control generated images more faithfully to given texts than existing methods.
Confronting Ambiguity in 6D Object Pose Estimation via Score-Based Diffusion on SE(3)
May 25, 2023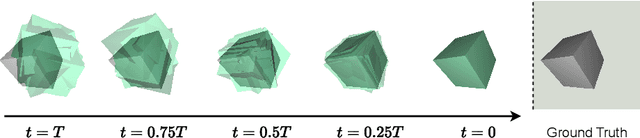


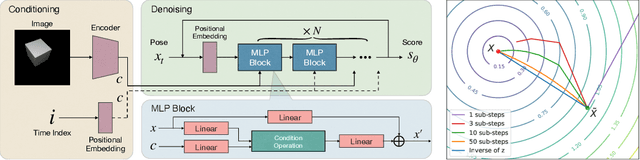
Addressing accuracy limitations and pose ambiguity in 6D object pose estimation from single RGB images presents a significant challenge, particularly due to object symmetries or occlusions. In response, we introduce a novel score-based diffusion method applied to the $SE(3)$ group, marking the first application of diffusion models to $SE(3)$ within the image domain, specifically tailored for pose estimation tasks. Extensive evaluations demonstrate the method's efficacy in handling pose ambiguity, mitigating perspective-induced ambiguity, and showcasing the robustness of our surrogate Stein score formulation on $SE(3)$. This formulation not only improves the convergence of Langevin dynamics but also enhances computational efficiency. Thus, we pioneer a promising strategy for 6D object pose estimation.
Unveiling Cross Modality Bias in Visual Question Answering: A Causal View with Possible Worlds VQA
May 31, 2023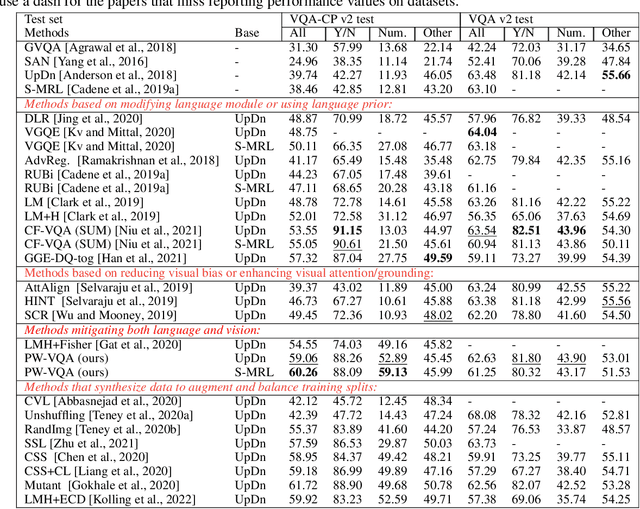
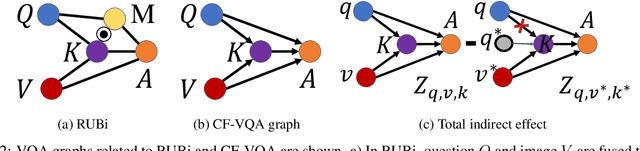

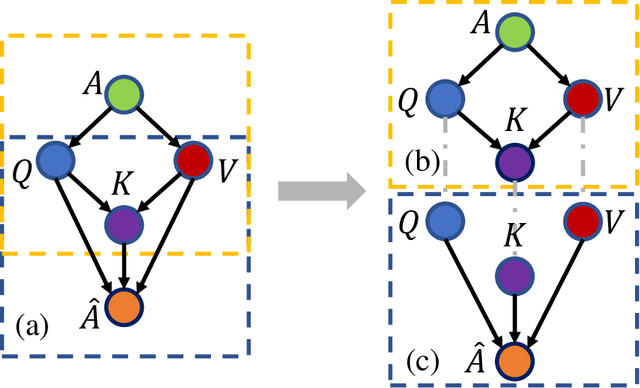
To increase the generalization capability of VQA systems, many recent studies have tried to de-bias spurious language or vision associations that shortcut the question or image to the answer. Despite these efforts, the literature fails to address the confounding effect of vision and language simultaneously. As a result, when they reduce bias learned from one modality, they usually increase bias from the other. In this paper, we first model a confounding effect that causes language and vision bias simultaneously, then propose a counterfactual inference to remove the influence of this effect. The model trained in this strategy can concurrently and efficiently reduce vision and language bias. To the best of our knowledge, this is the first work to reduce biases resulting from confounding effects of vision and language in VQA, leveraging causal explain-away relations. We accompany our method with an explain-away strategy, pushing the accuracy of the questions with numerical answers results compared to existing methods that have been an open problem. The proposed method outperforms the state-of-the-art methods in VQA-CP v2 datasets.
FlowCam: Training Generalizable 3D Radiance Fields without Camera Poses via Pixel-Aligned Scene Flow
May 31, 2023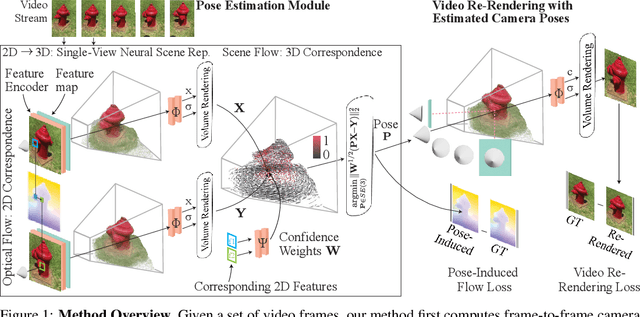



Reconstruction of 3D neural fields from posed images has emerged as a promising method for self-supervised representation learning. The key challenge preventing the deployment of these 3D scene learners on large-scale video data is their dependence on precise camera poses from structure-from-motion, which is prohibitively expensive to run at scale. We propose a method that jointly reconstructs camera poses and 3D neural scene representations online and in a single forward pass. We estimate poses by first lifting frame-to-frame optical flow to 3D scene flow via differentiable rendering, preserving locality and shift-equivariance of the image processing backbone. SE(3) camera pose estimation is then performed via a weighted least-squares fit to the scene flow field. This formulation enables us to jointly supervise pose estimation and a generalizable neural scene representation via re-rendering the input video, and thus, train end-to-end and fully self-supervised on real-world video datasets. We demonstrate that our method performs robustly on diverse, real-world video, notably on sequences traditionally challenging to optimization-based pose estimation techniques.