 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
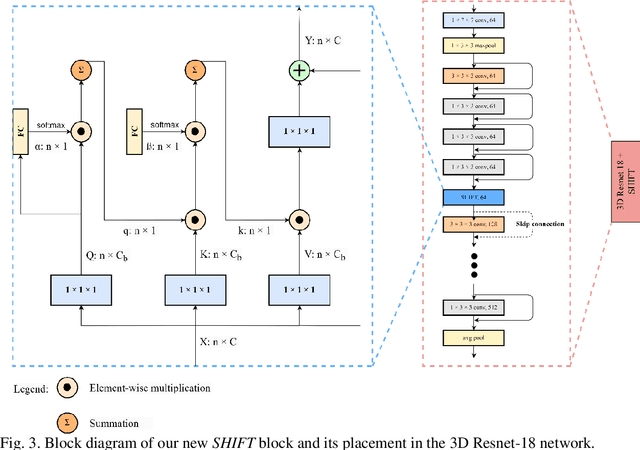
Hierarchical Disentangled Representation for Invertible Image Denoising and Beyond
Jan 31, 2023
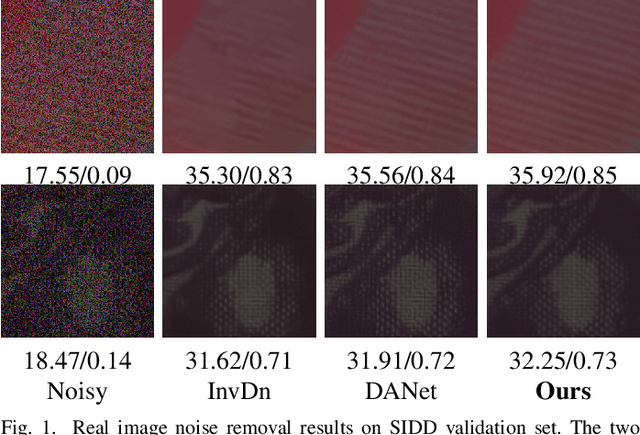
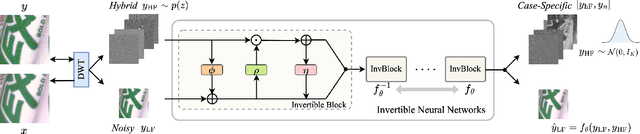
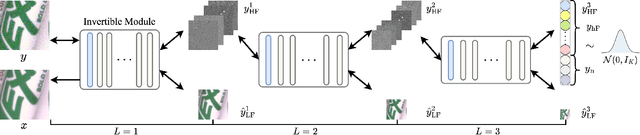
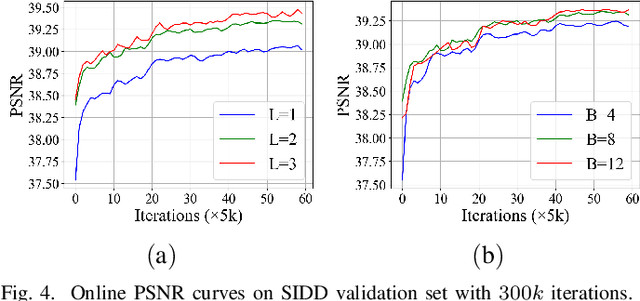
Image denoising is a typical ill-posed problem due to complex degradation. Leading methods based on normalizing flows have tried to solve this problem with an invertible transformation instead of a deterministic mapping. However, the implicit bijective mapping is not explored well. Inspired by a latent observation that noise tends to appear in the high-frequency part of the image, we propose a fully invertible denoising method that injects the idea of disentangled learning into a general invertible neural network to split noise from the high-frequency part. More specifically, we decompose the noisy image into clean low-frequency and hybrid high-frequency parts with an invertible transformation and then disentangle case-specific noise and high-frequency components in the latent space. In this way, denoising is made tractable by inversely merging noiseless low and high-frequency parts. Furthermore, we construct a flexible hierarchical disentangling framework, which aims to decompose most of the low-frequency image information while disentangling noise from the high-frequency part in a coarse-to-fine manner. Extensive experiments on real image denoising, JPEG compressed artifact removal, and medical low-dose CT image restoration have demonstrated that the proposed method achieves competing performance on both quantitative metrics and visual quality, with significantly less computational cost.
A Transformer-based representation-learning model with unified processing of multimodal input for clinical diagnostics
Jun 01, 2023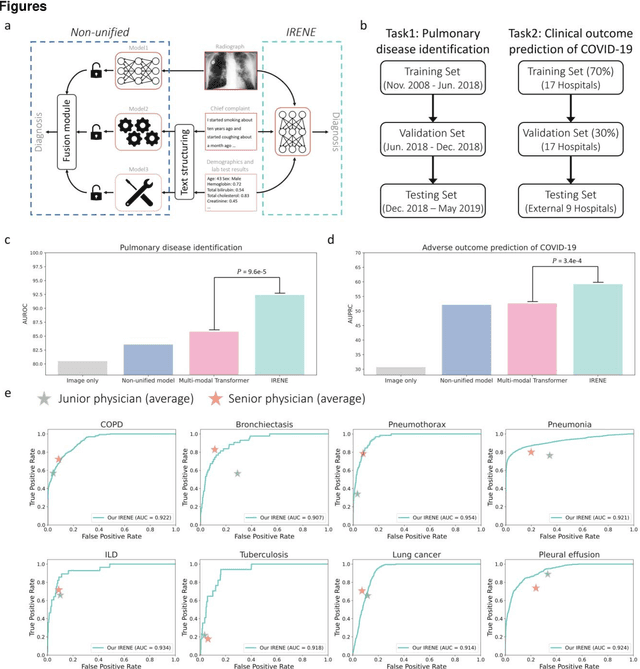
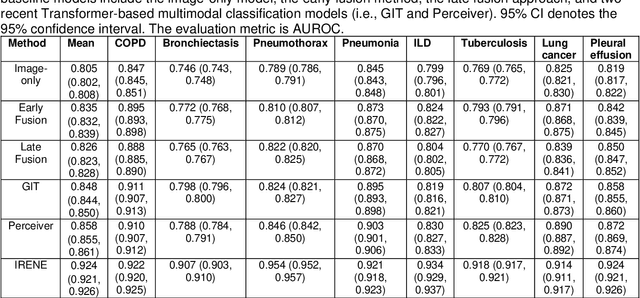
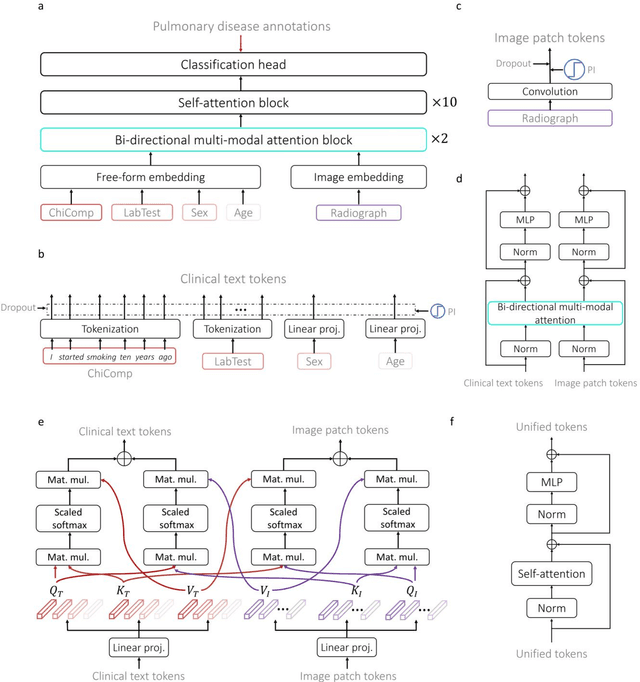
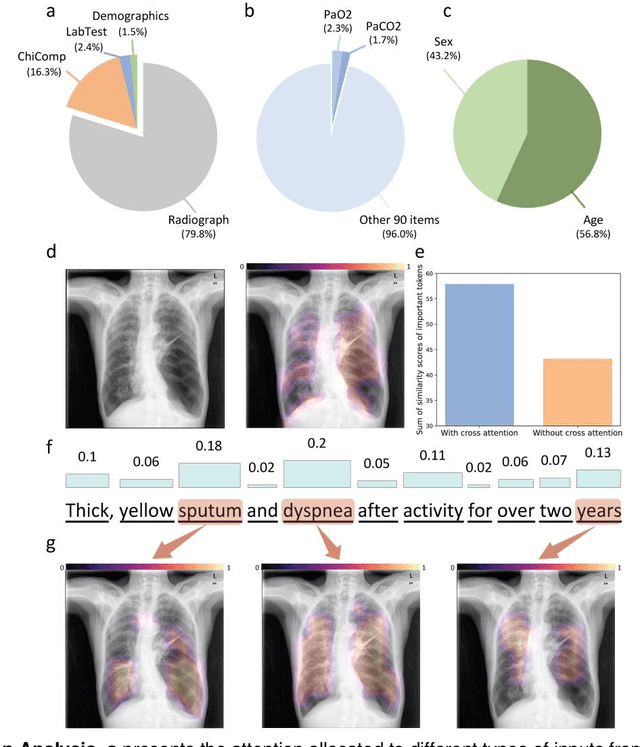
During the diagnostic process, clinicians leverage multimodal information, such as chief complaints, medical images, and laboratory-test results. Deep-learning models for aiding diagnosis have yet to meet this requirement. Here we report a Transformer-based representation-learning model as a clinical diagnostic aid that processes multimodal input in a unified manner. Rather than learning modality-specific features, the model uses embedding layers to convert images and unstructured and structured text into visual tokens and text tokens, and bidirectional blocks with intramodal and intermodal attention to learn a holistic representation of radiographs, the unstructured chief complaint and clinical history, structured clinical information such as laboratory-test results and patient demographic information. The unified model outperformed an image-only model and non-unified multimodal diagnosis models in the identification of pulmonary diseases (by 12% and 9%, respectively) and in the prediction of adverse clinical outcomes in patients with COVID-19 (by 29% and 7%, respectively). Leveraging unified multimodal Transformer-based models may help streamline triage of patients and facilitate the clinical decision process.
DiffRoom: Diffusion-based High-Quality 3D Room Reconstruction and Generation
Jun 01, 2023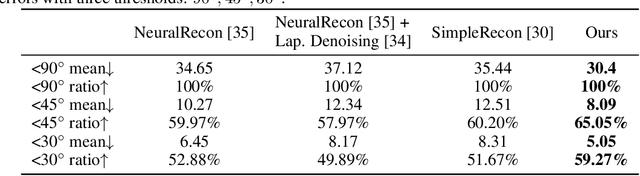

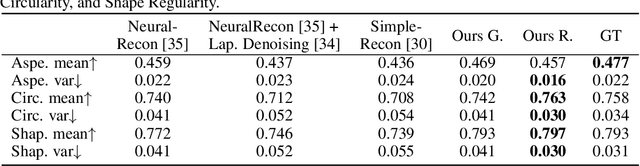
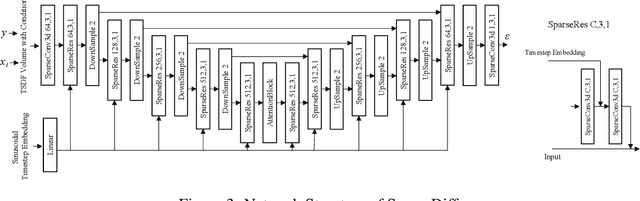
We present DiffRoom, a novel framework for tackling the problem of high-quality 3D indoor room reconstruction and generation, both of which are challenging due to the complexity and diversity of the room geometry. Although diffusion-based generative models have previously demonstrated impressive performance in image generation and object-level 3D generation, they have not yet been applied to room-level 3D generation due to their computationally intensive costs. In DiffRoom, we propose a sparse 3D diffusion network that is efficient and possesses strong generative performance for Truncated Signed Distance Field (TSDF), based on a rough occupancy prior. Inspired by KinectFusion's incremental alignment and fusion of local SDFs, we propose a diffusion-based TSDF fusion approach that iteratively diffuses and fuses TSDFs, facilitating the reconstruction and generation of an entire room environment. Additionally, to ease training, we introduce a curriculum diffusion learning paradigm that speeds up the training convergence process and enables high-quality reconstruction. According to the user study, the mesh quality generated by our DiffRoom can even outperform the ground truth mesh provided by ScanNet.
2D Object Detection with Transformers: A Review
Jun 07, 2023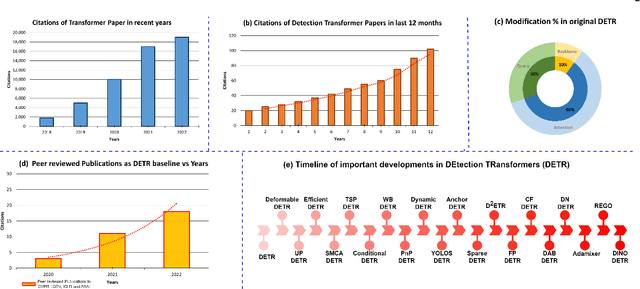
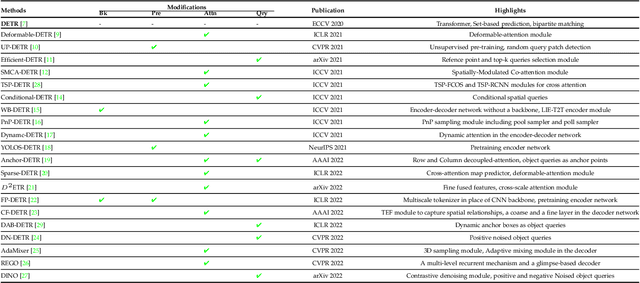
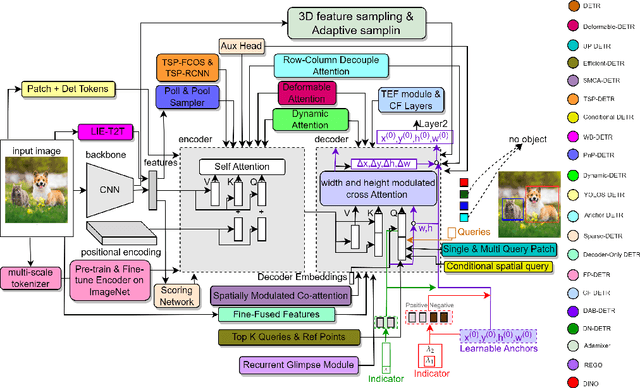
Astounding performance of Transformers in natural language processing (NLP) has delighted researchers to explore their utilization in computer vision tasks. Like other computer vision tasks, DEtection TRansformer (DETR) introduces transformers for object detection tasks by considering the detection as a set prediction problem without needing proposal generation and post-processing steps. It is a state-of-the-art (SOTA) method for object detection, particularly in scenarios where the number of objects in an image is relatively small. Despite the success of DETR, it suffers from slow training convergence and performance drops for small objects. Therefore, many improvements are proposed to address these issues, leading to immense refinement in DETR. Since 2020, transformer-based object detection has attracted increasing interest and demonstrated impressive performance. Although numerous surveys have been conducted on transformers in vision in general, a review regarding advancements made in 2D object detection using transformers is still missing. This paper gives a detailed review of twenty-one papers about recent developments in DETR. We begin with the basic modules of Transformers, such as self-attention, object queries and input features encoding. Then, we cover the latest advancements in DETR, including backbone modification, query design and attention refinement. We also compare all detection transformers in terms of performance and network design. We hope this study will increase the researcher's interest in solving existing challenges towards applying transformers in the object detection domain. Researchers can follow newer improvements in detection transformers on this webpage available at: https://github.com/mindgarage-shan/trans_object_detection_survey
A Light-weight Deep Learning Model for Remote Sensing Image Classification
Feb 25, 2023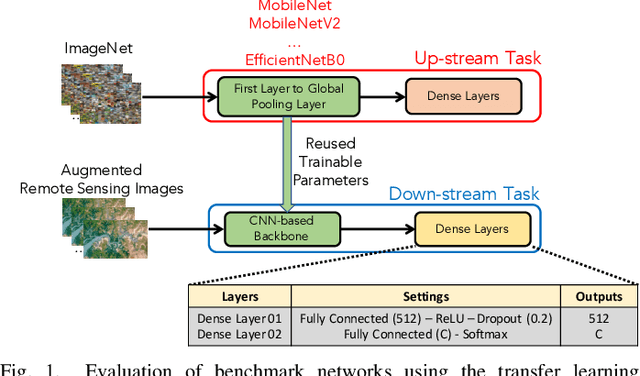
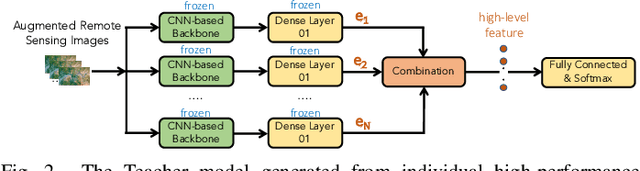
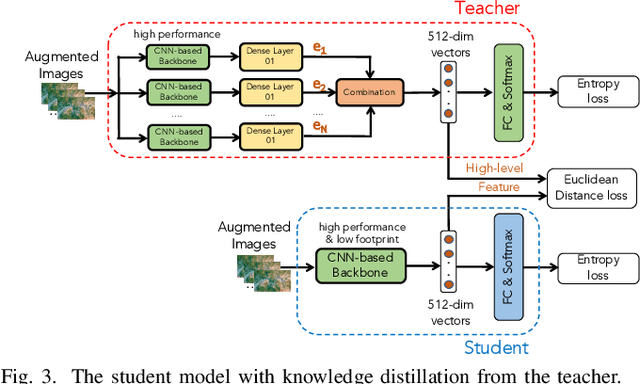

In this paper, we present a high-performance and light-weight deep learning model for Remote Sensing Image Classification (RSIC), the task of identifying the aerial scene of a remote sensing image. To this end, we first valuate various benchmark convolutional neural network (CNN) architectures: MobileNet V1/V2, ResNet 50/151V2, InceptionV3/InceptionResNetV2, EfficientNet B0/B7, DenseNet 121/201, ConNeXt Tiny/Large. Then, the best performing models are selected to train a compact model in a teacher-student arrangement. The knowledge distillation from the teacher aims to achieve high performance with significantly reduced complexity. By conducting extensive experiments on the NWPU-RESISC45 benchmark, our proposed teacher-student models outperforms the state-of-the-art systems, and has potential to be applied on a wide rage of edge devices.
RADIFUSION: A multi-radiomics deep learning based breast cancer risk prediction model using sequential mammographic images with image attention and bilateral asymmetry refinement
Apr 01, 2023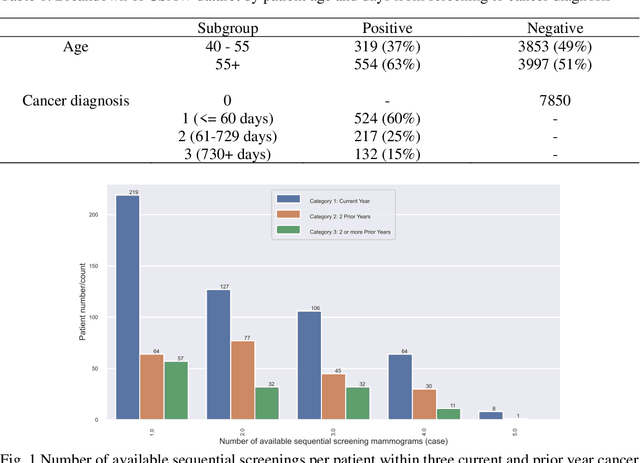
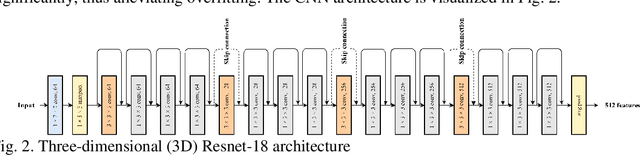

Breast cancer is a significant public health concern and early detection is critical for triaging high risk patients. Sequential screening mammograms can provide important spatiotemporal information about changes in breast tissue over time. In this study, we propose a deep learning architecture called RADIFUSION that utilizes sequential mammograms and incorporates a linear image attention mechanism, radiomic features, a new gating mechanism to combine different mammographic views, and bilateral asymmetry-based finetuning for breast cancer risk assessment. We evaluate our model on a screening dataset called Cohort of Screen-Aged Women (CSAW) dataset. Based on results obtained on the independent testing set consisting of 1,749 women, our approach achieved superior performance compared to other state-of-the-art models with area under the receiver operating characteristic curves (AUCs) of 0.905, 0.872 and 0.866 in the three respective metrics of 1-year AUC, 2-year AUC and > 2-year AUC. Our study highlights the importance of incorporating various deep learning mechanisms, such as image attention, radiomic features, gating mechanism, and bilateral asymmetry-based fine-tuning, to improve the accuracy of breast cancer risk assessment. We also demonstrate that our model's performance was enhanced by leveraging spatiotemporal information from sequential mammograms. Our findings suggest that RADIFUSION can provide clinicians with a powerful tool for breast cancer risk assessment.
The Surprising Effectiveness of Diffusion Models for Optical Flow and Monocular Depth Estimation
Jun 02, 2023
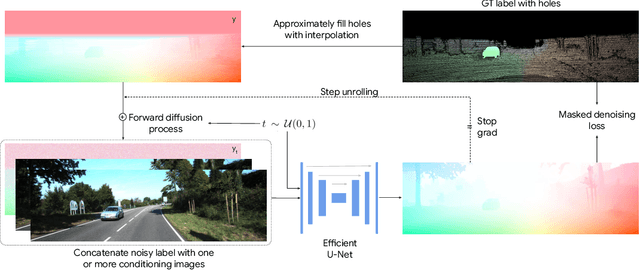
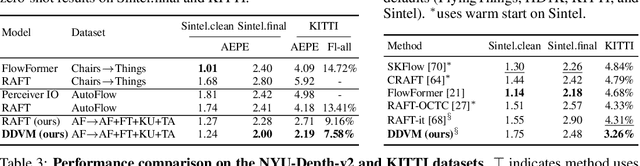

Denoising diffusion probabilistic models have transformed image generation with their impressive fidelity and diversity. We show that they also excel in estimating optical flow and monocular depth, surprisingly, without task-specific architectures and loss functions that are predominant for these tasks. Compared to the point estimates of conventional regression-based methods, diffusion models also enable Monte Carlo inference, e.g., capturing uncertainty and ambiguity in flow and depth. With self-supervised pre-training, the combined use of synthetic and real data for supervised training, and technical innovations (infilling and step-unrolled denoising diffusion training) to handle noisy-incomplete training data, and a simple form of coarse-to-fine refinement, one can train state-of-the-art diffusion models for depth and optical flow estimation. Extensive experiments focus on quantitative performance against benchmarks, ablations, and the model's ability to capture uncertainty and multimodality, and impute missing values. Our model, DDVM (Denoising Diffusion Vision Model), obtains a state-of-the-art relative depth error of 0.074 on the indoor NYU benchmark and an Fl-all outlier rate of 3.26\% on the KITTI optical flow benchmark, about 25\% better than the best published method. For an overview see https://diffusion-vision.github.io.
GANs and alternative methods of synthetic noise generation for domain adaption of defect classification of Non-destructive ultrasonic testing
Jun 02, 2023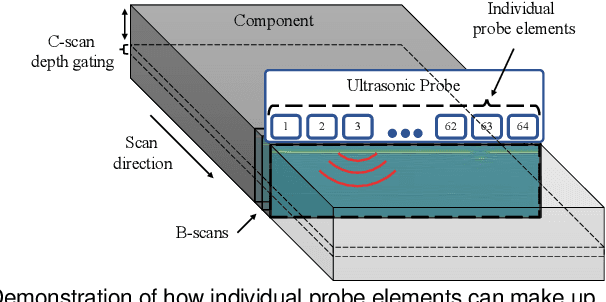


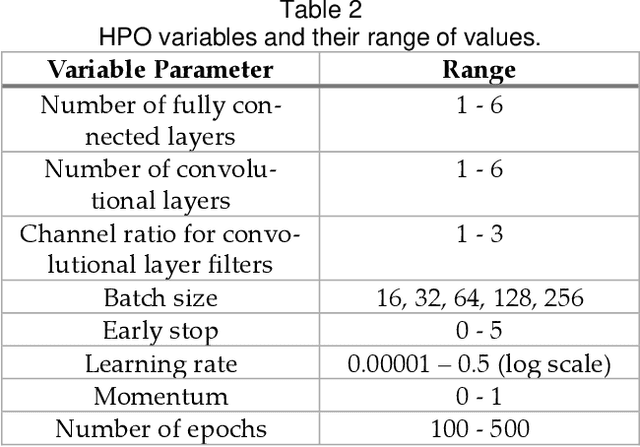
This work provides a solution to the challenge of small amounts of training data in Non-Destructive Ultrasonic Testing for composite components. It was demonstrated that direct simulation alone is ineffective at producing training data that was representative of the experimental domain due to poor noise reconstruction. Therefore, four unique synthetic data generation methods were proposed which use semi-analytical simulated data as a foundation. Each method was evaluated on its classification performance of real experimental images when trained on a Convolutional Neural Network which underwent hyperparameter optimization using a genetic algorithm. The first method introduced task specific modifications to CycleGAN, to learn the mapping from physics-based simulations of defect indications to experimental indications in resulting ultrasound images. The second method was based on combining real experimental defect free images with simulated defect responses. The final two methods fully simulated the noise responses at an image and signal level respectively. The purely simulated data produced a mean classification F1 score of 0.394. However, when trained on the new synthetic datasets, a significant improvement in classification performance on experimental data was realized, with mean classification F1 scores of 0.843, 0.688, 0.629, and 0.738 for the respective approaches.
Automatic Radiology Report Generation by Learning with Increasingly Hard Negatives
May 11, 2023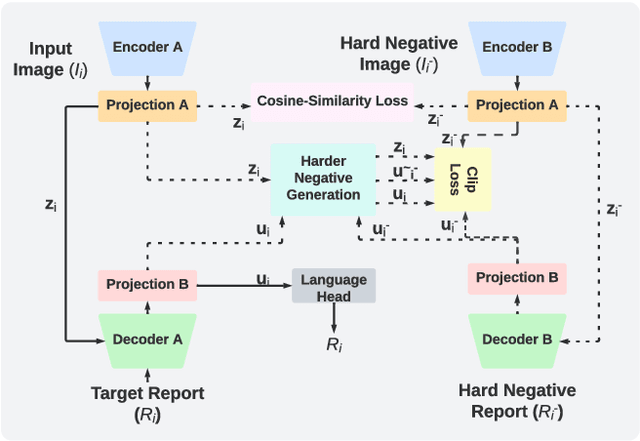
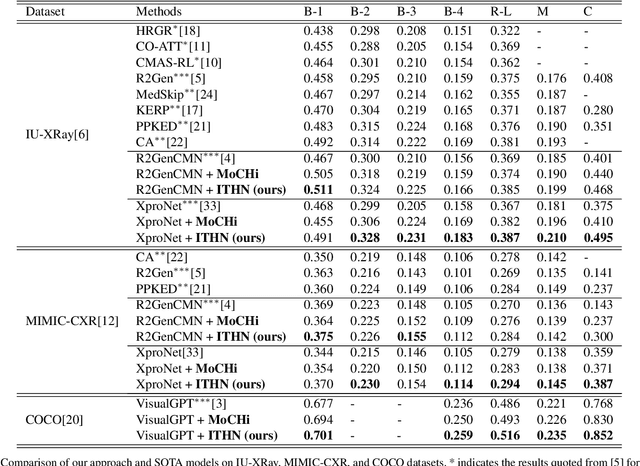
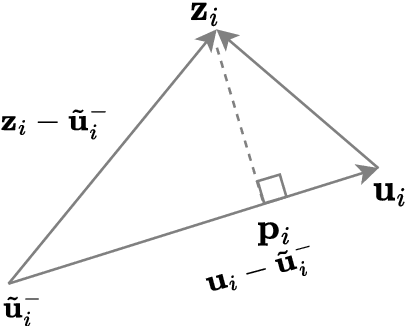
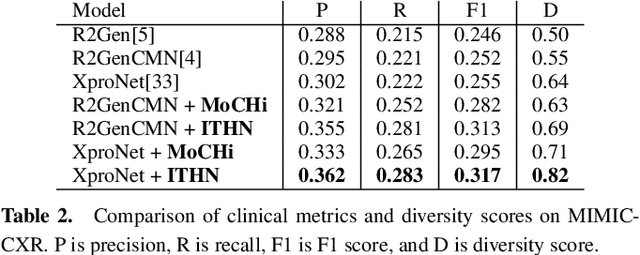
Automatic radiology report generation is challenging as medical images or reports are usually similar to each other due to the common content of anatomy. This makes a model hard to capture the uniqueness of individual images and is prone to producing undesired generic or mismatched reports. This situation calls for learning more discriminative features that could capture even fine-grained mismatches between images and reports. To achieve this, this paper proposes a novel framework to learn discriminative image and report features by distinguishing them from their closest peers, i.e., hard negatives. Especially, to attain more discriminative features, we gradually raise the difficulty of such a learning task by creating increasingly hard negative reports for each image in the feature space during training, respectively. By treating the increasingly hard negatives as auxiliary variables, we formulate this process as a min-max alternating optimisation problem. At each iteration, conditioned on a given set of hard negative reports, image and report features are learned as usual by minimising the loss functions related to report generation. After that, a new set of harder negative reports will be created by maximising a loss reflecting image-report alignment. By solving this optimisation, we attain a model that can generate more specific and accurate reports. It is noteworthy that our framework enhances discriminative feature learning without introducing extra network weights. Also, in contrast to the existing way of generating hard negatives, our framework extends beyond the granularity of the dataset by generating harder samples out of the training set. Experimental study on benchmark datasets verifies the efficacy of our framework and shows that it can serve as a plug-in to readily improve existing medical report generation models.
MRGAN360: Multi-stage Recurrent Generative Adversarial Network for 360 Degree Image Saliency Prediction
Mar 15, 2023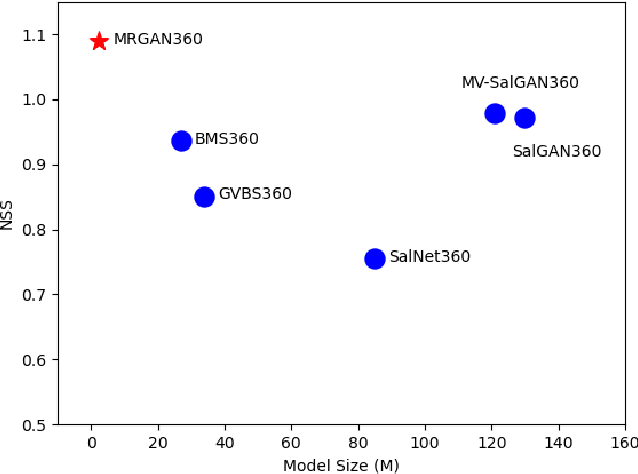
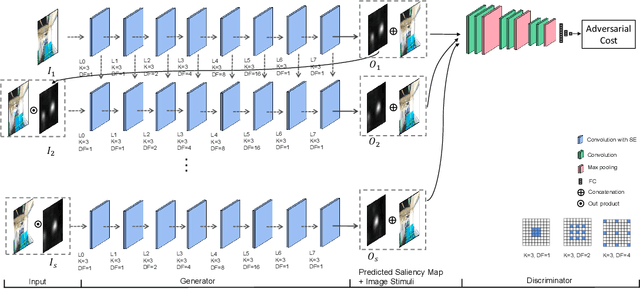
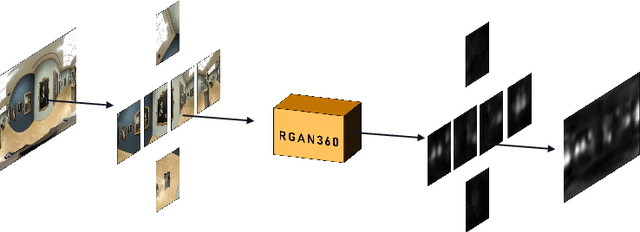

Thanks to the ability of providing an immersive and interactive experience, the uptake of 360 degree image content has been rapidly growing in consumer and industrial applications. Compared to planar 2D images, saliency prediction for 360 degree images is more challenging due to their high resolutions and spherical viewing ranges. Currently, most high-performance saliency prediction models for omnidirectional images (ODIs) rely on deeper or broader convolutional neural networks (CNNs), which benefit from CNNs' superior feature representation capabilities while suffering from their high computational costs. In this paper, inspired by the human visual cognitive process, i.e., human being's perception of a visual scene is always accomplished by multiple stages of analysis, we propose a novel multi-stage recurrent generative adversarial networks for ODIs dubbed MRGAN360, to predict the saliency maps stage by stage. At each stage, the prediction model takes as input the original image and the output of the previous stage and outputs a more accurate saliency map. We employ a recurrent neural network among adjacent prediction stages to model their correlations, and exploit a discriminator at the end of each stage to supervise the output saliency map. In addition, we share the weights among all the stages to obtain a lightweight architecture that is computationally cheap. Extensive experiments are conducted to demonstrate that our proposed model outperforms the state-of-the-art model in terms of both prediction accuracy and model size.