 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Revisiting Image Deblurring with an Efficient ConvNet
Feb 04, 2023
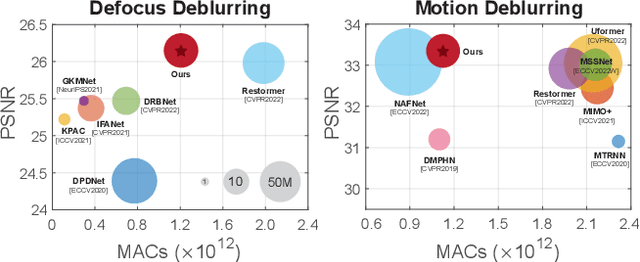
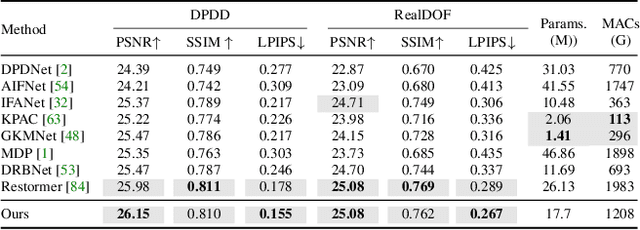
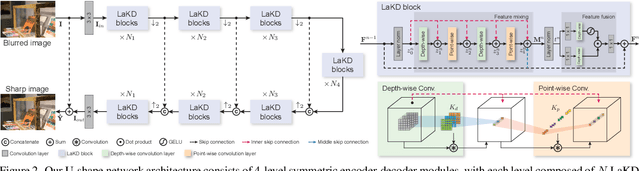
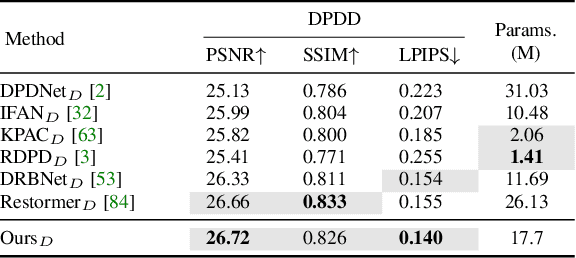
Image deblurring aims to recover the latent sharp image from its blurry counterpart and has a wide range of applications in computer vision. The Convolution Neural Networks (CNNs) have performed well in this domain for many years, and until recently an alternative network architecture, namely Transformer, has demonstrated even stronger performance. One can attribute its superiority to the multi-head self-attention (MHSA) mechanism, which offers a larger receptive field and better input content adaptability than CNNs. However, as MHSA demands high computational costs that grow quadratically with respect to the input resolution, it becomes impractical for high-resolution image deblurring tasks. In this work, we propose a unified lightweight CNN network that features a large effective receptive field (ERF) and demonstrates comparable or even better performance than Transformers while bearing less computational costs. Our key design is an efficient CNN block dubbed LaKD, equipped with a large kernel depth-wise convolution and spatial-channel mixing structure, attaining comparable or larger ERF than Transformers but with a smaller parameter scale. Specifically, we achieve +0.17dB / +0.43dB PSNR over the state-of-the-art Restormer on defocus / motion deblurring benchmark datasets with 32% fewer parameters and 39% fewer MACs. Extensive experiments demonstrate the superior performance of our network and the effectiveness of each module. Furthermore, we propose a compact and intuitive ERFMeter metric that quantitatively characterizes ERF, and shows a high correlation to the network performance. We hope this work can inspire the research community to further explore the pros and cons of CNN and Transformer architectures beyond image deblurring tasks.
Using Caterpillar to Nibble Small-Scale Images
May 28, 2023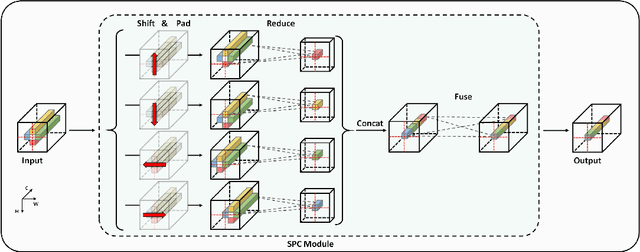
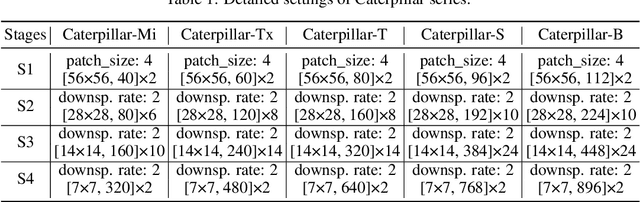
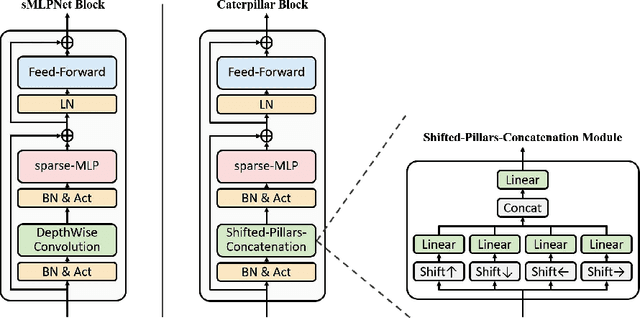
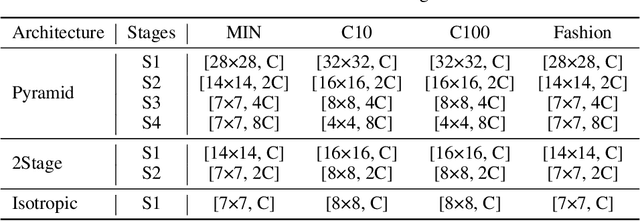
Recently, MLP-based models have become popular and attained significant performance on medium-scale datasets (e.g., ImageNet-1k). However, their direct applications to small-scale images remain limited. To address this issue, we design a new MLP-based network, namely Caterpillar, by proposing a key module of Shifted-Pillars-Concatenation (SPC) for exploiting the inductive bias of locality. SPC consists of two processes: (1) Pillars-Shift, which is to shift all pillars within an image along different directions to generate copies, and (2) Pillars-Concatenation, which is to capture the local information from discrete shift neighborhoods of the shifted copies. Extensive experiments demonstrate its strong scalability and superior performance on popular small-scale datasets, and the competitive performance on ImageNet-1K to recent state-of-the-art methods.
Fourier Test-time Adaptation with Multi-level Consistency for Robust Classification
Jun 05, 2023
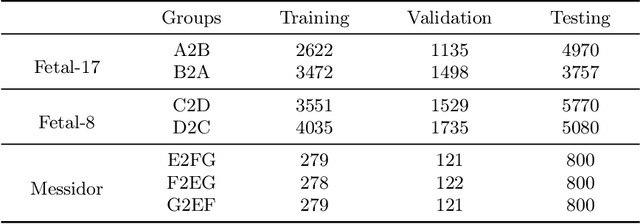

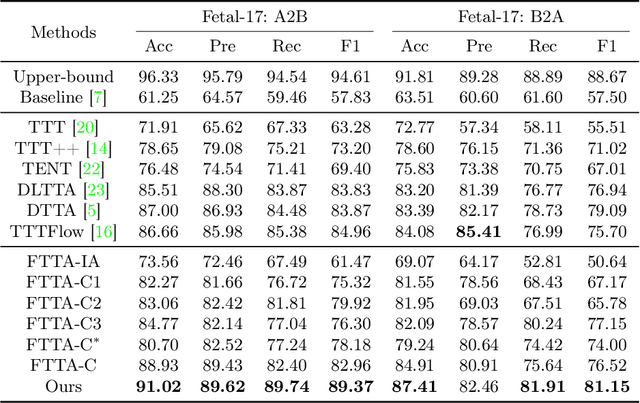
Deep classifiers may encounter significant performance degradation when processing unseen testing data from varying centers, vendors, and protocols. Ensuring the robustness of deep models against these domain shifts is crucial for their widespread clinical application. In this study, we propose a novel approach called Fourier Test-time Adaptation (FTTA), which employs a dual-adaptation design to integrate input and model tuning, thereby jointly improving the model robustness. The main idea of FTTA is to build a reliable multi-level consistency measurement of paired inputs for achieving self-correction of prediction. Our contribution is two-fold. First, we encourage consistency in global features and local attention maps between the two transformed images of the same input. Here, the transformation refers to Fourier-based input adaptation, which can transfer one unseen image into source style to reduce the domain gap. Furthermore, we leverage style-interpolated images to enhance the global and local features with learnable parameters, which can smooth the consistency measurement and accelerate convergence. Second, we introduce a regularization technique that utilizes style interpolation consistency in the frequency space to encourage self-consistency in the logit space of the model output. This regularization provides strong self-supervised signals for robustness enhancement. FTTA was extensively validated on three large classification datasets with different modalities and organs. Experimental results show that FTTA is general and outperforms other strong state-of-the-art methods.
Compressed Sensing: A Discrete Optimization Approach
Jun 05, 2023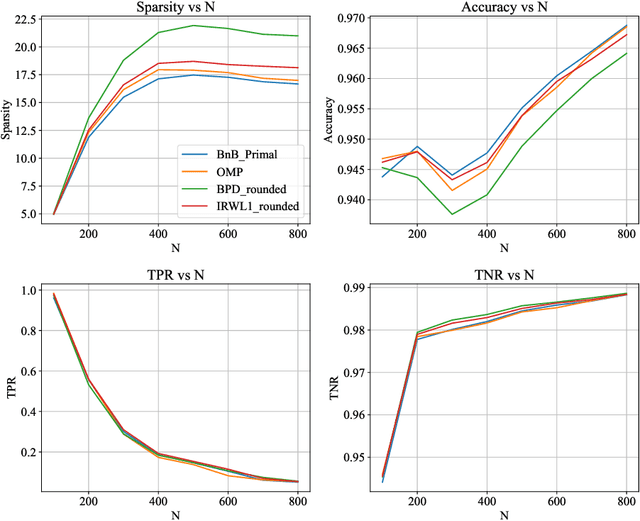
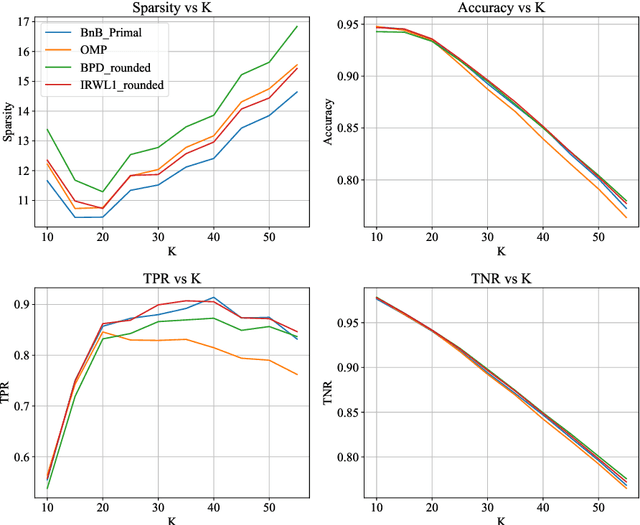
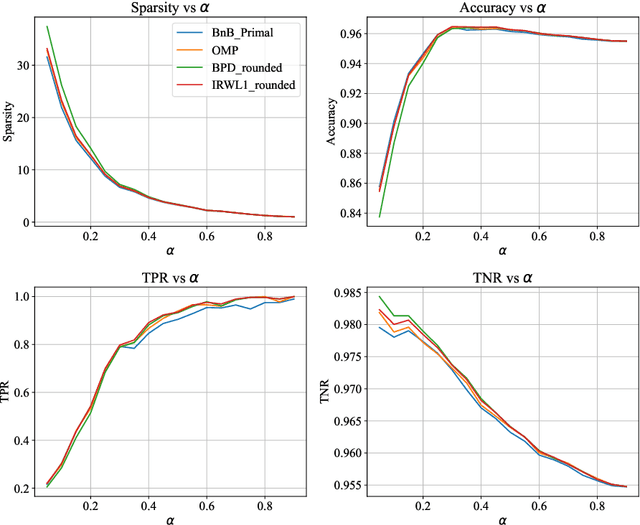
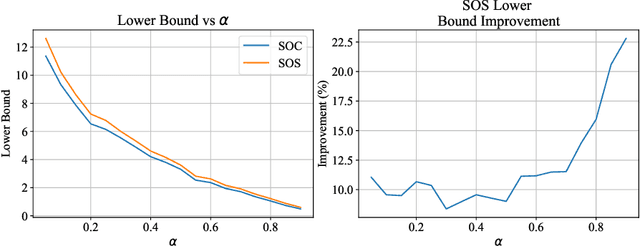
We study the Compressed Sensing (CS) problem, which is the problem of finding the most sparse vector that satisfies a set of linear measurements up to some numerical tolerance. CS is a central problem in Statistics, Operations Research and Machine Learning which arises in applications such as signal processing, data compression and image reconstruction. We introduce an $\ell_2$ regularized formulation of CS which we reformulate as a mixed integer second order cone program. We derive a second order cone relaxation of this problem and show that under mild conditions on the regularization parameter, the resulting relaxation is equivalent to the well studied basis pursuit denoising problem. We present a semidefinite relaxation that strengthens the second order cone relaxation and develop a custom branch-and-bound algorithm that leverages our second order cone relaxation to solve instances of CS to certifiable optimality. Our numerical results show that our approach produces solutions that are on average $6.22\%$ more sparse than solutions returned by state of the art benchmark methods on synthetic data in minutes. On real world ECG data, for a given $\ell_2$ reconstruction error our approach produces solutions that are on average $9.95\%$ more sparse than benchmark methods, while for a given sparsity level our approach produces solutions that have on average $10.77\%$ lower reconstruction error than benchmark methods in minutes.
Brain Diffusion for Visual Exploration: Cortical Discovery using Large Scale Generative Models
Jun 05, 2023
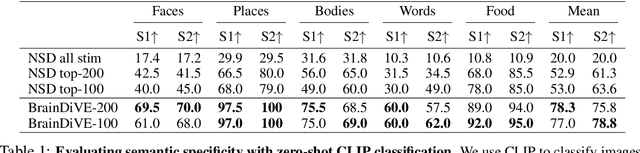
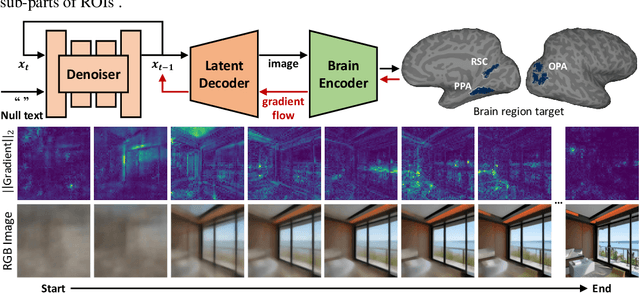
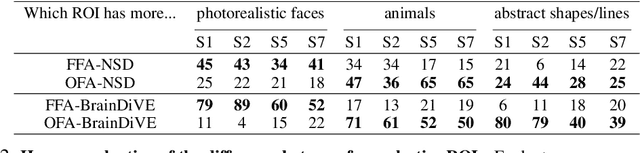
A long standing goal in neuroscience has been to elucidate the functional organization of the brain. Within higher visual cortex, functional accounts have remained relatively coarse, focusing on regions of interest (ROIs) and taking the form of selectivity for broad categories such as faces, places, bodies, food, or words. Because the identification of such ROIs has typically relied on manually assembled stimulus sets consisting of isolated objects in non-ecological contexts, exploring functional organization without robust a priori hypotheses has been challenging. To overcome these limitations, we introduce a data-driven approach in which we synthesize images predicted to activate a given brain region using paired natural images and fMRI recordings, bypassing the need for category-specific stimuli. Our approach -- Brain Diffusion for Visual Exploration ("BrainDiVE") -- builds on recent generative methods by combining large-scale diffusion models with brain-guided image synthesis. Validating our method, we demonstrate the ability to synthesize preferred images with appropriate semantic specificity for well-characterized category-selective ROIs. We then show that BrainDiVE can characterize differences between ROIs selective for the same high-level category. Finally we identify novel functional subdivisions within these ROIs, validated with behavioral data. These results advance our understanding of the fine-grained functional organization of human visual cortex, and provide well-specified constraints for further examination of cortical organization using hypothesis-driven methods.
AugDiff: Diffusion based Feature Augmentation for Multiple Instance Learning in Whole Slide Image
Mar 11, 2023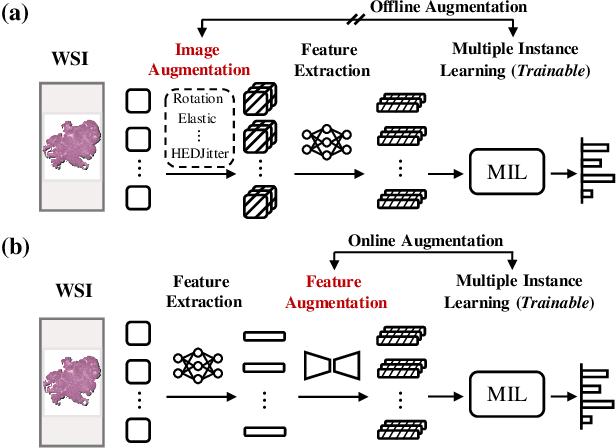
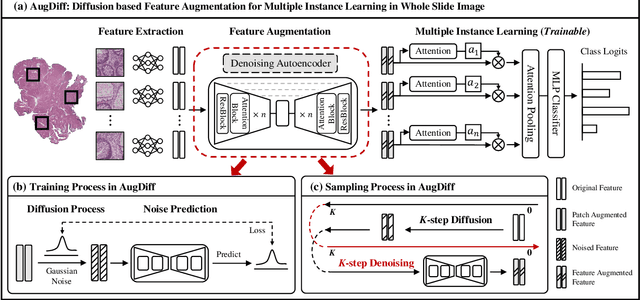
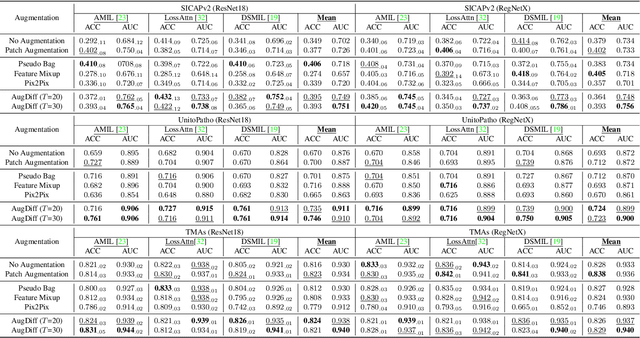
Multiple Instance Learning (MIL), a powerful strategy for weakly supervised learning, is able to perform various prediction tasks on gigapixel Whole Slide Images (WSIs). However, the tens of thousands of patches in WSIs usually incur a vast computational burden for image augmentation, limiting the MIL model's improvement in performance. Currently, the feature augmentation-based MIL framework is a promising solution, while existing methods such as Mixup often produce unrealistic features. To explore a more efficient and practical augmentation method, we introduce the Diffusion Model (DM) into MIL for the first time and propose a feature augmentation framework called AugDiff. Specifically, we employ the generation diversity of DM to improve the quality of feature augmentation and the step-by-step generation property to control the retention of semantic information. We conduct extensive experiments over three distinct cancer datasets, two different feature extractors, and three prevalent MIL algorithms to evaluate the performance of AugDiff. Ablation study and visualization further verify the effectiveness. Moreover, we highlight AugDiff's higher-quality augmented feature over image augmentation and its superiority over self-supervised learning. The generalization over external datasets indicates its broader applications.
A Transformer-based representation-learning model with unified processing of multimodal input for clinical diagnostics
Jun 01, 2023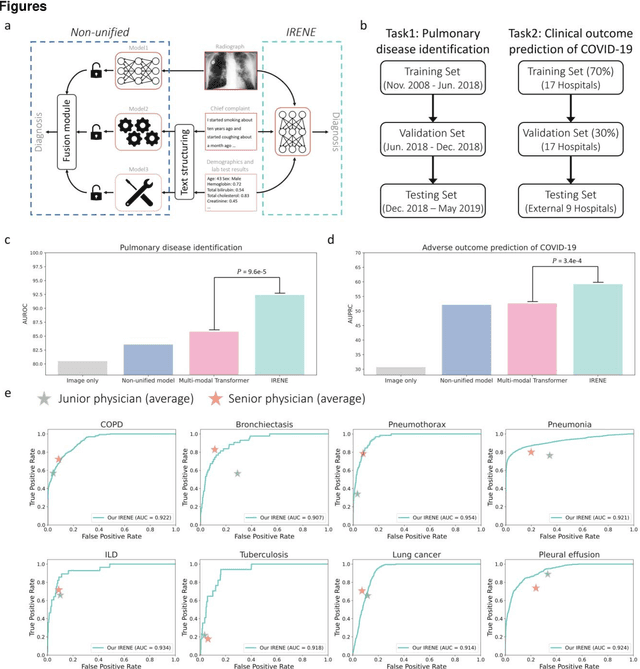
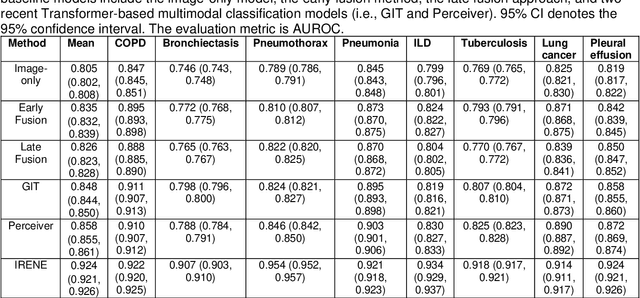
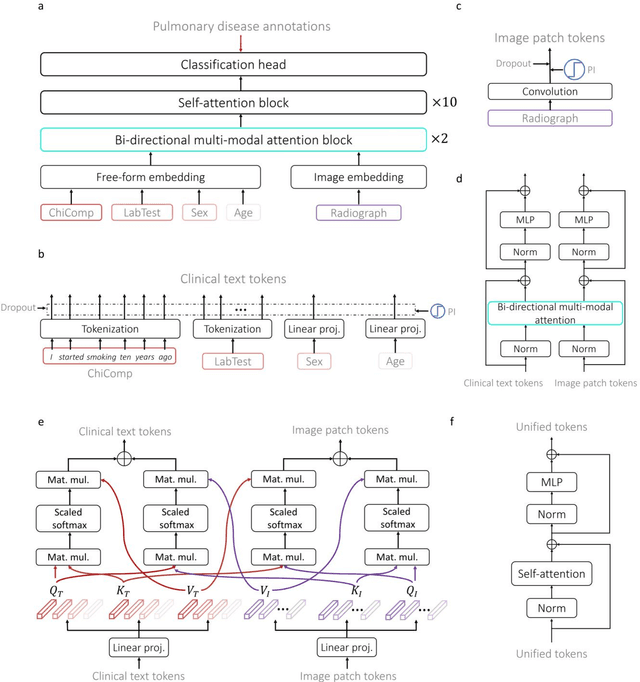
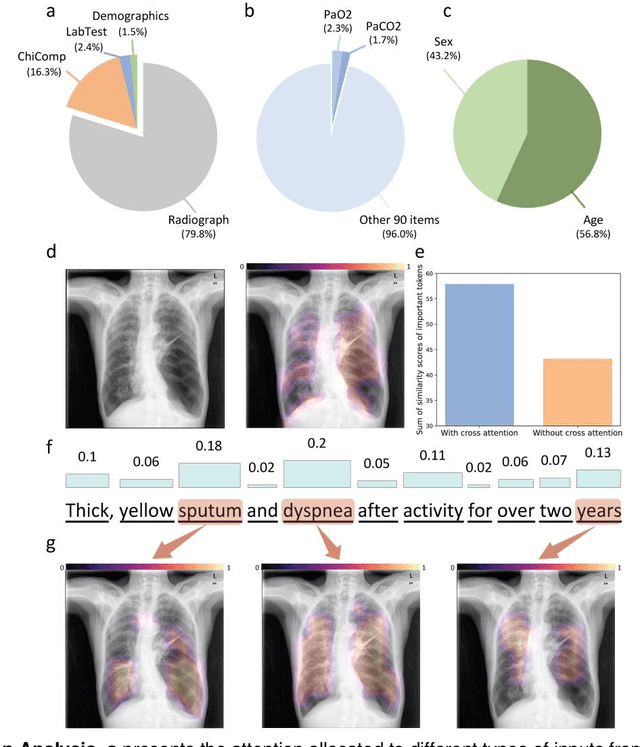
During the diagnostic process, clinicians leverage multimodal information, such as chief complaints, medical images, and laboratory-test results. Deep-learning models for aiding diagnosis have yet to meet this requirement. Here we report a Transformer-based representation-learning model as a clinical diagnostic aid that processes multimodal input in a unified manner. Rather than learning modality-specific features, the model uses embedding layers to convert images and unstructured and structured text into visual tokens and text tokens, and bidirectional blocks with intramodal and intermodal attention to learn a holistic representation of radiographs, the unstructured chief complaint and clinical history, structured clinical information such as laboratory-test results and patient demographic information. The unified model outperformed an image-only model and non-unified multimodal diagnosis models in the identification of pulmonary diseases (by 12% and 9%, respectively) and in the prediction of adverse clinical outcomes in patients with COVID-19 (by 29% and 7%, respectively). Leveraging unified multimodal Transformer-based models may help streamline triage of patients and facilitate the clinical decision process.
DiffRoom: Diffusion-based High-Quality 3D Room Reconstruction and Generation
Jun 01, 2023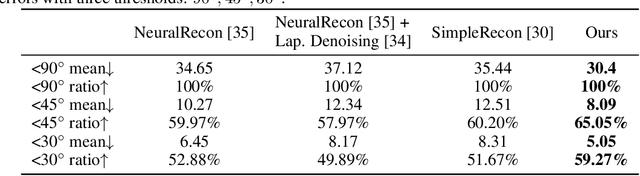

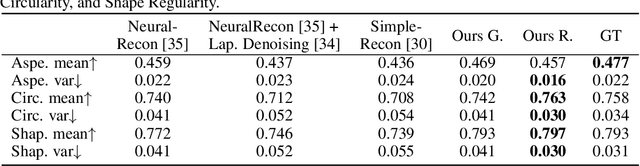
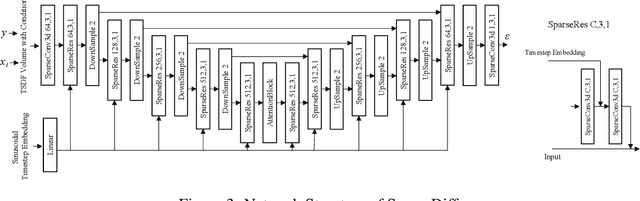
We present DiffRoom, a novel framework for tackling the problem of high-quality 3D indoor room reconstruction and generation, both of which are challenging due to the complexity and diversity of the room geometry. Although diffusion-based generative models have previously demonstrated impressive performance in image generation and object-level 3D generation, they have not yet been applied to room-level 3D generation due to their computationally intensive costs. In DiffRoom, we propose a sparse 3D diffusion network that is efficient and possesses strong generative performance for Truncated Signed Distance Field (TSDF), based on a rough occupancy prior. Inspired by KinectFusion's incremental alignment and fusion of local SDFs, we propose a diffusion-based TSDF fusion approach that iteratively diffuses and fuses TSDFs, facilitating the reconstruction and generation of an entire room environment. Additionally, to ease training, we introduce a curriculum diffusion learning paradigm that speeds up the training convergence process and enables high-quality reconstruction. According to the user study, the mesh quality generated by our DiffRoom can even outperform the ground truth mesh provided by ScanNet.
MMC: Multi-Modal Colorization of Images using Textual Descriptions
Apr 25, 2023
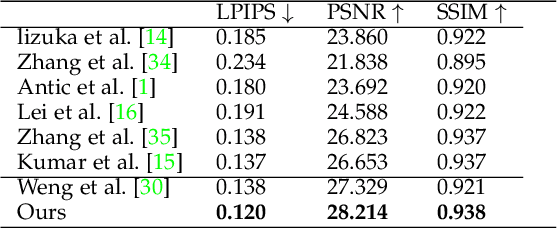
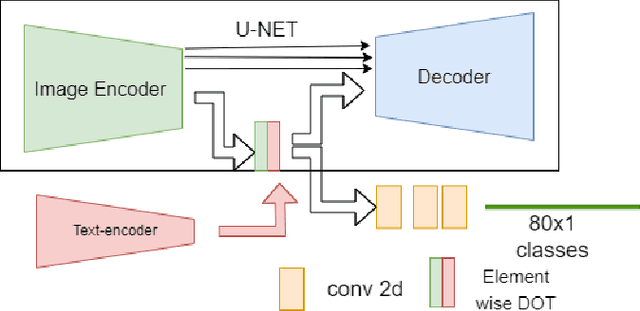
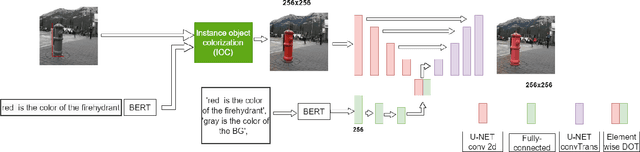
Handling various objects with different colors is a significant challenge for image colorization techniques. Thus, for complex real-world scenes, the existing image colorization algorithms often fail to maintain color consistency. In this work, we attempt to integrate textual descriptions as an auxiliary condition, along with the grayscale image that is to be colorized, to improve the fidelity of the colorization process. To do so, we have proposed a deep network that takes two inputs (grayscale image and the respective encoded text description) and tries to predict the relevant color components. Also, we have predicted each object in the image and have colorized them with their individual description to incorporate their specific attributes in the colorization process. After that, a fusion model fuses all the image objects (segments) to generate the final colorized image. As the respective textual descriptions contain color information of the objects present in the image, text encoding helps to improve the overall quality of predicted colors. In terms of performance, the proposed method outperforms existing colorization techniques in terms of LPIPS, PSNR and SSIM metrics.
SCOPE: Structural Continuity Preservation for Medical Image Segmentation
Apr 28, 2023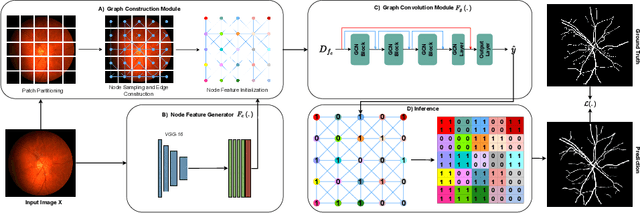
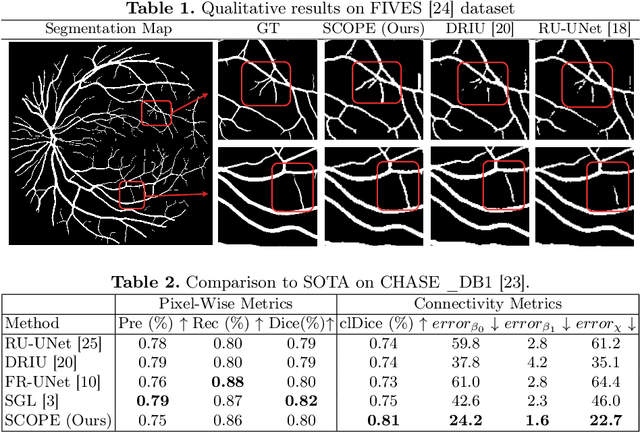
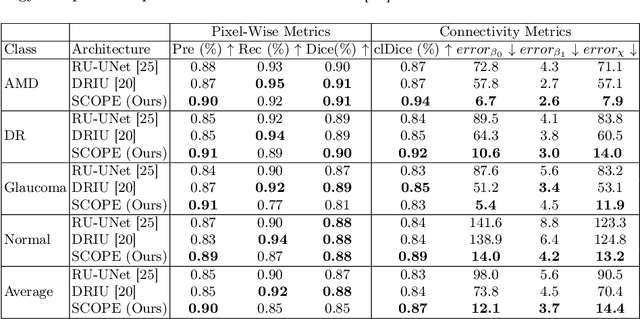
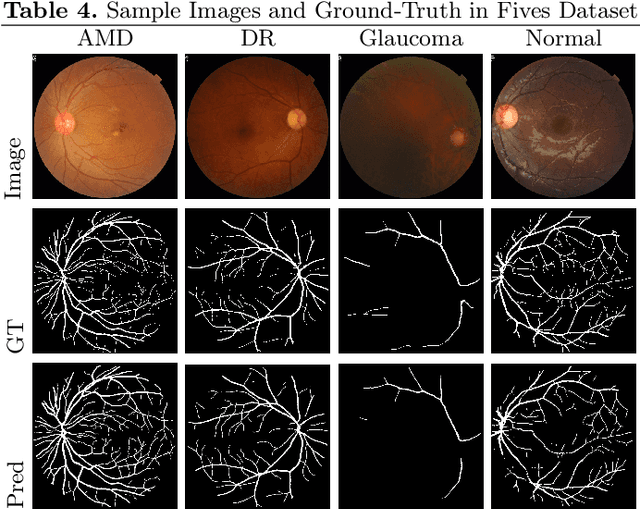
Although the preservation of shape continuity and physiological anatomy is a natural assumption in the segmentation of medical images, it is often neglected by deep learning methods that mostly aim for the statistical modeling of input data as pixels rather than interconnected structures. In biological structures, however, organs are not separate entities; for example, in reality, a severed vessel is an indication of an underlying problem, but traditional segmentation models are not designed to strictly enforce the continuity of anatomy, potentially leading to inaccurate medical diagnoses. To address this issue, we propose a graph-based approach that enforces the continuity and connectivity of anatomical topology in medical images. Our method encodes the continuity of shapes as a graph constraint, ensuring that the network's predictions maintain this continuity. We evaluate our method on two public benchmarks on retinal vessel segmentation, showing significant improvements in connectivity metrics compared to traditional methods while getting better or on-par performance on segmentation metrics.