 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic and Rapid Deep Synthesis of Molecular MRI Signals
May 30, 2023
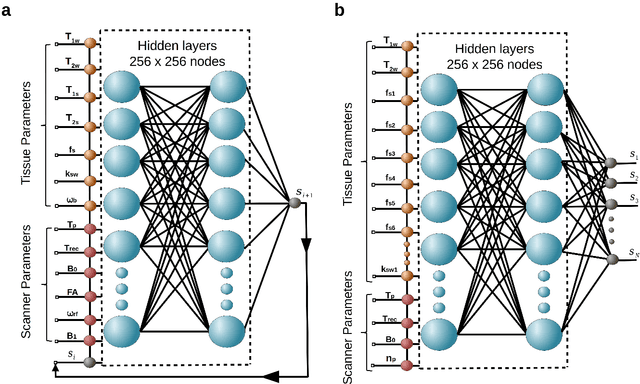

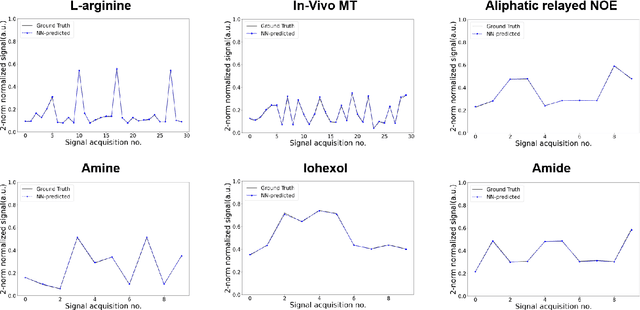
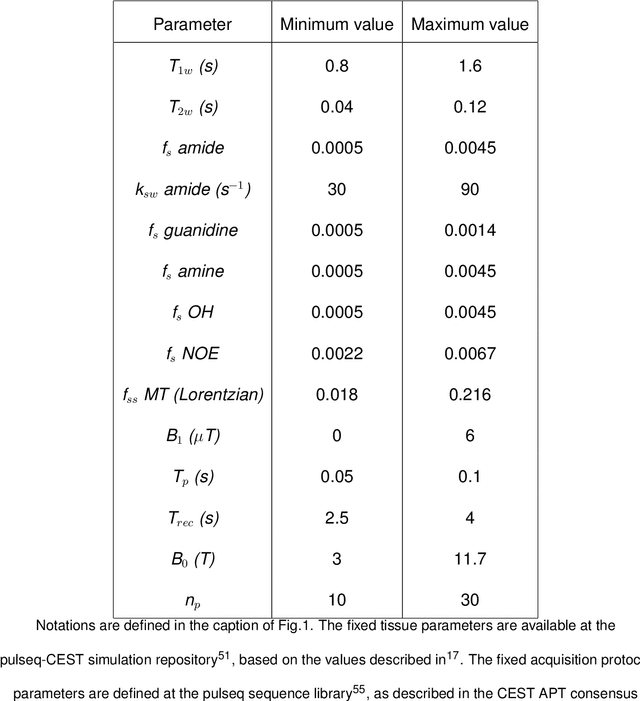
Model-driven analysis of biophysical phenomena is gaining increased attention and utility for medical imaging applications. In magnetic resonance imaging (MRI), the availability of well-established models for describing the relations between the nuclear magnetization, tissue properties, and the externally applied magnetic fields has enabled the prediction of image contrast and served as a powerful tool for designing the imaging protocols that are now routinely used in the clinic. Recently, various advanced imaging techniques have relied on these models for image reconstruction, quantitative tissue parameter extraction, and automatic optimization of acquisition protocols. In molecular MRI, however, the increased complexity of the imaging scenario, where the signals from various chemical compounds and multiple proton pools must be accounted for, results in exceedingly long model simulation times, severely hindering the progress of this approach and its dissemination for various clinical applications. Here, we show that a deep-learning-based system can capture the nonlinear relations embedded in the molecular MRI Bloch-McConnell model, enabling a rapid and accurate generation of biologically realistic synthetic data. The applicability of this simulated data for in-silico, in-vitro, and in-vivo imaging applications is then demonstrated for chemical exchange saturation transfer (CEST) and semisolid macromolecule magnetization transfer (MT) analysis and quantification. The proposed approach yielded 78%-99% acceleration in data synthesis time while retaining excellent agreement with the ground truth (Pearson's r$>$0.99, p$<$0.0001, normalized root mean square error $<$3%).
Weakly-Supervised Visual-Textual Grounding with Semantic Prior Refinement
May 18, 2023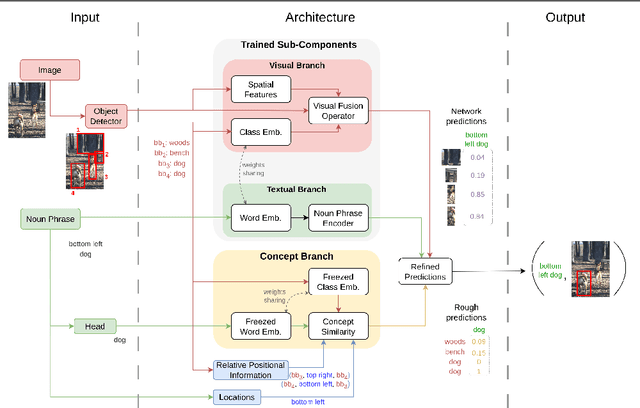
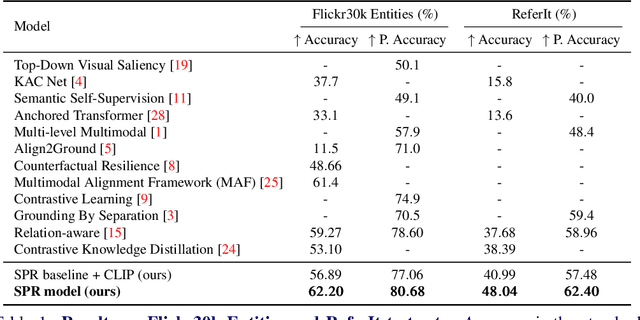
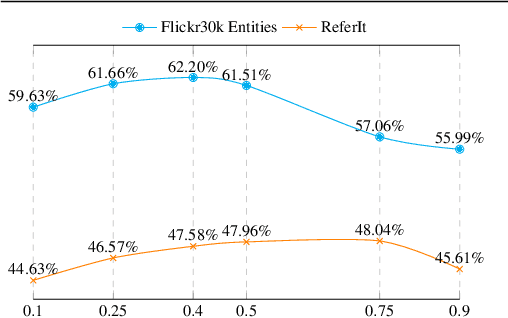
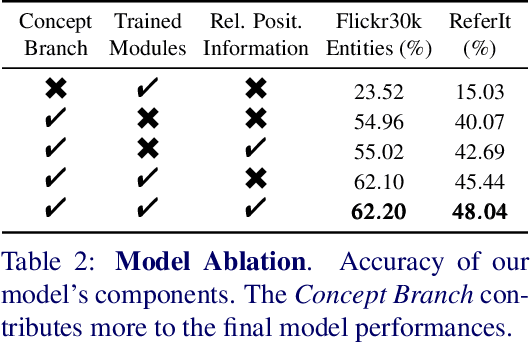
Using only image-sentence pairs, weakly-supervised visual-textual grounding aims to learn region-phrase correspondences of the respective entity mentions. Compared to the supervised approach, learning is more difficult since bounding boxes and textual phrases correspondences are unavailable. In light of this, we propose the Semantic Prior Refinement Model (SPRM), whose predictions are obtained by combining the output of two main modules. The first untrained module aims to return a rough alignment between textual phrases and bounding boxes. The second trained module is composed of two sub-components that refine the rough alignment to improve the accuracy of the final phrase-bounding box alignments. The model is trained to maximize the multimodal similarity between an image and a sentence, while minimizing the multimodal similarity of the same sentence and a new unrelated image, carefully selected to help the most during training. Our approach shows state-of-the-art results on two popular datasets, Flickr30k Entities and ReferIt, shining especially on ReferIt with a 9.6% absolute improvement. Moreover, thanks to the untrained component, it reaches competitive performances just using a small fraction of training examples.
Designing an Encoder for Fast Personalization of Text-to-Image Models
Feb 23, 2023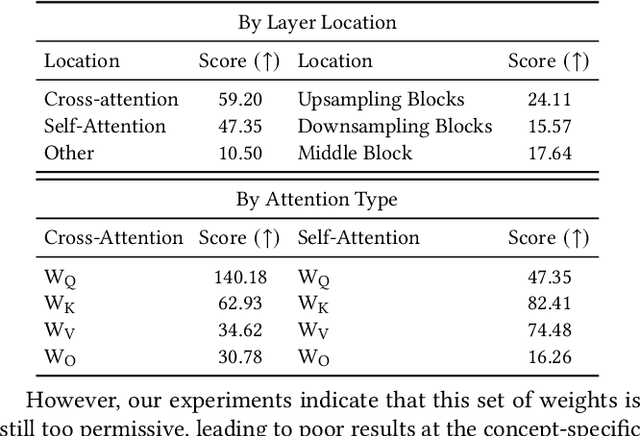
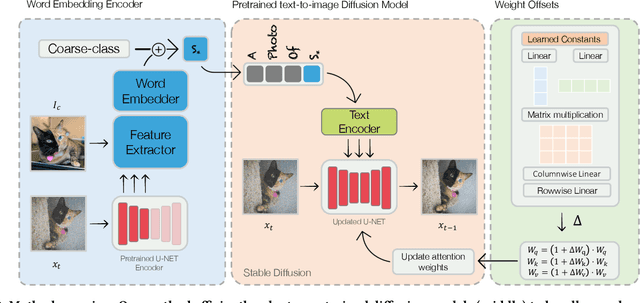

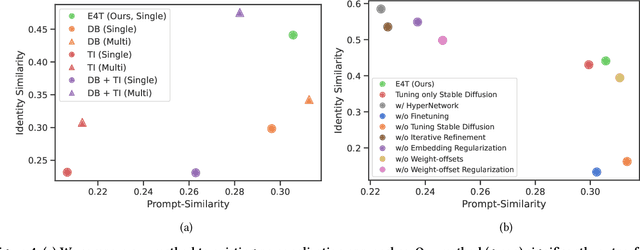
Text-to-image personalization aims to teach a pre-trained diffusion model to reason about novel, user provided concepts, embedding them into new scenes guided by natural language prompts. However, current personalization approaches struggle with lengthy training times, high storage requirements or loss of identity. To overcome these limitations, we propose an encoder-based domain-tuning approach. Our key insight is that by underfitting on a large set of concepts from a given domain, we can improve generalization and create a model that is more amenable to quickly adding novel concepts from the same domain. Specifically, we employ two components: First, an encoder that takes as an input a single image of a target concept from a given domain, e.g. a specific face, and learns to map it into a word-embedding representing the concept. Second, a set of regularized weight-offsets for the text-to-image model that learn how to effectively ingest additional concepts. Together, these components are used to guide the learning of unseen concepts, allowing us to personalize a model using only a single image and as few as 5 training steps - accelerating personalization from dozens of minutes to seconds, while preserving quality.
Urban-StyleGAN: Learning to Generate and Manipulate Images of Urban Scenes
May 16, 2023
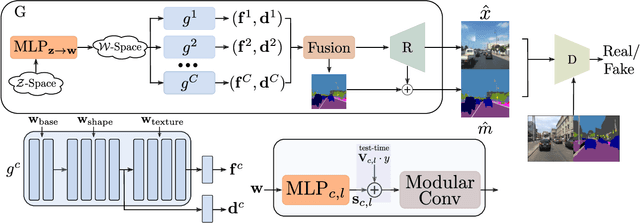
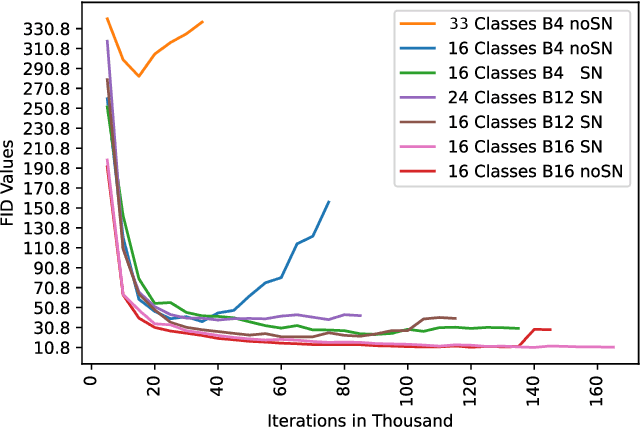
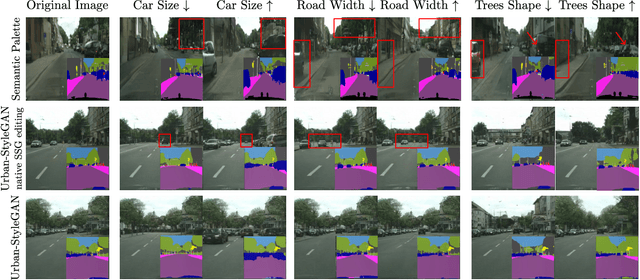
A promise of Generative Adversarial Networks (GANs) is to provide cheap photorealistic data for training and validating AI models in autonomous driving. Despite their huge success, their performance on complex images featuring multiple objects is understudied. While some frameworks produce high-quality street scenes with little to no control over the image content, others offer more control at the expense of high-quality generation. A common limitation of both approaches is the use of global latent codes for the whole image, which hinders the learning of independent object distributions. Motivated by SemanticStyleGAN (SSG), a recent work on latent space disentanglement in human face generation, we propose a novel framework, Urban-StyleGAN, for urban scene generation and manipulation. We find that a straightforward application of SSG leads to poor results because urban scenes are more complex than human faces. To provide a more compact yet disentangled latent representation, we develop a class grouping strategy wherein individual classes are grouped into super-classes. Moreover, we employ an unsupervised latent exploration algorithm in the $\mathcal{S}$-space of the generator and show that it is more efficient than the conventional $\mathcal{W}^{+}$-space in controlling the image content. Results on the Cityscapes and Mapillary datasets show the proposed approach achieves significantly more controllability and improved image quality than previous approaches on urban scenes and is on par with general-purpose non-controllable generative models (like StyleGAN2) in terms of quality.
Emotional Talking Head Generation based on Memory-Sharing and Attention-Augmented Networks
Jun 06, 2023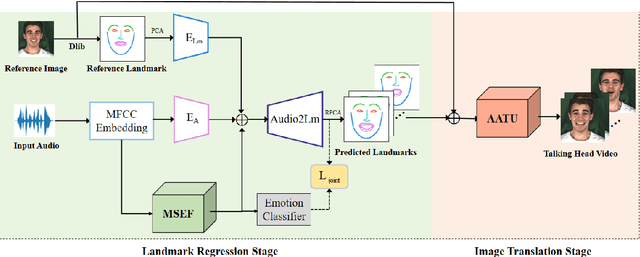
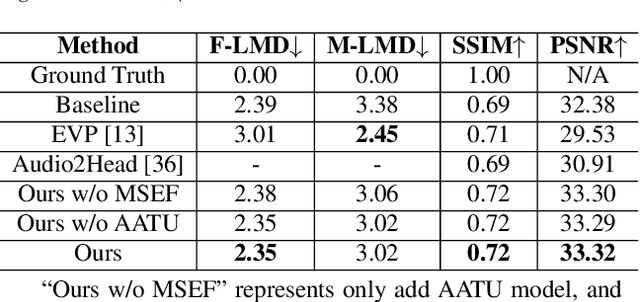
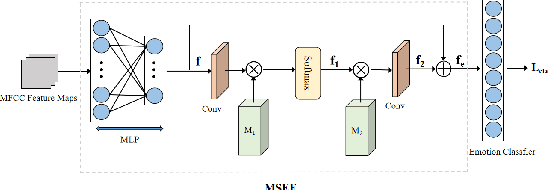
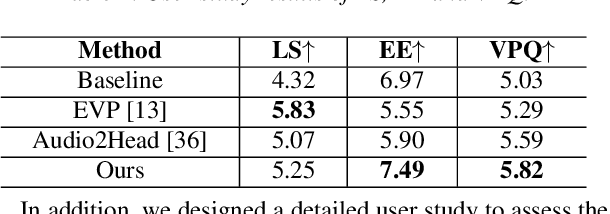
Given an audio clip and a reference face image, the goal of the talking head generation is to generate a high-fidelity talking head video. Although some audio-driven methods of generating talking head videos have made some achievements in the past, most of them only focused on lip and audio synchronization and lack the ability to reproduce the facial expressions of the target person. To this end, we propose a talking head generation model consisting of a Memory-Sharing Emotion Feature extractor (MSEF) and an Attention-Augmented Translator based on U-net (AATU). Firstly, MSEF can extract implicit emotional auxiliary features from audio to estimate more accurate emotional face landmarks.~Secondly, AATU acts as a translator between the estimated landmarks and the photo-realistic video frames. Extensive qualitative and quantitative experiments have shown the superiority of the proposed method to the previous works. Codes will be made publicly available.
AURA : Automatic Mask Generator using Randomized Input Sampling for Object Removal
May 13, 2023
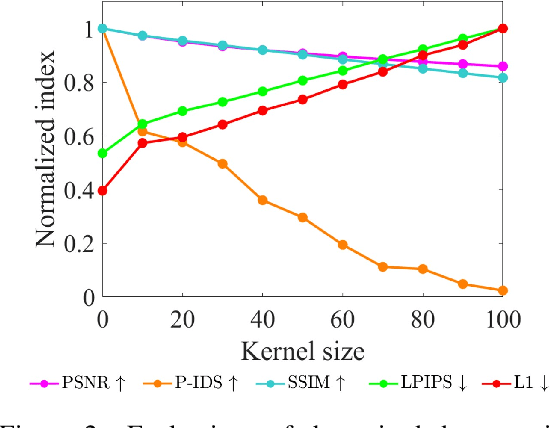
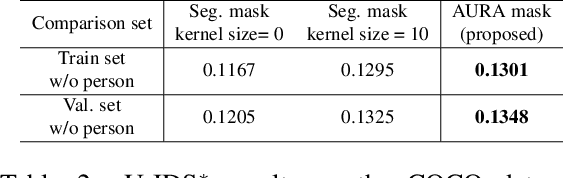
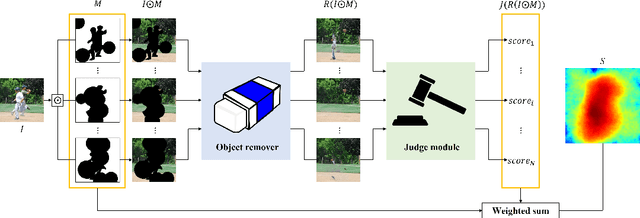
The objective of the image inpainting task is to fill missing regions of an image in a visually plausible way. Recently, deep-learning-based image inpainting networks have generated outstanding results, and some utilize their models as object removers by masking unwanted objects in an image. However, while trying to better remove objects using their networks, the previous works pay less attention to the importance of the input mask. In this paper, we focus on generating the input mask to better remove objects using the off-the-shelf image inpainting network. We propose an automatic mask generator inspired by the explainable AI (XAI) method, whose output can better remove objects than a semantic segmentation mask. The proposed method generates an importance map using randomly sampled input masks and quantitatively estimated scores of the completed images obtained from the random masks. The output mask is selected by a judge module among the candidate masks which are generated from the importance map. We design the judge module to quantitatively estimate the quality of the object removal results. In addition, we empirically find that the evaluation methods used in the previous works reporting object removal results are not appropriate for estimating the performance of an object remover. Therefore, we propose new evaluation metrics (FID$^*$ and U-IDS$^*$) to properly evaluate the quality of object removers. Experiments confirm that our method shows better performance in removing target class objects than the masks generated from the semantic segmentation maps, and the two proposed metrics make judgments consistent with humans.
DDS2M: Self-Supervised Denoising Diffusion Spatio-Spectral Model for Hyperspectral Image Restoration
Mar 19, 2023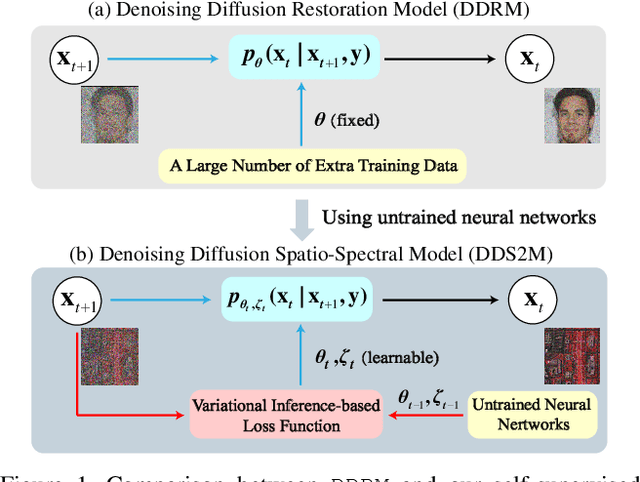
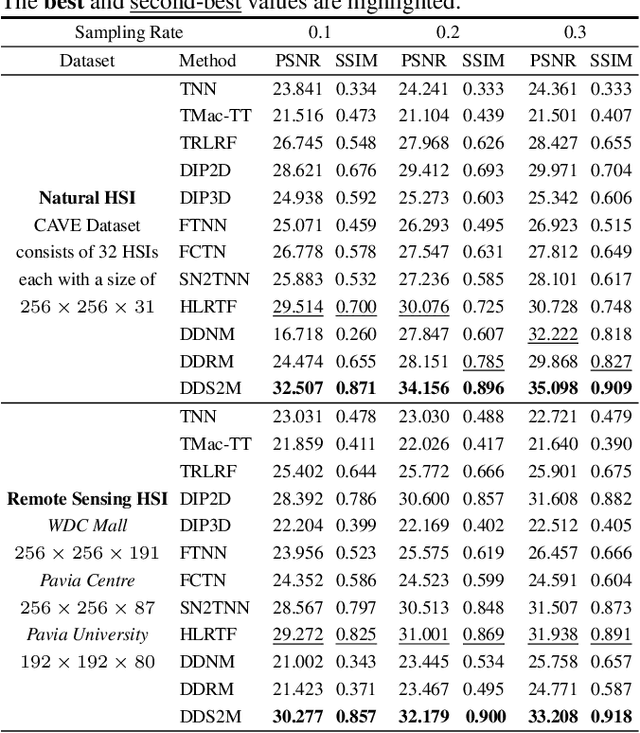
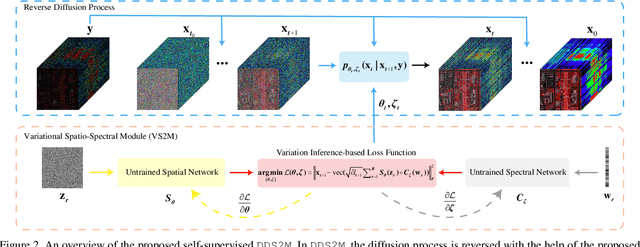
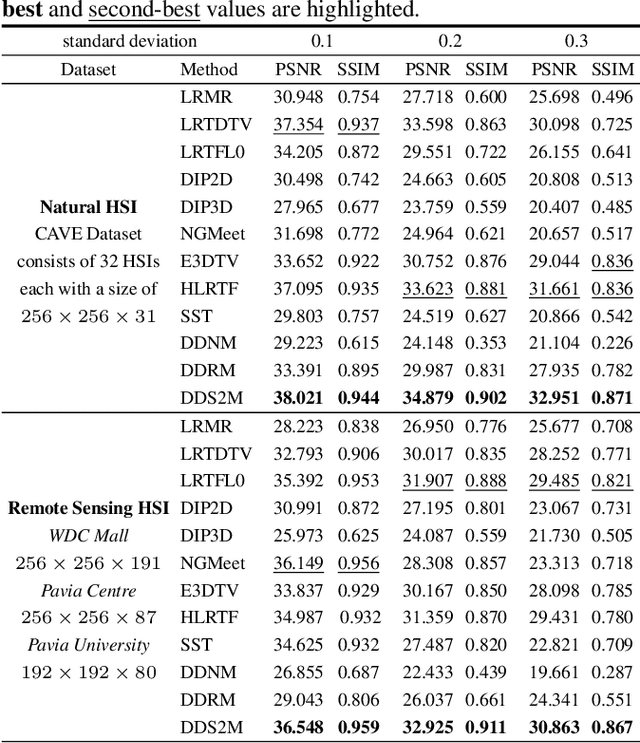
Diffusion models have recently received a surge of interest due to their impressive performance for image restoration, especially in terms of noise robustness. However, existing diffusion-based methods are trained on a large amount of training data and perform very well in-distribution, but can be quite susceptible to distribution shift. This is especially inappropriate for data-starved hyperspectral image (HSI) restoration. To tackle this problem, this work puts forth a self-supervised diffusion model for HSI restoration, namely Denoising Diffusion Spatio-Spectral Model (\texttt{DDS2M}), which works by inferring the parameters of the proposed Variational Spatio-Spectral Module (VS2M) during the reverse diffusion process, solely using the degraded HSI without any extra training data. In VS2M, a variational inference-based loss function is customized to enable the untrained spatial and spectral networks to learn the posterior distribution, which serves as the transitions of the sampling chain to help reverse the diffusion process. Benefiting from its self-supervised nature and the diffusion process, \texttt{DDS2M} enjoys stronger generalization ability to various HSIs compared to existing diffusion-based methods and superior robustness to noise compared to existing HSI restoration methods. Extensive experiments on HSI denoising, noisy HSI completion and super-resolution on a variety of HSIs demonstrate \texttt{DDS2M}'s superiority over the existing task-specific state-of-the-arts.
FIT: Frequency-based Image Translation for Domain Adaptive Object Detection
Mar 07, 2023
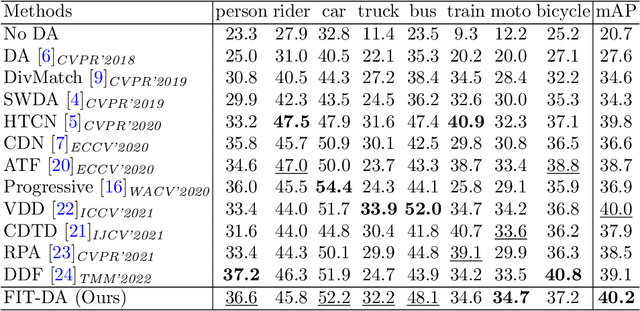
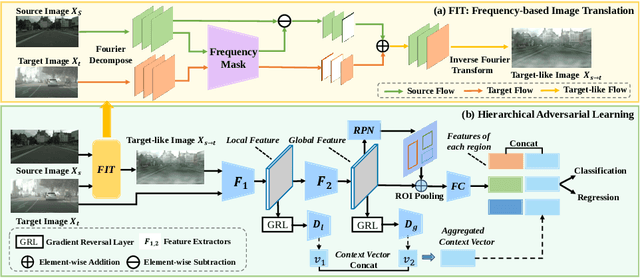

Domain adaptive object detection (DAOD) aims to adapt the detector from a labelled source domain to an unlabelled target domain. In recent years, DAOD has attracted massive attention since it can alleviate performance degradation due to the large shift of data distributions in the wild. To align distributions between domains, adversarial learning is widely used in existing DAOD methods. However, the decision boundary for the adversarial domain discriminator may be inaccurate, causing the model biased towards the source domain. To alleviate this bias, we propose a novel Frequency-based Image Translation (FIT) framework for DAOD. First, by keeping domain-invariant frequency components and swapping domain-specific ones, we conduct image translation to reduce domain shift at the input level. Second, hierarchical adversarial feature learning is utilized to further mitigate the domain gap at the feature level. Finally, we design a joint loss to train the entire network in an end-to-end manner without extra training to obtain translated images. Extensive experiments on three challenging DAOD benchmarks demonstrate the effectiveness of our method.
An Efficient Membership Inference Attack for the Diffusion Model by Proximal Initialization
May 26, 2023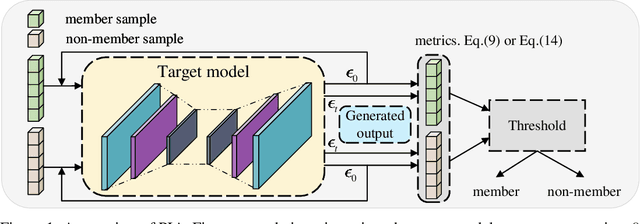
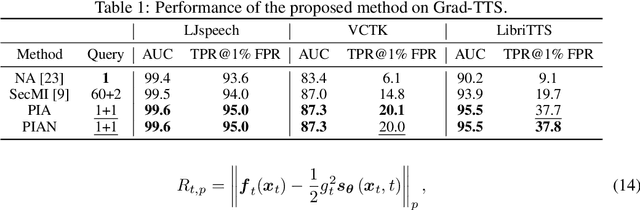
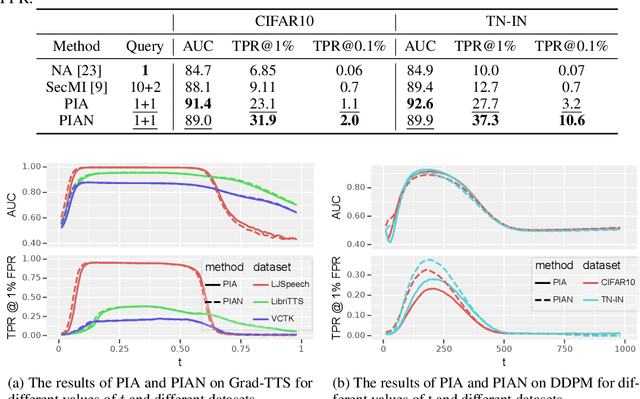
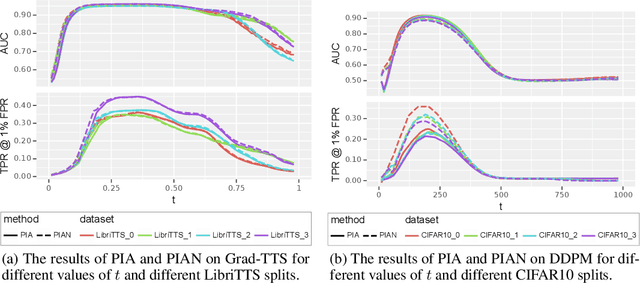
Recently, diffusion models have achieved remarkable success in generating tasks, including image and audio generation. However, like other generative models, diffusion models are prone to privacy issues. In this paper, we propose an efficient query-based membership inference attack (MIA), namely Proximal Initialization Attack (PIA), which utilizes groundtruth trajectory obtained by $\epsilon$ initialized in $t=0$ and predicted point to infer memberships. Experimental results indicate that the proposed method can achieve competitive performance with only two queries on both discrete-time and continuous-time diffusion models. Moreover, previous works on the privacy of diffusion models have focused on vision tasks without considering audio tasks. Therefore, we also explore the robustness of diffusion models to MIA in the text-to-speech (TTS) task, which is an audio generation task. To the best of our knowledge, this work is the first to study the robustness of diffusion models to MIA in the TTS task. Experimental results indicate that models with mel-spectrogram (image-like) output are vulnerable to MIA, while models with audio output are relatively robust to MIA. {Code is available at \url{https://github.com/kong13661/PIA}}.
Extremely weakly-supervised blood vessel segmentation with physiologically based synthesis and domain adaptation
May 26, 2023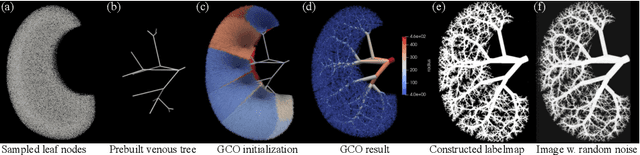

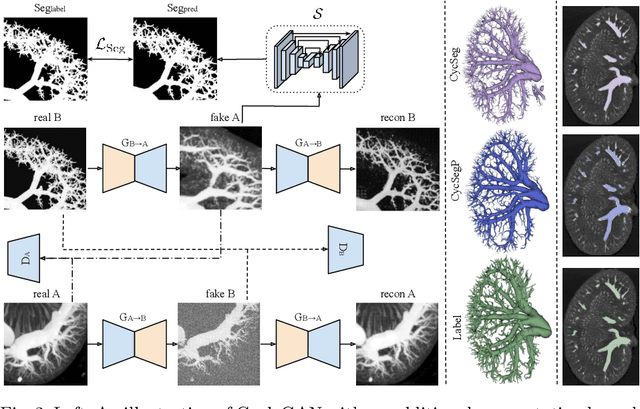
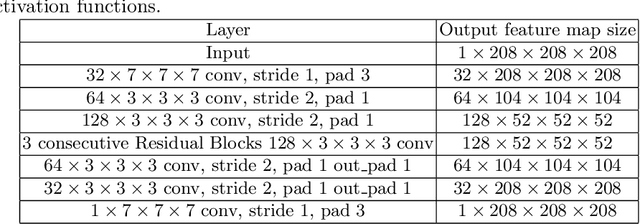
Accurate analysis and modeling of renal functions require a precise segmentation of the renal blood vessels. Micro-CT scans provide image data at higher resolutions, making more small vessels near the renal cortex visible. Although deep-learning-based methods have shown state-of-the-art performance in automatic blood vessel segmentations, they require a large amount of labeled training data. However, voxel-wise labeling in micro-CT scans is extremely time-consuming given the huge volume sizes. To mitigate the problem, we simulate synthetic renal vascular trees physiologically while generating corresponding scans of the simulated trees by training a generative model on unlabeled scans. This enables the generative model to learn the mapping implicitly without the need for explicit functions to emulate the image acquisition process. We further propose an additional segmentation branch over the generative model trained on the generated scans. We demonstrate that the model can directly segment blood vessels on real scans and validate our method on both 3D micro-CT scans of rat kidneys and a proof-of-concept experiment on 2D retinal images. Code and 3D results are available at https://github.com/miccai2023anony/RenalVesselSeg