 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Schema Inference for Interpretable Image Classification
Mar 12, 2023
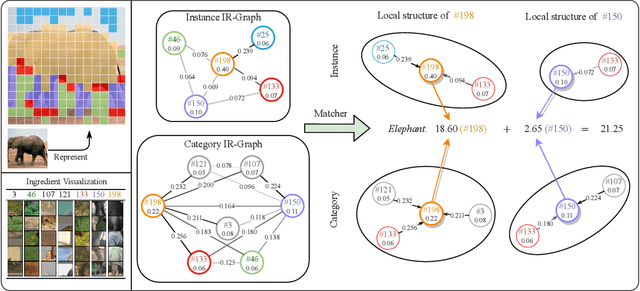
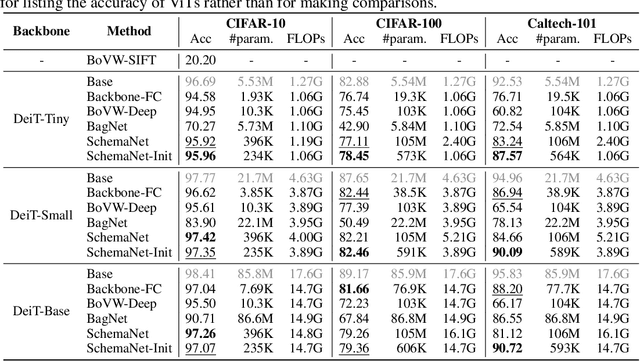
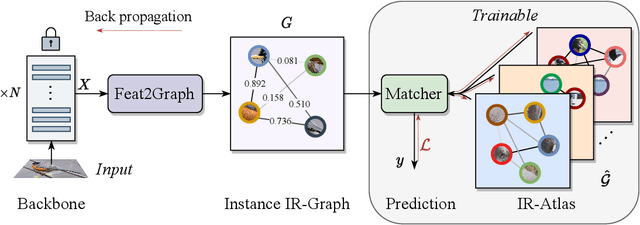
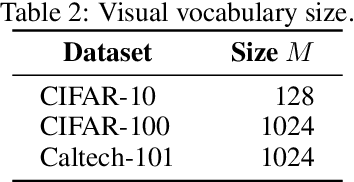
In this paper, we study a novel inference paradigm, termed as schema inference, that learns to deductively infer the explainable predictions by rebuilding the prior deep neural network (DNN) forwarding scheme, guided by the prevalent philosophical cognitive concept of schema. We strive to reformulate the conventional model inference pipeline into a graph matching policy that associates the extracted visual concepts of an image with the pre-computed scene impression, by analogy with human reasoning mechanism via impression matching. To this end, we devise an elaborated architecture, termed as SchemaNet, as a dedicated instantiation of the proposed schema inference concept, that models both the visual semantics of input instances and the learned abstract imaginations of target categories as topological relational graphs. Meanwhile, to capture and leverage the compositional contributions of visual semantics in a global view, we also introduce a universal Feat2Graph scheme in SchemaNet to establish the relational graphs that contain abundant interaction information. Both the theoretical analysis and the experimental results on several benchmarks demonstrate that the proposed schema inference achieves encouraging performance and meanwhile yields a clear picture of the deductive process leading to the predictions. Our code is available at https://github.com/zhfeing/SchemaNet-PyTorch.
Vision-Language Models in Remote Sensing: Current Progress and Future Trends
May 09, 2023
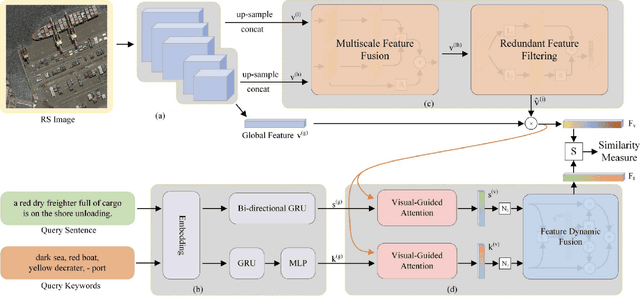
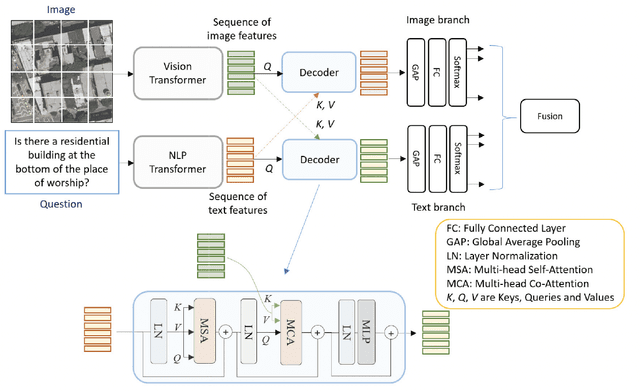
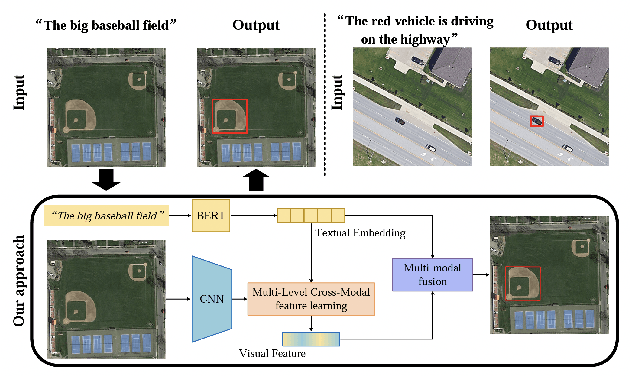
The remarkable achievements of ChatGPT and GPT-4 have sparked a wave of interest and research in the field of large language models for Artificial General Intelligence (AGI). These models provide us with intelligent solutions that are more similar to human thinking, enabling us to use general artificial intelligence to solve problems in various applications. However, in the field of remote sensing, the scientific literature on the implementation of AGI remains relatively scant. Existing AI-related research primarily focuses on visual understanding tasks while neglecting the semantic understanding of the objects and their relationships. This is where vision-language models excel, as they enable reasoning about images and their associated textual descriptions, allowing for a deeper understanding of the underlying semantics. Vision-language models can go beyond recognizing the objects in an image and can infer the relationships between them, as well as generate natural language descriptions of the image. This makes them better suited for tasks that require both visual and textual understanding, such as image captioning, text-based image retrieval, and visual question answering. This paper provides a comprehensive review of the research on vision-language models in remote sensing, summarizing the latest progress, highlighting the current challenges, and identifying potential research opportunities. Specifically, we review the application of vision-language models in several mainstream remote sensing tasks, including image captioning, text-based image generation, text-based image retrieval, visual question answering, scene classification, semantic segmentation, and object detection. For each task, we briefly describe the task background and review some representative works. Finally, we summarize the limitations of existing work and provide some possible directions for future development.
Few-Shot Domain Adaptation for Low Light RAW Image Enhancement
Mar 27, 2023
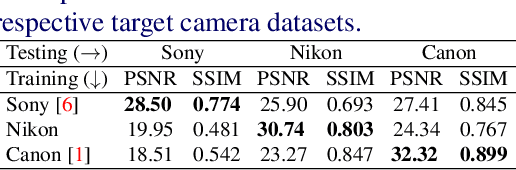
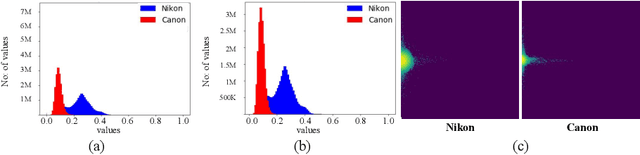
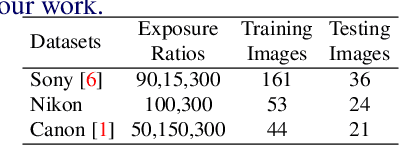
Enhancing practical low light raw images is a difficult task due to severe noise and color distortions from short exposure time and limited illumination. Despite the success of existing Convolutional Neural Network (CNN) based methods, their performance is not adaptable to different camera domains. In addition, such methods also require large datasets with short-exposure and corresponding long-exposure ground truth raw images for each camera domain, which is tedious to compile. To address this issue, we present a novel few-shot domain adaptation method to utilize the existing source camera labeled data with few labeled samples from the target camera to improve the target domain's enhancement quality in extreme low-light imaging. Our experiments show that only ten or fewer labeled samples from the target camera domain are sufficient to achieve similar or better enhancement performance than training a model with a large labeled target camera dataset. To support research in this direction, we also present a new low-light raw image dataset captured with a Nikon camera, comprising short-exposure and their corresponding long-exposure ground truth images.
* BMVC 2021 Best Student Paper Award (Runner-Up). Project Page: https://val.cds.iisc.ac.in/HDR/BMVC21/index.html
Learning Distortion Invariant Representation for Image Restoration from A Causality Perspective
Mar 13, 2023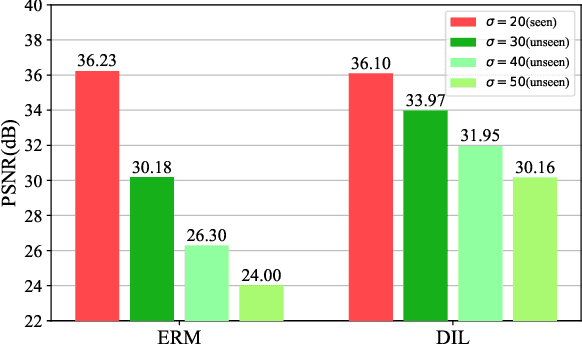
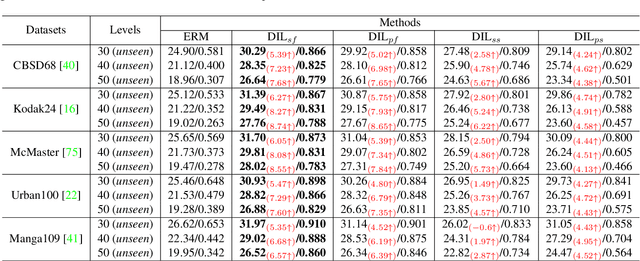
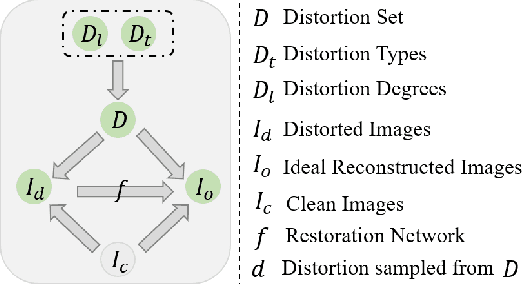
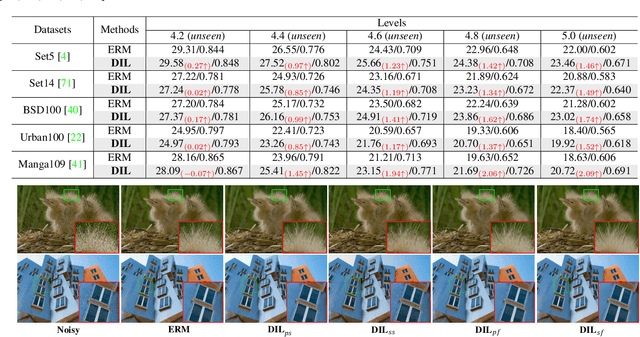
In recent years, we have witnessed the great advancement of Deep neural networks (DNNs) in image restoration. However, a critical limitation is that they cannot generalize well to real-world degradations with different degrees or types. In this paper, we are the first to propose a novel training strategy for image restoration from the causality perspective, to improve the generalization ability of DNNs for unknown degradations. Our method, termed Distortion Invariant representation Learning (DIL), treats each distortion type and degree as one specific confounder, and learns the distortion-invariant representation by eliminating the harmful confounding effect of each degradation. We derive our DIL with the back-door criterion in causality by modeling the interventions of different distortions from the optimization perspective. Particularly, we introduce counterfactual distortion augmentation to simulate the virtual distortion types and degrees as the confounders. Then, we instantiate the intervention of each distortion with a virtual model updating based on corresponding distorted images, and eliminate them from the meta-learning perspective. Extensive experiments demonstrate the effectiveness of our DIL on the generalization capability for unseen distortion types and degrees. Our code will be available at https://github.com/lixinustc/Casual-IRDIL.
Hi-ResNet: A High-Resolution Remote Sensing Network for Semantic Segmentation
May 23, 2023
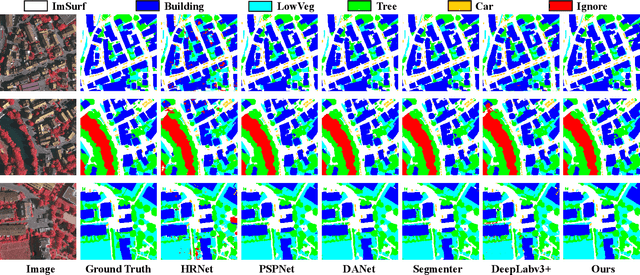
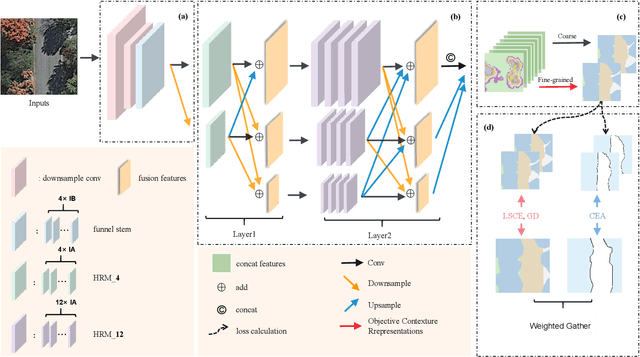
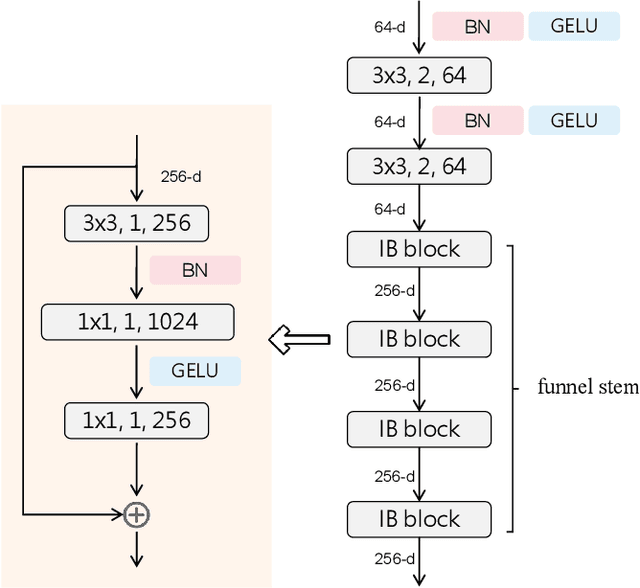
High-resolution remote sensing (HRS) semantic segmentation extracts key objects from high-resolution coverage areas. However, objects of the same category within HRS images generally show significant differences in scale and shape across diverse geographical environments, making it difficult to fit the data distribution. Additionally, a complex background environment causes similar appearances of objects of different categories, which precipitates a substantial number of objects into misclassification as background. These issues make existing learning algorithms sub-optimal. In this work, we solve the above-mentioned problems by proposing a High-resolution remote sensing network (Hi-ResNet) with efficient network structure designs, which consists of a funnel module, a multi-branch module with stacks of information aggregation (IA) blocks, and a feature refinement module, sequentially, and Class-agnostic Edge Aware (CEA) loss. Specifically, we propose a funnel module to downsample, which reduces the computational cost, and extract high-resolution semantic information from the initial input image. Secondly, we downsample the processed feature images into multi-resolution branches incrementally to capture image features at different scales and apply IA blocks, which capture key latent information by leveraging attention mechanisms, for effective feature aggregation, distinguishing image features of the same class with variant scales and shapes. Finally, our feature refinement module integrate the CEA loss function, which disambiguates inter-class objects with similar shapes and increases the data distribution distance for correct predictions. With effective pre-training strategies, we demonstrated the superiority of Hi-ResNet over state-of-the-art methods on three HRS segmentation benchmarks.
CG-3DSRGAN: A classification guided 3D generative adversarial network for image quality recovery from low-dose PET images
Apr 03, 2023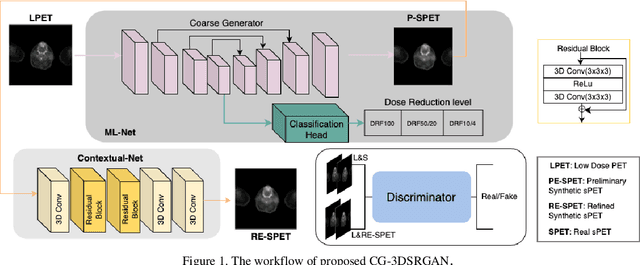
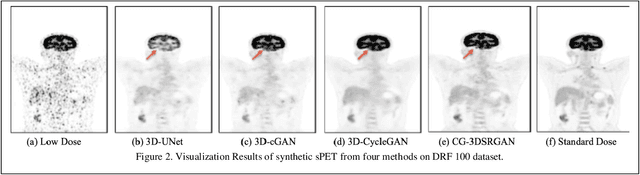
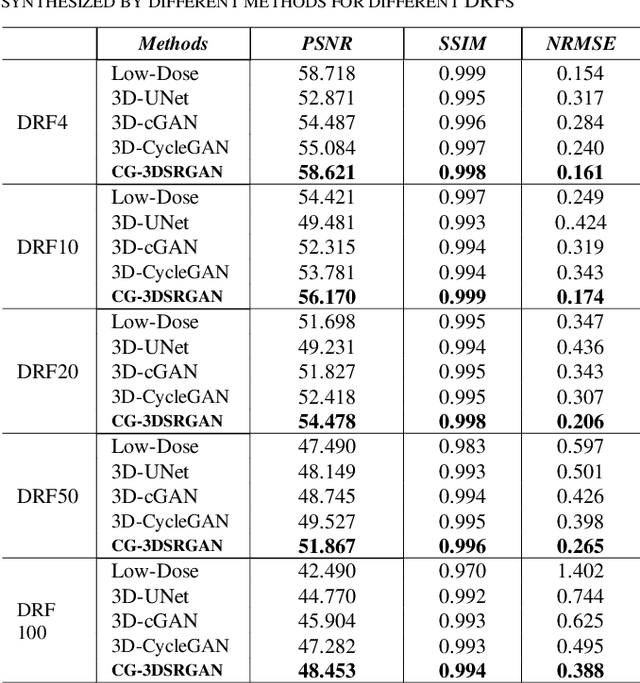
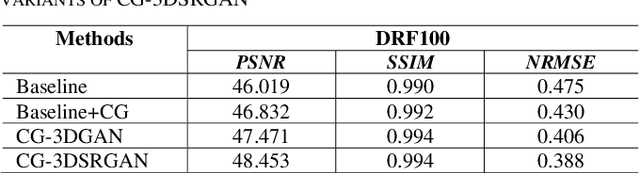
Positron emission tomography (PET) is the most sensitive molecular imaging modality routinely applied in our modern healthcare. High radioactivity caused by the injected tracer dose is a major concern in PET imaging and limits its clinical applications. However, reducing the dose leads to inadequate image quality for diagnostic practice. Motivated by the need to produce high quality images with minimum low-dose, Convolutional Neural Networks (CNNs) based methods have been developed for high quality PET synthesis from its low-dose counterparts. Previous CNNs-based studies usually directly map low-dose PET into features space without consideration of different dose reduction level. In this study, a novel approach named CG-3DSRGAN (Classification-Guided Generative Adversarial Network with Super Resolution Refinement) is presented. Specifically, a multi-tasking coarse generator, guided by a classification head, allows for a more comprehensive understanding of the noise-level features present in the low-dose data, resulting in improved image synthesis. Moreover, to recover spatial details of standard PET, an auxiliary super resolution network - Contextual-Net - is proposed as a second-stage training to narrow the gap between coarse prediction and standard PET. We compared our method to the state-of-the-art methods on whole-body PET with different dose reduction factors (DRFs). Experiments demonstrate our method can outperform others on all DRF.
Multimodal Garment Designer: Human-Centric Latent Diffusion Models for Fashion Image Editing
Apr 04, 2023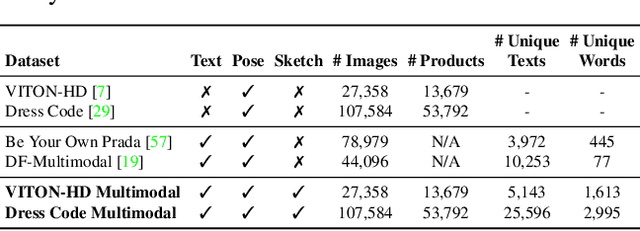
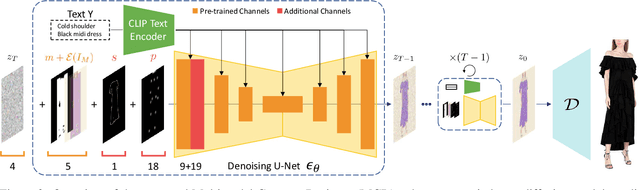
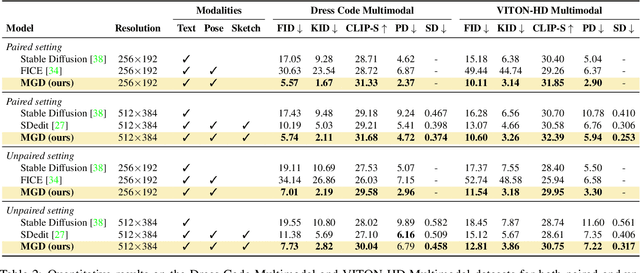

Fashion illustration is used by designers to communicate their vision and to bring the design idea from conceptualization to realization, showing how clothes interact with the human body. In this context, computer vision can thus be used to improve the fashion design process. Differently from previous works that mainly focused on the virtual try-on of garments, we propose the task of multimodal-conditioned fashion image editing, guiding the generation of human-centric fashion images by following multimodal prompts, such as text, human body poses, and garment sketches. We tackle this problem by proposing a new architecture based on latent diffusion models, an approach that has not been used before in the fashion domain. Given the lack of existing datasets suitable for the task, we also extend two existing fashion datasets, namely Dress Code and VITON-HD, with multimodal annotations collected in a semi-automatic manner. Experimental results on these new datasets demonstrate the effectiveness of our proposal, both in terms of realism and coherence with the given multimodal inputs. Source code and collected multimodal annotations will be publicly released at: https://github.com/aimagelab/multimodal-garment-designer.
RGI: robust GAN-inversion for mask-free image inpainting and unsupervised pixel-wise anomaly detection
Feb 24, 2023
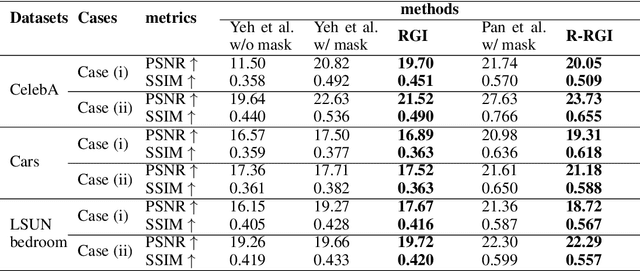
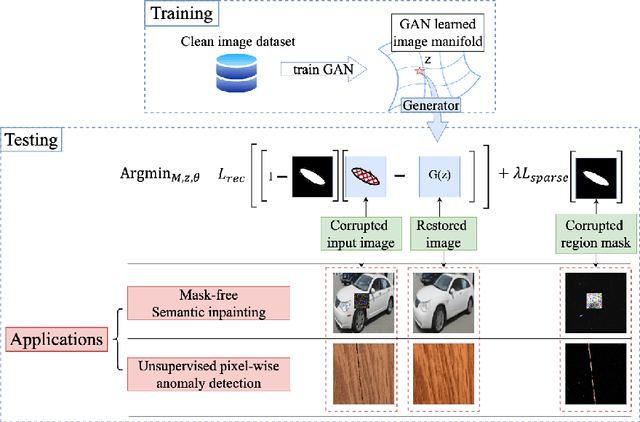
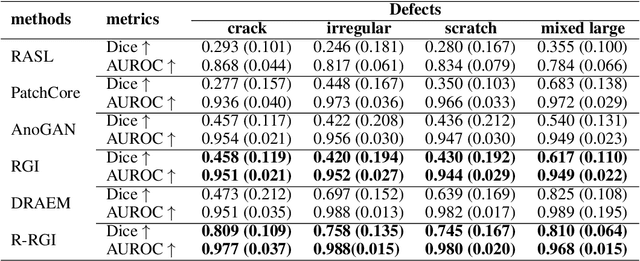
Generative adversarial networks (GANs), trained on a large-scale image dataset, can be a good approximator of the natural image manifold. GAN-inversion, using a pre-trained generator as a deep generative prior, is a promising tool for image restoration under corruptions. However, the performance of GAN-inversion can be limited by a lack of robustness to unknown gross corruptions, i.e., the restored image might easily deviate from the ground truth. In this paper, we propose a Robust GAN-inversion (RGI) method with a provable robustness guarantee to achieve image restoration under unknown \textit{gross} corruptions, where a small fraction of pixels are completely corrupted. Under mild assumptions, we show that the restored image and the identified corrupted region mask converge asymptotically to the ground truth. Moreover, we extend RGI to Relaxed-RGI (R-RGI) for generator fine-tuning to mitigate the gap between the GAN learned manifold and the true image manifold while avoiding trivial overfitting to the corrupted input image, which further improves the image restoration and corrupted region mask identification performance. The proposed RGI/R-RGI method unifies two important applications with state-of-the-art (SOTA) performance: (i) mask-free semantic inpainting, where the corruptions are unknown missing regions, the restored background can be used to restore the missing content; (ii) unsupervised pixel-wise anomaly detection, where the corruptions are unknown anomalous regions, the retrieved mask can be used as the anomalous region's segmentation mask.
ChatBridge: Bridging Modalities with Large Language Model as a Language Catalyst
May 25, 2023
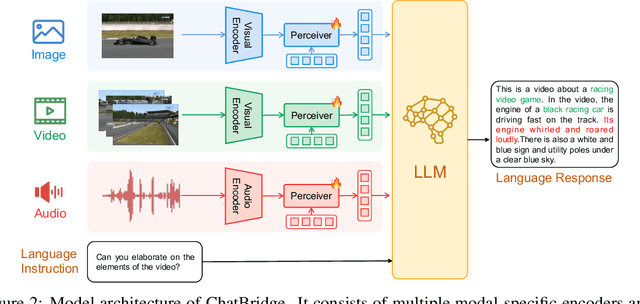
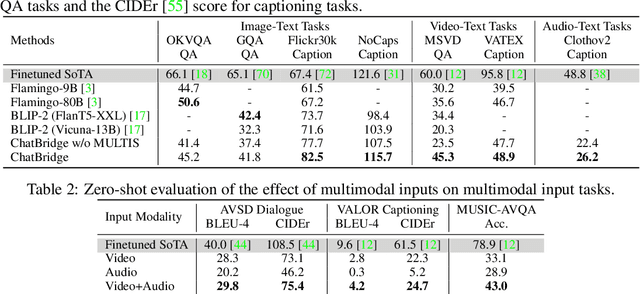
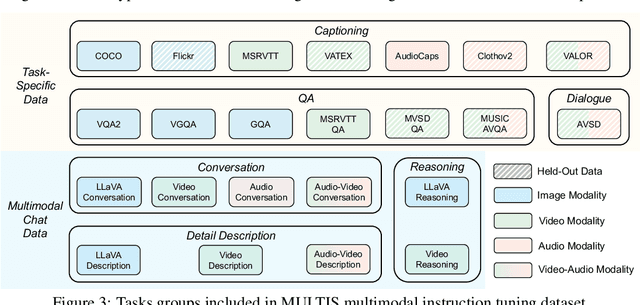
Building general-purpose models that can perceive diverse real-world modalities and solve various tasks is an appealing target in artificial intelligence. In this paper, we present ChatBridge, a novel multimodal language model that leverages the expressive capabilities of language as the catalyst to bridge the gap between various modalities. We show that only language-paired two-modality data is sufficient to connect all modalities. ChatBridge leverages recent large language models (LLM) and extends their zero-shot capabilities to incorporate diverse multimodal inputs. ChatBridge undergoes a two-stage training. The first stage aligns each modality with language, which brings emergent multimodal correlation and collaboration abilities. The second stage instruction-finetunes ChatBridge to align it with user intent with our newly proposed multimodal instruction tuning dataset, named MULTIS, which covers a wide range of 16 multimodal tasks of text, image, video, and audio modalities. We show strong quantitative and qualitative results on zero-shot multimodal tasks covering text, image, video, and audio modalities. All codes, data, and models of ChatBridge will be open-sourced.
Unlocking the Potential of Medical Imaging with ChatGPT's Intelligent Diagnostics
May 12, 2023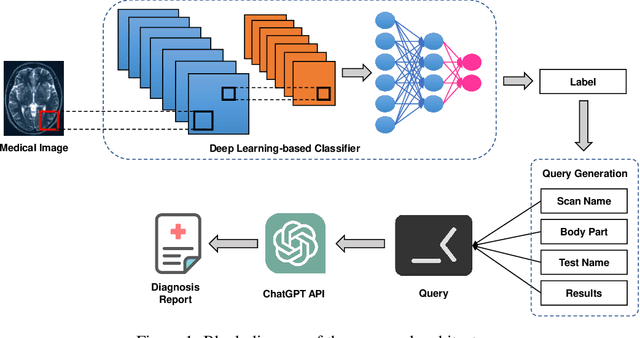
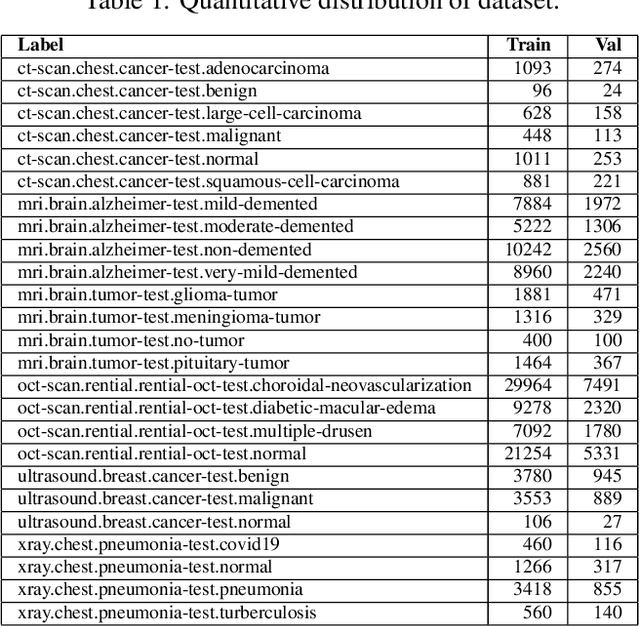
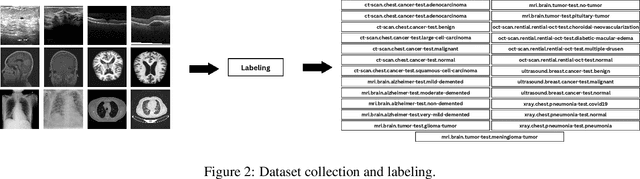
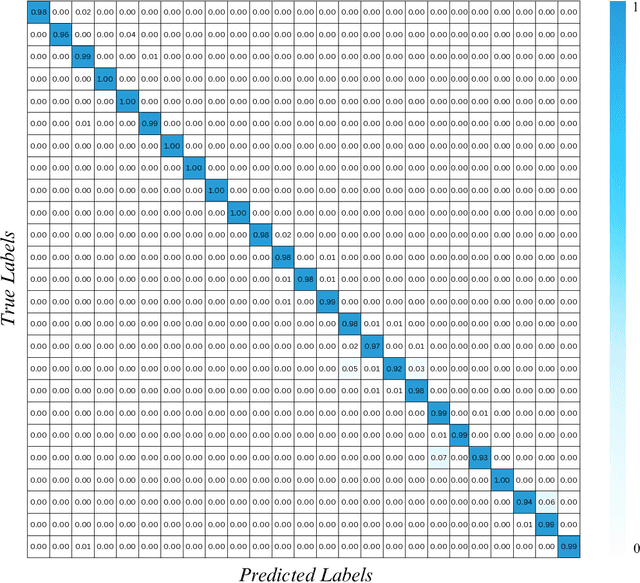
Medical imaging is an essential tool for diagnosing various healthcare diseases and conditions. However, analyzing medical images is a complex and time-consuming task that requires expertise and experience. This article aims to design a decision support system to assist healthcare providers and patients in making decisions about diagnosing, treating, and managing health conditions. The proposed architecture contains three stages: 1) data collection and labeling, 2) model training, and 3) diagnosis report generation. The key idea is to train a deep learning model on a medical image dataset to extract four types of information: the type of image scan, the body part, the test image, and the results. This information is then fed into ChatGPT to generate automatic diagnostics. The proposed system has the potential to enhance decision-making, reduce costs, and improve the capabilities of healthcare providers. The efficacy of the proposed system is analyzed by conducting extensive experiments on a large medical image dataset. The experimental outcomes exhibited promising performance for automatic diagnosis through medical images.