 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Revisiting Token Pruning for Object Detection and Instance Segmentation
Jun 12, 2023
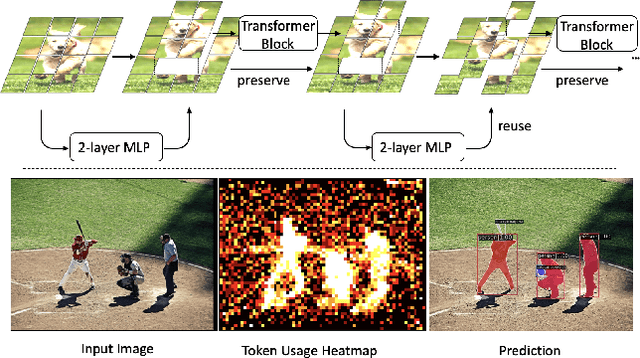
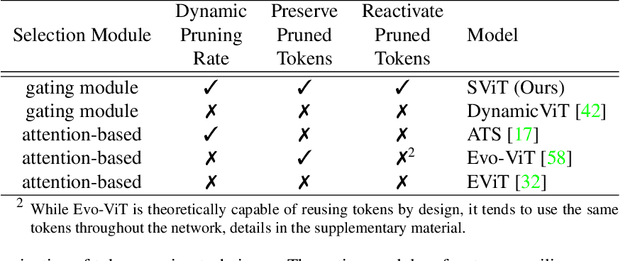
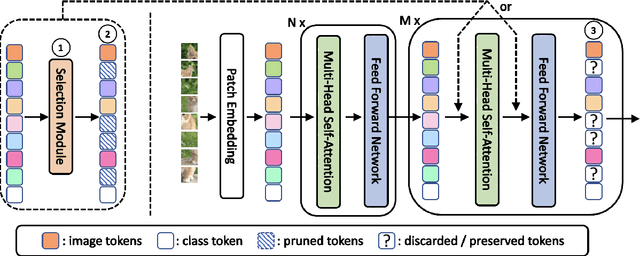
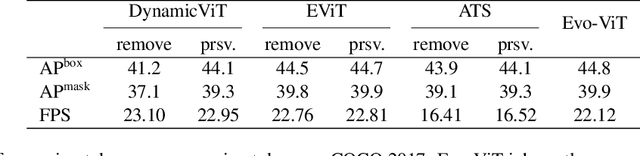
Vision Transformers (ViTs) have shown impressive performance in computer vision, but their high computational cost, quadratic in the number of tokens, limits their adoption in computation-constrained applications. However, this large number of tokens may not be necessary, as not all tokens are equally important. In this paper, we investigate token pruning to accelerate inference for object detection and instance segmentation, extending prior works from image classification. Through extensive experiments, we offer four insights for dense tasks: (i) tokens should not be completely pruned and discarded, but rather preserved in the feature maps for later use. (ii) reactivating previously pruned tokens can further enhance model performance. (iii) a dynamic pruning rate based on images is better than a fixed pruning rate. (iv) a lightweight, 2-layer MLP can effectively prune tokens, achieving accuracy comparable with complex gating networks with a simpler design. We evaluate the impact of these design choices on COCO dataset and present a method integrating these insights that outperforms prior art token pruning models, significantly reducing performance drop from ~1.5 mAP to ~0.3 mAP for both boxes and masks. Compared to the dense counterpart that uses all tokens, our method achieves up to 34% faster inference speed for the whole network and 46% for the backbone.
Temporal-controlled Frame Swap for Generating High-Fidelity Stereo Driving Data for Autonomy Analysis
Jun 12, 2023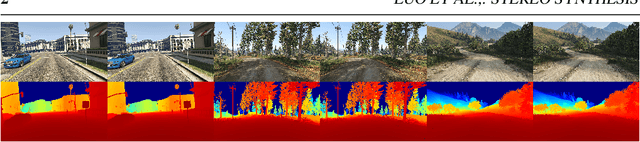

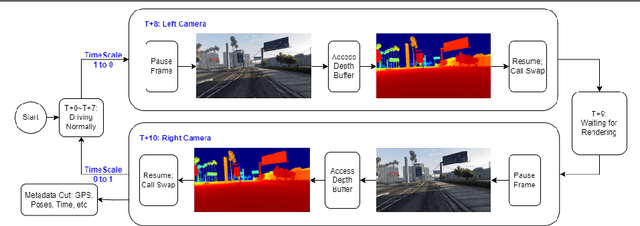
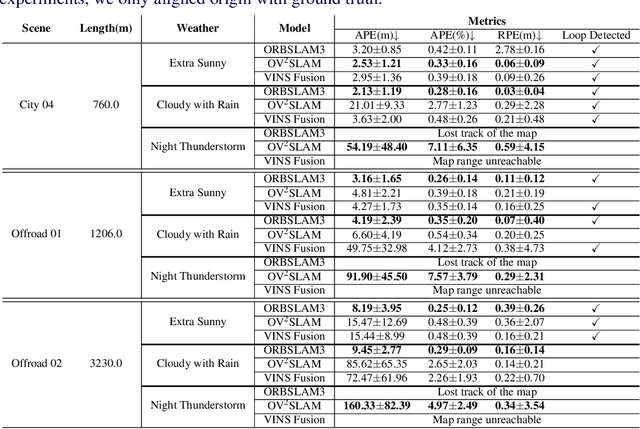
This paper presents a novel approach, TeFS (Temporal-controlled Frame Swap), to generate synthetic stereo driving data for visual simultaneous localization and mapping (vSLAM) tasks. TeFS is designed to overcome the lack of native stereo vision support in commercial driving simulators, and we demonstrate its effectiveness using Grand Theft Auto V (GTA V), a high-budget open-world video game engine. We introduce GTAV-TeFS, the first large-scale GTA V stereo-driving dataset, containing over 88,000 high-resolution stereo RGB image pairs, along with temporal information, GPS coordinates, camera poses, and full-resolution dense depth maps. GTAV-TeFS offers several advantages over other synthetic stereo datasets and enables the evaluation and enhancement of state-of-the-art stereo vSLAM models under GTA V's environment. We validate the quality of the stereo data collected using TeFS by conducting a comparative analysis with the conventional dual-viewport data using an open-source simulator. We also benchmark various vSLAM models using the challenging-case comparison groups included in GTAV-TeFS, revealing the distinct advantages and limitations inherent to each model. The goal of our work is to bring more high-fidelity stereo data from commercial-grade game simulators into the research domain and push the boundary of vSLAM models.
BayeSeg: Bayesian Modeling for Medical Image Segmentation with Interpretable Generalizability
Mar 03, 2023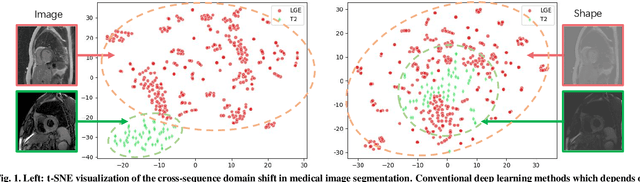
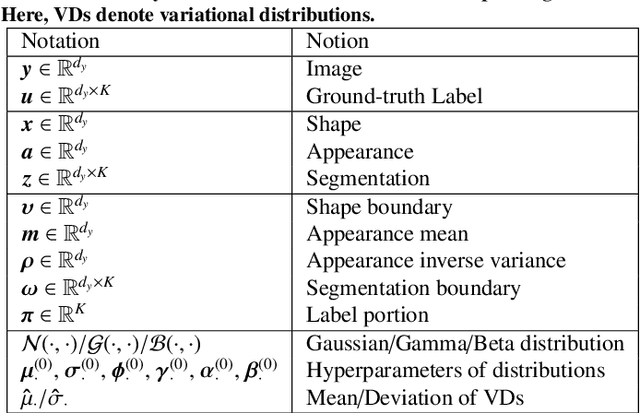
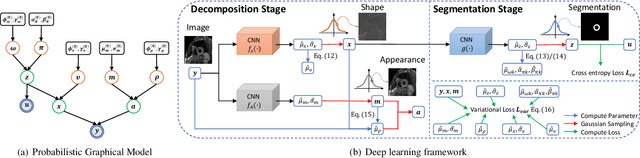

Due to the cross-domain distribution shift aroused from diverse medical imaging systems, many deep learning segmentation methods fail to perform well on unseen data, which limits their real-world applicability. Recent works have shown the benefits of extracting domain-invariant representations on domain generalization. However, the interpretability of domain-invariant features remains a great challenge. To address this problem, we propose an interpretable Bayesian framework (BayeSeg) through Bayesian modeling of image and label statistics to enhance model generalizability for medical image segmentation. Specifically, we first decompose an image into a spatial-correlated variable and a spatial-variant variable, assigning hierarchical Bayesian priors to explicitly force them to model the domain-stable shape and domain-specific appearance information respectively. Then, we model the segmentation as a locally smooth variable only related to the shape. Finally, we develop a variational Bayesian framework to infer the posterior distributions of these explainable variables. The framework is implemented with neural networks, and thus is referred to as deep Bayesian segmentation. Quantitative and qualitative experimental results on prostate segmentation and cardiac segmentation tasks have shown the effectiveness of our proposed method. Moreover, we investigated the interpretability of BayeSeg by explaining the posteriors and analyzed certain factors that affect the generalization ability through further ablation studies. Our code will be released via https://zmiclab.github.io/projects.html, once the manuscript is accepted for publication.
Image Classification of Stroke Blood Clot Origin using Deep Convolutional Neural Networks and Visual Transformers
May 25, 2023Stroke is one of two main causes of death worldwide. Many individuals suffer from ischemic stroke every year. Only in US more over 700,000 individuals meet ischemic stroke due to blood clot blocking an artery to the brain every year. The paper describes particular approach how to apply Artificial Intelligence for purposes of separating two major acute ischemic stroke (AIS) etiology subtypes: cardiac and large artery atherosclerosis. Four deep neural network architectures and simple ensemble method are used in the approach.
STPDnet: Spatial-temporal convolutional primal dual network for dynamic PET image reconstruction
Mar 08, 2023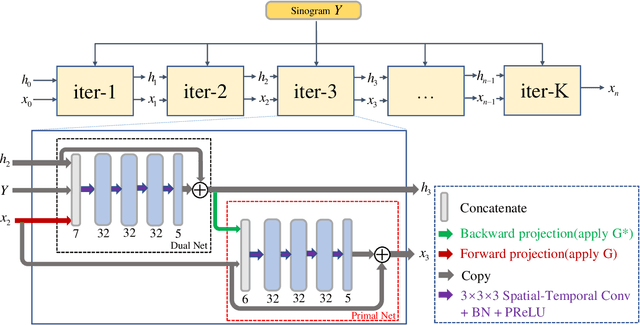
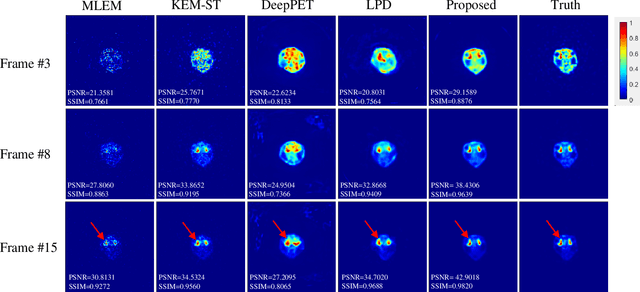
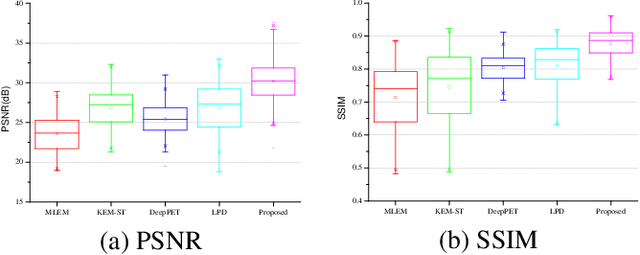
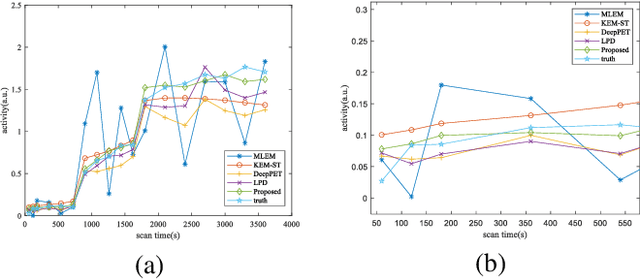
Dynamic positron emission tomography (dPET) image reconstruction is extremely challenging due to the limited counts received in individual frame. In this paper, we propose a spatial-temporal convolutional primal dual network (STPDnet) for dynamic PET image reconstruction. Both spatial and temporal correlations are encoded by 3D convolution operators. The physical projection of PET is embedded in the iterative learning process of the network, which provides the physical constraints and enhances interpretability. The experiments of real rat scan data have shown that the proposed method can achieve substantial noise reduction in both temporal and spatial domains and outperform the maximum likelihood expectation maximization (MLEM), spatial-temporal kernel method (KEM-ST), DeepPET and Learned Primal Dual (LPD).
Language Quantized AutoEncoders: Towards Unsupervised Text-Image Alignment
Feb 03, 2023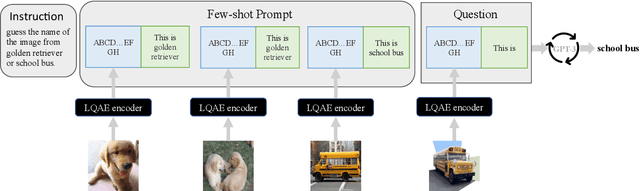
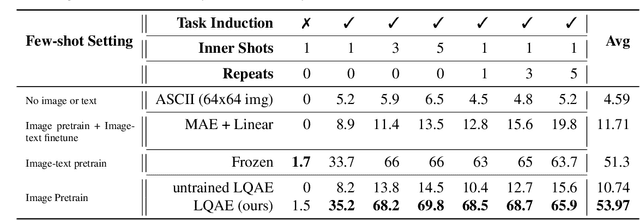
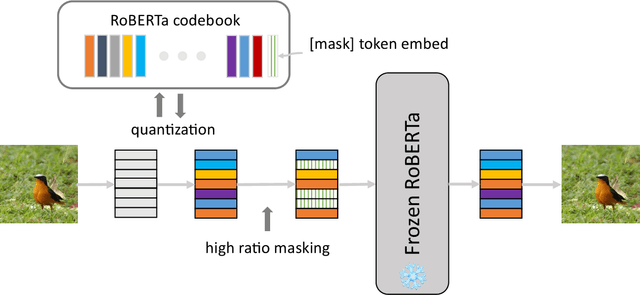
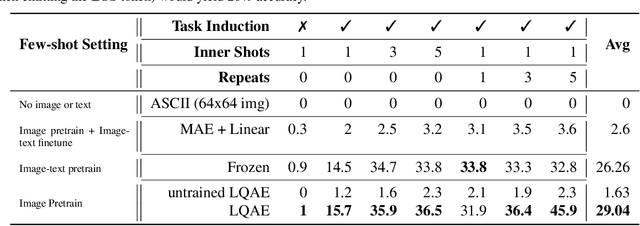
Recent progress in scaling up large language models has shown impressive capabilities in performing few-shot learning across a wide range of text-based tasks. However, a key limitation is that these language models fundamentally lack visual perception - a crucial attribute needed to extend these models to be able to interact with the real world and solve vision tasks, such as in visual-question answering and robotics. Prior works have largely connected image to text through pretraining and/or fine-tuning on curated image-text datasets, which can be a costly and expensive process. In order to resolve this limitation, we propose a simple yet effective approach called Language-Quantized AutoEncoder (LQAE), a modification of VQ-VAE that learns to align text-image data in an unsupervised manner by leveraging pretrained language models (e.g., BERT, RoBERTa). Our main idea is to encode image as sequences of text tokens by directly quantizing image embeddings using a pretrained language codebook. We then apply random masking followed by a BERT model, and have the decoder reconstruct the original image from BERT predicted text token embeddings. By doing so, LQAE learns to represent similar images with similar clusters of text tokens, thereby aligning these two modalities without the use of aligned text-image pairs. This enables few-shot image classification with large language models (e.g., GPT-3) as well as linear classification of images based on BERT text features. To the best of our knowledge, our work is the first work that uses unaligned images for multimodal tasks by leveraging the power of pretrained language models.
LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
Jun 01, 2023
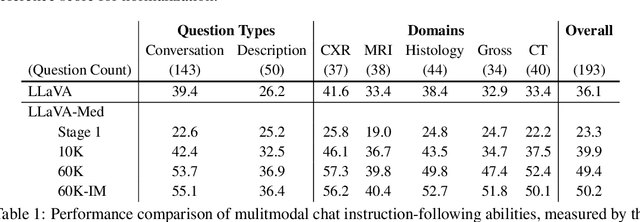
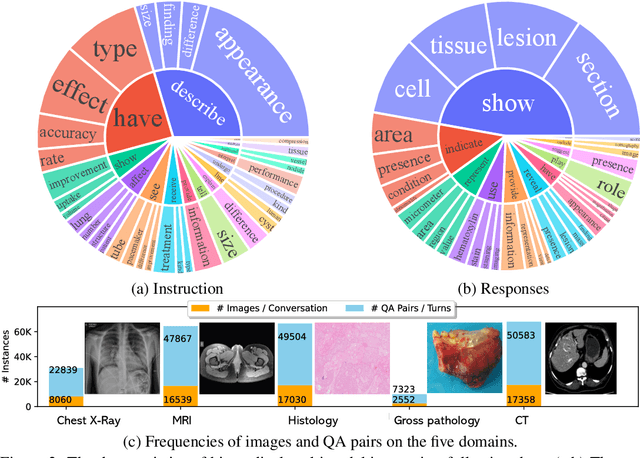

Conversational generative AI has demonstrated remarkable promise for empowering biomedical practitioners, but current investigations focus on unimodal text. Multimodal conversational AI has seen rapid progress by leveraging billions of image-text pairs from the public web, but such general-domain vision-language models still lack sophistication in understanding and conversing about biomedical images. In this paper, we propose a cost-efficient approach for training a vision-language conversational assistant that can answer open-ended research questions of biomedical images. The key idea is to leverage a large-scale, broad-coverage biomedical figure-caption dataset extracted from PubMed Central, use GPT-4 to self-instruct open-ended instruction-following data from the captions, and then fine-tune a large general-domain vision-language model using a novel curriculum learning method. Specifically, the model first learns to align biomedical vocabulary using the figure-caption pairs as is, then learns to master open-ended conversational semantics using GPT-4 generated instruction-following data, broadly mimicking how a layperson gradually acquires biomedical knowledge. This enables us to train a Large Language and Vision Assistant for BioMedicine (LLaVA-Med) in less than 15 hours (with eight A100s). LLaVA-Med exhibits excellent multimodal conversational capability and can follow open-ended instruction to assist with inquiries about a biomedical image. On three standard biomedical visual question answering datasets, LLaVA-Med outperforms previous supervised state-of-the-art on certain metrics. To facilitate biomedical multimodal research, we will release our instruction-following data and the LLaVA-Med model.
Bias mitigation techniques in image classification: fair machine learning in human heritage collections
Mar 20, 2023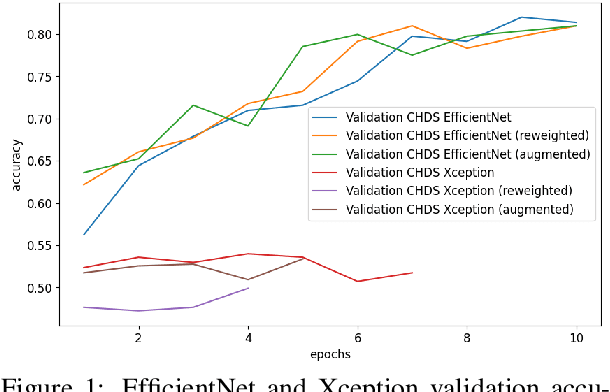
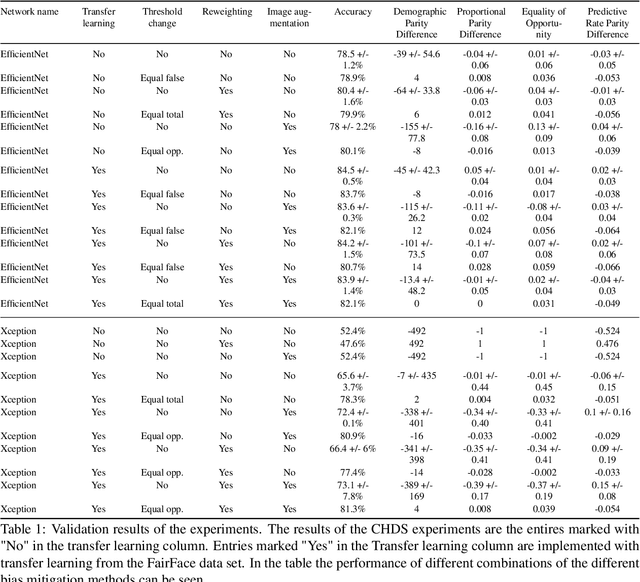
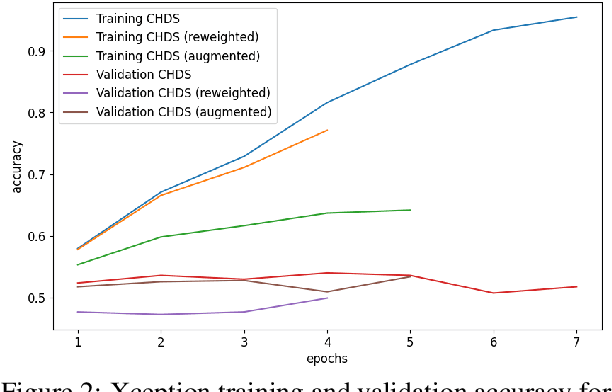
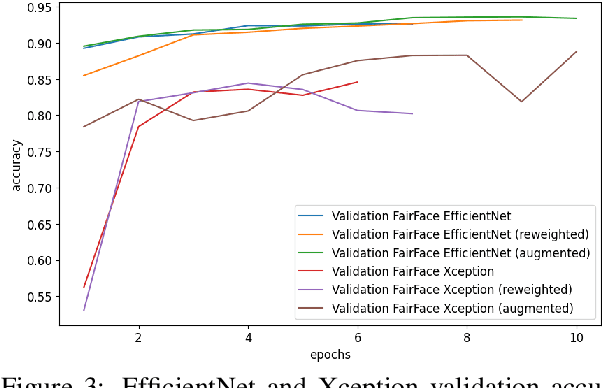
A major problem with using automated classification systems is that if they are not engineered correctly and with fairness considerations, they could be detrimental to certain populations. Furthermore, while engineers have developed cutting-edge technologies for image classification, there is still a gap in the application of these models in human heritage collections, where data sets usually consist of low-quality pictures of people with diverse ethnicity, gender, and age. In this work, we evaluate three bias mitigation techniques using two state-of-the-art neural networks, Xception and EfficientNet, for gender classification. Moreover, we explore the use of transfer learning using a fair data set to overcome the training data scarcity. We evaluated the effectiveness of the bias mitigation pipeline on a cultural heritage collection of photographs from the 19th and 20th centuries, and we used the FairFace data set for the transfer learning experiments. After the evaluation, we found that transfer learning is a good technique that allows better performance when working with a small data set. Moreover, the fairest classifier was found to be accomplished using transfer learning, threshold change, re-weighting and image augmentation as bias mitigation methods.
G-CAME: Gaussian-Class Activation Mapping Explainer for Object Detectors
Jun 06, 2023
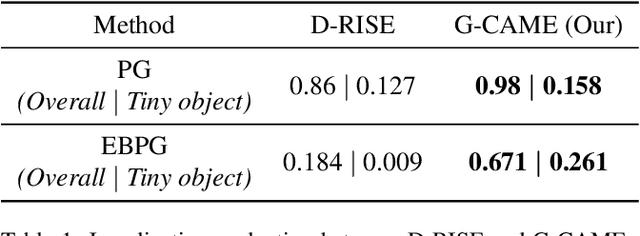
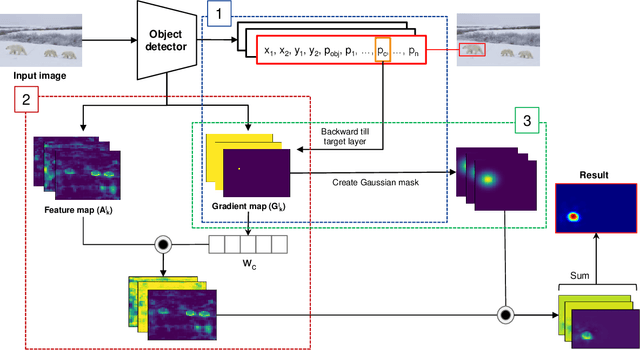
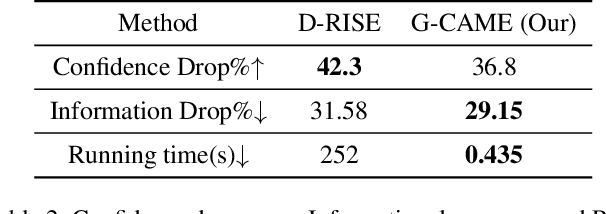
Nowadays, deep neural networks for object detection in images are very prevalent. However, due to the complexity of these networks, users find it hard to understand why these objects are detected by models. We proposed Gaussian Class Activation Mapping Explainer (G-CAME), which generates a saliency map as the explanation for object detection models. G-CAME can be considered a CAM-based method that uses the activation maps of selected layers combined with the Gaussian kernel to highlight the important regions in the image for the predicted box. Compared with other Region-based methods, G-CAME can transcend time constraints as it takes a very short time to explain an object. We also evaluated our method qualitatively and quantitatively with YOLOX on the MS-COCO 2017 dataset and guided to apply G-CAME into the two-stage Faster-RCNN model.
Real-Time Onboard Object Detection for Augmented Reality: Enhancing Head-Mounted Display with YOLOv8
Jun 06, 2023
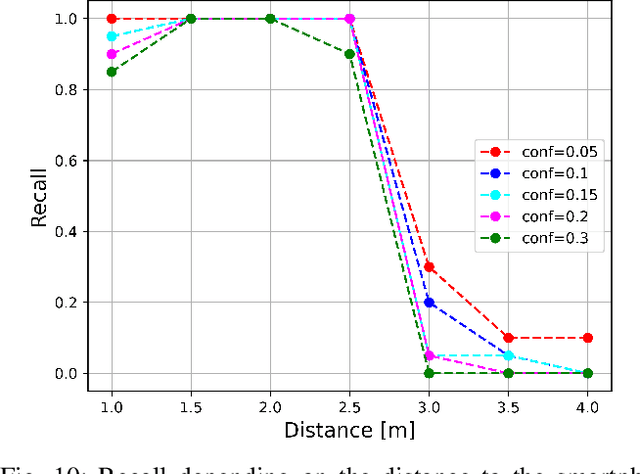
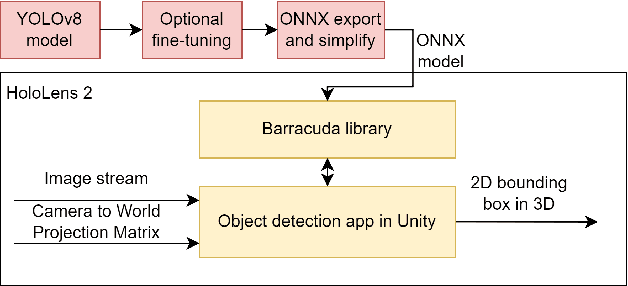
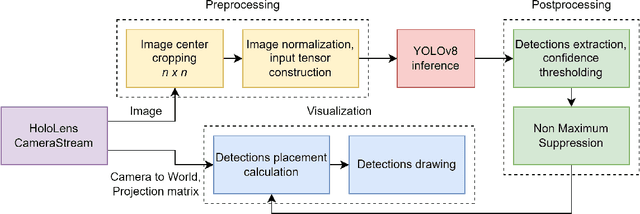
This paper introduces a software architecture for real-time object detection using machine learning (ML) in an augmented reality (AR) environment. Our approach uses the recent state-of-the-art YOLOv8 network that runs onboard on the Microsoft HoloLens 2 head-mounted display (HMD). The primary motivation behind this research is to enable the application of advanced ML models for enhanced perception and situational awareness with a wearable, hands-free AR platform. We show the image processing pipeline for the YOLOv8 model and the techniques used to make it real-time on the resource-limited edge computing platform of the headset. The experimental results demonstrate that our solution achieves real-time processing without needing offloading tasks to the cloud or any other external servers while retaining satisfactory accuracy regarding the usual mAP metric and measured qualitative performance