 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Flare7K++: Mixing Synthetic and Real Datasets for Nighttime Flare Removal and Beyond
Jun 08, 2023




Artificial lights commonly leave strong lens flare artifacts on the images captured at night, degrading both the visual quality and performance of vision algorithms. Existing flare removal approaches mainly focus on removing daytime flares and fail in nighttime cases. Nighttime flare removal is challenging due to the unique luminance and spectrum of artificial lights, as well as the diverse patterns and image degradation of the flares. The scarcity of the nighttime flare removal dataset constraints the research on this crucial task. In this paper, we introduce Flare7K++, the first comprehensive nighttime flare removal dataset, consisting of 962 real-captured flare images (Flare-R) and 7,000 synthetic flares (Flare7K). Compared to Flare7K, Flare7K++ is particularly effective in eliminating complicated degradation around the light source, which is intractable by using synthetic flares alone. Besides, the previous flare removal pipeline relies on the manual threshold and blur kernel settings to extract light sources, which may fail when the light sources are tiny or not overexposed. To address this issue, we additionally provide the annotations of light sources in Flare7K++ and propose a new end-to-end pipeline to preserve the light source while removing lens flares. Our dataset and pipeline offer a valuable foundation and benchmark for future investigations into nighttime flare removal studies. Extensive experiments demonstrate that Flare7K++ supplements the diversity of existing flare datasets and pushes the frontier of nighttime flare removal towards real-world scenarios.
Emotion Detection from EEG using Transfer Learning
Jun 09, 2023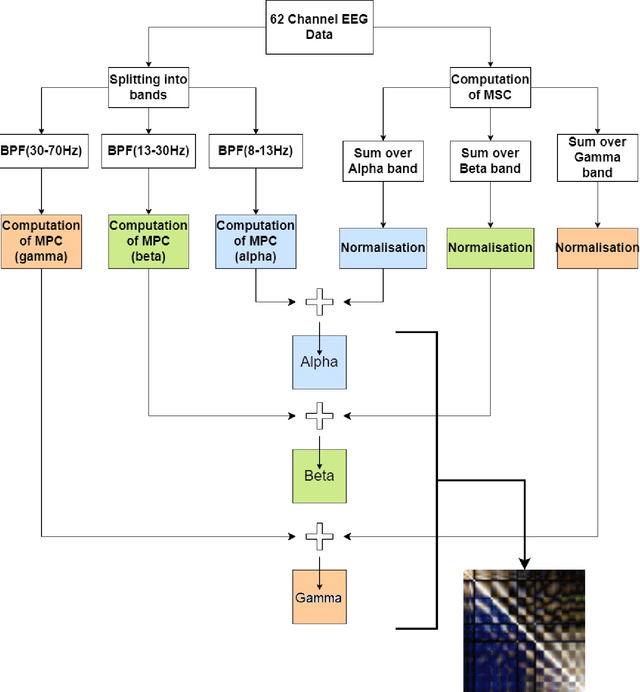
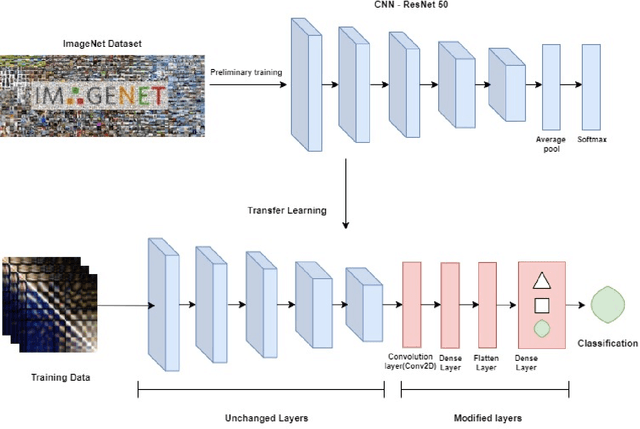
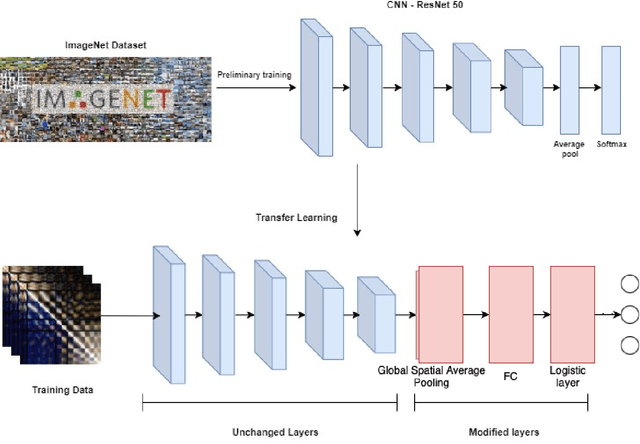
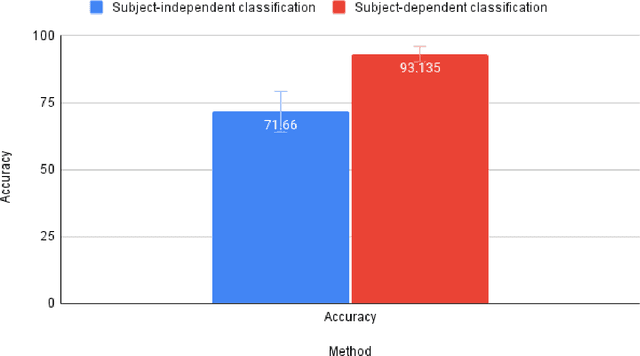
The detection of emotions using an Electroencephalogram (EEG) is a crucial area in brain-computer interfaces and has valuable applications in fields such as rehabilitation and medicine. In this study, we employed transfer learning to overcome the challenge of limited data availability in EEG-based emotion detection. The base model used in this study was Resnet50. Additionally, we employed a novel feature combination in EEG-based emotion detection. The input to the model was in the form of an image matrix, which comprised Mean Phase Coherence (MPC) and Magnitude Squared Coherence (MSC) in the upper-triangular and lower-triangular matrices, respectively. We further improved the technique by incorporating features obtained from the Differential Entropy (DE) into the diagonal, which previously held little to no useful information for classifying emotions. The dataset used in this study, SEED EEG (62 channel EEG), comprises three classes (Positive, Neutral, and Negative). We calculated both subject-independent and subject-dependent accuracy. The subject-dependent accuracy was obtained using a 10-fold cross-validation method and was 93.1%, while the subject-independent classification was performed by employing the leave-one-subject-out (LOSO) strategy. The accuracy obtained in subject-independent classification was 71.6%. Both of these accuracies are at least twice better than the chance accuracy of classifying 3 classes. The study found the use of MSC and MPC in EEG-based emotion detection promising for emotion classification. The future scope of this work includes the use of data augmentation techniques, enhanced classifiers, and better features for emotion classification.
Deep Industrial Image Anomaly Detection: A Survey
Jan 30, 2023

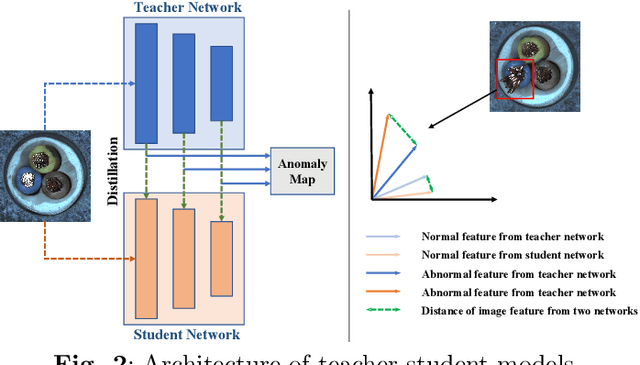
The recent rapid development of deep learning has laid a milestone in industrial Image Anomaly Detection (IAD). In this paper, we provide a comprehensive review of deep learning-based image anomaly detection techniques, from the perspectives of neural network architectures, levels of supervision, loss functions, metrics and datasets. In addition, we extract the new setting from industrial manufacturing and review the current IAD approaches under our proposed our new setting. Moreover, we highlight several opening challenges for image anomaly detection. The merits and downsides of representative network architectures under varying supervision are discussed. Finally, we summarize the research findings and point out future research directions. More resources are available at https://github.com/M-3LAB/awesome-industrial-anomaly-detection.
U-TILISE: A Sequence-to-sequence Model for Cloud Removal in Optical Satellite Time Series
May 22, 2023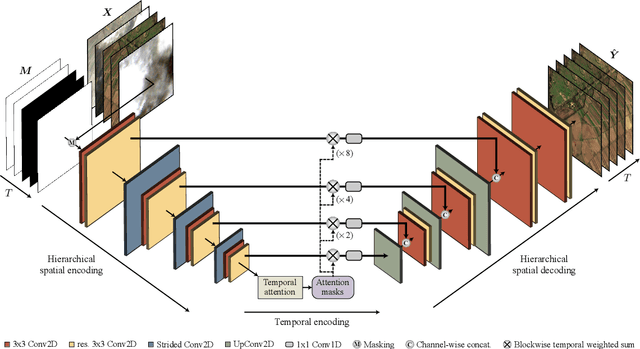
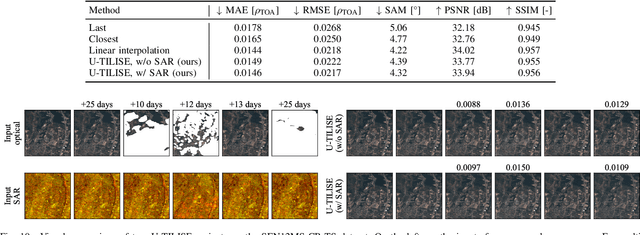
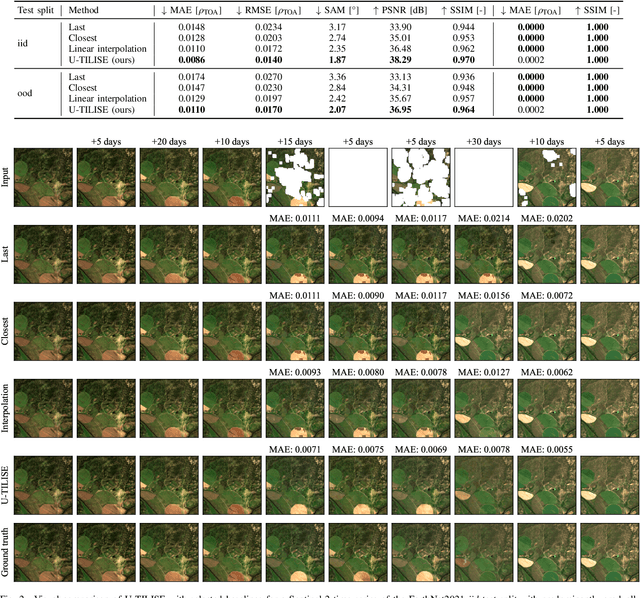

Satellite image time series in the optical and infrared spectrum suffer from frequent data gaps due to cloud cover, cloud shadows, and temporary sensor outages. It has been a long-standing problem of remote sensing research how to best reconstruct the missing pixel values and obtain complete, cloud-free image sequences. We approach that problem from the perspective of representation learning and develop U-TILISE, an efficient neural model that is able to implicitly capture spatio-temporal patterns of the spectral intensities, and that can therefore be trained to map a cloud-masked input sequence to a cloud-free output sequence. The model consists of a convolutional spatial encoder that maps each individual frame of the input sequence to a latent encoding; an attention-based temporal encoder that captures dependencies between those per-frame encodings and lets them exchange information along the time dimension; and a convolutional spatial decoder that decodes the latent embeddings back into multi-spectral images. We experimentally evaluate the proposed model on EarthNet2021, a dataset of Sentinel-2 time series acquired all over Europe, and demonstrate its superior ability to reconstruct the missing pixels. Compared to a standard interpolation baseline, it increases the PSNR by 1.8 dB at previously seen locations and by 1.3 dB at unseen locations.
Revisiting pre-trained remote sensing model benchmarks: resizing and normalization matters
May 22, 2023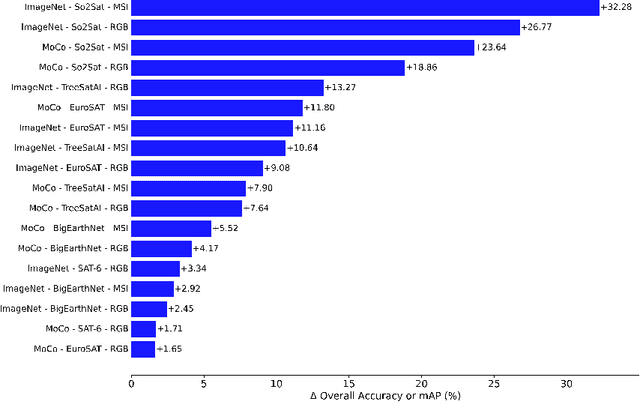
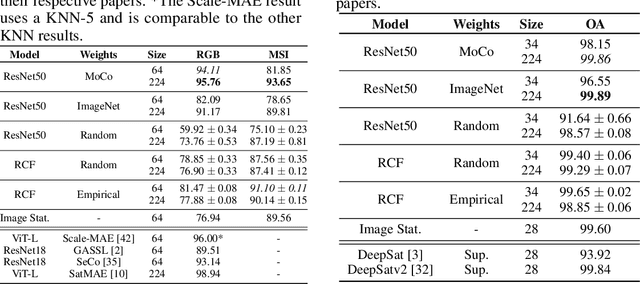
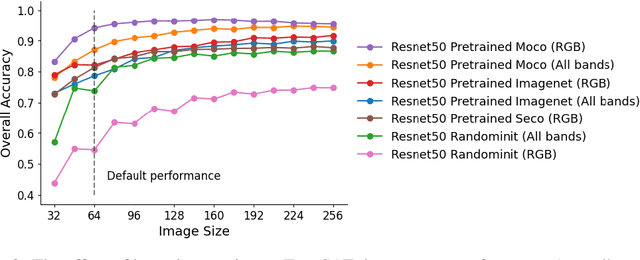
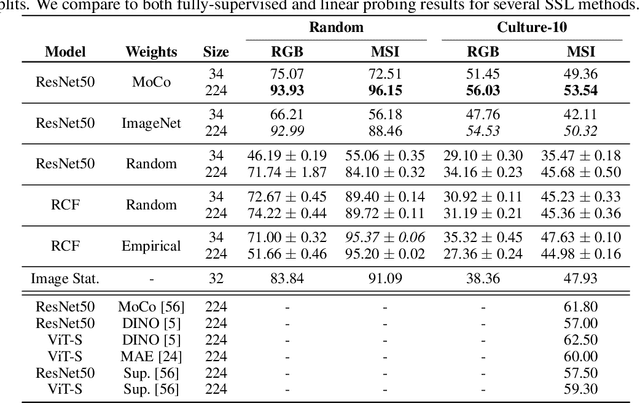
Research in self-supervised learning (SSL) with natural images has progressed rapidly in recent years and is now increasingly being applied to and benchmarked with datasets containing remotely sensed imagery. A common benchmark case is to evaluate SSL pre-trained model embeddings on datasets of remotely sensed imagery with small patch sizes, e.g., 32x32 pixels, whereas standard SSL pre-training takes place with larger patch sizes, e.g., 224x224. Furthermore, pre-training methods tend to use different image normalization preprocessing steps depending on the dataset. In this paper, we show, across seven satellite and aerial imagery datasets of varying resolution, that by simply following the preprocessing steps used in pre-training (precisely, image sizing and normalization methods), one can achieve significant performance improvements when evaluating the extracted features on downstream tasks -- an important detail overlooked in previous work in this space. We show that by following these steps, ImageNet pre-training remains a competitive baseline for satellite imagery based transfer learning tasks -- for example we find that these steps give +32.28 to overall accuracy on the So2Sat random split dataset and +11.16 on the EuroSAT dataset. Finally, we report comprehensive benchmark results with a variety of simple baseline methods for each of the seven datasets, forming an initial benchmark suite for remote sensing imagery.
When SAM Meets Medical Images: An Investigation of Segment Anything Model (SAM) on Multi-phase Liver Tumor Segmentation
May 04, 2023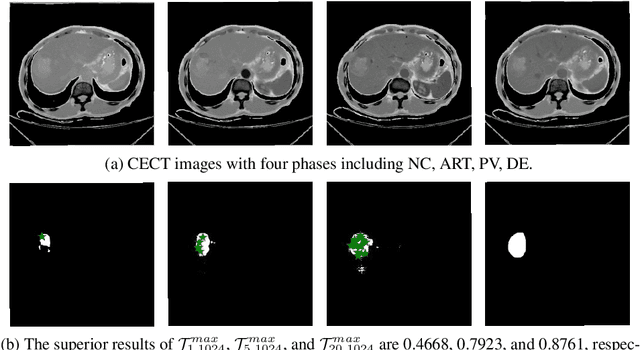
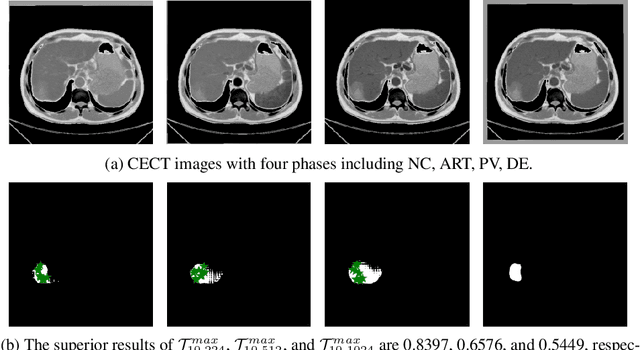
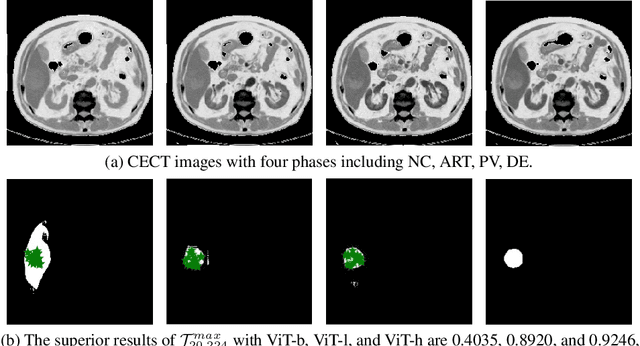
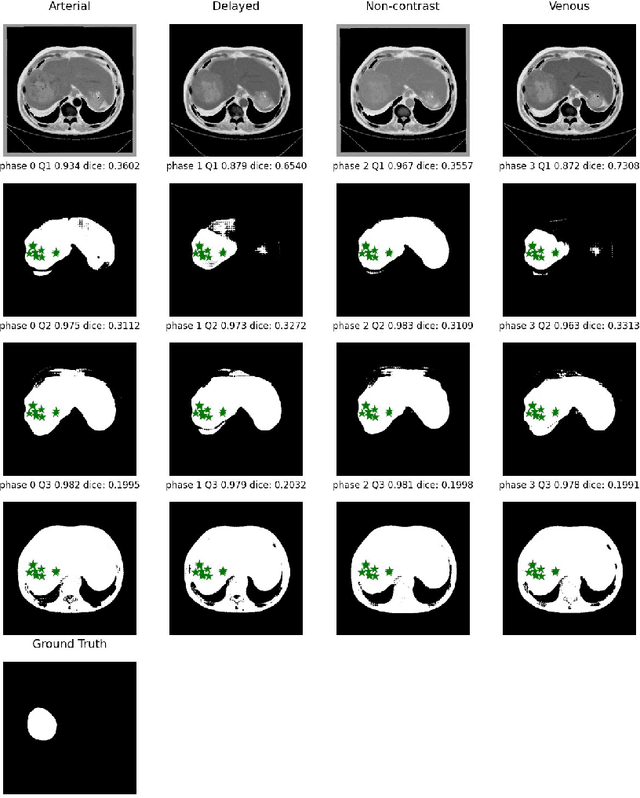
Learning to segmentation without large-scale samples is an inherent capability of human. Recently, Segment Anything Model (SAM) performs the significant zero-shot image segmentation, attracting considerable attention from the computer vision community. Here, we investigate the capability of SAM for medical image analysis, especially for multi-phase liver tumor segmentation (MPLiTS), in terms of prompts, data resolution, phases. Experimental results demonstrate that there might be a large gap between SAM and expected performance. Fortunately, the qualitative results show that SAM is a powerful annotation tool for the community of interactive medical image segmentation.
Prompt Stealing Attacks Against Text-to-Image Generation Models
Feb 20, 2023
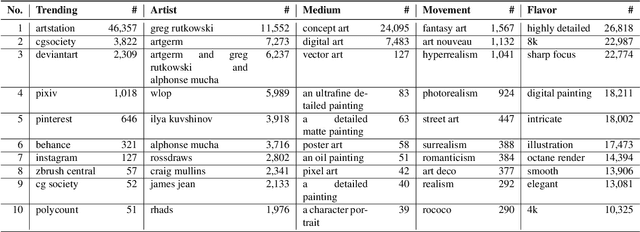


Text-to-Image generation models have revolutionized the artwork design process and enabled anyone to create high-quality images by entering text descriptions called prompts. Creating a high-quality prompt that consists of a subject and several modifiers can be time-consuming and costly. In consequence, a trend of trading high-quality prompts on specialized marketplaces has emerged. In this paper, we propose a novel attack, namely prompt stealing attack, which aims to steal prompts from generated images by text-to-image generation models. Successful prompt stealing attacks direct violate the intellectual property and privacy of prompt engineers and also jeopardize the business model of prompt trading marketplaces. We first perform a large-scale analysis on a dataset collected by ourselves and show that a successful prompt stealing attack should consider a prompt's subject as well as its modifiers. We then propose the first learning-based prompt stealing attack, PromptStealer, and demonstrate its superiority over two baseline methods quantitatively and qualitatively. We also make some initial attempts to defend PromptStealer. In general, our study uncovers a new attack surface in the ecosystem created by the popular text-to-image generation models. We hope our results can help to mitigate the threat. To facilitate research in this field, we will share our dataset and code with the community.
3D Colored Shape Reconstruction from a Single RGB Image through Diffusion
Feb 11, 2023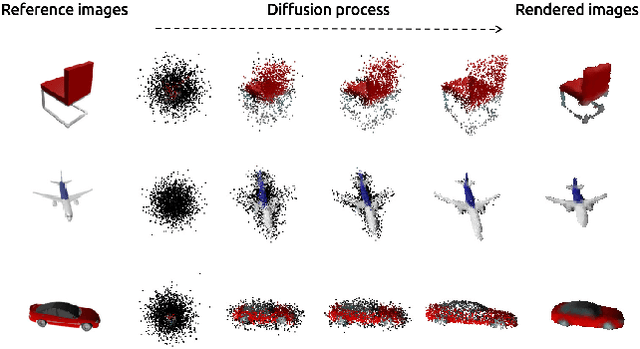
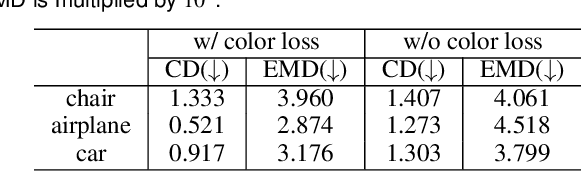
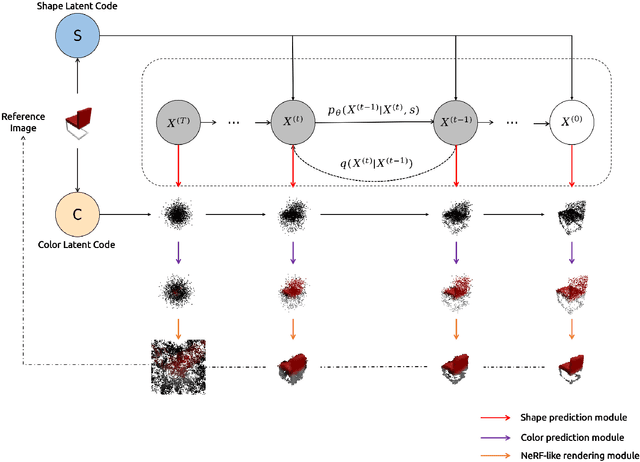
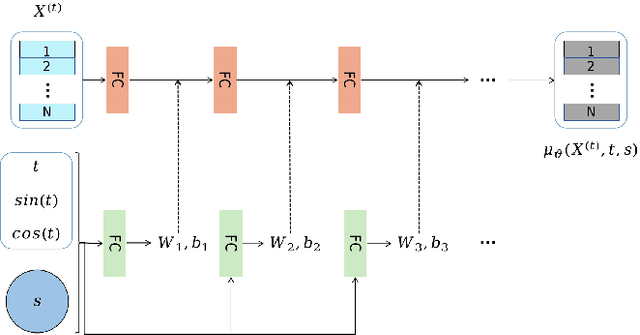
We propose a novel 3d colored shape reconstruction method from a single RGB image through diffusion model. Diffusion models have shown great development potentials for high-quality 3D shape generation. However, most existing work based on diffusion models only focus on geometric shape generation, they cannot either accomplish 3D reconstruction from a single image, or produce 3D geometric shape with color information. In this work, we propose to reconstruct a 3D colored shape from a single RGB image through a novel conditional diffusion model. The reverse process of the proposed diffusion model is consisted of three modules, shape prediction module, color prediction module and NeRF-like rendering module. In shape prediction module, the reference RGB image is first encoded into a high-level shape feature and then the shape feature is utilized as a condition to predict the reverse geometric noise in diffusion model. Then the color of each 3D point updated in shape prediction module is predicted by color prediction module. Finally, a NeRF-like rendering module is designed to render the colored point cloud predicted by the former two modules to 2D image space to guide the training conditioned only on a reference image. As far as the authors know, the proposed method is the first diffusion model for 3D colored shape reconstruction from a single RGB image. Experimental results demonstrate that the proposed method achieves competitive performance on colored 3D shape reconstruction, and the ablation study validates the positive role of the color prediction module in improving the reconstruction quality of 3D geometric point cloud.
Variation-Aware Semantic Image Synthesis
Jan 25, 2023
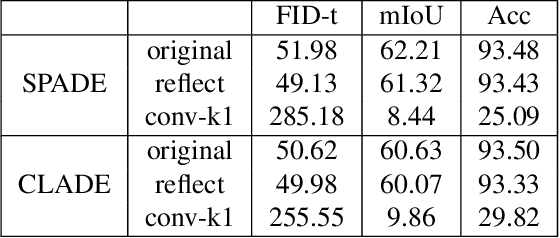
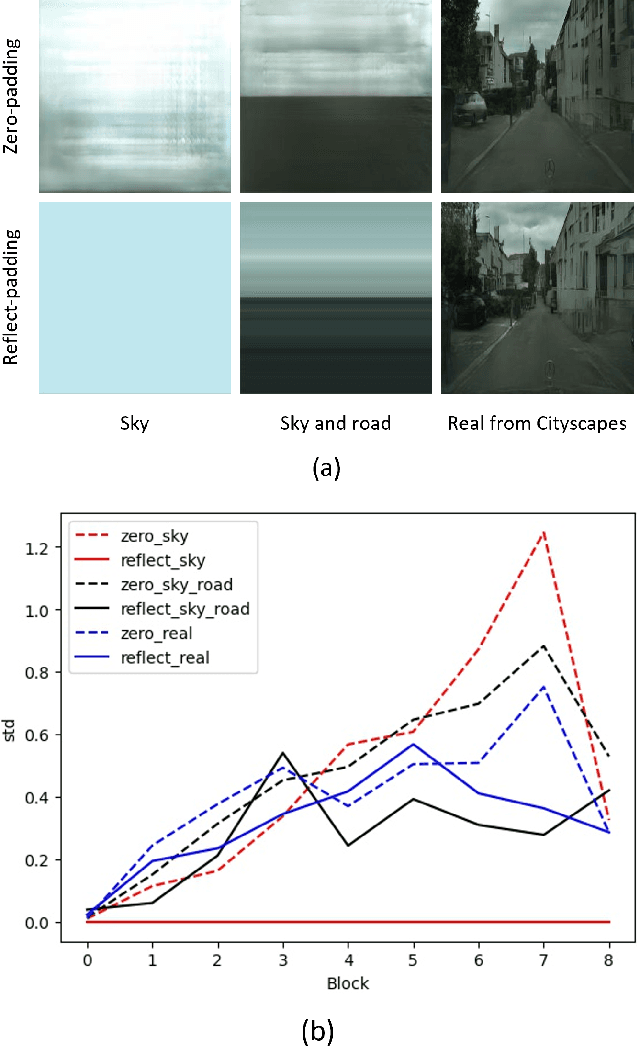
Semantic image synthesis (SIS) aims to produce photorealistic images aligning to given conditional semantic layout and has witnessed a significant improvement in recent years. Although the diversity in image-level has been discussed heavily, class-level mode collapse widely exists in current algorithms. Therefore, we declare a new requirement for SIS to achieve more photorealistic images, variation-aware, which consists of inter- and intra-class variation. The inter-class variation is the diversity between different semantic classes while the intra-class variation stresses the diversity inside one class. Through analysis, we find that current algorithms elusively embrace the inter-class variation but the intra-class variation is still not enough. Further, we introduce two simple methods to achieve variation-aware semantic image synthesis (VASIS) with a higher intra-class variation, semantic noise and position code. We combine our method with several state-of-the-art algorithms and the experimental result shows that our models generate more natural images and achieves slightly better FIDs and/or mIoUs than the counterparts. Our codes and models will be publicly available.
HSCNet++: Hierarchical Scene Coordinate Classification and Regression for Visual Localization with Transformer
May 05, 2023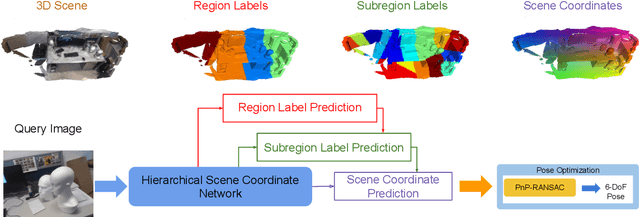
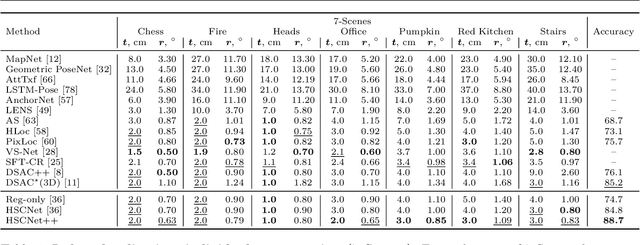
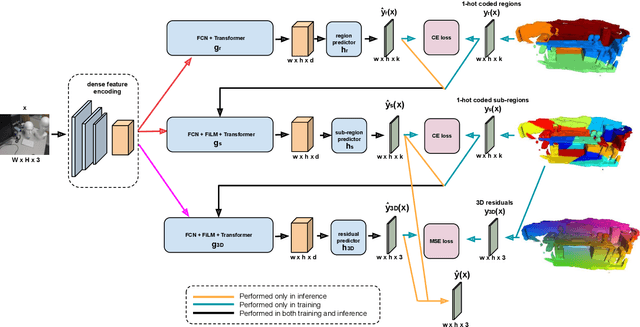
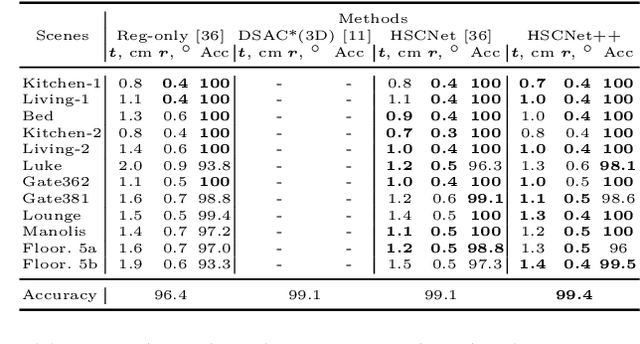
Visual localization is critical to many applications in computer vision and robotics. To address single-image RGB localization, state-of-the-art feature-based methods match local descriptors between a query image and a pre-built 3D model. Recently, deep neural networks have been exploited to regress the mapping between raw pixels and 3D coordinates in the scene, and thus the matching is implicitly performed by the forward pass through the network. However, in a large and ambiguous environment, learning such a regression task directly can be difficult for a single network. In this work, we present a new hierarchical scene coordinate network to predict pixel scene coordinates in a coarse-to-fine manner from a single RGB image. The proposed method, which is an extension of HSCNet, allows us to train compact models which scale robustly to large environments. It sets a new state-of-the-art for single-image localization on the 7-Scenes, 12 Scenes, Cambridge Landmarks datasets, and the combined indoor scenes.