 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Integrated Decision Gradients: Compute Your Attributions Where the Model Makes Its Decision
May 31, 2023
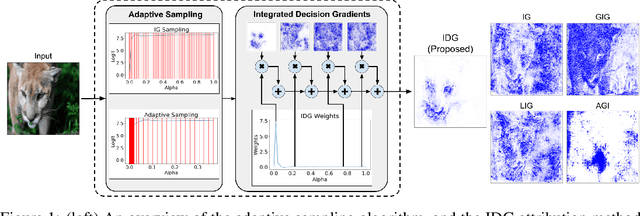
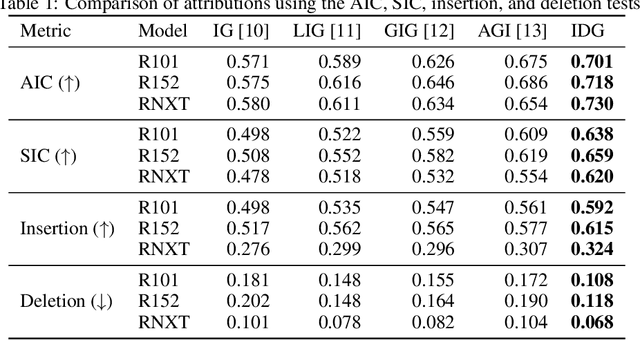
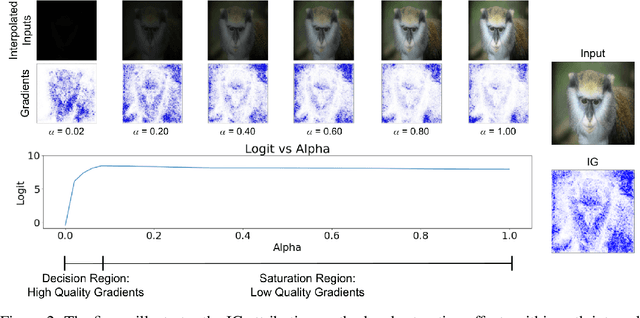

Attribution algorithms are frequently employed to explain the decisions of neural network models. Integrated Gradients (IG) is an influential attribution method due to its strong axiomatic foundation. The algorithm is based on integrating the gradients along a path from a reference image to the input image. Unfortunately, it can be observed that gradients computed from regions where the output logit changes minimally along the path provide poor explanations for the model decision, which is called the saturation effect problem. In this paper, we propose an attribution algorithm called integrated decision gradients (IDG). The algorithm focuses on integrating gradients from the region of the path where the model makes its decision, i.e., the portion of the path where the output logit rapidly transitions from zero to its final value. This is practically realized by scaling each gradient by the derivative of the output logit with respect to the path. The algorithm thereby provides a principled solution to the saturation problem. Additionally, we minimize the errors within the Riemann sum approximation of the path integral by utilizing non-uniform subdivisions determined by adaptive sampling. In the evaluation on ImageNet, it is demonstrated that IDG outperforms IG, left-IG, guided IG, and adversarial gradient integration both qualitatively and quantitatively using standard insertion and deletion metrics across three common models.
Annotation-free Audio-Visual Segmentation
May 19, 2023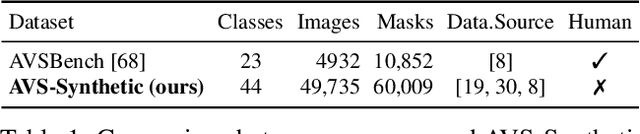
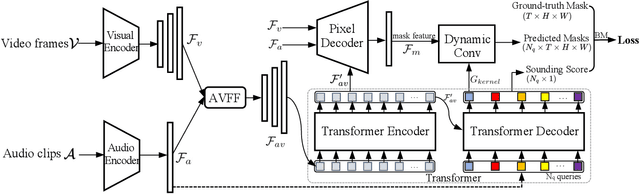


The objective of Audio-Visual Segmentation (AVS) is to locate sounding objects within visual scenes by accurately predicting pixelwise segmentation masks. In this paper, we present the following contributions: (i), we propose a scalable and annotation-free pipeline for generating artificial data for the AVS task. We leverage existing image segmentation and audio datasets to draw links between category labels, image-mask pairs, and audio samples, which allows us to easily compose (image, audio, mask) triplets for training AVS models; (ii), we introduce a novel Audio-Aware Transformer (AuTR) architecture that features an audio-aware query-based transformer decoder. This architecture enables the model to search for sounding objects with the guidance of audio signals, resulting in more accurate segmentation; (iii), we present extensive experiments conducted on both synthetic and real datasets, which demonstrate the effectiveness of training AVS models with synthetic data generated by our proposed pipeline. Additionally, our proposed AuTR architecture exhibits superior performance and strong generalization ability on public benchmarks. The project page is https://jinxiang-liu.github.io/anno-free-AVS/.
DSI2I: Dense Style for Unpaired Image-to-Image Translation
Dec 29, 2022

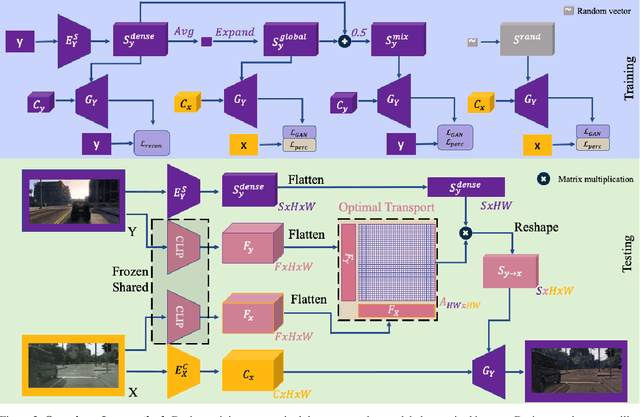

Unpaired exemplar-based image-to-image (UEI2I) translation aims to translate a source image to a target image domain with the style of a target image exemplar, without ground-truth input-translation pairs. Existing UEI2I methods represent style using either a global, image-level feature vector, or one vector per object instance/class but requiring knowledge of the scene semantics. Here, by contrast, we propose to represent style as a dense feature map, allowing for a finer-grained transfer to the source image without requiring any external semantic information. We then rely on perceptual and adversarial losses to disentangle our dense style and content representations, and exploit unsupervised cross-domain semantic correspondences to warp the exemplar style to the source content. We demonstrate the effectiveness of our method on two datasets using standard metrics together with a new localized style metric measuring style similarity in a class-wise manner. Our results evidence that the translations produced by our approach are more diverse and closer to the exemplars than those of the state-of-the-art methods while nonetheless preserving the source content.
SCRNet: a Retinex Structure-based Low-light Enhancement Model Guided by Spatial Consistency
May 14, 2023
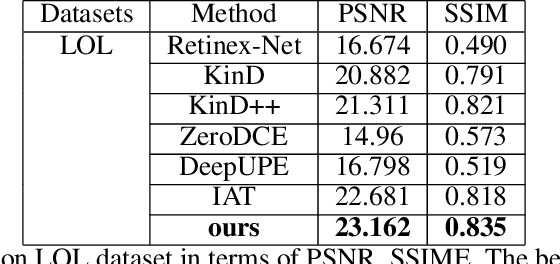
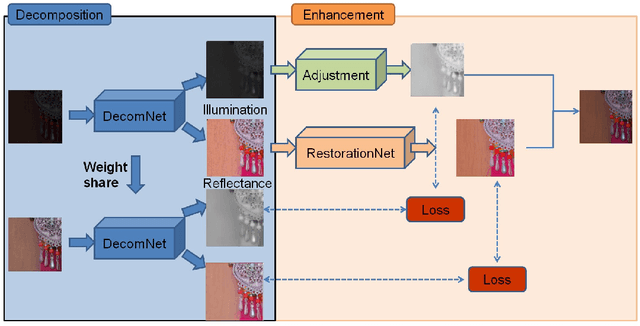
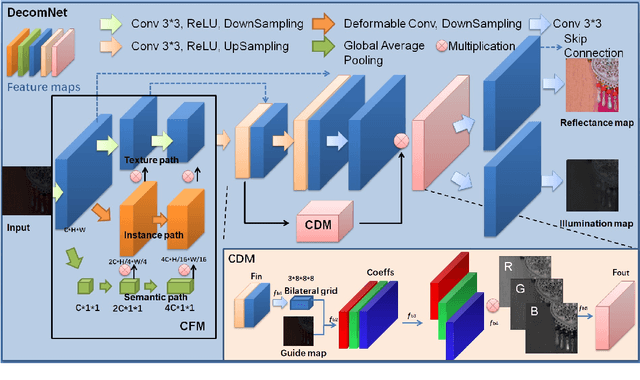
Images captured under low-light conditions are often plagued by several challenges, including diminished contrast, increased noise, loss of fine details, and unnatural color reproduction. These factors can significantly hinder the performance of computer vision tasks such as object detection and image segmentation. As a result, improving the quality of low-light images is of paramount importance for practical applications in the computer vision domain.To effectively address these challenges, we present a novel low-light image enhancement model, termed Spatial Consistency Retinex Network (SCRNet), which leverages the Retinex-based structure and is guided by the principle of spatial consistency.Specifically, our proposed model incorporates three levels of consistency: channel level, semantic level, and texture level, inspired by the principle of spatial consistency.These levels of consistency enable our model to adaptively enhance image features, ensuring more accurate and visually pleasing results.Extensive experimental evaluations on various low-light image datasets demonstrate that our proposed SCRNet outshines existing state-of-the-art methods, highlighting the potential of SCRNet as an effective solution for enhancing low-light images.
Designing an Encoder for Fast Personalization of Text-to-Image Models
Feb 26, 2023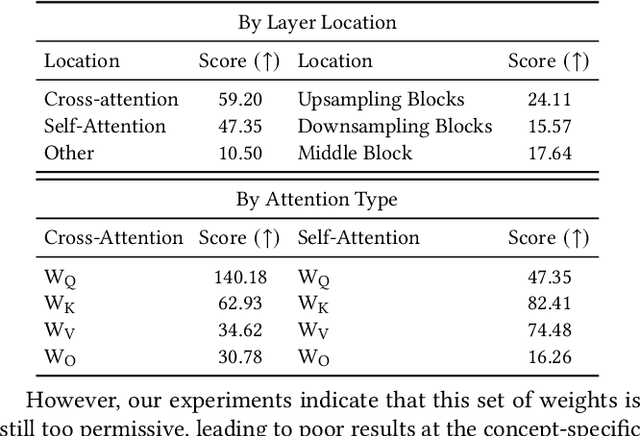
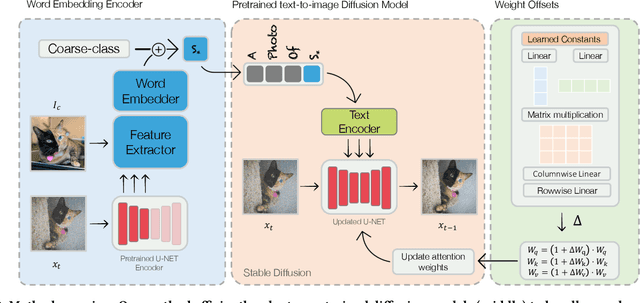

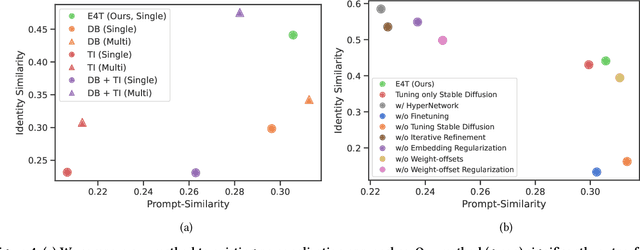
Text-to-image personalization aims to teach a pre-trained diffusion model to reason about novel, user provided concepts, embedding them into new scenes guided by natural language prompts. However, current personalization approaches struggle with lengthy training times, high storage requirements or loss of identity. To overcome these limitations, we propose an encoder-based domain-tuning approach. Our key insight is that by underfitting on a large set of concepts from a given domain, we can improve generalization and create a model that is more amenable to quickly adding novel concepts from the same domain. Specifically, we employ two components: First, an encoder that takes as an input a single image of a target concept from a given domain, e.g. a specific face, and learns to map it into a word-embedding representing the concept. Second, a set of regularized weight-offsets for the text-to-image model that learn how to effectively ingest additional concepts. Together, these components are used to guide the learning of unseen concepts, allowing us to personalize a model using only a single image and as few as 5 training steps - accelerating personalization from dozens of minutes to seconds, while preserving quality.
Continual Learning for Abdominal Multi-Organ and Tumor Segmentation
Jun 01, 2023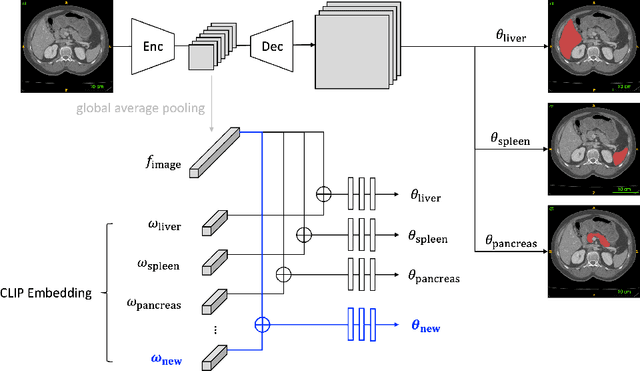

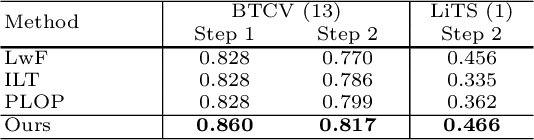
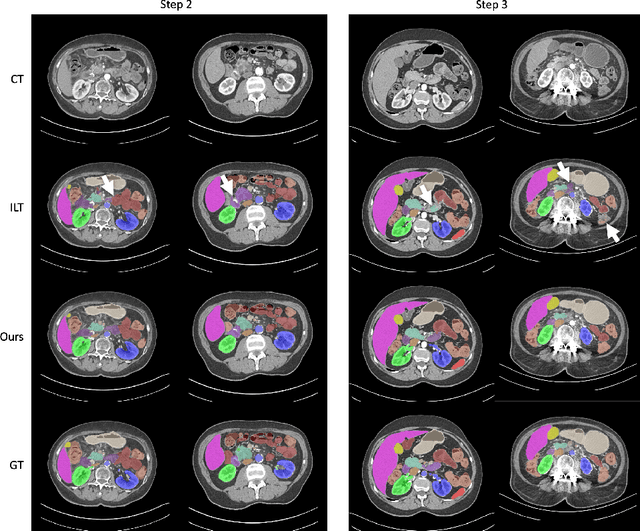
The ability to dynamically extend a model to new data and classes is critical for multiple organ and tumor segmentation. However, due to privacy regulations, accessing previous data and annotations can be problematic in the medical domain. This poses a significant barrier to preserving the high segmentation accuracy of the old classes when learning from new classes because of the catastrophic forgetting problem. In this paper, we first empirically demonstrate that simply using high-quality pseudo labels can fairly mitigate this problem in the setting of organ segmentation. Furthermore, we put forward an innovative architecture designed specifically for continuous organ and tumor segmentation, which incurs minimal computational overhead. Our proposed design involves replacing the conventional output layer with a suite of lightweight, class-specific heads, thereby offering the flexibility to accommodate newly emerging classes. These heads enable independent predictions for newly introduced and previously learned classes, effectively minimizing the impact of new classes on old ones during the course of continual learning. We further propose incorporating Contrastive Language-Image Pretraining (CLIP) embeddings into the organ-specific heads. These embeddings encapsulate the semantic information of each class, informed by extensive image-text co-training. The proposed method is evaluated on both in-house and public abdominal CT datasets under organ and tumor segmentation tasks. Empirical results suggest that the proposed design improves the segmentation performance of a baseline neural network on newly-introduced and previously-learned classes along the learning trajectory.
F?D: On understanding the role of deep feature spaces on face generation evaluation
Jun 01, 2023
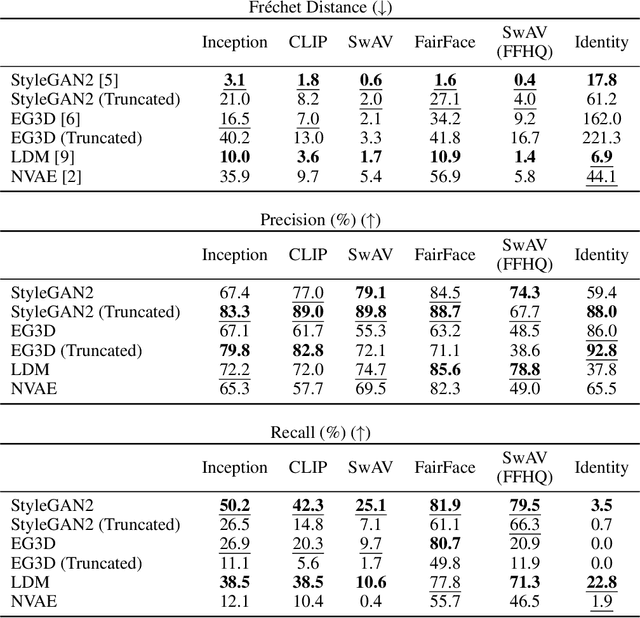
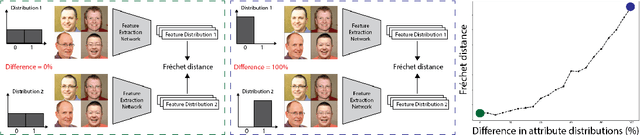
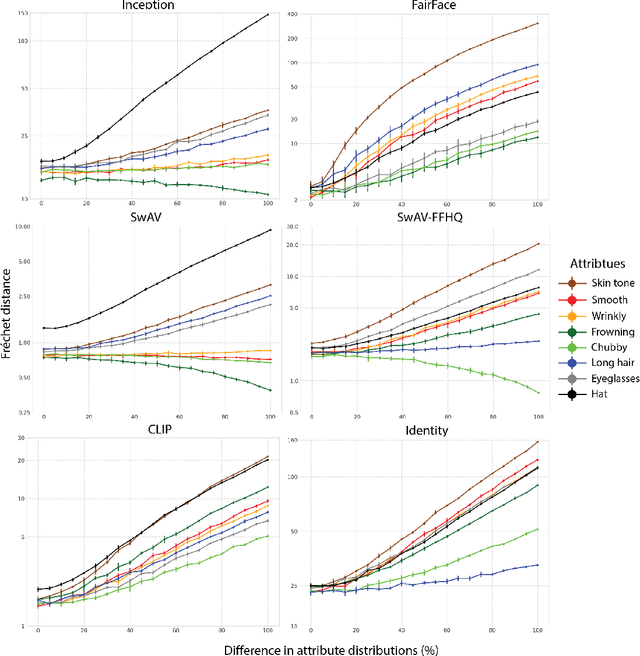
Perceptual metrics, like the Fr\'echet Inception Distance (FID), are widely used to assess the similarity between synthetically generated and ground truth (real) images. The key idea behind these metrics is to compute errors in a deep feature space that captures perceptually and semantically rich image features. Despite their popularity, the effect that different deep features and their design choices have on a perceptual metric has not been well studied. In this work, we perform a causal analysis linking differences in semantic attributes and distortions between face image distributions to Fr\'echet distances (FD) using several popular deep feature spaces. A key component of our analysis is the creation of synthetic counterfactual faces using deep face generators. Our experiments show that the FD is heavily influenced by its feature space's training dataset and objective function. For example, FD using features extracted from ImageNet-trained models heavily emphasize hats over regions like the eyes and mouth. Moreover, FD using features from a face gender classifier emphasize hair length more than distances in an identity (recognition) feature space. Finally, we evaluate several popular face generation models across feature spaces and find that StyleGAN2 consistently ranks higher than other face generators, except with respect to identity (recognition) features. This suggests the need for considering multiple feature spaces when evaluating generative models and using feature spaces that are tuned to nuances of the domain of interest.
Large-scale Dataset Pruning with Dynamic Uncertainty
Jun 08, 2023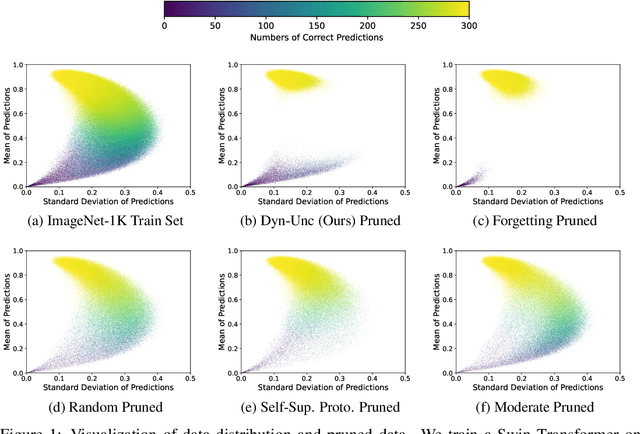
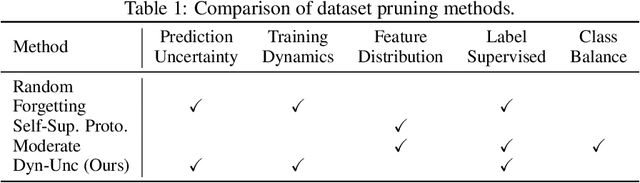

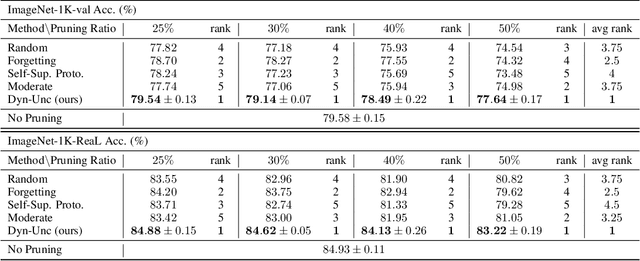
The state of the art of many learning tasks, e.g., image classification, is advanced by collecting larger datasets and then training larger models on them. As the outcome, the increasing computational cost is becoming unaffordable. In this paper, we investigate how to prune the large-scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible performance drop. We propose a simple yet effective dataset pruning method by exploring both the prediction uncertainty and training dynamics. To our knowledge, this is the first work to study dataset pruning on large-scale datasets, i.e., ImageNet-1K and ImageNet-21K, and advanced models, i.e., Swin Transformer and ConvNeXt. Extensive experimental results indicate that our method outperforms the state of the art and achieves 75% lossless compression ratio on both ImageNet-1K and ImageNet-21K. The code and pruned datasets are available at https://github.com/BAAI-DCAI/Dataset-Pruning.
A framework for dynamically training and adapting deep reinforcement learning models to different, low-compute, and continuously changing radiology deployment environments
Jun 08, 2023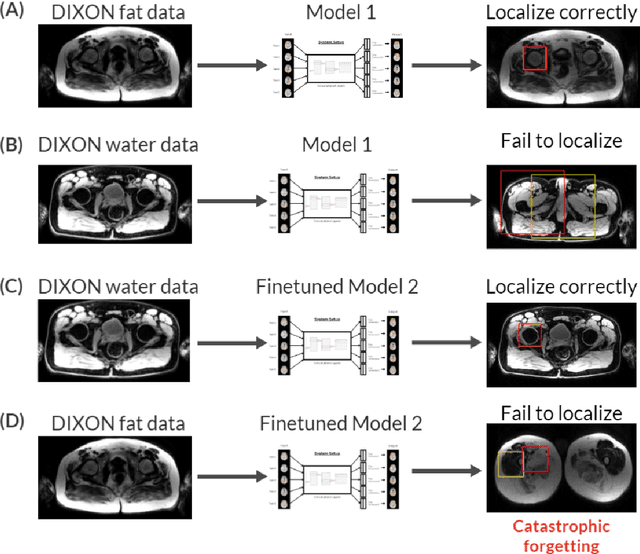
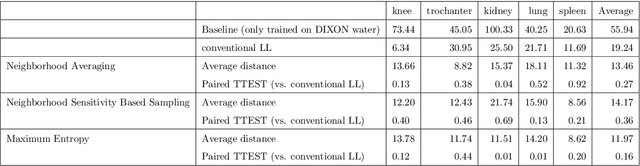
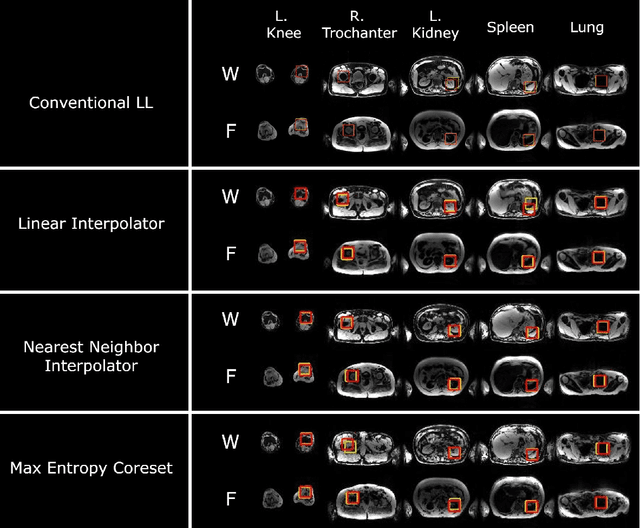
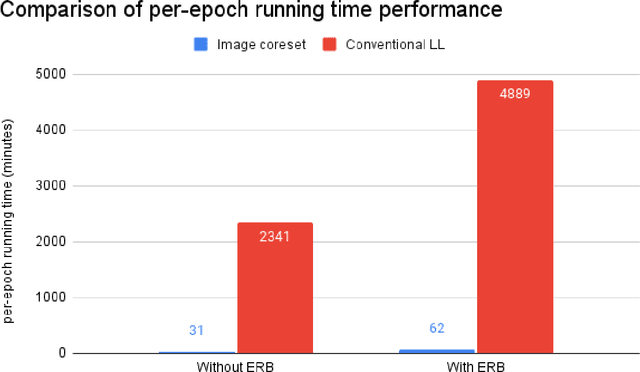
While Deep Reinforcement Learning has been widely researched in medical imaging, the training and deployment of these models usually require powerful GPUs. Since imaging environments evolve rapidly and can be generated by edge devices, the algorithm is required to continually learn and adapt to changing environments, and adjust to low-compute devices. To this end, we developed three image coreset algorithms to compress and denoise medical images for selective experience replayed-based lifelong reinforcement learning. We implemented neighborhood averaging coreset, neighborhood sensitivity-based sampling coreset, and maximum entropy coreset on full-body DIXON water and DIXON fat MRI images. All three coresets produced 27x compression with excellent performance in localizing five anatomical landmarks: left knee, right trochanter, left kidney, spleen, and lung across both imaging environments. Maximum entropy coreset obtained the best performance of $11.97\pm 12.02$ average distance error, compared to the conventional lifelong learning framework's $19.24\pm 50.77$.
Ownership Protection of Generative Adversarial Networks
Jun 08, 2023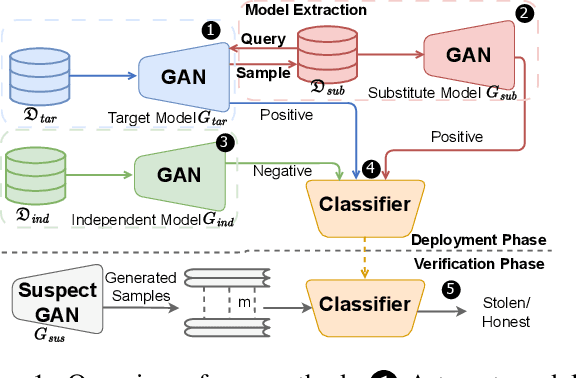

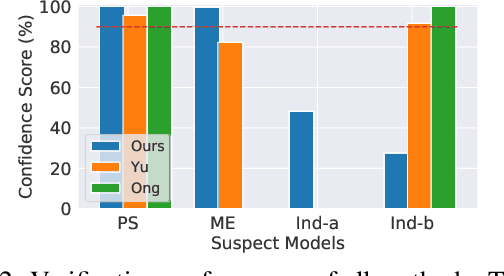
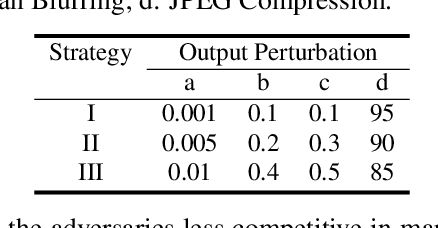
Generative adversarial networks (GANs) have shown remarkable success in image synthesis, making GAN models themselves commercially valuable to legitimate model owners. Therefore, it is critical to technically protect the intellectual property of GANs. Prior works need to tamper with the training set or training process, and they are not robust to emerging model extraction attacks. In this paper, we propose a new ownership protection method based on the common characteristics of a target model and its stolen models. Our method can be directly applicable to all well-trained GANs as it does not require retraining target models. Extensive experimental results show that our new method can achieve the best protection performance, compared to the state-of-the-art methods. Finally, we demonstrate the effectiveness of our method with respect to the number of generations of model extraction attacks, the number of generated samples, different datasets, as well as adaptive attacks.