 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
Mar 19, 2024

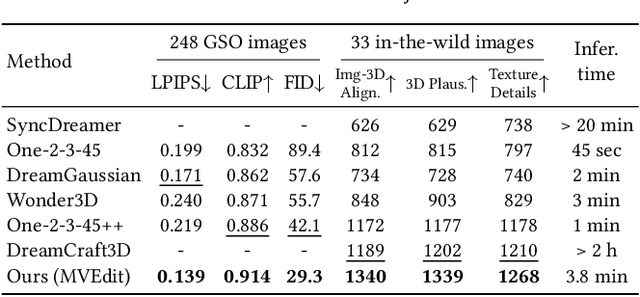
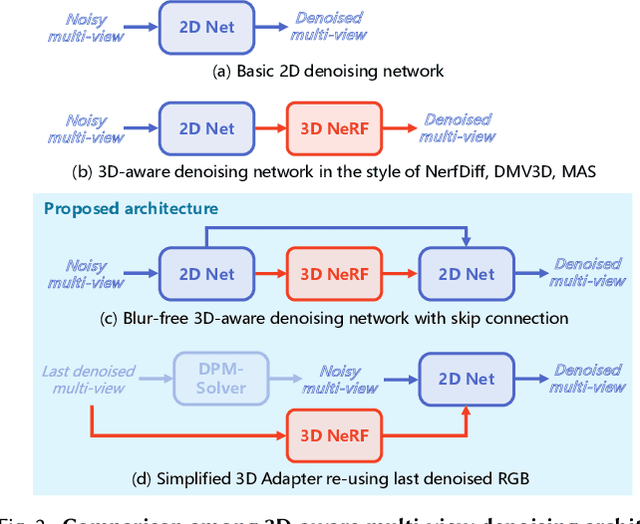
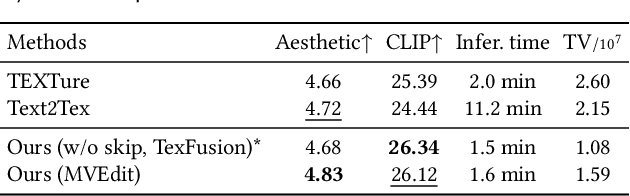
Open-domain 3D object synthesis has been lagging behind image synthesis due to limited data and higher computational complexity. To bridge this gap, recent works have investigated multi-view diffusion but often fall short in either 3D consistency, visual quality, or efficiency. This paper proposes MVEdit, which functions as a 3D counterpart of SDEdit, employing ancestral sampling to jointly denoise multi-view images and output high-quality textured meshes. Built on off-the-shelf 2D diffusion models, MVEdit achieves 3D consistency through a training-free 3D Adapter, which lifts the 2D views of the last timestep into a coherent 3D representation, then conditions the 2D views of the next timestep using rendered views, without uncompromising visual quality. With an inference time of only 2-5 minutes, this framework achieves better trade-off between quality and speed than score distillation. MVEdit is highly versatile and extendable, with a wide range of applications including text/image-to-3D generation, 3D-to-3D editing, and high-quality texture synthesis. In particular, evaluations demonstrate state-of-the-art performance in both image-to-3D and text-guided texture generation tasks. Additionally, we introduce a method for fine-tuning 2D latent diffusion models on small 3D datasets with limited resources, enabling fast low-resolution text-to-3D initialization.
Average Calibration Error: A Differentiable Loss for Improved Reliability in Image Segmentation
Mar 11, 2024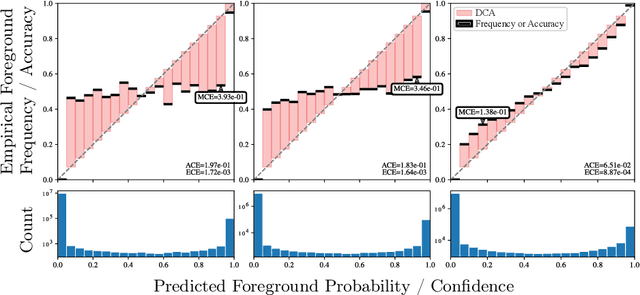
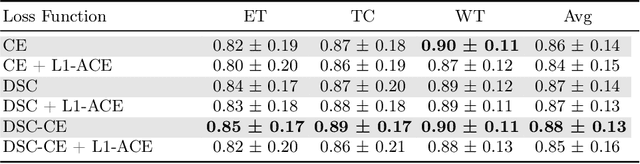
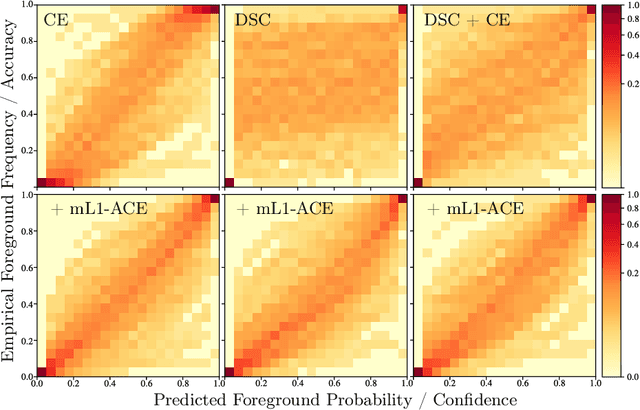
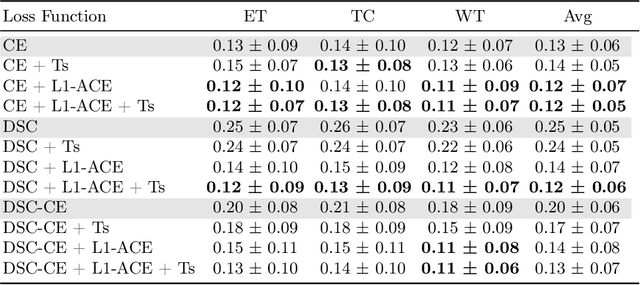
Deep neural networks for medical image segmentation often produce overconfident results misaligned with empirical observations. Such miscalibration, challenges their clinical translation. We propose to use marginal L1 average calibration error (mL1-ACE) as a novel auxiliary loss function to improve pixel-wise calibration without compromising segmentation quality. We show that this loss, despite using hard binning, is directly differentiable, bypassing the need for approximate but differentiable surrogate or soft binning approaches. Our work also introduces the concept of dataset reliability histograms which generalises standard reliability diagrams for refined visual assessment of calibration in semantic segmentation aggregated at the dataset level. Using mL1-ACE, we reduce average and maximum calibration error by 45% and 55% respectively, maintaining a Dice score of 87% on the BraTS 2021 dataset. We share our code here: https://github.com/cai4cai/ACE-DLIRIS
Semantic Gaussians: Open-Vocabulary Scene Understanding with 3D Gaussian Splatting
Mar 22, 2024Open-vocabulary 3D scene understanding presents a significant challenge in computer vision, withwide-ranging applications in embodied agents and augmented reality systems. Previous approaches haveadopted Neural Radiance Fields (NeRFs) to analyze 3D scenes. In this paper, we introduce SemanticGaussians, a novel open-vocabulary scene understanding approach based on 3D Gaussian Splatting. Our keyidea is distilling pre-trained 2D semantics into 3D Gaussians. We design a versatile projection approachthat maps various 2Dsemantic features from pre-trained image encoders into a novel semantic component of 3D Gaussians, withoutthe additional training required by NeRFs. We further build a 3D semantic network that directly predictsthe semantic component from raw 3D Gaussians for fast inference. We explore several applications ofSemantic Gaussians: semantic segmentation on ScanNet-20, where our approach attains a 4.2% mIoU and 4.0%mAcc improvement over prior open-vocabulary scene understanding counterparts; object part segmentation,sceneediting, and spatial-temporal segmentation with better qualitative results over 2D and 3D baselines,highlighting its versatility and effectiveness on supporting diverse downstream tasks.
SC-Tune: Unleashing Self-Consistent Referential Comprehension in Large Vision Language Models
Mar 20, 2024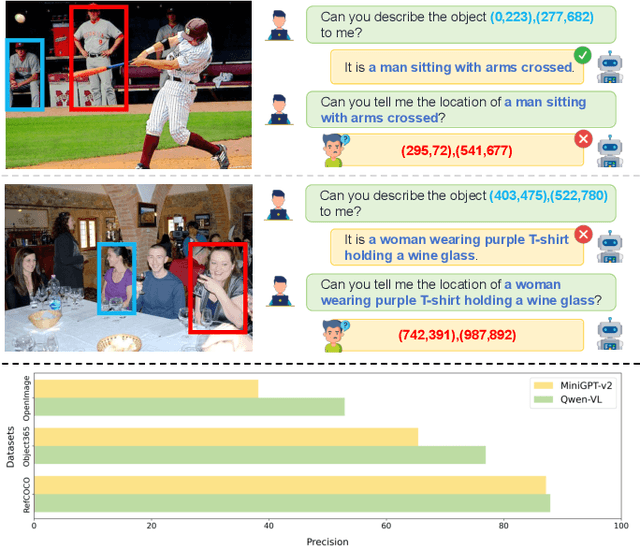
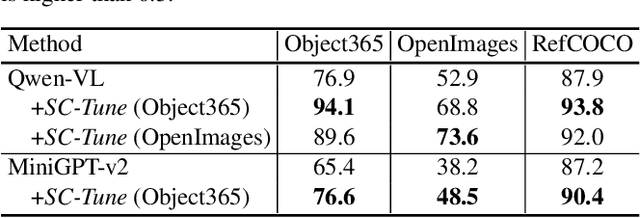
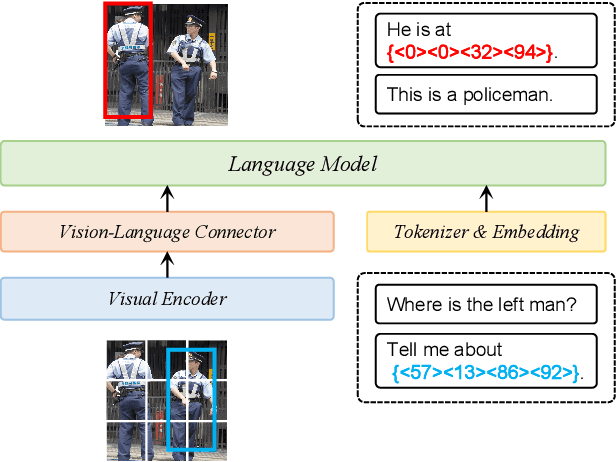
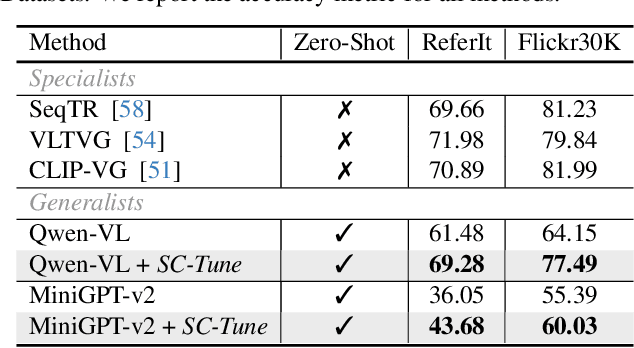
Recent trends in Large Vision Language Models (LVLMs) research have been increasingly focusing on advancing beyond general image understanding towards more nuanced, object-level referential comprehension. In this paper, we present and delve into the self-consistency capability of LVLMs, a crucial aspect that reflects the models' ability to both generate informative captions for specific objects and subsequently utilize these captions to accurately re-identify the objects in a closed-loop process. This capability significantly mirrors the precision and reliability of fine-grained visual-language understanding. Our findings reveal that the self-consistency level of existing LVLMs falls short of expectations, posing limitations on their practical applicability and potential. To address this gap, we introduce a novel fine-tuning paradigm named Self-Consistency Tuning (SC-Tune). It features the synergistic learning of a cyclic describer-locator system. This paradigm is not only data-efficient but also exhibits generalizability across multiple LVLMs. Through extensive experiments, we demonstrate that SC-Tune significantly elevates performance across a spectrum of object-level vision-language benchmarks and maintains competitive or improved performance on image-level vision-language benchmarks. Both our model and code will be publicly available at https://github.com/ivattyue/SC-Tune.
FFT-based Selection and Optimization of Statistics for Robust Recognition of Severely Corrupted Images
Mar 21, 2024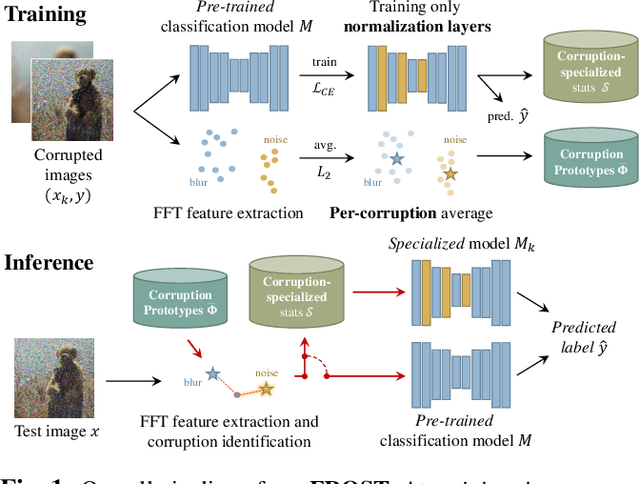
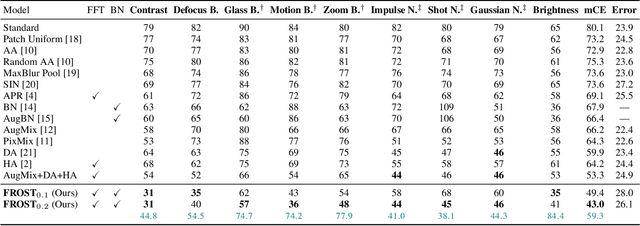
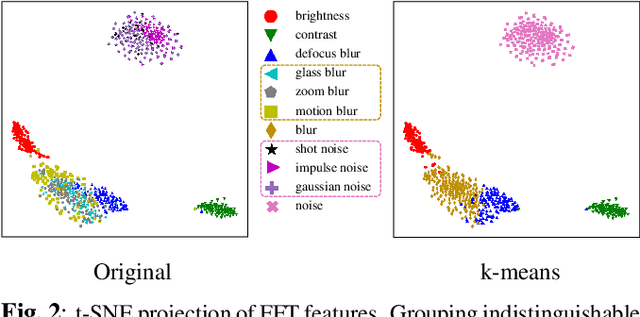

Improving model robustness in case of corrupted images is among the key challenges to enable robust vision systems on smart devices, such as robotic agents. Particularly, robust test-time performance is imperative for most of the applications. This paper presents a novel approach to improve robustness of any classification model, especially on severely corrupted images. Our method (FROST) employs high-frequency features to detect input image corruption type, and select layer-wise feature normalization statistics. FROST provides the state-of-the-art results for different models and datasets, outperforming competitors on ImageNet-C by up to 37.1% relative gain, improving baseline of 40.9% mCE on severe corruptions.
Once for Both: Single Stage of Importance and Sparsity Search for Vision Transformer Compression
Mar 23, 2024Recent Vision Transformer Compression (VTC) works mainly follow a two-stage scheme, where the importance score of each model unit is first evaluated or preset in each submodule, followed by the sparsity score evaluation according to the target sparsity constraint. Such a separate evaluation process induces the gap between importance and sparsity score distributions, thus causing high search costs for VTC. In this work, for the first time, we investigate how to integrate the evaluations of importance and sparsity scores into a single stage, searching the optimal subnets in an efficient manner. Specifically, we present OFB, a cost-efficient approach that simultaneously evaluates both importance and sparsity scores, termed Once for Both (OFB), for VTC. First, a bi-mask scheme is developed by entangling the importance score and the differentiable sparsity score to jointly determine the pruning potential (prunability) of each unit. Such a bi-mask search strategy is further used together with a proposed adaptive one-hot loss to realize the progressive-and-efficient search for the most important subnet. Finally, Progressive Masked Image Modeling (PMIM) is proposed to regularize the feature space to be more representative during the search process, which may be degraded by the dimension reduction. Extensive experiments demonstrate that OFB can achieve superior compression performance over state-of-the-art searching-based and pruning-based methods under various Vision Transformer architectures, meanwhile promoting search efficiency significantly, e.g., costing one GPU search day for the compression of DeiT-S on ImageNet-1K.
Innovative Quantitative Analysis for Disease Progression Assessment in Familial Cerebral Cavernous Malformations
Mar 23, 2024Familial cerebral cavernous malformation (FCCM) is a hereditary disorder characterized by abnormal vascular structures within the central nervous system. The FCCM lesions are often numerous and intricate, making quantitative analysis of the lesions a labor-intensive task. Consequently, clinicians face challenges in quantitatively assessing the severity of lesions and determining whether lesions have progressed. To alleviate this problem, we propose a quantitative statistical framework for FCCM, comprising an efficient annotation module, an FCCM lesion segmentation module, and an FCCM lesion quantitative statistics module. Our framework demonstrates precise segmentation of the FCCM lesion based on efficient data annotation, achieving a Dice coefficient of 93.22\%. More importantly, we focus on quantitative statistics of lesions, which is combined with image registration to realize the quantitative comparison of lesions between different examinations of patients, and a visualization framework has been established for doctors to comprehensively compare and analyze lesions. The experimental results have demonstrated that our proposed framework not only obtains objective, accurate, and comprehensive quantitative statistical information, which provides a quantitative assessment method for disease progression and drug efficacy study, but also considerably reduces the manual measurement and statistical workload of lesions, assisting clinical decision-making for FCCM and accelerating progress in FCCM clinical research. This highlights the potential of practical application of the framework in FCCM clinical research and clinical decision-making. The codes are available at https://github.com/6zrg/Quantitative-Statistics-of-FCCM.
uniGradICON: A Foundation Model for Medical Image Registration
Mar 09, 2024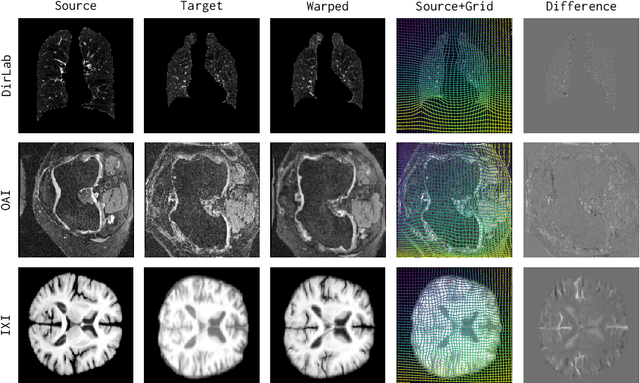
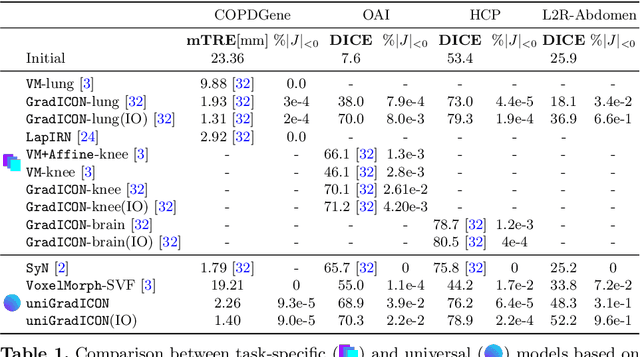

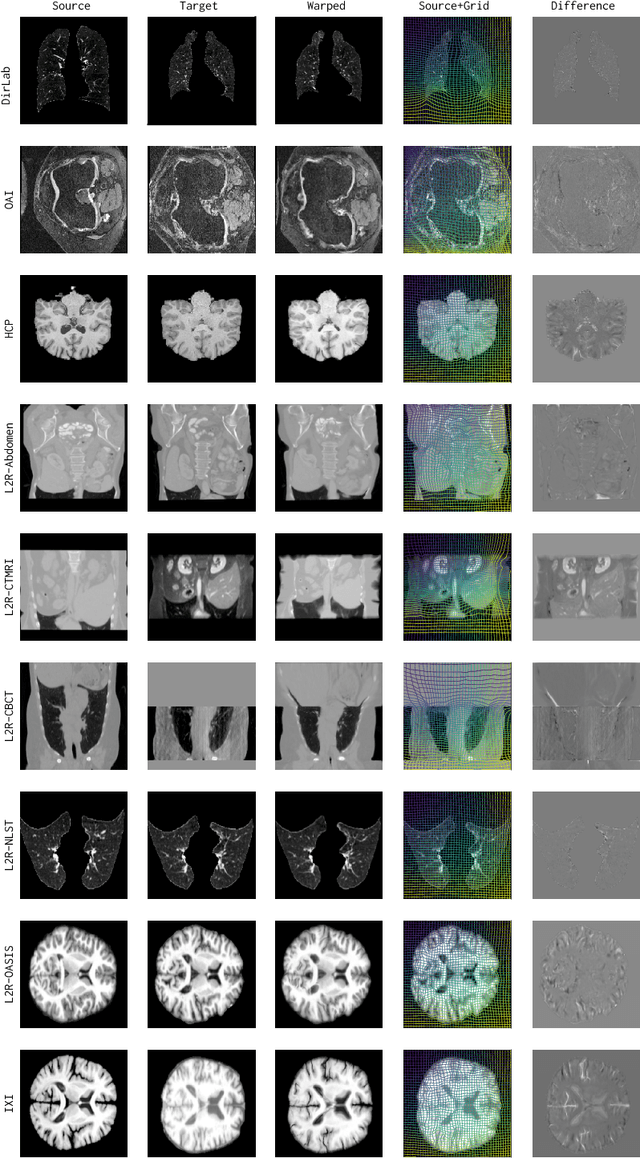
Conventional medical image registration approaches directly optimize over the parameters of a transformation model. These approaches have been highly successful and are used generically for registrations of different anatomical regions. Recent deep registration networks are incredibly fast and accurate but are only trained for specific tasks. Hence, they are no longer generic registration approaches. We therefore propose uniGradICON, a first step toward a foundation model for registration providing 1) great performance \emph{across} multiple datasets which is not feasible for current learning-based registration methods, 2) zero-shot capabilities for new registration tasks suitable for different acquisitions, anatomical regions, and modalities compared to the training dataset, and 3) a strong initialization for finetuning on out-of-distribution registration tasks. UniGradICON unifies the speed and accuracy benefits of learning-based registration algorithms with the generic applicability of conventional non-deep-learning approaches. We extensively trained and evaluated uniGradICON on twelve different public datasets. Our code and the uniGradICON model are available at https://github.com/uncbiag/uniGradICON.
Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing
Mar 06, 2024
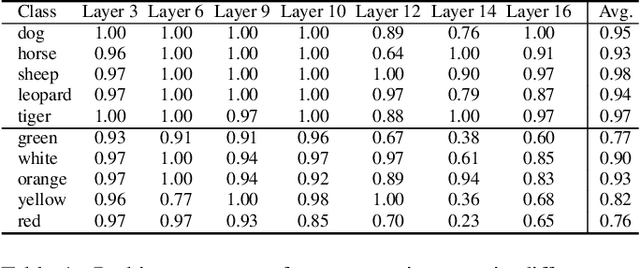
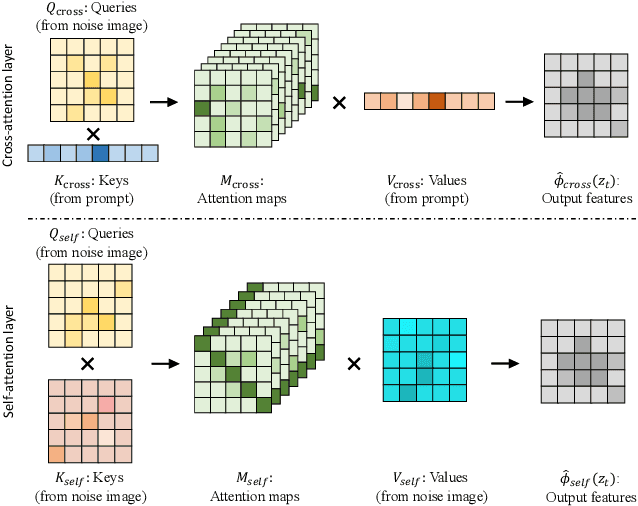
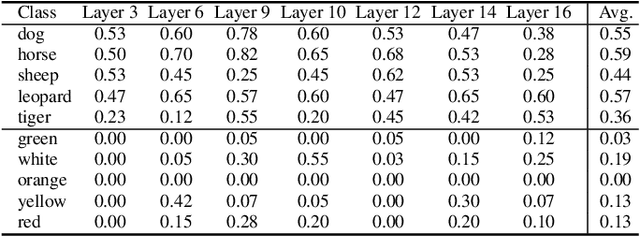
Deep Text-to-Image Synthesis (TIS) models such as Stable Diffusion have recently gained significant popularity for creative Text-to-image generation. Yet, for domain-specific scenarios, tuning-free Text-guided Image Editing (TIE) is of greater importance for application developers, which modify objects or object properties in images by manipulating feature components in attention layers during the generation process. However, little is known about what semantic meanings these attention layers have learned and which parts of the attention maps contribute to the success of image editing. In this paper, we conduct an in-depth probing analysis and demonstrate that cross-attention maps in Stable Diffusion often contain object attribution information that can result in editing failures. In contrast, self-attention maps play a crucial role in preserving the geometric and shape details of the source image during the transformation to the target image. Our analysis offers valuable insights into understanding cross and self-attention maps in diffusion models. Moreover, based on our findings, we simplify popular image editing methods and propose a more straightforward yet more stable and efficient tuning-free procedure that only modifies self-attention maps of the specified attention layers during the denoising process. Experimental results show that our simplified method consistently surpasses the performance of popular approaches on multiple datasets.
Language-Based Depth Hints for Monocular Depth Estimation
Mar 22, 2024Monocular depth estimation (MDE) is inherently ambiguous, as a given image may result from many different 3D scenes and vice versa. To resolve this ambiguity, an MDE system must make assumptions about the most likely 3D scenes for a given input. These assumptions can be either explicit or implicit. In this work, we demonstrate the use of natural language as a source of an explicit prior about the structure of the world. The assumption is made that human language encodes the likely distribution in depth-space of various objects. We first show that a language model encodes this implicit bias during training, and that it can be extracted using a very simple learned approach. We then show that this prediction can be provided as an explicit source of assumption to an MDE system, using an off-the-shelf instance segmentation model that provides the labels used as the input to the language model. We demonstrate the performance of our method on the NYUD2 dataset, showing improvement compared to the baseline and to random controls.