 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Real-time myocardial landmark tracking for MRI-guided cardiac radio-ablation using Gaussian Processes
Jun 19, 2023
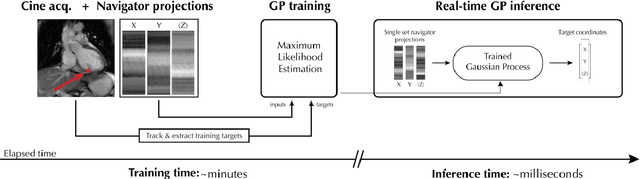

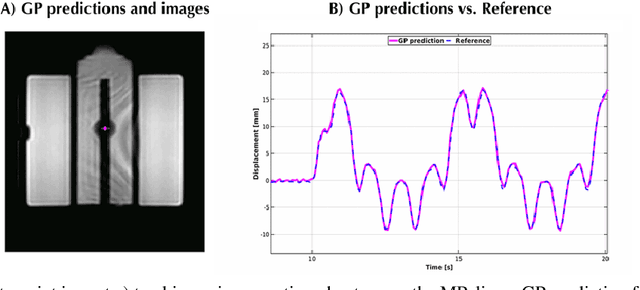
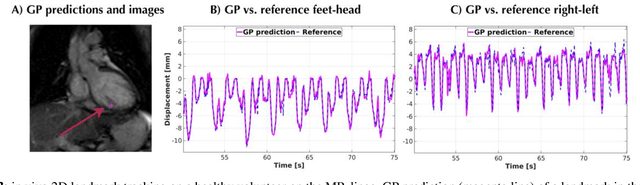
The high speed of cardiorespiratory motion introduces a unique challenge for cardiac stereotactic radio-ablation (STAR) treatments with the MR-linac. Such treatments require tracking myocardial landmarks with a maximum latency of 100 ms, which includes the acquisition of the required data. The aim of this study is to present a new method that allows to track myocardial landmarks from few readouts of MRI data, thereby achieving a latency sufficient for STAR treatments. We present a tracking framework that requires only few readouts of k-space data as input, which can be acquired at least an order of magnitude faster than MR-images. Combined with the real-time tracking speed of a probabilistic machine learning framework called Gaussian Processes, this allows to track myocardial landmarks with a sufficiently low latency for cardiac STAR guidance, including both the acquisition of required data, and the tracking inference. The framework is demonstrated in 2D on a motion phantom, and in vivo on volunteers and a ventricular tachycardia (arrhythmia) patient. Moreover, the feasibility of an extension to 3D was demonstrated by in silico 3D experiments with a digital motion phantom. The framework was compared with template matching - a reference, image-based, method - and linear regression methods. Results indicate an order of magnitude lower total latency (<10 ms) for the proposed framework in comparison with alternative methods. The root-mean-square-distances and mean end-point-distance with the reference tracking method was less than 0.8 mm for all experiments, showing excellent (sub-voxel) agreement. The high accuracy in combination with a total latency of less than 10 ms - including data acquisition and processing - make the proposed method a suitable candidate for tracking during STAR treatments.
DeltaEdit: Exploring Text-free Training for Text-Driven Image Manipulation
Mar 11, 2023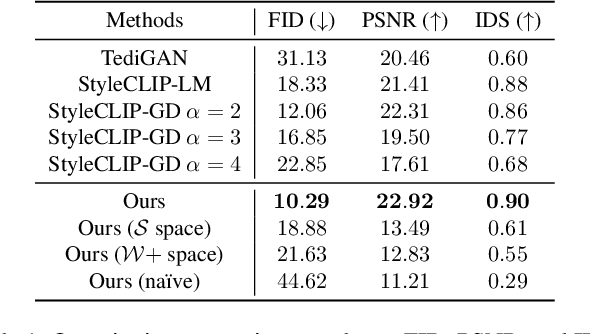
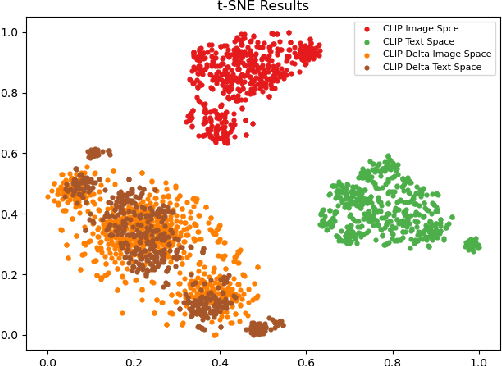

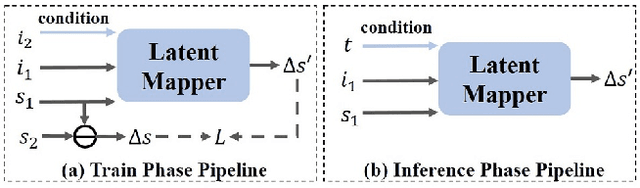
Text-driven image manipulation remains challenging in training or inference flexibility. Conditional generative models depend heavily on expensive annotated training data. Meanwhile, recent frameworks, which leverage pre-trained vision-language models, are limited by either per text-prompt optimization or inference-time hyper-parameters tuning. In this work, we propose a novel framework named \textit{DeltaEdit} to address these problems. Our key idea is to investigate and identify a space, namely delta image and text space that has well-aligned distribution between CLIP visual feature differences of two images and CLIP textual embedding differences of source and target texts. Based on the CLIP delta space, the DeltaEdit network is designed to map the CLIP visual features differences to the editing directions of StyleGAN at training phase. Then, in inference phase, DeltaEdit predicts the StyleGAN's editing directions from the differences of the CLIP textual features. In this way, DeltaEdit is trained in a text-free manner. Once trained, it can well generalize to various text prompts for zero-shot inference without bells and whistles. Code is available at https://github.com/Yueming6568/DeltaEdit.
Memorization Capacity of Multi-Head Attention in Transformers
Jun 03, 2023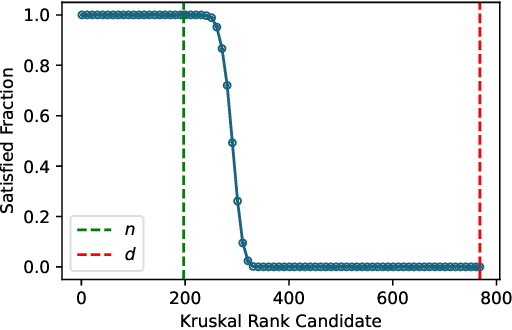

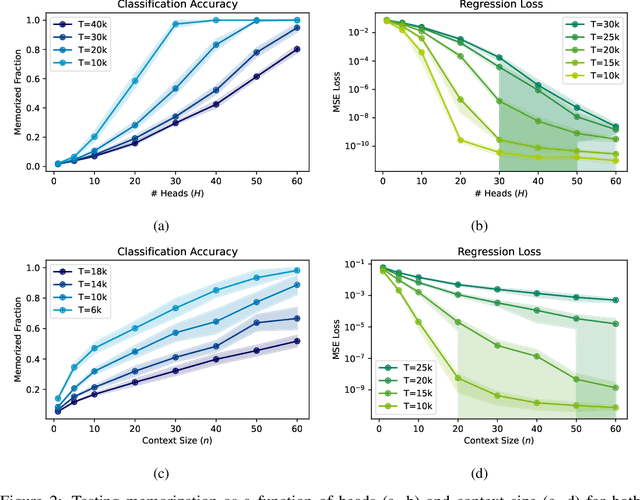
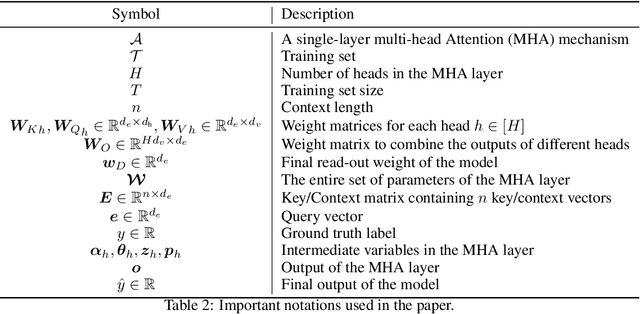
In this paper, we investigate the memorization capabilities of multi-head attention in Transformers, motivated by the central role attention plays in these models. Under a mild linear independence assumption on the input data, we present a theoretical analysis demonstrating that an $H$-head attention layer with a context size $n$, dimension $d$, and $O(Hd^2)$ parameters can memorize $O(Hn)$ examples. We conduct experiments that verify our assumptions on the image classification task using Vision Transformer. To validate our theoretical findings, we perform synthetic experiments and show a linear relationship between memorization capacity and the number of attention heads.
LAMM: Language-Assisted Multi-Modal Instruction-Tuning Dataset, Framework, and Benchmark
Jun 11, 2023
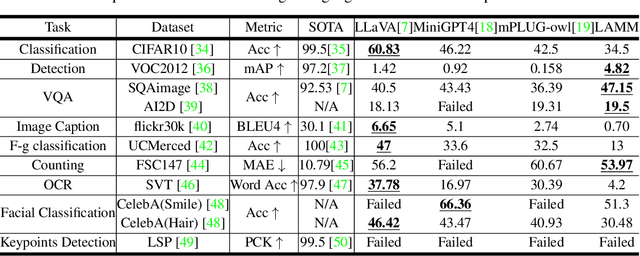
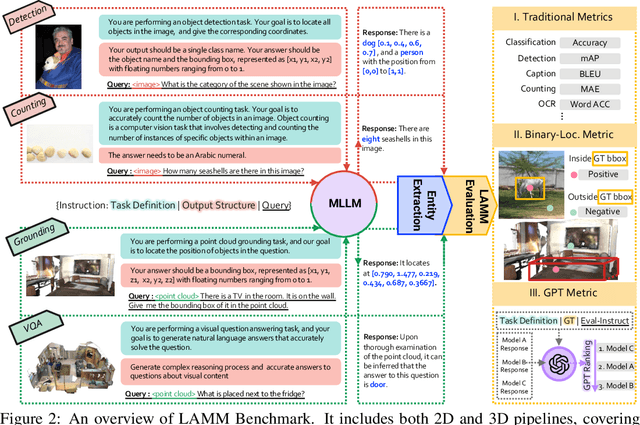
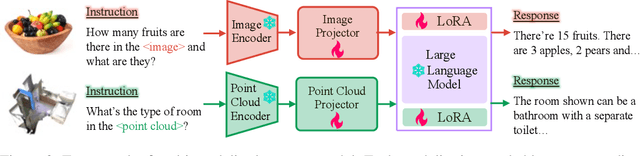
Large language models have become a potential pathway toward achieving artificial general intelligence. Recent works on multi-modal large language models have demonstrated their effectiveness in handling visual modalities. In this work, we extend the research of MLLMs to point clouds and present the LAMM-Dataset and LAMM-Benchmark for 2D image and 3D point cloud understanding. We also establish an extensible framework to facilitate the extension of MLLMs to additional modalities. Our main contribution is three-fold: 1) We present the LAMM-Dataset and LAMM-Benchmark, which cover almost all high-level vision tasks for 2D and 3D vision. Extensive experiments validate the effectiveness of our dataset and benchmark. 2) We demonstrate the detailed methods of constructing instruction-tuning datasets and benchmarks for MLLMs, which will enable future research on MLLMs to scale up and extend to other domains, tasks, and modalities faster. 3) We provide a primary but potential MLLM training framework optimized for modalities' extension. We also provide baseline models, comprehensive experimental observations, and analysis to accelerate future research.
3rd Place Solution for PVUW Challenge 2023: Video Panoptic Segmentation
Jun 11, 2023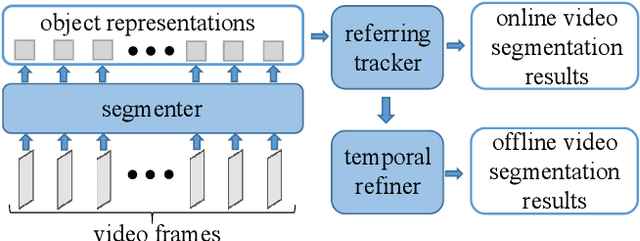
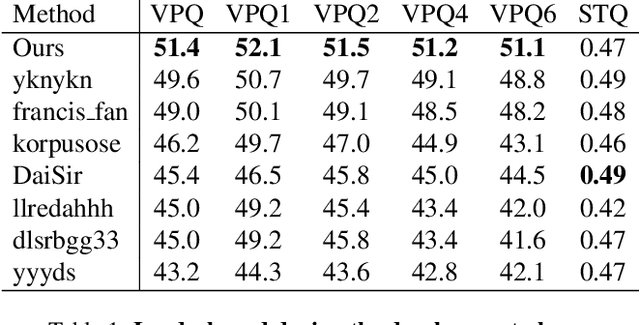
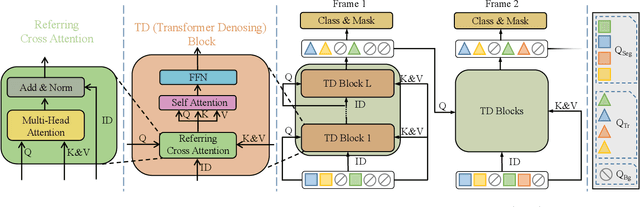
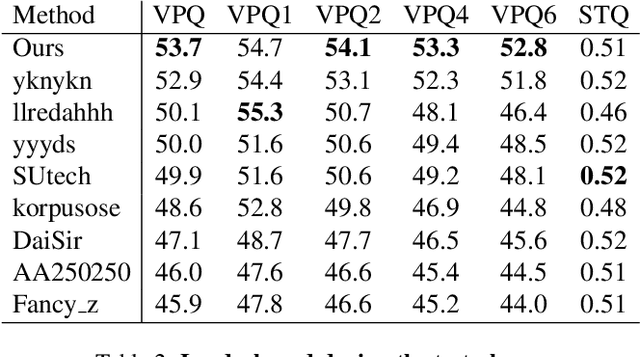
In order to deal with the task of video panoptic segmentation in the wild, we propose a robust integrated video panoptic segmentation solution. In our solution, we regard the video panoptic segmentation task as a segmentation target querying task, represent both semantic and instance targets as a set of queries, and then combine these queries with video features extracted by neural networks to predict segmentation masks. In order to improve the learning accuracy and convergence speed of the solution, we add additional tasks of video semantic segmentation and video instance segmentation for joint training. In addition, we also add an additional image semantic segmentation model to further improve the performance of semantic classes. In addition, we also add some additional operations to improve the robustness of the model. Extensive experiments on the VIPSeg dataset show that the proposed solution achieves state-of-the-art performance with 50.04\% VPQ on the VIPSeg test set, which is 3rd place on the video panoptic segmentation track of the PVUW Challenge 2023.
On the Efficacy of 3D Point Cloud Reinforcement Learning
Jun 11, 2023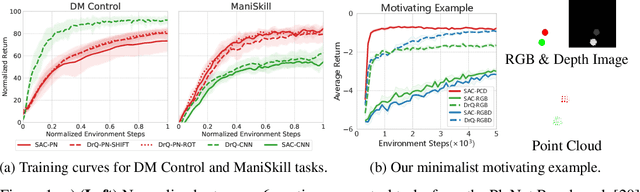


Recent studies on visual reinforcement learning (visual RL) have explored the use of 3D visual representations. However, none of these work has systematically compared the efficacy of 3D representations with 2D representations across different tasks, nor have they analyzed 3D representations from the perspective of agent-object / object-object relationship reasoning. In this work, we seek answers to the question of when and how do 3D neural networks that learn features in the 3D-native space provide a beneficial inductive bias for visual RL. We specifically focus on 3D point clouds, one of the most common forms of 3D representations. We systematically investigate design choices for 3D point cloud RL, leading to the development of a robust algorithm for various robotic manipulation and control tasks. Furthermore, through comparisons between 2D image vs 3D point cloud RL methods on both minimalist synthetic tasks and complex robotic manipulation tasks, we find that 3D point cloud RL can significantly outperform the 2D counterpart when agent-object / object-object relationship encoding is a key factor.
Random-Access Neural Compression of Material Textures
May 26, 2023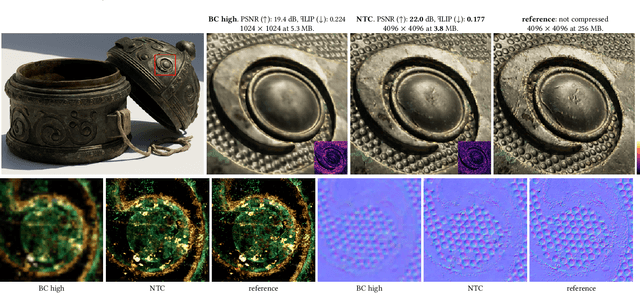

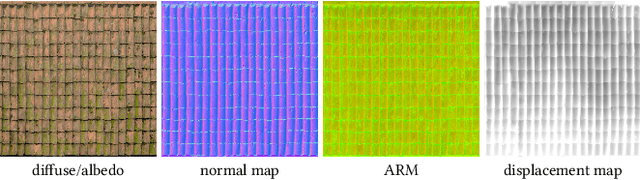

The continuous advancement of photorealism in rendering is accompanied by a growth in texture data and, consequently, increasing storage and memory demands. To address this issue, we propose a novel neural compression technique specifically designed for material textures. We unlock two more levels of detail, i.e., 16x more texels, using low bitrate compression, with image quality that is better than advanced image compression techniques, such as AVIF and JPEG XL. At the same time, our method allows on-demand, real-time decompression with random access similar to block texture compression on GPUs, enabling compression on disk and memory. The key idea behind our approach is compressing multiple material textures and their mipmap chains together, and using a small neural network, that is optimized for each material, to decompress them. Finally, we use a custom training implementation to achieve practical compression speeds, whose performance surpasses that of general frameworks, like PyTorch, by an order of magnitude.
Linear Object Detection in Document Images using Multiple Object Tracking
May 26, 2023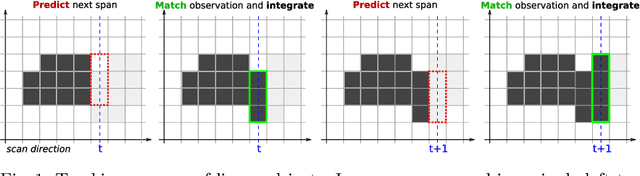
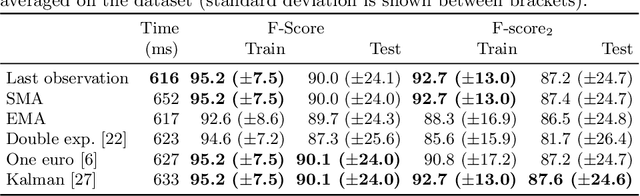

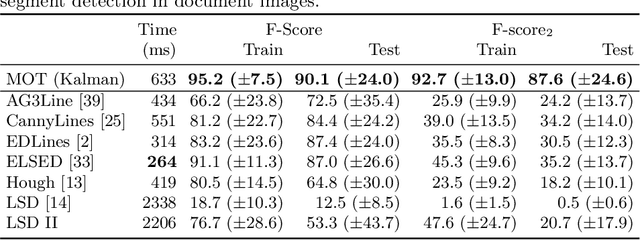
Linear objects convey substantial information about document structure, but are challenging to detect accurately because of degradation (curved, erased) or decoration (doubled, dashed). Many approaches can recover some vector representation, but only one closed-source technique introduced in 1994, based on Kalman filters (a particular case of Multiple Object Tracking algorithm), can perform a pixel-accurate instance segmentation of linear objects and enable to selectively remove them from the original image. We aim at re-popularizing this approach and propose: 1. a framework for accurate instance segmentation of linear objects in document images using Multiple Object Tracking (MOT); 2. document image datasets and metrics which enable both vector- and pixel-based evaluation of linear object detection; 3. performance measures of MOT approaches against modern segment detectors; 4. performance measures of various tracking strategies, exhibiting alternatives to the original Kalman filters approach; and 5. an open-source implementation of a detector which can discriminate instances of curved, erased, dashed, intersecting and/or overlapping linear objects.
Towards Better Explanations for Object Detection
Jun 06, 2023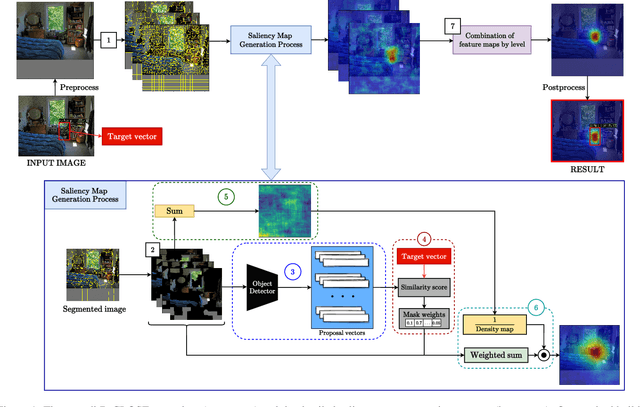

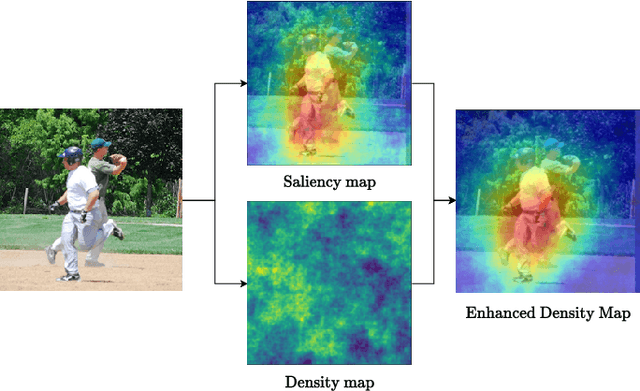
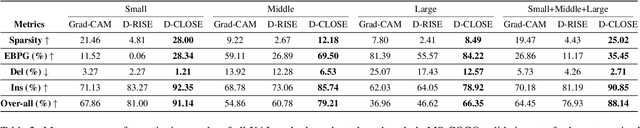
Recent advances in Artificial Intelligence (AI) technology have promoted their use in almost every field. The growing complexity of deep neural networks (DNNs) makes it increasingly difficult and important to explain the inner workings and decisions of the network. However, most current techniques for explaining DNNs focus mainly on interpreting classification tasks. This paper proposes a method to explain the decision for any object detection model called D-CLOSE. To closely track the model's behavior, we used multiple levels of segmentation on the image and a process to combine them. We performed tests on the MS-COCO dataset with the YOLOX model, which shows that our method outperforms D-RISE and can give a better quality and less noise explanation.
Single-Shot Global Localization via Graph-Theoretic Correspondence Matching
Jun 06, 2023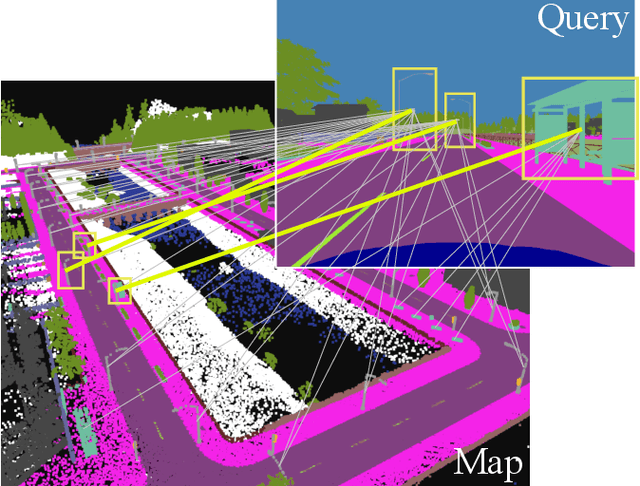
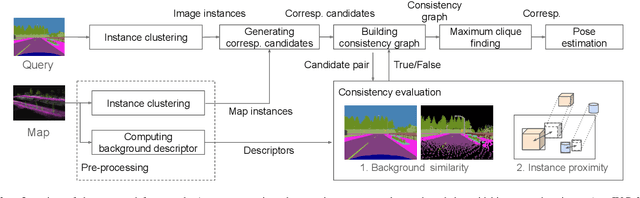
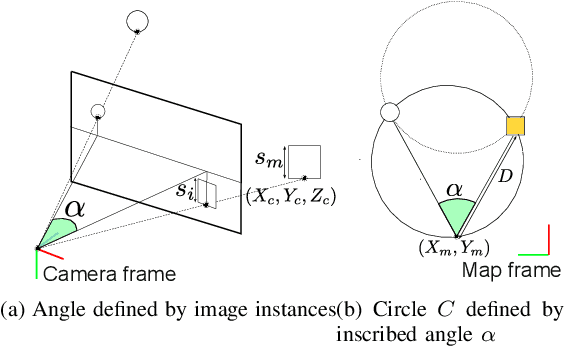
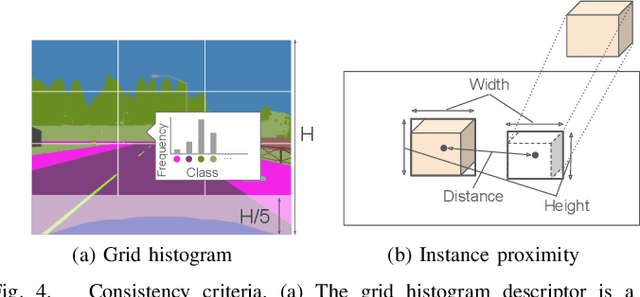
This paper describes a method of global localization based on graph-theoretic association of instances between a query and the prior map. The proposed framework employs correspondence matching based on the maximum clique problem (MCP). The framework is potentially applicable to other map and/or query modalities thanks to the graph-based abstraction of the problem, while many of existing global localization methods rely on a query and the dataset in the same modality. We implement it with a semantically labeled 3D point cloud map, and a semantic segmentation image as a query. Leveraging the graph-theoretic framework, the proposed method realizes global localization exploiting only the map and the query. The method shows promising results on multiple large-scale simulated maps of urban scenes.