 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FLSL: Feature-level Self-supervised Learning
Jun 09, 2023
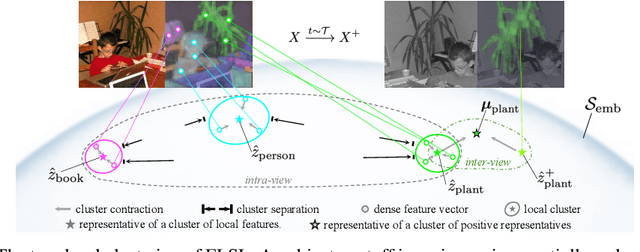
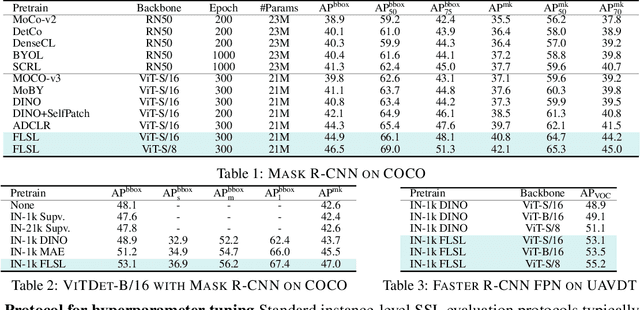
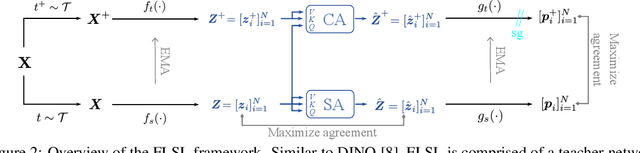
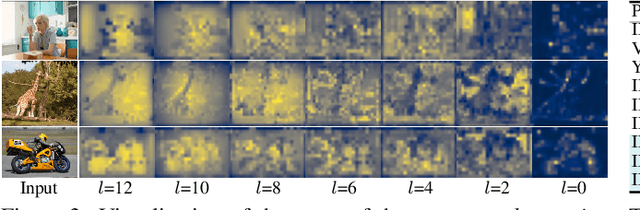
Current self-supervised learning (SSL) methods (e.g., SimCLR, DINO, VICReg, MOCOv3) target primarily on representations at instance level and do not generalize well to dense prediction tasks, such as object detection and segmentation. Towards aligning SSL with dense predictions, this paper demonstrates for the first time the underlying mean-shift clustering process of Vision Transformers (ViT), which aligns well with natural image semantics (e.g., a world of objects and stuffs). By employing transformer for joint embedding and clustering, we propose a two-level feature clustering SSL method, coined Feature-Level Self-supervised Learning (FLSL). We present the formal definition of the FLSL problem and construct the objectives from the mean-shift and k-means perspectives. We show that FLSL promotes remarkable semantic cluster representations and learns an embedding scheme amenable to intra-view and inter-view feature clustering. Experiments show that FLSL yields significant improvements in dense prediction tasks, achieving 44.9 (+2.8)% AP and 46.5% AP in object detection, as well as 40.8 (+2.3)% AP and 42.1% AP in instance segmentation on MS-COCO, using Mask R-CNN with ViT-S/16 and ViT-S/8 as backbone, respectively. FLSL consistently outperforms existing SSL methods across additional benchmarks, including UAV object detection on UAVDT, and video instance segmentation on DAVIS 2017. We conclude by presenting visualization and various ablation studies to better 20 understand the success of FLSL.
EfficientBioAI: Making Bioimaging AI Models Efficient in Energy, Latency and Representation
Jun 09, 2023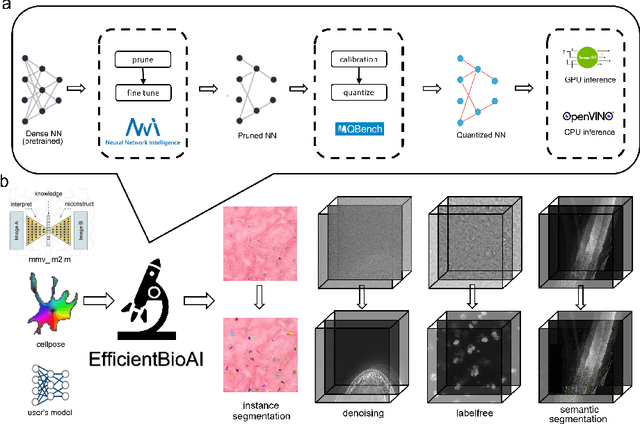
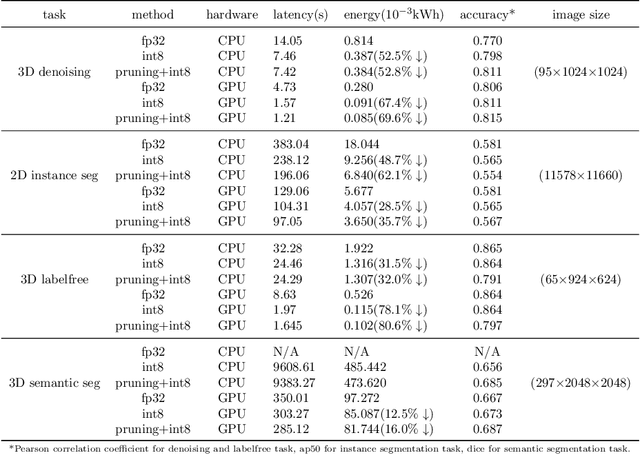
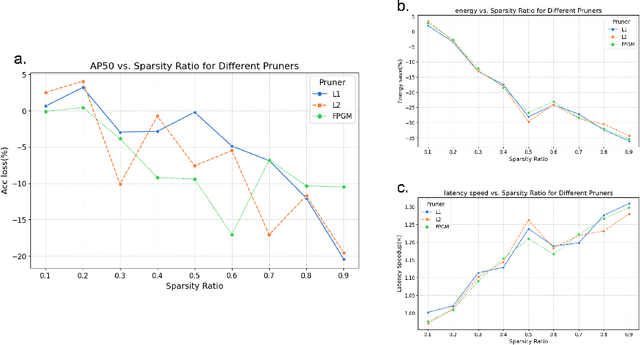
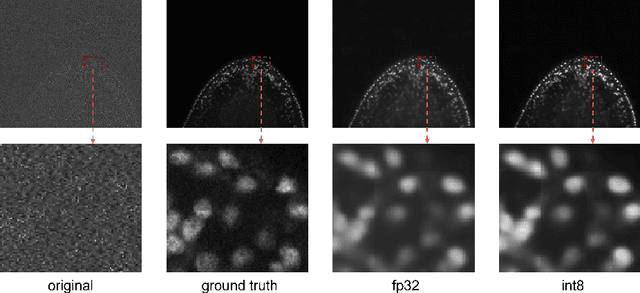
Artificial intelligence (AI) has been widely used in bioimage image analysis nowadays, but the efficiency of AI models, like the energy consumption and latency is not ignorable due to the growing model size and complexity, as well as the fast-growing analysis needs in modern biomedical studies. Like we can compress large images for efficient storage and sharing, we can also compress the AI models for efficient applications and deployment. In this work, we present EfficientBioAI, a plug-and-play toolbox that can compress given bioimaging AI models for them to run with significantly reduced energy cost and inference time on both CPU and GPU, without compromise on accuracy. In some cases, the prediction accuracy could even increase after compression, since the compression procedure could remove redundant information in the model representation and therefore reduce over-fitting. From four different bioimage analysis applications, we observed around 2-5 times speed-up during inference and 30-80$\%$ saving in energy. Cutting the runtime of large scale bioimage analysis from days to hours or getting a two-minutes bioimaging AI model inference done in near real-time will open new doors for method development and biomedical discoveries. We hope our toolbox will facilitate resource-constrained bioimaging AI and accelerate large-scale AI-based quantitative biological studies in an eco-friendly way, as well as stimulate further research on the efficiency of bioimaging AI.
Hidden Classification Layers: a study on Data Hidden Representations with a Higher Degree of Linear Separability between the Classes
Jun 09, 2023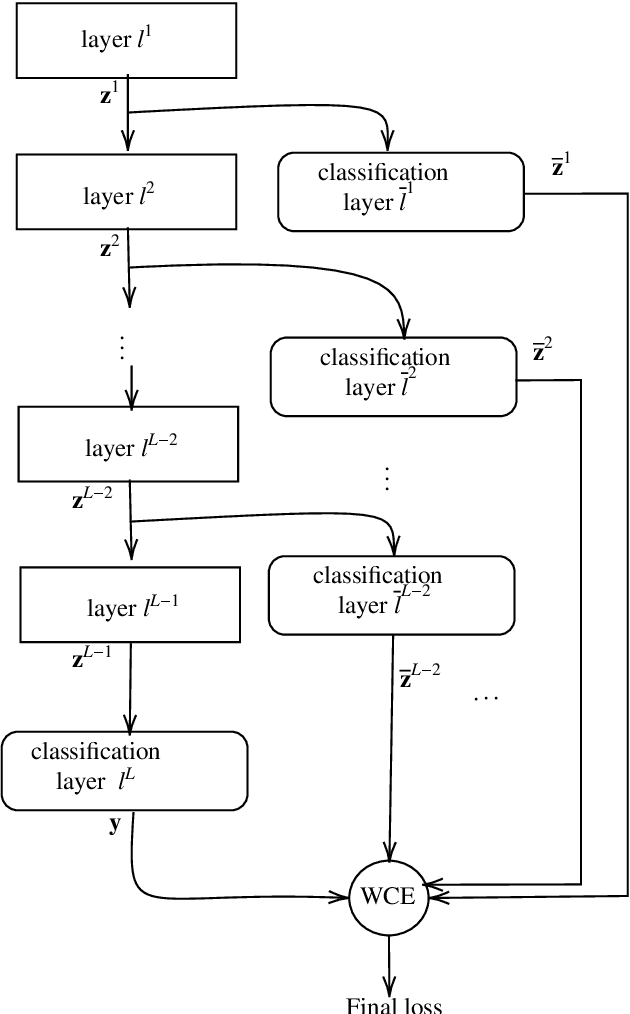
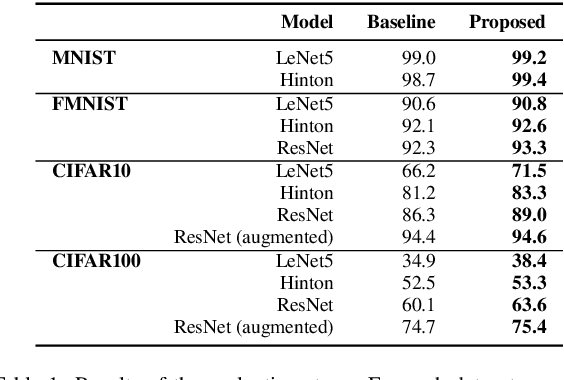
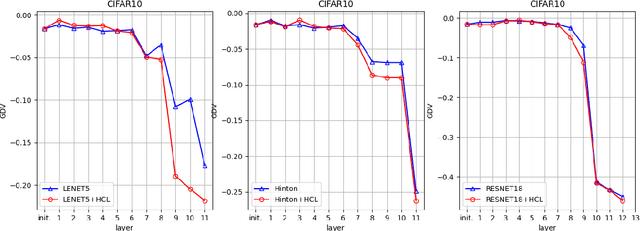
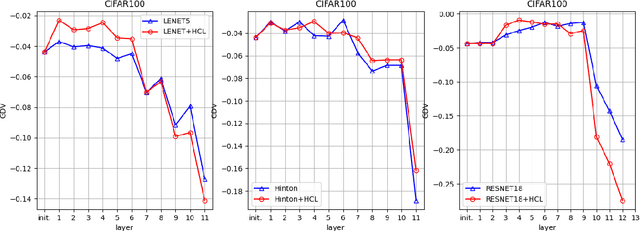
In the context of classification problems, Deep Learning (DL) approaches represent state of art. Many DL approaches are based on variations of standard multi-layer feed-forward neural networks. These are also referred to as deep networks. The basic idea is that each hidden neural layer accomplishes a data transformation which is expected to make the data representation "somewhat more linearly separable" than the previous one to obtain a final data representation which is as linearly separable as possible. However, determining the appropriate neural network parameters that can perform these transformations is a critical problem. In this paper, we investigate the impact on deep network classifier performances of a training approach favouring solutions where data representations at the hidden layers have a higher degree of linear separability between the classes with respect to standard methods. To this aim, we propose a neural network architecture which induces an error function involving the outputs of all the network layers. Although similar approaches have already been partially discussed in the past literature, here we propose a new architecture with a novel error function and an extensive experimental analysis. This experimental analysis was made in the context of image classification tasks considering four widely used datasets. The results show that our approach improves the accuracy on the test set in all the considered cases.
Feature Selection using Sparse Adaptive Bottleneck Centroid-Encoder
Jun 09, 2023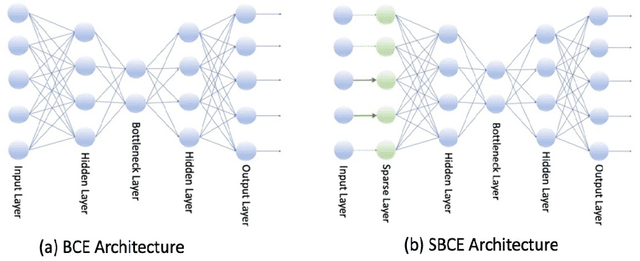

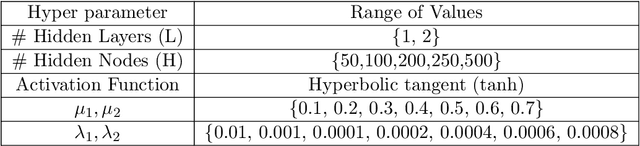
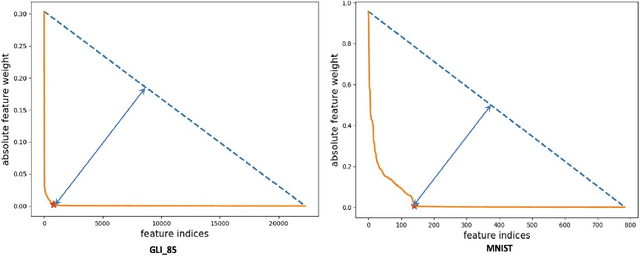
We introduce a novel nonlinear model, Sparse Adaptive Bottleneck Centroid-Encoder (SABCE), for determining the features that discriminate between two or more classes. The algorithm aims to extract discriminatory features in groups while reconstructing the class centroids in the ambient space and simultaneously use additional penalty terms in the bottleneck layer to decrease within-class scatter and increase the separation of different class centroids. The model has a sparsity-promoting layer (SPL) with a one-to-one connection to the input layer. Along with the primary objective, we minimize the $l_{2,1}$-norm of the sparse layer, which filters out unnecessary features from input data. During training, we update class centroids by taking the Hadamard product of the centroids and weights of the sparse layer, thus ignoring the irrelevant features from the target. Therefore the proposed method learns to reconstruct the critical components of class centroids rather than the whole centroids. The algorithm is applied to various real-world data sets, including high-dimensional biological, image, speech, and accelerometer sensor data. We compared our method to different state-of-the-art feature selection techniques, including supervised Concrete Autoencoders (SCAE), Feature Selection Networks (FsNet), Stochastic Gates (STG), and LassoNet. We empirically showed that SABCE features often produced better classification accuracy than other methods on the sequester test sets, setting new state-of-the-art results.
Measuring Faithful and Plausible Visual Grounding in VQA
May 24, 2023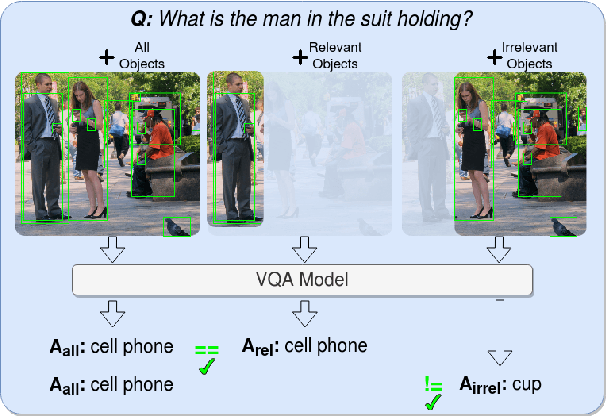

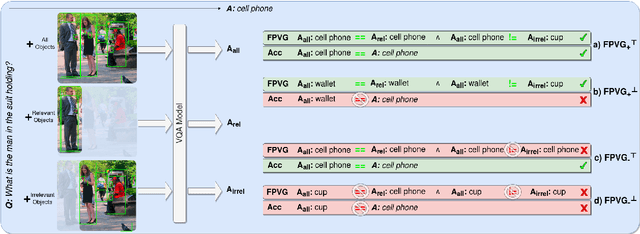
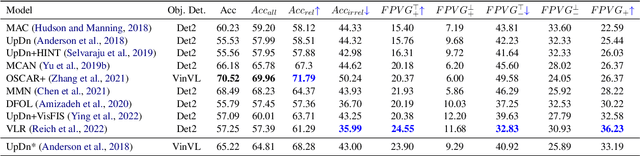
Metrics for Visual Grounding (VG) in Visual Question Answering (VQA) systems primarily aim to measure a system's reliance on relevant parts of the image when inferring an answer to the given question. Lack of VG has been a common problem among state-of-the-art VQA systems and can manifest in over-reliance on irrelevant image parts or a disregard for the visual modality entirely. Although inference capabilities of VQA models are often illustrated by a few qualitative illustrations, most systems are not quantitatively assessed for their VG properties. We believe, an easily calculated criterion for meaningfully measuring a system's VG can help remedy this shortcoming, as well as add another valuable dimension to model evaluations and analysis. To this end, we propose a new VG metric that captures if a model a) identifies question-relevant objects in the scene, and b) actually relies on the information contained in the relevant objects when producing its answer, i.e., if its visual grounding is both "faithful" and "plausible". Our metric, called "Faithful and Plausible Visual Grounding" (FPVG), is straightforward to determine for most VQA model designs. We give a detailed description of FPVG and evaluate several reference systems spanning various VQA architectures. Code to support the metric calculations on the GQA data set is available on GitHub.
Towards Anytime Classification in Early-Exit Architectures by Enforcing Conditional Monotonicity
Jun 05, 2023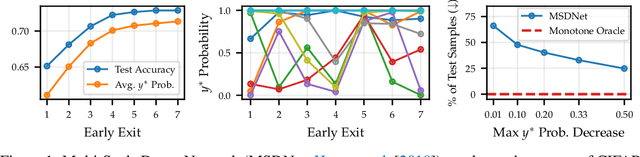
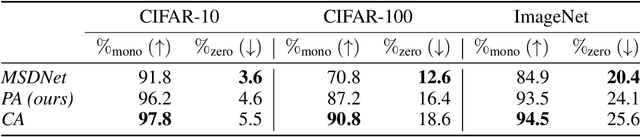
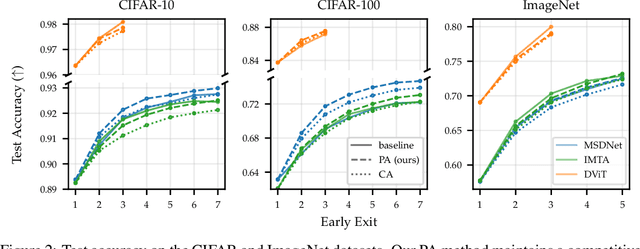
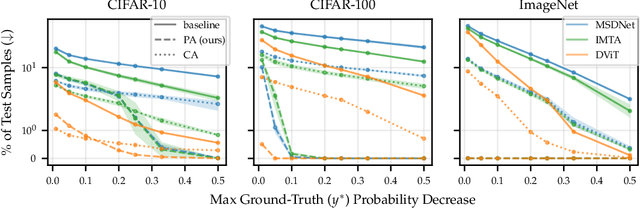
Modern predictive models are often deployed to environments in which computational budgets are dynamic. Anytime algorithms are well-suited to such environments as, at any point during computation, they can output a prediction whose quality is a function of computation time. Early-exit neural networks have garnered attention in the context of anytime computation due to their capability to provide intermediate predictions at various stages throughout the network. However, we demonstrate that current early-exit networks are not directly applicable to anytime settings, as the quality of predictions for individual data points is not guaranteed to improve with longer computation. To address this shortcoming, we propose an elegant post-hoc modification, based on the Product-of-Experts, that encourages an early-exit network to become gradually confident. This gives our deep models the property of conditional monotonicity in the prediction quality -- an essential stepping stone towards truly anytime predictive modeling using early-exit architectures. Our empirical results on standard image-classification tasks demonstrate that such behaviors can be achieved while preserving competitive accuracy on average.
Weakly-Supervised Conditional Embedding for Referred Visual Search
Jun 05, 2023
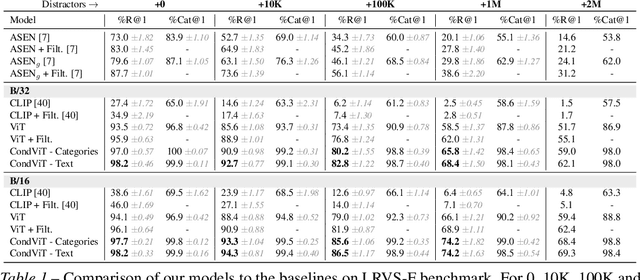
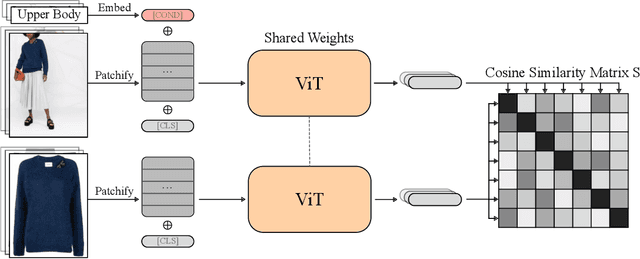

This paper presents a new approach to image similarity search in the context of fashion, a domain with inherent ambiguity due to the multiple ways in which images can be considered similar. We introduce the concept of Referred Visual Search (RVS), where users provide additional information to define the desired similarity. We present a new dataset, LAION-RVS-Fashion, consisting of 272K fashion products with 842K images extracted from LAION, designed explicitly for this task. We then propose an innovative method for learning conditional embeddings using weakly-supervised training, achieving a 6% increase in Recall at one (R@1) against a gallery with 2M distractors, compared to classical approaches based on explicit attention and filtering. The proposed method demonstrates robustness, maintaining similar R@1 when dealing with 2.5 times as many distractors as the baseline methods. We believe this is a step forward in the emerging field of Referred Visual Search both in terms of accessible data and approach. Code, data and models are available at https://www.github.com/Simon-Lepage/CondViT-LRVSF .
Input gradient diversity for neural network ensembles
Jun 05, 2023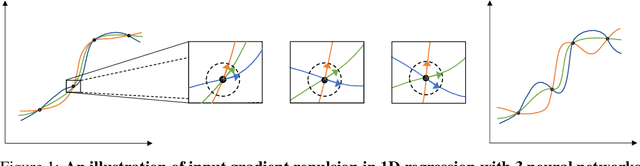


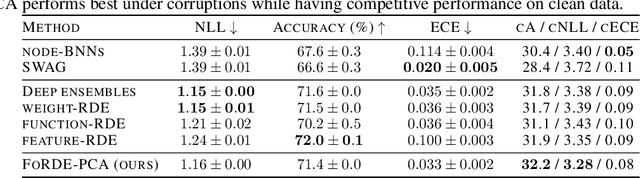
Deep Ensembles (DEs) demonstrate improved accuracy, calibration and robustness to perturbations over single neural networks partly due to their functional diversity. Particle-based variational inference (ParVI) methods enhance diversity by formalizing a repulsion term based on a network similarity kernel. However, weight-space repulsion is inefficient due to over-parameterization, while direct function-space repulsion has been found to produce little improvement over DEs. To sidestep these difficulties, we propose First-order Repulsive Deep Ensemble (FoRDE), an ensemble learning method based on ParVI, which performs repulsion in the space of first-order input gradients. As input gradients uniquely characterize a function up to translation and are much smaller in dimension than the weights, this method guarantees that ensemble members are functionally different. Intuitively, diversifying the input gradients encourages each network to learn different features, which is expected to improve the robustness of an ensemble. Experiments on image classification datasets show that FoRDE significantly outperforms the gold-standard DEs and other ensemble methods in accuracy and calibration under covariate shift due to input perturbations.
Computational 3D topographic microscopy from terabytes of data per sample
Jun 05, 2023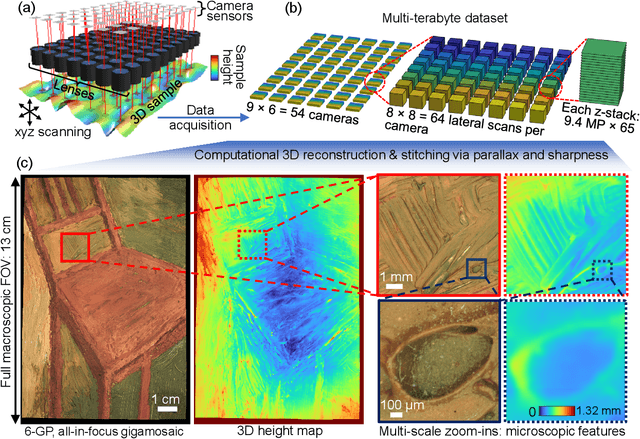

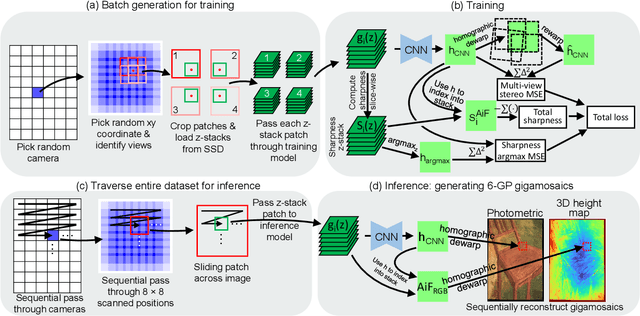
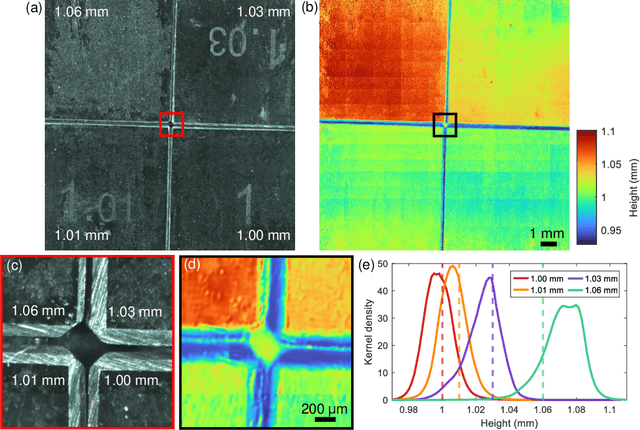
We present a large-scale computational 3D topographic microscope that enables 6-gigapixel profilometric 3D imaging at micron-scale resolution across $>$110 cm$^2$ areas over multi-millimeter axial ranges. Our computational microscope, termed STARCAM (Scanning Topographic All-in-focus Reconstruction with a Computational Array Microscope), features a parallelized, 54-camera architecture with 3-axis translation to capture, for each sample of interest, a multi-dimensional, 2.1-terabyte (TB) dataset, consisting of a total of 224,640 9.4-megapixel images. We developed a self-supervised neural network-based algorithm for 3D reconstruction and stitching that jointly estimates an all-in-focus photometric composite and 3D height map across the entire field of view, using multi-view stereo information and image sharpness as a focal metric. The memory-efficient, compressed differentiable representation offered by the neural network effectively enables joint participation of the entire multi-TB dataset during the reconstruction process. To demonstrate the broad utility of our new computational microscope, we applied STARCAM to a variety of decimeter-scale objects, with applications ranging from cultural heritage to industrial inspection.
CuNeRF: Cube-Based Neural Radiance Field for Zero-Shot Medical Image Arbitrary-Scale Super Resolution
Apr 09, 2023
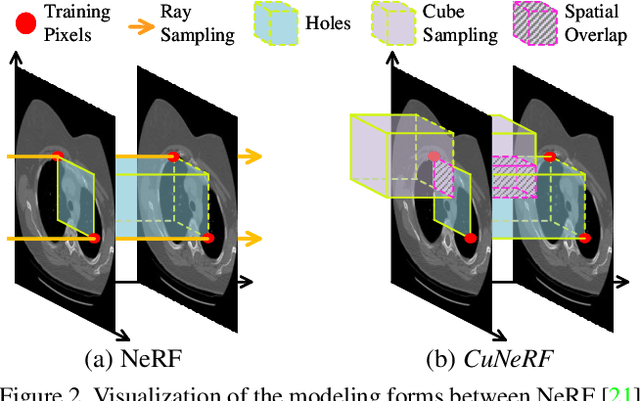


Medical image arbitrary-scale super-resolution (MIASSR) has recently gained widespread attention, aiming to super sample medical volumes at arbitrary scales via a single model. However, existing MIASSR methods face two major limitations: (i) reliance on high-resolution (HR) volumes and (ii) limited generalization ability, which restricts their application in various scenarios. To overcome these limitations, we propose Cube-based Neural Radiance Field (CuNeRF), a zero-shot MIASSR framework that can yield medical images at arbitrary scales and viewpoints in a continuous domain. Unlike existing MIASSR methods that fit the mapping between low-resolution (LR) and HR volumes, CuNeRF focuses on building a coordinate-intensity continuous representation from LR volumes without the need for HR references. This is achieved by the proposed differentiable modules: including cube-based sampling, isotropic volume rendering, and cube-based hierarchical rendering. Through extensive experiments on magnetic resource imaging (MRI) and computed tomography (CT) modalities, we demonstrate that CuNeRF outperforms state-of-the-art MIASSR methods. CuNeRF yields better visual verisimilitude and reduces aliasing artifacts at various upsampling factors. Moreover, our CuNeRF does not need any LR-HR training pairs, which is more flexible and easier to be used than others. Our code will be publicly available soon.