 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bi-parametric prostate MR image synthesis using pathology and sequence-conditioned stable diffusion
Mar 03, 2023
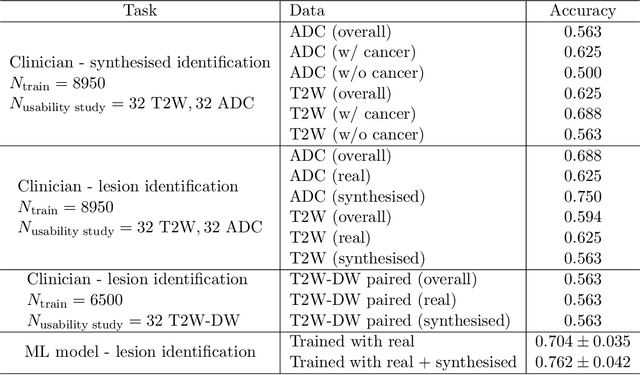

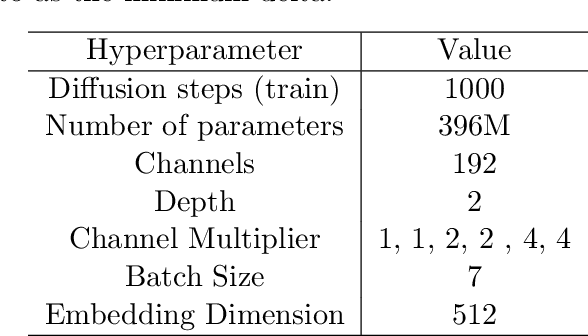
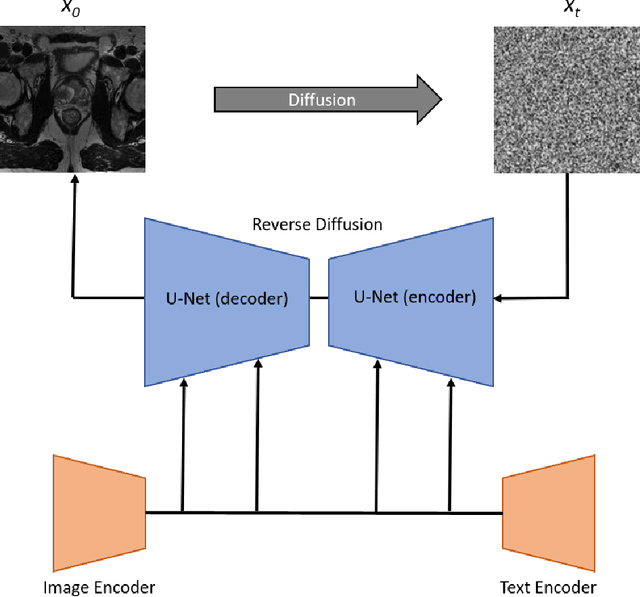
We propose an image synthesis mechanism for multi-sequence prostate MR images conditioned on text, to control lesion presence and sequence, as well as to generate paired bi-parametric images conditioned on images e.g. for generating diffusion-weighted MR from T2-weighted MR for paired data, which are two challenging tasks in pathological image synthesis. Our proposed mechanism utilises and builds upon the recent stable diffusion model by proposing image-based conditioning for paired data generation. We validate our method using 2D image slices from real suspected prostate cancer patients. The realism of the synthesised images is validated by means of a blind expert evaluation for identifying real versus fake images, where a radiologist with 4 years experience reading urological MR only achieves 59.4% accuracy across all tested sequences (where chance is 50%). For the first time, we evaluate the realism of the generated pathology by blind expert identification of the presence of suspected lesions, where we find that the clinician performs similarly for both real and synthesised images, with a 2.9 percentage point difference in lesion identification accuracy between real and synthesised images, demonstrating the potentials in radiological training purposes. Furthermore, we also show that a machine learning model, trained for lesion identification, shows better performance (76.2% vs 70.4%, statistically significant improvement) when trained with real data augmented by synthesised data as opposed to training with only real images, demonstrating usefulness for model training.
SimpleNet: A Simple Network for Image Anomaly Detection and Localization
Mar 27, 2023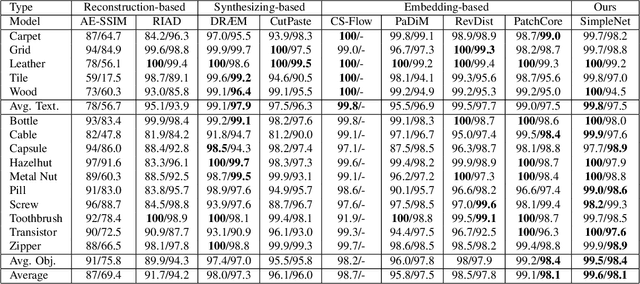
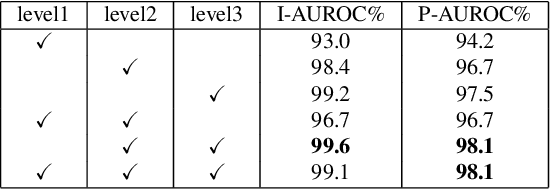
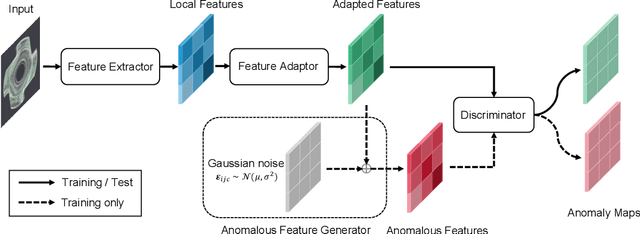

We propose a simple and application-friendly network (called SimpleNet) for detecting and localizing anomalies. SimpleNet consists of four components: (1) a pre-trained Feature Extractor that generates local features, (2) a shallow Feature Adapter that transfo local features towards target domain, (3) a simple Anomaly Feature Generator that counterfeits anomaly features by adding Gaussian noise to normal features, and (4) a binary Anomaly Discriminator that distinguishes anomaly features from normal features. During inference, the Anomaly Feature Generator would be discarded. Our approach is based on three intuitions. First, transforming pre-trained features to target-oriented features helps avoid domain bias. Second, generating synthetic anomalies in feature space is more effective, as defects may not have much commonality in the image space. Third, a simple discriminator is much efficient and practical. In spite of simplicity, SimpleNet outperforms previous methods quantitatively and qualitatively. On the MVTec AD benchmark, SimpleNet achieves an anomaly detection AUROC of 99.6%, reducing the error by 55.5% compared to the next best performing model. Furthermore, SimpleNet is faster than existing methods, with a high frame rate of 77 FPS on a 3080ti GPU. Additionally, SimpleNet demonstrates significant improvements in performance on the One-Class Novelty Detection task. Code: https://github.com/DonaldRR/SimpleNet.
Eliminating Prior Bias for Semantic Image Editing via Dual-Cycle Diffusion
Feb 07, 2023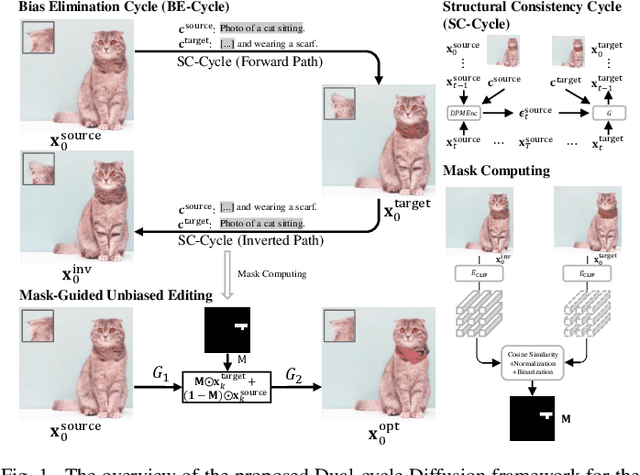
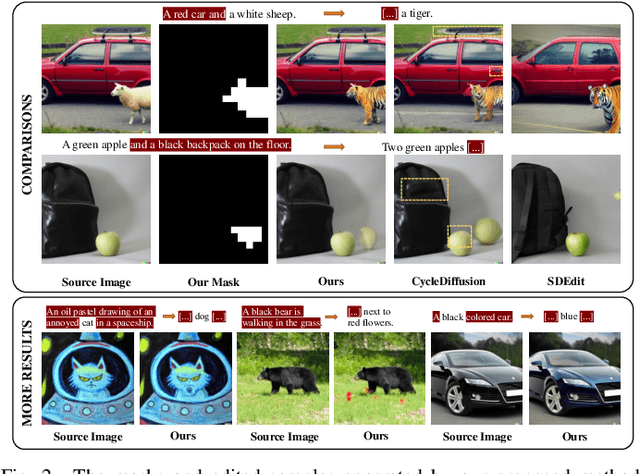

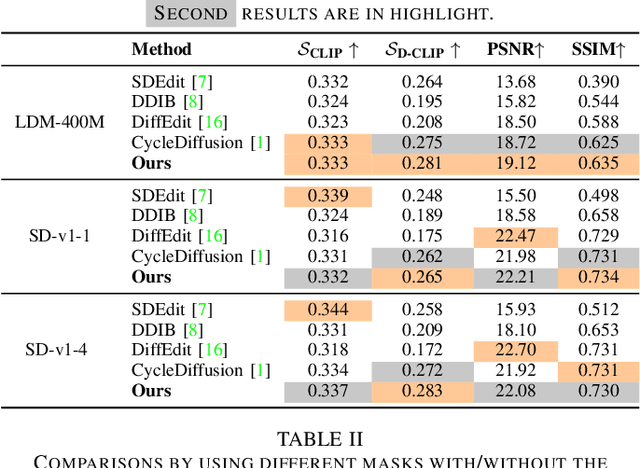
The recent success of text-to-image generation diffusion models has also revolutionized semantic image editing, enabling the manipulation of images based on query/target texts. Despite these advancements, a significant challenge lies in the potential introduction of prior bias in pre-trained models during image editing, e.g., making unexpected modifications to inappropriate regions. To this point, we present a novel Dual-Cycle Diffusion model that addresses the issue of prior bias by generating an unbiased mask as the guidance of image editing. The proposed model incorporates a Bias Elimination Cycle that consists of both a forward path and an inverted path, each featuring a Structural Consistency Cycle to ensure the preservation of image content during the editing process. The forward path utilizes the pre-trained model to produce the edited image, while the inverted path converts the result back to the source image. The unbiased mask is generated by comparing differences between the processed source image and the edited image to ensure that both conform to the same distribution. Our experiments demonstrate the effectiveness of the proposed method, as it significantly improves the D-CLIP score from 0.272 to 0.283. The code will be available at https://github.com/JohnDreamer/DualCycleDiffsion.
Towards Few-shot Entity Recognition in Document Images: A Graph Neural Network Approach Robust to Image Manipulation
May 24, 2023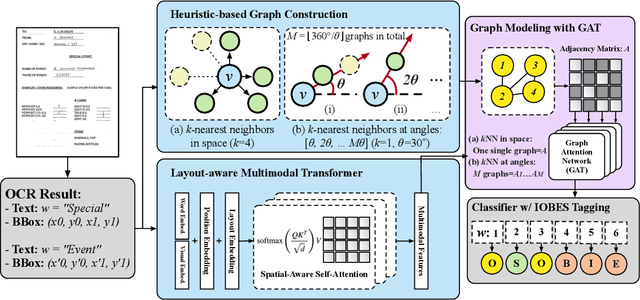

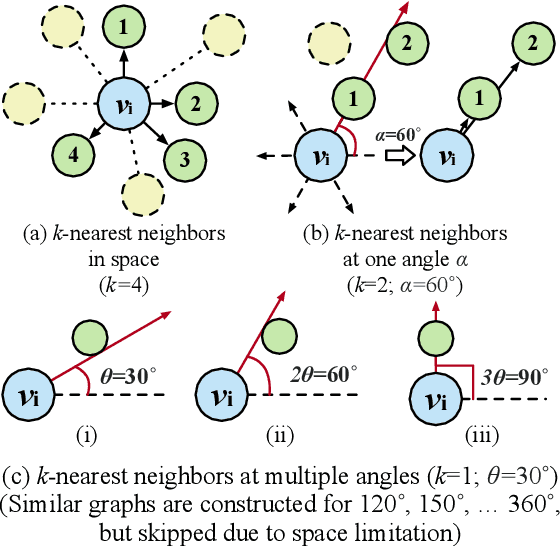
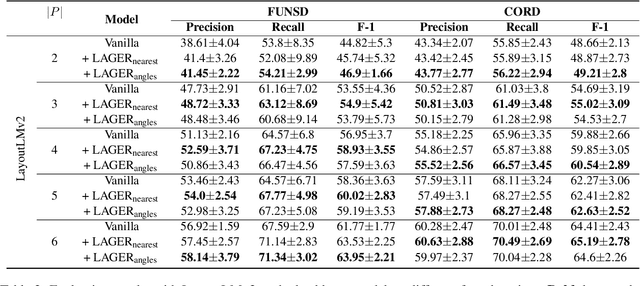
Recent advances of incorporating layout information, typically bounding box coordinates, into pre-trained language models have achieved significant performance in entity recognition from document images. Using coordinates can easily model the absolute position of each token, but they might be sensitive to manipulations in document images (e.g., shifting, rotation or scaling), especially when the training data is limited in few-shot settings. In this paper, we propose to further introduce the topological adjacency relationship among the tokens, emphasizing their relative position information. Specifically, we consider the tokens in the documents as nodes and formulate the edges based on the topological heuristics from the k-nearest bounding boxes. Such adjacency graphs are invariant to affine transformations including shifting, rotations and scaling. We incorporate these graphs into the pre-trained language model by adding graph neural network layers on top of the language model embeddings, leading to a novel model LAGER. Extensive experiments on two benchmark datasets show that LAGER significantly outperforms strong baselines under different few-shot settings and also demonstrate better robustness to manipulations.
Measuring Faithful and Plausible Visual Grounding in VQA
May 24, 2023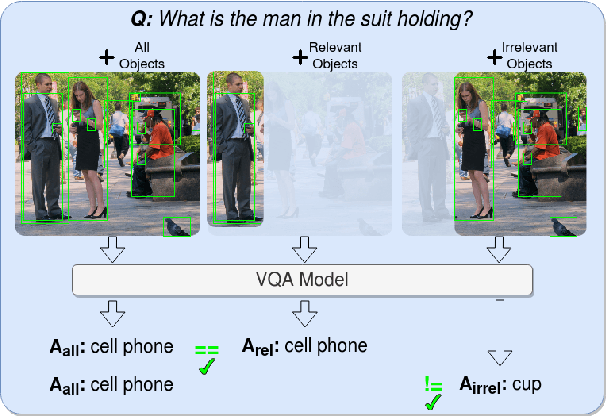

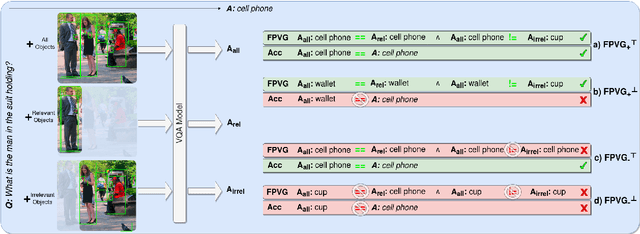
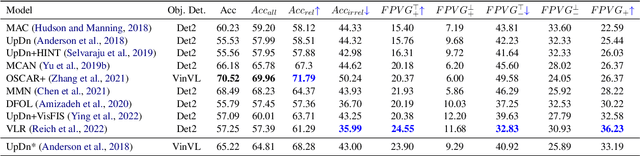
Metrics for Visual Grounding (VG) in Visual Question Answering (VQA) systems primarily aim to measure a system's reliance on relevant parts of the image when inferring an answer to the given question. Lack of VG has been a common problem among state-of-the-art VQA systems and can manifest in over-reliance on irrelevant image parts or a disregard for the visual modality entirely. Although inference capabilities of VQA models are often illustrated by a few qualitative illustrations, most systems are not quantitatively assessed for their VG properties. We believe, an easily calculated criterion for meaningfully measuring a system's VG can help remedy this shortcoming, as well as add another valuable dimension to model evaluations and analysis. To this end, we propose a new VG metric that captures if a model a) identifies question-relevant objects in the scene, and b) actually relies on the information contained in the relevant objects when producing its answer, i.e., if its visual grounding is both "faithful" and "plausible". Our metric, called "Faithful and Plausible Visual Grounding" (FPVG), is straightforward to determine for most VQA model designs. We give a detailed description of FPVG and evaluate several reference systems spanning various VQA architectures. Code to support the metric calculations on the GQA data set is available on GitHub.
DiffUTE: Universal Text Editing Diffusion Model
May 19, 2023
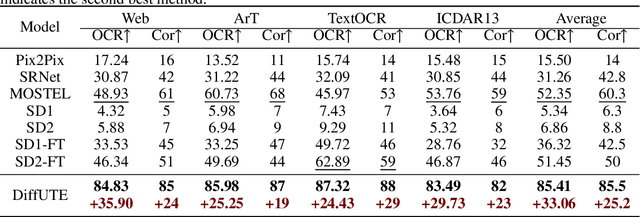
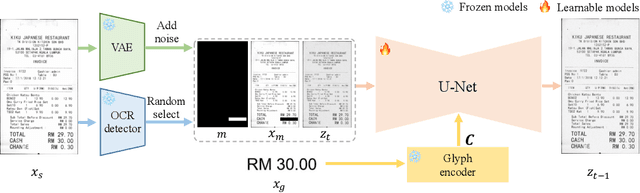
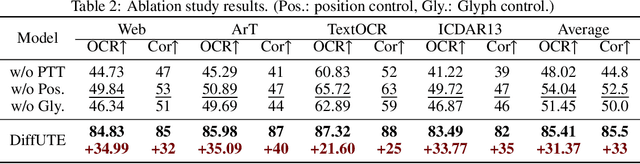
Diffusion model based language-guided image editing has achieved great success recently. However, existing state-of-the-art diffusion models struggle with rendering correct text and text style during generation. To tackle this problem, we propose a universal self-supervised text editing diffusion model (DiffUTE), which aims to replace or modify words in the source image with another one while maintaining its realistic appearance. Specifically, we build our model on a diffusion model and carefully modify the network structure to enable the model for drawing multilingual characters with the help of glyph and position information. Moreover, we design a self-supervised learning framework to leverage large amounts of web data to improve the representation ability of the model. Experimental results show that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity. Our code will be avaliable in \url{https://github.com/chenhaoxing/DiffUTE}.
Probing the Role of Positional Information in Vision-Language Models
May 17, 2023

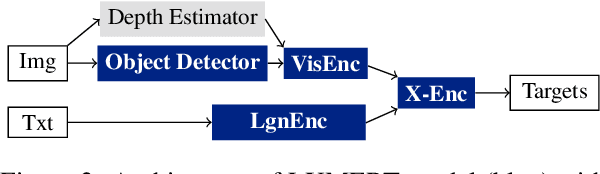
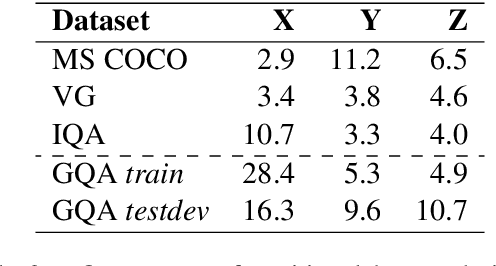
In most Vision-Language models (VL), the understanding of the image structure is enabled by injecting the position information (PI) about objects in the image. In our case study of LXMERT, a state-of-the-art VL model, we probe the use of the PI in the representation and study its effect on Visual Question Answering. We show that the model is not capable of leveraging the PI for the image-text matching task on a challenge set where only position differs. Yet, our experiments with probing confirm that the PI is indeed present in the representation. We introduce two strategies to tackle this: (i) Positional Information Pre-training and (ii) Contrastive Learning on PI using Cross-Modality Matching. Doing so, the model can correctly classify if images with detailed PI statements match. Additionally to the 2D information from bounding boxes, we introduce the object's depth as new feature for a better object localization in the space. Even though we were able to improve the model properties as defined by our probes, it only has a negligible effect on the downstream performance. Our results thus highlight an important issue of multimodal modeling: the mere presence of information detectable by a probing classifier is not a guarantee that the information is available in a cross-modal setup.
Self-supervised arbitrary scale super-resolution framework for anisotropic MRI
May 02, 2023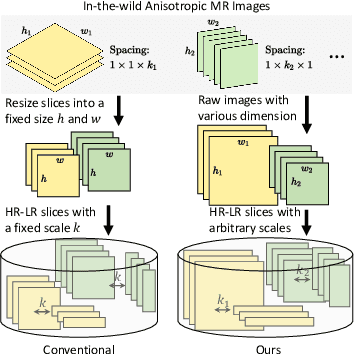
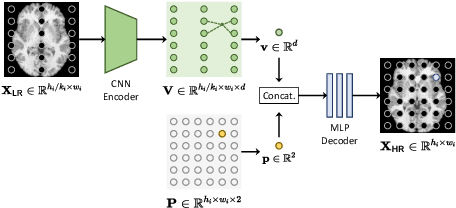
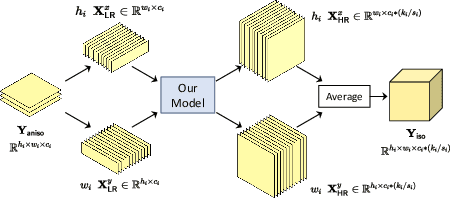
In this paper, we propose an efficient self-supervised arbitrary-scale super-resolution (SR) framework to reconstruct isotropic magnetic resonance (MR) images from anisotropic MRI inputs without involving external training data. The proposed framework builds a training dataset using in-the-wild anisotropic MR volumes with arbitrary image resolution. We then formulate the 3D volume SR task as a SR problem for 2D image slices. The anisotropic volume's high-resolution (HR) plane is used to build the HR-LR image pairs for model training. We further adapt the implicit neural representation (INR) network to implement the 2D arbitrary-scale image SR model. Finally, we leverage the well-trained proposed model to up-sample the 2D LR plane extracted from the anisotropic MR volumes to their HR views. The isotropic MR volumes thus can be reconstructed by stacking and averaging the generated HR slices. Our proposed framework has two major advantages: (1) It only involves the arbitrary-resolution anisotropic MR volumes, which greatly improves the model practicality in real MR imaging scenarios (e.g., clinical brain image acquisition); (2) The INR-based SR model enables arbitrary-scale image SR from the arbitrary-resolution input image, which significantly improves model training efficiency. We perform experiments on a simulated public adult brain dataset and a real collected 7T brain dataset. The results indicate that our current framework greatly outperforms two well-known self-supervised models for anisotropic MR image SR tasks.
GMMap: Memory-Efficient Continuous Occupancy Map Using Gaussian Mixture Model
Jun 06, 2023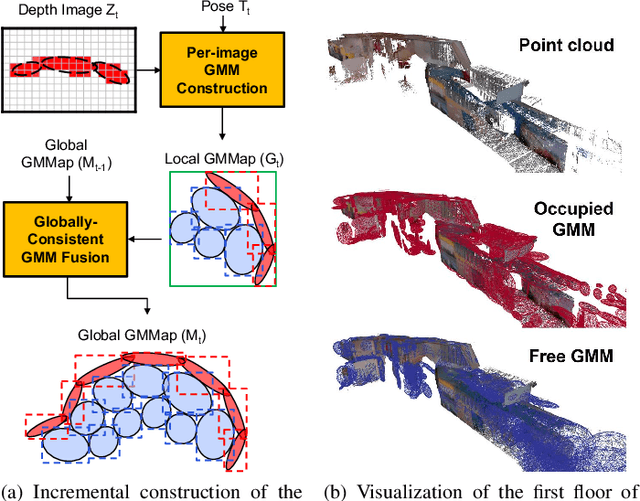

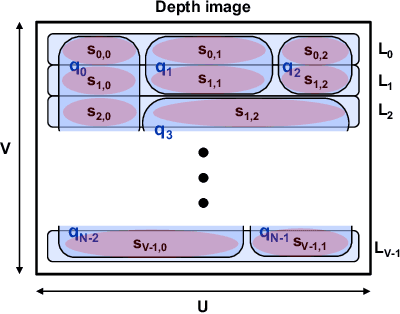
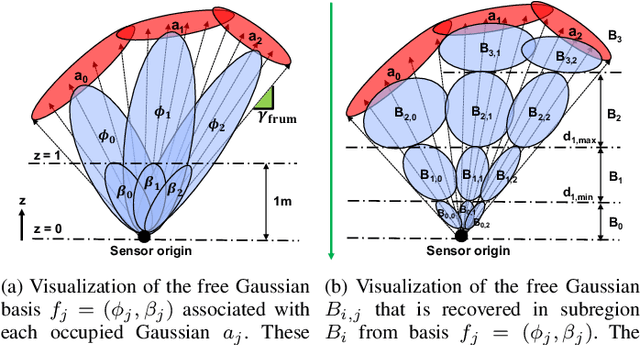
Energy consumption of memory accesses dominates the compute energy in energy-constrained robots which require a compact 3D map of the environment to achieve autonomy. Recent mapping frameworks only focused on reducing the map size while incurring significant memory usage during map construction due to multi-pass processing of each depth image. In this work, we present a memory-efficient continuous occupancy map, named GMMap, that accurately models the 3D environment using a Gaussian Mixture Model (GMM). Memory-efficient GMMap construction is enabled by the single-pass compression of depth images into local GMMs which are directly fused together into a globally-consistent map. By extending Gaussian Mixture Regression to model unexplored regions, occupancy probability is directly computed from Gaussians. Using a low-power ARM Cortex A57 CPU, GMMap can be constructed in real-time at up to 60 images per second. Compared with prior works, GMMap maintains high accuracy while reducing the map size by at least 56%, memory overhead by at least 88%, DRAM access by at least 78%, and energy consumption by at least 69%. Thus, GMMap enables real-time 3D mapping on energy-constrained robots.
VideoComposer: Compositional Video Synthesis with Motion Controllability
Jun 06, 2023
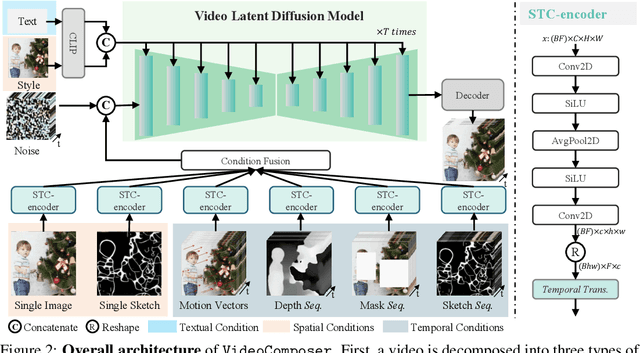


The pursuit of controllability as a higher standard of visual content creation has yielded remarkable progress in customizable image synthesis. However, achieving controllable video synthesis remains challenging due to the large variation of temporal dynamics and the requirement of cross-frame temporal consistency. Based on the paradigm of compositional generation, this work presents VideoComposer that allows users to flexibly compose a video with textual conditions, spatial conditions, and more importantly temporal conditions. Specifically, considering the characteristic of video data, we introduce the motion vector from compressed videos as an explicit control signal to provide guidance regarding temporal dynamics. In addition, we develop a Spatio-Temporal Condition encoder (STC-encoder) that serves as a unified interface to effectively incorporate the spatial and temporal relations of sequential inputs, with which the model could make better use of temporal conditions and hence achieve higher inter-frame consistency. Extensive experimental results suggest that VideoComposer is able to control the spatial and temporal patterns simultaneously within a synthesized video in various forms, such as text description, sketch sequence, reference video, or even simply hand-crafted motions. The code and models will be publicly available at https://videocomposer.github.io.