 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Soft Thresholding for Visual Image Enhancement
Jan 19, 2023

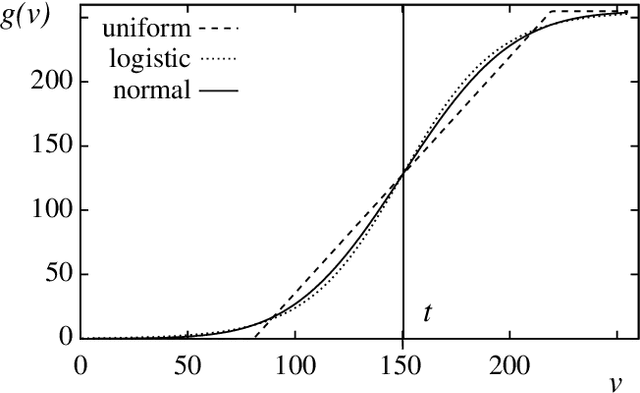
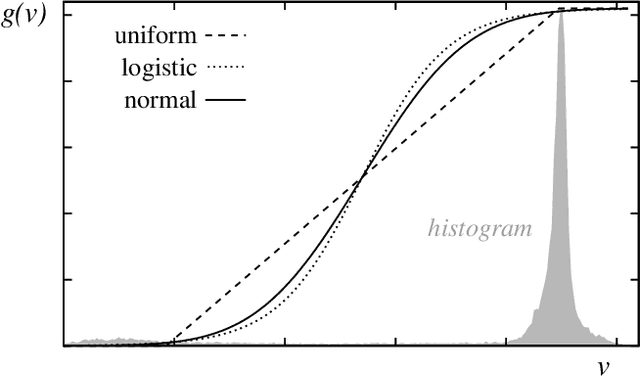

Thresholding converts a greyscale image into a binary image, and is thus often a necessary segmentation step in image processing. For a human viewer however, thresholding usually has a negative impact on the legibility of document images. This report describes a simple method for "smearing out" the threshold and transforming the greyscale image into a different greyscale image. The method is similar to fuzzy thresholding, but is discussed here in the simpler context of greyscale transformations and, unlike fuzzy thresholding, it is independent from the method for finding the threshold. A simple formula is presented for automatically determining the width of the threshold spread. The method can be used, e.g., for enhancing images for the presentation in online facsimile repositories.
Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement
Feb 23, 2023

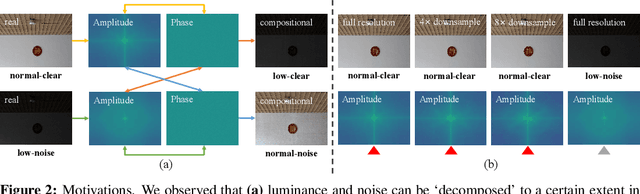
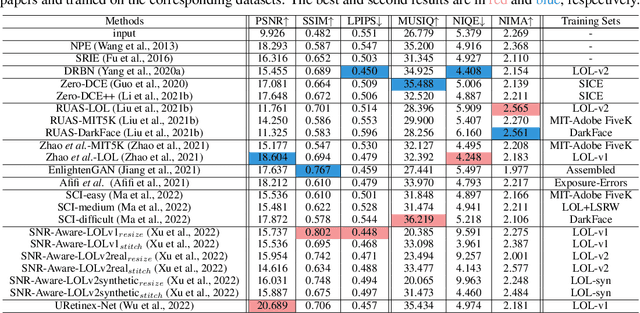
Ultra-High-Definition (UHD) photo has gradually become the standard configuration in advanced imaging devices. The new standard unveils many issues in existing approaches for low-light image enhancement (LLIE), especially in dealing with the intricate issue of joint luminance enhancement and noise removal while remaining efficient. Unlike existing methods that address the problem in the spatial domain, we propose a new solution, UHDFour, that embeds Fourier transform into a cascaded network. Our approach is motivated by a few unique characteristics in the Fourier domain: 1) most luminance information concentrates on amplitudes while noise is closely related to phases, and 2) a high-resolution image and its low-resolution version share similar amplitude patterns.Through embedding Fourier into our network, the amplitude and phase of a low-light image are separately processed to avoid amplifying noise when enhancing luminance. Besides, UHDFour is scalable to UHD images by implementing amplitude and phase enhancement under the low-resolution regime and then adjusting the high-resolution scale with few computations. We also contribute the first real UHD LLIE dataset, \textbf{UHD-LL}, that contains 2,150 low-noise/normal-clear 4K image pairs with diverse darkness and noise levels captured in different scenarios. With this dataset, we systematically analyze the performance of existing LLIE methods for processing UHD images and demonstrate the advantage of our solution. We believe our new framework, coupled with the dataset, would push the frontier of LLIE towards UHD. The code and dataset are available at https://li-chongyi.github.io/UHDFour.
* Porject page: https://li-chongyi.github.io/UHDFour
High-order Spatial Interactions Enhanced Lightweight Model for Optical Remote Sensing Image-based Small Ship Detection
Apr 07, 2023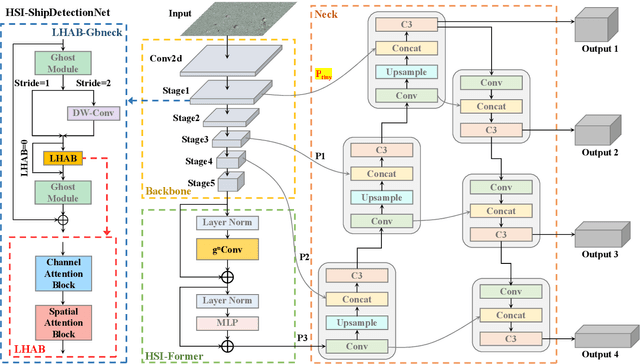
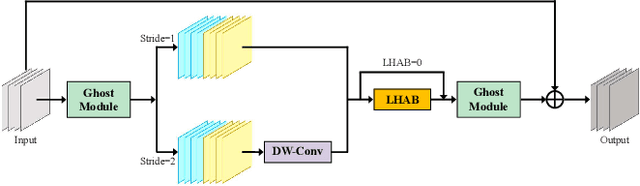
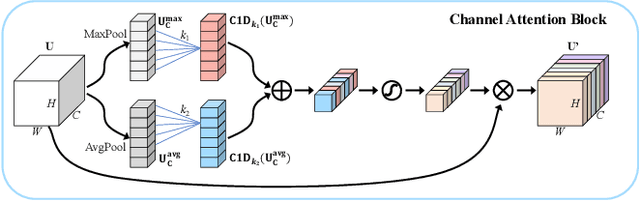
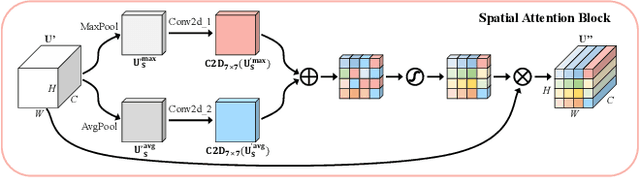
Accurate and reliable optical remote sensing image-based small-ship detection is crucial for maritime surveillance systems, but existing methods often struggle with balancing detection performance and computational complexity. In this paper, we propose a novel lightweight framework called \textit{HSI-ShipDetectionNet} that is based on high-order spatial interactions and is suitable for deployment on resource-limited platforms, such as satellites and unmanned aerial vehicles. HSI-ShipDetectionNet includes a prediction branch specifically for tiny ships and a lightweight hybrid attention block for reduced complexity. Additionally, the use of a high-order spatial interactions module improves advanced feature understanding and modeling ability. Our model is evaluated using the public Kaggle marine ship detection dataset and compared with multiple state-of-the-art models including small object detection models, lightweight detection models, and ship detection models. The results show that HSI-ShipDetectionNet outperforms the other models in terms of recall, and mean average precision (mAP) while being lightweight and suitable for deployment on resource-limited platforms.
Towards Few-shot Entity Recognition in Document Images: A Graph Neural Network Approach Robust to Image Manipulation
May 24, 2023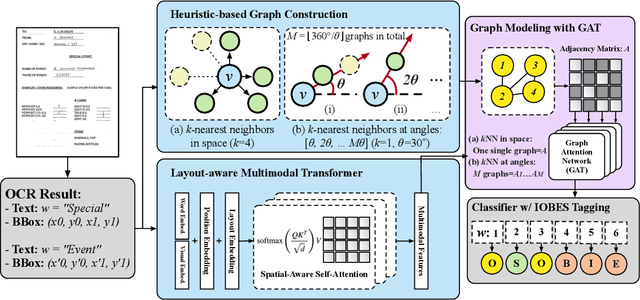

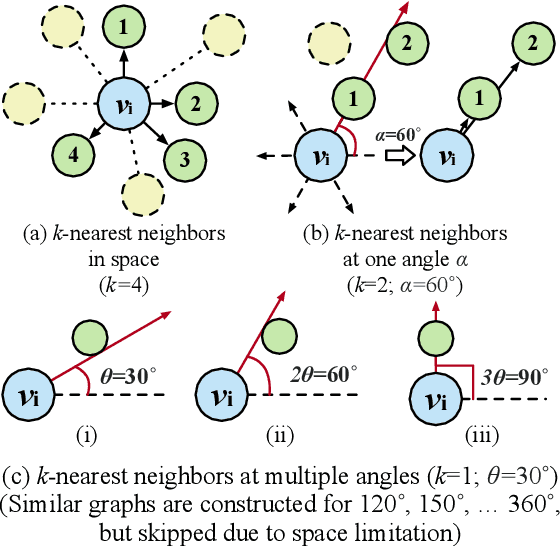
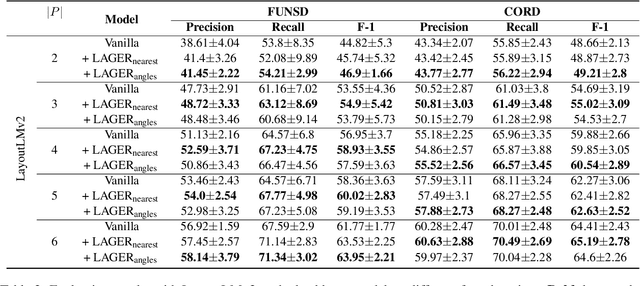
Recent advances of incorporating layout information, typically bounding box coordinates, into pre-trained language models have achieved significant performance in entity recognition from document images. Using coordinates can easily model the absolute position of each token, but they might be sensitive to manipulations in document images (e.g., shifting, rotation or scaling), especially when the training data is limited in few-shot settings. In this paper, we propose to further introduce the topological adjacency relationship among the tokens, emphasizing their relative position information. Specifically, we consider the tokens in the documents as nodes and formulate the edges based on the topological heuristics from the k-nearest bounding boxes. Such adjacency graphs are invariant to affine transformations including shifting, rotations and scaling. We incorporate these graphs into the pre-trained language model by adding graph neural network layers on top of the language model embeddings, leading to a novel model LAGER. Extensive experiments on two benchmark datasets show that LAGER significantly outperforms strong baselines under different few-shot settings and also demonstrate better robustness to manipulations.
Operational Neural Networks for Efficient Hyperspectral Single-Image Super-Resolution
Mar 29, 2023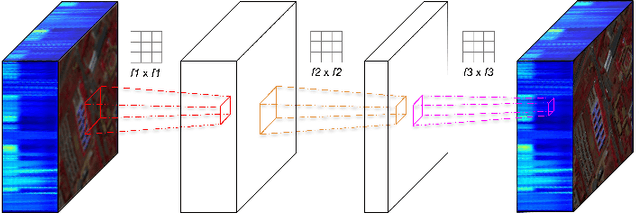
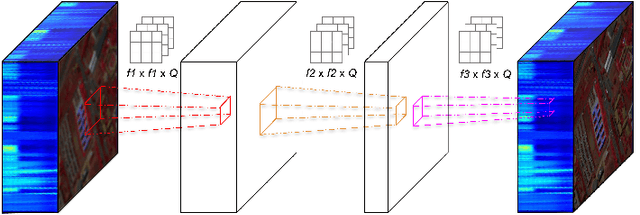
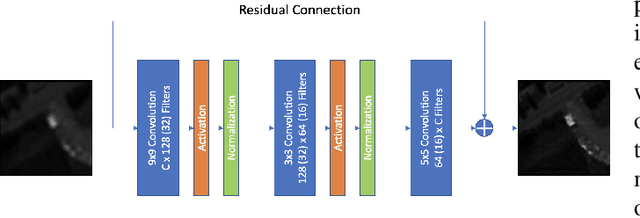

Hyperspectral Imaging is a crucial tool in remote sensing which captures far more spectral information than standard color images. However, the increase in spectral information comes at the cost of spatial resolution. Super-resolution is a popular technique where the goal is to generate a high-resolution version of a given low-resolution input. The majority of modern super-resolution approaches use convolutional neural networks. However, convolution itself is a linear operation and the networks rely on the non-linear activation functions after each layer to provide the necessary non-linearity to learn the complex underlying function. This means that convolutional neural networks tend to be very deep to achieve the desired results. Recently, self-organized operational neural networks have been proposed that aim to overcome this limitation by replacing the convolutional filters with learnable non-linear functions through the use of MacLaurin series expansions. This work focuses on extending the convolutional filters of a popular super-resolution model to more powerful operational filters to enhance the model performance on hyperspectral images. We also investigate the effects that residual connections and different normalization types have on this type of enhanced network. Despite having fewer parameters than their convolutional network equivalents, our results show that operational neural networks achieve superior super-resolution performance on small hyperspectral image datasets.
Fine-grained Cross-modal Fusion based Refinement for Text-to-Image Synthesis
Feb 20, 2023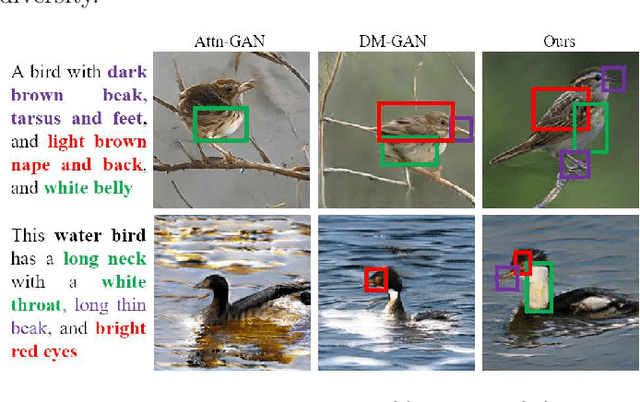
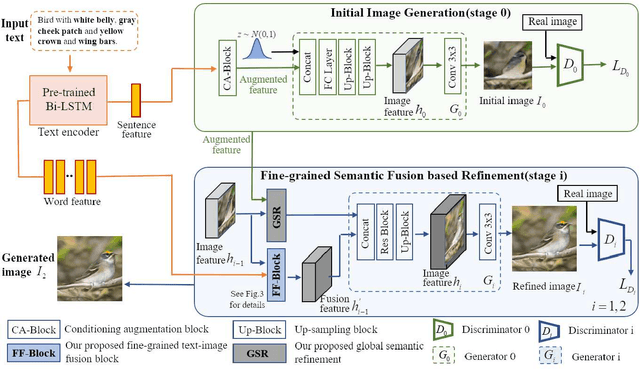
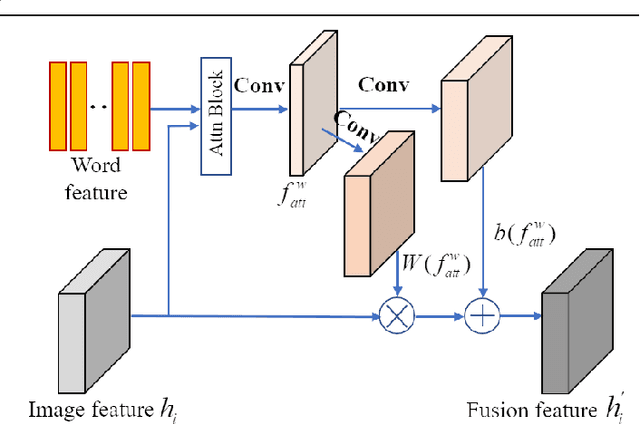

Text-to-image synthesis refers to generating visual-realistic and semantically consistent images from given textual descriptions. Previous approaches generate an initial low-resolution image and then refine it to be high-resolution. Despite the remarkable progress, these methods are limited in fully utilizing the given texts and could generate text-mismatched images, especially when the text description is complex. We propose a novel Fine-grained text-image Fusion based Generative Adversarial Networks, dubbed FF-GAN, which consists of two modules: Fine-grained text-image Fusion Block (FF-Block) and Global Semantic Refinement (GSR). The proposed FF-Block integrates an attention block and several convolution layers to effectively fuse the fine-grained word-context features into the corresponding visual features, in which the text information is fully used to refine the initial image with more details. And the GSR is proposed to improve the global semantic consistency between linguistic and visual features during the refinement process. Extensive experiments on CUB-200 and COCO datasets demonstrate the superiority of FF-GAN over other state-of-the-art approaches in generating images with semantic consistency to the given texts.Code is available at https://github.com/haoranhfut/FF-GAN.
Measuring Faithful and Plausible Visual Grounding in VQA
May 24, 2023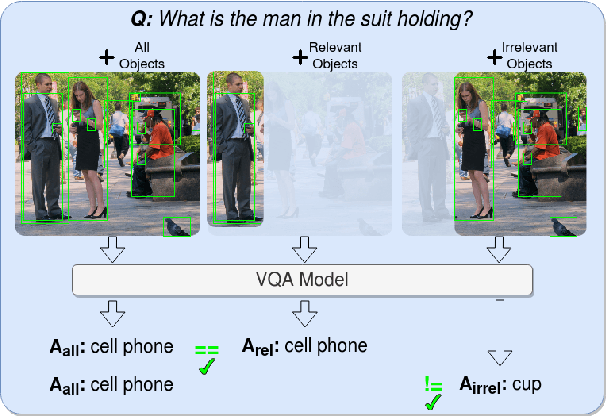

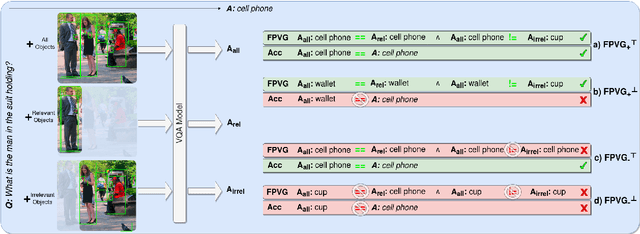
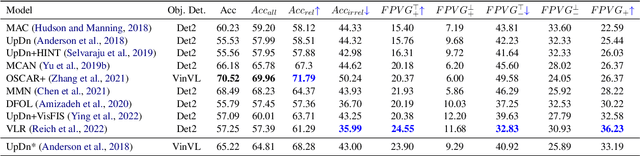
Metrics for Visual Grounding (VG) in Visual Question Answering (VQA) systems primarily aim to measure a system's reliance on relevant parts of the image when inferring an answer to the given question. Lack of VG has been a common problem among state-of-the-art VQA systems and can manifest in over-reliance on irrelevant image parts or a disregard for the visual modality entirely. Although inference capabilities of VQA models are often illustrated by a few qualitative illustrations, most systems are not quantitatively assessed for their VG properties. We believe, an easily calculated criterion for meaningfully measuring a system's VG can help remedy this shortcoming, as well as add another valuable dimension to model evaluations and analysis. To this end, we propose a new VG metric that captures if a model a) identifies question-relevant objects in the scene, and b) actually relies on the information contained in the relevant objects when producing its answer, i.e., if its visual grounding is both "faithful" and "plausible". Our metric, called "Faithful and Plausible Visual Grounding" (FPVG), is straightforward to determine for most VQA model designs. We give a detailed description of FPVG and evaluate several reference systems spanning various VQA architectures. Code to support the metric calculations on the GQA data set is available on GitHub.
Comprehensive Comparisons of Uniform Quantization in Deep Image Compression
Mar 01, 2023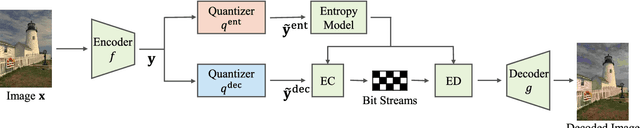

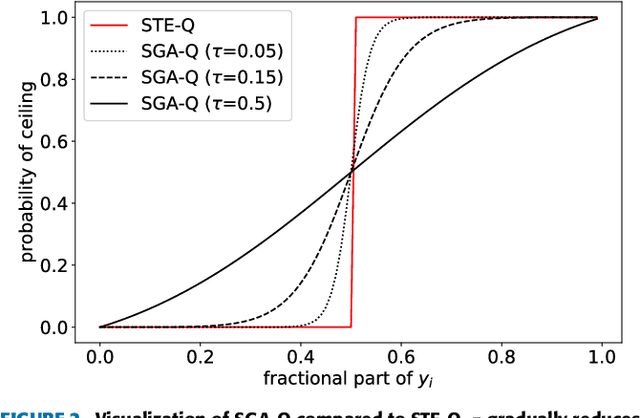

In deep image compression, uniform quantization is applied to latent representations obtained by using an auto-encoder architecture for reducing bits and entropy coding. Quantization is a problem encountered in the end-to-end training of deep image compression. Quantization's gradient is zero, and it cannot backpropagate meaningful gradients. Many methods have been proposed to address the approximations of quantization to obtain gradients. However, there have not been equitable comparisons among them. In this study, we comprehensively compare the existing approximations of uniform quantization. Furthermore, we evaluate possible combinations of quantizers for the decoder and the entropy model, as the approximated quantizers can be different for them. We conduct experiments using three network architectures on two test datasets. The experimental results reveal that the best approximated quantization differs by the network architectures, and the best approximations of the three are different from the original ones used for the architectures. We also show that the combination of quantizers that uses universal quantization for the entropy model and differentiable soft quantization for the decoder is a comparatively good choice for different architectures and datasets.
DiffUTE: Universal Text Editing Diffusion Model
May 19, 2023
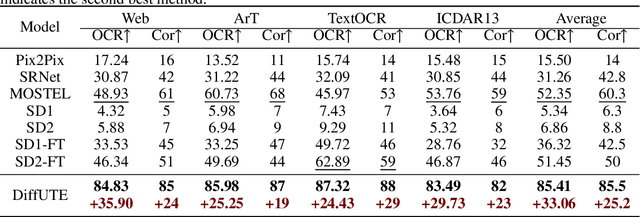
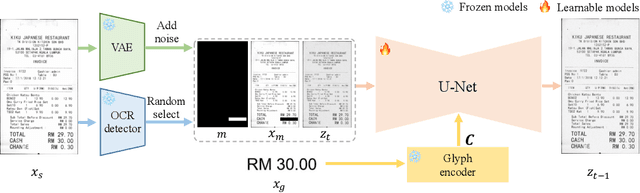
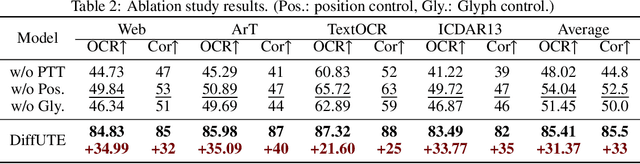
Diffusion model based language-guided image editing has achieved great success recently. However, existing state-of-the-art diffusion models struggle with rendering correct text and text style during generation. To tackle this problem, we propose a universal self-supervised text editing diffusion model (DiffUTE), which aims to replace or modify words in the source image with another one while maintaining its realistic appearance. Specifically, we build our model on a diffusion model and carefully modify the network structure to enable the model for drawing multilingual characters with the help of glyph and position information. Moreover, we design a self-supervised learning framework to leverage large amounts of web data to improve the representation ability of the model. Experimental results show that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity. Our code will be avaliable in \url{https://github.com/chenhaoxing/DiffUTE}.
Spatially-Adaptive Feature Modulation for Efficient Image Super-Resolution
Feb 27, 2023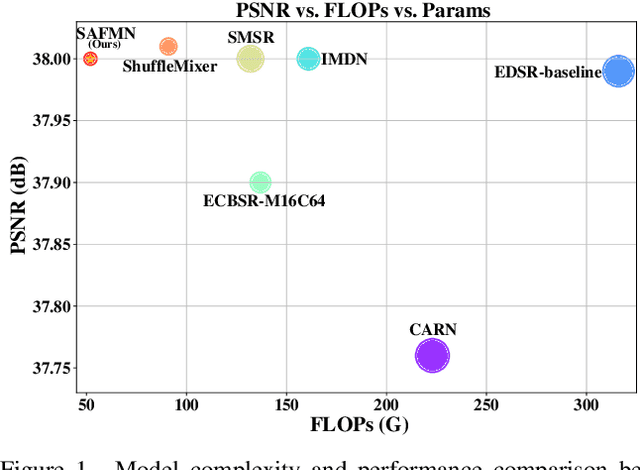

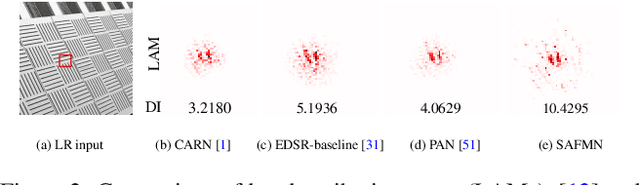

Although numerous solutions have been proposed for image super-resolution, they are usually incompatible with low-power devices with many computational and memory constraints. In this paper, we address this problem by proposing a simple yet effective deep network to solve image super-resolution efficiently. In detail, we develop a spatially-adaptive feature modulation (SAFM) mechanism upon a vision transformer (ViT)-like block. Within it, we first apply the SAFM block over input features to dynamically select representative feature representations. As the SAFM block processes the input features from a long-range perspective, we further introduce a convolutional channel mixer (CCM) to simultaneously extract local contextual information and perform channel mixing. Extensive experimental results show that the proposed method is $3\times$ smaller than state-of-the-art efficient SR methods, e.g., IMDN, in terms of the network parameters and requires less computational cost while achieving comparable performance. The code is available at https://github.com/sunny2109/SAFMN.