 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAM3D: Zero-Shot 3D Object Detection via Segment Anything Model
Jun 04, 2023
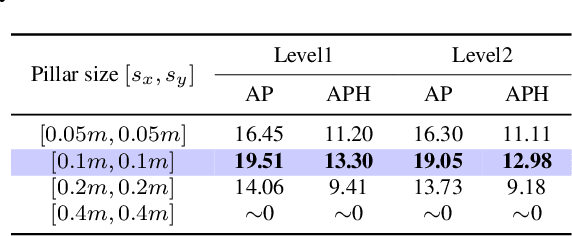
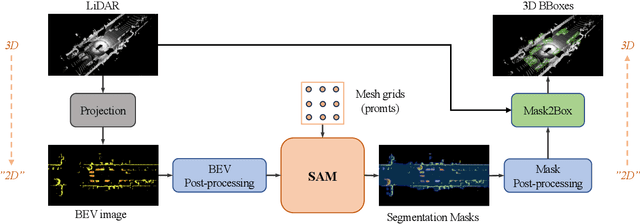


With the development of large language models, many remarkable linguistic systems like ChatGPT have thrived and achieved astonishing success on many tasks, showing the incredible power of foundation models. In the spirit of unleashing the capability of foundation models on vision tasks, the Segment Anything Model (SAM), a vision foundation model for image segmentation, has been proposed recently and presents strong zero-shot ability on many downstream 2D tasks. However, whether SAM can be adapted to 3D vision tasks has yet to be explored, especially 3D object detection. With this inspiration, we explore adapting the zero-shot ability of SAM to 3D object detection in this paper. We propose a SAM-powered BEV processing pipeline to detect objects and get promising results on the large-scale Waymo open dataset. As an early attempt, our method takes a step toward 3D object detection with vision foundation models and presents the opportunity to unleash their power on 3D vision tasks. The code is released at https://github.com/DYZhang09/SAM3D.
Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement
Feb 23, 2023

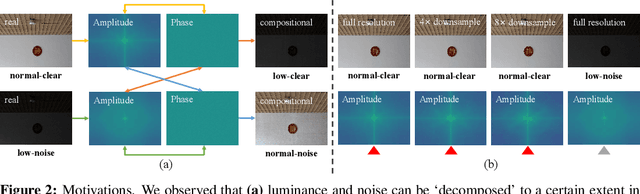
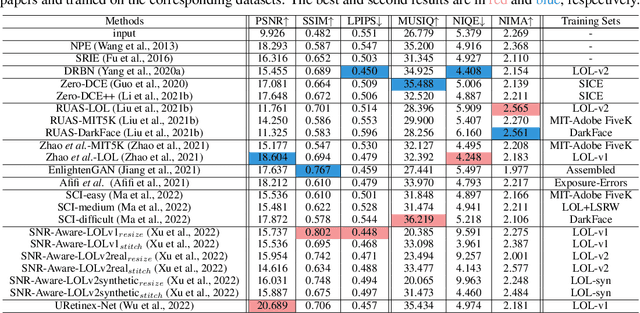
Ultra-High-Definition (UHD) photo has gradually become the standard configuration in advanced imaging devices. The new standard unveils many issues in existing approaches for low-light image enhancement (LLIE), especially in dealing with the intricate issue of joint luminance enhancement and noise removal while remaining efficient. Unlike existing methods that address the problem in the spatial domain, we propose a new solution, UHDFour, that embeds Fourier transform into a cascaded network. Our approach is motivated by a few unique characteristics in the Fourier domain: 1) most luminance information concentrates on amplitudes while noise is closely related to phases, and 2) a high-resolution image and its low-resolution version share similar amplitude patterns.Through embedding Fourier into our network, the amplitude and phase of a low-light image are separately processed to avoid amplifying noise when enhancing luminance. Besides, UHDFour is scalable to UHD images by implementing amplitude and phase enhancement under the low-resolution regime and then adjusting the high-resolution scale with few computations. We also contribute the first real UHD LLIE dataset, \textbf{UHD-LL}, that contains 2,150 low-noise/normal-clear 4K image pairs with diverse darkness and noise levels captured in different scenarios. With this dataset, we systematically analyze the performance of existing LLIE methods for processing UHD images and demonstrate the advantage of our solution. We believe our new framework, coupled with the dataset, would push the frontier of LLIE towards UHD. The code and dataset are available at https://li-chongyi.github.io/UHDFour.
* Porject page: https://li-chongyi.github.io/UHDFour
Fashionpedia-Taste: A Dataset towards Explaining Human Fashion Taste
May 03, 2023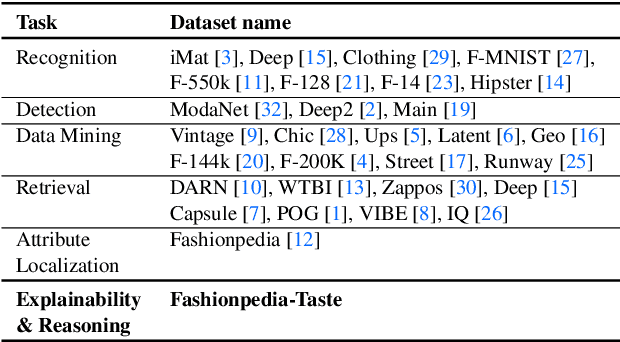
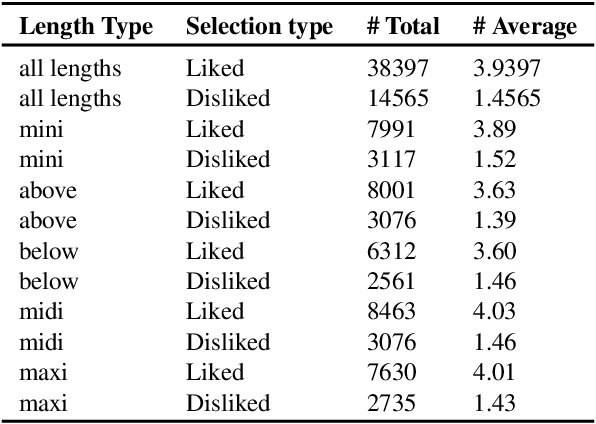

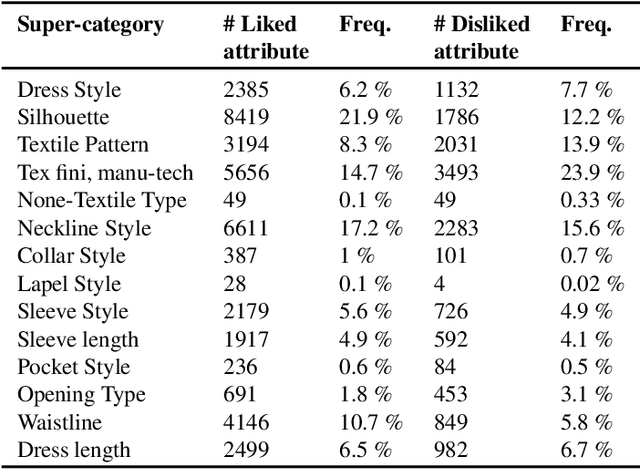
Existing fashion datasets do not consider the multi-facts that cause a consumer to like or dislike a fashion image. Even two consumers like a same fashion image, they could like this image for total different reasons. In this paper, we study the reason why a consumer like a certain fashion image. Towards this goal, we introduce an interpretability dataset, Fashionpedia-taste, consist of rich annotation to explain why a subject like or dislike a fashion image from the following 3 perspectives: 1) localized attributes; 2) human attention; 3) caption. Furthermore, subjects are asked to provide their personal attributes and preference on fashion, such as personality and preferred fashion brands. Our dataset makes it possible for researchers to build computational models to fully understand and interpret human fashion taste from different humanistic perspectives and modalities.
Better "CMOS" Produces Clearer Images: Learning Space-Variant Blur Estimation for Blind Image Super-Resolution
Apr 07, 2023
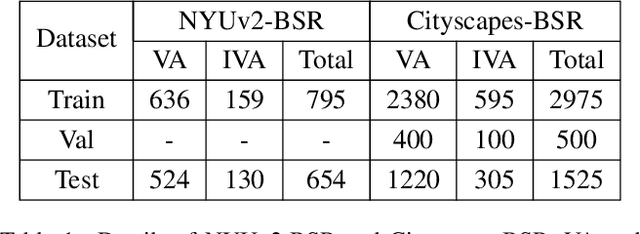

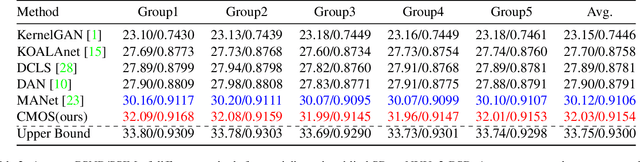
Most of the existing blind image Super-Resolution (SR) methods assume that the blur kernels are space-invariant. However, the blur involved in real applications are usually space-variant due to object motion, out-of-focus, etc., resulting in severe performance drop of the advanced SR methods. To address this problem, we firstly introduce two new datasets with out-of-focus blur, i.e., NYUv2-BSR and Cityscapes-BSR, to support further researches of blind SR with space-variant blur. Based on the datasets, we design a novel Cross-MOdal fuSion network (CMOS) that estimate both blur and semantics simultaneously, which leads to improved SR results. It involves a feature Grouping Interactive Attention (GIA) module to make the two modalities interact more effectively and avoid inconsistency. GIA can also be used for the interaction of other features because of the universality of its structure. Qualitative and quantitative experiments compared with state-of-the-art methods on above datasets and real-world images demonstrate the superiority of our method, e.g., obtaining PSNR/SSIM by +1.91/+0.0048 on NYUv2-BSR than MANet.
Context-TAP: Tracking Any Point Demands Spatial Context Features
Jun 03, 2023
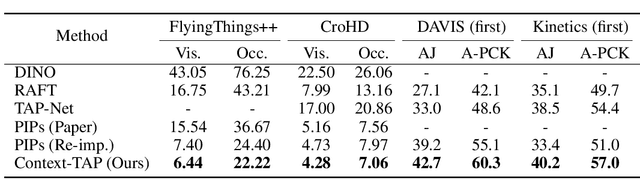
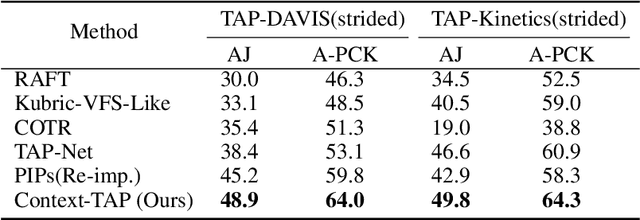

We tackle the problem of Tracking Any Point (TAP) in videos, which specifically aims at estimating persistent long-term trajectories of query points in videos. Previous methods attempted to estimate these trajectories independently to incorporate longer image sequences, therefore, ignoring the potential benefits of incorporating spatial context features. We argue that independent video point tracking also demands spatial context features. To this end, we propose a novel framework Context-TAP, which effectively improves point trajectory accuracy by aggregating spatial context features in videos. Context-TAP contains two main modules: 1) a SOurse Feature Enhancement (SOFE) module, and 2) a TArget Feature Aggregation (TAFA) module. Context-TAP significantly improves PIPs all-sided, reducing 11.4% Average Trajectory Error of Occluded Points (ATE-Occ) on CroHD and increasing 11.8% Average Percentage of Correct Keypoint (A-PCK) on TAP-Vid-Kinectics. Demos are available at this $\href{https://wkbian.github.io/Projects/Context-TAP/}{webpage}$.
Spatially-Adaptive Feature Modulation for Efficient Image Super-Resolution
Feb 27, 2023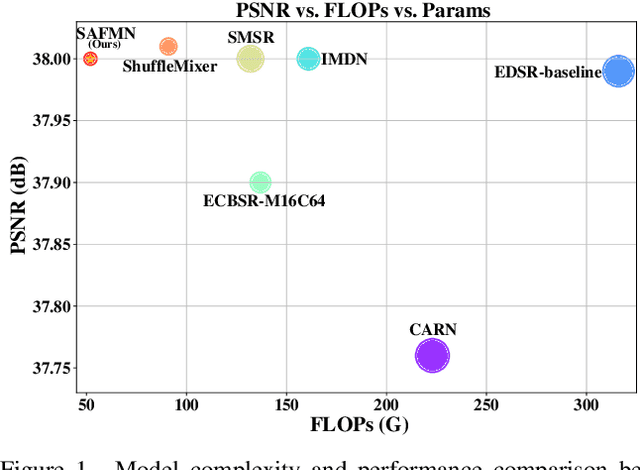

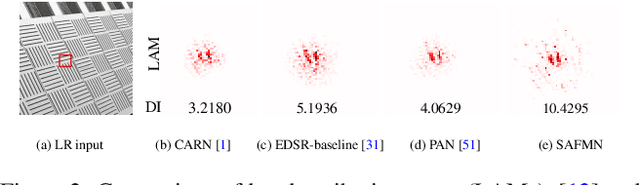

Although numerous solutions have been proposed for image super-resolution, they are usually incompatible with low-power devices with many computational and memory constraints. In this paper, we address this problem by proposing a simple yet effective deep network to solve image super-resolution efficiently. In detail, we develop a spatially-adaptive feature modulation (SAFM) mechanism upon a vision transformer (ViT)-like block. Within it, we first apply the SAFM block over input features to dynamically select representative feature representations. As the SAFM block processes the input features from a long-range perspective, we further introduce a convolutional channel mixer (CCM) to simultaneously extract local contextual information and perform channel mixing. Extensive experimental results show that the proposed method is $3\times$ smaller than state-of-the-art efficient SR methods, e.g., IMDN, in terms of the network parameters and requires less computational cost while achieving comparable performance. The code is available at https://github.com/sunny2109/SAFMN.
Comprehensive Comparisons of Uniform Quantization in Deep Image Compression
Mar 01, 2023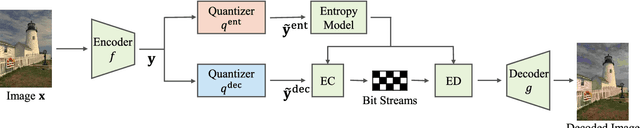

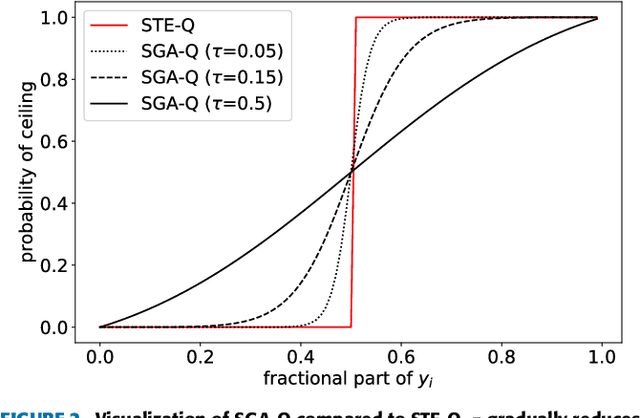

In deep image compression, uniform quantization is applied to latent representations obtained by using an auto-encoder architecture for reducing bits and entropy coding. Quantization is a problem encountered in the end-to-end training of deep image compression. Quantization's gradient is zero, and it cannot backpropagate meaningful gradients. Many methods have been proposed to address the approximations of quantization to obtain gradients. However, there have not been equitable comparisons among them. In this study, we comprehensively compare the existing approximations of uniform quantization. Furthermore, we evaluate possible combinations of quantizers for the decoder and the entropy model, as the approximated quantizers can be different for them. We conduct experiments using three network architectures on two test datasets. The experimental results reveal that the best approximated quantization differs by the network architectures, and the best approximations of the three are different from the original ones used for the architectures. We also show that the combination of quantizers that uses universal quantization for the entropy model and differentiable soft quantization for the decoder is a comparatively good choice for different architectures and datasets.
Image Restoration with Mean-Reverting Stochastic Differential Equations
Jan 30, 2023
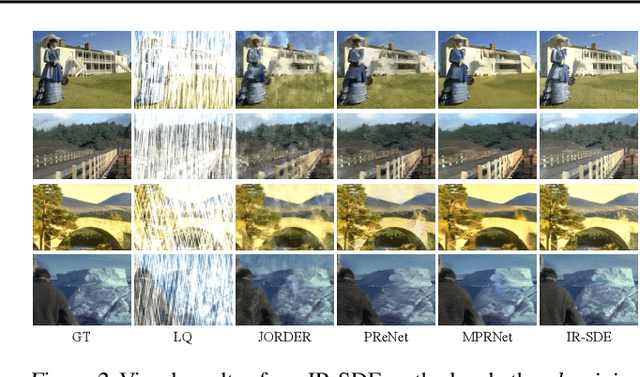
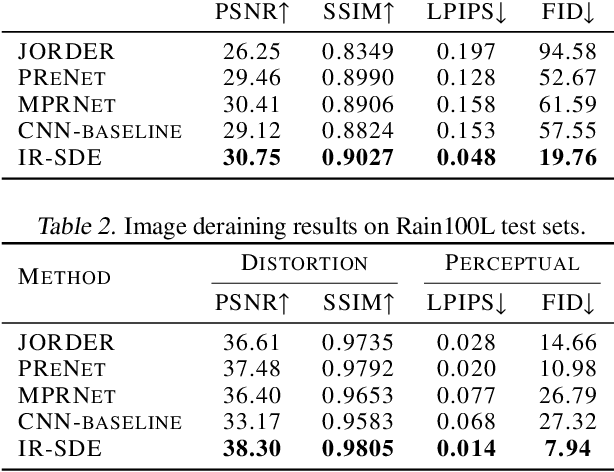
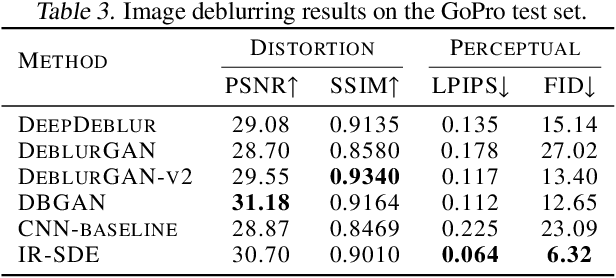
This paper presents a stochastic differential equation (SDE) approach for general-purpose image restoration. The key construction consists in a mean-reverting SDE that transforms a high-quality image into a degraded counterpart as a mean state with fixed Gaussian noise. Then, by simulating the corresponding reverse-time SDE, we are able to restore the origin of the low-quality image without relying on any task-specific prior knowledge. Crucially, the proposed mean-reverting SDE has a closed-form solution, allowing us to compute the ground truth time-dependent score and learn it with a neural network. Moreover, we propose a maximum likelihood objective to learn an optimal reverse trajectory which stabilizes the training and improves the restoration results. In the experiments, we show that our proposed method achieves highly competitive performance in quantitative comparisons on image deraining, deblurring, and denoising, setting a new state-of-the-art on two deraining datasets. Finally, the general applicability of our approach is further demonstrated via qualitative results on image super-resolution, inpainting, and dehazing. Code is available at https://github.com/Algolzw/image-restoration-sde.
Parallel Sampling of Diffusion Models
Jun 08, 2023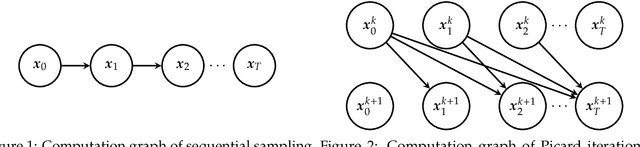



Diffusion models are powerful generative models but suffer from slow sampling, often taking 1000 sequential denoising steps for one sample. As a result, considerable efforts have been directed toward reducing the number of denoising steps, but these methods hurt sample quality. Instead of reducing the number of denoising steps (trading quality for speed), in this paper we explore an orthogonal approach: can we run the denoising steps in parallel (trading compute for speed)? In spite of the sequential nature of the denoising steps, we show that surprisingly it is possible to parallelize sampling via Picard iterations, by guessing the solution of future denoising steps and iteratively refining until convergence. With this insight, we present ParaDiGMS, a novel method to accelerate the sampling of pretrained diffusion models by denoising multiple steps in parallel. ParaDiGMS is the first diffusion sampling method that enables trading compute for speed and is even compatible with existing fast sampling techniques such as DDIM and DPMSolver. Using ParaDiGMS, we improve sampling speed by 2-4x across a range of robotics and image generation models, giving state-of-the-art sampling speeds of 0.2s on 100-step DiffusionPolicy and 16s on 1000-step StableDiffusion-v2 with no measurable degradation of task reward, FID score, or CLIP score.
FlowFormer: A Transformer Architecture and Its Masked Cost Volume Autoencoding for Optical Flow
Jun 08, 2023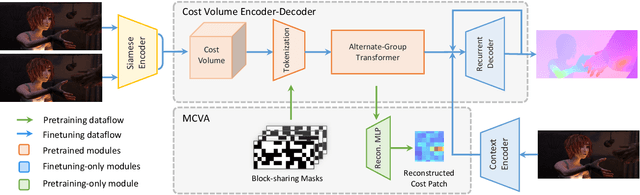
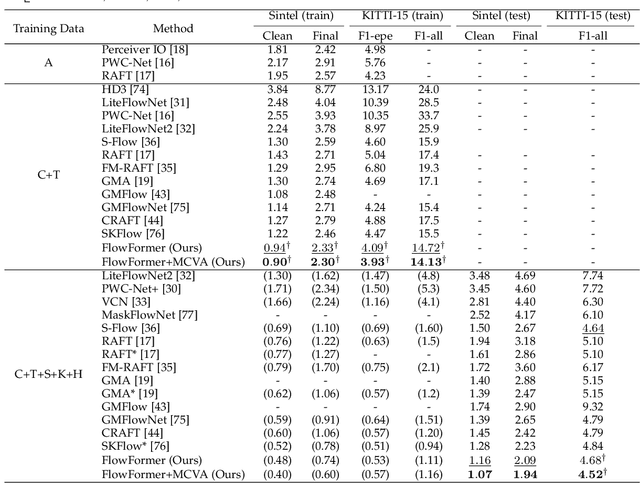
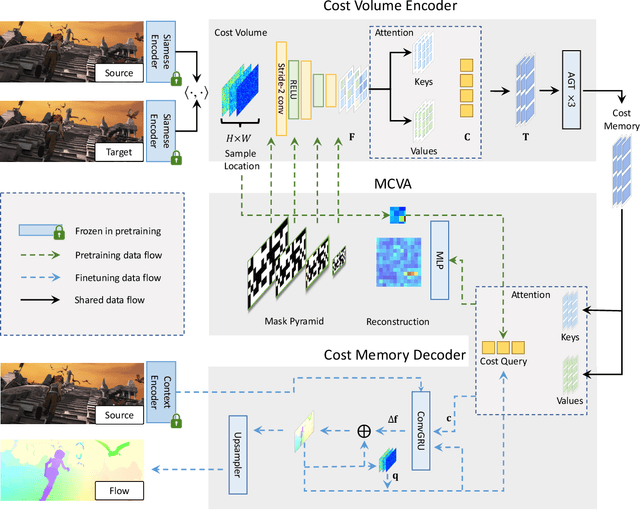
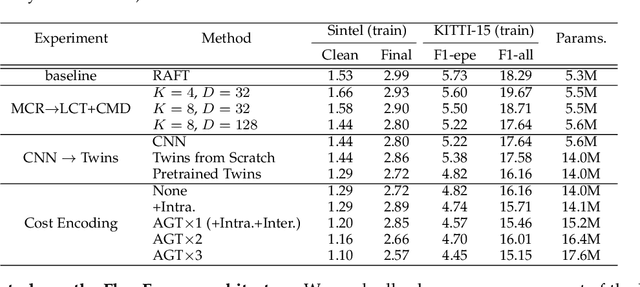
This paper introduces a novel transformer-based network architecture, FlowFormer, along with the Masked Cost Volume AutoEncoding (MCVA) for pretraining it to tackle the problem of optical flow estimation. FlowFormer tokenizes the 4D cost-volume built from the source-target image pair and iteratively refines flow estimation with a cost-volume encoder-decoder architecture. The cost-volume encoder derives a cost memory with alternate-group transformer~(AGT) layers in a latent space and the decoder recurrently decodes flow from the cost memory with dynamic positional cost queries. On the Sintel benchmark, FlowFormer architecture achieves 1.16 and 2.09 average end-point-error~(AEPE) on the clean and final pass, a 16.5\% and 15.5\% error reduction from the GMA~(1.388 and 2.47). MCVA enhances FlowFormer by pretraining the cost-volume encoder with a masked autoencoding scheme, which further unleashes the capability of FlowFormer with unlabeled data. This is especially critical in optical flow estimation because ground truth flows are more expensive to acquire than labels in other vision tasks. MCVA improves FlowFormer all-sided and FlowFormer+MCVA ranks 1st among all published methods on both Sintel and KITTI-2015 benchmarks and achieves the best generalization performance. Specifically, FlowFormer+MCVA achieves 1.07 and 1.94 AEPE on the Sintel benchmark, leading to 7.76\% and 7.18\% error reductions from FlowFormer.