 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-source adversarial transfer learning based on similar source domains with local features
May 30, 2023
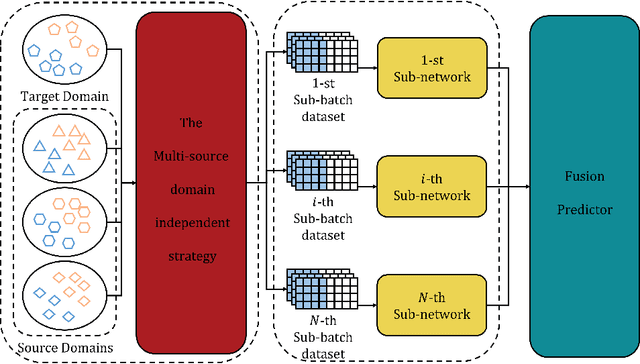

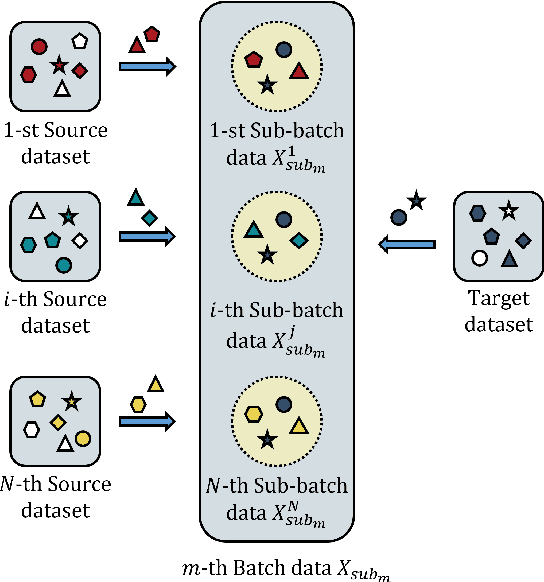
Transfer learning leverages knowledge from other domains and has been successful in many applications. Transfer learning methods rely on the overall similarity of the source and target domains. However, in some cases, it is impossible to provide an overall similar source domain, and only some source domains with similar local features can be provided. Can transfer learning be achieved? In this regard, we propose a multi-source adversarial transfer learning method based on local feature similarity to the source domain to handle transfer scenarios where the source and target domains have only local similarities. This method extracts transferable local features between a single source domain and the target domain through a sub-network. Specifically, the feature extractor of the sub-network is induced by the domain discriminator to learn transferable knowledge between the source domain and the target domain. The extracted features are then weighted by an attention module to suppress non-transferable local features while enhancing transferable local features. In order to ensure that the data from the target domain in different sub-networks in the same batch is exactly the same, we designed a multi-source domain independent strategy to provide the possibility for later local feature fusion to complete the key features required. In order to verify the effectiveness of the method, we made the dataset "Local Carvana Image Masking Dataset". Applying the proposed method to the image segmentation task of the proposed dataset achieves better transfer performance than other multi-source transfer learning methods. It is shown that the designed transfer learning method is feasible for transfer scenarios where the source and target domains have only local similarities.
Better "CMOS" Produces Clearer Images: Learning Space-Variant Blur Estimation for Blind Image Super-Resolution
Apr 07, 2023
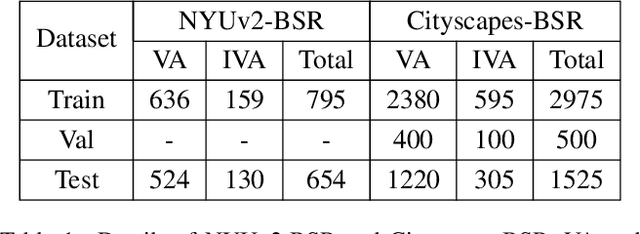

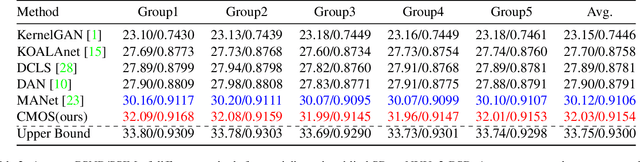
Most of the existing blind image Super-Resolution (SR) methods assume that the blur kernels are space-invariant. However, the blur involved in real applications are usually space-variant due to object motion, out-of-focus, etc., resulting in severe performance drop of the advanced SR methods. To address this problem, we firstly introduce two new datasets with out-of-focus blur, i.e., NYUv2-BSR and Cityscapes-BSR, to support further researches of blind SR with space-variant blur. Based on the datasets, we design a novel Cross-MOdal fuSion network (CMOS) that estimate both blur and semantics simultaneously, which leads to improved SR results. It involves a feature Grouping Interactive Attention (GIA) module to make the two modalities interact more effectively and avoid inconsistency. GIA can also be used for the interaction of other features because of the universality of its structure. Qualitative and quantitative experiments compared with state-of-the-art methods on above datasets and real-world images demonstrate the superiority of our method, e.g., obtaining PSNR/SSIM by +1.91/+0.0048 on NYUv2-BSR than MANet.
Bi-parametric prostate MR image synthesis using pathology and sequence-conditioned stable diffusion
Mar 03, 2023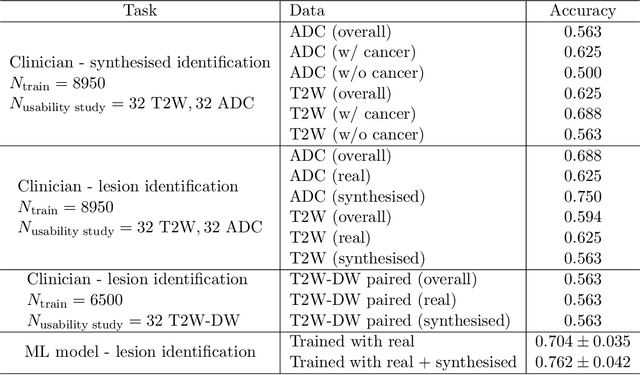

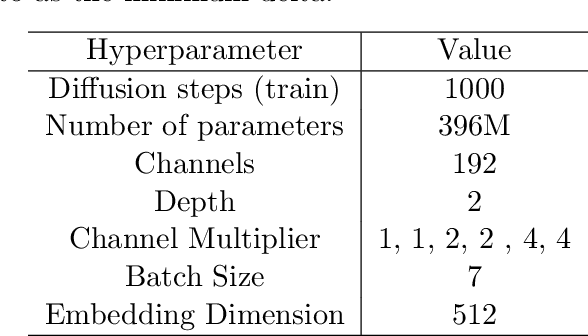
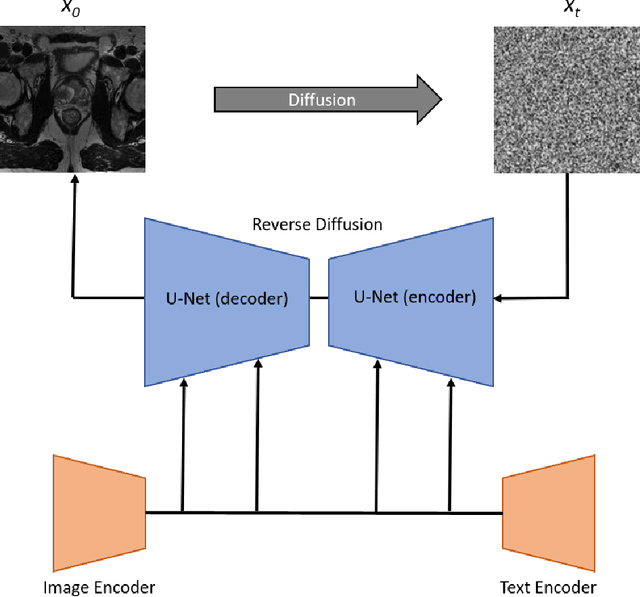
We propose an image synthesis mechanism for multi-sequence prostate MR images conditioned on text, to control lesion presence and sequence, as well as to generate paired bi-parametric images conditioned on images e.g. for generating diffusion-weighted MR from T2-weighted MR for paired data, which are two challenging tasks in pathological image synthesis. Our proposed mechanism utilises and builds upon the recent stable diffusion model by proposing image-based conditioning for paired data generation. We validate our method using 2D image slices from real suspected prostate cancer patients. The realism of the synthesised images is validated by means of a blind expert evaluation for identifying real versus fake images, where a radiologist with 4 years experience reading urological MR only achieves 59.4% accuracy across all tested sequences (where chance is 50%). For the first time, we evaluate the realism of the generated pathology by blind expert identification of the presence of suspected lesions, where we find that the clinician performs similarly for both real and synthesised images, with a 2.9 percentage point difference in lesion identification accuracy between real and synthesised images, demonstrating the potentials in radiological training purposes. Furthermore, we also show that a machine learning model, trained for lesion identification, shows better performance (76.2% vs 70.4%, statistically significant improvement) when trained with real data augmented by synthesised data as opposed to training with only real images, demonstrating usefulness for model training.
Interpretable and Explainable Logical Policies via Neurally Guided Symbolic Abstraction
Jun 02, 2023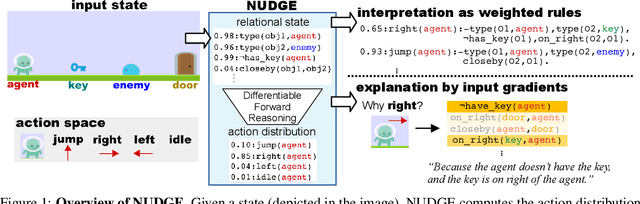
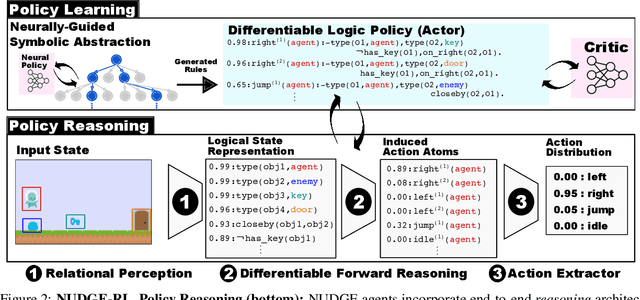
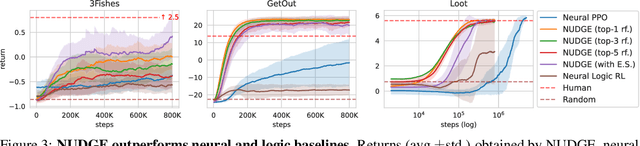

The limited priors required by neural networks make them the dominating choice to encode and learn policies using reinforcement learning (RL). However, they are also black-boxes, making it hard to understand the agent's behaviour, especially when working on the image level. Therefore, neuro-symbolic RL aims at creating policies that are interpretable in the first place. Unfortunately, interpretability is not explainability. To achieve both, we introduce Neurally gUided Differentiable loGic policiEs (NUDGE). NUDGE exploits trained neural network-based agents to guide the search of candidate-weighted logic rules, then uses differentiable logic to train the logic agents. Our experimental evaluation demonstrates that NUDGE agents can induce interpretable and explainable policies while outperforming purely neural ones and showing good flexibility to environments of different initial states and problem sizes.
Generative Autoencoders as Watermark Attackers: Analyses of Vulnerabilities and Threats
Jun 02, 2023
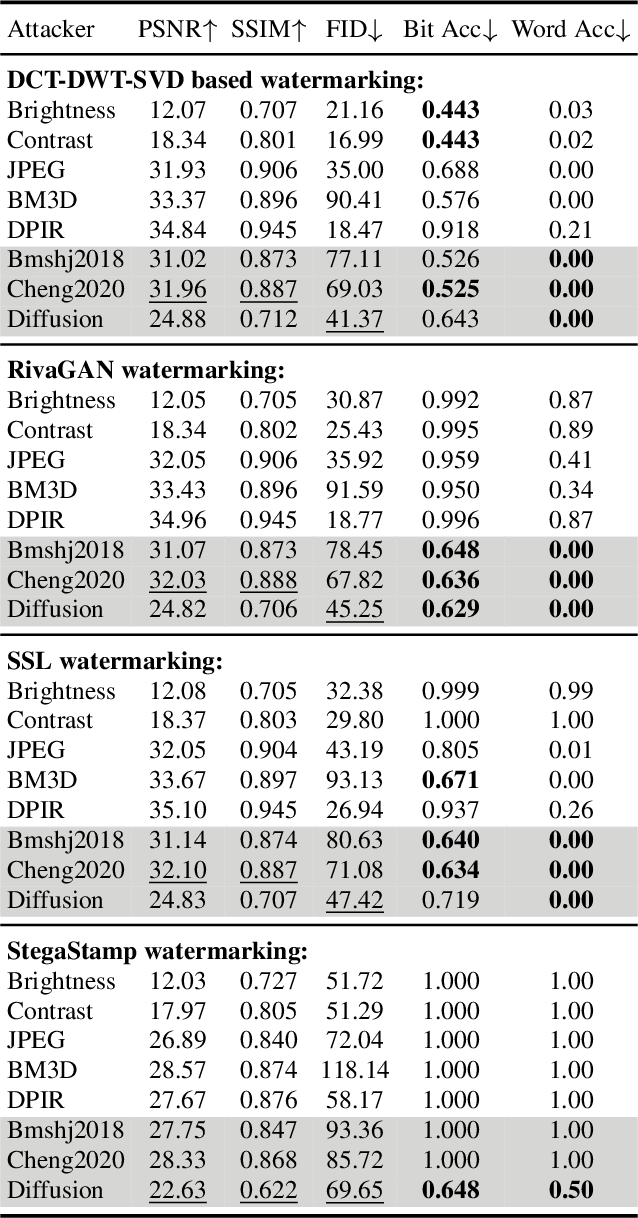
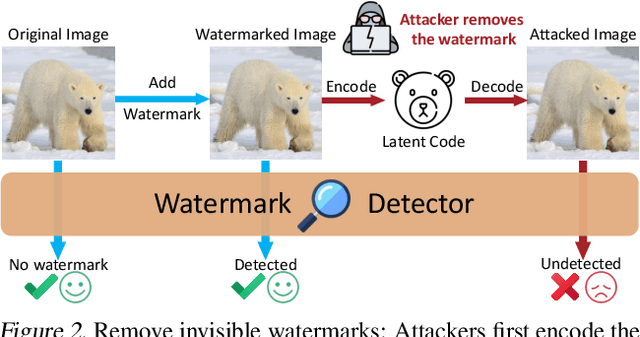
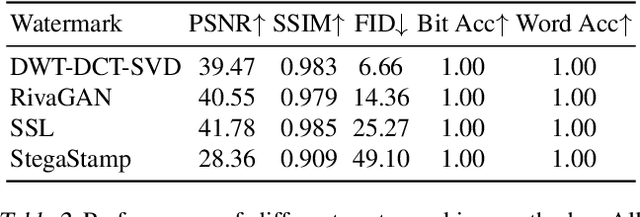
Invisible watermarks safeguard images' copyrights by embedding hidden messages detectable by owners. It also prevents people from misusing images, especially those generated by AI models. Malicious adversaries can violate these rights by removing the watermarks. In order to remove watermarks without damaging the visual quality, the adversary needs to erase them while retaining the essential information in the image. This is analogous to the encoding and decoding process of generative autoencoders, especially variational autoencoders (VAEs) and diffusion models. We propose a framework using generative autoencoders to remove invisible watermarks and test it using VAEs and diffusions. Our results reveal that, even without specific training, off-the-shelf Stable Diffusion effectively removes most watermarks, surpassing all current attackers. The result underscores the vulnerabilities in existing watermarking schemes and calls for more robust methods for copyright protection.
A Data-Driven Measure of Relative Uncertainty for Misclassification Detection
Jun 02, 2023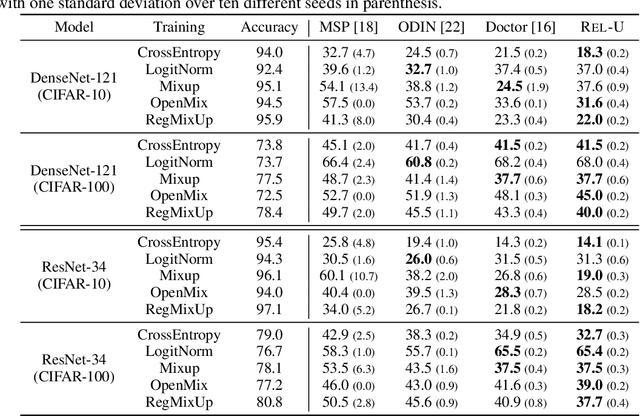
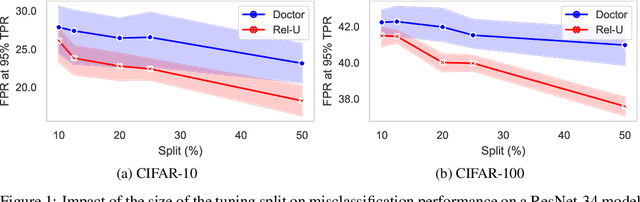
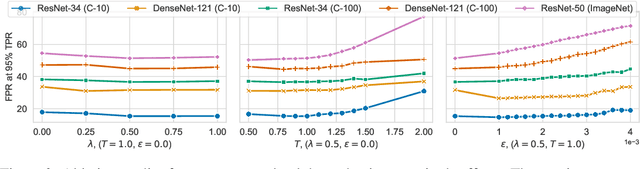
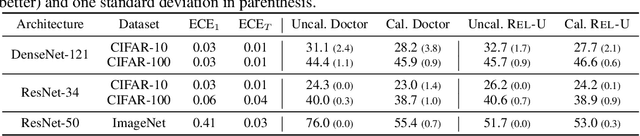
Misclassification detection is an important problem in machine learning, as it allows for the identification of instances where the model's predictions are unreliable. However, conventional uncertainty measures such as Shannon entropy do not provide an effective way to infer the real uncertainty associated with the model's predictions. In this paper, we introduce a novel data-driven measure of relative uncertainty to an observer for misclassification detection. By learning patterns in the distribution of soft-predictions, our uncertainty measure can identify misclassified samples based on the predicted class probabilities. Interestingly, according to the proposed measure, soft-predictions that correspond to misclassified instances can carry a large amount of uncertainty, even though they may have low Shannon entropy. We demonstrate empirical improvements over multiple image classification tasks, outperforming state-of-the-art misclassification detection methods.
UniControl: A Unified Diffusion Model for Controllable Visual Generation In the Wild
May 18, 2023
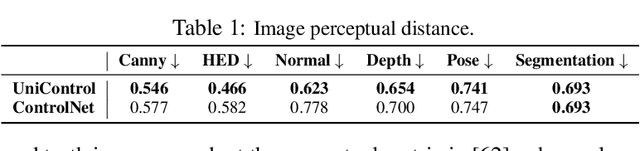
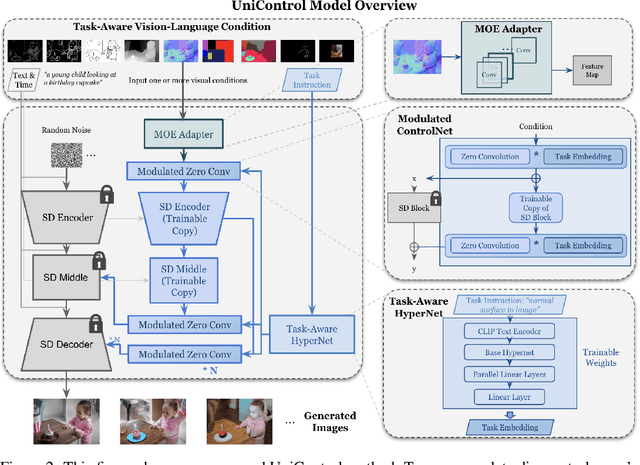

Achieving machine autonomy and human control often represent divergent objectives in the design of interactive AI systems. Visual generative foundation models such as Stable Diffusion show promise in navigating these goals, especially when prompted with arbitrary languages. However, they often fall short in generating images with spatial, structural, or geometric controls. The integration of such controls, which can accommodate various visual conditions in a single unified model, remains an unaddressed challenge. In response, we introduce UniControl, a new generative foundation model that consolidates a wide array of controllable condition-to-image (C2I) tasks within a singular framework, while still allowing for arbitrary language prompts. UniControl enables pixel-level-precise image generation, where visual conditions primarily influence the generated structures and language prompts guide the style and context. To equip UniControl with the capacity to handle diverse visual conditions, we augment pretrained text-to-image diffusion models and introduce a task-aware HyperNet to modulate the diffusion models, enabling the adaptation to different C2I tasks simultaneously. Trained on nine unique C2I tasks, UniControl demonstrates impressive zero-shot generation abilities with unseen visual conditions. Experimental results show that UniControl often surpasses the performance of single-task-controlled methods of comparable model sizes. This control versatility positions UniControl as a significant advancement in the realm of controllable visual generation.
OpenShape: Scaling Up 3D Shape Representation Towards Open-World Understanding
May 18, 2023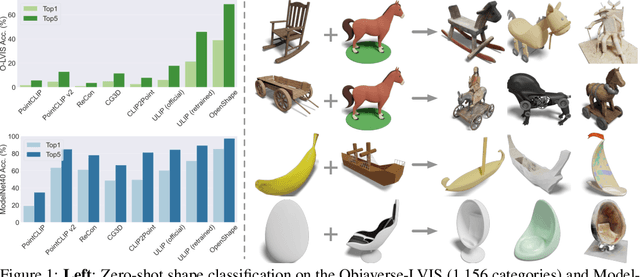
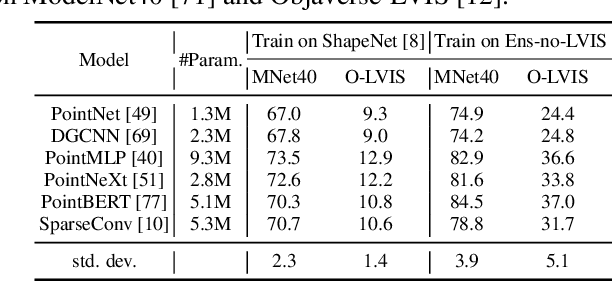
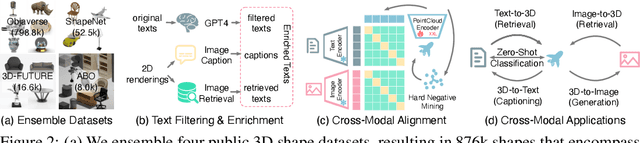
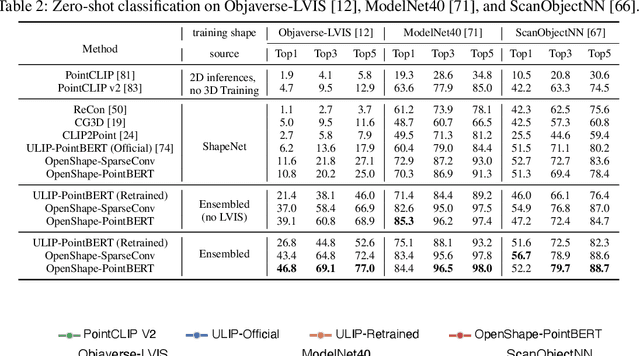
We introduce OpenShape, a method for learning multi-modal joint representations of text, image, and point clouds. We adopt the commonly used multi-modal contrastive learning framework for representation alignment, but with a specific focus on scaling up 3D representations to enable open-world 3D shape understanding. To achieve this, we scale up training data by ensembling multiple 3D datasets and propose several strategies to automatically filter and enrich noisy text descriptions. We also explore and compare strategies for scaling 3D backbone networks and introduce a novel hard negative mining module for more efficient training. We evaluate OpenShape on zero-shot 3D classification benchmarks and demonstrate its superior capabilities for open-world recognition. Specifically, OpenShape achieves a zero-shot accuracy of 46.8% on the 1,156-category Objaverse-LVIS benchmark, compared to less than 10% for existing methods. OpenShape also achieves an accuracy of 85.3% on ModelNet40, outperforming previous zero-shot baseline methods by 20% and performing on par with some fully-supervised methods. Furthermore, we show that our learned embeddings encode a wide range of visual and semantic concepts (e.g., subcategories, color, shape, style) and facilitate fine-grained text-3D and image-3D interactions. Due to their alignment with CLIP embeddings, our learned shape representations can also be integrated with off-the-shelf CLIP-based models for various applications, such as point cloud captioning and point cloud-conditioned image generation.
Operational Neural Networks for Efficient Hyperspectral Single-Image Super-Resolution
Mar 29, 2023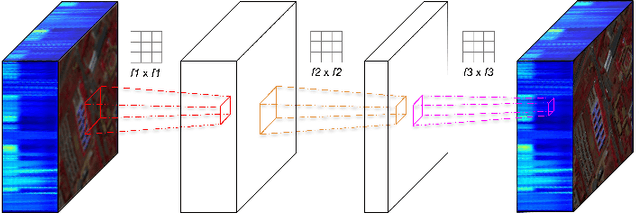
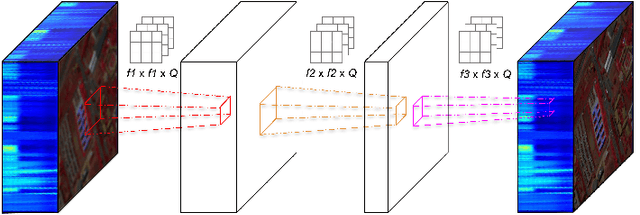
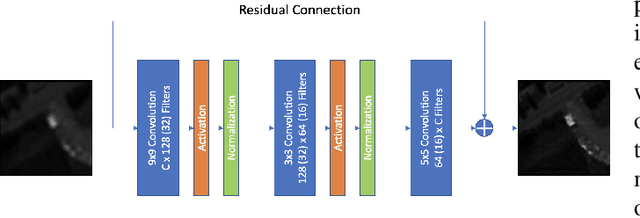

Hyperspectral Imaging is a crucial tool in remote sensing which captures far more spectral information than standard color images. However, the increase in spectral information comes at the cost of spatial resolution. Super-resolution is a popular technique where the goal is to generate a high-resolution version of a given low-resolution input. The majority of modern super-resolution approaches use convolutional neural networks. However, convolution itself is a linear operation and the networks rely on the non-linear activation functions after each layer to provide the necessary non-linearity to learn the complex underlying function. This means that convolutional neural networks tend to be very deep to achieve the desired results. Recently, self-organized operational neural networks have been proposed that aim to overcome this limitation by replacing the convolutional filters with learnable non-linear functions through the use of MacLaurin series expansions. This work focuses on extending the convolutional filters of a popular super-resolution model to more powerful operational filters to enhance the model performance on hyperspectral images. We also investigate the effects that residual connections and different normalization types have on this type of enhanced network. Despite having fewer parameters than their convolutional network equivalents, our results show that operational neural networks achieve superior super-resolution performance on small hyperspectral image datasets.
Fast light-field 3D microscopy with out-of-distribution detection and adaptation through Conditional Normalizing Flows
Jun 10, 2023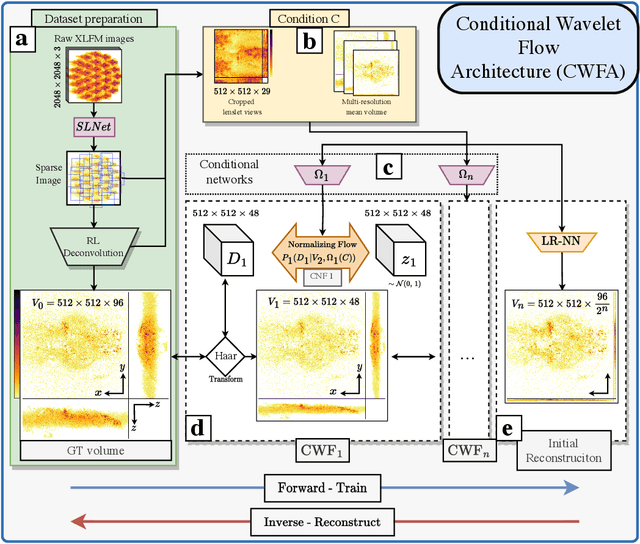
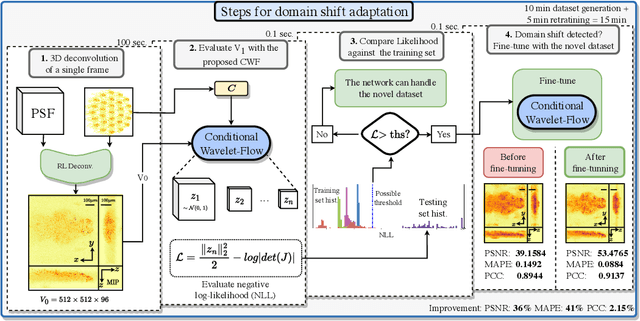
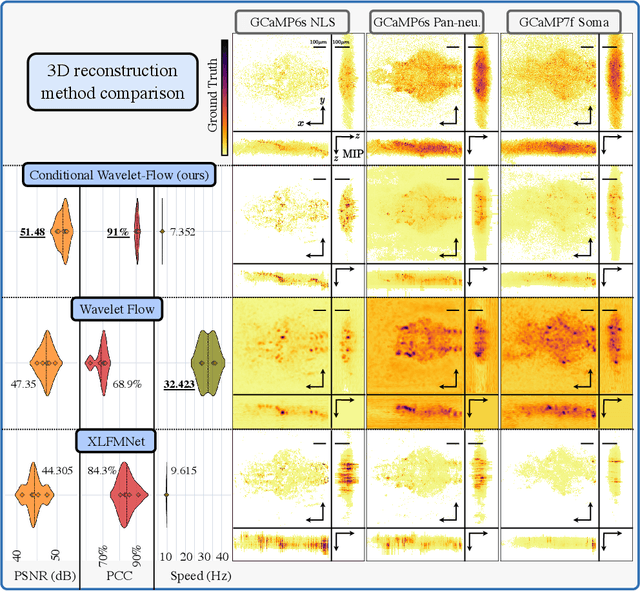
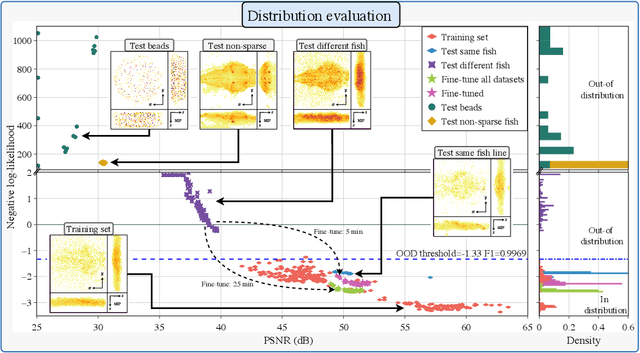
Real-time 3D fluorescence microscopy is crucial for the spatiotemporal analysis of live organisms, such as neural activity monitoring. The eXtended field-of-view light field microscope (XLFM), also known as Fourier light field microscope, is a straightforward, single snapshot solution to achieve this. The XLFM acquires spatial-angular information in a single camera exposure. In a subsequent step, a 3D volume can be algorithmically reconstructed, making it exceptionally well-suited for real-time 3D acquisition and potential analysis. Unfortunately, traditional reconstruction methods (like deconvolution) require lengthy processing times (0.0220 Hz), hampering the speed advantages of the XLFM. Neural network architectures can overcome the speed constraints at the expense of lacking certainty metrics, which renders them untrustworthy for the biomedical realm. This work proposes a novel architecture to perform fast 3D reconstructions of live immobilized zebrafish neural activity based on a conditional normalizing flow. It reconstructs volumes at 8 Hz spanning 512x512x96 voxels, and it can be trained in under two hours due to the small dataset requirements (10 image-volume pairs). Furthermore, normalizing flows allow for exact Likelihood computation, enabling distribution monitoring, followed by out-of-distribution detection and retraining of the system when a novel sample is detected. We evaluate the proposed method on a cross-validation approach involving multiple in-distribution samples (genetically identical zebrafish) and various out-of-distribution ones.