 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CNN Feature Map Augmentation for Single-Source Domain Generalization
May 26, 2023
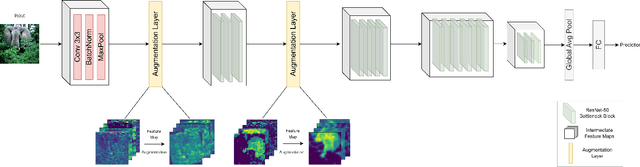
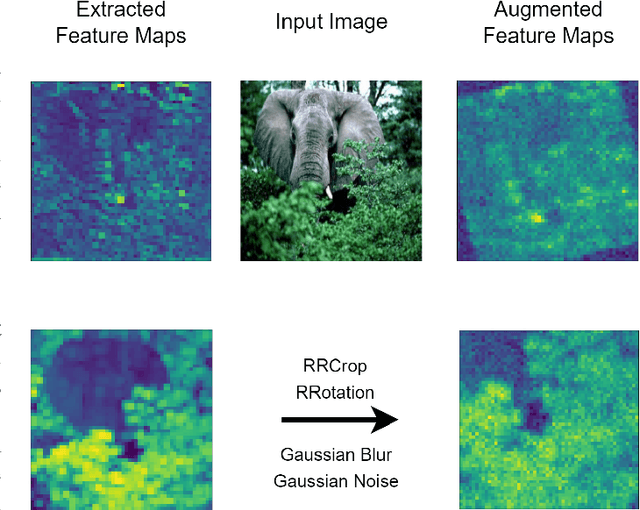
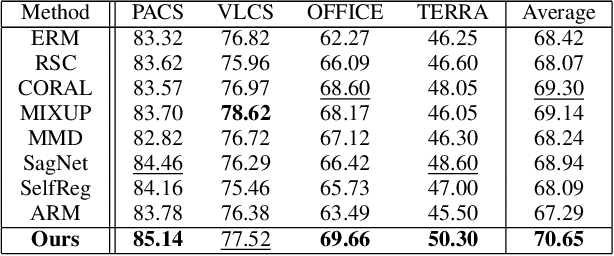
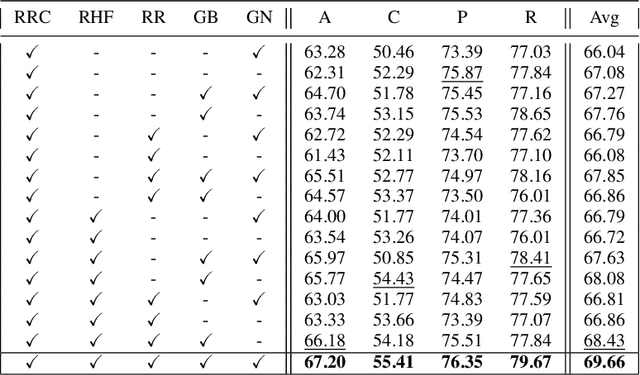
In search of robust and generalizable machine learning models, Domain Generalization (DG) has gained significant traction during the past few years. The goal in DG is to produce models which continue to perform well when presented with data distributions different from the ones seen during training. While deep convolutional neural networks (CNN) have been able to achieve outstanding performance on downstream computer vision tasks, they still often fail to generalize on previously unseen data Domains. Therefore, in this work we focus on producing a model which is able to remain robust under data distribution shift and propose an alternative regularization technique for convolutional neural network architectures in the single-source DG image classification setting. To mitigate the problem caused by domain shift between source and target data, we propose augmenting intermediate feature maps of CNNs. Specifically, we pass them through a novel Augmentation Layer to prevent models from overfitting on the training set and improve their cross-domain generalization. To the best of our knowledge, this is the first paper proposing such a setup for the DG image classification setting. Experiments on the DG benchmark datasets of PACS, VLCS, Office-Home and TerraIncognita validate the effectiveness of our method, in which our model surpasses state-of-the-art algorithms in most cases.
Technical outlier detection via convolutional variational autoencoder for the ADMANI breast mammogram dataset
May 20, 2023
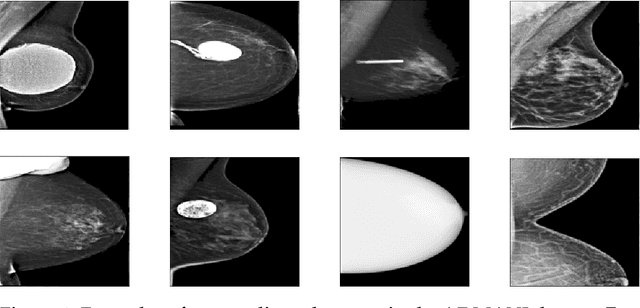

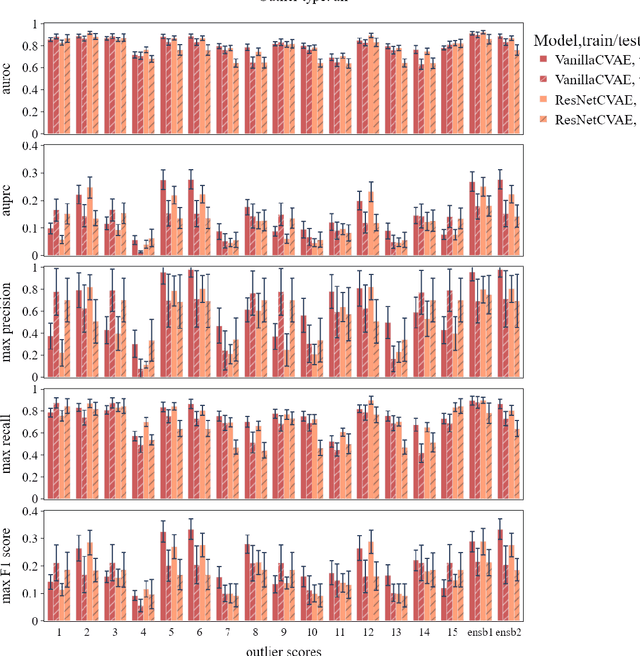
The ADMANI datasets (annotated digital mammograms and associated non-image datasets) from the Transforming Breast Cancer Screening with AI programme (BRAIx) run by BreastScreen Victoria in Australia are multi-centre, large scale, clinically curated, real-world databases. The datasets are expected to aid in the development of clinically relevant Artificial Intelligence (AI) algorithms for breast cancer detection, early diagnosis, and other applications. To ensure high data quality, technical outliers must be removed before any downstream algorithm development. As a first step, we randomly select 30,000 individual mammograms and use Convolutional Variational Autoencoder (CVAE), a deep generative neural network, to detect outliers. CVAE is expected to detect all sorts of outliers, although its detection performance differs among different types of outliers. Traditional image processing techniques such as erosion and pectoral muscle analysis can compensate for the poor performance of CVAE in certain outlier types. We identify seven types of technical outliers: implant, pacemaker, cardiac loop recorder, improper radiography, atypical lesion/calcification, incorrect exposure parameter and improper placement. The outlier recall rate for the test set is 61% if CVAE, erosion and pectoral muscle analysis each select the top 1% images ranked in ascending or descending order according to image outlier score under each detection method, and 83% if each selects the top 5% images. This study offers an overview of technical outliers in the ADMANI dataset and suggests future directions to improve outlier detection effectiveness.
Incorporating Transformer Designs into Convolutions for Lightweight Image Super-Resolution
Mar 25, 2023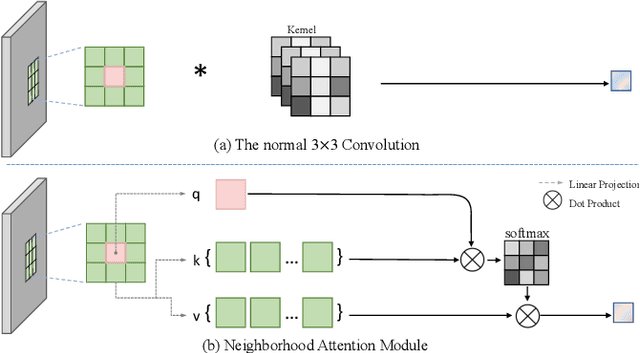
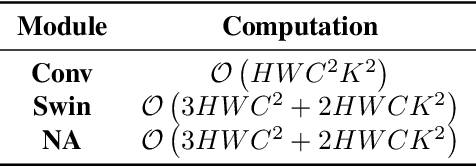
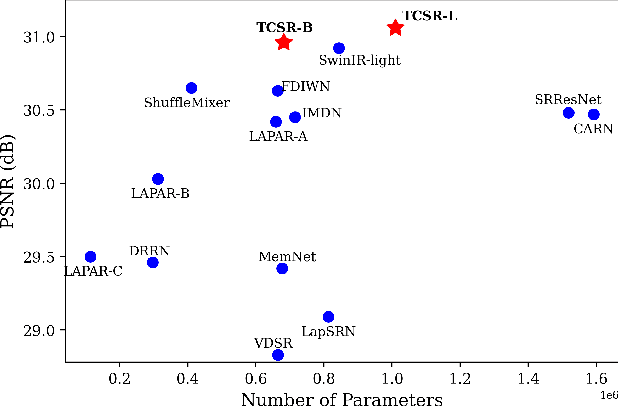
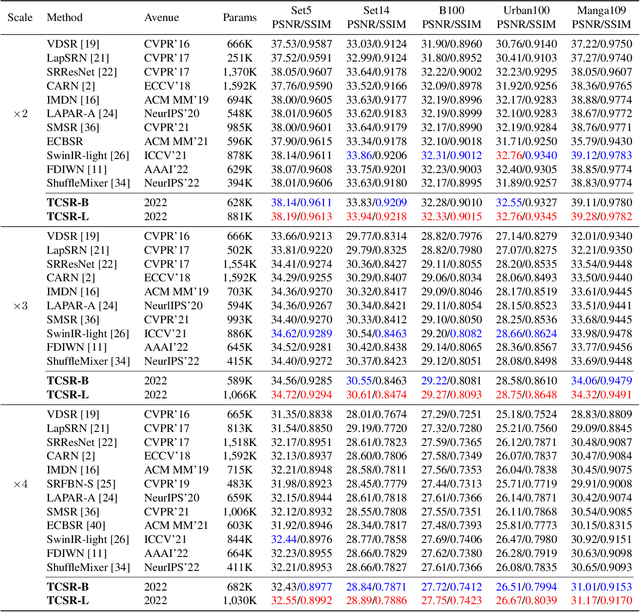
In recent years, the use of large convolutional kernels has become popular in designing convolutional neural networks due to their ability to capture long-range dependencies and provide large receptive fields. However, the increase in kernel size also leads to a quadratic growth in the number of parameters, resulting in heavy computation and memory requirements. To address this challenge, we propose a neighborhood attention (NA) module that upgrades the standard convolution with a self-attention mechanism. The NA module efficiently extracts long-range dependencies in a sliding window pattern, thereby achieving similar performance to large convolutional kernels but with fewer parameters. Building upon the NA module, we propose a lightweight single image super-resolution (SISR) network named TCSR. Additionally, we introduce an enhanced feed-forward network (EFFN) in TCSR to improve the SISR performance. EFFN employs a parameter-free spatial-shift operation for efficient feature aggregation. Our extensive experiments and ablation studies demonstrate that TCSR outperforms existing lightweight SISR methods and achieves state-of-the-art performance. Our codes are available at \url{https://github.com/Aitical/TCSR}.
Improving Object Detection in Medical Image Analysis through Multiple Expert Annotators: An Empirical Investigation
Mar 29, 2023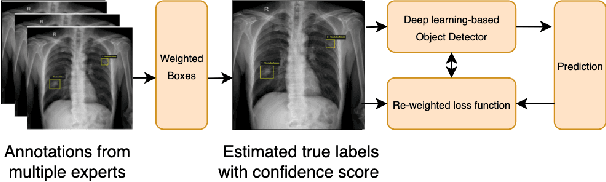

The work discusses the use of machine learning algorithms for anomaly detection in medical image analysis and how the performance of these algorithms depends on the number of annotators and the quality of labels. To address the issue of subjectivity in labeling with a single annotator, we introduce a simple and effective approach that aggregates annotations from multiple annotators with varying levels of expertise. We then aim to improve the efficiency of predictive models in abnormal detection tasks by estimating hidden labels from multiple annotations and using a re-weighted loss function to improve detection performance. Our method is evaluated on a real-world medical imaging dataset and outperforms relevant baselines that do not consider disagreements among annotators.
HDR image watermarking using saliency detection and quantization index modulation
Feb 23, 2023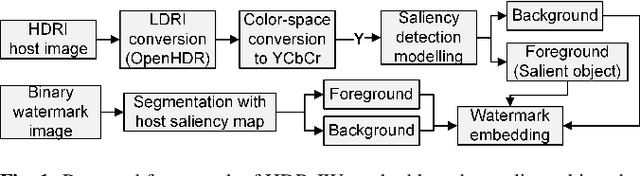
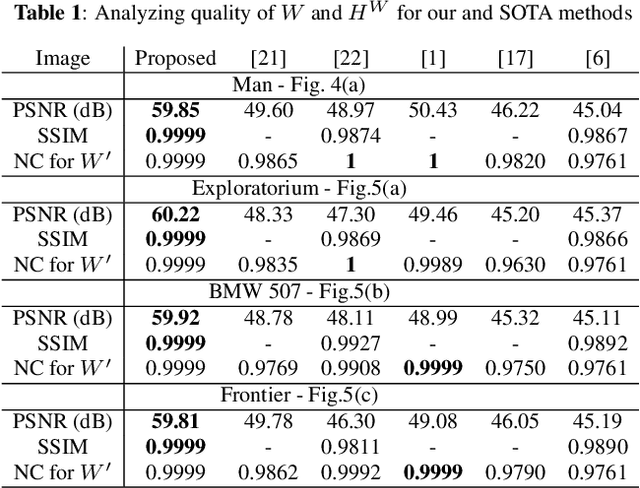
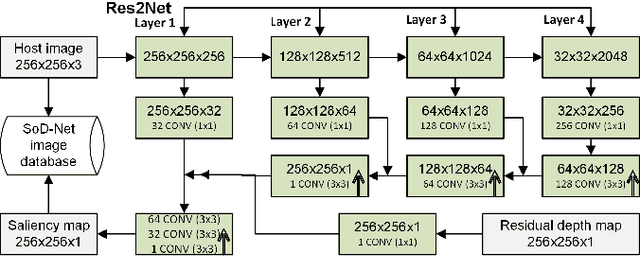

High-dynamic range (HDR) images are circulated rapidly over the internet with risks of being exploited for unauthorized usage. To protect these images, some HDR image based watermarking (HDR-IW) methods were put forward. However, they inherited the same problem faced by conventional IW methods for standard dynamic range (SDR) images, where only trade-offs among conflicting requirements are managed instead of simultaneous improvement. In this paper, a novel saliency (eye-catching object) detection based trade-off independent HDR-IW is proposed, to simultaneously improve robustness, imperceptibility and payload. First, the host image goes through our proposed salient object detection model to produce a saliency map, which is, in turn, exploited to segment the foreground and background of the host image. Next, the binary watermark is partitioned into the foregrounds and backgrounds using the same mask and scrambled using a random permutation algorithm. Finally, the watermark segments are embedded into selected bit-plane of the corresponding host segments using quantized indexed modulation. Experimental results suggest that the proposed work outperforms state-of-the-art methods in terms of improving the conflicting requirements.
Towards Arbitrary-scale Histopathology Image Super-resolution: An Efficient Dual-branch Framework based on Implicit Self-texture Enhancement
Apr 09, 2023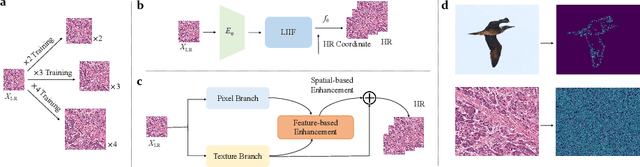
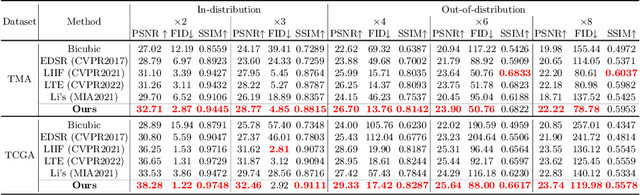
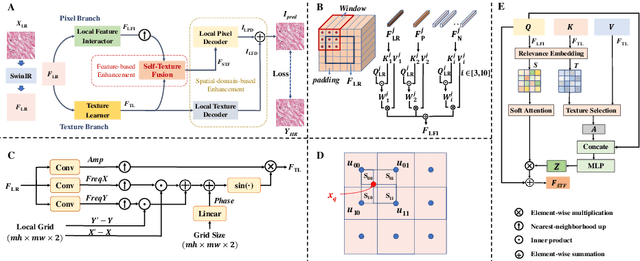

Existing super-resolution models for pathology images can only work in fixed integer magnifications and have limited performance. Though implicit neural network-based methods have shown promising results in arbitrary-scale super-resolution of natural images, it is not effective to directly apply them in pathology images, because pathology images have special fine-grained image textures different from natural images. To address this challenge, we propose a dual-branch framework with an efficient self-texture enhancement mechanism for arbitrary-scale super-resolution of pathology images. Extensive experiments on two public datasets show that our method outperforms both existing fixed-scale and arbitrary-scale algorithms. To the best of our knowledge, this is the first work to achieve arbitrary-scale super-resolution in the field of pathology images. Codes will be available.
Report of the Medical Image De-Identification (MIDI) Task Group -- Best Practices and Recommendations
Mar 18, 2023This report addresses the technical aspects of de-identification of medical images of human subjects and biospecimens, such that re-identification risk of ethical, moral, and legal concern is sufficiently reduced to allow unrestricted public sharing for any purpose, regardless of the jurisdiction of the source and distribution sites. All medical images, regardless of the mode of acquisition, are considered, though the primary emphasis is on those with accompanying data elements, especially those encoded in formats in which the data elements are embedded, particularly Digital Imaging and Communications in Medicine (DICOM). These images include image-like objects such as Segmentations, Parametric Maps, and Radiotherapy (RT) Dose objects. The scope also includes related non-image objects, such as RT Structure Sets, Plans and Dose Volume Histograms, Structured Reports, and Presentation States. Only de-identification of publicly released data is considered, and alternative approaches to privacy preservation, such as federated learning for artificial intelligence (AI) model development, are out of scope, as are issues of privacy leakage from AI model sharing. Only technical issues of public sharing are addressed.
Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models
May 23, 2023
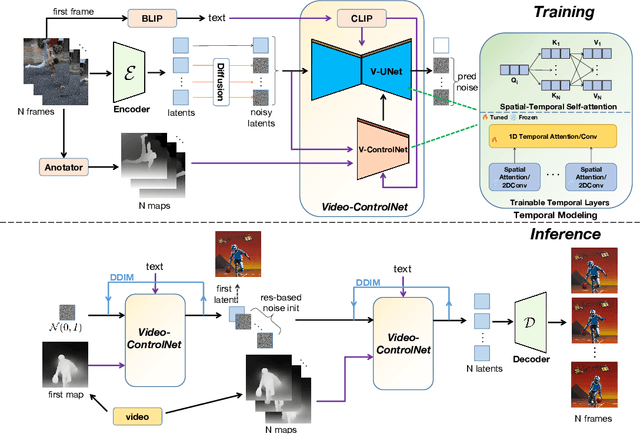


This paper presents a controllable text-to-video (T2V) diffusion model, named Video-ControlNet, that generates videos conditioned on a sequence of control signals, such as edge or depth maps. Video-ControlNet is built on a pre-trained conditional text-to-image (T2I) diffusion model by incorporating a spatial-temporal self-attention mechanism and trainable temporal layers for efficient cross-frame modeling. A first-frame conditioning strategy is proposed to facilitate the model to generate videos transferred from the image domain as well as arbitrary-length videos in an auto-regressive manner. Moreover, Video-ControlNet employs a novel residual-based noise initialization strategy to introduce motion prior from an input video, producing more coherent videos. With the proposed architecture and strategies, Video-ControlNet can achieve resource-efficient convergence and generate superior quality and consistent videos with fine-grained control. Extensive experiments demonstrate its success in various video generative tasks such as video editing and video style transfer, outperforming previous methods in terms of consistency and quality. Project Page: https://controlavideo.github.io/
MIPI 2023 Challenge on Nighttime Flare Removal: Methods and Results
May 23, 2023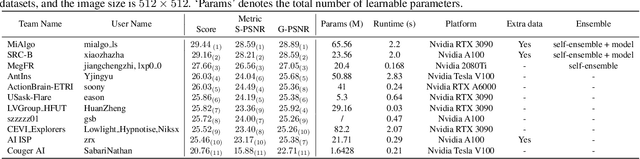

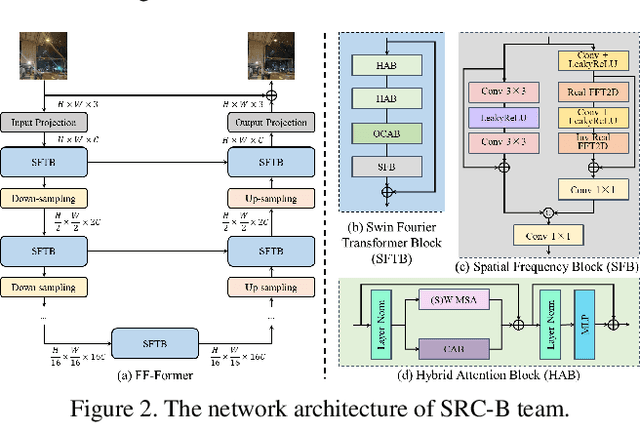
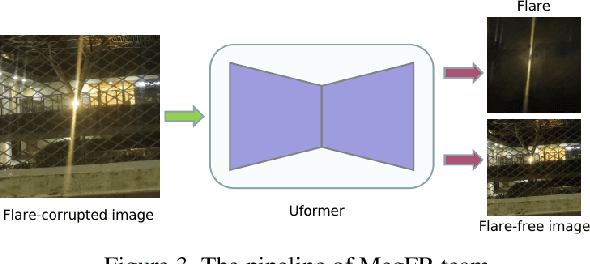
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). With the success of the 1st MIPI Workshop@ECCV 2022, we introduce the second MIPI challenge including four tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2023. In total, 120 participants were successfully registered, and 11 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023/ .
Coarse Is Better? A New Pipeline Towards Self-Supervised Learning with Uncurated Images
Jun 08, 2023
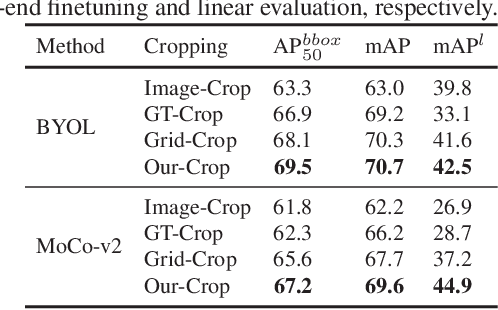
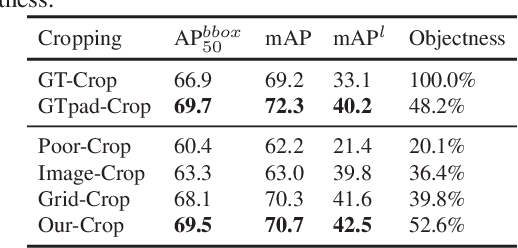
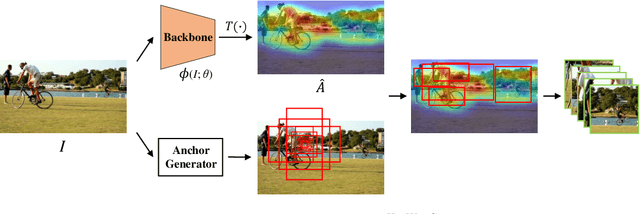
Most self-supervised learning (SSL) methods often work on curated datasets where the object-centric assumption holds. This assumption breaks down in uncurated images. Existing scene image SSL methods try to find the two views from original scene images that are well matched or dense, which is both complex and computationally heavy. This paper proposes a conceptually different pipeline: first find regions that are coarse objects (with adequate objectness), crop them out as pseudo object-centric images, then any SSL method can be directly applied as in a real object-centric dataset. That is, coarse crops benefits scene images SSL. A novel cropping strategy that produces coarse object box is proposed. The new pipeline and cropping strategy successfully learn quality features from uncurated datasets without ImageNet. Experiments show that our pipeline outperforms existing SSL methods (MoCo-v2, DenseCL and MAE) on classification, detection and segmentation tasks. We further conduct extensively ablations to verify that: 1) the pipeline do not rely on pretrained models; 2) the cropping strategy is better than existing object discovery methods; 3) our method is not sensitive to hyperparameters and data augmentations.