 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning the Visualness of Text Using Large Vision-Language Models
May 11, 2023
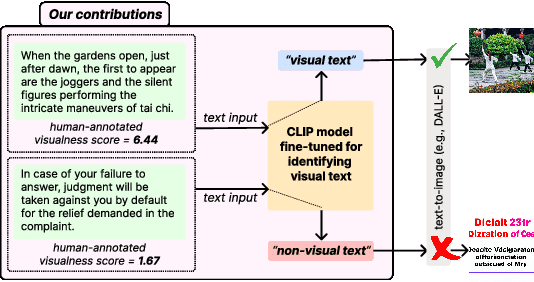

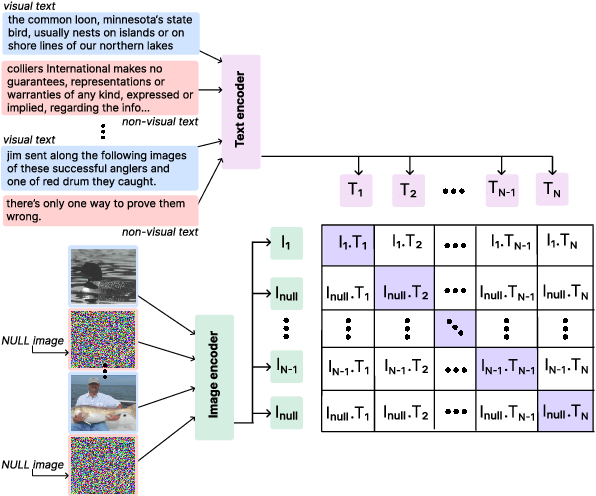
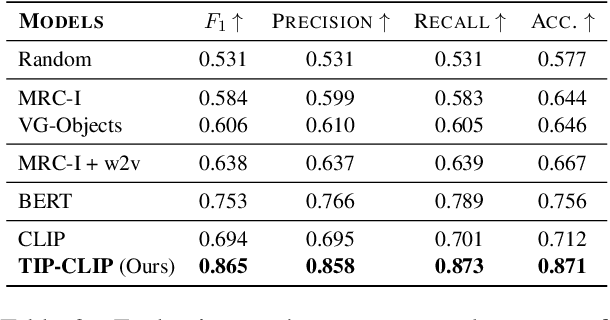
Visual text evokes an image in a person's mind, while non-visual text fails to do so. A method to automatically detect visualness in text will unlock the ability to augment text with relevant images, as neural text-to-image generation and retrieval models operate on the implicit assumption that the input text is visual in nature. We curate a dataset of 3,620 English sentences and their visualness scores provided by multiple human annotators. Additionally, we use documents that contain text and visual assets to create a distantly supervised corpus of document text and associated images. We also propose a fine-tuning strategy that adapts large vision-language models like CLIP that assume a one-to-one correspondence between text and image to the task of scoring text visualness from text input alone. Our strategy involves modifying the model's contrastive learning objective to map text identified as non-visual to a common NULL image while matching visual text to their corresponding images in the document. We evaluate the proposed approach on its ability to (i) classify visual and non-visual text accurately, and (ii) attend over words that are identified as visual in psycholinguistic studies. Empirical evaluation indicates that our approach performs better than several heuristics and baseline models for the proposed task. Furthermore, to highlight the importance of modeling the visualness of text, we conduct qualitative analyses of text-to-image generation systems like DALL-E.
MDP: A Generalized Framework for Text-Guided Image Editing by Manipulating the Diffusion Path
Mar 30, 2023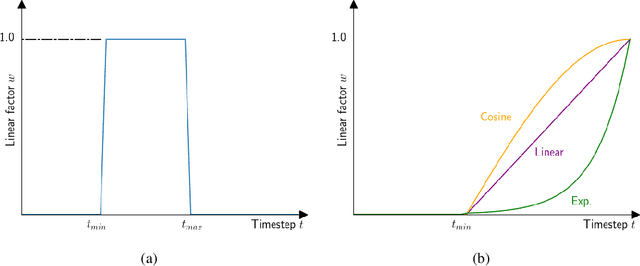
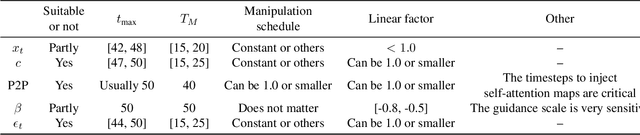
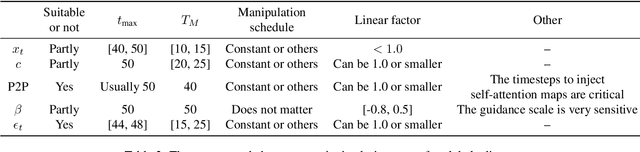

Image generation using diffusion can be controlled in multiple ways. In this paper, we systematically analyze the equations of modern generative diffusion networks to propose a framework, called MDP, that explains the design space of suitable manipulations. We identify 5 different manipulations, including intermediate latent, conditional embedding, cross attention maps, guidance, and predicted noise. We analyze the corresponding parameters of these manipulations and the manipulation schedule. We show that some previous editing methods fit nicely into our framework. Particularly, we identified one specific configuration as a new type of control by manipulating the predicted noise, which can perform higher-quality edits than previous work for a variety of local and global edits.
Designing an Encoder for Fast Personalization of Text-to-Image Models
Feb 23, 2023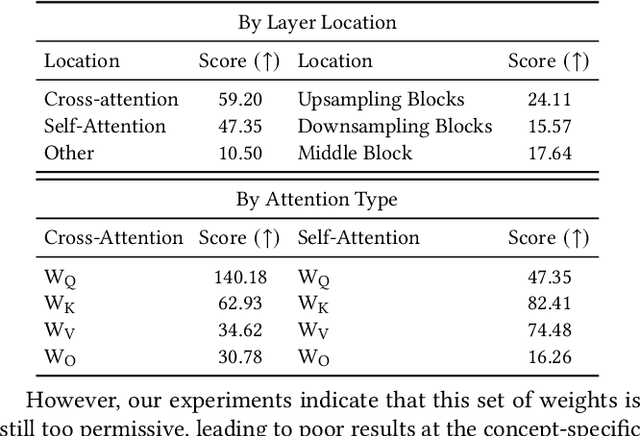
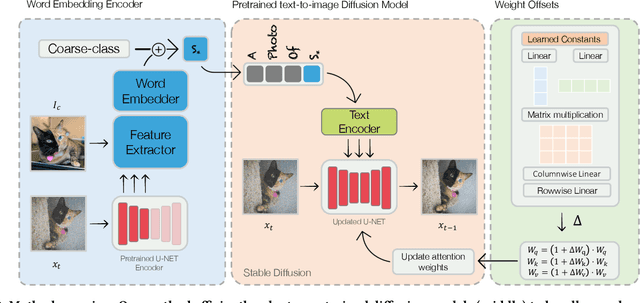

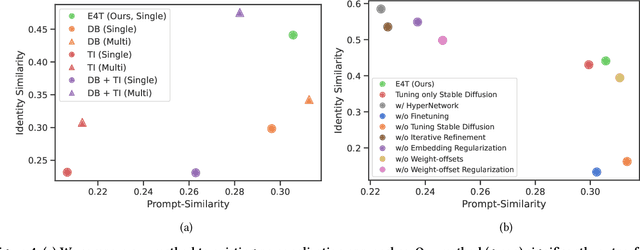
Text-to-image personalization aims to teach a pre-trained diffusion model to reason about novel, user provided concepts, embedding them into new scenes guided by natural language prompts. However, current personalization approaches struggle with lengthy training times, high storage requirements or loss of identity. To overcome these limitations, we propose an encoder-based domain-tuning approach. Our key insight is that by underfitting on a large set of concepts from a given domain, we can improve generalization and create a model that is more amenable to quickly adding novel concepts from the same domain. Specifically, we employ two components: First, an encoder that takes as an input a single image of a target concept from a given domain, e.g. a specific face, and learns to map it into a word-embedding representing the concept. Second, a set of regularized weight-offsets for the text-to-image model that learn how to effectively ingest additional concepts. Together, these components are used to guide the learning of unseen concepts, allowing us to personalize a model using only a single image and as few as 5 training steps - accelerating personalization from dozens of minutes to seconds, while preserving quality.
GenerateCT: Text-Guided 3D Chest CT Generation
May 26, 2023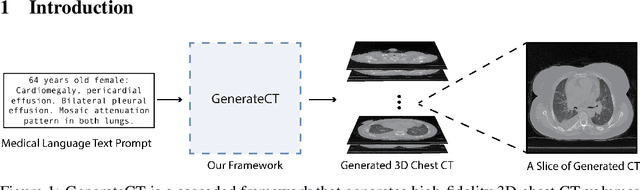
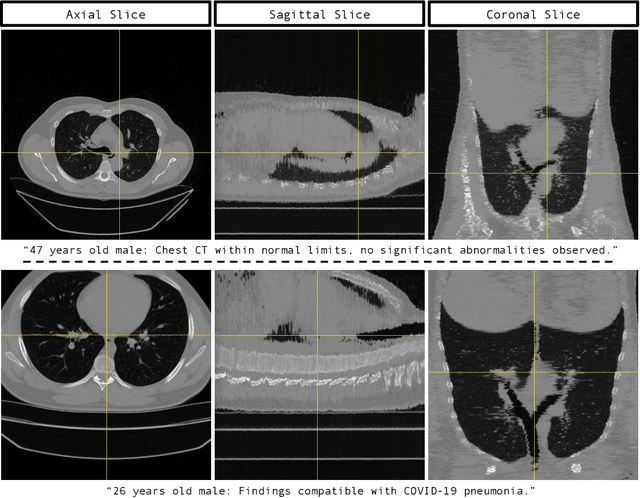

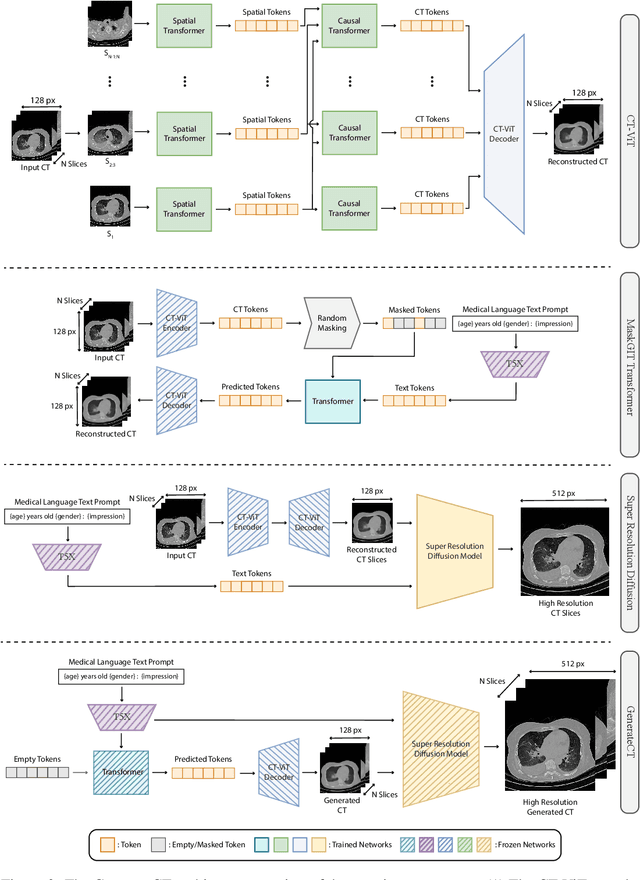
Generative modeling has experienced substantial progress in recent years, particularly in text-to-image and text-to-video synthesis. However, the medical field has not yet fully exploited the potential of large-scale foundational models for synthetic data generation. In this paper, we introduce GenerateCT, the first method for text-conditional computed tomography (CT) generation, addressing the limitations in 3D medical imaging research and making our entire framework open-source. GenerateCT consists of a pre-trained large language model, a transformer-based text-conditional 3D chest CT generation architecture, and a text-conditional spatial super-resolution diffusion model. We also propose CT-ViT, which efficiently compresses CT volumes while preserving auto-regressiveness in-depth, enabling the generation of 3D CT volumes with variable numbers of axial slices. Our experiments demonstrate that GenerateCT can produce realistic, high-resolution, and high-fidelity 3D chest CT volumes consistent with medical language text prompts. We further investigate the potential of GenerateCT by training a model using generated CT volumes for multi-abnormality classification of chest CT volumes. Our contributions provide a valuable foundation for future research in text-conditional 3D medical image generation and have the potential to accelerate advancements in medical imaging research. Our code, pre-trained models, and generated data are available at https://github.com/ibrahimethemhamamci/GenerateCT.
CLIP3Dstyler: Language Guided 3D Arbitrary Neural Style Transfer
May 26, 2023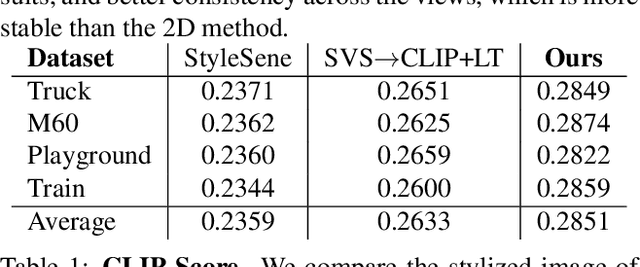

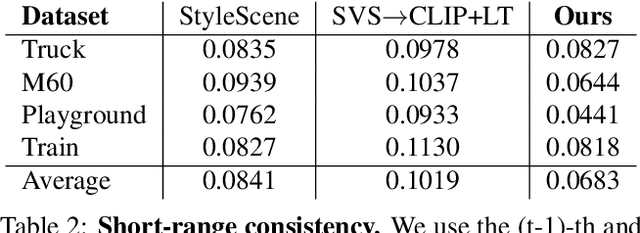

In this paper, we propose a novel language-guided 3D arbitrary neural style transfer method (CLIP3Dstyler). We aim at stylizing any 3D scene with an arbitrary style from a text description, and synthesizing the novel stylized view, which is more flexible than the image-conditioned style transfer. Compared with the previous 2D method CLIPStyler, we are able to stylize a 3D scene and generalize to novel scenes without re-train our model. A straightforward solution is to combine previous image-conditioned 3D style transfer and text-conditioned 2D style transfer \bigskip methods. However, such a solution cannot achieve our goal due to two main challenges. First, there is no multi-modal model matching point clouds and language at different feature scales (low-level, high-level). Second, we observe a style mixing issue when we stylize the content with different style conditions from text prompts. To address the first issue, we propose a 3D stylization framework to match the point cloud features with text features in local and global views. For the second issue, we propose an improved directional divergence loss to make arbitrary text styles more distinguishable as a complement to our framework. We conduct extensive experiments to show the effectiveness of our model on text-guided 3D scene style transfer.
CNN Feature Map Augmentation for Single-Source Domain Generalization
May 26, 2023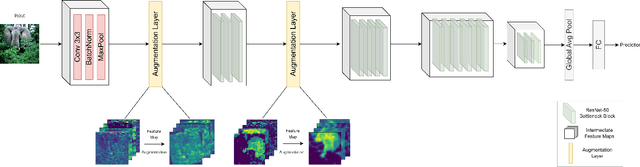
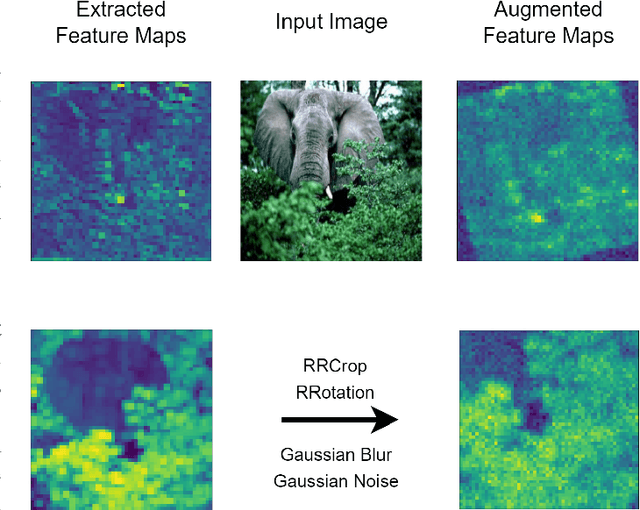
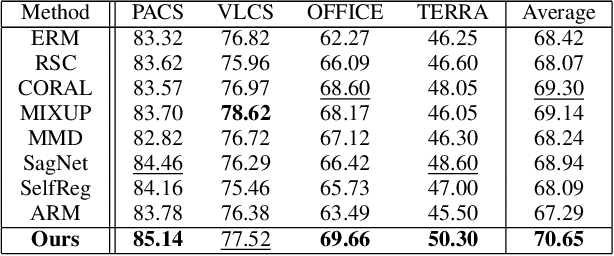
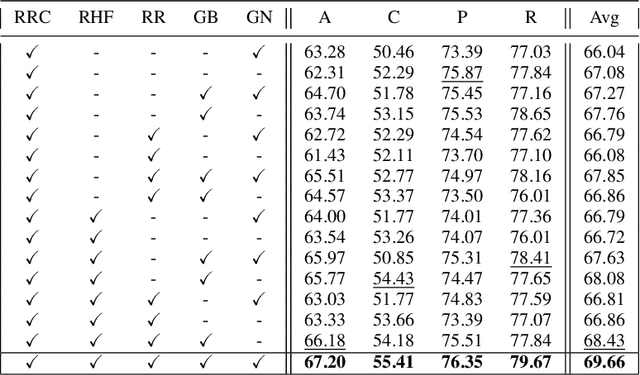
In search of robust and generalizable machine learning models, Domain Generalization (DG) has gained significant traction during the past few years. The goal in DG is to produce models which continue to perform well when presented with data distributions different from the ones seen during training. While deep convolutional neural networks (CNN) have been able to achieve outstanding performance on downstream computer vision tasks, they still often fail to generalize on previously unseen data Domains. Therefore, in this work we focus on producing a model which is able to remain robust under data distribution shift and propose an alternative regularization technique for convolutional neural network architectures in the single-source DG image classification setting. To mitigate the problem caused by domain shift between source and target data, we propose augmenting intermediate feature maps of CNNs. Specifically, we pass them through a novel Augmentation Layer to prevent models from overfitting on the training set and improve their cross-domain generalization. To the best of our knowledge, this is the first paper proposing such a setup for the DG image classification setting. Experiments on the DG benchmark datasets of PACS, VLCS, Office-Home and TerraIncognita validate the effectiveness of our method, in which our model surpasses state-of-the-art algorithms in most cases.
LDM3D: Latent Diffusion Model for 3D
May 21, 2023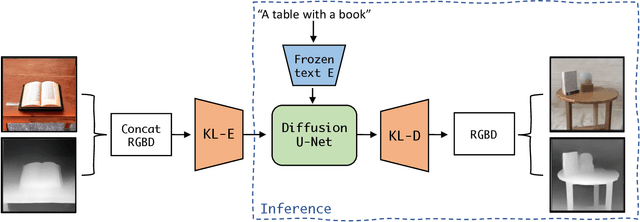
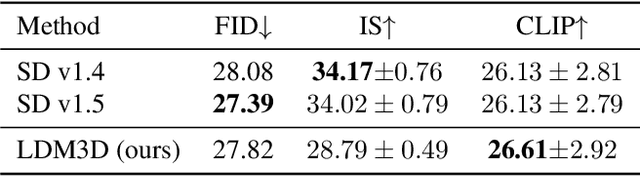
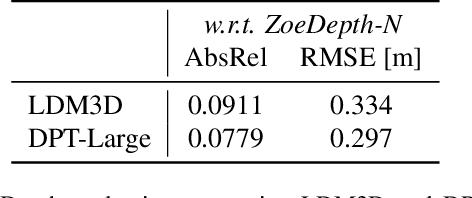
This research paper proposes a Latent Diffusion Model for 3D (LDM3D) that generates both image and depth map data from a given text prompt, allowing users to generate RGBD images from text prompts. The LDM3D model is fine-tuned on a dataset of tuples containing an RGB image, depth map and caption, and validated through extensive experiments. We also develop an application called DepthFusion, which uses the generated RGB images and depth maps to create immersive and interactive 360-degree-view experiences using TouchDesigner. This technology has the potential to transform a wide range of industries, from entertainment and gaming to architecture and design. Overall, this paper presents a significant contribution to the field of generative AI and computer vision, and showcases the potential of LDM3D and DepthFusion to revolutionize content creation and digital experiences. A short video summarizing the approach can be found at https://t.ly/tdi2.
Towards More Transparent and Accurate Cancer Diagnosis with an Unsupervised CAE Approach
May 19, 2023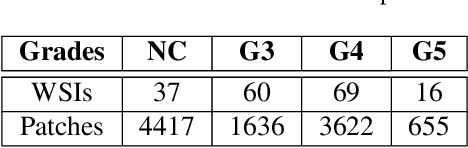
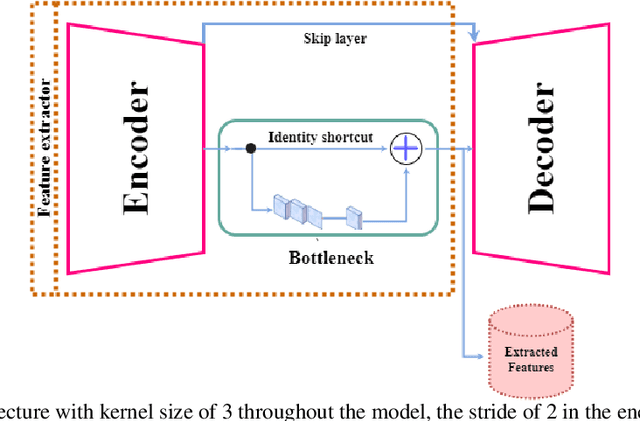
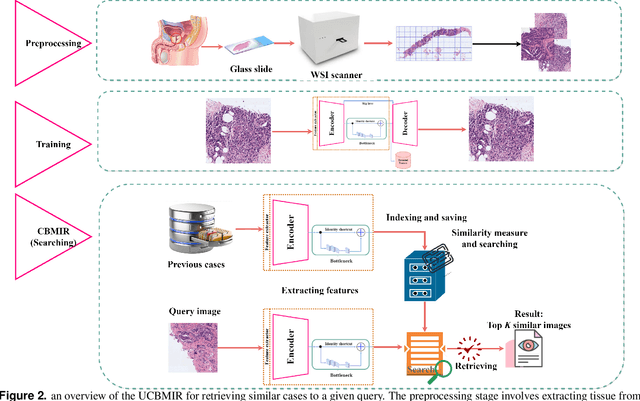
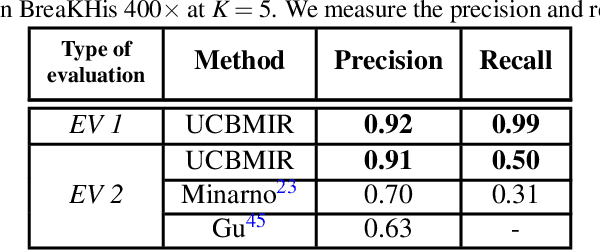
Digital pathology has revolutionized cancer diagnosis by leveraging Content-Based Medical Image Retrieval (CBMIR) for analyzing histopathological Whole Slide Images (WSIs). CBMIR enables searching for similar content, enhancing diagnostic reliability and accuracy. In 2020, breast and prostate cancer constituted 11.7% and 14.1% of cases, respectively, as reported by the Global Cancer Observatory (GCO). The proposed Unsupervised CBMIR (UCBMIR) replicates the traditional cancer diagnosis workflow, offering a dependable method to support pathologists in WSI-based diagnostic conclusions. This approach alleviates pathologists' workload, potentially enhancing diagnostic efficiency. To address the challenge of the lack of labeled histopathological images in CBMIR, a customized unsupervised Convolutional Auto Encoder (CAE) was developed, extracting 200 features per image for the search engine component. UCBMIR was evaluated using widely-used numerical techniques in CBMIR, alongside visual evaluation and comparison with a classifier. The validation involved three distinct datasets, with an external evaluation demonstrating its effectiveness. UCBMIR outperformed previous studies, achieving a top 5 recall of 99% and 80% on BreaKHis and SICAPv2, respectively, using the first evaluation technique. Precision rates of 91% and 70% were achieved for BreaKHis and SICAPv2, respectively, using the second evaluation technique. Furthermore, UCBMIR demonstrated the capability to identify various patterns in patches, achieving an 81% accuracy in the top 5 when tested on an external image from Arvaniti.
APPLeNet: Visual Attention Parameterized Prompt Learning for Few-Shot Remote Sensing Image Generalization using CLIP
Apr 12, 2023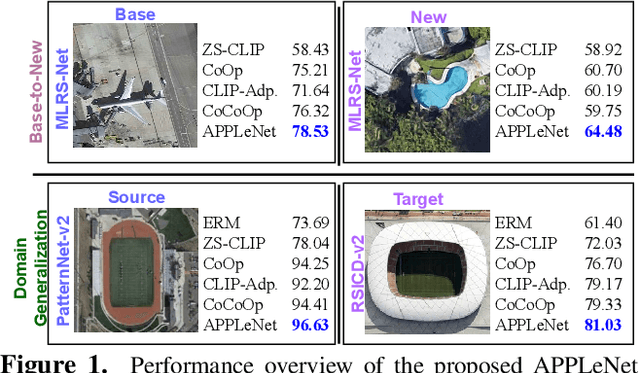

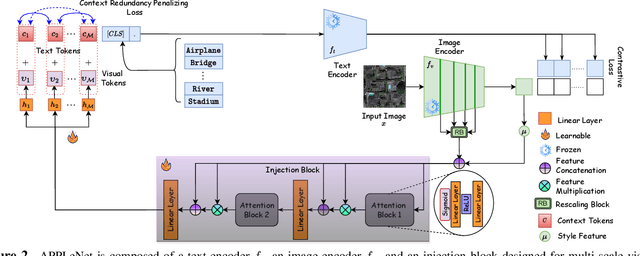
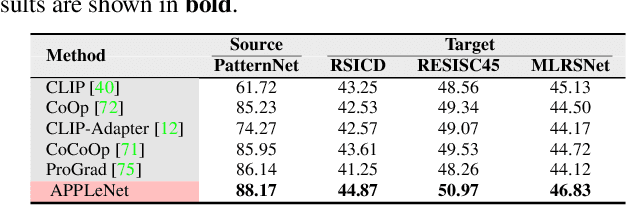
In recent years, the success of large-scale vision-language models (VLMs) such as CLIP has led to their increased usage in various computer vision tasks. These models enable zero-shot inference through carefully crafted instructional text prompts without task-specific supervision. However, the potential of VLMs for generalization tasks in remote sensing (RS) has not been fully realized. To address this research gap, we propose a novel image-conditioned prompt learning strategy called the Visual Attention Parameterized Prompts Learning Network (APPLeNet). APPLeNet emphasizes the importance of multi-scale feature learning in RS scene classification and disentangles visual style and content primitives for domain generalization tasks. To achieve this, APPLeNet combines visual content features obtained from different layers of the vision encoder and style properties obtained from feature statistics of domain-specific batches. An attention-driven injection module is further introduced to generate visual tokens from this information. We also introduce an anti-correlation regularizer to ensure discrimination among the token embeddings, as this visual information is combined with the textual tokens. To validate APPLeNet, we curated four available RS benchmarks and introduced experimental protocols and datasets for three domain generalization tasks. Our results consistently outperform the relevant literature and code is available at https://github.com/mainaksingha01/APPLeNet
Technical outlier detection via convolutional variational autoencoder for the ADMANI breast mammogram dataset
May 20, 2023
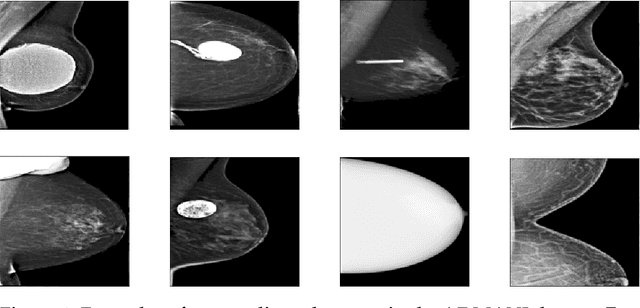

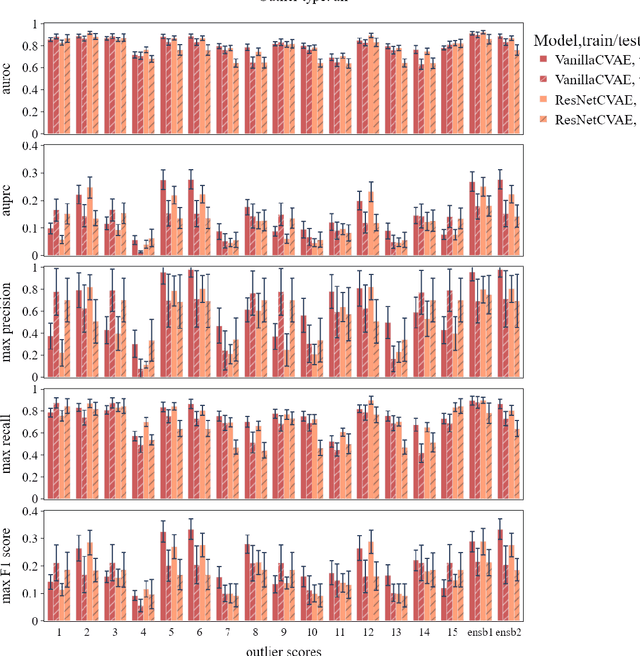
The ADMANI datasets (annotated digital mammograms and associated non-image datasets) from the Transforming Breast Cancer Screening with AI programme (BRAIx) run by BreastScreen Victoria in Australia are multi-centre, large scale, clinically curated, real-world databases. The datasets are expected to aid in the development of clinically relevant Artificial Intelligence (AI) algorithms for breast cancer detection, early diagnosis, and other applications. To ensure high data quality, technical outliers must be removed before any downstream algorithm development. As a first step, we randomly select 30,000 individual mammograms and use Convolutional Variational Autoencoder (CVAE), a deep generative neural network, to detect outliers. CVAE is expected to detect all sorts of outliers, although its detection performance differs among different types of outliers. Traditional image processing techniques such as erosion and pectoral muscle analysis can compensate for the poor performance of CVAE in certain outlier types. We identify seven types of technical outliers: implant, pacemaker, cardiac loop recorder, improper radiography, atypical lesion/calcification, incorrect exposure parameter and improper placement. The outlier recall rate for the test set is 61% if CVAE, erosion and pectoral muscle analysis each select the top 1% images ranked in ascending or descending order according to image outlier score under each detection method, and 83% if each selects the top 5% images. This study offers an overview of technical outliers in the ADMANI dataset and suggests future directions to improve outlier detection effectiveness.