 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Graph-based methods coupled with specific distributional distances for adversarial attack detection
May 31, 2023

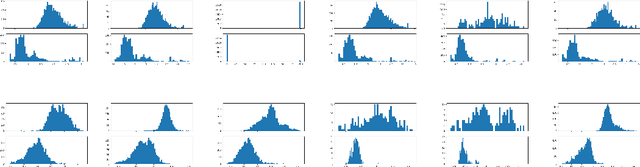

Artificial neural networks are prone to being fooled by carefully perturbed inputs which cause an egregious misclassification. These \textit{adversarial} attacks have been the focus of extensive research. Likewise, there has been an abundance of research in ways to detect and defend against them. We introduce a novel approach of detection and interpretation of adversarial attacks from a graph perspective. For an image, benign or adversarial, we study how a neural network's architecture can induce an associated graph. We study this graph and introduce specific measures used to predict and interpret adversarial attacks. We show that graphs-based approaches help to investigate the inner workings of adversarial attacks.
Prototype of a Cardiac MRI Simulator for the Training of Supervised Neural Networks
May 25, 2023Supervised deep learning methods typically rely on large datasets for training. Ethical and practical considerations usually make it difficult to access large amounts of healthcare data, such as medical images, with known task-specific ground truth. This hampers the development of adequate, unbiased and robust deep learning methods for clinical tasks. Magnetic Resonance Images (MRI) are the result of several complex physical and engineering processes and the generation of synthetic MR images provides a formidable challenge. Here, we present the first results of ongoing work to create a generator for large synthetic cardiac MR image datasets. As an application for the simulator, we show how the synthetic images can be used to help train a supervised neural network that estimates the volume of the left ventricular myocardium directly from cardiac MR images. Despite its current limitations, our generator may in the future help address the current shortage of labelled cardiac MRI needed for the development of supervised deep learning tools. It is likely to also find applications in the development of image reconstruction methods and tools to improve robustness, verification and interpretability of deep networks in this setting.
NVTC: Nonlinear Vector Transform Coding
May 25, 2023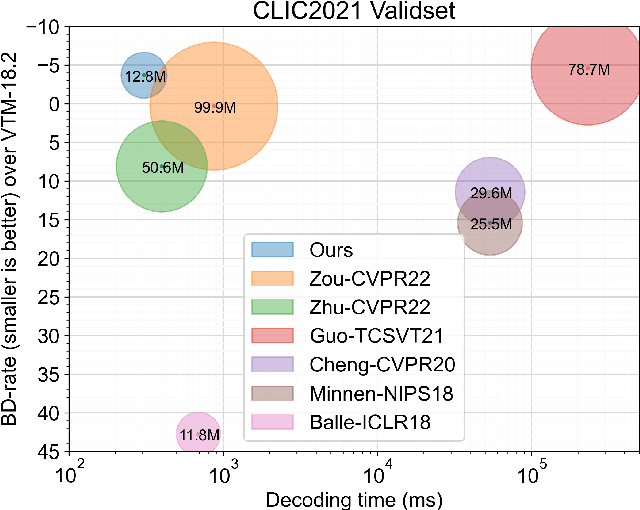
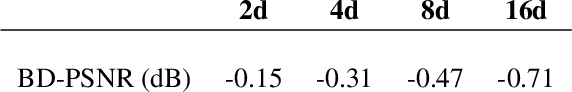

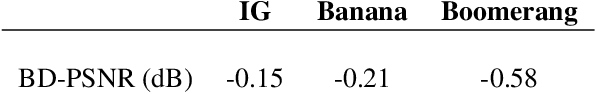
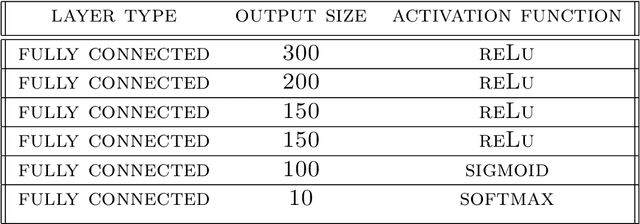
In theory, vector quantization (VQ) is always better than scalar quantization (SQ) in terms of rate-distortion (R-D) performance. Recent state-of-the-art methods for neural image compression are mainly based on nonlinear transform coding (NTC) with uniform scalar quantization, overlooking the benefits of VQ due to its exponentially increased complexity. In this paper, we first investigate on some toy sources, demonstrating that even if modern neural networks considerably enhance the compression performance of SQ with nonlinear transform, there is still an insurmountable chasm between SQ and VQ. Therefore, revolving around VQ, we propose a novel framework for neural image compression named Nonlinear Vector Transform Coding (NVTC). NVTC solves the critical complexity issue of VQ through (1) a multi-stage quantization strategy and (2) nonlinear vector transforms. In addition, we apply entropy-constrained VQ in latent space to adaptively determine the quantization boundaries for joint rate-distortion optimization, which improves the performance both theoretically and experimentally. Compared to previous NTC approaches, NVTC demonstrates superior rate-distortion performance, faster decoding speed, and smaller model size. Our code is available at https://github.com/USTC-IMCL/NVTC
Are Diffusion Models Vision-And-Language Reasoners?
May 25, 2023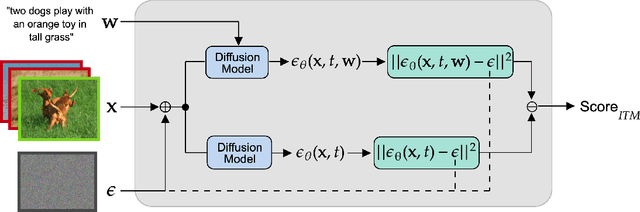
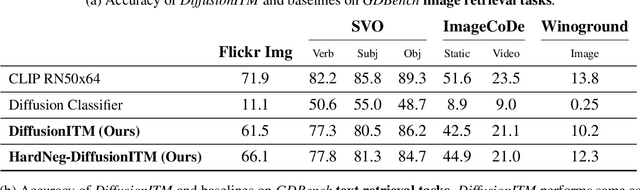
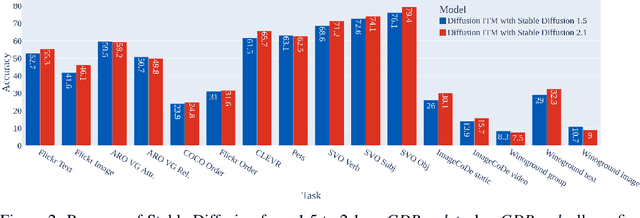
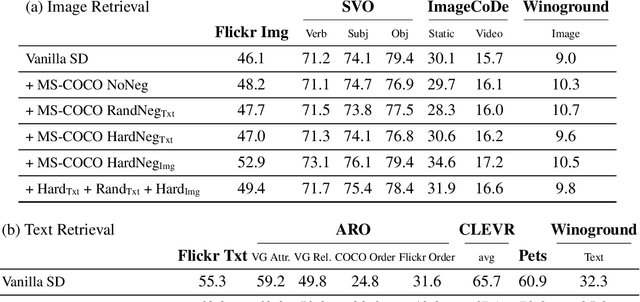
Text-conditioned image generation models have recently shown immense qualitative success using denoising diffusion processes. However, unlike discriminative vision-and-language models, it is a non-trivial task to subject these diffusion-based generative models to automatic fine-grained quantitative evaluation of high-level phenomena such as compositionality. Towards this goal, we perform two innovations. First, we transform diffusion-based models (in our case, Stable Diffusion) for any image-text matching (ITM) task using a novel method called DiffusionITM. Second, we introduce the Generative-Discriminative Evaluation Benchmark (GDBench) benchmark with 7 complex vision-and-language tasks, bias evaluation and detailed analysis. We find that Stable Diffusion + DiffusionITM is competitive on many tasks and outperforms CLIP on compositional tasks like like CLEVR and Winoground. We further boost its compositional performance with a transfer setup by fine-tuning on MS-COCO while retaining generative capabilities. We also measure the stereotypical bias in diffusion models, and find that Stable Diffusion 2.1 is, for the most part, less biased than Stable Diffusion 1.5. Overall, our results point in an exciting direction bringing discriminative and generative model evaluation closer. We will release code and benchmark setup soon.
Multi-Modality Deep Network for JPEG Artifacts Reduction
May 04, 2023

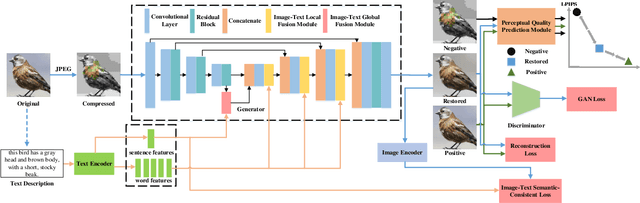
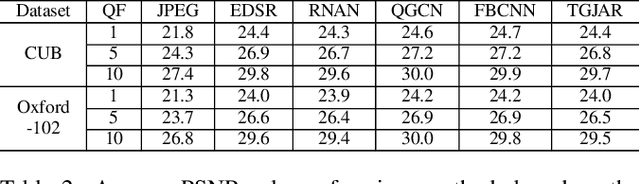
In recent years, many convolutional neural network-based models are designed for JPEG artifacts reduction, and have achieved notable progress. However, few methods are suitable for extreme low-bitrate image compression artifacts reduction. The main challenge is that the highly compressed image loses too much information, resulting in reconstructing high-quality image difficultly. To address this issue, we propose a multimodal fusion learning method for text-guided JPEG artifacts reduction, in which the corresponding text description not only provides the potential prior information of the highly compressed image, but also serves as supplementary information to assist in image deblocking. We fuse image features and text semantic features from the global and local perspectives respectively, and design a contrastive loss built upon contrastive learning to produce visually pleasing results. Extensive experiments, including a user study, prove that our method can obtain better deblocking results compared to the state-of-the-art methods.
Few-Shot Domain Adaptation for Low Light RAW Image Enhancement
Mar 27, 2023
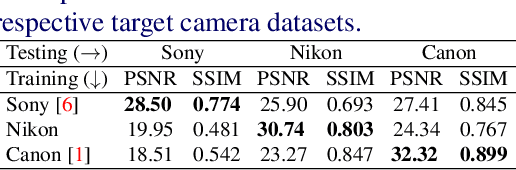
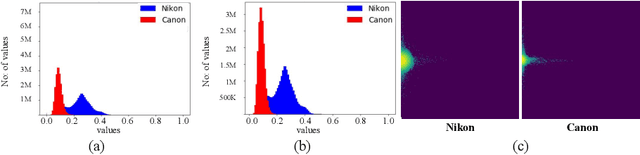
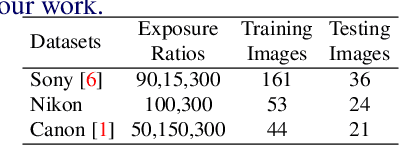
Enhancing practical low light raw images is a difficult task due to severe noise and color distortions from short exposure time and limited illumination. Despite the success of existing Convolutional Neural Network (CNN) based methods, their performance is not adaptable to different camera domains. In addition, such methods also require large datasets with short-exposure and corresponding long-exposure ground truth raw images for each camera domain, which is tedious to compile. To address this issue, we present a novel few-shot domain adaptation method to utilize the existing source camera labeled data with few labeled samples from the target camera to improve the target domain's enhancement quality in extreme low-light imaging. Our experiments show that only ten or fewer labeled samples from the target camera domain are sufficient to achieve similar or better enhancement performance than training a model with a large labeled target camera dataset. To support research in this direction, we also present a new low-light raw image dataset captured with a Nikon camera, comprising short-exposure and their corresponding long-exposure ground truth images.
* BMVC 2021 Best Student Paper Award (Runner-Up). Project Page: https://val.cds.iisc.ac.in/HDR/BMVC21/index.html
SparseGNV: Generating Novel Views of Indoor Scenes with Sparse Input Views
May 11, 2023
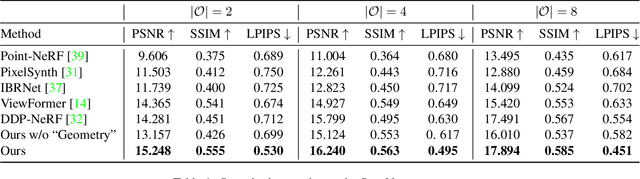
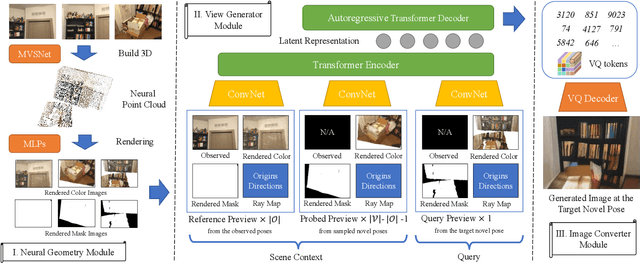

We study to generate novel views of indoor scenes given sparse input views. The challenge is to achieve both photorealism and view consistency. We present SparseGNV: a learning framework that incorporates 3D structures and image generative models to generate novel views with three modules. The first module builds a neural point cloud as underlying geometry, providing contextual information and guidance for the target novel view. The second module utilizes a transformer-based network to map the scene context and the guidance into a shared latent space and autoregressively decodes the target view in the form of discrete image tokens. The third module reconstructs the tokens into the image of the target view. SparseGNV is trained across a large indoor scene dataset to learn generalizable priors. Once trained, it can efficiently generate novel views of an unseen indoor scene in a feed-forward manner. We evaluate SparseGNV on both real-world and synthetic indoor scenes and demonstrate that it outperforms state-of-the-art methods based on either neural radiance fields or conditional image generation.
PixMIM: Rethinking Pixel Reconstruction in Masked Image Modeling
Mar 04, 2023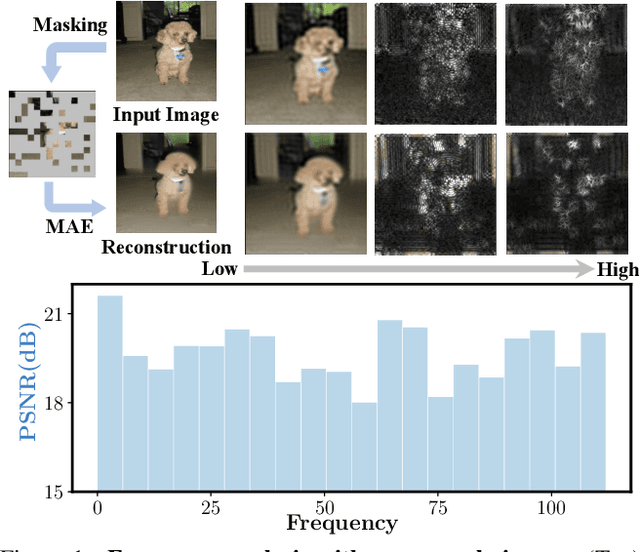


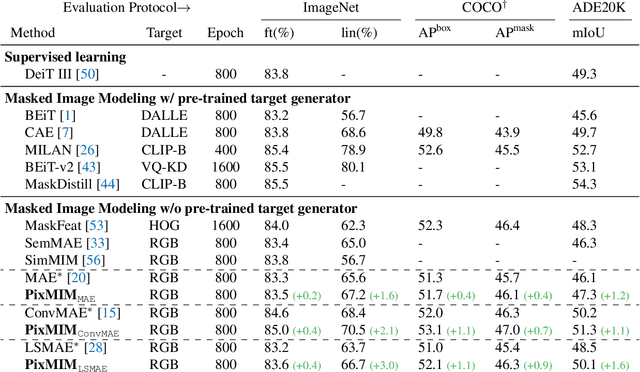
Masked Image Modeling (MIM) has achieved promising progress with the advent of Masked Autoencoders (MAE) and BEiT. However, subsequent works have complicated the framework with new auxiliary tasks or extra pre-trained models, inevitably increasing computational overhead. This paper undertakes a fundamental analysis of MIM from the perspective of pixel reconstruction, which examines the input image patches and reconstruction target, and highlights two critical but previously overlooked bottlenecks.Based on this analysis, we propose a remarkably simple and effective method, PixMIM, that entails two strategies: 1) filtering the high-frequency components from the reconstruction target to de-emphasize the network's focus on texture-rich details and 2) adopting a conservative data transform strategy to alleviate the problem of missing foreground in MIM training. PixMIM can be easily integrated into most existing pixel-based MIM approaches (i.e., using raw images as reconstruction target) with negligible additional computation. Without bells and whistles, our method consistently improves three MIM approaches, MAE, ConvMAE, and LSMAE, across various downstream tasks. We believe this effective plug-and-play method will serve as a strong baseline for self-supervised learning and provide insights for future improvements of the MIM framework. Code will be available at https://github.com/open-mmlab/mmselfsup.
NeRFuser: Large-Scale Scene Representation by NeRF Fusion
May 22, 2023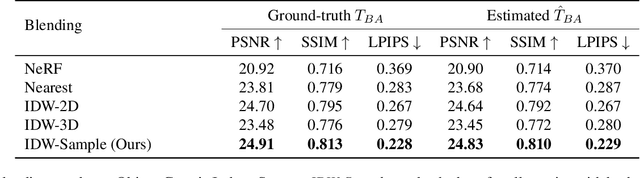

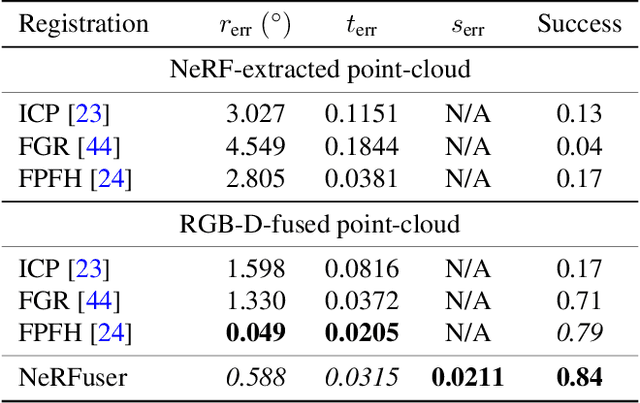
A practical benefit of implicit visual representations like Neural Radiance Fields (NeRFs) is their memory efficiency: large scenes can be efficiently stored and shared as small neural nets instead of collections of images. However, operating on these implicit visual data structures requires extending classical image-based vision techniques (e.g., registration, blending) from image sets to neural fields. Towards this goal, we propose NeRFuser, a novel architecture for NeRF registration and blending that assumes only access to pre-generated NeRFs, and not the potentially large sets of images used to generate them. We propose registration from re-rendering, a technique to infer the transformation between NeRFs based on images synthesized from individual NeRFs. For blending, we propose sample-based inverse distance weighting to blend visual information at the ray-sample level. We evaluate NeRFuser on public benchmarks and a self-collected object-centric indoor dataset, showing the robustness of our method, including to views that are challenging to render from the individual source NeRFs.
Coarse Is Better? A New Pipeline Towards Self-Supervised Learning with Uncurated Images
Jun 08, 2023
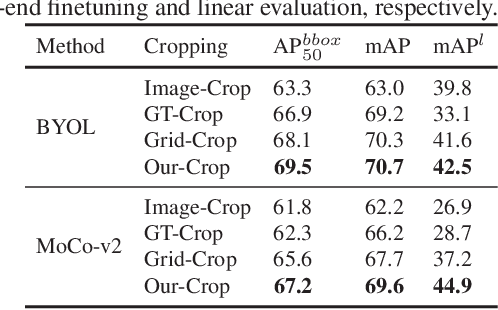
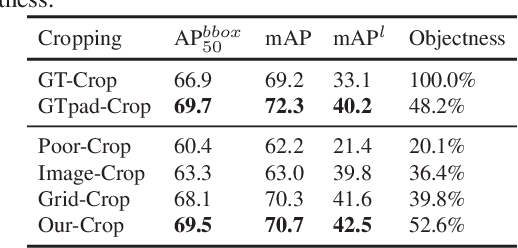
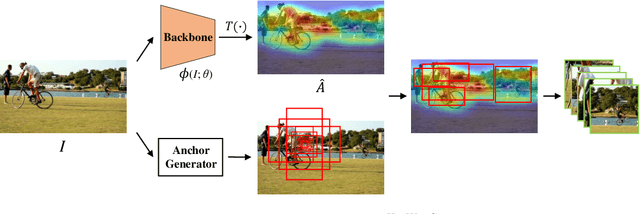
Most self-supervised learning (SSL) methods often work on curated datasets where the object-centric assumption holds. This assumption breaks down in uncurated images. Existing scene image SSL methods try to find the two views from original scene images that are well matched or dense, which is both complex and computationally heavy. This paper proposes a conceptually different pipeline: first find regions that are coarse objects (with adequate objectness), crop them out as pseudo object-centric images, then any SSL method can be directly applied as in a real object-centric dataset. That is, coarse crops benefits scene images SSL. A novel cropping strategy that produces coarse object box is proposed. The new pipeline and cropping strategy successfully learn quality features from uncurated datasets without ImageNet. Experiments show that our pipeline outperforms existing SSL methods (MoCo-v2, DenseCL and MAE) on classification, detection and segmentation tasks. We further conduct extensively ablations to verify that: 1) the pipeline do not rely on pretrained models; 2) the cropping strategy is better than existing object discovery methods; 3) our method is not sensitive to hyperparameters and data augmentations.