 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ladder: A software to label images, detect objects and deploy models recurrently for object detection
Jun 17, 2023
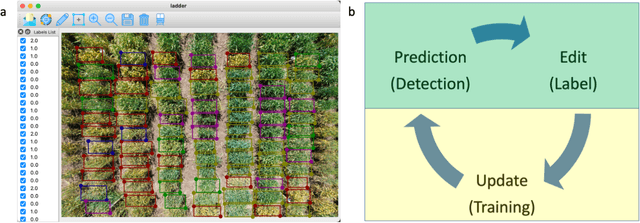
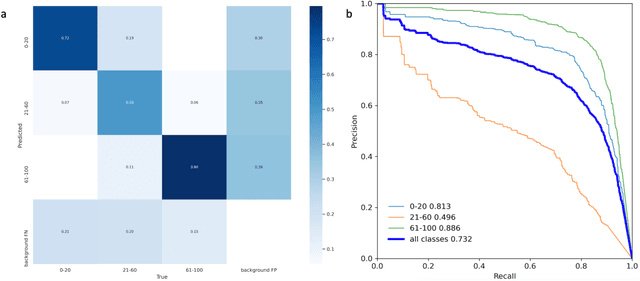
Object Detection (OD) is a computer vision technology that can locate and classify objects in images and videos, which has the potential to significantly improve efficiency in precision agriculture. To simplify OD application process, we developed Ladder - a software that provides users with a friendly graphic user interface (GUI) that allows for efficient labelling of training datasets, training OD models, and deploying the trained model. Ladder was designed with an interactive recurrent framework that leverages predictions from a pre-trained OD model as the initial image labeling. After adding human labels, the newly labeled images can be added into the training data to retrain the OD model. With the same GUI, users can also deploy well-trained OD models by loading the model weight file to detect new images. We used Ladder to develop a deep learning model to access wheat stripe rust in RGB (red, green, blue) images taken by an Unmanned Aerial Vehicle (UAV). Ladder employs OD to directly evaluate different severity levels of wheat stripe rust in field images, eliminating the need for photo stitching process for UAVs-based images. The accuracy for low, medium and high severity scores were 72%, 50% and 80%, respectively. This case demonstrates how Ladder empowers OD in precision agriculture and crop breeding.
GRILL: Grounded Vision-language Pre-training via Aligning Text and Image Regions
May 24, 2023
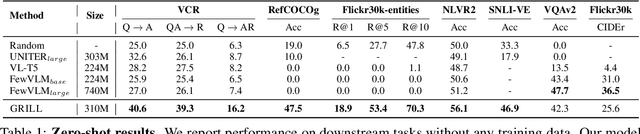
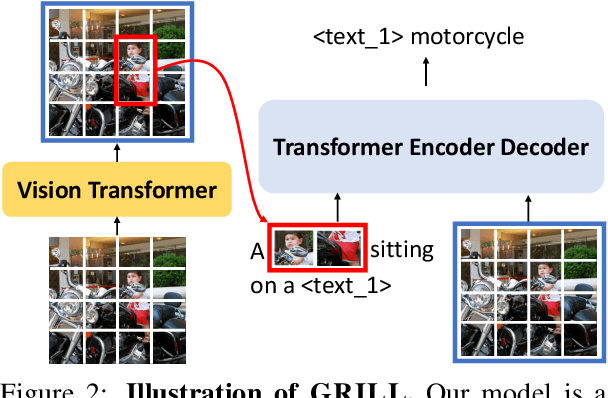

Generalization to unseen tasks is an important ability for few-shot learners to achieve better zero-/few-shot performance on diverse tasks. However, such generalization to vision-language tasks including grounding and generation tasks has been under-explored; existing few-shot VL models struggle to handle tasks that involve object grounding and multiple images such as visual commonsense reasoning or NLVR2. In this paper, we introduce GRILL, GRounded vIsion Language aLigning, a novel VL model that can be generalized to diverse tasks including visual question answering, captioning, and grounding tasks with no or very few training instances. Specifically, GRILL learns object grounding and localization by exploiting object-text alignments, which enables it to transfer to grounding tasks in a zero-/few-shot fashion. We evaluate our model on various zero-/few-shot VL tasks and show that it consistently surpasses the state-of-the-art few-shot methods.
AIMS: All-Inclusive Multi-Level Segmentation
May 28, 2023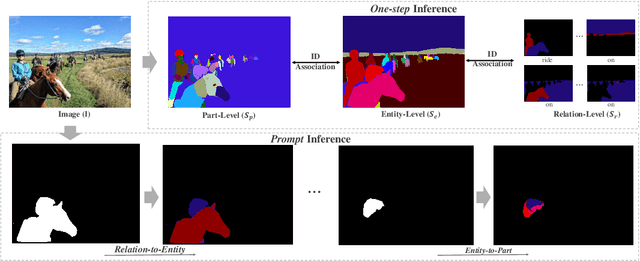

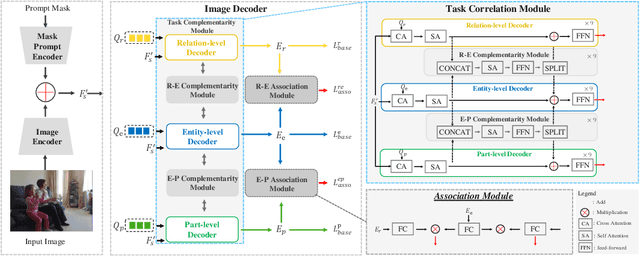

Despite the progress of image segmentation for accurate visual entity segmentation, completing the diverse requirements of image editing applications for different-level region-of-interest selections remains unsolved. In this paper, we propose a new task, All-Inclusive Multi-Level Segmentation (AIMS), which segments visual regions into three levels: part, entity, and relation (two entities with some semantic relationships). We also build a unified AIMS model through multi-dataset multi-task training to address the two major challenges of annotation inconsistency and task correlation. Specifically, we propose task complementarity, association, and prompt mask encoder for three-level predictions. Extensive experiments demonstrate the effectiveness and generalization capacity of our method compared to other state-of-the-art methods on a single dataset or the concurrent work on segmenting anything. We will make our code and training model publicly available.
Towards Monocular Shape from Refraction
May 31, 2023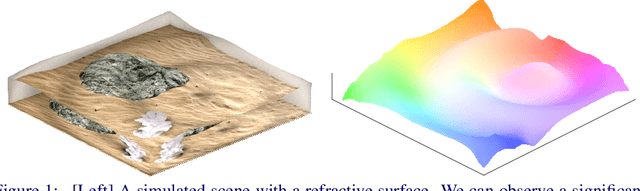
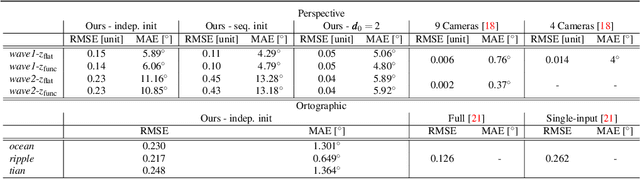
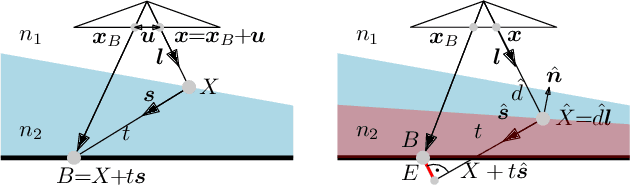
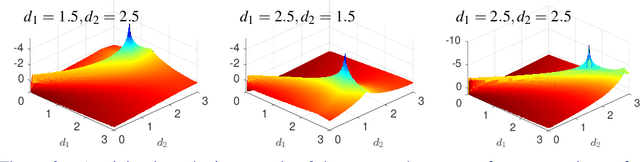
Refraction is a common physical phenomenon and has long been researched in computer vision. Objects imaged through a refractive object appear distorted in the image as a function of the shape of the interface between the media. This hinders many computer vision applications, but can be utilized for obtaining the geometry of the refractive interface. Previous approaches for refractive surface recovery largely relied on various priors or additional information like multiple images of the analyzed surface. In contrast, we claim that a simple energy function based on Snell's law enables the reconstruction of an arbitrary refractive surface geometry using just a single image and known background texture and geometry. In the case of a single point, Snell's law has two degrees of freedom, therefore to estimate a surface depth, we need additional information. We show that solving for an entire surface at once introduces implicit parameter-free spatial regularization and yields convincing results when an intelligent initial guess is provided. We demonstrate our approach through simulations and real-world experiments, where the reconstruction shows encouraging results in the single-frame monocular setting.
* 12 pages, 6 figures, The 32nd British Machine Vision Conference (BMVC)
Deep Ultrasound Denoising Using Diffusion Probabilistic Models
Jun 12, 2023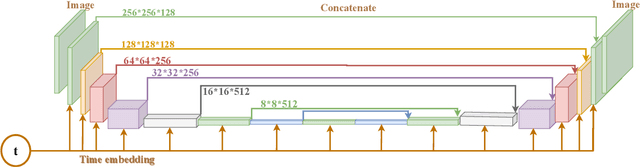
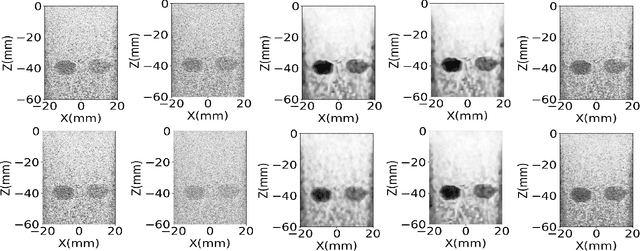

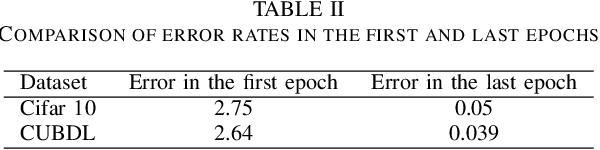
Ultrasound images are widespread in medical diagnosis for musculoskeletal, cardiac, and obstetrical imaging due to the efficiency and non-invasiveness of the acquisition methodology. However, the acquired images are degraded by acoustic (e.g. reverberation and clutter) and electronic sources of noise. To improve the Peak Signal to Noise Ratio (PSNR) of the images, previous denoising methods often remove the speckles, which could be informative for radiologists and also for quantitative ultrasound. Herein, a method based on the recent Denoising Diffusion Probabilistic Models (DDPM) is proposed. It iteratively enhances the image quality by eliminating the noise while preserving the speckle texture. It is worth noting that the proposed method is trained in a completely unsupervised manner, and no annotated data is required. The experimental blind test results show that our method outperforms the previous nonlocal means denoising methods in terms of PSNR and Generalized Contrast to Noise Ratio (GCNR) while preserving speckles.
Towards Robust Feature Learning with t-vFM Similarity for Continual Learning
Jun 04, 2023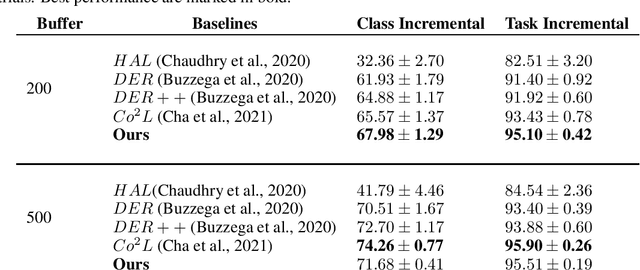
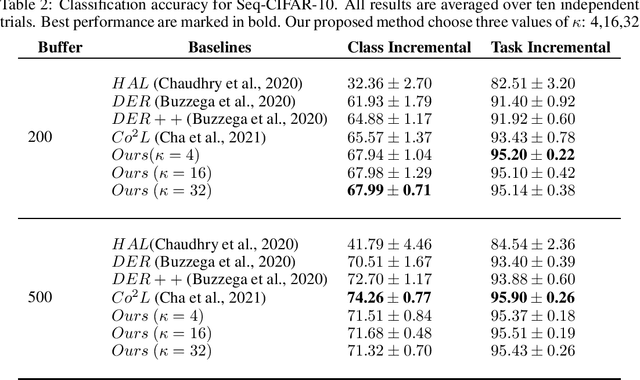
Continual learning has been developed using standard supervised contrastive loss from the perspective of feature learning. Due to the data imbalance during the training, there are still challenges in learning better representations. In this work, we suggest using a different similarity metric instead of cosine similarity in supervised contrastive loss in order to learn more robust representations. We validate the our method on one of the image classification datasets Seq-CIFAR-10 and the results outperform recent continual learning baselines.
Forget-Me-Not: Learning to Forget in Text-to-Image Diffusion Models
Mar 30, 2023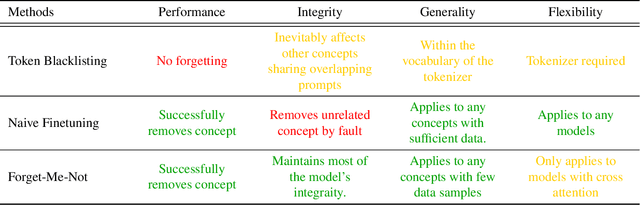
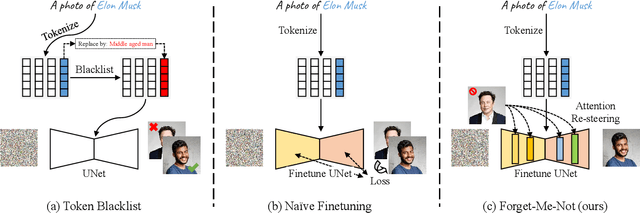
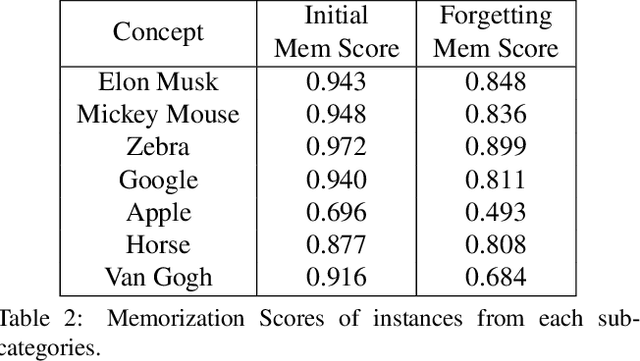
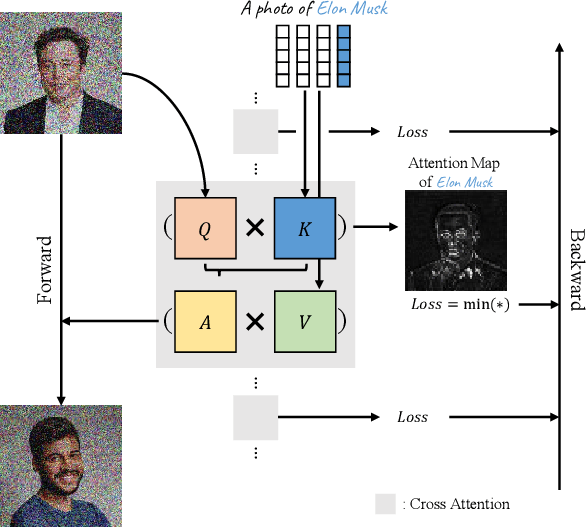
The unlearning problem of deep learning models, once primarily an academic concern, has become a prevalent issue in the industry. The significant advances in text-to-image generation techniques have prompted global discussions on privacy, copyright, and safety, as numerous unauthorized personal IDs, content, artistic creations, and potentially harmful materials have been learned by these models and later utilized to generate and distribute uncontrolled content. To address this challenge, we propose \textbf{Forget-Me-Not}, an efficient and low-cost solution designed to safely remove specified IDs, objects, or styles from a well-configured text-to-image model in as little as 30 seconds, without impairing its ability to generate other content. Alongside our method, we introduce the \textbf{Memorization Score (M-Score)} and \textbf{ConceptBench} to measure the models' capacity to generate general concepts, grouped into three primary categories: ID, object, and style. Using M-Score and ConceptBench, we demonstrate that Forget-Me-Not can effectively eliminate targeted concepts while maintaining the model's performance on other concepts. Furthermore, Forget-Me-Not offers two practical extensions: a) removal of potentially harmful or NSFW content, and b) enhancement of model accuracy, inclusion and diversity through \textbf{concept correction and disentanglement}. It can also be adapted as a lightweight model patch for Stable Diffusion, allowing for concept manipulation and convenient distribution. To encourage future research in this critical area and promote the development of safe and inclusive generative models, we will open-source our code and ConceptBench at \href{https://github.com/SHI-Labs/Forget-Me-Not}{https://github.com/SHI-Labs/Forget-Me-Not}.
Self-supervised 3D Human Pose Estimation from a Single Image
Apr 05, 2023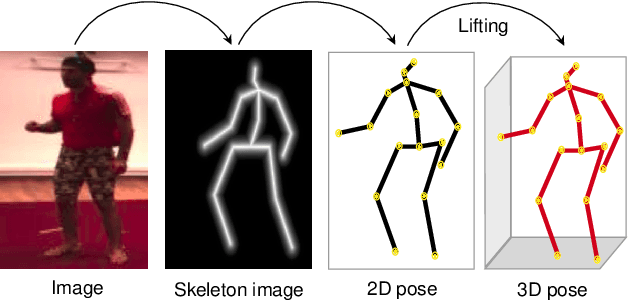
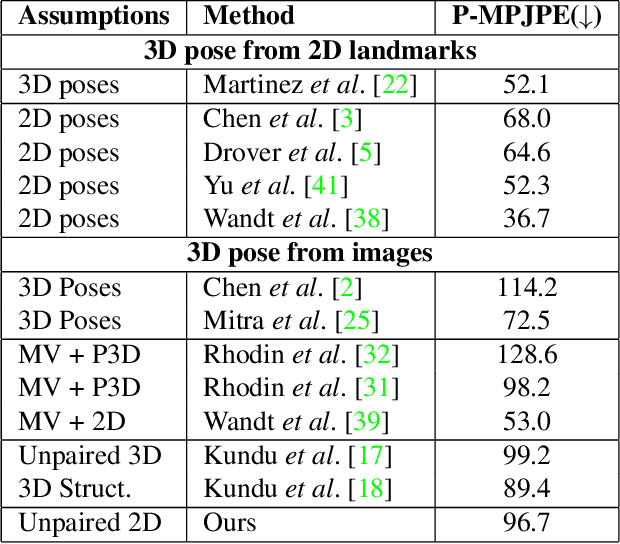

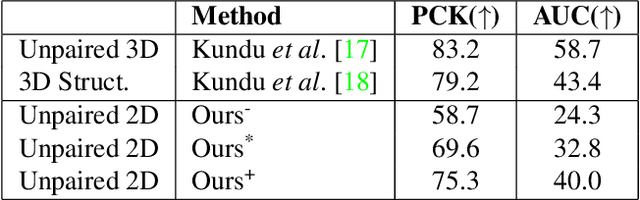
We propose a new self-supervised method for predicting 3D human body pose from a single image. The prediction network is trained from a dataset of unlabelled images depicting people in typical poses and a set of unpaired 2D poses. By minimising the need for annotated data, the method has the potential for rapid application to pose estimation of other articulated structures (e.g. animals). The self-supervision comes from an earlier idea exploiting consistency between predicted pose under 3D rotation. Our method is a substantial advance on state-of-the-art self-supervised methods in training a mapping directly from images, without limb articulation constraints or any 3D empirical pose prior. We compare performance with state-of-the-art self-supervised methods using benchmark datasets that provide images and ground-truth 3D pose (Human3.6M, MPI-INF-3DHP). Despite the reduced requirement for annotated data, we show that the method outperforms on Human3.6M and matches performance on MPI-INF-3DHP. Qualitative results on a dataset of human hands show the potential for rapidly learning to predict 3D pose for articulated structures other than the human body.
Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence
May 23, 2023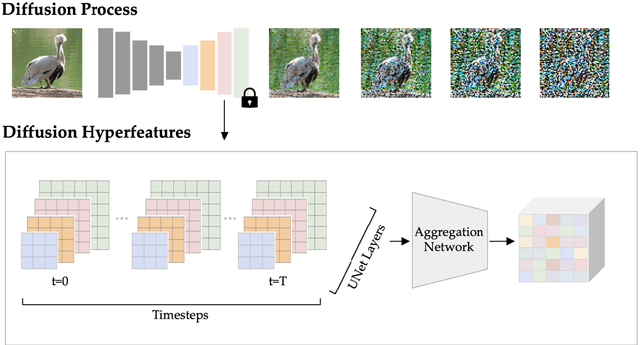
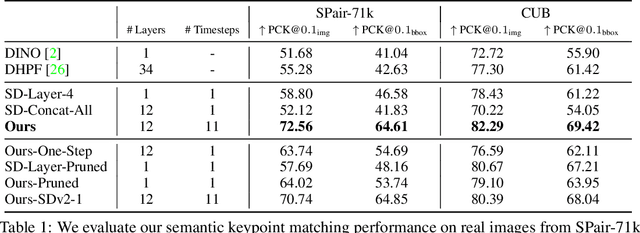
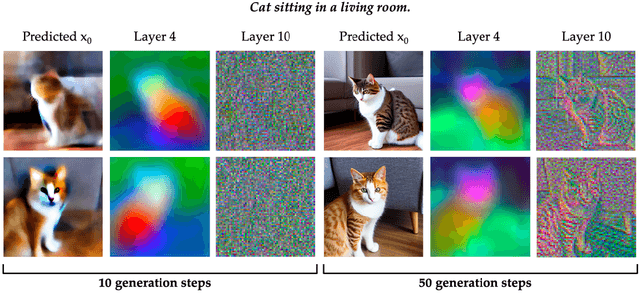
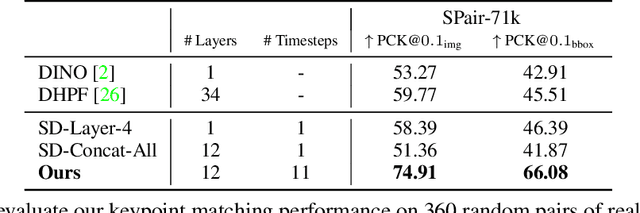
Diffusion models have been shown to be capable of generating high-quality images, suggesting that they could contain meaningful internal representations. Unfortunately, the feature maps that encode a diffusion model's internal information are spread not only over layers of the network, but also over diffusion timesteps, making it challenging to extract useful descriptors. We propose Diffusion Hyperfeatures, a framework for consolidating multi-scale and multi-timestep feature maps into per-pixel feature descriptors that can be used for downstream tasks. These descriptors can be extracted for both synthetic and real images using the generation and inversion processes. We evaluate the utility of our Diffusion Hyperfeatures on the task of semantic keypoint correspondence: our method achieves superior performance on the SPair-71k real image benchmark. We also demonstrate that our method is flexible and transferable: our feature aggregation network trained on the inversion features of real image pairs can be used on the generation features of synthetic image pairs with unseen objects and compositions. Our code is available at \url{https://diffusion-hyperfeatures.github.io}.
Generating Parametric BRDFs from Natural Language Descriptions
Jun 19, 2023
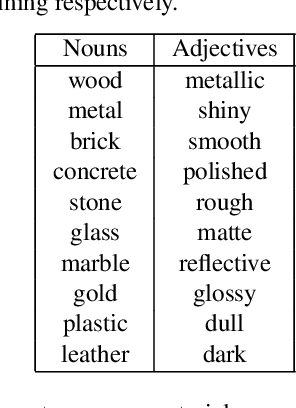
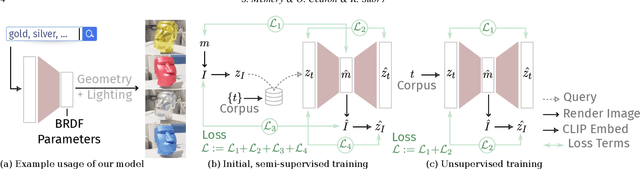
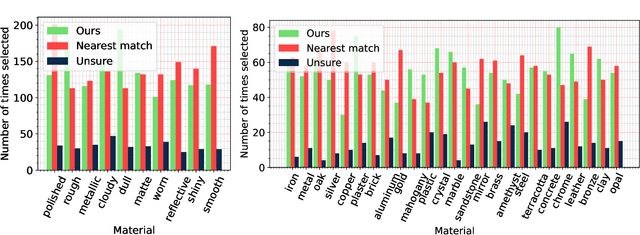
Artistic authoring of 3D environments is a laborious enterprise that also requires skilled content creators. There have been impressive improvements in using machine learning to address different aspects of generating 3D content, such as generating meshes, arranging geometry, synthesizing textures, etc. In this paper we develop a model to generate Bidirectional Reflectance Distribution Functions (BRDFs) from descriptive textual prompts. BRDFs are four dimensional probability distributions that characterize the interaction of light with surface materials. They are either represented parametrically, or by tabulating the probability density associated with every pair of incident and outgoing angles. The former lends itself to artistic editing while the latter is used when measuring the appearance of real materials. Numerous works have focused on hypothesizing BRDF models from images of materials. We learn a mapping from textual descriptions of materials to parametric BRDFs. Our model is first trained using a semi-supervised approach before being tuned via an unsupervised scheme. Although our model is general, in this paper we specifically generate parameters for MDL materials, conditioned on natural language descriptions, within NVIDIA's Omniverse platform. This enables use cases such as real-time text prompts to change materials of objects in 3D environments such as "dull plastic" or "shiny iron". Since the output of our model is a parametric BRDF, rather than an image of the material, it may be used to render materials using any shape under arbitrarily specified viewing and lighting conditions.