 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AURA : Automatic Mask Generator using Randomized Input Sampling for Object Removal
May 13, 2023

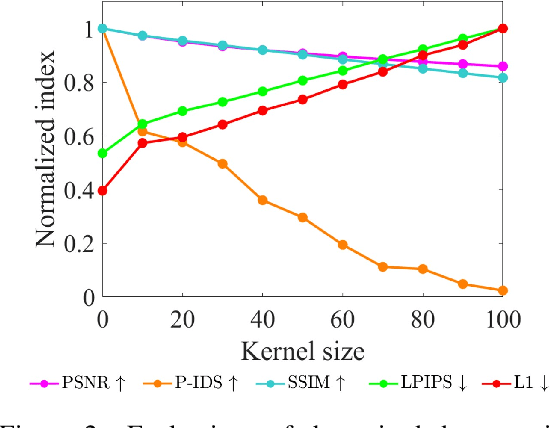
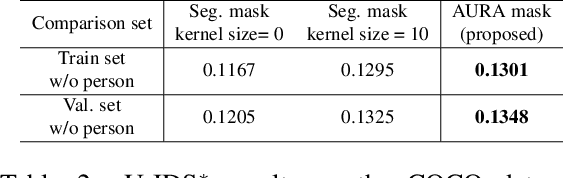
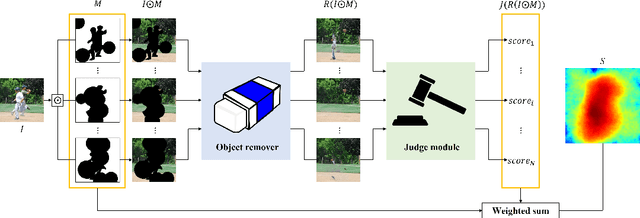
The objective of the image inpainting task is to fill missing regions of an image in a visually plausible way. Recently, deep-learning-based image inpainting networks have generated outstanding results, and some utilize their models as object removers by masking unwanted objects in an image. However, while trying to better remove objects using their networks, the previous works pay less attention to the importance of the input mask. In this paper, we focus on generating the input mask to better remove objects using the off-the-shelf image inpainting network. We propose an automatic mask generator inspired by the explainable AI (XAI) method, whose output can better remove objects than a semantic segmentation mask. The proposed method generates an importance map using randomly sampled input masks and quantitatively estimated scores of the completed images obtained from the random masks. The output mask is selected by a judge module among the candidate masks which are generated from the importance map. We design the judge module to quantitatively estimate the quality of the object removal results. In addition, we empirically find that the evaluation methods used in the previous works reporting object removal results are not appropriate for estimating the performance of an object remover. Therefore, we propose new evaluation metrics (FID$^*$ and U-IDS$^*$) to properly evaluate the quality of object removers. Experiments confirm that our method shows better performance in removing target class objects than the masks generated from the semantic segmentation maps, and the two proposed metrics make judgments consistent with humans.
STPDnet: Spatial-temporal convolutional primal dual network for dynamic PET image reconstruction
Mar 08, 2023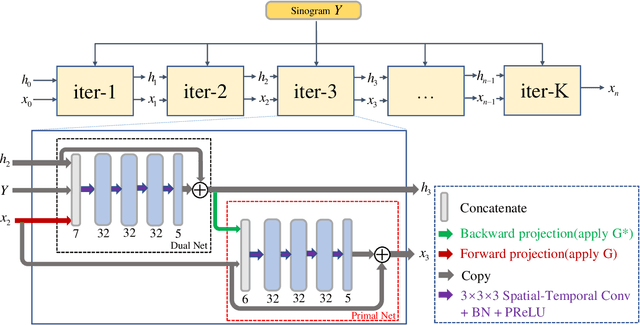
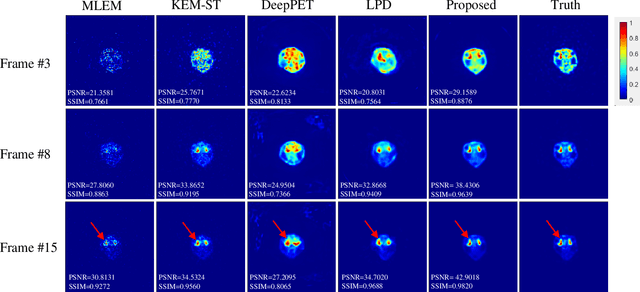
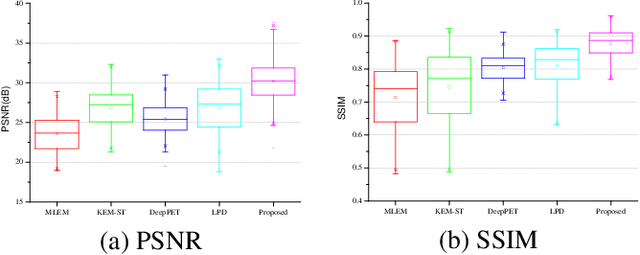
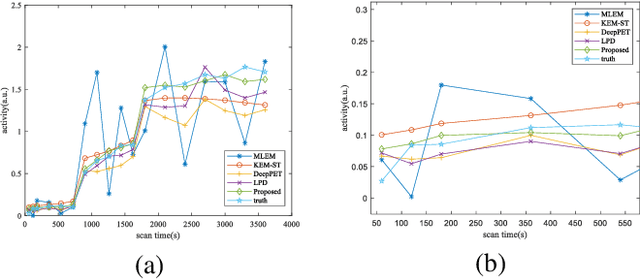
Dynamic positron emission tomography (dPET) image reconstruction is extremely challenging due to the limited counts received in individual frame. In this paper, we propose a spatial-temporal convolutional primal dual network (STPDnet) for dynamic PET image reconstruction. Both spatial and temporal correlations are encoded by 3D convolution operators. The physical projection of PET is embedded in the iterative learning process of the network, which provides the physical constraints and enhances interpretability. The experiments of real rat scan data have shown that the proposed method can achieve substantial noise reduction in both temporal and spatial domains and outperform the maximum likelihood expectation maximization (MLEM), spatial-temporal kernel method (KEM-ST), DeepPET and Learned Primal Dual (LPD).
Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancement
Mar 12, 2023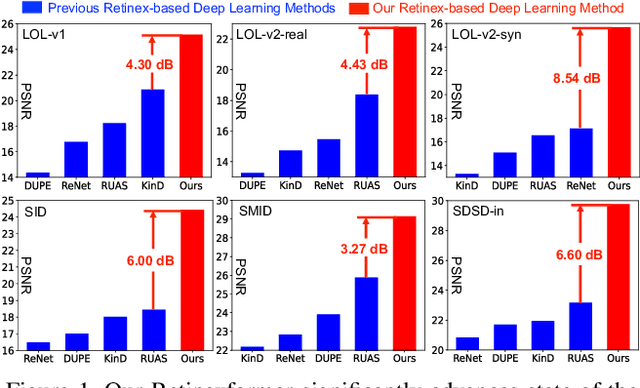
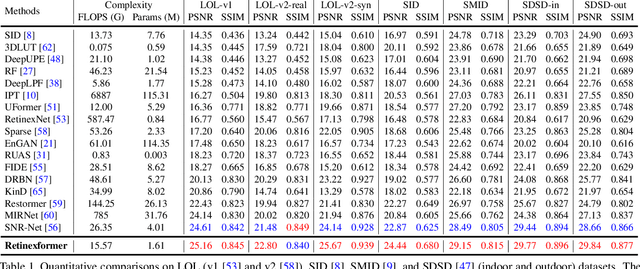
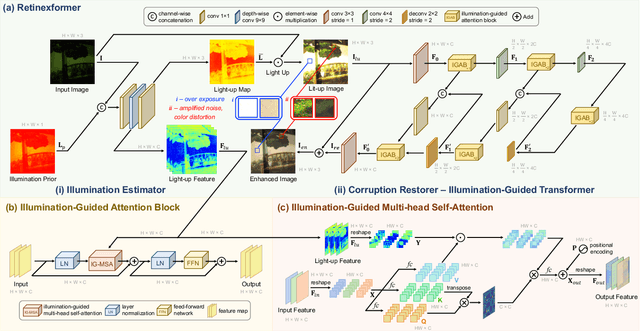
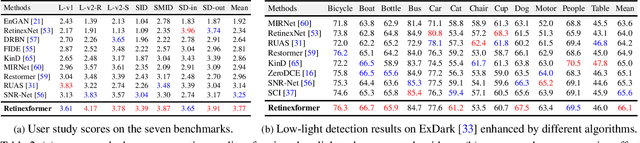
When enhancing low-light images, many deep learning algorithms are based on the Retinex theory. However, the Retinex model does not consider the corruptions hidden in the dark or introduced by the light-up process. Besides, these methods usually require a tedious multi-stage training pipeline and rely on convolutional neural networks, showing limitations in capturing long-range dependencies. In this paper, we formulate a simple yet principled One-stage Retinex-based Framework (ORF). ORF first estimates the illumination information to light up the low-light image and then restores the corruption to produce the enhanced image. We design an Illumination-Guided Transformer (IGT) that utilizes illumination representations to direct the modeling of non-local interactions of regions with different lighting conditions. By plugging IGT into ORF, we obtain our algorithm, Retinexformer. Comprehensive quantitative and qualitative experiments demonstrate that our Retinexformer significantly outperforms state-of-the-art methods on seven benchmarks. The user study and application on low-light object detection also reveal the latent practical values of our method. Codes and pre-trained models will be released.
BayeSeg: Bayesian Modeling for Medical Image Segmentation with Interpretable Generalizability
Mar 03, 2023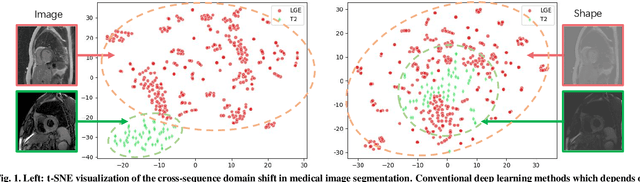
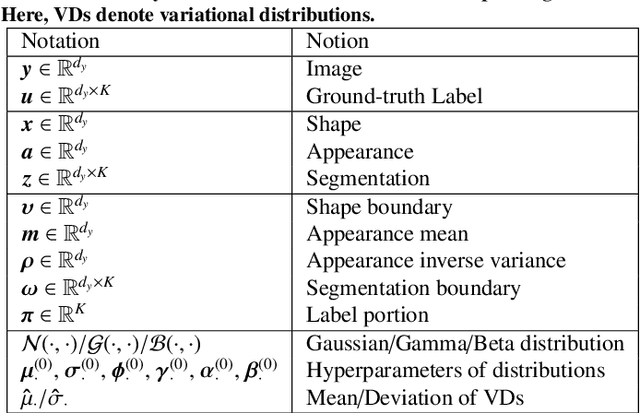
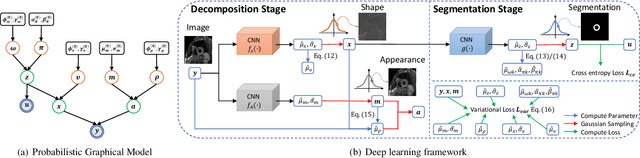

Due to the cross-domain distribution shift aroused from diverse medical imaging systems, many deep learning segmentation methods fail to perform well on unseen data, which limits their real-world applicability. Recent works have shown the benefits of extracting domain-invariant representations on domain generalization. However, the interpretability of domain-invariant features remains a great challenge. To address this problem, we propose an interpretable Bayesian framework (BayeSeg) through Bayesian modeling of image and label statistics to enhance model generalizability for medical image segmentation. Specifically, we first decompose an image into a spatial-correlated variable and a spatial-variant variable, assigning hierarchical Bayesian priors to explicitly force them to model the domain-stable shape and domain-specific appearance information respectively. Then, we model the segmentation as a locally smooth variable only related to the shape. Finally, we develop a variational Bayesian framework to infer the posterior distributions of these explainable variables. The framework is implemented with neural networks, and thus is referred to as deep Bayesian segmentation. Quantitative and qualitative experimental results on prostate segmentation and cardiac segmentation tasks have shown the effectiveness of our proposed method. Moreover, we investigated the interpretability of BayeSeg by explaining the posteriors and analyzed certain factors that affect the generalization ability through further ablation studies. Our code will be released via https://zmiclab.github.io/projects.html, once the manuscript is accepted for publication.
An Approach to Solving the Abstraction and Reasoning Corpus (ARC) Challenge
Jun 06, 2023

We utilise the power of Large Language Models (LLMs), in particular GPT4, to be prompt engineered into performing an arbitrary task. Here, we give the model some human priors via text, along with some typical procedures for solving the ARC tasks, and ask it to generate the i) broad description of the input-output relation, ii) detailed steps of the input-output mapping, iii) use the detailed steps to perform manipulation on the test input and derive the test output. The current GPT3.5/GPT4 prompt solves 2 out of 4 tested small ARC challenges (those with small grids of 8x8 and below). With tweaks to the prompt to make it more specific for the use case, it can solve more. We posit that when scaled to a multi-agent system with usage of past memory and equipped with an image interpretation tool via Visual Question Answering, we may actually be able to solve the majority of the ARC challenge
GEO-Bench: Toward Foundation Models for Earth Monitoring
Jun 06, 2023
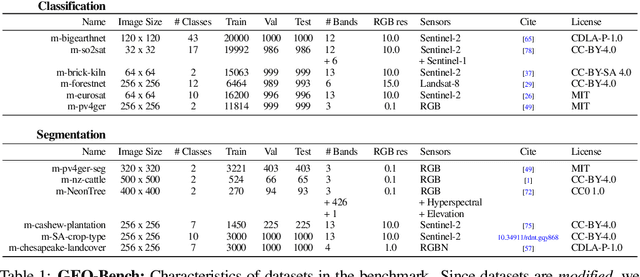

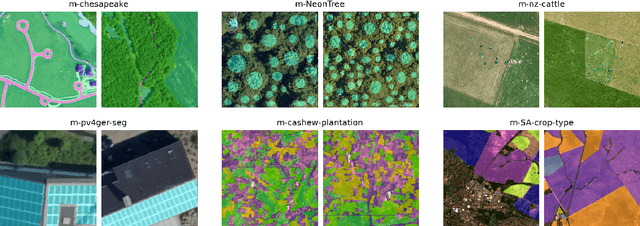
Recent progress in self-supervision has shown that pre-training large neural networks on vast amounts of unsupervised data can lead to substantial increases in generalization to downstream tasks. Such models, recently coined foundation models, have been transformational to the field of natural language processing. Variants have also been proposed for image data, but their applicability to remote sensing tasks is limited. To stimulate the development of foundation models for Earth monitoring, we propose a benchmark comprised of six classification and six segmentation tasks, which were carefully curated and adapted to be both relevant to the field and well-suited for model evaluation. We accompany this benchmark with a robust methodology for evaluating models and reporting aggregated results to enable a reliable assessment of progress. Finally, we report results for 20 baselines to gain information about the performance of existing models. We believe that this benchmark will be a driver of progress across a variety of Earth monitoring tasks.
Learning Human Mesh Recovery in 3D Scenes
Jun 06, 2023
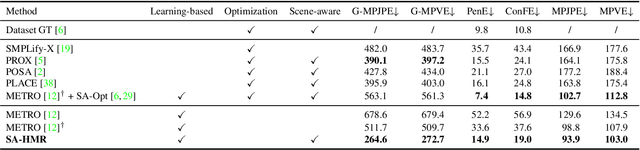
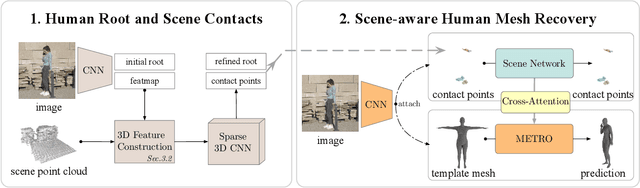
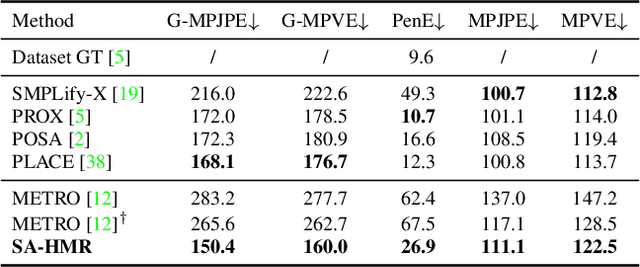
We present a novel method for recovering the absolute pose and shape of a human in a pre-scanned scene given a single image. Unlike previous methods that perform sceneaware mesh optimization, we propose to first estimate absolute position and dense scene contacts with a sparse 3D CNN, and later enhance a pretrained human mesh recovery network by cross-attention with the derived 3D scene cues. Joint learning on images and scene geometry enables our method to reduce the ambiguity caused by depth and occlusion, resulting in more reasonable global postures and contacts. Encoding scene-aware cues in the network also allows the proposed method to be optimization-free, and opens up the opportunity for real-time applications. The experiments show that the proposed network is capable of recovering accurate and physically-plausible meshes by a single forward pass and outperforms state-of-the-art methods in terms of both accuracy and speed.
DSI2I: Dense Style for Unpaired Image-to-Image Translation
Dec 29, 2022

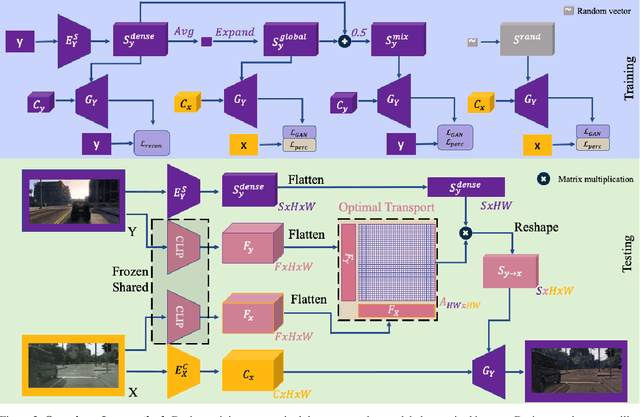

Unpaired exemplar-based image-to-image (UEI2I) translation aims to translate a source image to a target image domain with the style of a target image exemplar, without ground-truth input-translation pairs. Existing UEI2I methods represent style using either a global, image-level feature vector, or one vector per object instance/class but requiring knowledge of the scene semantics. Here, by contrast, we propose to represent style as a dense feature map, allowing for a finer-grained transfer to the source image without requiring any external semantic information. We then rely on perceptual and adversarial losses to disentangle our dense style and content representations, and exploit unsupervised cross-domain semantic correspondences to warp the exemplar style to the source content. We demonstrate the effectiveness of our method on two datasets using standard metrics together with a new localized style metric measuring style similarity in a class-wise manner. Our results evidence that the translations produced by our approach are more diverse and closer to the exemplars than those of the state-of-the-art methods while nonetheless preserving the source content.
PixMIM: Rethinking Pixel Reconstruction in Masked Image Modeling
Mar 04, 2023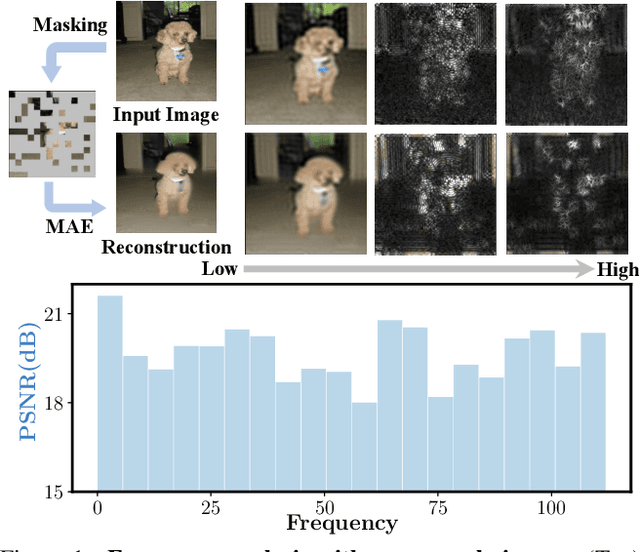


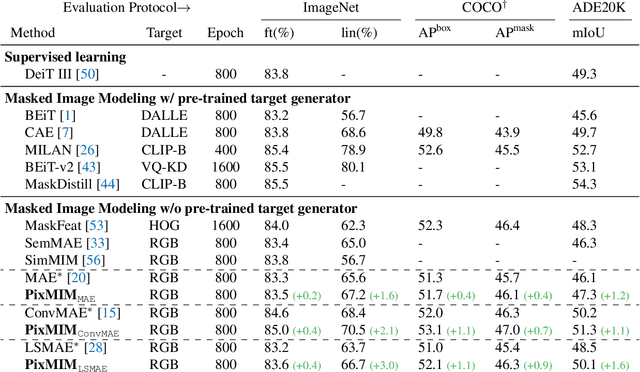
Masked Image Modeling (MIM) has achieved promising progress with the advent of Masked Autoencoders (MAE) and BEiT. However, subsequent works have complicated the framework with new auxiliary tasks or extra pre-trained models, inevitably increasing computational overhead. This paper undertakes a fundamental analysis of MIM from the perspective of pixel reconstruction, which examines the input image patches and reconstruction target, and highlights two critical but previously overlooked bottlenecks.Based on this analysis, we propose a remarkably simple and effective method, PixMIM, that entails two strategies: 1) filtering the high-frequency components from the reconstruction target to de-emphasize the network's focus on texture-rich details and 2) adopting a conservative data transform strategy to alleviate the problem of missing foreground in MIM training. PixMIM can be easily integrated into most existing pixel-based MIM approaches (i.e., using raw images as reconstruction target) with negligible additional computation. Without bells and whistles, our method consistently improves three MIM approaches, MAE, ConvMAE, and LSMAE, across various downstream tasks. We believe this effective plug-and-play method will serve as a strong baseline for self-supervised learning and provide insights for future improvements of the MIM framework. Code will be available at https://github.com/open-mmlab/mmselfsup.
Multimodal Garment Designer: Human-Centric Latent Diffusion Models for Fashion Image Editing
Apr 04, 2023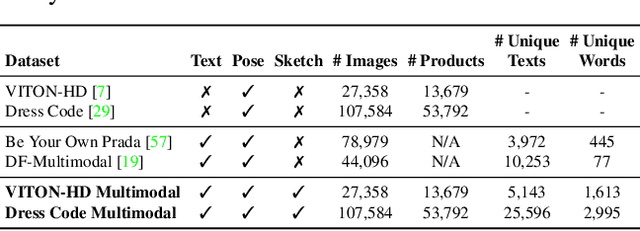
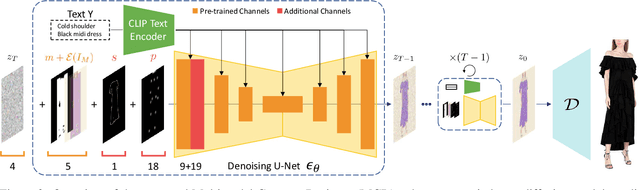
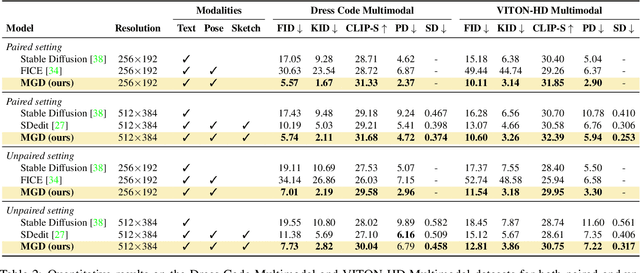

Fashion illustration is used by designers to communicate their vision and to bring the design idea from conceptualization to realization, showing how clothes interact with the human body. In this context, computer vision can thus be used to improve the fashion design process. Differently from previous works that mainly focused on the virtual try-on of garments, we propose the task of multimodal-conditioned fashion image editing, guiding the generation of human-centric fashion images by following multimodal prompts, such as text, human body poses, and garment sketches. We tackle this problem by proposing a new architecture based on latent diffusion models, an approach that has not been used before in the fashion domain. Given the lack of existing datasets suitable for the task, we also extend two existing fashion datasets, namely Dress Code and VITON-HD, with multimodal annotations collected in a semi-automatic manner. Experimental results on these new datasets demonstrate the effectiveness of our proposal, both in terms of realism and coherence with the given multimodal inputs. Source code and collected multimodal annotations will be publicly released at: https://github.com/aimagelab/multimodal-garment-designer.