 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Contrast, Attend and Diffuse to Decode High-Resolution Images from Brain Activities
May 26, 2023
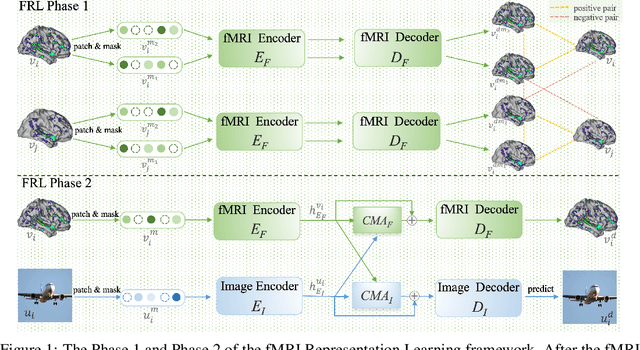
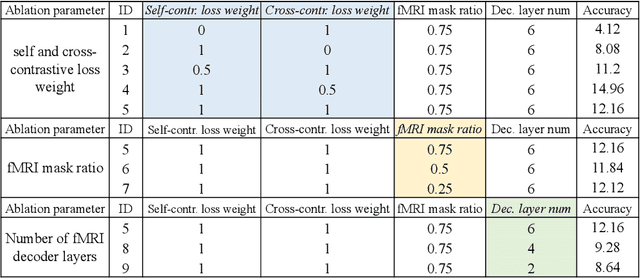
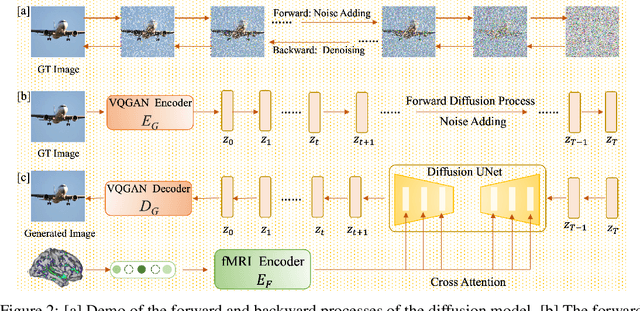
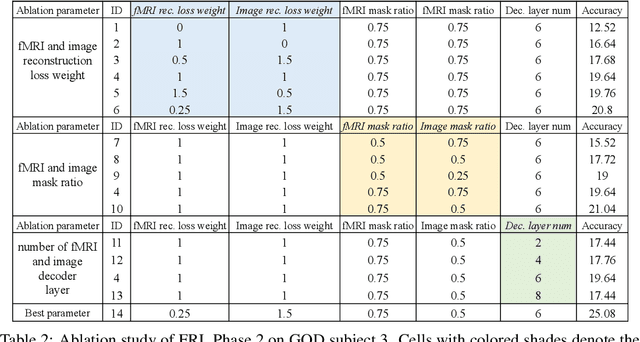
Decoding visual stimuli from neural responses recorded by functional Magnetic Resonance Imaging (fMRI) presents an intriguing intersection between cognitive neuroscience and machine learning, promising advancements in understanding human visual perception and building non-invasive brain-machine interfaces. However, the task is challenging due to the noisy nature of fMRI signals and the intricate pattern of brain visual representations. To mitigate these challenges, we introduce a two-phase fMRI representation learning framework. The first phase pre-trains an fMRI feature learner with a proposed Double-contrastive Mask Auto-encoder to learn denoised representations. The second phase tunes the feature learner to attend to neural activation patterns most informative for visual reconstruction with guidance from an image auto-encoder. The optimized fMRI feature learner then conditions a latent diffusion model to reconstruct image stimuli from brain activities. Experimental results demonstrate our model's superiority in generating high-resolution and semantically accurate images, substantially exceeding previous state-of-the-art methods by 39.34% in the 50-way-top-1 semantic classification accuracy. Our research invites further exploration of the decoding task's potential and contributes to the development of non-invasive brain-machine interfaces.
Combination of Single and Multi-frame Image Super-resolution: An Analytical Perspective
Mar 06, 2023Super-resolution is the process of obtaining a high-resolution image from one or more low-resolution images. Single image super-resolution (SISR) and multi-frame super-resolution (MFSR) methods have been evolved almost independently for years. A neglected study in this field is the theoretical analysis of finding the optimum combination of SISR and MFSR. To fill this gap, we propose a novel theoretical analysis based on the iterative shrinkage and thresholding algorithm. We implement and compare several approaches for combining SISR and MFSR, and simulation results support the finding of our theoretical analysis, both quantitatively and qualitatively.
Unlocking the Potential of Medical Imaging with ChatGPT's Intelligent Diagnostics
May 12, 2023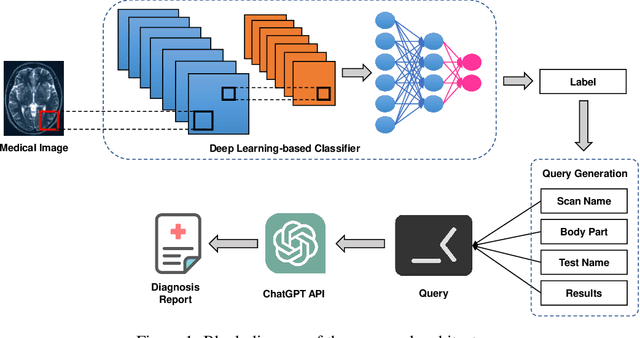
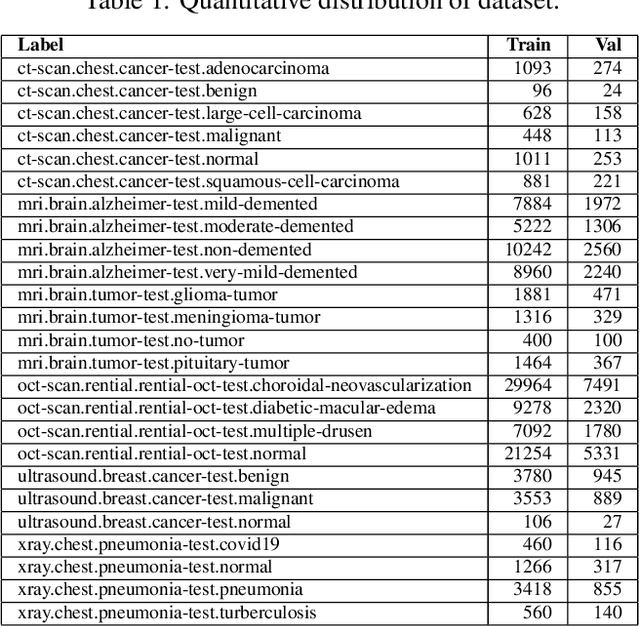
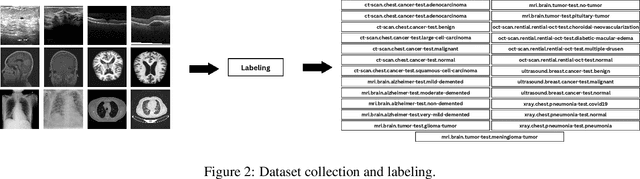
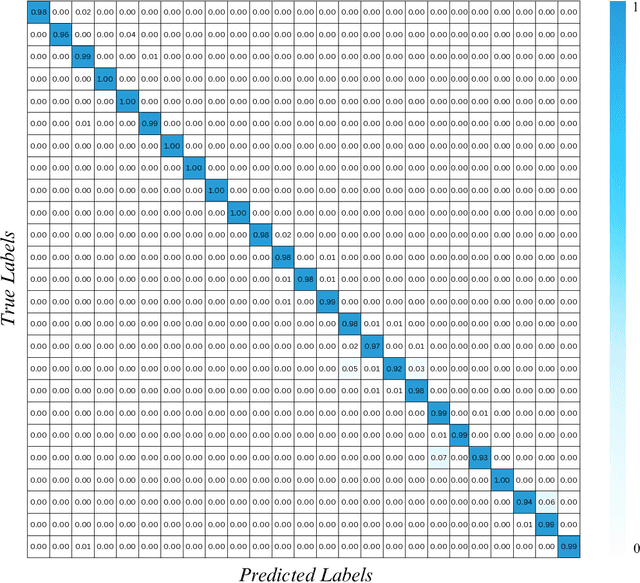
Medical imaging is an essential tool for diagnosing various healthcare diseases and conditions. However, analyzing medical images is a complex and time-consuming task that requires expertise and experience. This article aims to design a decision support system to assist healthcare providers and patients in making decisions about diagnosing, treating, and managing health conditions. The proposed architecture contains three stages: 1) data collection and labeling, 2) model training, and 3) diagnosis report generation. The key idea is to train a deep learning model on a medical image dataset to extract four types of information: the type of image scan, the body part, the test image, and the results. This information is then fed into ChatGPT to generate automatic diagnostics. The proposed system has the potential to enhance decision-making, reduce costs, and improve the capabilities of healthcare providers. The efficacy of the proposed system is analyzed by conducting extensive experiments on a large medical image dataset. The experimental outcomes exhibited promising performance for automatic diagnosis through medical images.
SAM-helps-Shadow:When Segment Anything Model meet shadow removal
Jun 01, 2023
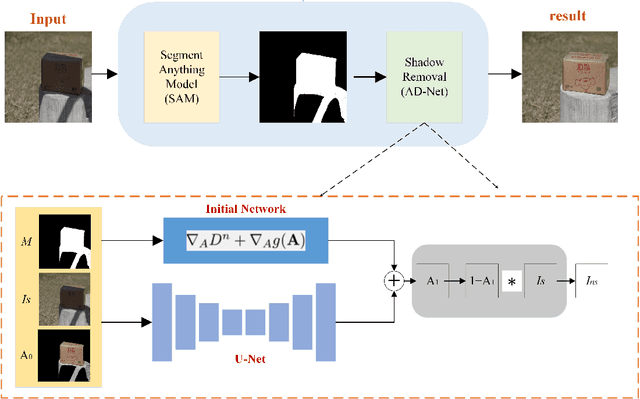


The challenges surrounding the application of image shadow removal to real-world images and not just constrained datasets like ISTD/SRD have highlighted an urgent need for zero-shot learning in this field. In this study, we innovatively adapted the SAM (Segment anything model) for shadow removal by introducing SAM-helps-Shadow, effectively integrating shadow detection and removal into a single stage. Our approach utilized the model's detection results as a potent prior for facilitating shadow detection, followed by shadow removal using a second-order deep unfolding network. The source code of SAM-helps-Shadow can be obtained from https://github.com/zhangbaijin/SAM-helps-Shadow.
Weakly-Supervised Visual-Textual Grounding with Semantic Prior Refinement
May 18, 2023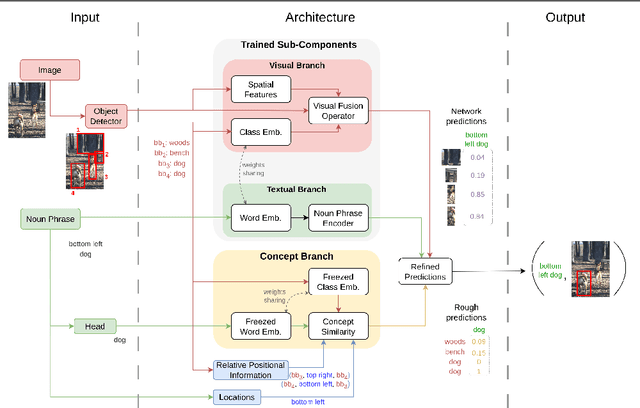
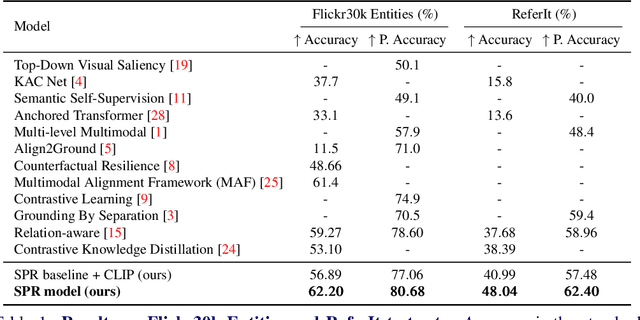
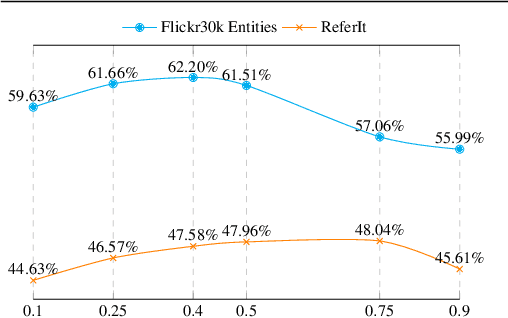
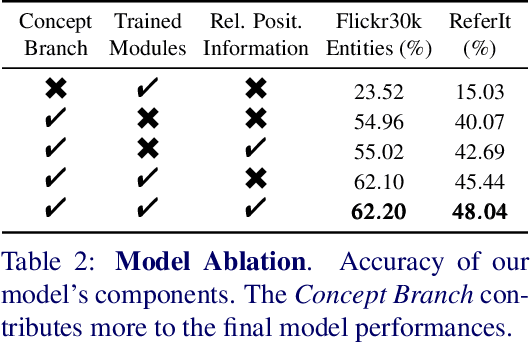
Using only image-sentence pairs, weakly-supervised visual-textual grounding aims to learn region-phrase correspondences of the respective entity mentions. Compared to the supervised approach, learning is more difficult since bounding boxes and textual phrases correspondences are unavailable. In light of this, we propose the Semantic Prior Refinement Model (SPRM), whose predictions are obtained by combining the output of two main modules. The first untrained module aims to return a rough alignment between textual phrases and bounding boxes. The second trained module is composed of two sub-components that refine the rough alignment to improve the accuracy of the final phrase-bounding box alignments. The model is trained to maximize the multimodal similarity between an image and a sentence, while minimizing the multimodal similarity of the same sentence and a new unrelated image, carefully selected to help the most during training. Our approach shows state-of-the-art results on two popular datasets, Flickr30k Entities and ReferIt, shining especially on ReferIt with a 9.6% absolute improvement. Moreover, thanks to the untrained component, it reaches competitive performances just using a small fraction of training examples.
Bias mitigation techniques in image classification: fair machine learning in human heritage collections
Mar 20, 2023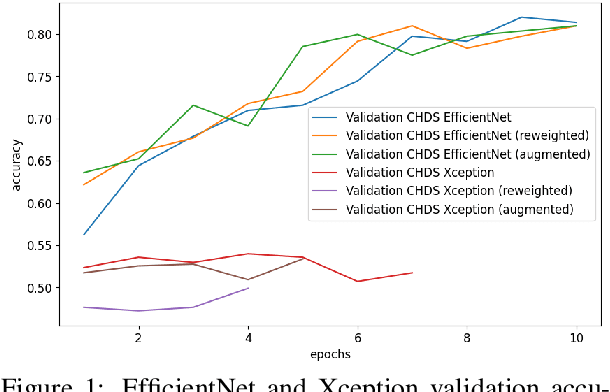
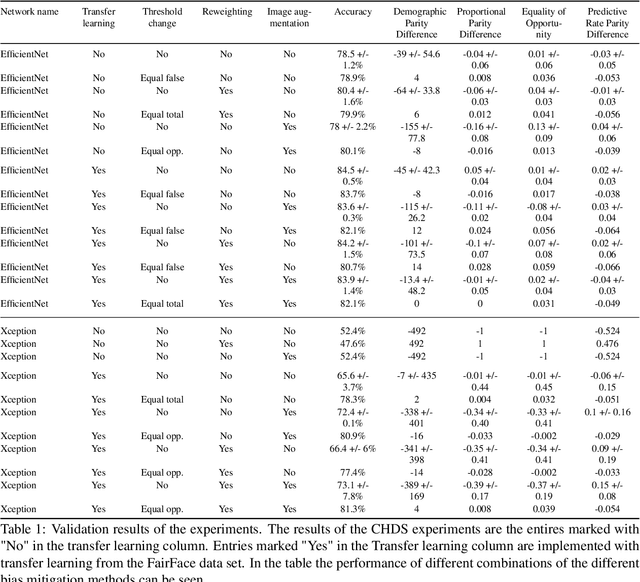
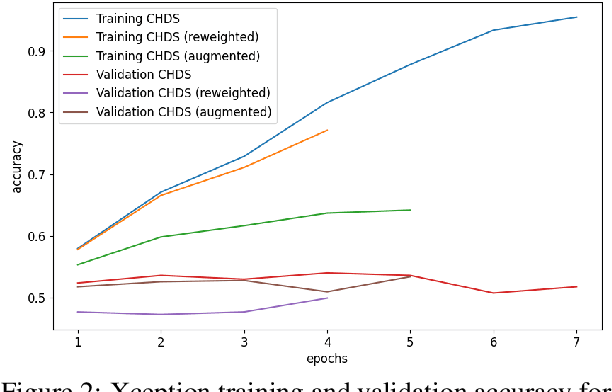
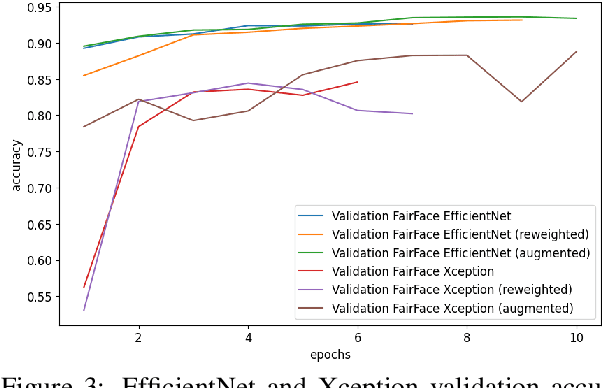
A major problem with using automated classification systems is that if they are not engineered correctly and with fairness considerations, they could be detrimental to certain populations. Furthermore, while engineers have developed cutting-edge technologies for image classification, there is still a gap in the application of these models in human heritage collections, where data sets usually consist of low-quality pictures of people with diverse ethnicity, gender, and age. In this work, we evaluate three bias mitigation techniques using two state-of-the-art neural networks, Xception and EfficientNet, for gender classification. Moreover, we explore the use of transfer learning using a fair data set to overcome the training data scarcity. We evaluated the effectiveness of the bias mitigation pipeline on a cultural heritage collection of photographs from the 19th and 20th centuries, and we used the FairFace data set for the transfer learning experiments. After the evaluation, we found that transfer learning is a good technique that allows better performance when working with a small data set. Moreover, the fairest classifier was found to be accomplished using transfer learning, threshold change, re-weighting and image augmentation as bias mitigation methods.
Instance-Aware Repeat Factor Sampling for Long-Tailed Object Detection
May 14, 2023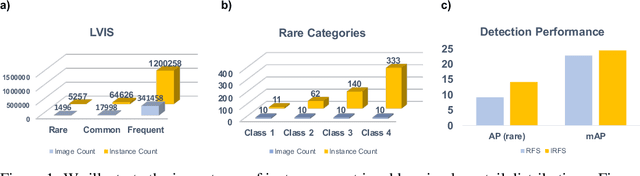
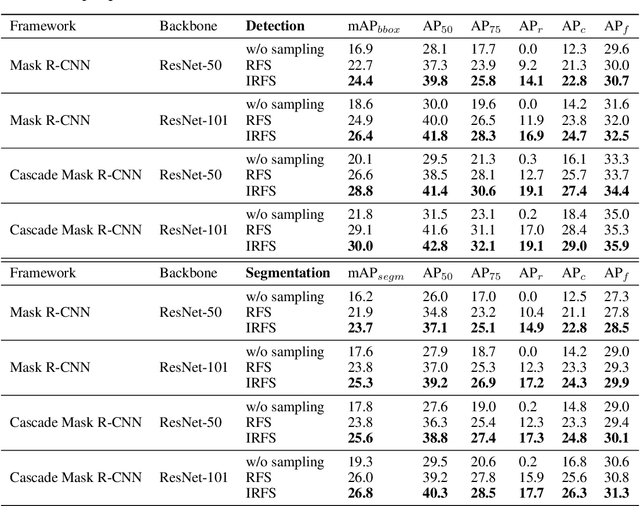

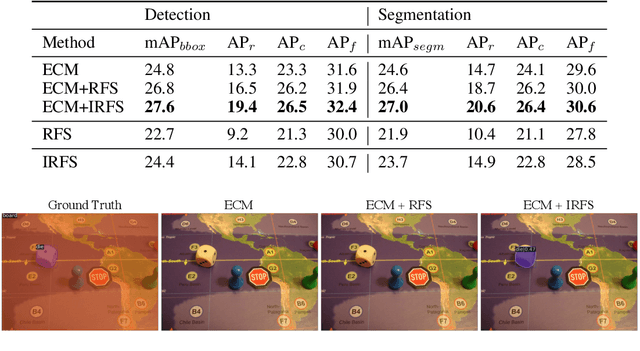
We propose an embarrassingly simple method -- instance-aware repeat factor sampling (IRFS) to address the problem of imbalanced data in long-tailed object detection. Imbalanced datasets in real-world object detection often suffer from a large disparity in the number of instances for each class. To improve the generalization performance of object detection models on rare classes, various data sampling techniques have been proposed. Repeat factor sampling (RFS) has shown promise due to its simplicity and effectiveness. Despite its efficiency, RFS completely neglects the instance counts and solely relies on the image count during re-sampling process. However, instance count may immensely vary for different classes with similar image counts. Such variation highlights the importance of both image and instance for addressing the long-tail distributions. Thus, we propose IRFS which unifies instance and image counts for the re-sampling process to be aware of different perspectives of the imbalance in long-tailed datasets. Our method shows promising results on the challenging LVIS v1.0 benchmark dataset over various architectures and backbones, demonstrating their effectiveness in improving the performance of object detection models on rare classes with a relative $+50\%$ average precision (AP) improvement over counterpart RFS. IRFS can serve as a strong baseline and be easily incorporated into existing long-tailed frameworks.
Urban-StyleGAN: Learning to Generate and Manipulate Images of Urban Scenes
May 16, 2023
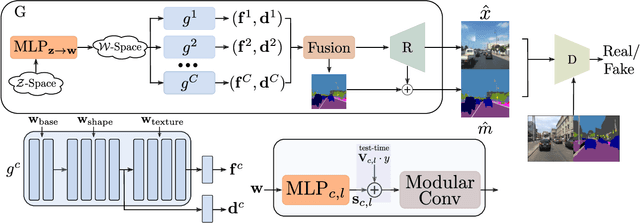
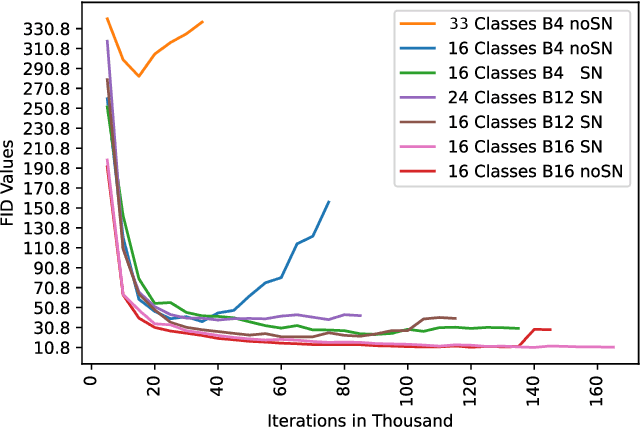
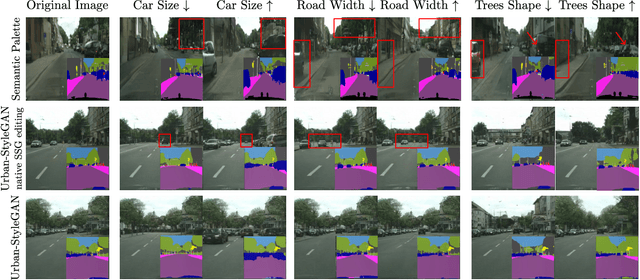
A promise of Generative Adversarial Networks (GANs) is to provide cheap photorealistic data for training and validating AI models in autonomous driving. Despite their huge success, their performance on complex images featuring multiple objects is understudied. While some frameworks produce high-quality street scenes with little to no control over the image content, others offer more control at the expense of high-quality generation. A common limitation of both approaches is the use of global latent codes for the whole image, which hinders the learning of independent object distributions. Motivated by SemanticStyleGAN (SSG), a recent work on latent space disentanglement in human face generation, we propose a novel framework, Urban-StyleGAN, for urban scene generation and manipulation. We find that a straightforward application of SSG leads to poor results because urban scenes are more complex than human faces. To provide a more compact yet disentangled latent representation, we develop a class grouping strategy wherein individual classes are grouped into super-classes. Moreover, we employ an unsupervised latent exploration algorithm in the $\mathcal{S}$-space of the generator and show that it is more efficient than the conventional $\mathcal{W}^{+}$-space in controlling the image content. Results on the Cityscapes and Mapillary datasets show the proposed approach achieves significantly more controllability and improved image quality than previous approaches on urban scenes and is on par with general-purpose non-controllable generative models (like StyleGAN2) in terms of quality.
STPDnet: Spatial-temporal convolutional primal dual network for dynamic PET image reconstruction
Mar 08, 2023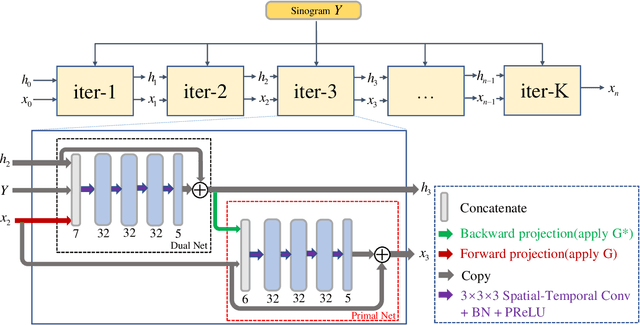
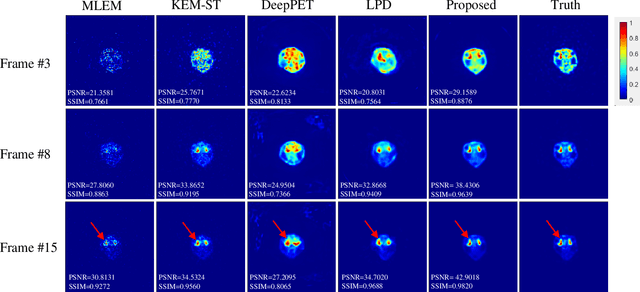
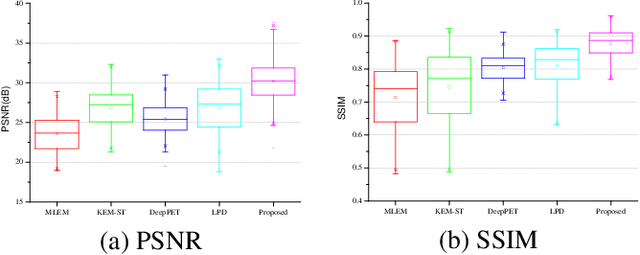
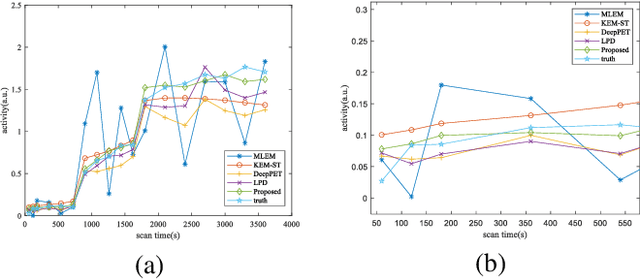
Dynamic positron emission tomography (dPET) image reconstruction is extremely challenging due to the limited counts received in individual frame. In this paper, we propose a spatial-temporal convolutional primal dual network (STPDnet) for dynamic PET image reconstruction. Both spatial and temporal correlations are encoded by 3D convolution operators. The physical projection of PET is embedded in the iterative learning process of the network, which provides the physical constraints and enhances interpretability. The experiments of real rat scan data have shown that the proposed method can achieve substantial noise reduction in both temporal and spatial domains and outperform the maximum likelihood expectation maximization (MLEM), spatial-temporal kernel method (KEM-ST), DeepPET and Learned Primal Dual (LPD).
Contrastive Learning for Predicting Cancer Prognosis Using Gene Expression Values
Jun 09, 2023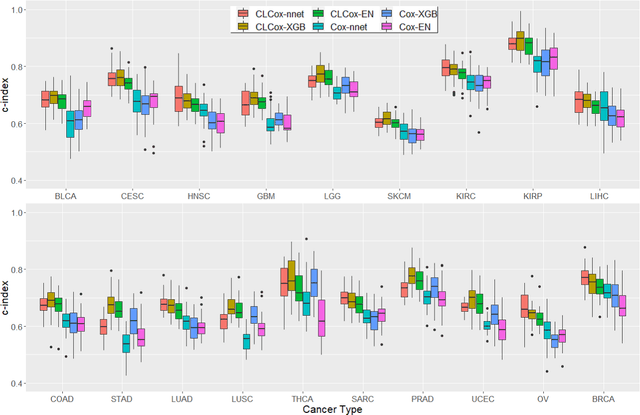
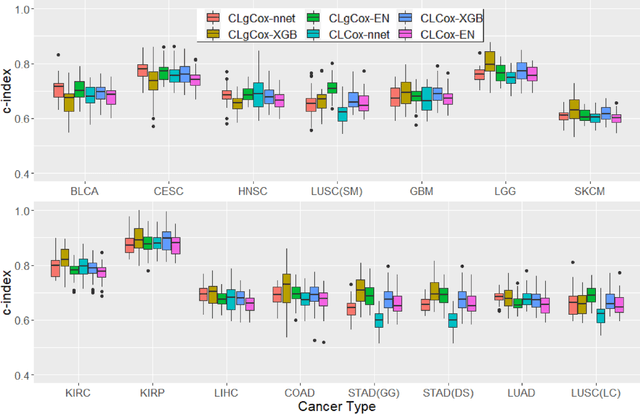
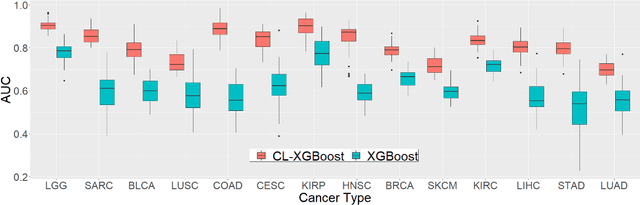
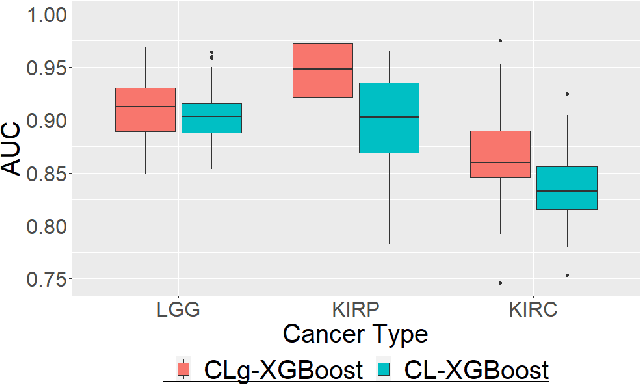
Several artificial neural networks (ANNs) have recently been developed as the Cox proportional hazard model for predicting cancer prognosis based on tumor transcriptome. However, they have not demonstrated significantly better performance than the traditional Cox regression with regularization. Training an ANN with high prediction power is challenging in the presence of a limited number of data samples and a high-dimensional feature space. Recent advancements in image classification have shown that contrastive learning can facilitate further learning tasks by learning good feature representation from a limited number of data samples. In this paper, we applied supervised contrastive learning to tumor gene expression and clinical data to learn feature representations in a low-dimensional space. We then used these learned features to train the Cox model for predicting cancer prognosis. Using data from The Cancer Genome Atlas (TCGA), we demonstrated that our contrastive learning-based Cox model (CLCox) significantly outperformed existing methods in predicting the prognosis of 18 types of cancer under consideration. We also developed contrastive learning-based classifiers to classify tumors into different risk groups and showed that contrastive learning can significantly improve classification accuracy.