 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffHand: End-to-End Hand Mesh Reconstruction via Diffusion Models
May 23, 2023
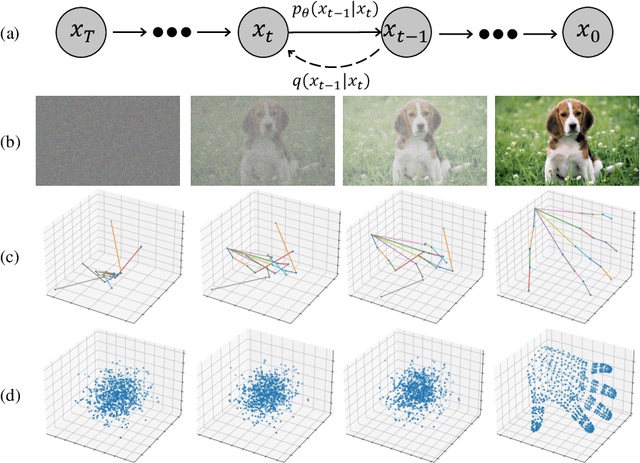
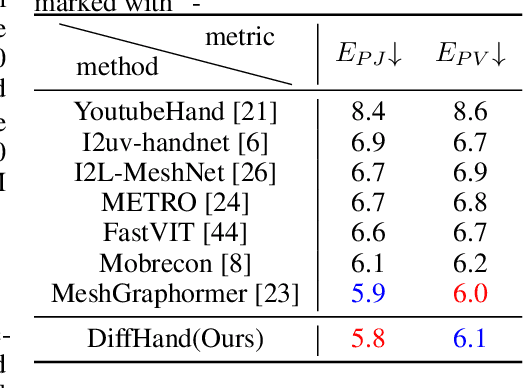
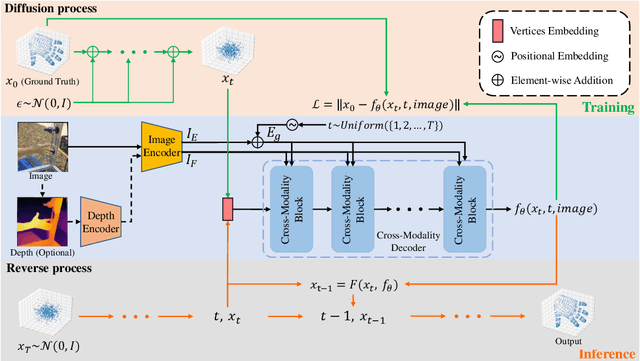
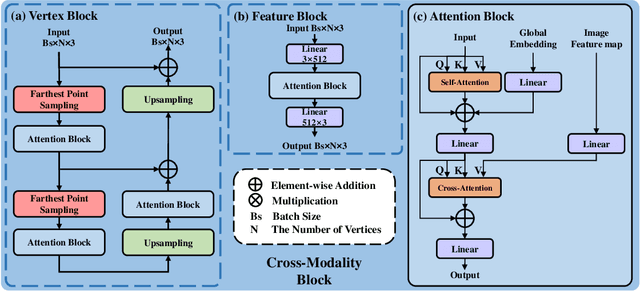
Hand mesh reconstruction from the monocular image is a challenging task due to its depth ambiguity and severe occlusion, there remains a non-unique mapping between the monocular image and hand mesh. To address this, we develop DiffHand, the first diffusion-based framework that approaches hand mesh reconstruction as a denoising diffusion process. Our one-stage pipeline utilizes noise to model the uncertainty distribution of the intermediate hand mesh in a forward process. We reformulate the denoising diffusion process to gradually refine noisy hand mesh and then select mesh with the highest probability of being correct based on the image itself, rather than relying on 2D joints extracted beforehand. To better model the connectivity of hand vertices, we design a novel network module called the cross-modality decoder. Extensive experiments on the popular benchmarks demonstrate that our method outperforms the state-of-the-art hand mesh reconstruction approaches by achieving 5.8mm PA-MPJPE on the Freihand test set, 4.98mm PA-MPJPE on the DexYCB test set.
Improving Zero-Shot Detection of Low Prevalence Chest Pathologies using Domain Pre-trained Language Models
Jun 13, 2023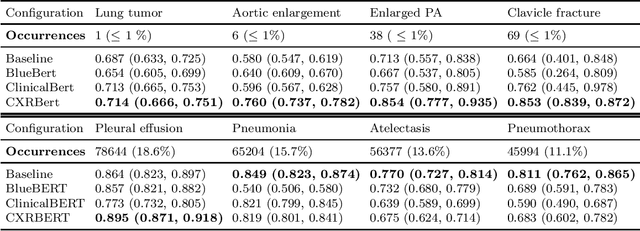
Recent advances in zero-shot learning have enabled the use of paired image-text data to replace structured labels, replacing the need for expert annotated datasets. Models such as CLIP-based CheXzero utilize these advancements in the domain of chest X-ray interpretation. We hypothesize that domain pre-trained models such as CXR-BERT, BlueBERT, and ClinicalBERT offer the potential to improve the performance of CLIP-like models with specific domain knowledge by replacing BERT weights at the cost of breaking the original model's alignment. We evaluate the performance of zero-shot classification models with domain-specific pre-training for detecting low-prevalence pathologies. Even though replacing the weights of the original CLIP-BERT degrades model performance on commonly found pathologies, we show that pre-trained text towers perform exceptionally better on low-prevalence diseases. This motivates future ensemble models with a combination of differently trained language models for maximal performance.
TaleCrafter: Interactive Story Visualization with Multiple Characters
May 30, 2023

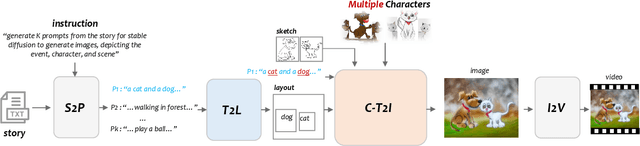
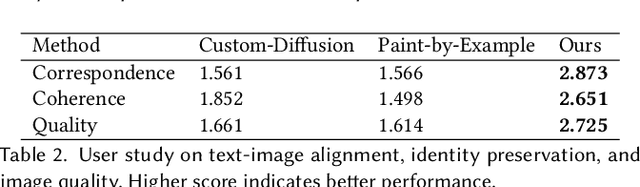
Accurate Story visualization requires several necessary elements, such as identity consistency across frames, the alignment between plain text and visual content, and a reasonable layout of objects in images. Most previous works endeavor to meet these requirements by fitting a text-to-image (T2I) model on a set of videos in the same style and with the same characters, e.g., the FlintstonesSV dataset. However, the learned T2I models typically struggle to adapt to new characters, scenes, and styles, and often lack the flexibility to revise the layout of the synthesized images. This paper proposes a system for generic interactive story visualization, capable of handling multiple novel characters and supporting the editing of layout and local structure. It is developed by leveraging the prior knowledge of large language and T2I models, trained on massive corpora. The system comprises four interconnected components: story-to-prompt generation (S2P), text-to-layout generation (T2L), controllable text-to-image generation (C-T2I), and image-to-video animation (I2V). First, the S2P module converts concise story information into detailed prompts required for subsequent stages. Next, T2L generates diverse and reasonable layouts based on the prompts, offering users the ability to adjust and refine the layout to their preference. The core component, C-T2I, enables the creation of images guided by layouts, sketches, and actor-specific identifiers to maintain consistency and detail across visualizations. Finally, I2V enriches the visualization process by animating the generated images. Extensive experiments and a user study are conducted to validate the effectiveness and flexibility of interactive editing of the proposed system.
BlindHarmony: "Blind" Harmonization for MR Images via Flow model
May 18, 2023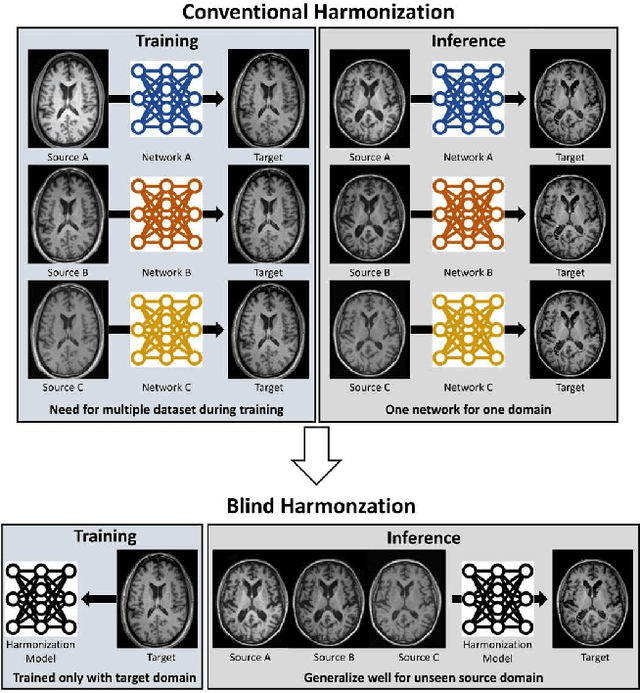
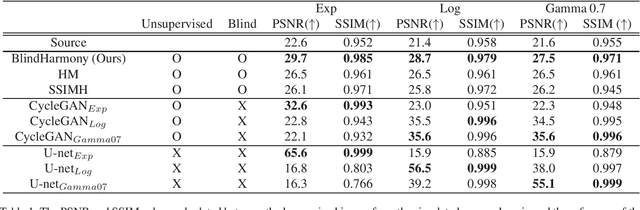
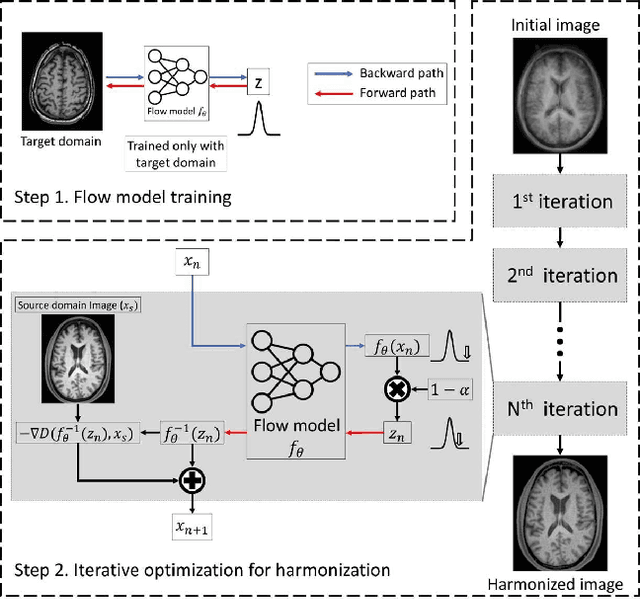
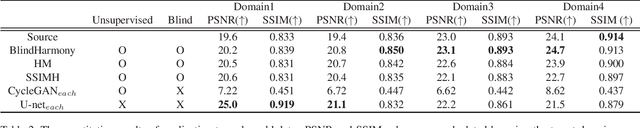
In MRI, images of the same contrast (e.g., T1) from the same subject can show noticeable differences when acquired using different hardware, sequences, or scan parameters. These differences in images create a domain gap that needs to be bridged by a step called image harmonization, in order to process the images successfully using conventional or deep learning-based image analysis (e.g., segmentation). Several methods, including deep learning-based approaches, have been proposed to achieve image harmonization. However, they often require datasets of multiple characteristics for deep learning training and may still be unsuccessful when applied to images of an unseen domain. To address this limitation, we propose a novel concept called "Blind Harmonization," which utilizes only target domain data for training but still has the capability of harmonizing unseen domain images. For the implementation of Blind Harmonization, we developed BlindHarmony using an unconditional flow model trained on target domain data. The harmonized image is optimized to have a correlation with the input source domain image while ensuring that the latent vector of the flow model is close to the center of the Gaussian. BlindHarmony was evaluated using simulated and real datasets and compared with conventional methods. BlindHarmony achieved a noticeable performance in both datasets, highlighting its potential for future use in clinical settings.
PV2TEA: Patching Visual Modality to Textual-Established Information Extraction
Jun 01, 2023

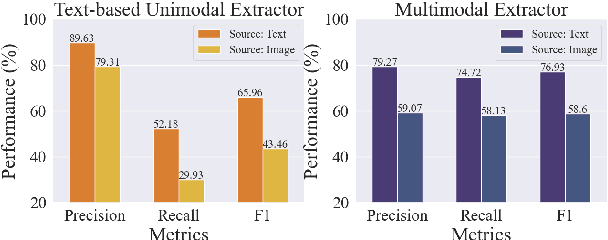
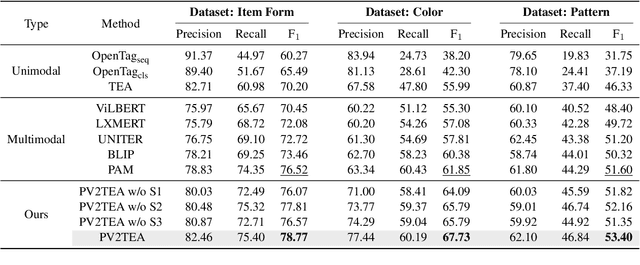
Information extraction, e.g., attribute value extraction, has been extensively studied and formulated based only on text. However, many attributes can benefit from image-based extraction, like color, shape, pattern, among others. The visual modality has long been underutilized, mainly due to multimodal annotation difficulty. In this paper, we aim to patch the visual modality to the textual-established attribute information extractor. The cross-modality integration faces several unique challenges: (C1) images and textual descriptions are loosely paired intra-sample and inter-samples; (C2) images usually contain rich backgrounds that can mislead the prediction; (C3) weakly supervised labels from textual-established extractors are biased for multimodal training. We present PV2TEA, an encoder-decoder architecture equipped with three bias reduction schemes: (S1) Augmented label-smoothed contrast to improve the cross-modality alignment for loosely-paired image and text; (S2) Attention-pruning that adaptively distinguishes the visual foreground; (S3) Two-level neighborhood regularization that mitigates the label textual bias via reliability estimation. Empirical results on real-world e-Commerce datasets demonstrate up to 11.74% absolute (20.97% relatively) F1 increase over unimodal baselines.
FreeSeg: Unified, Universal and Open-Vocabulary Image Segmentation
Mar 30, 2023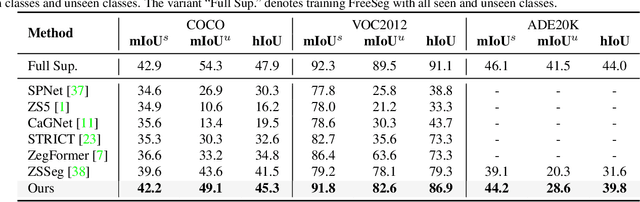
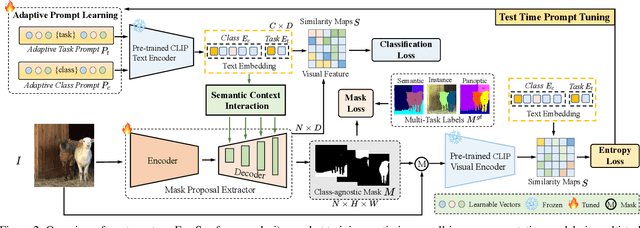

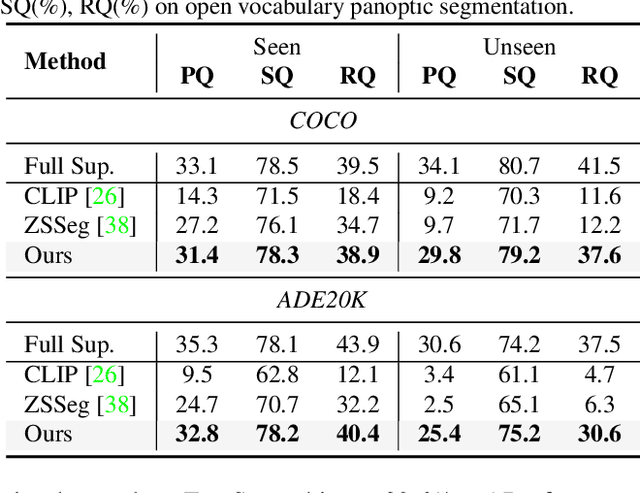
Recently, open-vocabulary learning has emerged to accomplish segmentation for arbitrary categories of text-based descriptions, which popularizes the segmentation system to more general-purpose application scenarios. However, existing methods devote to designing specialized architectures or parameters for specific segmentation tasks. These customized design paradigms lead to fragmentation between various segmentation tasks, thus hindering the uniformity of segmentation models. Hence in this paper, we propose FreeSeg, a generic framework to accomplish Unified, Universal and Open-Vocabulary Image Segmentation. FreeSeg optimizes an all-in-one network via one-shot training and employs the same architecture and parameters to handle diverse segmentation tasks seamlessly in the inference procedure. Additionally, adaptive prompt learning facilitates the unified model to capture task-aware and category-sensitive concepts, improving model robustness in multi-task and varied scenarios. Extensive experimental results demonstrate that FreeSeg establishes new state-of-the-art results in performance and generalization on three segmentation tasks, which outperforms the best task-specific architectures by a large margin: 5.5% mIoU on semantic segmentation, 17.6% mAP on instance segmentation, 20.1% PQ on panoptic segmentation for the unseen class on COCO.
A Coarse to Fine Framework for Object Detection in High Resolution Image
Mar 02, 2023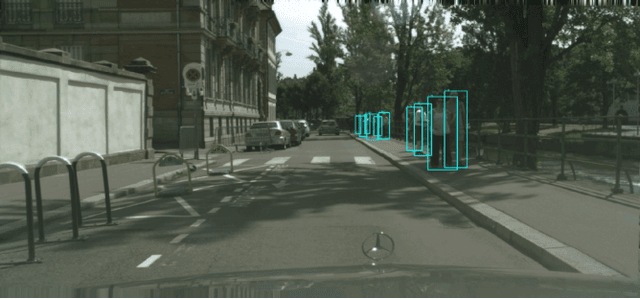
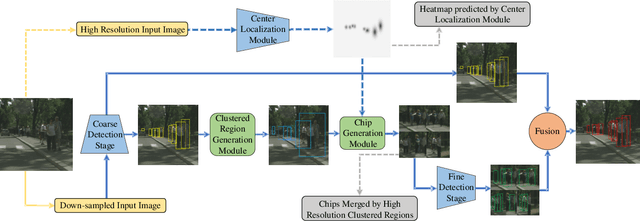
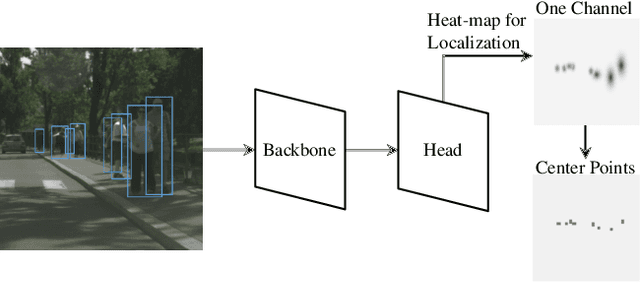
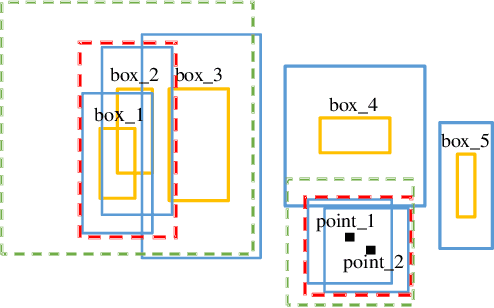
Object detection is a fundamental problem in computer vision, aiming at locating and classifying objects in image. Although current devices can easily take very high-resolution images, current approaches of object detection seldom consider detecting tiny object or the large scale variance problem in high resolution images. In this paper, we introduce a simple yet efficient approach that improves accuracy of object detection especially for small objects and large scale variance scene while reducing the computational cost in high resolution image. Inspired by observing that overall detection accuracy is reduced if the image is properly down-sampled but the recall rate is not significantly reduced. Besides, small objects can be better detected by inputting high-resolution images even if using lightweight detector. We propose a cluster-based coarse-to-fine object detection framework to enhance the performance for detecting small objects while ensure the accuracy of large objects in high-resolution images. For the first stage, we perform coarse detection on the down-sampled image and center localization of small objects by lightweight detector on high-resolution image, and then obtains image chips based on cluster region generation method by coarse detection and center localization results, and further sends chips to the second stage detector for fine detection. Finally, we merge the coarse detection and fine detection results. Our approach can make good use of the sparsity of the objects and the information in high-resolution image, thereby making the detection more efficient. Experiment results show that our proposed approach achieves promising performance compared with other state-of-the-art detectors.
Comparing the Efficacy of Fine-Tuning and Meta-Learning for Few-Shot Policy Imitation
Jun 23, 2023
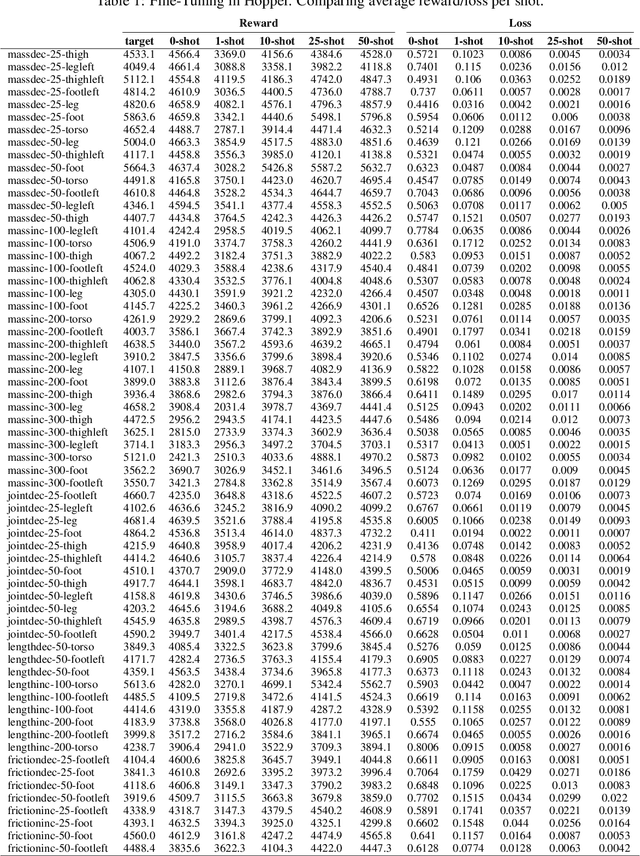
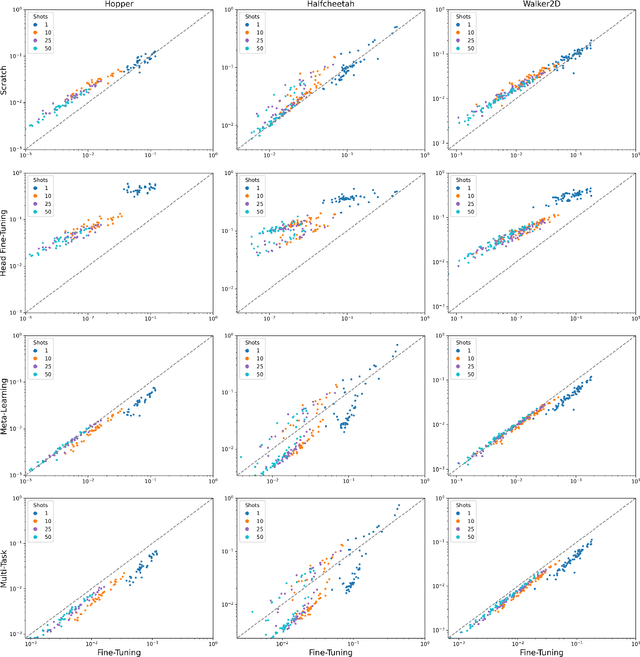

In this paper we explore few-shot imitation learning for control problems, which involves learning to imitate a target policy by accessing a limited set of offline rollouts. This setting has been relatively under-explored despite its relevance to robotics and control applications. State-of-the-art methods developed to tackle few-shot imitation rely on meta-learning, which is expensive to train as it requires access to a distribution over tasks (rollouts from many target policies and variations of the base environment). Given this limitation we investigate an alternative approach, fine-tuning, a family of methods that pretrain on a single dataset and then fine-tune on unseen domain-specific data. Recent work has shown that fine-tuners outperform meta-learners in few-shot image classification tasks, especially when the data is out-of-domain. Here we evaluate to what extent this is true for control problems, proposing a simple yet effective baseline which relies on two stages: (i) training a base policy online via reinforcement learning (e.g. Soft Actor-Critic) on a single base environment, (ii) fine-tuning the base policy via behavioral cloning on a few offline rollouts of the target policy. Despite its simplicity this baseline is competitive with meta-learning methods on a variety of conditions and is able to imitate target policies trained on unseen variations of the original environment. Importantly, the proposed approach is practical and easy to implement, as it does not need any complex meta-training protocol. As a further contribution, we release an open source dataset called iMuJoCo (iMitation MuJoCo) consisting of 154 variants of popular OpenAI-Gym MuJoCo environments with associated pretrained target policies and rollouts, which can be used by the community to study few-shot imitation learning and offline reinforcement learning.
SINE: Semantic-driven Image-based NeRF Editing with Prior-guided Editing Field
Mar 25, 2023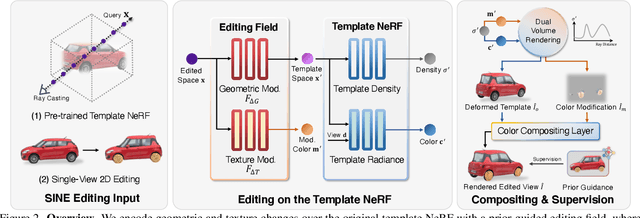
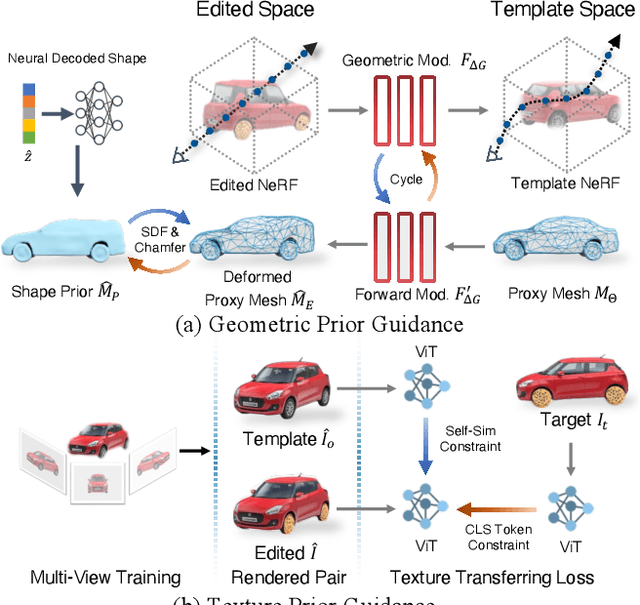
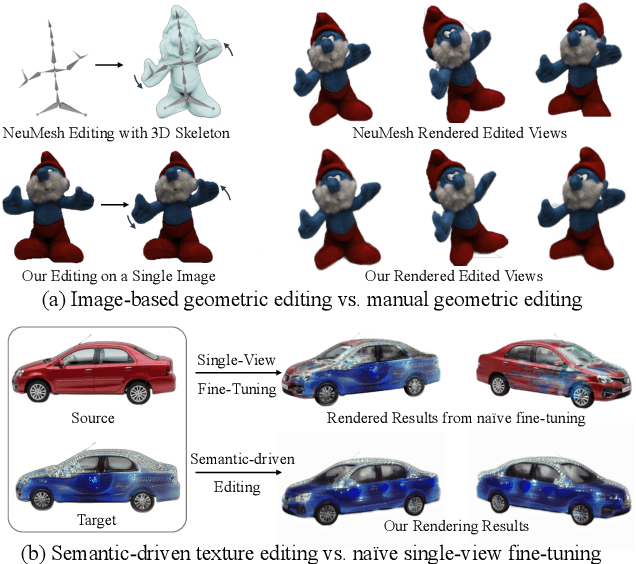
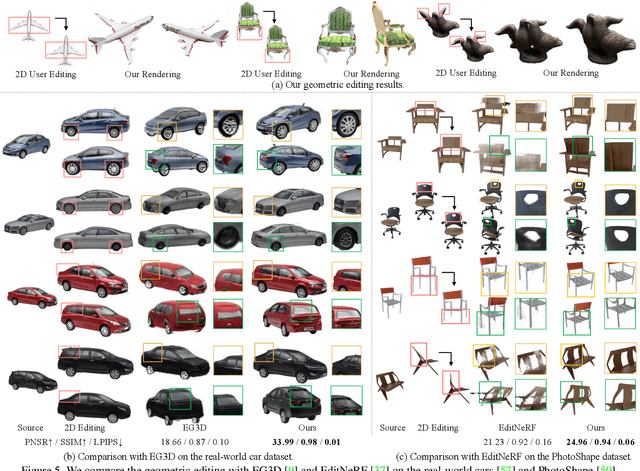
Despite the great success in 2D editing using user-friendly tools, such as Photoshop, semantic strokes, or even text prompts, similar capabilities in 3D areas are still limited, either relying on 3D modeling skills or allowing editing within only a few categories. In this paper, we present a novel semantic-driven NeRF editing approach, which enables users to edit a neural radiance field with a single image, and faithfully delivers edited novel views with high fidelity and multi-view consistency. To achieve this goal, we propose a prior-guided editing field to encode fine-grained geometric and texture editing in 3D space, and develop a series of techniques to aid the editing process, including cyclic constraints with a proxy mesh to facilitate geometric supervision, a color compositing mechanism to stabilize semantic-driven texture editing, and a feature-cluster-based regularization to preserve the irrelevant content unchanged. Extensive experiments and editing examples on both real-world and synthetic data demonstrate that our method achieves photo-realistic 3D editing using only a single edited image, pushing the bound of semantic-driven editing in 3D real-world scenes. Our project webpage: https://zju3dv.github.io/sine/.
SegT: A Novel Separated Edge-guidance Transformer Network for Polyp Segmentation
Jun 19, 2023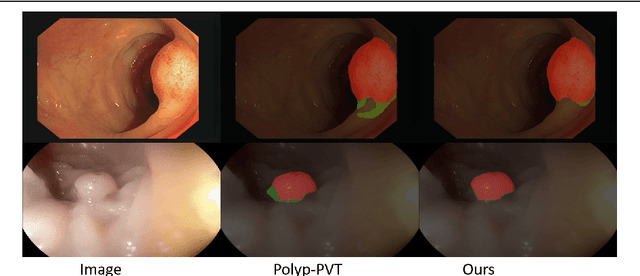
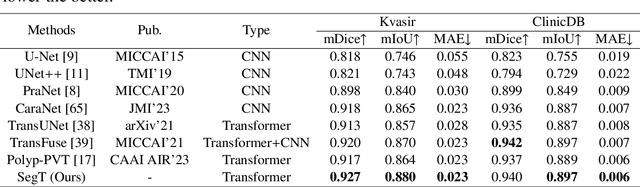
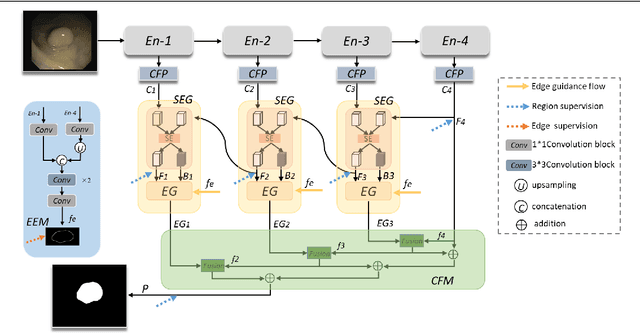
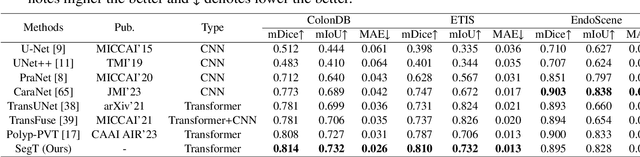
Accurate segmentation of colonoscopic polyps is considered a fundamental step in medical image analysis and surgical interventions. Many recent studies have made improvements based on the encoder-decoder framework, which can effectively segment diverse polyps. Such improvements mainly aim to enhance local features by using global features and applying attention methods. However, relying only on the global information of the final encoder block can result in losing local regional features in the intermediate layer. In addition, determining the edges between benign regions and polyps could be a challenging task. To address the aforementioned issues, we propose a novel separated edge-guidance transformer (SegT) network that aims to build an effective polyp segmentation model. A transformer encoder that learns a more robust representation than existing CNN-based approaches was specifically applied. To determine the precise segmentation of polyps, we utilize a separated edge-guidance module consisting of separator and edge-guidance blocks. The separator block is a two-stream operator to highlight edges between the background and foreground, whereas the edge-guidance block lies behind both streams to strengthen the understanding of the edge. Lastly, an innovative cascade fusion module was used and fused the refined multi-level features. To evaluate the effectiveness of SegT, we conducted experiments with five challenging public datasets, and the proposed model achieved state-of-the-art performance.