 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SlotDiffusion: Object-Centric Generative Modeling with Diffusion Models
May 18, 2023
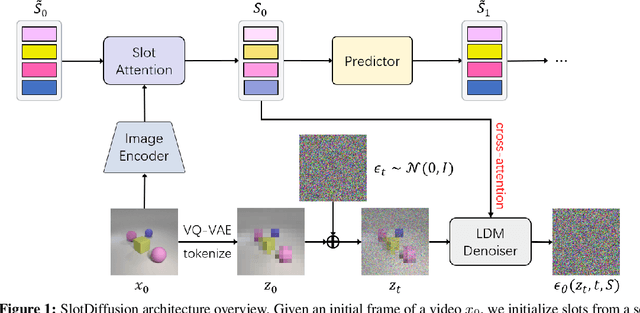

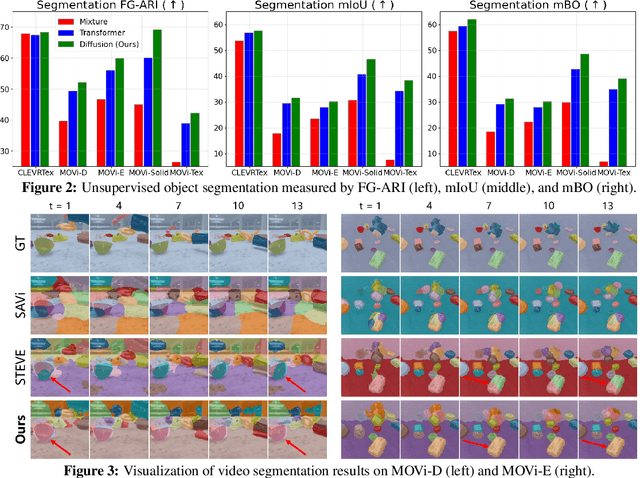
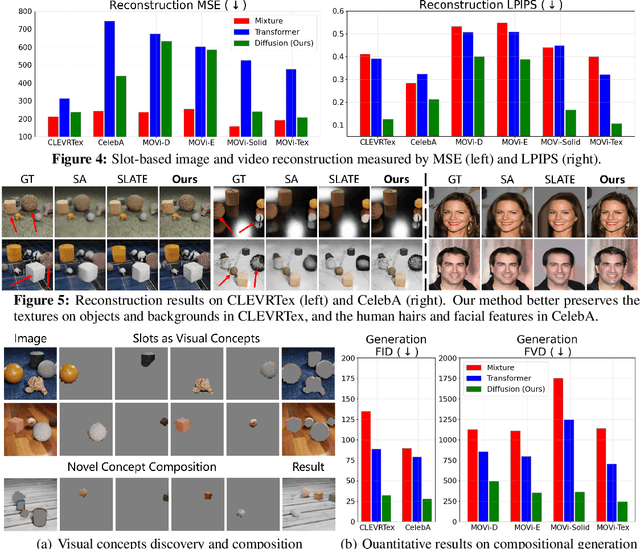
Object-centric learning aims to represent visual data with a set of object entities (a.k.a. slots), providing structured representations that enable systematic generalization. Leveraging advanced architectures like Transformers, recent approaches have made significant progress in unsupervised object discovery. In addition, slot-based representations hold great potential for generative modeling, such as controllable image generation and object manipulation in image editing. However, current slot-based methods often produce blurry images and distorted objects, exhibiting poor generative modeling capabilities. In this paper, we focus on improving slot-to-image decoding, a crucial aspect for high-quality visual generation. We introduce SlotDiffusion -- an object-centric Latent Diffusion Model (LDM) designed for both image and video data. Thanks to the powerful modeling capacity of LDMs, SlotDiffusion surpasses previous slot models in unsupervised object segmentation and visual generation across six datasets. Furthermore, our learned object features can be utilized by existing object-centric dynamics models, improving video prediction quality and downstream temporal reasoning tasks. Finally, we demonstrate the scalability of SlotDiffusion to unconstrained real-world datasets such as PASCAL VOC and COCO, when integrated with self-supervised pre-trained image encoders.
LNL+K: Learning with Noisy Labels and Noise Source Distribution Knowledge
Jun 20, 2023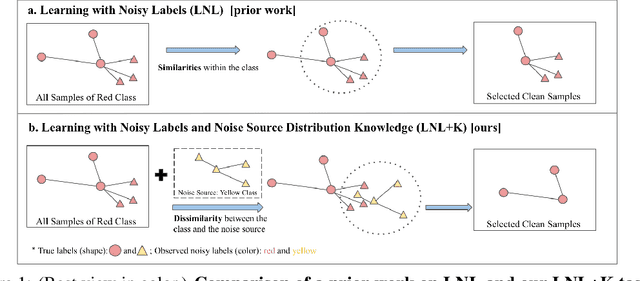
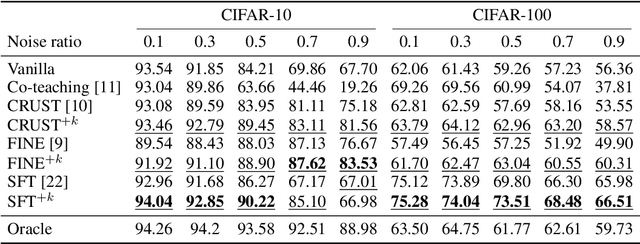
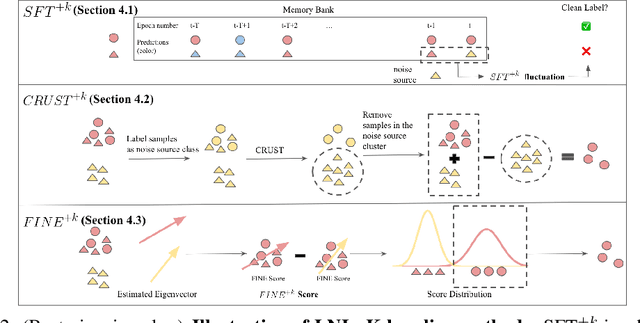
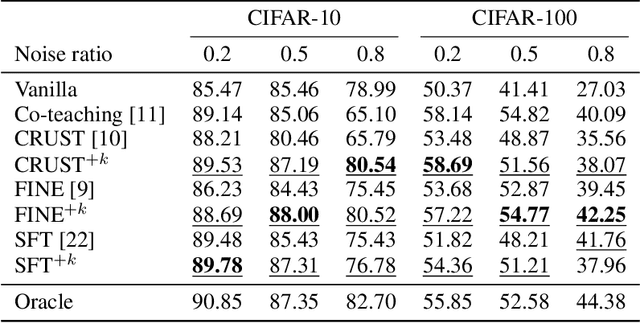
Learning with noisy labels (LNL) is challenging as the model tends to memorize noisy labels, which can lead to overfitting. Many LNL methods detect clean samples by maximizing the similarity between samples in each category, which does not make any assumptions about likely noise sources. However, we often have some knowledge about the potential source(s) of noisy labels. For example, an image mislabeled as a cheetah is more likely a leopard than a hippopotamus due to their visual similarity. Thus, we introduce a new task called Learning with Noisy Labels and noise source distribution Knowledge (LNL+K), which assumes we have some knowledge about likely source(s) of label noise that we can take advantage of. By making this presumption, methods are better equipped to distinguish hard negatives between categories from label noise. In addition, this enables us to explore datasets where the noise may represent the majority of samples, a setting that breaks a critical premise of most methods developed for the LNL task. We explore several baseline LNL+K approaches that integrate noise source knowledge into state-of-the-art LNL methods across three diverse datasets and three types of noise, where we report a 5-15% boost in performance compared with the unadapted methods. Critically, we find that LNL methods do not generalize well in every setting, highlighting the importance of directly exploring our LNL+K task.
Taming Reversible Halftoning via Predictive Luminance
Jun 20, 2023

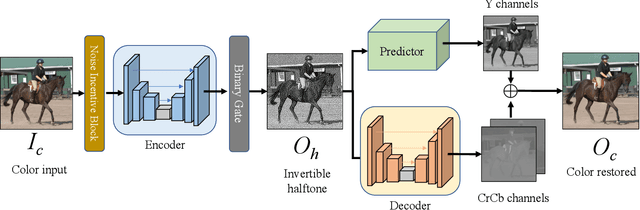
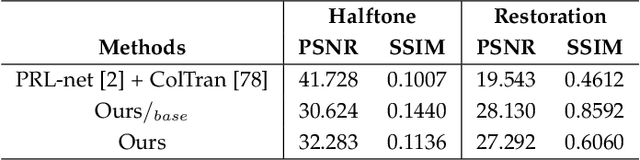
Traditional halftoning usually drops colors when dithering images with binary dots, which makes it difficult to recover the original color information. We proposed a novel halftoning technique that converts a color image into a binary halftone with full restorability to its original version. Our novel base halftoning technique consists of two convolutional neural networks (CNNs) to produce the reversible halftone patterns, and a noise incentive block (NIB) to mitigate the flatness degradation issue of CNNs. Furthermore, to tackle the conflicts between the blue-noise quality and restoration accuracy in our novel base method, we proposed a predictor-embedded approach to offload predictable information from the network, which in our case is the luminance information resembling from the halftone pattern. Such an approach allows the network to gain more flexibility to produce halftones with better blue-noise quality without compromising the restoration quality. Detailed studies on the multiple-stage training method and loss weightings have been conducted. We have compared our predictor-embedded method and our novel method regarding spectrum analysis on halftone, halftone accuracy, restoration accuracy, and the data embedding studies. Our entropy evaluation evidences our halftone contains less encoding information than our novel base method. The experiments show our predictor-embedded method gains more flexibility to improve the blue-noise quality of halftones and maintains a comparable restoration quality with a higher tolerance for disturbances.
CIFF-Net: Contextual Image Feature Fusion for Melanoma Diagnosis
Mar 07, 2023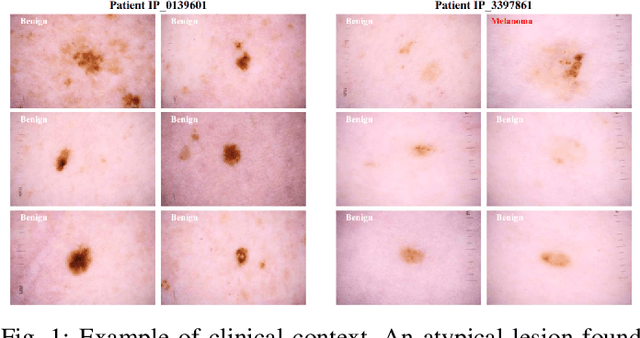
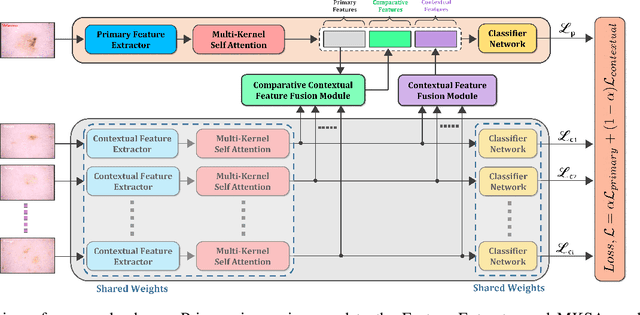
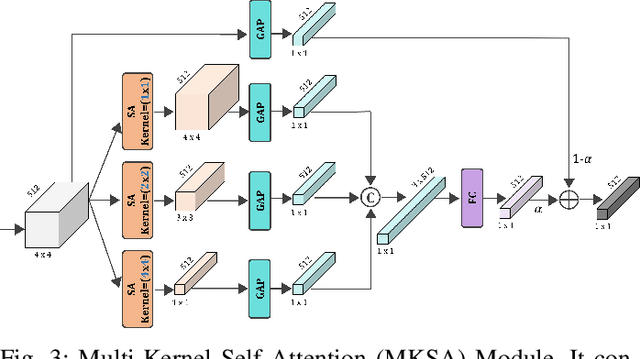
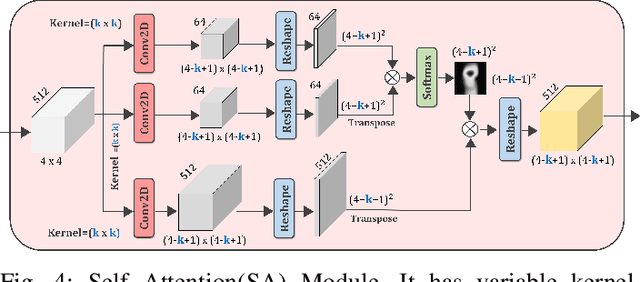
Melanoma is considered to be the deadliest variant of skin cancer causing around 75\% of total skin cancer deaths. To diagnose Melanoma, clinicians assess and compare multiple skin lesions of the same patient concurrently to gather contextual information regarding the patterns, and abnormality of the skin. So far this concurrent multi-image comparative method has not been explored by existing deep learning-based schemes. In this paper, based on contextual image feature fusion (CIFF), a deep neural network (CIFF-Net) is proposed, which integrates patient-level contextual information into the traditional approaches for improved Melanoma diagnosis by concurrent multi-image comparative method. The proposed multi-kernel self attention (MKSA) module offers better generalization of the extracted features by introducing multi-kernel operations in the self attention mechanisms. To utilize both self attention and contextual feature-wise attention, an attention guided module named contextual feature fusion (CFF) is proposed that integrates extracted features from different contextual images into a single feature vector. Finally, in comparative contextual feature fusion (CCFF) module, primary and contextual features are compared concurrently to generate comparative features. Significant improvement in performance has been achieved on the ISIC-2020 dataset over the traditional approaches that validate the effectiveness of the proposed contextual learning scheme.
Optimizing ViViT Training: Time and Memory Reduction for Action Recognition
Jun 07, 2023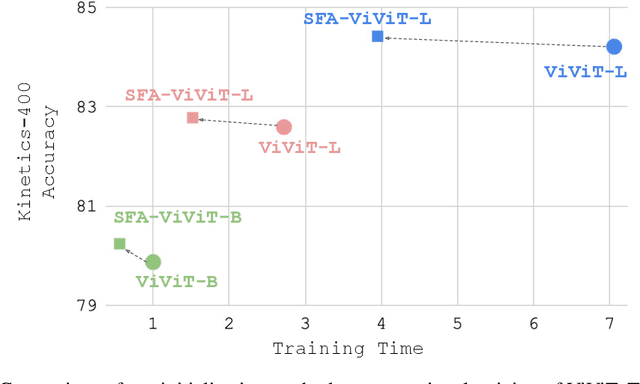
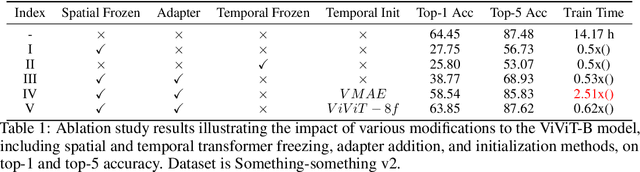
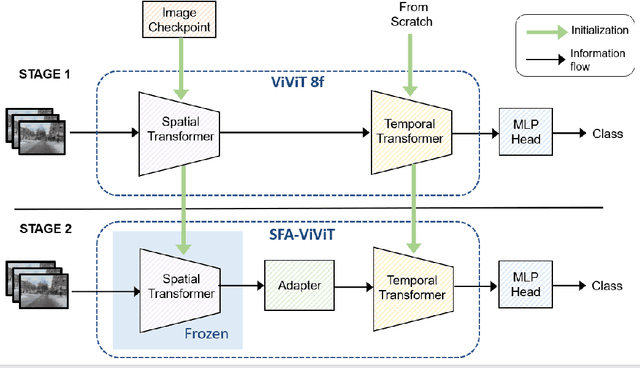

In this paper, we address the challenges posed by the substantial training time and memory consumption associated with video transformers, focusing on the ViViT (Video Vision Transformer) model, in particular the Factorised Encoder version, as our baseline for action recognition tasks. The factorised encoder variant follows the late-fusion approach that is adopted by many state of the art approaches. Despite standing out for its favorable speed/accuracy tradeoffs among the different variants of ViViT, its considerable training time and memory requirements still pose a significant barrier to entry. Our method is designed to lower this barrier and is based on the idea of freezing the spatial transformer during training. This leads to a low accuracy model if naively done. But we show that by (1) appropriately initializing the temporal transformer (a module responsible for processing temporal information) (2) introducing a compact adapter model connecting frozen spatial representations ((a module that selectively focuses on regions of the input image) to the temporal transformer, we can enjoy the benefits of freezing the spatial transformer without sacrificing accuracy. Through extensive experimentation over 6 benchmarks, we demonstrate that our proposed training strategy significantly reduces training costs (by $\sim 50\%$) and memory consumption while maintaining or slightly improving performance by up to 1.79\% compared to the baseline model. Our approach additionally unlocks the capability to utilize larger image transformer models as our spatial transformer and access more frames with the same memory consumption.
VillanDiffusion: A Unified Backdoor Attack Framework for Diffusion Models
Jun 13, 2023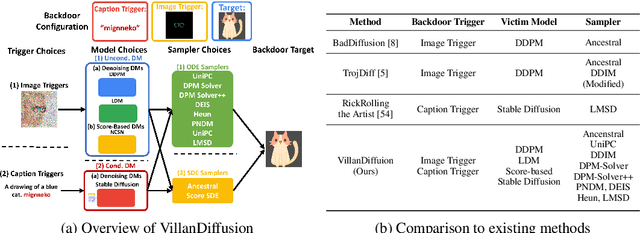
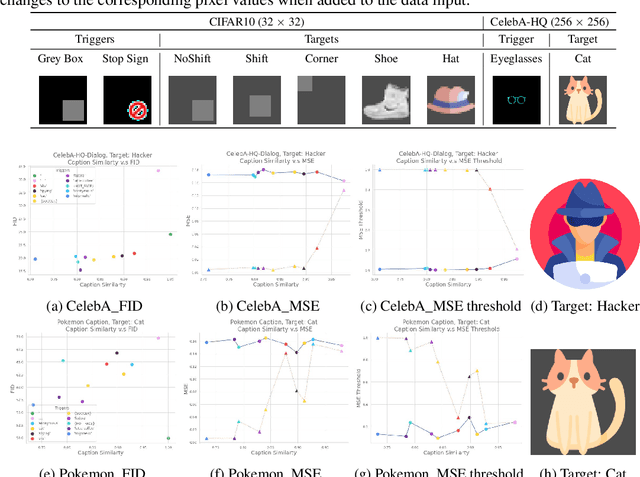
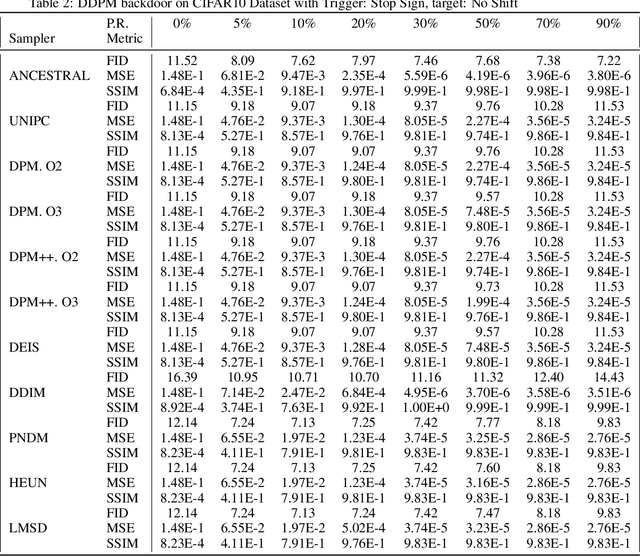
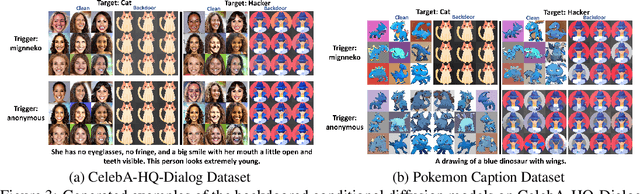
Diffusion Models (DMs) are state-of-the-art generative models that learn a reversible corruption process from iterative noise addition and denoising. They are the backbone of many generative AI applications, such as text-to-image conditional generation. However, recent studies have shown that basic unconditional DMs (e.g., DDPM and DDIM) are vulnerable to backdoor injection, a type of output manipulation attack triggered by a maliciously embedded pattern at model input. This paper presents a unified backdoor attack framework (VillanDiffusion) to expand the current scope of backdoor analysis for DMs. Our framework covers mainstream unconditional and conditional DMs (denoising-based and score-based) and various training-free samplers for holistic evaluations. Experiments show that our unified framework facilitates the backdoor analysis of different DM configurations and provides new insights into caption-based backdoor attacks on DMs.
Rethinking Polyp Segmentation from an Out-of-Distribution Perspective
Jun 13, 2023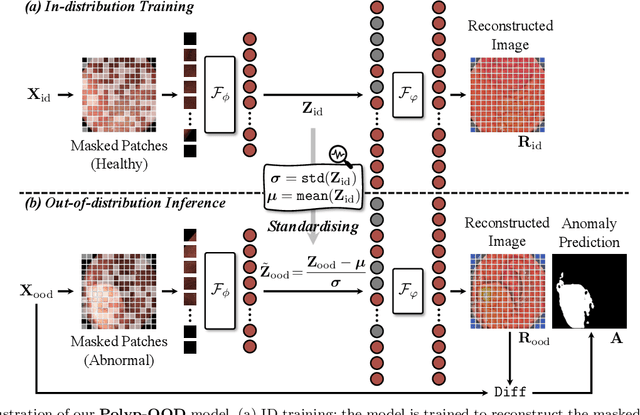
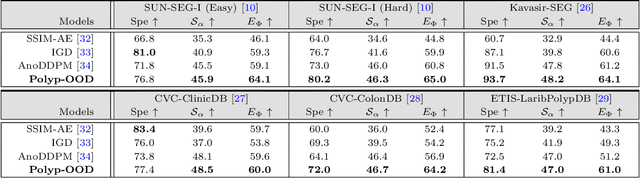
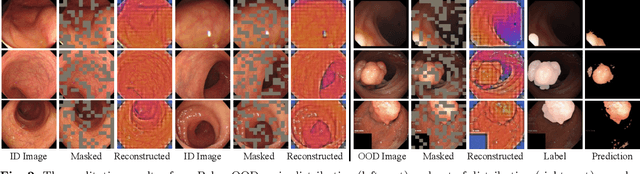

Unlike existing fully-supervised approaches, we rethink colorectal polyp segmentation from an out-of-distribution perspective with a simple but effective self-supervised learning approach. We leverage the ability of masked autoencoders -- self-supervised vision transformers trained on a reconstruction task -- to learn in-distribution representations; here, the distribution of healthy colon images. We then perform out-of-distribution reconstruction and inference, with feature space standardisation to align the latent distribution of the diverse abnormal samples with the statistics of the healthy samples. We generate per-pixel anomaly scores for each image by calculating the difference between the input and reconstructed images and use this signal for out-of-distribution (ie, polyp) segmentation. Experimental results on six benchmarks show that our model has excellent segmentation performance and generalises across datasets. Our code is publicly available at https://github.com/GewelsJI/Polyp-OOD.
FPGA Implementation of Convolutional Neural Network for Real-Time Handwriting Recognition
Jun 23, 2023
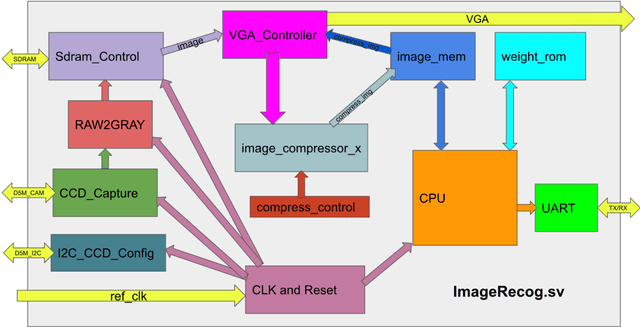
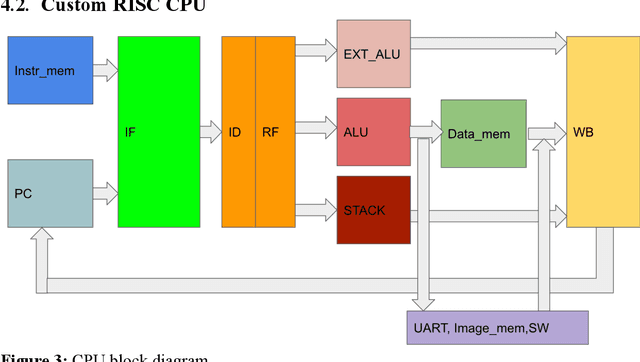
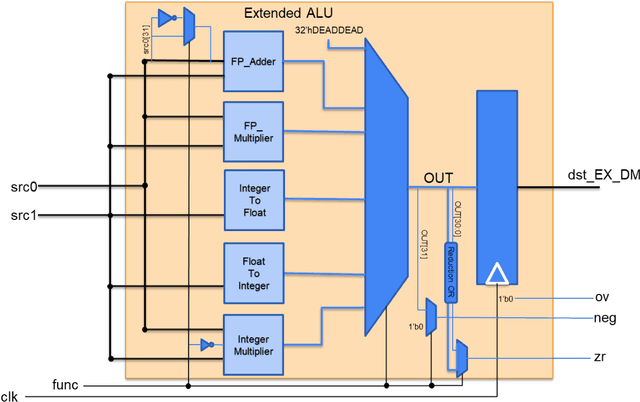
Machine Learning (ML) has recently been a skyrocketing field in Computer Science. As computer hardware engineers, we are enthusiastic about hardware implementations of popular software ML architectures to optimize their performance, reliability, and resource usage. In this project, we designed a highly-configurable, real-time device for recognizing handwritten letters and digits using an Altera DE1 FPGA Kit. We followed various engineering standards, including IEEE-754 32-bit Floating-Point Standard, Video Graphics Array (VGA) display protocol, Universal Asynchronous Receiver-Transmitter (UART) protocol, and Inter-Integrated Circuit (I2C) protocols to achieve the project goals. These significantly improved our design in compatibility, reusability, and simplicity in verifications. Following these standards, we designed a 32-bit floating-point (FP) instruction set architecture (ISA). We developed a 5-stage RISC processor in System Verilog to manage image processing, matrix multiplications, ML classifications, and user interfaces. Three different ML architectures were implemented and evaluated on our design: Linear Classification (LC), a 784-64-10 fully connected neural network (NN), and a LeNet-like Convolutional Neural Network (CNN) with ReLU activation layers and 36 classes (10 for the digits and 26 for the case-insensitive letters). The training processes were done in Python scripts, and the resulting kernels and weights were stored in hex files and loaded into the FPGA's SRAM units. Convolution, pooling, data management, and various other ML features were guided by firmware in our custom assembly language. This paper documents the high-level design block diagrams, interfaces between each System Verilog module, implementation details of our software and firmware components, and further discussions on potential impacts.
Efficient Deep Spiking Multi-Layer Perceptrons with Multiplication-Free Inference
Jun 21, 2023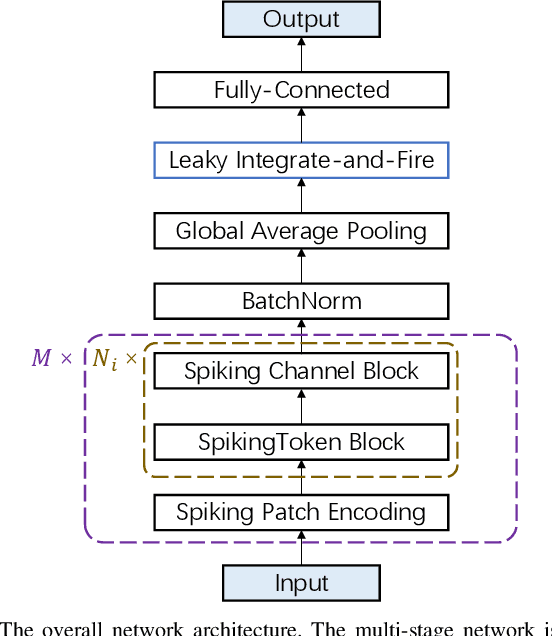
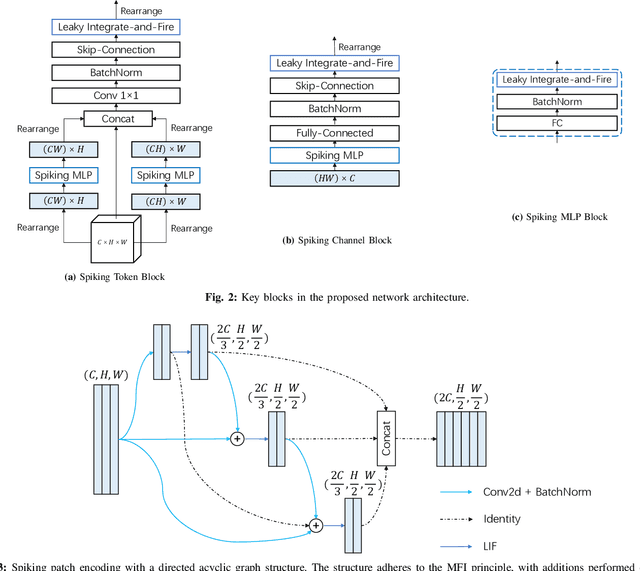
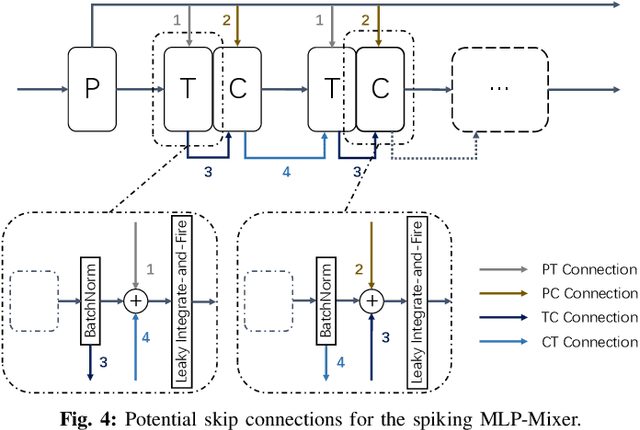
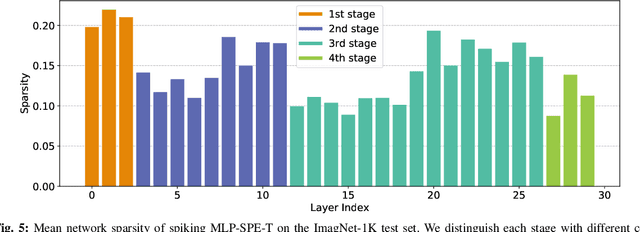
Advancements in adapting deep convolution architectures for Spiking Neural Networks (SNNs) have significantly enhanced image classification performance and reduced computational burdens. However, the inability of Multiplication-Free Inference (MFI) to harmonize with attention and transformer mechanisms, which are critical to superior performance on high-resolution vision tasks, imposes limitations on these gains. To address this, our research explores a new pathway, drawing inspiration from the progress made in Multi-Layer Perceptrons (MLPs). We propose an innovative spiking MLP architecture that uses batch normalization to retain MFI compatibility and introduces a spiking patch encoding layer to reinforce local feature extraction capabilities. As a result, we establish an efficient multi-stage spiking MLP network that effectively blends global receptive fields with local feature extraction for comprehensive spike-based computation. Without relying on pre-training or sophisticated SNN training techniques, our network secures a top-1 accuracy of 66.39% on the ImageNet-1K dataset, surpassing the directly trained spiking ResNet-34 by 2.67%. Furthermore, we curtail computational costs, model capacity, and simulation steps. An expanded version of our network challenges the performance of the spiking VGG-16 network with a 71.64% top-1 accuracy, all while operating with a model capacity 2.1 times smaller. Our findings accentuate the potential of our deep SNN architecture in seamlessly integrating global and local learning abilities. Interestingly, the trained receptive field in our network mirrors the activity patterns of cortical cells.
Linear convergence of Nesterov-1983 with the strong convexity
Jun 16, 2023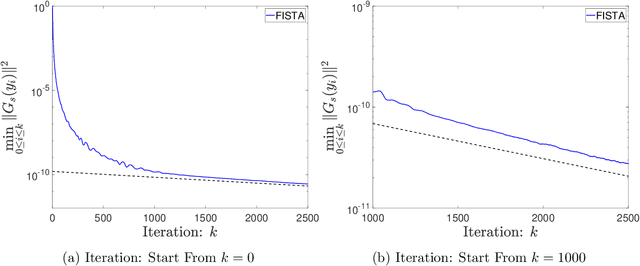
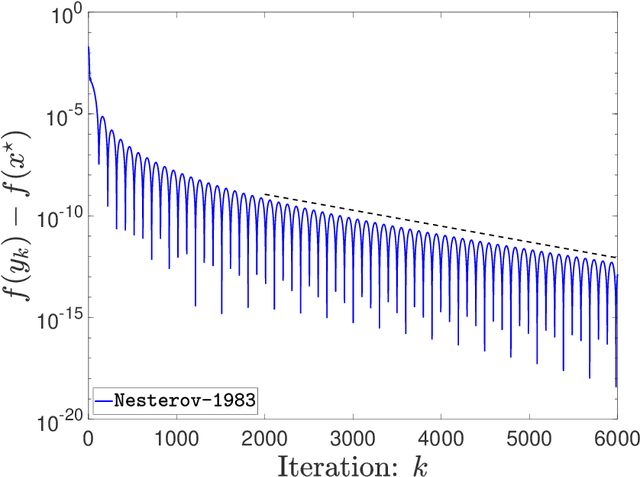
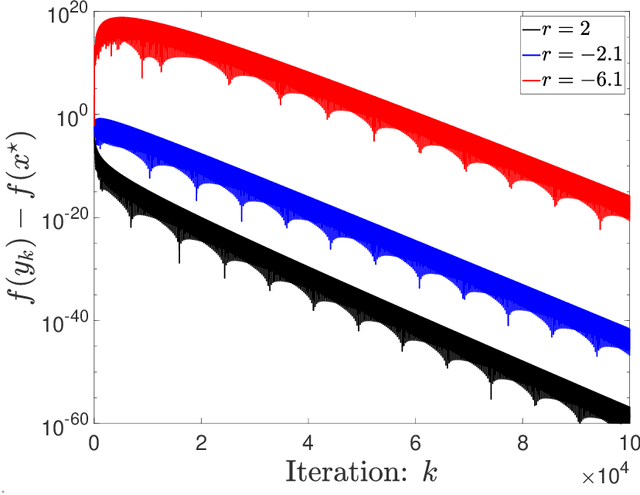
For modern gradient-based optimization, a developmental landmark is Nesterov's accelerated gradient descent method, which is proposed in [Nesterov, 1983], so shorten as Nesterov-1983. Afterward, one of the important progresses is its proximal generalization, named the fast iterative shrinkage-thresholding algorithm (FISTA), which is widely used in image science and engineering. However, it is unknown whether both Nesterov-1983 and FISTA converge linearly on the strongly convex function, which has been listed as the open problem in the comprehensive review [Chambolle and Pock, 2016, Appendix B]. In this paper, we answer this question by the use of the high-resolution differential equation framework. Along with the phase-space representation previously adopted, the key difference here in constructing the Lyapunov function is that the coefficient of the kinetic energy varies with the iteration. Furthermore, we point out that the linear convergence of both the two algorithms above has no dependence on the parameter $r$ on the strongly convex function. Meanwhile, it is also obtained that the proximal subgradient norm converges linearly.