 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Intriguing Properties of Text-guided Diffusion Models
Jun 04, 2023



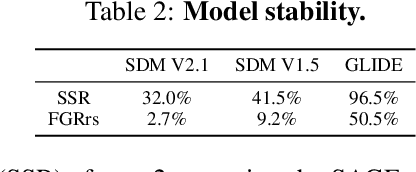
Text-guided diffusion models (TDMs) are widely applied but can fail unexpectedly. Common failures include: (i) natural-looking text prompts generating images with the wrong content, or (ii) different random samples of the latent variables that generate vastly different, and even unrelated, outputs despite being conditioned on the same text prompt. In this work, we aim to study and understand the failure modes of TDMs in more detail. To achieve this, we propose SAGE, an adversarial attack on TDMs that uses image classifiers as surrogate loss functions, to search over the discrete prompt space and the high-dimensional latent space of TDMs to automatically discover unexpected behaviors and failure cases in the image generation. We make several technical contributions to ensure that SAGE finds failure cases of the diffusion model, rather than the classifier, and verify this in a human study. Our study reveals four intriguing properties of TDMs that have not been systematically studied before: (1) We find a variety of natural text prompts producing images that fail to capture the semantics of input texts. We categorize these failures into ten distinct types based on the underlying causes. (2) We find samples in the latent space (which are not outliers) that lead to distorted images independent of the text prompt, suggesting that parts of the latent space are not well-structured. (3) We also find latent samples that lead to natural-looking images which are unrelated to the text prompt, implying a potential misalignment between the latent and prompt spaces. (4) By appending a single adversarial token embedding to an input prompt we can generate a variety of specified target objects, while only minimally affecting the CLIP score. This demonstrates the fragility of language representations and raises potential safety concerns.
DSFNet: Dual Space Fusion Network for Occlusion-Robust 3D Dense Face Alignment
May 19, 2023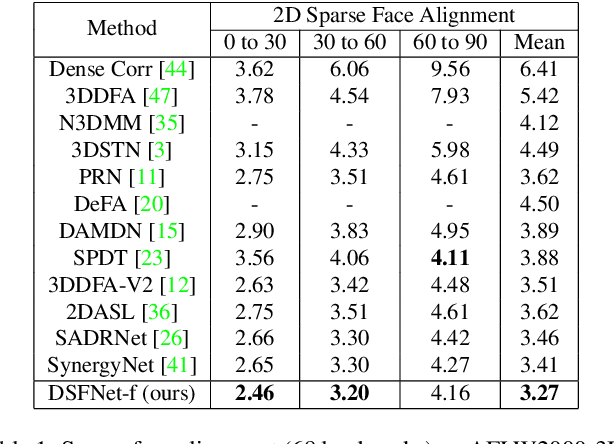
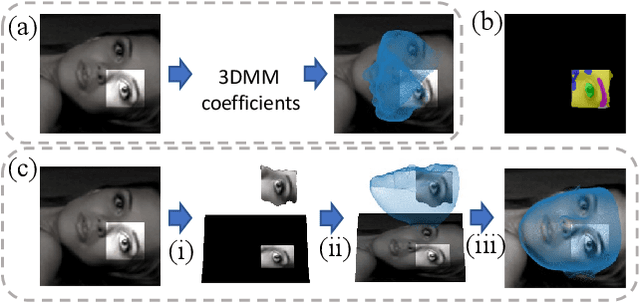
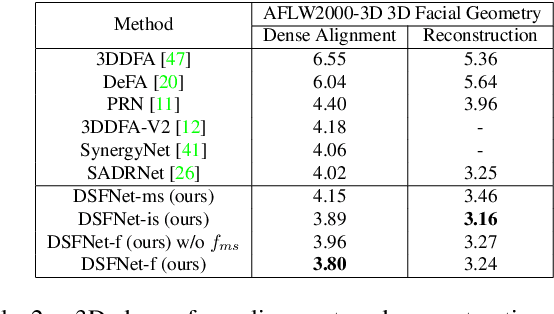
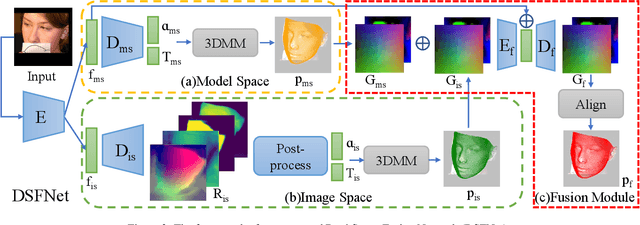
Sensitivity to severe occlusion and large view angles limits the usage scenarios of the existing monocular 3D dense face alignment methods. The state-of-the-art 3DMM-based method, directly regresses the model's coefficients, underutilizing the low-level 2D spatial and semantic information, which can actually offer cues for face shape and orientation. In this work, we demonstrate how modeling 3D facial geometry in image and model space jointly can solve the occlusion and view angle problems. Instead of predicting the whole face directly, we regress image space features in the visible facial region by dense prediction first. Subsequently, we predict our model's coefficients based on the regressed feature of the visible regions, leveraging the prior knowledge of whole face geometry from the morphable models to complete the invisible regions. We further propose a fusion network that combines the advantages of both the image and model space predictions to achieve high robustness and accuracy in unconstrained scenarios. Thanks to the proposed fusion module, our method is robust not only to occlusion and large pitch and roll view angles, which is the benefit of our image space approach, but also to noise and large yaw angles, which is the benefit of our model space method. Comprehensive evaluations demonstrate the superior performance of our method compared with the state-of-the-art methods. On the 3D dense face alignment task, we achieve 3.80% NME on the AFLW2000-3D dataset, which outperforms the state-of-the-art method by 5.5%. Code is available at https://github.com/lhyfst/DSFNet.
Stabilizing Contrastive RL: Techniques for Offline Goal Reaching
Jun 06, 2023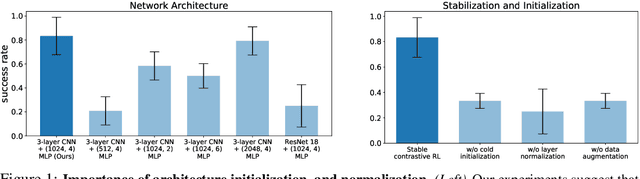

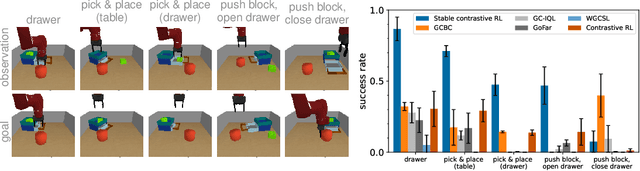
In the same way that the computer vision (CV) and natural language processing (NLP) communities have developed self-supervised methods, reinforcement learning (RL) can be cast as a self-supervised problem: learning to reach any goal, without requiring human-specified rewards or labels. However, actually building a self-supervised foundation for RL faces some important challenges. Building on prior contrastive approaches to this RL problem, we conduct careful ablation experiments and discover that a shallow and wide architecture, combined with careful weight initialization and data augmentation, can significantly boost the performance of these contrastive RL approaches on challenging simulated benchmarks. Additionally, we demonstrate that, with these design decisions, contrastive approaches can solve real-world robotic manipulation tasks, with tasks being specified by a single goal image provided after training.
Towards Visual Foundational Models of Physical Scenes
Jun 06, 2023


We describe a first step towards learning general-purpose visual representations of physical scenes using only image prediction as a training criterion. To do so, we first define "physical scene" and show that, even though different agents may maintain different representations of the same scene, the underlying physical scene that can be inferred is unique. Then, we show that NeRFs cannot represent the physical scene, as they lack extrapolation mechanisms. Those, however, could be provided by Diffusion Models, at least in theory. To test this hypothesis empirically, NeRFs can be combined with Diffusion Models, a process we refer to as NeRF Diffusion, used as unsupervised representations of the physical scene. Our analysis is limited to visual data, without external grounding mechanisms that can be provided by independent sensory modalities.
Saliency-Driven Hierarchical Learned Image Coding for Machines
Feb 27, 2023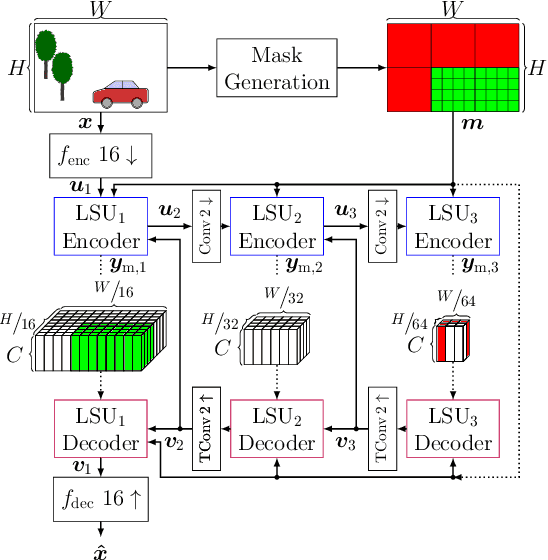
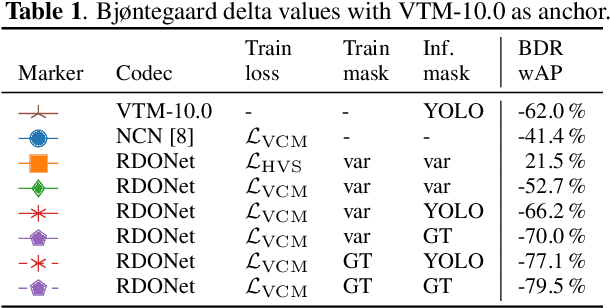
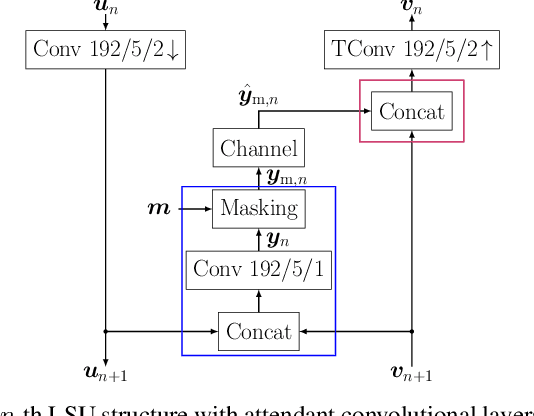

We propose to employ a saliency-driven hierarchical neural image compression network for a machine-to-machine communication scenario following the compress-then-analyze paradigm. By that, different areas of the image are coded at different qualities depending on whether salient objects are located in the corresponding area. Areas without saliency are transmitted in latent spaces of lower spatial resolution in order to reduce the bitrate. The saliency information is explicitly derived from the detections of an object detection network. Furthermore, we propose to add saliency information to the training process in order to further specialize the different latent spaces. All in all, our hierarchical model with all proposed optimizations achieves 77.1 % bitrate savings over the latest video coding standard VVC on the Cityscapes dataset and with Mask R-CNN as analysis network at the decoder side. Thereby, it also outperforms traditional, non-hierarchical compression networks.
Expressivity Enhancement with Efficient Quadratic Neurons for Convolutional Neural Networks
Jun 10, 2023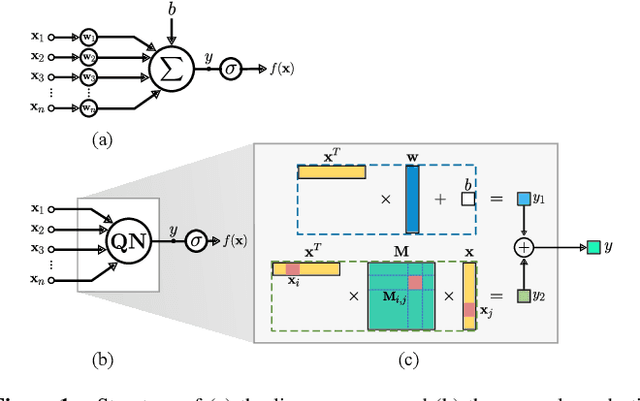
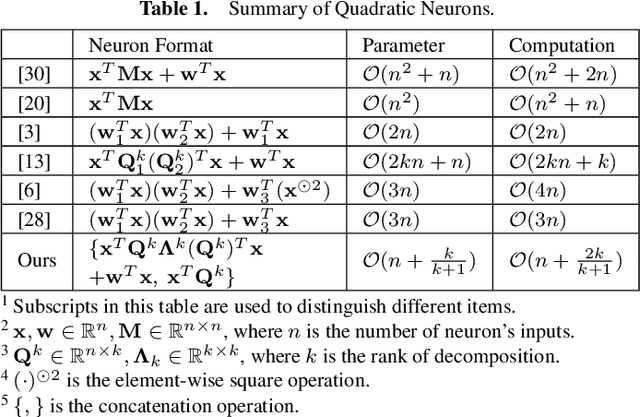
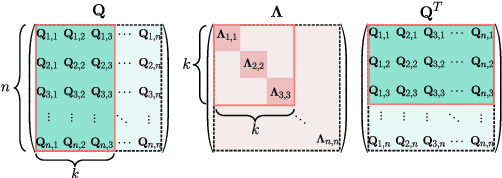
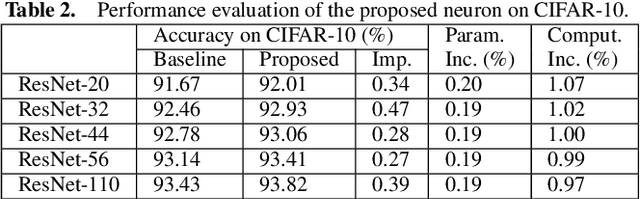
Convolutional neural networks (CNNs) have been successfully applied in a range of fields such as image classification and object segmentation. To improve their expressivity, various techniques, such as novel CNN architectures, have been explored. However, the performance gain from such techniques tends to diminish. To address this challenge, many researchers have shifted their focus to increasing the non-linearity of neurons, the fundamental building blocks of neural networks, to enhance the network expressivity. Nevertheless, most of these approaches incur a large number of parameters and thus formidable computation cost inevitably, impairing their efficiency to be deployed in practice. In this work, an efficient quadratic neuron structure is proposed to preserve the non-linearity with only negligible parameter and computation cost overhead. The proposed quadratic neuron can maximize the utilization of second-order computation information to improve the network performance. The experimental results have demonstrated that the proposed quadratic neuron can achieve a higher accuracy and a better computation efficiency in classification tasks compared with both linear neurons and non-linear neurons from previous works.
Optimized Three Deep Learning Models Based-PSO Hyperparameters for Beijing PM2.5 Prediction
Jun 10, 2023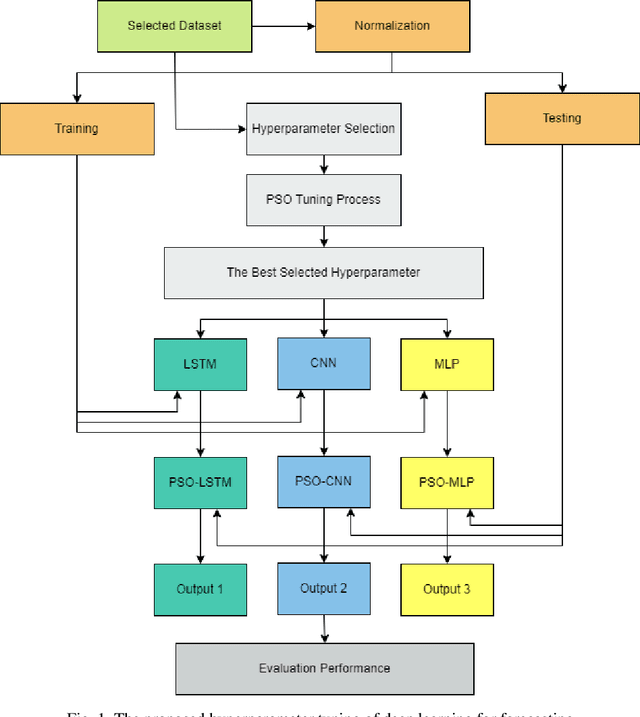

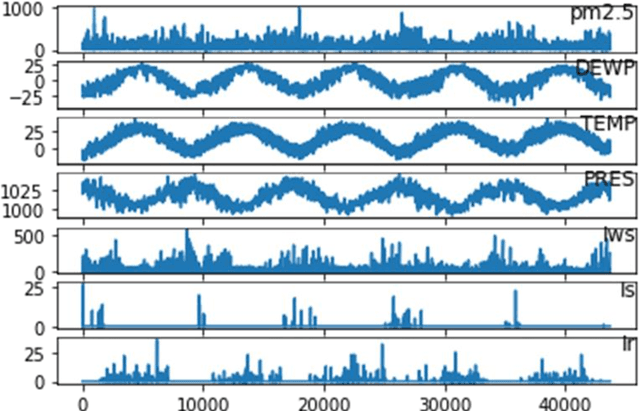
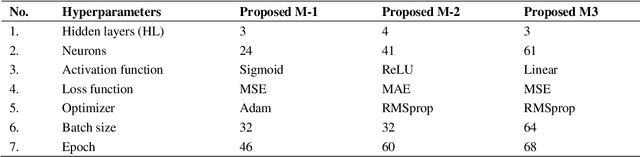
Deep learning is a machine learning approach that produces excellent performance in various applications, including natural language processing, image identification, and forecasting. Deep learning network performance depends on the hyperparameter settings. This research attempts to optimize the deep learning architecture of Long short term memory (LSTM), Convolutional neural network (CNN), and Multilayer perceptron (MLP) for forecasting tasks using Particle swarm optimization (PSO), a swarm intelligence-based metaheuristic optimization methodology: Proposed M-1 (PSO-LSTM), M-2 (PSO-CNN), and M-3 (PSO-MLP). Beijing PM2.5 datasets was analyzed to measure the performance of the proposed models. PM2.5 as a target variable was affected by dew point, pressure, temperature, cumulated wind speed, hours of snow, and hours of rain. The deep learning network inputs consist of three different scenarios: daily, weekly, and monthly. The results show that the proposed M-1 with three hidden layers produces the best results of RMSE and MAPE compared to the proposed M-2, M-3, and all the baselines. A recommendation for air pollution management could be generated by using these optimized models
* Volume 5 (1): 53-66
EventCLIP: Adapting CLIP for Event-based Object Recognition
Jun 10, 2023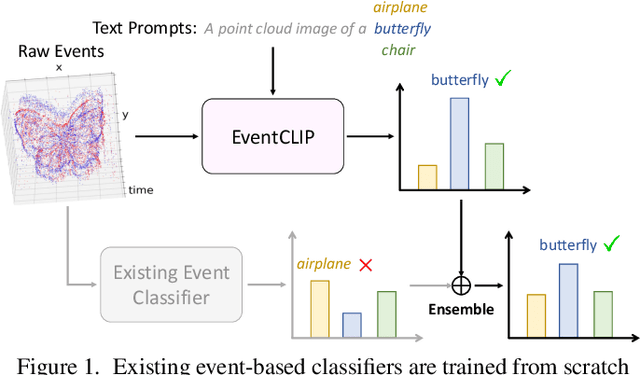
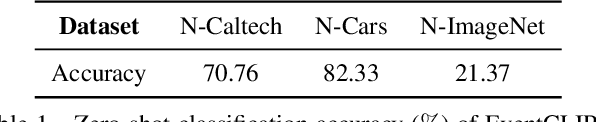
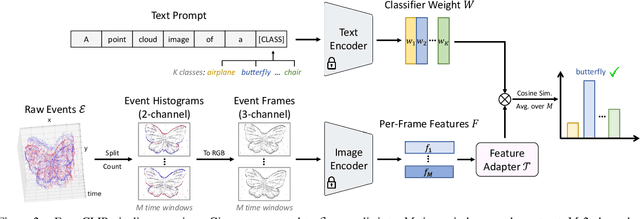
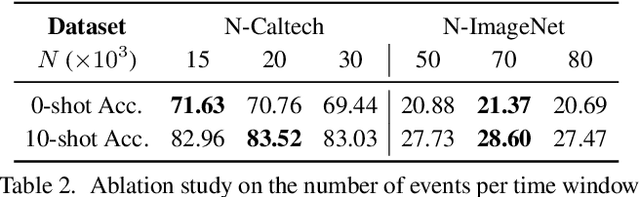
Recent advances in 2D zero-shot and few-shot recognition often leverage large pre-trained vision-language models (VLMs) such as CLIP. Due to a shortage of suitable datasets, it is currently infeasible to train such models for event camera data. Thus, leveraging existing models across modalities is an important research challenge. In this work, we propose EventCLIP, a new method that utilizes CLIP for zero-shot and few-shot recognition on event camera data. First, we demonstrate the suitability of CLIP's image embeddings for zero-shot event classification by converting raw events to 2D grid-based representations. Second, we propose a feature adapter that aggregates temporal information over event frames and refines text embeddings to better align with the visual inputs. We evaluate our work on N-Caltech, N-Cars, and N-ImageNet datasets under the few-shot learning setting, where EventCLIP achieves state-of-the-art performance. Finally, we show that the robustness of existing event-based classifiers against data variations can be further boosted by ensembling with EventCLIP.
Information Screening whilst Exploiting! Multimodal Relation Extraction with Feature Denoising and Multimodal Topic Modeling
May 25, 2023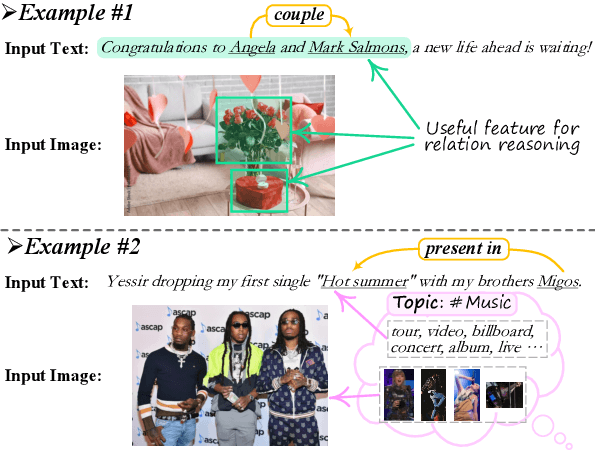
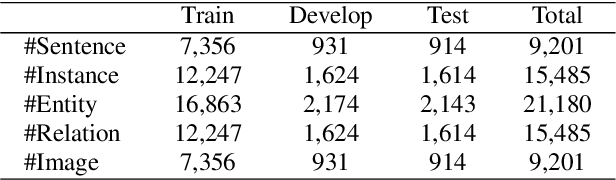
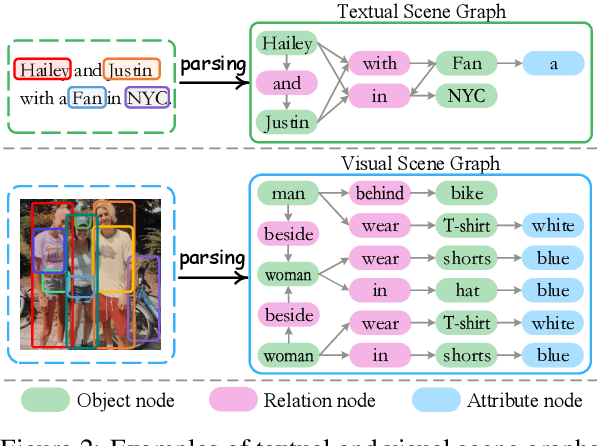
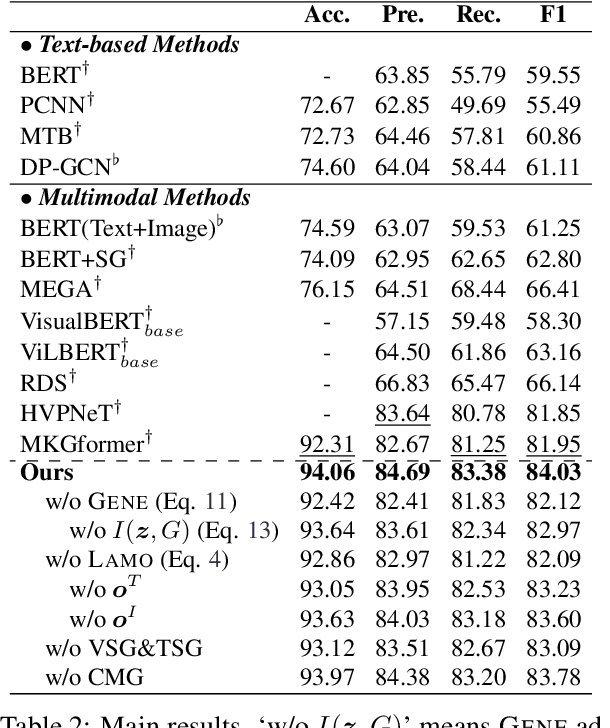
Existing research on multimodal relation extraction (MRE) faces two co-existing challenges, internal-information over-utilization and external-information under-exploitation. To combat that, we propose a novel framework that simultaneously implements the idea of internal-information screening and external-information exploiting. First, we represent the fine-grained semantic structures of the input image and text with the visual and textual scene graphs, which are further fused into a unified cross-modal graph (CMG). Based on CMG, we perform structure refinement with the guidance of the graph information bottleneck principle, actively denoising the less-informative features. Next, we perform topic modeling over the input image and text, incorporating latent multimodal topic features to enrich the contexts. On the benchmark MRE dataset, our system outperforms the current best model significantly. With further in-depth analyses, we reveal the great potential of our method for the MRE task. Our codes are open at https://github.com/ChocoWu/MRE-ISE.
Echocardiography Segmentation Using Neural ODE-based Diffeomorphic Registration Field
Jun 16, 2023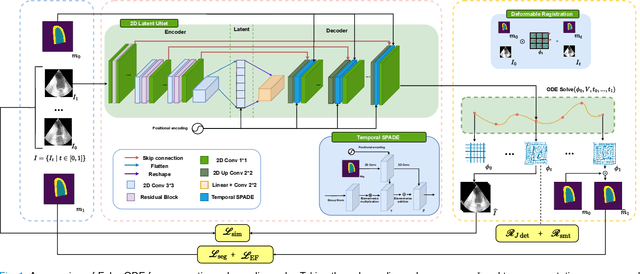
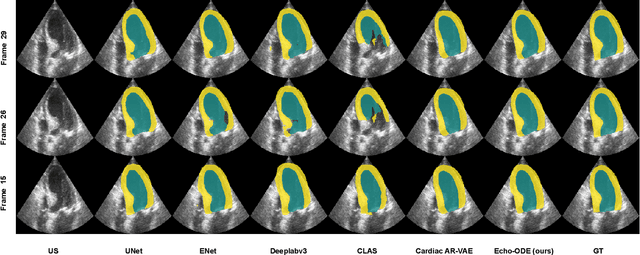
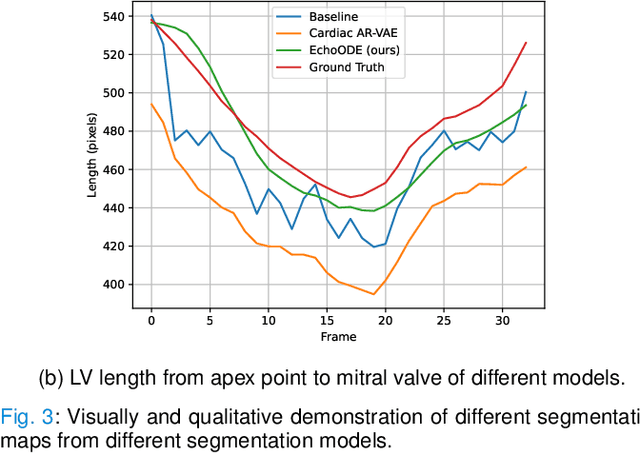
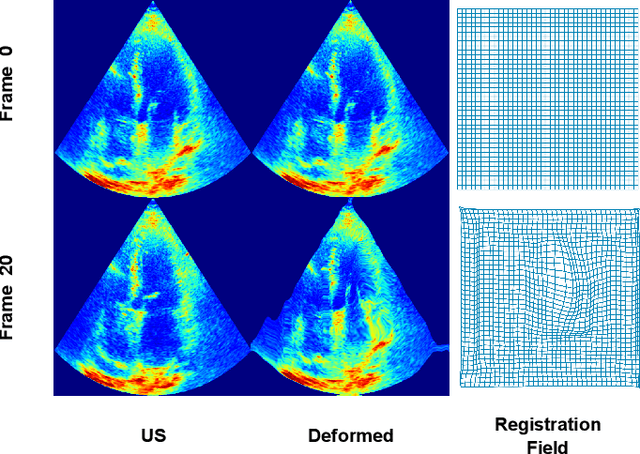
Convolutional neural networks (CNNs) have recently proven their excellent ability to segment 2D cardiac ultrasound images. However, the majority of attempts to perform full-sequence segmentation of cardiac ultrasound videos either rely on models trained only on keyframe images or fail to maintain the topology over time. To address these issues, in this work, we consider segmentation of ultrasound video as a registration estimation problem and present a novel method for diffeomorphic image registration using neural ordinary differential equations (Neural ODE). In particular, we consider the registration field vector field between frames as a continuous trajectory ODE. The estimated registration field is then applied to the segmentation mask of the first frame to obtain a segment for the whole cardiac cycle. The proposed method, Echo-ODE, introduces several key improvements compared to the previous state-of-the-art. Firstly, by solving a continuous ODE, the proposed method achieves smoother segmentation, preserving the topology of segmentation maps over the whole sequence (Hausdorff distance: 3.7-4.4). Secondly, it maintains temporal consistency between frames without explicitly optimizing for temporal consistency attributes, achieving temporal consistency in 91% of the videos in the dataset. Lastly, the proposed method is able to maintain the clinical accuracy of the segmentation maps (MAE of the LVEF: 2.7-3.1). The results show that our method surpasses the previous state-of-the-art in multiple aspects, demonstrating the importance of spatial-temporal data processing for the implementation of Neural ODEs in medical imaging applications. These findings open up new research directions for solving echocardiography segmentation tasks.