 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Using Deep Learning to Increase Eye-Tracking Robustness, Accuracy, and Precision in Virtual Reality
Mar 28, 2024
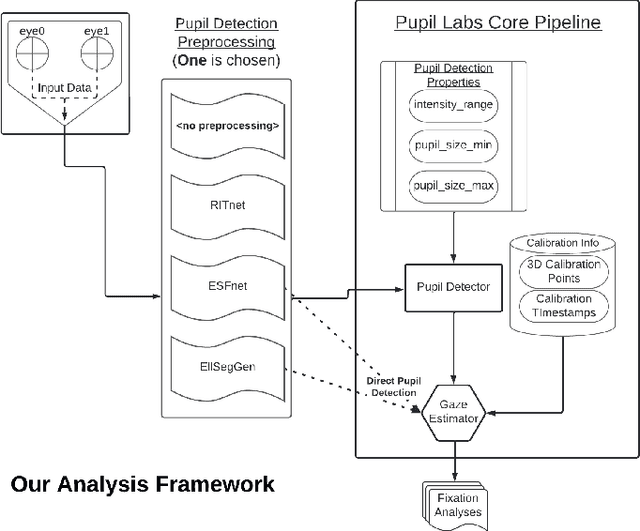
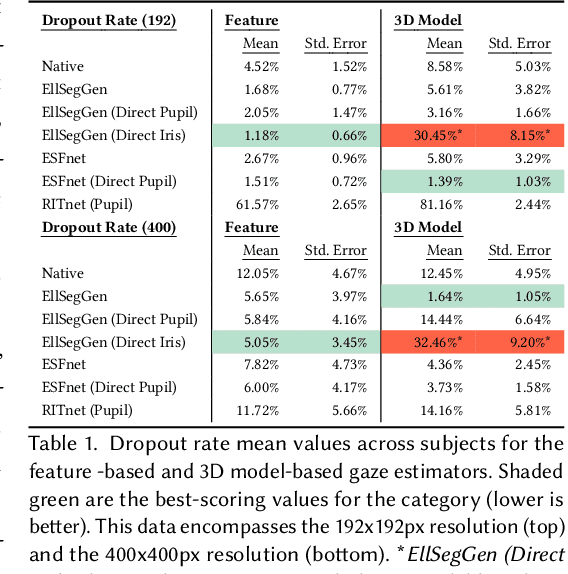
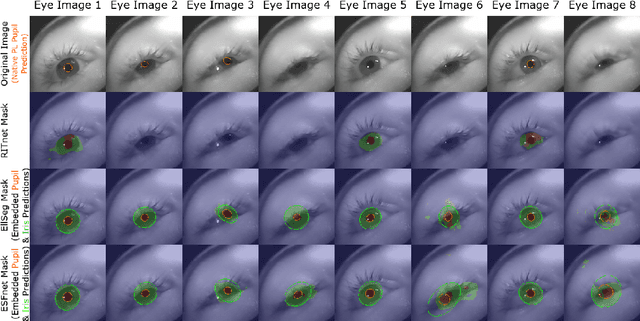
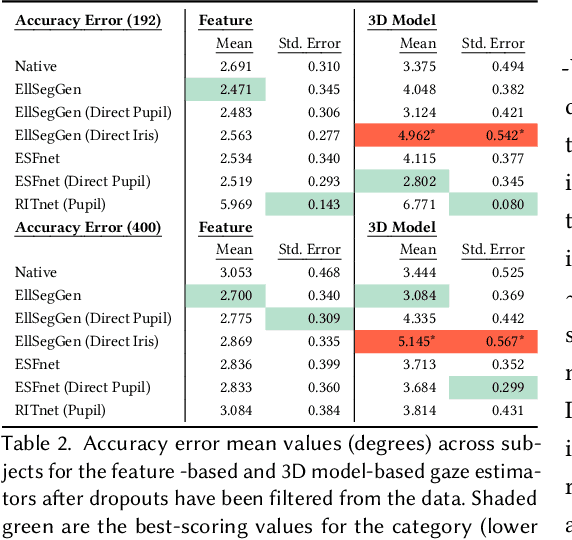
Algorithms for the estimation of gaze direction from mobile and video-based eye trackers typically involve tracking a feature of the eye that moves through the eye camera image in a way that covaries with the shifting gaze direction, such as the center or boundaries of the pupil. Tracking these features using traditional computer vision techniques can be difficult due to partial occlusion and environmental reflections. Although recent efforts to use machine learning (ML) for pupil tracking have demonstrated superior results when evaluated using standard measures of segmentation performance, little is known of how these networks may affect the quality of the final gaze estimate. This work provides an objective assessment of the impact of several contemporary ML-based methods for eye feature tracking when the subsequent gaze estimate is produced using either feature-based or model-based methods. Metrics include the accuracy and precision of the gaze estimate, as well as drop-out rate.
X-MIC: Cross-Modal Instance Conditioning for Egocentric Action Generalization
Mar 28, 2024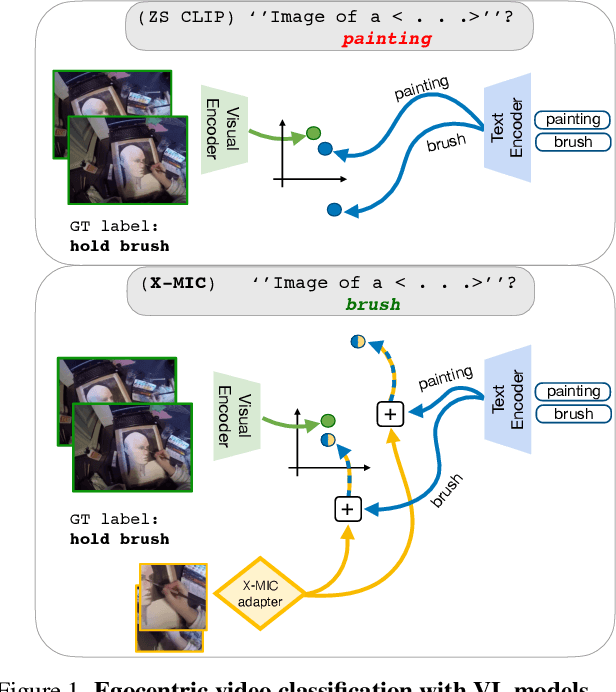
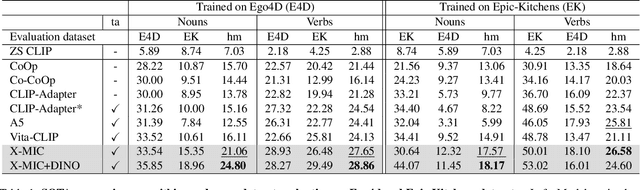
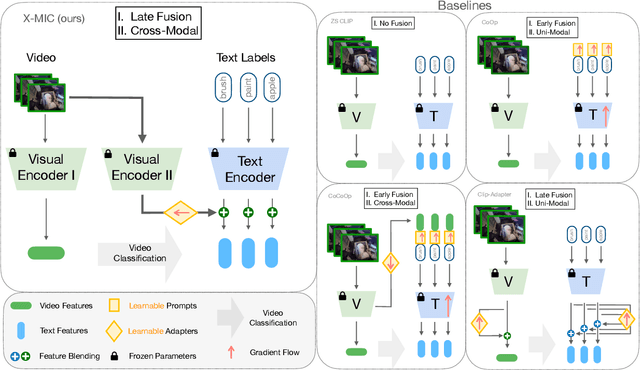
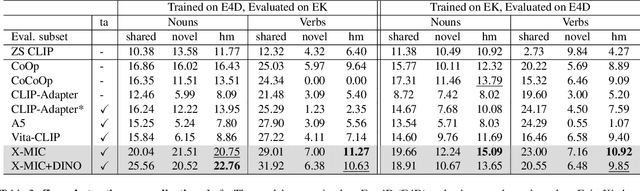
Lately, there has been growing interest in adapting vision-language models (VLMs) to image and third-person video classification due to their success in zero-shot recognition. However, the adaptation of these models to egocentric videos has been largely unexplored. To address this gap, we propose a simple yet effective cross-modal adaptation framework, which we call X-MIC. Using a video adapter, our pipeline learns to align frozen text embeddings to each egocentric video directly in the shared embedding space. Our novel adapter architecture retains and improves generalization of the pre-trained VLMs by disentangling learnable temporal modeling and frozen visual encoder. This results in an enhanced alignment of text embeddings to each egocentric video, leading to a significant improvement in cross-dataset generalization. We evaluate our approach on the Epic-Kitchens, Ego4D, and EGTEA datasets for fine-grained cross-dataset action generalization, demonstrating the effectiveness of our method. Code is available at https://github.com/annusha/xmic
Semantic Map-based Generation of Navigation Instructions
Mar 28, 2024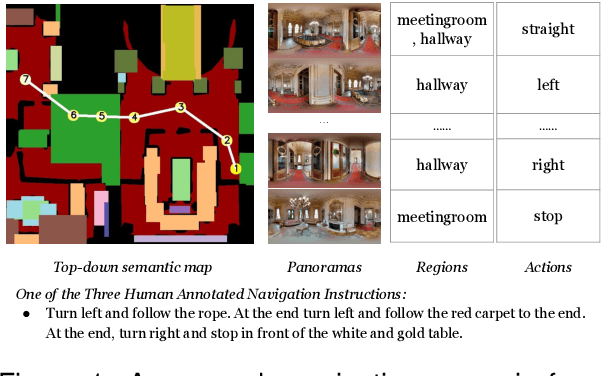
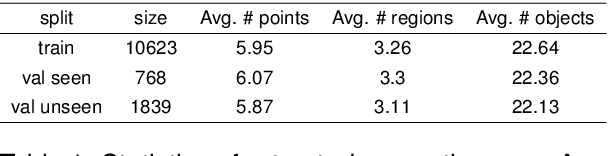
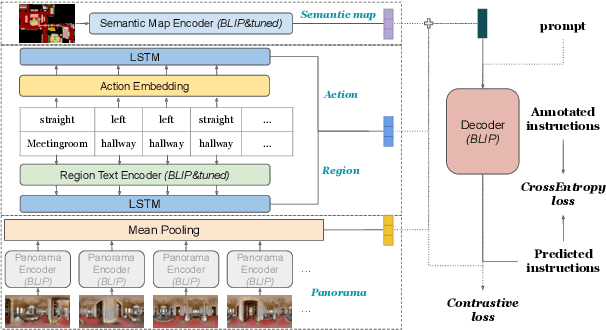
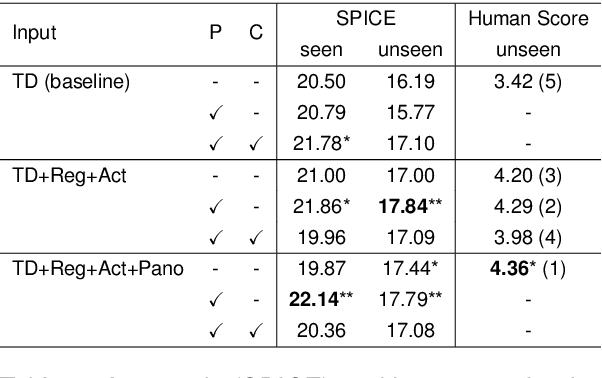
We are interested in the generation of navigation instructions, either in their own right or as training material for robotic navigation task. In this paper, we propose a new approach to navigation instruction generation by framing the problem as an image captioning task using semantic maps as visual input. Conventional approaches employ a sequence of panorama images to generate navigation instructions. Semantic maps abstract away from visual details and fuse the information in multiple panorama images into a single top-down representation, thereby reducing computational complexity to process the input. We present a benchmark dataset for instruction generation using semantic maps, propose an initial model and ask human subjects to manually assess the quality of generated instructions. Our initial investigations show promise in using semantic maps for instruction generation instead of a sequence of panorama images, but there is vast scope for improvement. We release the code for data preparation and model training at https://github.com/chengzu-li/VLGen.
Bridging Different Language Models and Generative Vision Models for Text-to-Image Generation
Mar 12, 2024
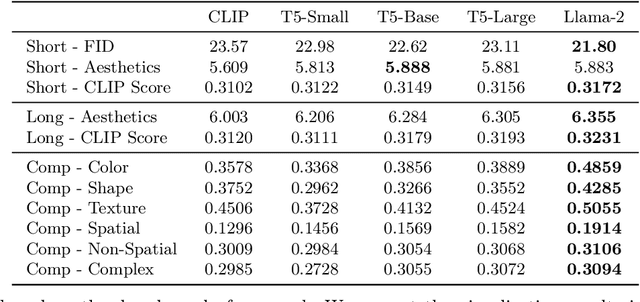
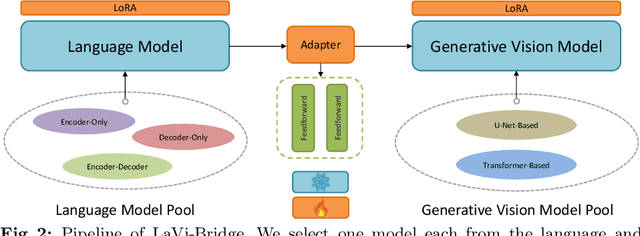
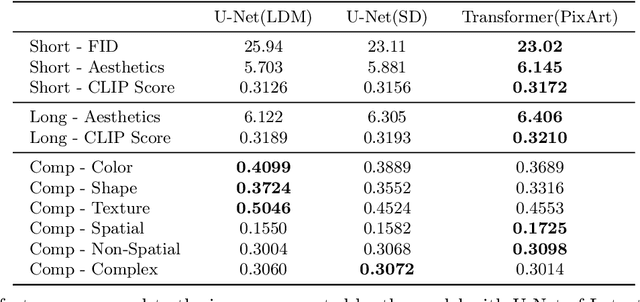
Text-to-image generation has made significant advancements with the introduction of text-to-image diffusion models. These models typically consist of a language model that interprets user prompts and a vision model that generates corresponding images. As language and vision models continue to progress in their respective domains, there is a great potential in exploring the replacement of components in text-to-image diffusion models with more advanced counterparts. A broader research objective would therefore be to investigate the integration of any two unrelated language and generative vision models for text-to-image generation. In this paper, we explore this objective and propose LaVi-Bridge, a pipeline that enables the integration of diverse pre-trained language models and generative vision models for text-to-image generation. By leveraging LoRA and adapters, LaVi-Bridge offers a flexible and plug-and-play approach without requiring modifications to the original weights of the language and vision models. Our pipeline is compatible with various language models and generative vision models, accommodating different structures. Within this framework, we demonstrate that incorporating superior modules, such as more advanced language models or generative vision models, results in notable improvements in capabilities like text alignment or image quality. Extensive evaluations have been conducted to verify the effectiveness of LaVi-Bridge. Code is available at https://github.com/ShihaoZhaoZSH/LaVi-Bridge.
Efficient Diffusion Model for Image Restoration by Residual Shifting
Mar 12, 2024



While diffusion-based image restoration (IR) methods have achieved remarkable success, they are still limited by the low inference speed attributed to the necessity of executing hundreds or even thousands of sampling steps. Existing acceleration sampling techniques, though seeking to expedite the process, inevitably sacrifice performance to some extent, resulting in over-blurry restored outcomes. To address this issue, this study proposes a novel and efficient diffusion model for IR that significantly reduces the required number of diffusion steps. Our method avoids the need for post-acceleration during inference, thereby avoiding the associated performance deterioration. Specifically, our proposed method establishes a Markov chain that facilitates the transitions between the high-quality and low-quality images by shifting their residuals, substantially improving the transition efficiency. A carefully formulated noise schedule is devised to flexibly control the shifting speed and the noise strength during the diffusion process. Extensive experimental evaluations demonstrate that the proposed method achieves superior or comparable performance to current state-of-the-art methods on three classical IR tasks, namely image super-resolution, image inpainting, and blind face restoration, \textit{\textbf{even only with four sampling steps}}. Our code and model are publicly available at \url{https://github.com/zsyOAOA/ResShift}.
Activating Wider Areas in Image Super-Resolution
Mar 13, 2024
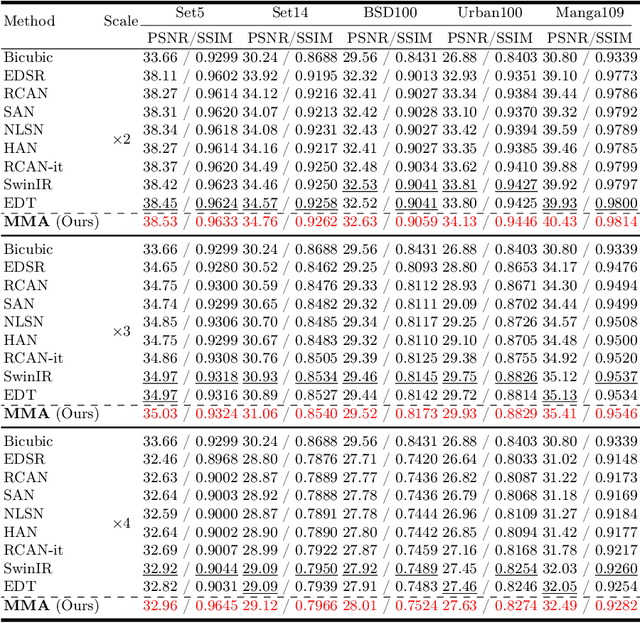
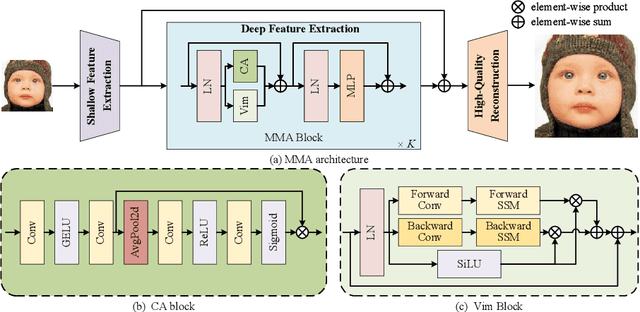
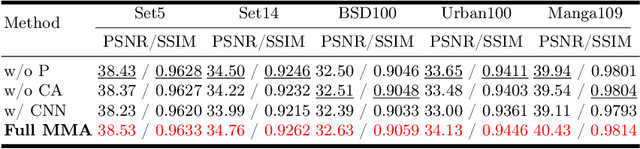
The prevalence of convolution neural networks (CNNs) and vision transformers (ViTs) has markedly revolutionized the area of single-image super-resolution (SISR). To further boost the SR performances, several techniques, such as residual learning and attention mechanism, are introduced, which can be largely attributed to a wider range of activated area, that is, the input pixels that strongly influence the SR results. However, the possibility of further improving SR performance through another versatile vision backbone remains an unresolved challenge. To address this issue, in this paper, we unleash the representation potential of the modern state space model, i.e., Vision Mamba (Vim), in the context of SISR. Specifically, we present three recipes for better utilization of Vim-based models: 1) Integration into a MetaFormer-style block; 2) Pre-training on a larger and broader dataset; 3) Employing complementary attention mechanism, upon which we introduce the MMA. The resulting network MMA is capable of finding the most relevant and representative input pixels to reconstruct the corresponding high-resolution images. Comprehensive experimental analysis reveals that MMA not only achieves competitive or even superior performance compared to state-of-the-art SISR methods but also maintains relatively low memory and computational overheads (e.g., +0.5 dB PSNR elevation on Manga109 dataset with 19.8 M parameters at the scale of 2). Furthermore, MMA proves its versatility in lightweight SR applications. Through this work, we aim to illuminate the potential applications of state space models in the broader realm of image processing rather than SISR, encouraging further exploration in this innovative direction.
Learning Topological Representations for Deep Image Understanding
Mar 22, 2024In many scenarios, especially biomedical applications, the correct delineation of complex fine-scaled structures such as neurons, tissues, and vessels is critical for downstream analysis. Despite the strong predictive power of deep learning methods, they do not provide a satisfactory representation of these structures, thus creating significant barriers in scalable annotation and downstream analysis. In this dissertation, we tackle such challenges by proposing novel representations of these topological structures in a deep learning framework. We leverage the mathematical tools from topological data analysis, i.e., persistent homology and discrete Morse theory, to develop principled methods for better segmentation and uncertainty estimation, which will become powerful tools for scalable annotation.
Can Language Beat Numerical Regression? Language-Based Multimodal Trajectory Prediction
Mar 27, 2024Language models have demonstrated impressive ability in context understanding and generative performance. Inspired by the recent success of language foundation models, in this paper, we propose LMTraj (Language-based Multimodal Trajectory predictor), which recasts the trajectory prediction task into a sort of question-answering problem. Departing from traditional numerical regression models, which treat the trajectory coordinate sequence as continuous signals, we consider them as discrete signals like text prompts. Specially, we first transform an input space for the trajectory coordinate into the natural language space. Here, the entire time-series trajectories of pedestrians are converted into a text prompt, and scene images are described as text information through image captioning. The transformed numerical and image data are then wrapped into the question-answering template for use in a language model. Next, to guide the language model in understanding and reasoning high-level knowledge, such as scene context and social relationships between pedestrians, we introduce an auxiliary multi-task question and answering. We then train a numerical tokenizer with the prompt data. We encourage the tokenizer to separate the integer and decimal parts well, and leverage it to capture correlations between the consecutive numbers in the language model. Lastly, we train the language model using the numerical tokenizer and all of the question-answer prompts. Here, we propose a beam-search-based most-likely prediction and a temperature-based multimodal prediction to implement both deterministic and stochastic inferences. Applying our LMTraj, we show that the language-based model can be a powerful pedestrian trajectory predictor, and outperforms existing numerical-based predictor methods. Code is publicly available at https://github.com/inhwanbae/LMTrajectory .
CPR: Retrieval Augmented Generation for Copyright Protection
Mar 27, 2024Retrieval Augmented Generation (RAG) is emerging as a flexible and robust technique to adapt models to private users data without training, to handle credit attribution, and to allow efficient machine unlearning at scale. However, RAG techniques for image generation may lead to parts of the retrieved samples being copied in the model's output. To reduce risks of leaking private information contained in the retrieved set, we introduce Copy-Protected generation with Retrieval (CPR), a new method for RAG with strong copyright protection guarantees in a mixed-private setting for diffusion models.CPR allows to condition the output of diffusion models on a set of retrieved images, while also guaranteeing that unique identifiable information about those example is not exposed in the generated outputs. In particular, it does so by sampling from a mixture of public (safe) distribution and private (user) distribution by merging their diffusion scores at inference. We prove that CPR satisfies Near Access Freeness (NAF) which bounds the amount of information an attacker may be able to extract from the generated images. We provide two algorithms for copyright protection, CPR-KL and CPR-Choose. Unlike previously proposed rejection-sampling-based NAF methods, our methods enable efficient copyright-protected sampling with a single run of backward diffusion. We show that our method can be applied to any pre-trained conditional diffusion model, such as Stable Diffusion or unCLIP. In particular, we empirically show that applying CPR on top of unCLIP improves quality and text-to-image alignment of the generated results (81.4 to 83.17 on TIFA benchmark), while enabling credit attribution, copy-right protection, and deterministic, constant time, unlearning.
Continuous, Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
Mar 25, 2024In recent years, advances in text-to-image (T2I) diffusion models have substantially elevated the quality of their generated images. However, achieving fine-grained control over attributes remains a challenge due to the limitations of natural language prompts (such as no continuous set of intermediate descriptions existing between ``person'' and ``old person''). Even though many methods were introduced that augment the model or generation process to enable such control, methods that do not require a fixed reference image are limited to either enabling global fine-grained attribute expression control or coarse attribute expression control localized to specific subjects, not both simultaneously. We show that there exist directions in the commonly used token-level CLIP text embeddings that enable fine-grained subject-specific control of high-level attributes in text-to-image models. Based on this observation, we introduce one efficient optimization-free and one robust optimization-based method to identify these directions for specific attributes from contrastive text prompts. We demonstrate that these directions can be used to augment the prompt text input with fine-grained control over attributes of specific subjects in a compositional manner (control over multiple attributes of a single subject) without having to adapt the diffusion model. Project page: https://compvis.github.io/attribute-control. Code is available at https://github.com/CompVis/attribute-control.