 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Revisiting the Evaluation of Image Synthesis with GANs
Apr 04, 2023
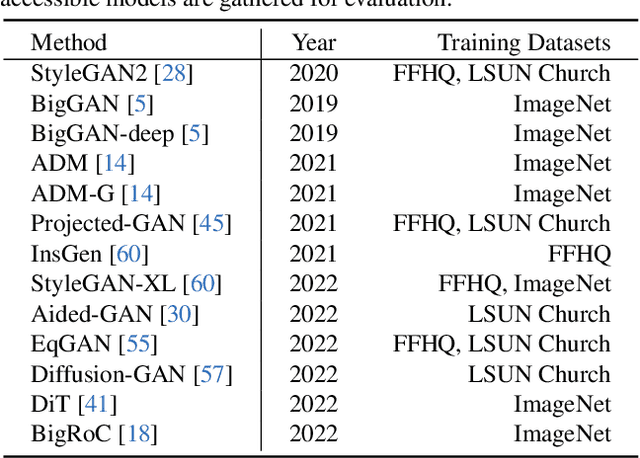
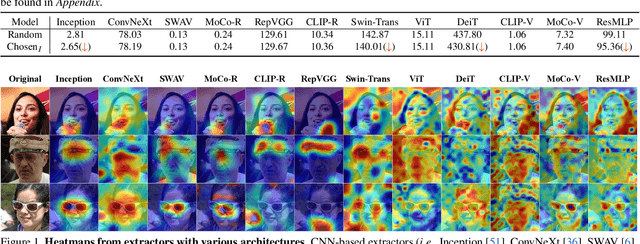
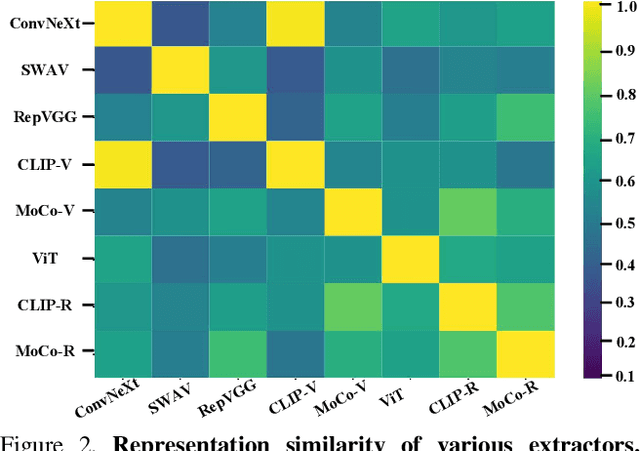

A good metric, which promises a reliable comparison between solutions, is essential to a well-defined task. Unlike most vision tasks that have per-sample ground-truth, image synthesis targets generating \emph{unseen} data and hence is usually evaluated with a distributional distance between one set of real samples and another set of generated samples. This work provides an empirical study on the evaluation of synthesis performance by taking the popular generative adversarial networks (GANs) as a representative of generative models. In particular, we make in-depth analyses on how to represent a data point in the feature space, how to calculate a fair distance using selected samples, and how many instances to use from each set. Experiments on multiple datasets and settings suggest that (1) a group of models including both CNN-based and ViT-based architectures serve as reliable and robust feature extractors, (2) Centered Kernel Alignment (CKA) enables better comparison across various extractors and hierarchical layers in one model, and (3) CKA shows satisfactory sample efficiency and complements existing metrics (\textit{e.g.}, FID) in characterizing the similarity between two internal data correlations. These findings help us design a new measurement system, based on which we re-evaluate the state-of-the-art generative models in a consistent and reliable way.
INDigo: An INN-Guided Probabilistic Diffusion Algorithm for Inverse Problems
Jun 05, 2023
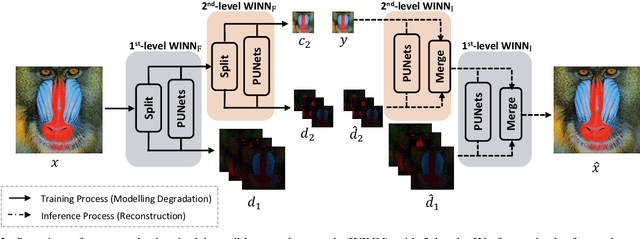
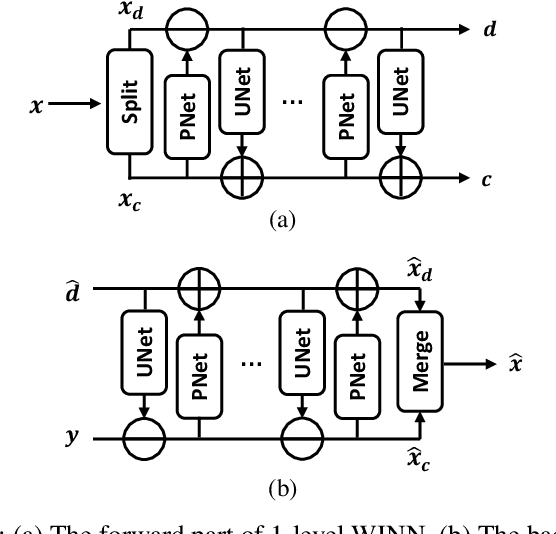
Recently it has been shown that using diffusion models for inverse problems can lead to remarkable results. However, these approaches require a closed-form expression of the degradation model and can not support complex degradations. To overcome this limitation, we propose a method (INDigo) that combines invertible neural networks (INN) and diffusion models for general inverse problems. Specifically, we train the forward process of INN to simulate an arbitrary degradation process and use the inverse as a reconstruction process. During the diffusion sampling process, we impose an additional data-consistency step that minimizes the distance between the intermediate result and the INN-optimized result at every iteration, where the INN-optimized image is composed of the coarse information given by the observed degraded image and the details generated by the diffusion process. With the help of INN, our algorithm effectively estimates the details lost in the degradation process and is no longer limited by the requirement of knowing the closed-form expression of the degradation model. Experiments demonstrate that our algorithm obtains competitive results compared with recently leading methods both quantitatively and visually. Moreover, our algorithm performs well on more complex degradation models and real-world low-quality images.
Aerial Diffusion: Text Guided Ground-to-Aerial View Translation from a Single Image using Diffusion Models
Mar 15, 2023
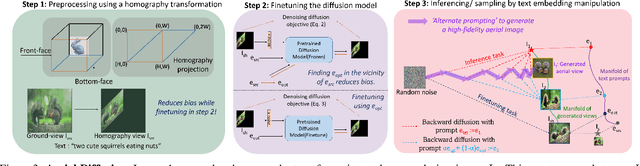


We present a novel method, Aerial Diffusion, for generating aerial views from a single ground-view image using text guidance. Aerial Diffusion leverages a pretrained text-image diffusion model for prior knowledge. We address two main challenges corresponding to domain gap between the ground-view and the aerial view and the two views being far apart in the text-image embedding manifold. Our approach uses a homography inspired by inverse perspective mapping prior to finetuning the pretrained diffusion model. Additionally, using the text corresponding to the ground-view to finetune the model helps us capture the details in the ground-view image at a relatively low bias towards the ground-view image. Aerial Diffusion uses an alternating sampling strategy to compute the optimal solution on complex high-dimensional manifold and generate a high-fidelity (w.r.t. ground view) aerial image. We demonstrate the quality and versatility of Aerial Diffusion on a plethora of images from various domains including nature, human actions, indoor scenes, etc. We qualitatively prove the effectiveness of our method with extensive ablations and comparisons. To the best of our knowledge, Aerial Diffusion is the first approach that performs ground-to-aerial translation in an unsupervised manner.
Report of the Medical Image De-Identification (MIDI) Task Group -- Best Practices and Recommendations
Apr 01, 2023This report addresses the technical aspects of de-identification of medical images of human subjects and biospecimens, such that re-identification risk of ethical, moral, and legal concern is sufficiently reduced to allow unrestricted public sharing for any purpose, regardless of the jurisdiction of the source and distribution sites. All medical images, regardless of the mode of acquisition, are considered, though the primary emphasis is on those with accompanying data elements, especially those encoded in formats in which the data elements are embedded, particularly Digital Imaging and Communications in Medicine (DICOM). These images include image-like objects such as Segmentations, Parametric Maps, and Radiotherapy (RT) Dose objects. The scope also includes related non-image objects, such as RT Structure Sets, Plans and Dose Volume Histograms, Structured Reports, and Presentation States. Only de-identification of publicly released data is considered, and alternative approaches to privacy preservation, such as federated learning for artificial intelligence (AI) model development, are out of scope, as are issues of privacy leakage from AI model sharing. Only technical issues of public sharing are addressed.
Shape Guided Gradient Voting for Domain Generalization
Jun 19, 2023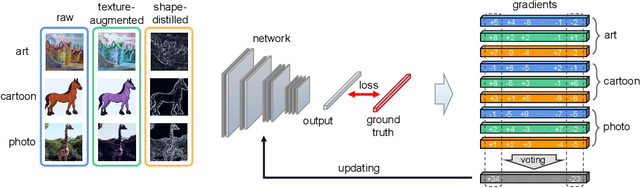
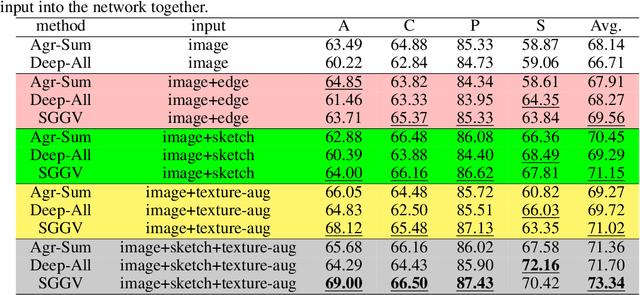
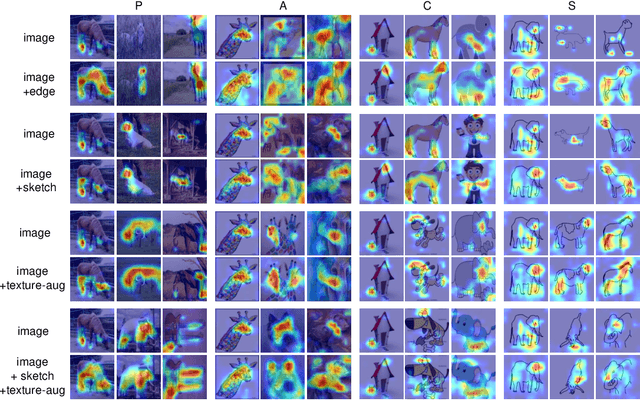

Domain generalization aims to address the domain shift between training and testing data. To learn the domain invariant representations, the model is usually trained on multiple domains. It has been found that the gradients of network weight relative to a specific task loss can characterize the task itself. In this work, with the assumption that the gradients of a specific domain samples under the classification task could also reflect the property of the domain, we propose a Shape Guided Gradient Voting (SGGV) method for domain generalization. Firstly, we introduce shape prior via extra inputs of the network to guide gradient descending towards a shape-biased direction for better generalization. Secondly, we propose a new gradient voting strategy to remove the outliers for robust optimization in the presence of shape guidance. To provide shape guidance, we add edge/sketch extracted from the training data as an explicit way, and also use texture augmented images as an implicit way. We conduct experiments on several popular domain generalization datasets in image classification task, and show that our shape guided gradient updating strategy brings significant improvement of the generalization.
UncLe-SLAM: Uncertainty Learning for Dense Neural SLAM
Jun 19, 2023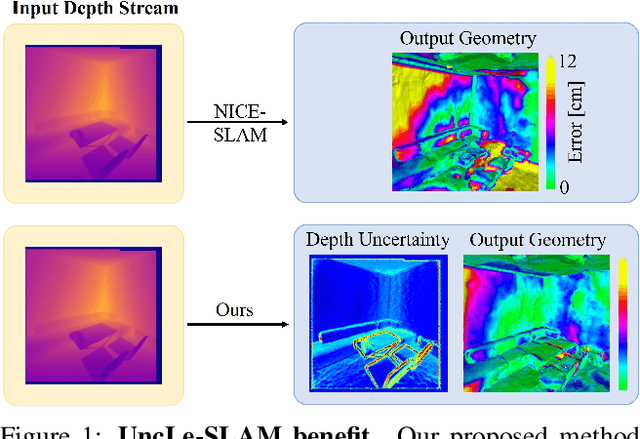
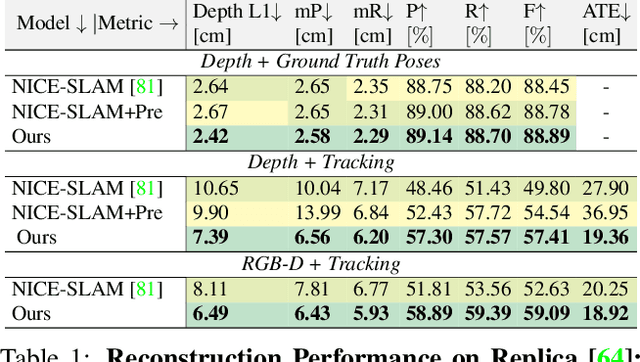
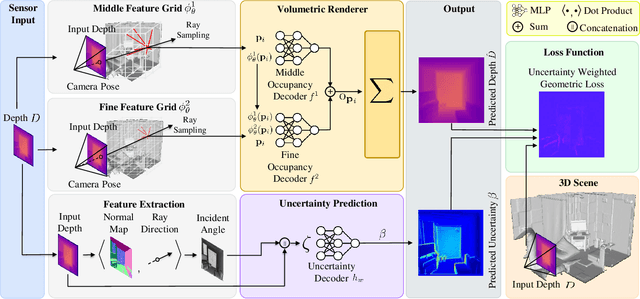
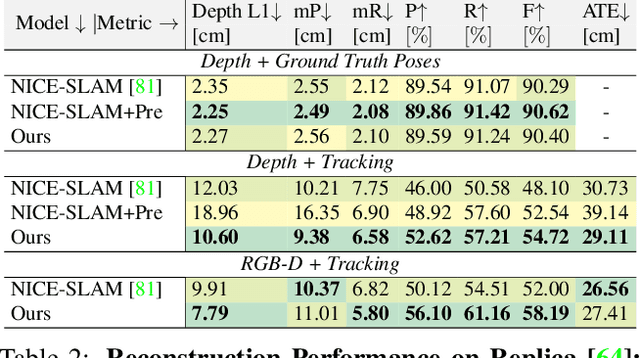
We present an uncertainty learning framework for dense neural simultaneous localization and mapping (SLAM). Estimating pixel-wise uncertainties for the depth input of dense SLAM methods allows to re-weigh the tracking and mapping losses towards image regions that contain more suitable information that is more reliable for SLAM. To this end, we propose an online framework for sensor uncertainty estimation that can be trained in a self-supervised manner from only 2D input data. We further discuss the advantages of the uncertainty learning for the case of multi-sensor input. Extensive analysis, experimentation, and ablations show that our proposed modeling paradigm improves both mapping and tracking accuracy and often performs better than alternatives that require ground truth depth or 3D. Our experiments show that we achieve a 38% and 27% lower absolute trajectory tracking error (ATE) on the 7-Scenes and TUM-RGBD datasets respectively. On the popular Replica dataset on two types of depth sensors we report an 11% F1-score improvement on RGBD SLAM compared to the recent state-of-the-art neural implicit approaches. Our source code will be made available.
AutoEnsemble: Automated Ensemble Search Framework for Semantic Segmentation Using Image Labels
Mar 15, 2023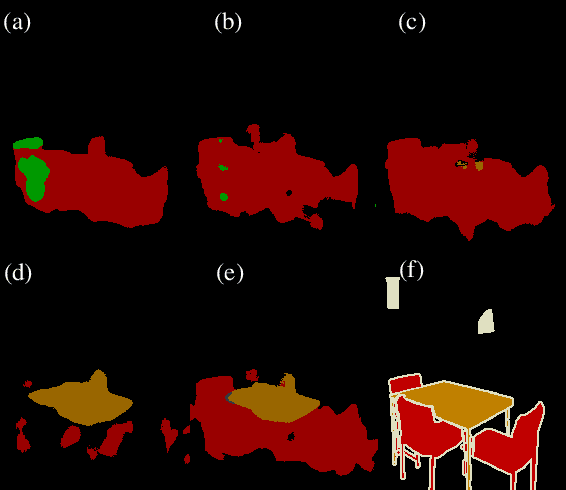
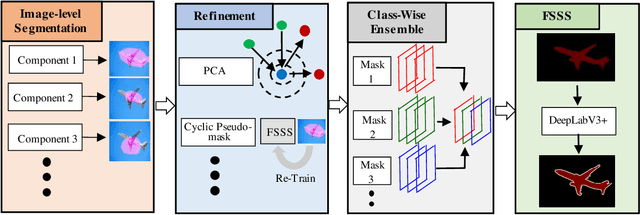


A key bottleneck of employing state-of-the-art semantic segmentation networks in the real world is the availability of training labels. Standard semantic segmentation networks require massive pixel-wise annotated labels to reach state-of-the-art prediction quality. Hence, several works focus on semantic segmentation networks trained with only image-level annotations. However, when scrutinizing the state-of-the-art results in more detail, we notice that although they are very close to each other on average prediction quality, different approaches perform better in different classes while providing low quality in others. To address this problem, we propose a novel framework, AutoEnsemble, which employs an ensemble of the "pseudo-labels" for a given set of different segmentation techniques on a class-wise level. Pseudo-labels are the pixel-wise predictions of the image-level semantic segmentation frameworks used to train the final segmentation model. Our pseudo-labels seamlessly combine the strong points of multiple segmentation techniques approaches to reach superior prediction quality. We reach up to 2.4% improvement over AutoEnsemble's components. An exhaustive analysis was performed to demonstrate AutoEnsemble's effectiveness over state-of-the-art frameworks for image-level semantic segmentation.
Design a Delicious Lunchbox in Style
May 22, 2023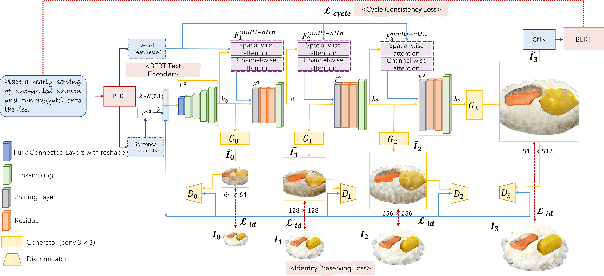
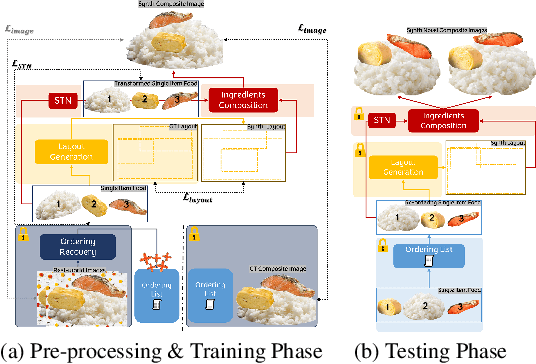

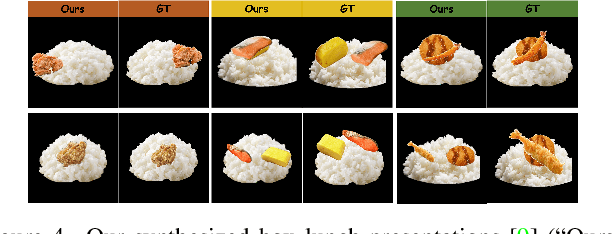
We propose a cyclic generative adversarial network with spatial-wise and channel-wise attention modules for text-to-image synthesis. To accurately depict and design scenes with multiple occluded objects, we design a pre-trained ordering recovery model and a generative adversarial network to predict layout and composite novel box lunch presentations. In the experiments, we devise the Bento800 dataset to evaluate the performance of the text-to-image synthesis model and the layout generation & image composition model. This paper is the continuation of our previous paper works. We also present additional experiments and qualitative performance comparisons to verify the effectiveness of our proposed method. Bento800 dataset is available at https://github.com/Yutong-Zhou-cv/Bento800_Dataset
Enhance Reasoning Ability of Visual-Language Models via Large Language Models
May 22, 2023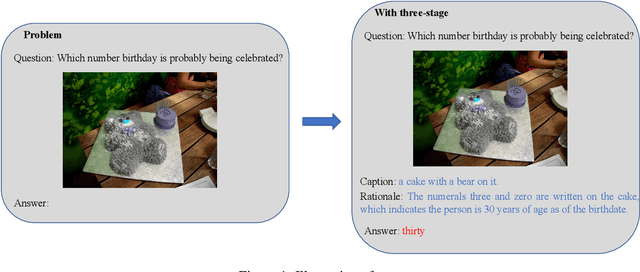
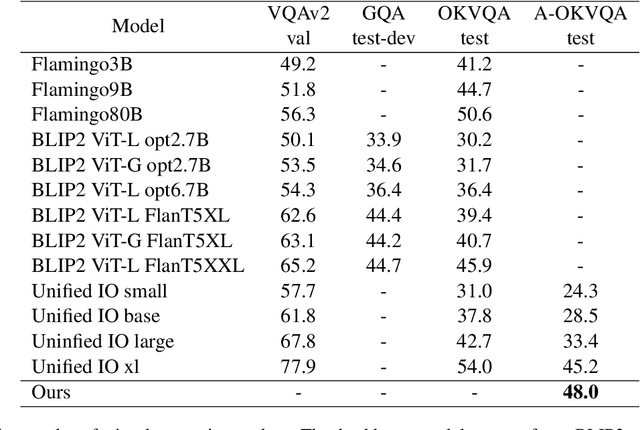


Pre-trained visual language models (VLM) have shown excellent performance in image caption tasks. However, it sometimes shows insufficient reasoning ability. In contrast, large language models (LLMs) emerge with powerful reasoning capabilities. Therefore, we propose a method called TReE, which transfers the reasoning ability of a large language model to a visual language model in zero-shot scenarios. TReE contains three stages: observation, thinking, and re-thinking. Observation stage indicates that VLM obtains the overall information of the relative image. Thinking stage combines the image information and task description as the prompt of the LLM, inference with the rationals. Re-Thinking stage learns from rationale and then inference the final result through VLM.
Covariance properties under natural image transformations for the generalized Gaussian derivative model for visual receptive fields
Mar 17, 2023
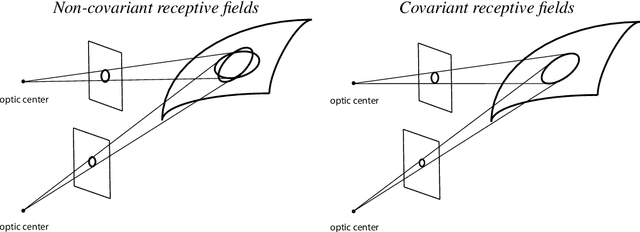


This paper presents a theory for how geometric image transformations can be handled by a first layer of linear receptive fields, in terms of true covariance properties, which, in turn, enable geometric invariance properties at higher levels in the visual hierarchy. Specifically, we develop this theory for a generalized Gaussian derivative model for visual receptive fields, which is derived in an axiomatic manner from first principles, that reflect symmetry properties of the environment, complemented by structural assumptions to guarantee internally consistent treatment of image structures over multiple spatio-temporal scales. It is shown how the studied generalized Gaussian derivative model for visual receptive fields obeys true covariance properties under spatial scaling transformations, spatial affine transformations, Galilean transformations and temporal scaling transformations, implying that a vision system, based on image and video measurements in terms of the receptive fields according to this model, can to first order of approximation handle the image and video deformations between multiple views of objects delimited by smooth surfaces, as well as between multiple views of spatio-temporal events, under varying relative motions between the objects and events in the world and the observer. We conclude by describing implications of the presented theory for biological vision, regarding connections between the variabilities of the shapes of biological visual receptive fields and the variabilities of spatial and spatio-temporal image structures under natural image transformations.