 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modulating Pretrained Diffusion Models for Multimodal Image Synthesis
Feb 24, 2023

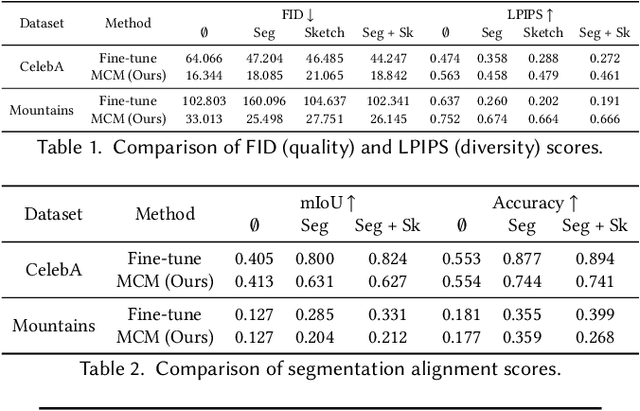
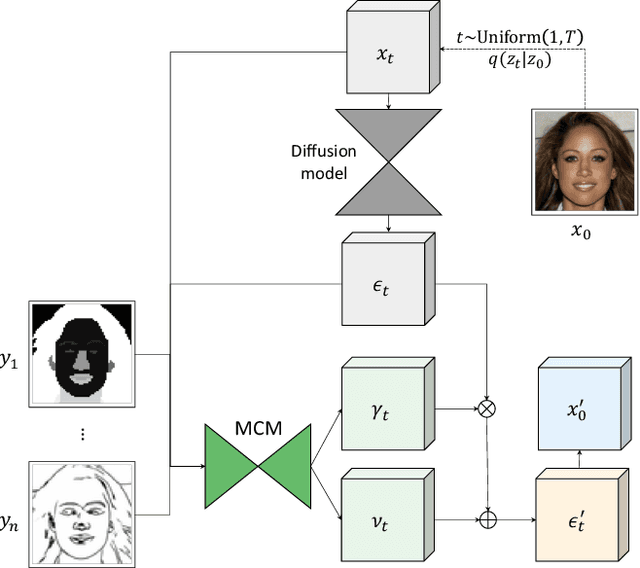
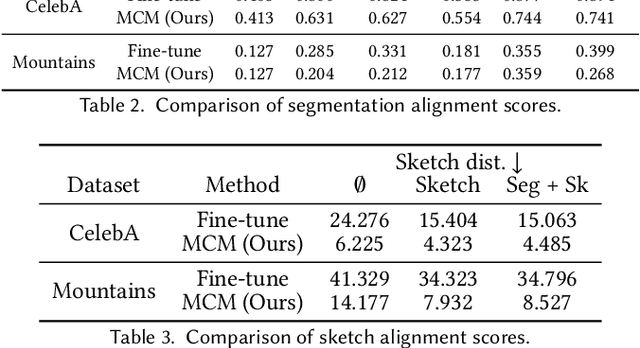
We present multimodal conditioning modules (MCM) for enabling conditional image synthesis using pretrained diffusion models. Previous multimodal synthesis works rely on training networks from scratch or fine-tuning pretrained networks, both of which are computationally expensive for large, state-of-the-art diffusion models. Our method uses pretrained networks but does not require any updates to the diffusion network's parameters. MCM is a small module trained to modulate the diffusion network's predictions during sampling using 2D modalities (e.g., semantic segmentation maps, sketches) that were unseen during the original training of the diffusion model. We show that MCM enables user control over the spatial layout of the image and leads to increased control over the image generation process. Training MCM is cheap as it does not require gradients from the original diffusion net, consists of only $\sim$1$\%$ of the number of parameters of the base diffusion model, and is trained using only a limited number of training examples. We evaluate our method on unconditional and text-conditional models to demonstrate the improved control over the generated images and their alignment with respect to the conditioning inputs.
Variational Quantum Neural Networks (VQNNS) in Image Classification
Mar 10, 2023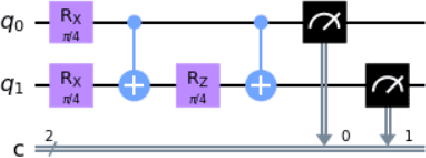

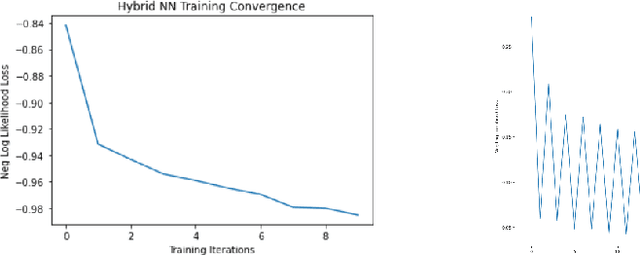
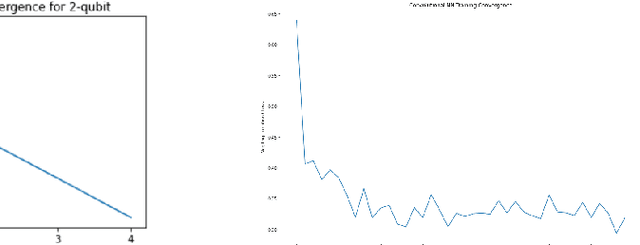
Quantum machine learning has established as an interdisciplinary field to overcome limitations of classical machine learning and neural networks. This is a field of research which can prove that quantum computers are able to solve problems with complex correlations between inputs that can be hard for classical computers. This suggests that learning models made on quantum computers may be more powerful for applications, potentially faster computation and better generalization on less data. The objective of this paper is to investigate how training of quantum neural network (QNNs) can be done using quantum optimization algorithms for improving the performance and time complexity of QNNs. A classical neural network can be partially quantized to create a hybrid quantum-classical neural network which is used mainly in classification and image recognition. In this paper, a QNN structure is made where a variational parameterized circuit is incorporated as an input layer named as Variational Quantum Neural Network (VQNNs). We encode the cost function of QNNs onto relative phases of a superposition state in the Hilbert space of the network parameters. The parameters are tuned with an iterative quantum approximate optimisation (QAOA) mixer and problem hamiltonians. VQNNs is experimented with MNIST digit recognition (less complex) and crack image classification datasets (more complex) which converges the computation in lesser time than QNN with decent training accuracy.
Random-Access Neural Compression of Material Textures
May 26, 2023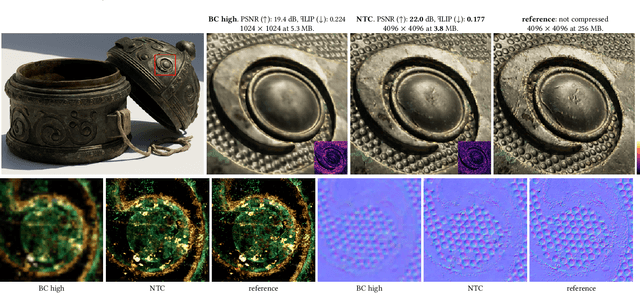

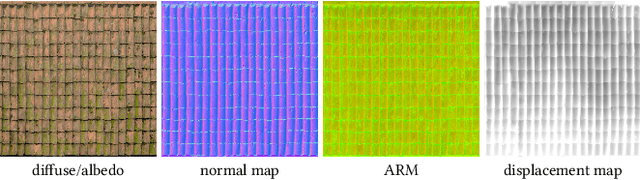

The continuous advancement of photorealism in rendering is accompanied by a growth in texture data and, consequently, increasing storage and memory demands. To address this issue, we propose a novel neural compression technique specifically designed for material textures. We unlock two more levels of detail, i.e., 16x more texels, using low bitrate compression, with image quality that is better than advanced image compression techniques, such as AVIF and JPEG XL. At the same time, our method allows on-demand, real-time decompression with random access similar to block texture compression on GPUs, enabling compression on disk and memory. The key idea behind our approach is compressing multiple material textures and their mipmap chains together, and using a small neural network, that is optimized for each material, to decompress them. Finally, we use a custom training implementation to achieve practical compression speeds, whose performance surpasses that of general frameworks, like PyTorch, by an order of magnitude.
Linear Object Detection in Document Images using Multiple Object Tracking
May 26, 2023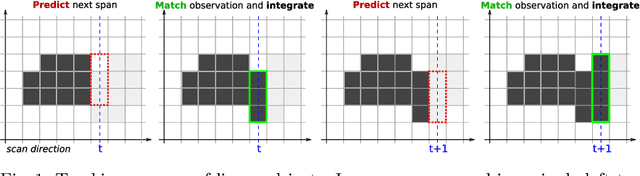
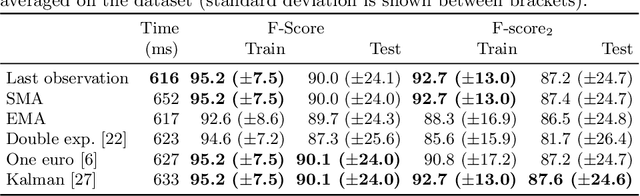

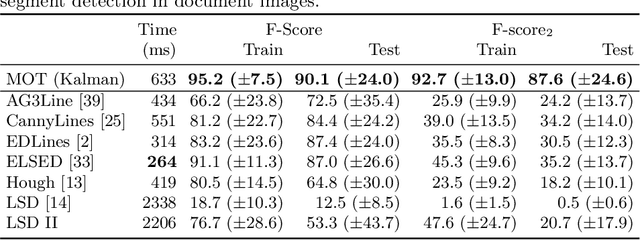
Linear objects convey substantial information about document structure, but are challenging to detect accurately because of degradation (curved, erased) or decoration (doubled, dashed). Many approaches can recover some vector representation, but only one closed-source technique introduced in 1994, based on Kalman filters (a particular case of Multiple Object Tracking algorithm), can perform a pixel-accurate instance segmentation of linear objects and enable to selectively remove them from the original image. We aim at re-popularizing this approach and propose: 1. a framework for accurate instance segmentation of linear objects in document images using Multiple Object Tracking (MOT); 2. document image datasets and metrics which enable both vector- and pixel-based evaluation of linear object detection; 3. performance measures of MOT approaches against modern segment detectors; 4. performance measures of various tracking strategies, exhibiting alternatives to the original Kalman filters approach; and 5. an open-source implementation of a detector which can discriminate instances of curved, erased, dashed, intersecting and/or overlapping linear objects.
Real-World Denoising via Diffusion Model
May 08, 2023
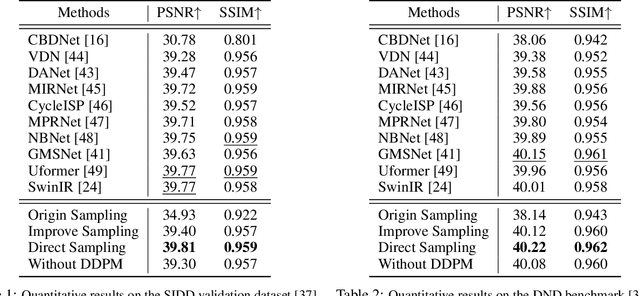


Real-world image denoising is an extremely important image processing problem, which aims to recover clean images from noisy images captured in natural environments. In recent years, diffusion models have achieved very promising results in the field of image generation, outperforming previous generation models. However, it has not been widely used in the field of image denoising because it is difficult to control the appropriate position of the added noise. Inspired by diffusion models, this paper proposes a novel general denoising diffusion model that can be used for real-world image denoising. We introduce a diffusion process with linear interpolation, and the intermediate noisy image is interpolated from the original clean image and the corresponding real-world noisy image, so that this diffusion model can handle the level of added noise. In particular, we also introduce two sampling algorithms for this diffusion model. The first one is a simple sampling procedure defined according to the diffusion process, and the second one targets the problem of the first one and makes a number of improvements. Our experimental results show that our proposed method with a simple CNNs Unet achieves comparable results compared to the Transformer architecture. Both quantitative and qualitative evaluations on real-world denoising benchmarks show that the proposed general diffusion model performs almost as well as against the state-of-the-art methods.
SS-BSN: Attentive Blind-Spot Network for Self-Supervised Denoising with Nonlocal Self-Similarity
May 17, 2023
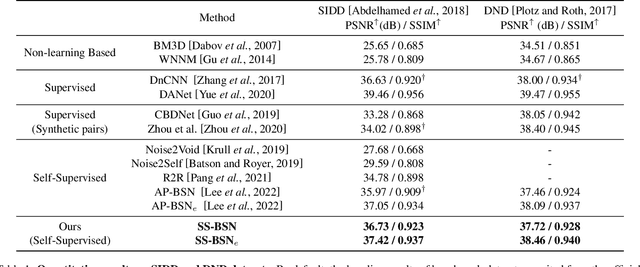
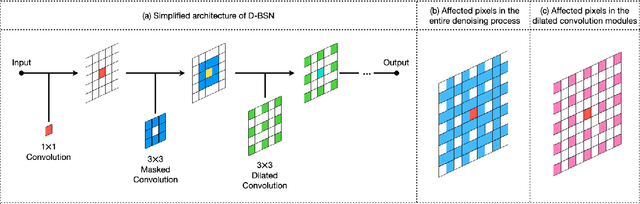
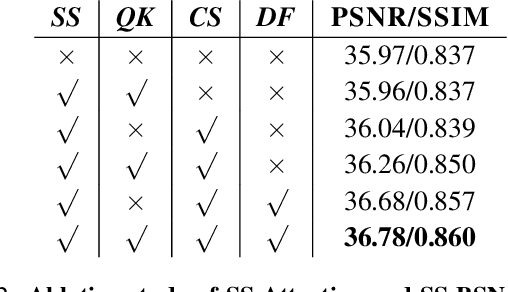
Recently, numerous studies have been conducted on supervised learning-based image denoising methods. However, these methods rely on large-scale noisy-clean image pairs, which are difficult to obtain in practice. Denoising methods with self-supervised training that can be trained with only noisy images have been proposed to address the limitation. These methods are based on the convolutional neural network (CNN) and have shown promising performance. However, CNN-based methods do not consider using nonlocal self-similarities essential in the traditional method, which can cause performance limitations. This paper presents self-similarity attention (SS-Attention), a novel self-attention module that can capture nonlocal self-similarities to solve the problem. We focus on designing a lightweight self-attention module in a pixel-wise manner, which is nearly impossible to implement using the classic self-attention module due to the quadratically increasing complexity with spatial resolution. Furthermore, we integrate SS-Attention into the blind-spot network called self-similarity-based blind-spot network (SS-BSN). We conduct the experiments on real-world image denoising tasks. The proposed method quantitatively and qualitatively outperforms state-of-the-art methods in self-supervised denoising on the Smartphone Image Denoising Dataset (SIDD) and Darmstadt Noise Dataset (DND) benchmark datasets.
Align, Perturb and Decouple: Toward Better Leverage of Difference Information for RSI Change Detection
May 30, 2023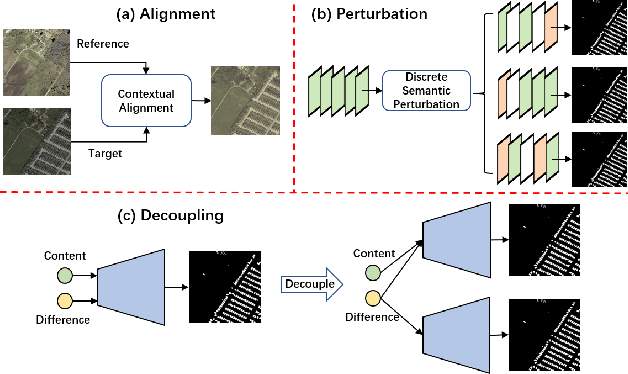
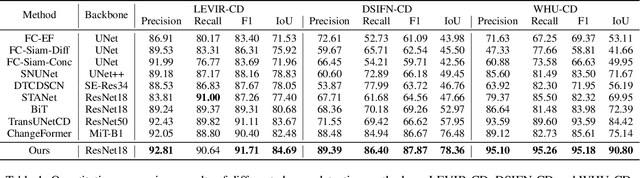
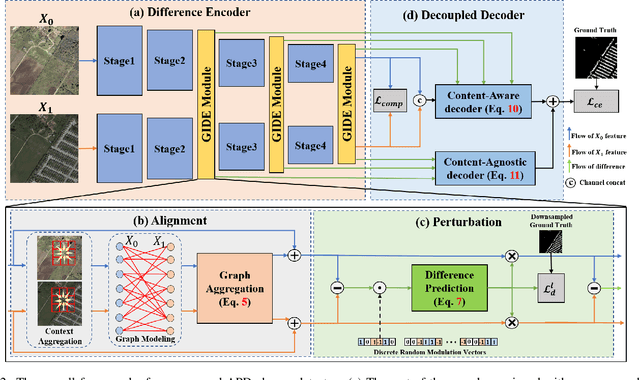
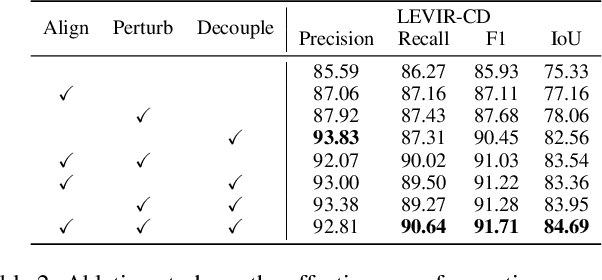
Change detection is a widely adopted technique in remote sense imagery (RSI) analysis in the discovery of long-term geomorphic evolution. To highlight the areas of semantic changes, previous effort mostly pays attention to learning representative feature descriptors of a single image, while the difference information is either modeled with simple difference operations or implicitly embedded via feature interactions. Nevertheless, such difference modeling can be noisy since it suffers from non-semantic changes and lacks explicit guidance from image content or context. In this paper, we revisit the importance of feature difference for change detection in RSI, and propose a series of operations to fully exploit the difference information: Alignment, Perturbation and Decoupling (APD). Firstly, alignment leverages contextual similarity to compensate for the non-semantic difference in feature space. Next, a difference module trained with semantic-wise perturbation is adopted to learn more generalized change estimators, which reversely bootstraps feature extraction and prediction. Finally, a decoupled dual-decoder structure is designed to predict semantic changes in both content-aware and content-agnostic manners. Extensive experiments are conducted on benchmarks of LEVIR-CD, WHU-CD and DSIFN-CD, demonstrating our proposed operations bring significant improvement and achieve competitive results under similar comparative conditions. Code is available at https://github.com/wangsp1999/CD-Research/tree/main/openAPD
Fine-Grained is Too Coarse: A Novel Data-Centric Approach for Efficient Scene Graph Generation
May 30, 2023
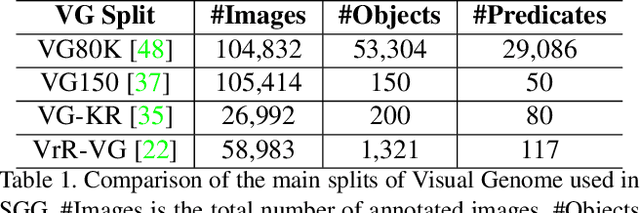
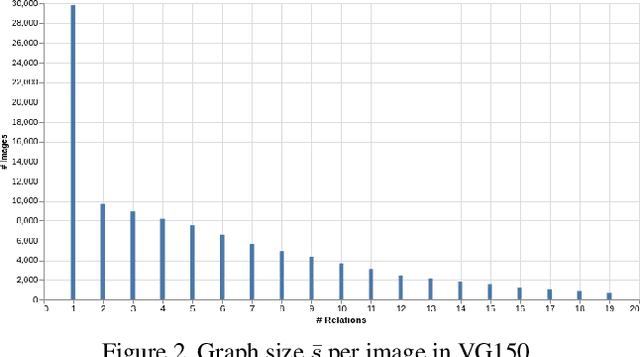
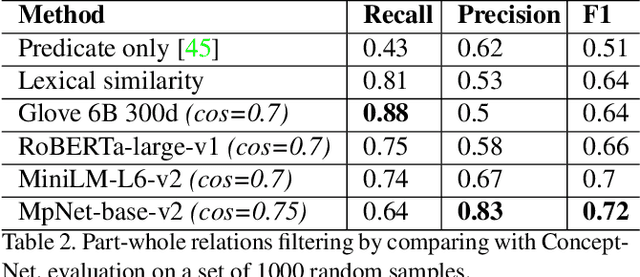
Learning to compose visual relationships from raw images in the form of scene graphs is a highly challenging task due to contextual dependencies, but it is essential in computer vision applications that depend on scene understanding. However, no current approaches in Scene Graph Generation (SGG) aim at providing useful graphs for downstream tasks. Instead, the main focus has primarily been on the task of unbiasing the data distribution for predicting more fine-grained relations. That being said, all fine-grained relations are not equally relevant and at least a part of them are of no use for real-world applications. In this work, we introduce the task of Efficient SGG that prioritizes the generation of relevant relations, facilitating the use of Scene Graphs in downstream tasks such as Image Generation. To support further approaches in this task, we present a new dataset, VG150-curated, based on the annotations of the popular Visual Genome dataset. We show through a set of experiments that this dataset contains more high-quality and diverse annotations than the one usually adopted by approaches in SGG. Finally, we show the efficiency of this dataset in the task of Image Generation from Scene Graphs. Our approach can be easily replicated to improve the quality of other Scene Graph Generation datasets.
Selective Amnesia: A Continual Learning Approach to Forgetting in Deep Generative Models
May 17, 2023
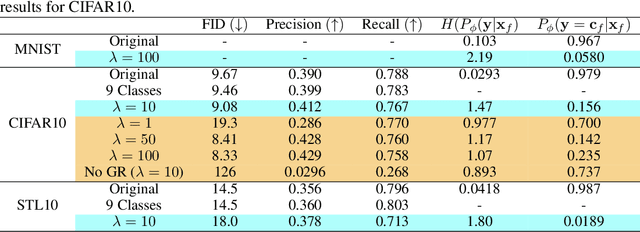

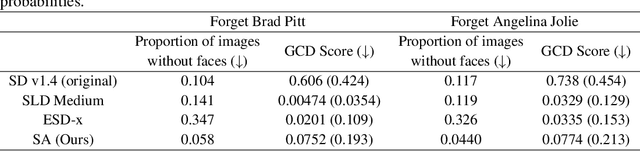
The recent proliferation of large-scale text-to-image models has led to growing concerns that such models may be misused to generate harmful, misleading, and inappropriate content. Motivated by this issue, we derive a technique inspired by continual learning to selectively forget concepts in pretrained deep generative models. Our method, dubbed Selective Amnesia, enables controllable forgetting where a user can specify how a concept should be forgotten. Selective Amnesia can be applied to conditional variational likelihood models, which encompass a variety of popular deep generative frameworks, including variational autoencoders and large-scale text-to-image diffusion models. Experiments across different models demonstrate that our approach induces forgetting on a variety of concepts, from entire classes in standard datasets to celebrity and nudity prompts in text-to-image models. Our code is publicly available at https://github.com/clear-nus/selective-amnesia.
BIFRNet: A Brain-Inspired Feature Restoration DNN for Partially Occluded Image Recognition
Mar 02, 2023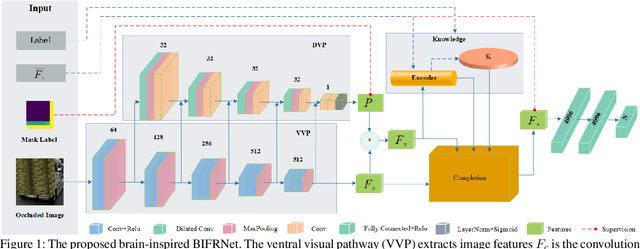


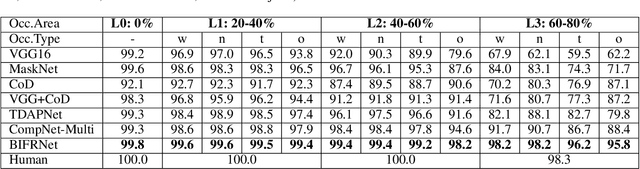
The partially occluded image recognition (POIR) problem has been a challenge for artificial intelligence for a long time. A common strategy to handle the POIR problem is using the non-occluded features for classification. Unfortunately, this strategy will lose effectiveness when the image is severely occluded, since the visible parts can only provide limited information. Several studies in neuroscience reveal that feature restoration which fills in the occluded information and is called amodal completion is essential for human brains to recognize partially occluded images. However, feature restoration is commonly ignored by CNNs, which may be the reason why CNNs are ineffective for the POIR problem. Inspired by this, we propose a novel brain-inspired feature restoration network (BIFRNet) to solve the POIR problem. It mimics a ventral visual pathway to extract image features and a dorsal visual pathway to distinguish occluded and visible image regions. In addition, it also uses a knowledge module to store object prior knowledge and uses a completion module to restore occluded features based on visible features and prior knowledge. Thorough experiments on synthetic and real-world occluded image datasets show that BIFRNet outperforms the existing methods in solving the POIR problem. Especially for severely occluded images, BIRFRNet surpasses other methods by a large margin and is close to the human brain performance. Furthermore, the brain-inspired design makes BIFRNet more interpretable.