 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Better Explanations for Object Detection
Jun 06, 2023
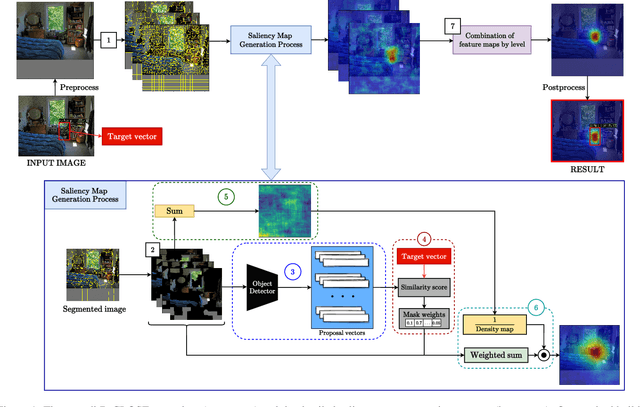

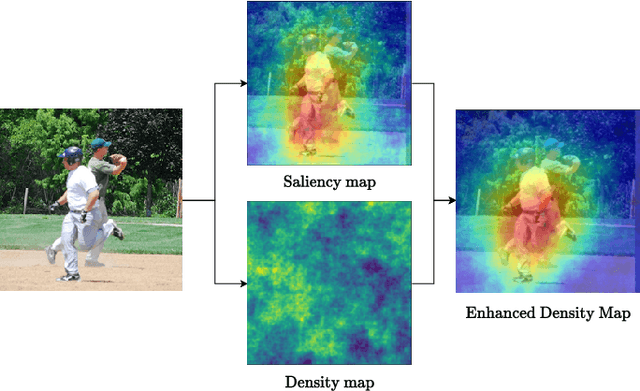
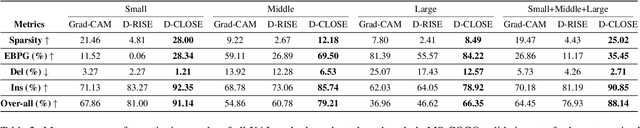
Recent advances in Artificial Intelligence (AI) technology have promoted their use in almost every field. The growing complexity of deep neural networks (DNNs) makes it increasingly difficult and important to explain the inner workings and decisions of the network. However, most current techniques for explaining DNNs focus mainly on interpreting classification tasks. This paper proposes a method to explain the decision for any object detection model called D-CLOSE. To closely track the model's behavior, we used multiple levels of segmentation on the image and a process to combine them. We performed tests on the MS-COCO dataset with the YOLOX model, which shows that our method outperforms D-RISE and can give a better quality and less noise explanation.
Single-Shot Global Localization via Graph-Theoretic Correspondence Matching
Jun 06, 2023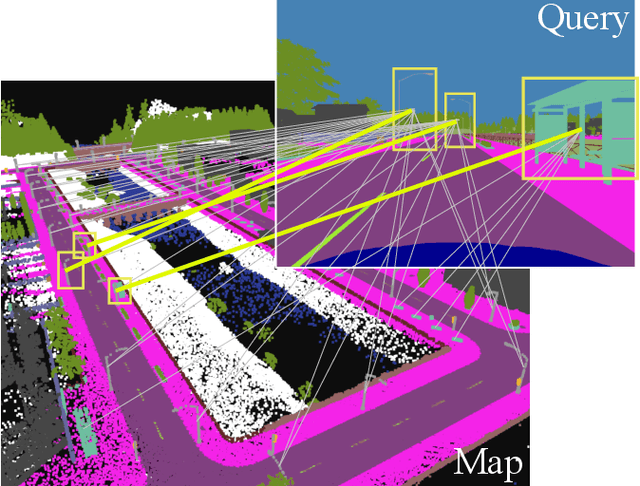
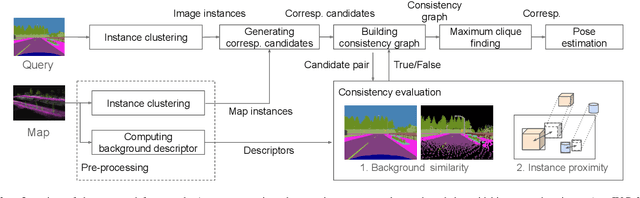
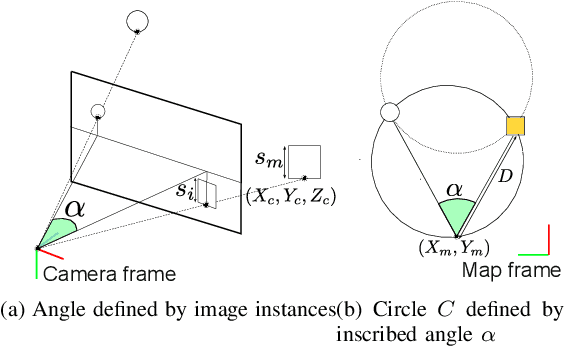
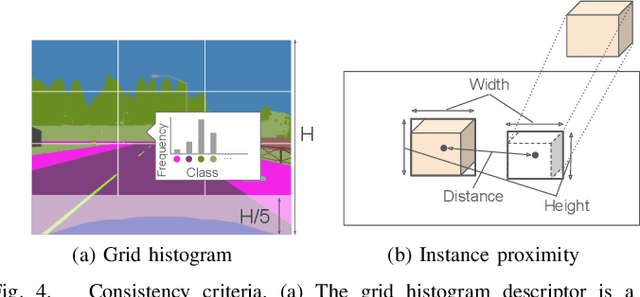
This paper describes a method of global localization based on graph-theoretic association of instances between a query and the prior map. The proposed framework employs correspondence matching based on the maximum clique problem (MCP). The framework is potentially applicable to other map and/or query modalities thanks to the graph-based abstraction of the problem, while many of existing global localization methods rely on a query and the dataset in the same modality. We implement it with a semantically labeled 3D point cloud map, and a semantic segmentation image as a query. Leveraging the graph-theoretic framework, the proposed method realizes global localization exploiting only the map and the query. The method shows promising results on multiple large-scale simulated maps of urban scenes.
Memorization Capacity of Multi-Head Attention in Transformers
Jun 03, 2023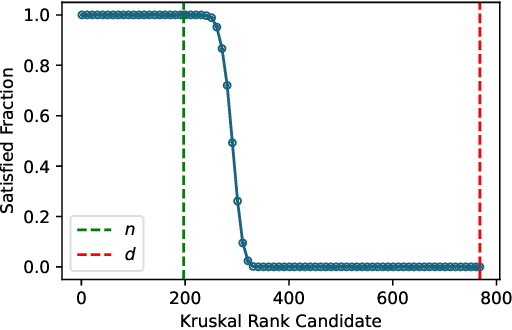

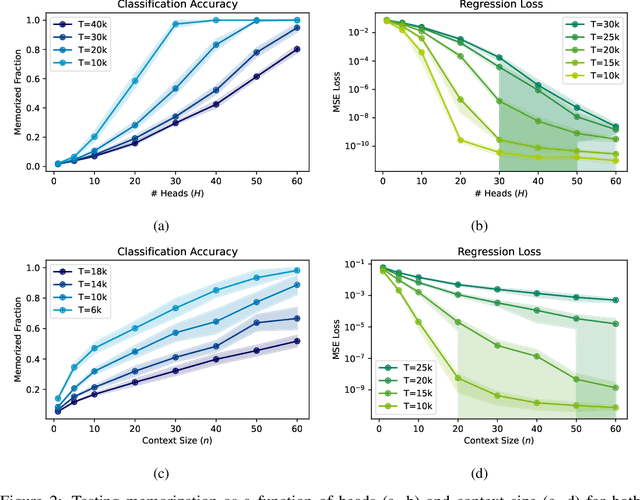
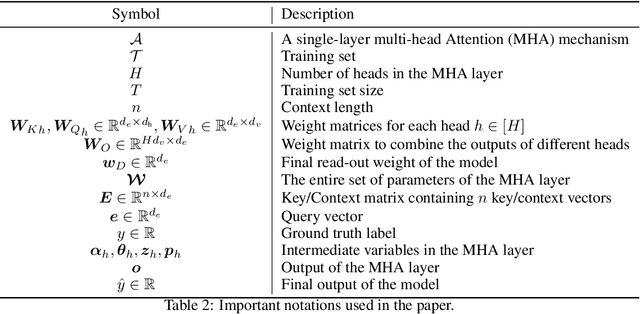
In this paper, we investigate the memorization capabilities of multi-head attention in Transformers, motivated by the central role attention plays in these models. Under a mild linear independence assumption on the input data, we present a theoretical analysis demonstrating that an $H$-head attention layer with a context size $n$, dimension $d$, and $O(Hd^2)$ parameters can memorize $O(Hn)$ examples. We conduct experiments that verify our assumptions on the image classification task using Vision Transformer. To validate our theoretical findings, we perform synthetic experiments and show a linear relationship between memorization capacity and the number of attention heads.
Depth Estimation and Image Restoration by Deep Learning from Defocused Images
Feb 21, 2023

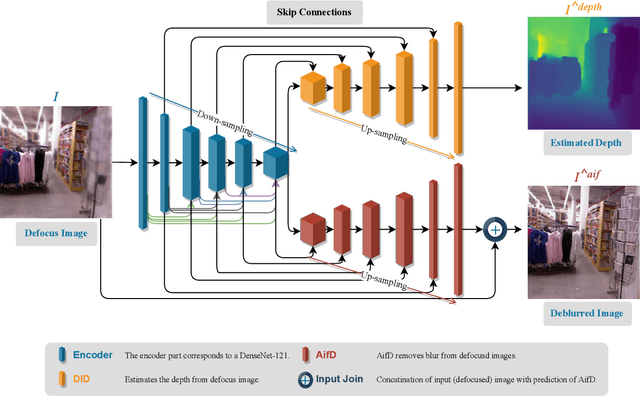
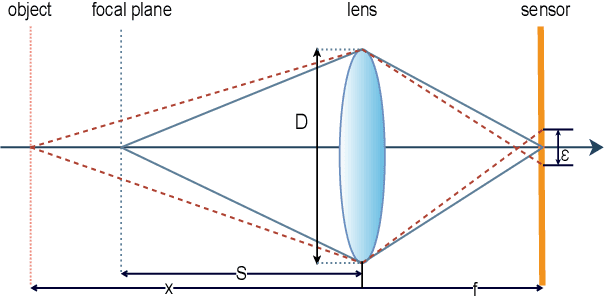
Monocular depth estimation and image deblurring are two fundamental tasks in computer vision, given their crucial role in understanding 3D scenes. Performing any of them by relying on a single image is an ill-posed problem. The recent advances in the field of deep convolutional neural networks (DNNs) have revolutionized many tasks in computer vision, including depth estimation and image deblurring. When it comes to using defocused images, the depth estimation and the recovery of the All-in-Focus (Aif) image become related problems due to defocus physics. In spite of this, most of the existing models treat them separately. There are, however, recent models that solve these problems simultaneously by concatenating two networks in a sequence to first estimate the depth or defocus map and then reconstruct the focused image based on it. We propose a DNN that solves the depth estimation and image deblurring in parallel. Our Two-headed Depth Estimation and Deblurring Network (2HDED:NET) extends a conventional Depth from Defocus (DFD) network with a deblurring branch that shares the same encoder as the depth branch. The proposed method has been successfully tested on two benchmarks, one for indoor and the other for outdoor scenes: NYU-v2 and Make3D. Extensive experiments with 2HDED:NET on these benchmarks have demonstrated superior or close performances to those of the state-of-the-art models for depth estimation and image deblurring.
MemeCap: A Dataset for Captioning and Interpreting Memes
May 23, 2023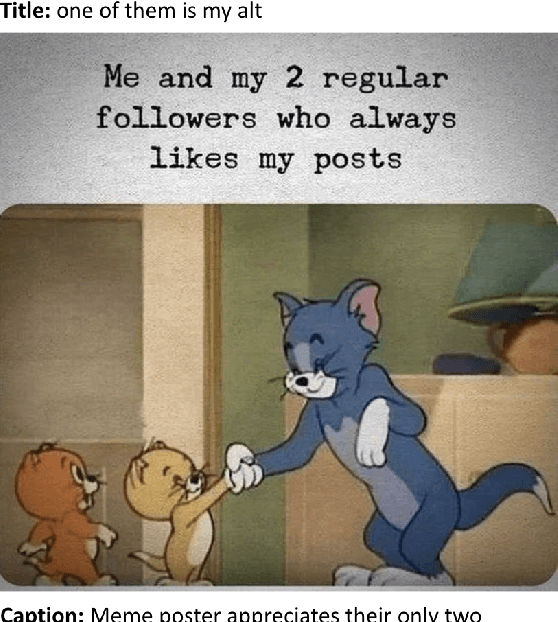
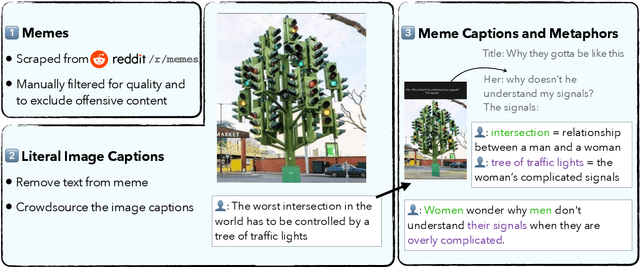

Memes are a widely popular tool for web users to express their thoughts using visual metaphors. Understanding memes requires recognizing and interpreting visual metaphors with respect to the text inside or around the meme, often while employing background knowledge and reasoning abilities. We present the task of meme captioning and release a new dataset, MemeCap. Our dataset contains 6.3K memes along with the title of the post containing the meme, the meme captions, the literal image caption, and the visual metaphors. Despite the recent success of vision and language (VL) models on tasks such as image captioning and visual question answering, our extensive experiments using state-of-the-art VL models show that they still struggle with visual metaphors, and perform substantially worse than humans.
Recyclable Semi-supervised Method Based on Multi-model Ensemble for Video Scene Parsing
Jun 05, 2023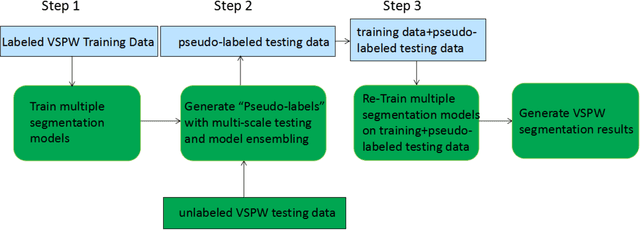

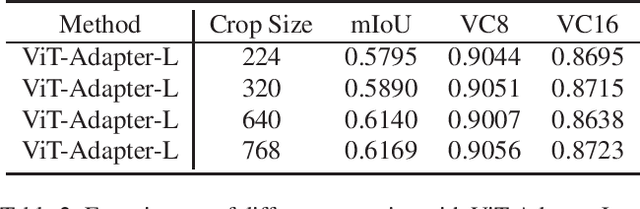

Pixel-level Scene Understanding is one of the fundamental problems in computer vision, which aims at recognizing object classes, masks and semantics of each pixel in the given image. Since the real-world is actually video-based rather than a static state, learning to perform video semantic segmentation is more reasonable and practical for realistic applications. In this paper, we adopt Mask2Former as architecture and ViT-Adapter as backbone. Then, we propose a recyclable semi-supervised training method based on multi-model ensemble. Our method achieves the mIoU scores of 62.97% and 65.83% on Development test and final test respectively. Finally, we obtain the 2nd place in the Video Scene Parsing in the Wild Challenge at CVPR 2023.
CDPMSR: Conditional Diffusion Probabilistic Models for Single Image Super-Resolution
Feb 14, 2023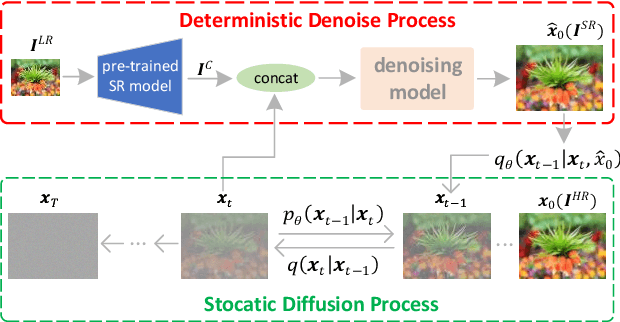
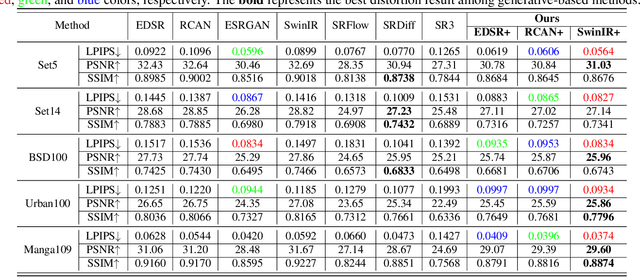

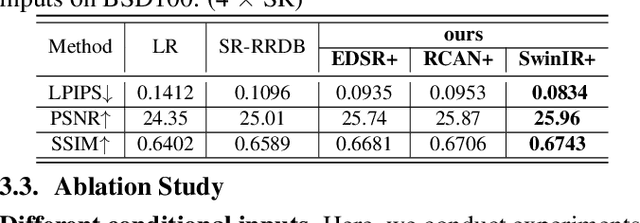
Diffusion probabilistic models (DPM) have been widely adopted in image-to-image translation to generate high-quality images. Prior attempts at applying the DPM to image super-resolution (SR) have shown that iteratively refining a pure Gaussian noise with a conditional image using a U-Net trained on denoising at various-level noises can help obtain a satisfied high-resolution image for the low-resolution one. To further improve the performance and simplify current DPM-based super-resolution methods, we propose a simple but non-trivial DPM-based super-resolution post-process framework,i.e., cDPMSR. After applying a pre-trained SR model on the to-be-test LR image to provide the conditional input, we adapt the standard DPM to conduct conditional image generation and perform super-resolution through a deterministic iterative denoising process. Our method surpasses prior attempts on both qualitative and quantitative results and can generate more photo-realistic counterparts for the low-resolution images with various benchmark datasets including Set5, Set14, Urban100, BSD100, and Manga109. Code will be published after accepted.
Real-World Denoising via Diffusion Model
May 08, 2023
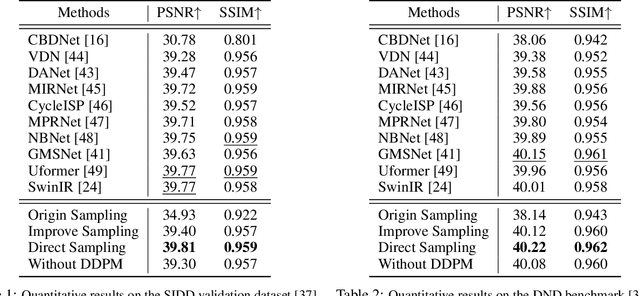


Real-world image denoising is an extremely important image processing problem, which aims to recover clean images from noisy images captured in natural environments. In recent years, diffusion models have achieved very promising results in the field of image generation, outperforming previous generation models. However, it has not been widely used in the field of image denoising because it is difficult to control the appropriate position of the added noise. Inspired by diffusion models, this paper proposes a novel general denoising diffusion model that can be used for real-world image denoising. We introduce a diffusion process with linear interpolation, and the intermediate noisy image is interpolated from the original clean image and the corresponding real-world noisy image, so that this diffusion model can handle the level of added noise. In particular, we also introduce two sampling algorithms for this diffusion model. The first one is a simple sampling procedure defined according to the diffusion process, and the second one targets the problem of the first one and makes a number of improvements. Our experimental results show that our proposed method with a simple CNNs Unet achieves comparable results compared to the Transformer architecture. Both quantitative and qualitative evaluations on real-world denoising benchmarks show that the proposed general diffusion model performs almost as well as against the state-of-the-art methods.
Modulating Pretrained Diffusion Models for Multimodal Image Synthesis
Feb 24, 2023
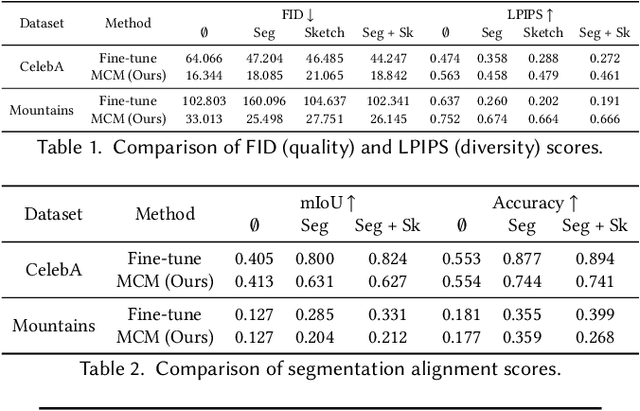
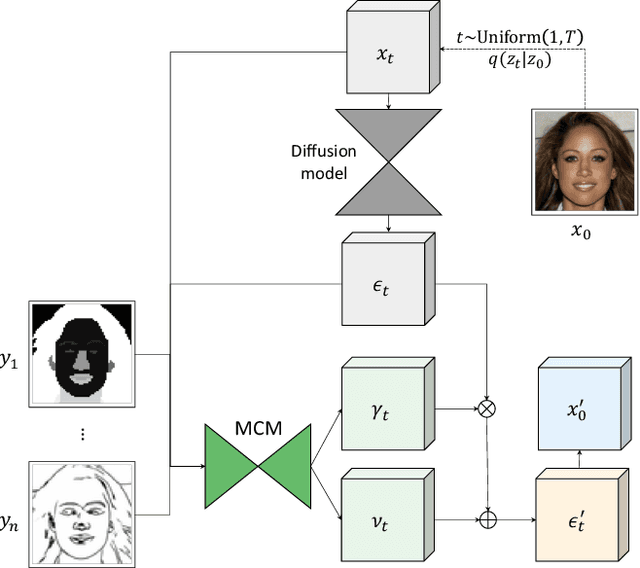
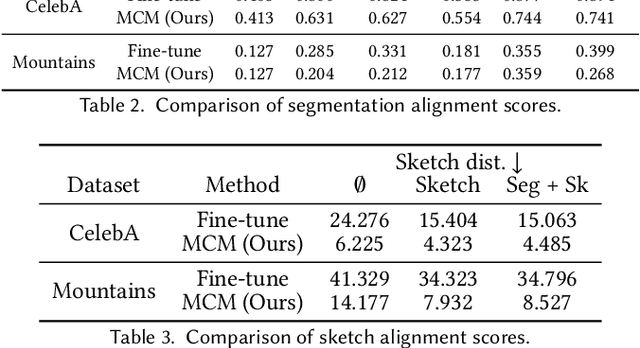
We present multimodal conditioning modules (MCM) for enabling conditional image synthesis using pretrained diffusion models. Previous multimodal synthesis works rely on training networks from scratch or fine-tuning pretrained networks, both of which are computationally expensive for large, state-of-the-art diffusion models. Our method uses pretrained networks but does not require any updates to the diffusion network's parameters. MCM is a small module trained to modulate the diffusion network's predictions during sampling using 2D modalities (e.g., semantic segmentation maps, sketches) that were unseen during the original training of the diffusion model. We show that MCM enables user control over the spatial layout of the image and leads to increased control over the image generation process. Training MCM is cheap as it does not require gradients from the original diffusion net, consists of only $\sim$1$\%$ of the number of parameters of the base diffusion model, and is trained using only a limited number of training examples. We evaluate our method on unconditional and text-conditional models to demonstrate the improved control over the generated images and their alignment with respect to the conditioning inputs.
Inspecting the Geographical Representativeness of Images from Text-to-Image Models
May 18, 2023
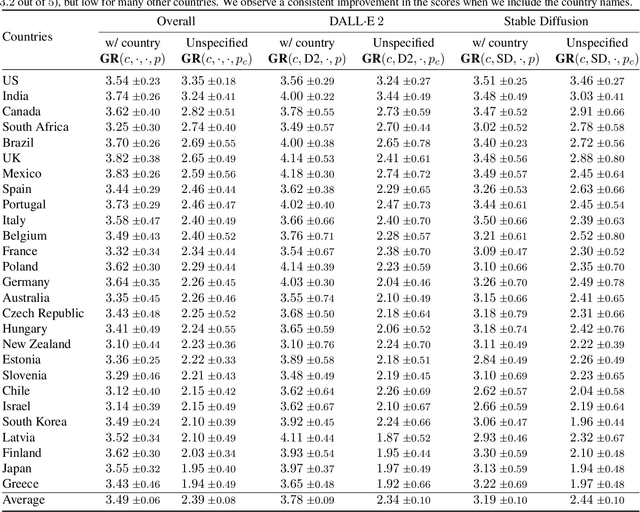
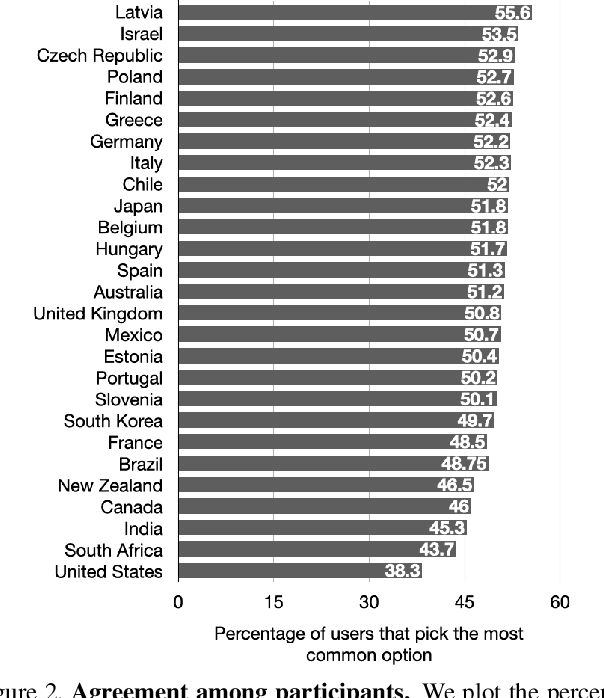
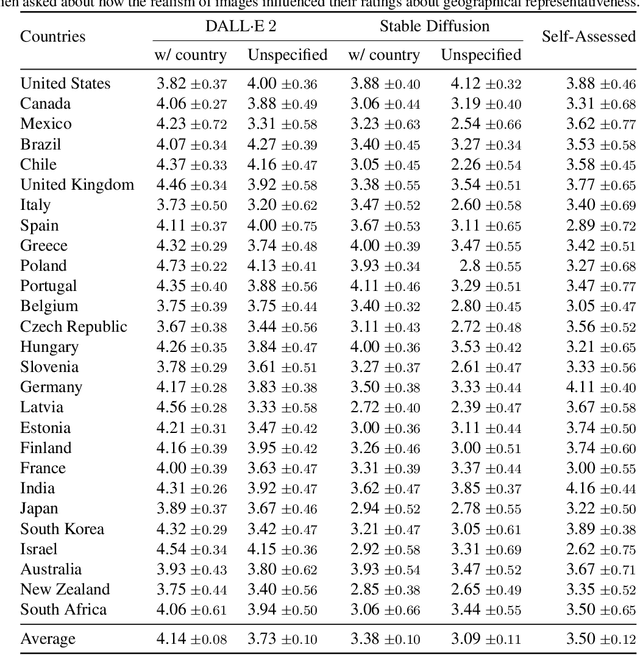
Recent progress in generative models has resulted in models that produce both realistic as well as relevant images for most textual inputs. These models are being used to generate millions of images everyday, and hold the potential to drastically impact areas such as generative art, digital marketing and data augmentation. Given their outsized impact, it is important to ensure that the generated content reflects the artifacts and surroundings across the globe, rather than over-representing certain parts of the world. In this paper, we measure the geographical representativeness of common nouns (e.g., a house) generated through DALL.E 2 and Stable Diffusion models using a crowdsourced study comprising 540 participants across 27 countries. For deliberately underspecified inputs without country names, the generated images most reflect the surroundings of the United States followed by India, and the top generations rarely reflect surroundings from all other countries (average score less than 3 out of 5). Specifying the country names in the input increases the representativeness by 1.44 points on average for DALL.E 2 and 0.75 for Stable Diffusion, however, the overall scores for many countries still remain low, highlighting the need for future models to be more geographically inclusive. Lastly, we examine the feasibility of quantifying the geographical representativeness of generated images without conducting user studies.