 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Scene Chronology
Jun 13, 2023
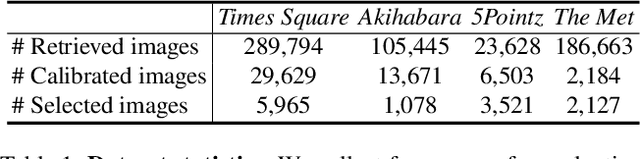
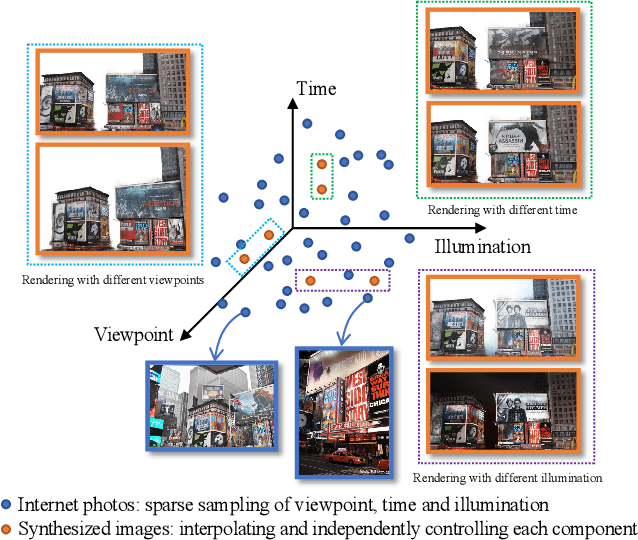
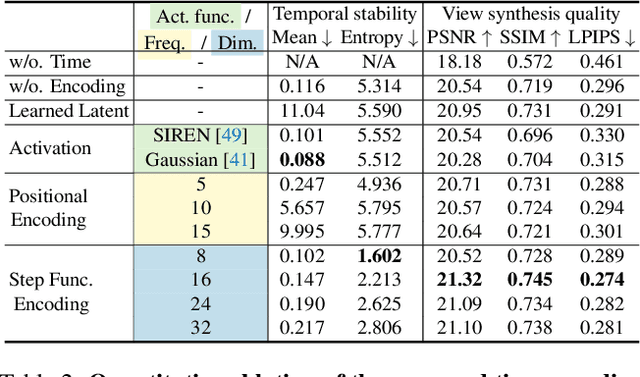
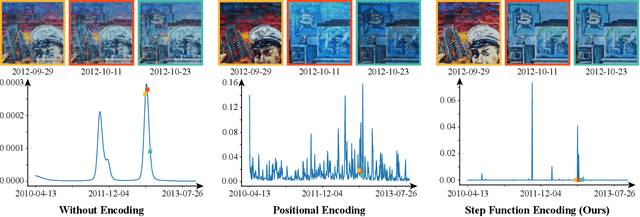
In this work, we aim to reconstruct a time-varying 3D model, capable of rendering photo-realistic renderings with independent control of viewpoint, illumination, and time, from Internet photos of large-scale landmarks. The core challenges are twofold. First, different types of temporal changes, such as illumination and changes to the underlying scene itself (such as replacing one graffiti artwork with another) are entangled together in the imagery. Second, scene-level temporal changes are often discrete and sporadic over time, rather than continuous. To tackle these problems, we propose a new scene representation equipped with a novel temporal step function encoding method that can model discrete scene-level content changes as piece-wise constant functions over time. Specifically, we represent the scene as a space-time radiance field with a per-image illumination embedding, where temporally-varying scene changes are encoded using a set of learned step functions. To facilitate our task of chronology reconstruction from Internet imagery, we also collect a new dataset of four scenes that exhibit various changes over time. We demonstrate that our method exhibits state-of-the-art view synthesis results on this dataset, while achieving independent control of viewpoint, time, and illumination.
A Zero-/Few-Shot Anomaly Classification and Segmentation Method for CVPR 2023 VAND Workshop Challenge Tracks 1&2: 1st Place on Zero-shot AD and 4th Place on Few-shot AD
Jun 13, 2023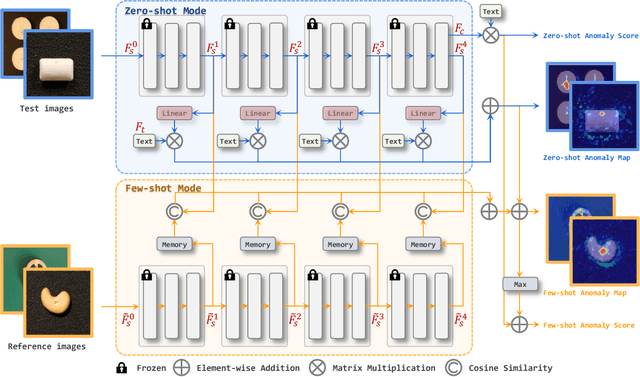
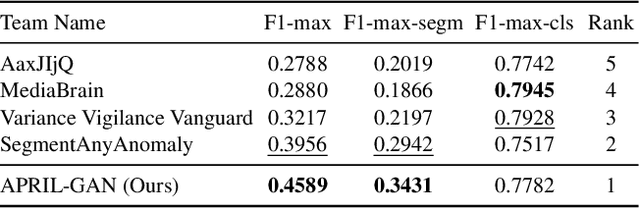

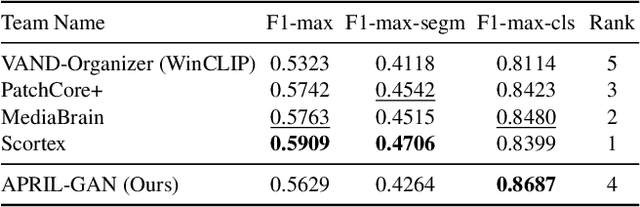
In this technical report, we briefly introduce our solution for the Zero/Few-shot Track of the Visual Anomaly and Novelty Detection (VAND) 2023 Challenge. For industrial visual inspection, building a single model that can be rapidly adapted to numerous categories without or with only a few normal reference images is a promising research direction. This is primarily because of the vast variety of the product types. For the zero-shot track, we propose a solution based on the CLIP model by adding extra linear layers. These layers are used to map the image features to the joint embedding space, so that they can compare with the text features to generate the anomaly maps. Besides, when the reference images are available, we utilize multiple memory banks to store their features and compare them with the features of the test images during the testing phase. In this challenge, our method achieved first place in the zero-shot track, especially excelling in segmentation with an impressive F1 score improvement of 0.0489 over the second-ranked participant. Furthermore, in the few-shot track, we secured the fourth position overall, with our classification F1 score of 0.8687 ranking first among all participating teams.
Retrieve Anyone: A General-purpose Person Re-identification Task with Instructions
Jun 13, 2023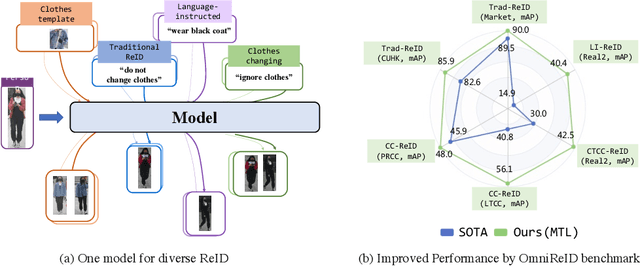
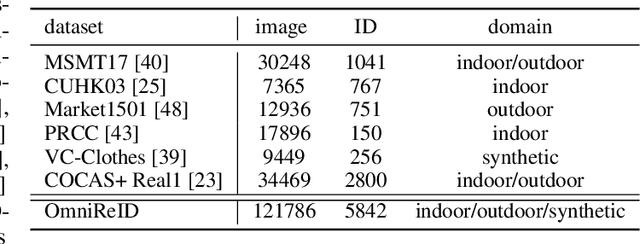
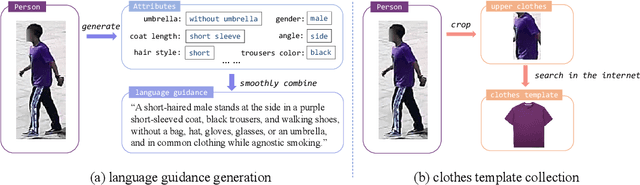
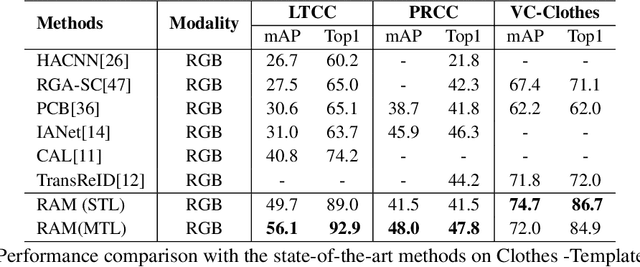
Human intelligence can retrieve any person according to both visual and language descriptions. However, the current computer vision community studies specific person re-identification (ReID) tasks in different scenarios separately, which limits the applications in the real world. This paper strives to resolve this problem by proposing a new instruct-ReID task that requires the model to retrieve images according to the given image or language instructions.Our instruct-ReID is a more general ReID setting, where existing ReID tasks can be viewed as special cases by designing different instructions. We propose a large-scale OmniReID benchmark and an adaptive triplet loss as a baseline method to facilitate research in this new setting. Experimental results show that the baseline model trained on our OmniReID benchmark can improve +0.5%, +3.3% mAP on Market1501 and CUHK03 for traditional ReID, +2.1%, +0.2%, +15.3% mAP on PRCC, VC-Clothes, LTCC for clothes-changing ReID, +12.5% mAP on COCAS+ real2 for clothestemplate based clothes-changing ReID when using only RGB images, +25.5% mAP on COCAS+ real2 for our newly defined language-instructed ReID. The dataset, model, and code will be available at https://github.com/hwz-zju/Instruct-ReID.
JCCS-PFGM: A Novel Circle-Supervision based Poisson Flow Generative Model for Multiphase CECT Progressive Low-Dose Reconstruction with Joint Condition
Jun 13, 2023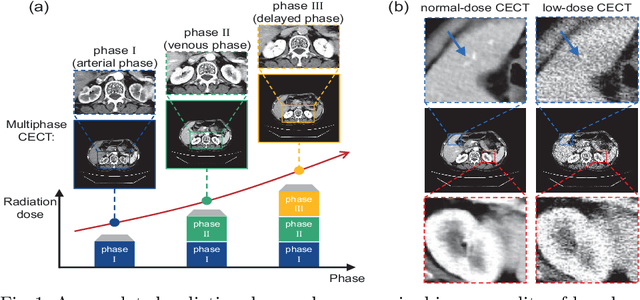

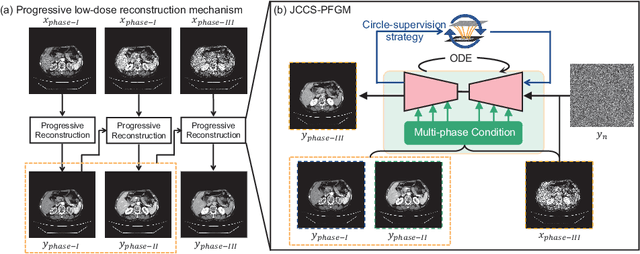
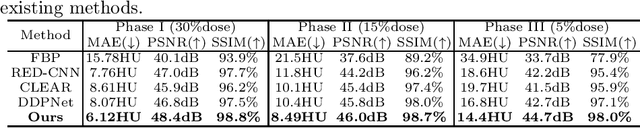
Multiphase contrast-enhanced computed tomography (CECT) scan is clinically significant to demonstrate the anatomy at different phases. In practice, such a multiphase CECT scan inherently takes longer time and deposits much more radiation dose into a patient body than a regular CT scan, and reduction of the radiation dose typically compromise the CECT image quality and its diagnostic value. With Joint Condition and Circle-Supervision, here we propose a novel Poisson Flow Generative Model (JCCS-PFGM) to promote the progressive low-dose reconstruction for multiphase CECT. JCCS-PFGM is characterized by the following three aspects: a progressive low-dose reconstruction scheme, a circle-supervision strategy, and a joint condition mechanism. Our extensive experiments are performed on a clinical dataset consisting of 11436 images. The results show that our JCCS-PFGM achieves promising PSNR up to 46.3dB, SSIM up to 98.5%, and MAE down to 9.67 HU averagely on phases I, II and III, in quantitative evaluations, as well as gains high-quality readable visualizations in qualitative assessments. All of these findings reveal our method a great potential to be adapted for clinical CECT scans at a much-reduced radiation dose.
RealFusion: 360° Reconstruction of Any Object from a Single Image
Feb 21, 2023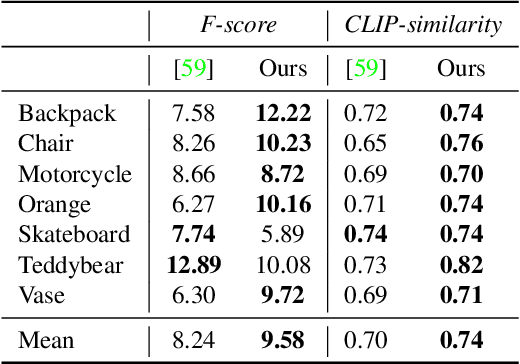
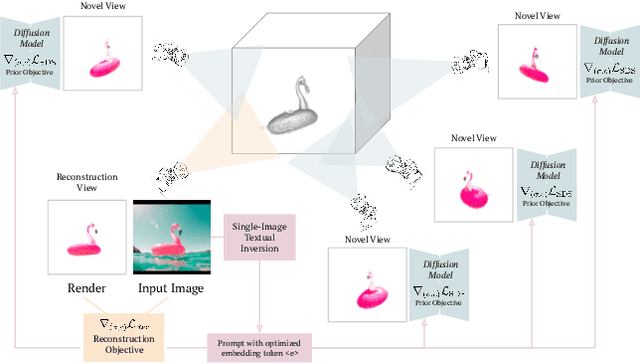


We consider the problem of reconstructing a full 360{\deg} photographic model of an object from a single image of it. We do so by fitting a neural radiance field to the image, but find this problem to be severely ill-posed. We thus take an off-the-self conditional image generator based on diffusion and engineer a prompt that encourages it to ``dream up'' novel views of the object. Using an approach inspired by DreamFields and DreamFusion, we fuse the given input view, the conditional prior, and other regularizers in a final, consistent reconstruction. We demonstrate state-of-the-art reconstruction results on benchmark images when compared to prior methods for monocular 3D reconstruction of objects. Qualitatively, our reconstructions provide a faithful match of the input view and a plausible extrapolation of its appearance and 3D shape, including to the side of the object not visible in the image.
Sim-to-Real Segmentation in Robot-assisted Transoral Tracheal Intubation
May 19, 2023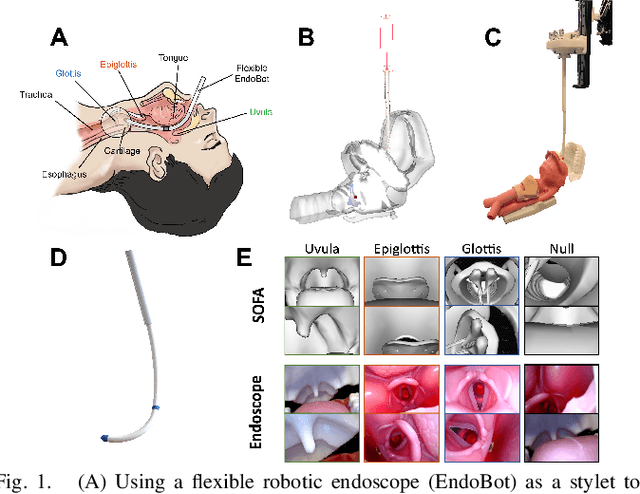
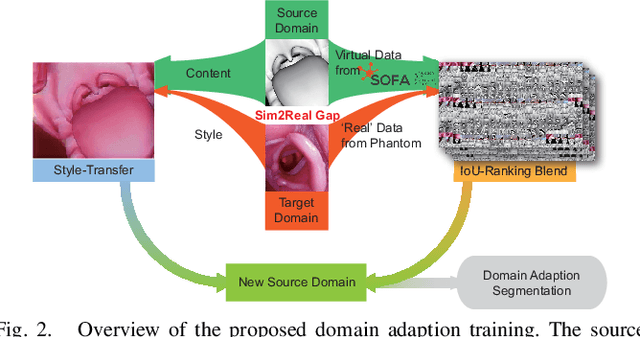
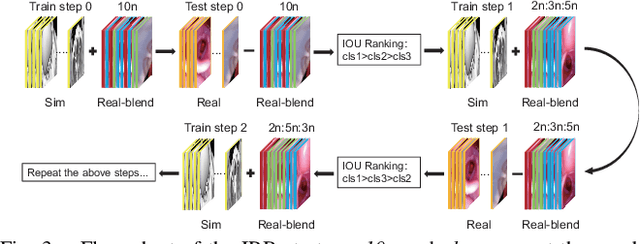
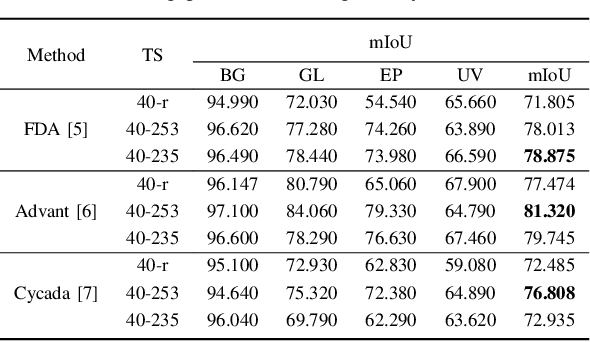
Robotic-assisted tracheal intubation requires the robot to distinguish anatomical features like an experienced physician using deep-learning techniques. However, real datasets of oropharyngeal organs are limited due to patient privacy issues, making it challenging to train deep-learning models for accurate image segmentation. We hereby consider generating a new data modality through a virtual environment to assist the training process. Specifically, this work introduces a virtual dataset generated by the Simulation Open Framework Architecture (SOFA) framework to overcome the limited availability of actual endoscopic images. We also propose a domain adaptive Sim-to-Real method for oropharyngeal organ image segmentation, which employs an image blending strategy called IoU-Ranking Blend (IRB) and style-transfer techniques to address discrepancies between datasets. Experimental results demonstrate the superior performance of the proposed approach with domain adaptive models, improving segmentation accuracy and training stability. In the practical application, the trained segmentation model holds great promise for robot-assisted intubation surgery and intelligent surgical navigation.
Efficient Cross-Lingual Transfer for Chinese Stable Diffusion with Images as Pivots
May 19, 2023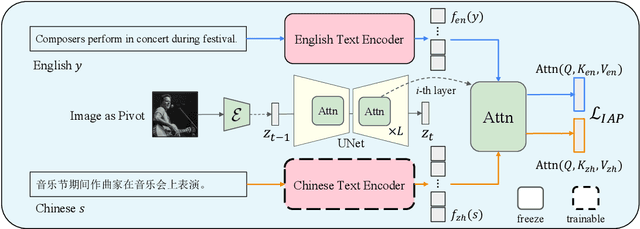
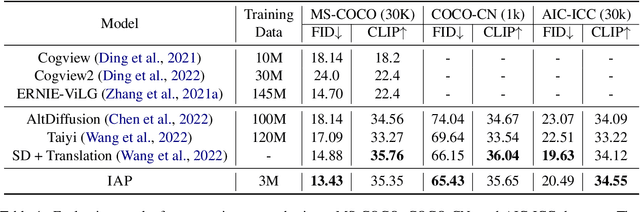

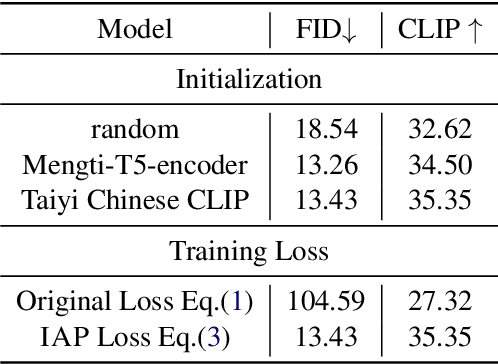
Diffusion models have made impressive progress in text-to-image synthesis. However, training such large-scale models (e.g. Stable Diffusion), from scratch requires high computational costs and massive high-quality text-image pairs, which becomes unaffordable in other languages. To handle this challenge, we propose IAP, a simple but effective method to transfer English Stable Diffusion into Chinese. IAP optimizes only a separate Chinese text encoder with all other parameters fixed to align Chinese semantics space to the English one in CLIP. To achieve this, we innovatively treat images as pivots and minimize the distance of attentive features produced from cross-attention between images and each language respectively. In this way, IAP establishes connections of Chinese, English and visual semantics in CLIP's embedding space efficiently, advancing the quality of the generated image with direct Chinese prompts. Experimental results show that our method outperforms several strong Chinese diffusion models with only 5%~10% training data.
Robust Lane Detection through Self Pre-training with Masked Sequential Autoencoders and Fine-tuning with Customized PolyLoss
May 26, 2023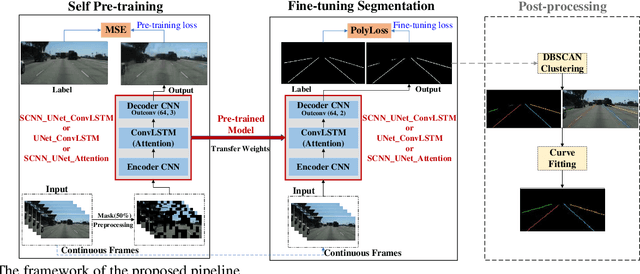
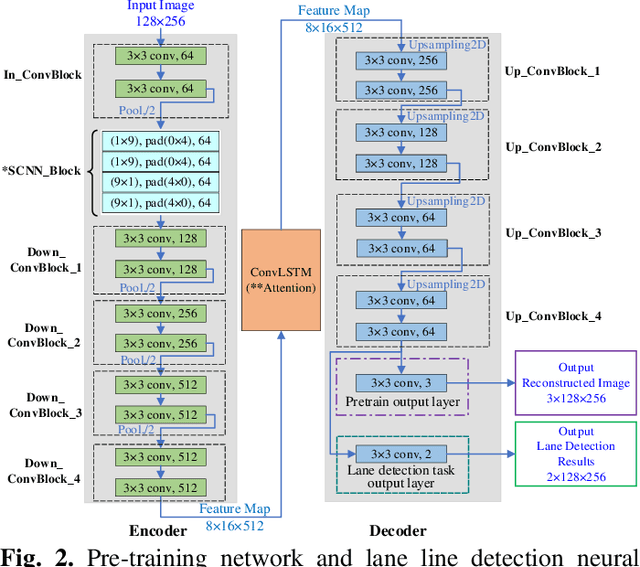
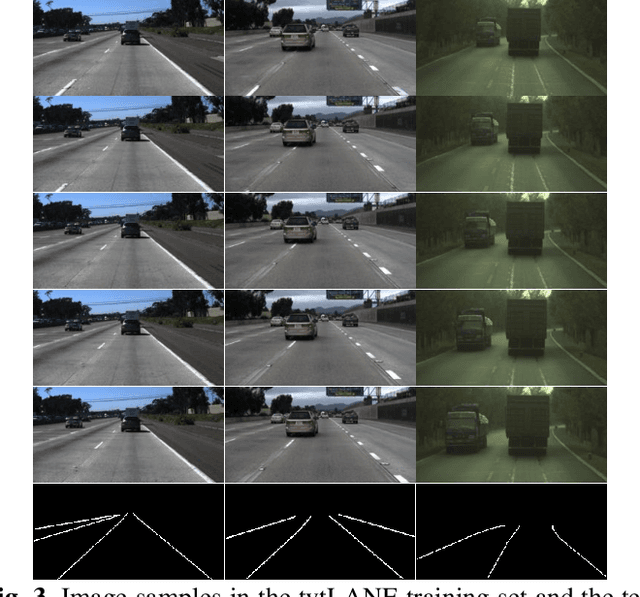

Lane detection is crucial for vehicle localization which makes it the foundation for automated driving and many intelligent and advanced driving assistant systems. Available vision-based lane detection methods do not make full use of the valuable features and aggregate contextual information, especially the interrelationships between lane lines and other regions of the images in continuous frames. To fill this research gap and upgrade lane detection performance, this paper proposes a pipeline consisting of self pre-training with masked sequential autoencoders and fine-tuning with customized PolyLoss for the end-to-end neural network models using multi-continuous image frames. The masked sequential autoencoders are adopted to pre-train the neural network models with reconstructing the missing pixels from a random masked image as the objective. Then, in the fine-tuning segmentation phase where lane detection segmentation is performed, the continuous image frames are served as the inputs, and the pre-trained model weights are transferred and further updated using the backpropagation mechanism with customized PolyLoss calculating the weighted errors between the output lane detection results and the labeled ground truth. Extensive experiment results demonstrate that, with the proposed pipeline, the lane detection model performance on both normal and challenging scenes can be advanced beyond the state-of-the-art, delivering the best testing accuracy (98.38%), precision (0.937), and F1-measure (0.924) on the normal scene testing set, together with the best overall accuracy (98.36%) and precision (0.844) in the challenging scene test set, while the training time can be substantially shortened.
Too Large; Data Reduction for Vision-Language Pre-Training
Jun 01, 2023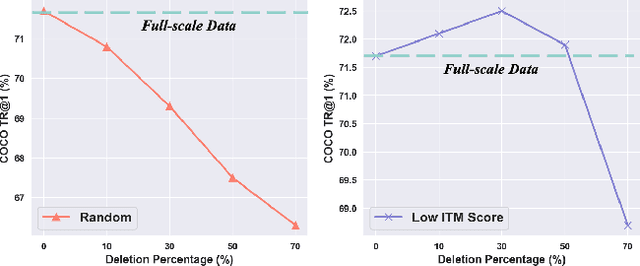

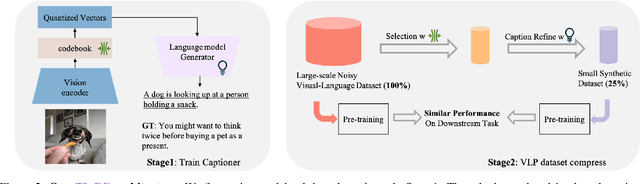
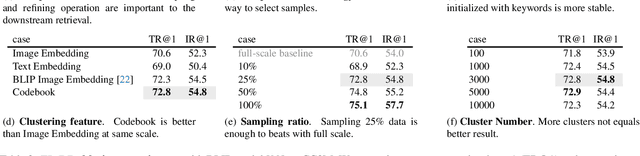
This paper examines the problems of severe image-text misalignment and high redundancy in the widely-used large-scale Vision-Language Pre-Training (VLP) datasets. To address these issues, we propose an efficient and straightforward Vision-Language learning algorithm called TL;DR, which aims to compress the existing large VLP data into a small, high-quality set. Our approach consists of two major steps. First, a codebook-based encoder-decoder captioner is developed to select representative samples. Second, a new caption is generated to complement the original captions for selected samples, mitigating the text-image misalignment problem while maintaining uniqueness. As the result, TL;DR enables us to reduce the large dataset into a small set of high-quality data, which can serve as an alternative pre-training dataset. This algorithm significantly speeds up the time-consuming pretraining process. Specifically, TL;DR can compress the mainstream VLP datasets at a high ratio, e.g., reduce well-cleaned CC3M dataset from 2.82M to 0.67M ($\sim$24\%) and noisy YFCC15M from 15M to 2.5M ($\sim$16.7\%). Extensive experiments with three popular VLP models over seven downstream tasks show that VLP model trained on the compressed dataset provided by TL;DR can perform similar or even better results compared with training on the full-scale dataset. The code will be made available at \url{https://github.com/showlab/data-centric.vlp}.
Microstructure quality control of steels using deep learning
Jun 01, 2023
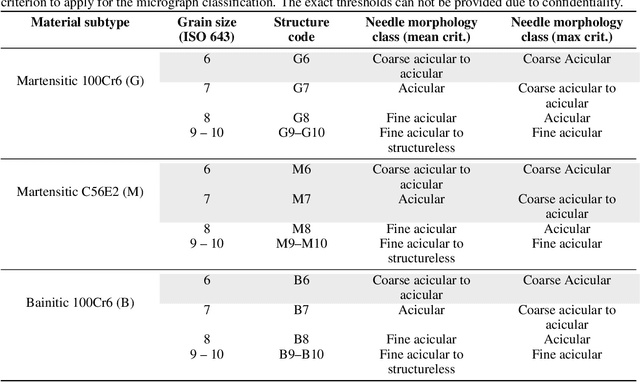

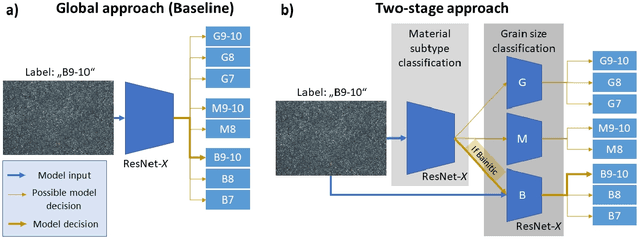
In quality control, microstructures are investigated rigorously to ensure structural integrity, exclude the presence of critical volume defects, and validate the formation of the target microstructure. For quenched, hierarchically-structured steels, the morphology of the bainitic and martensitic microstructures are of major concern to guarantee the reliability of the material under service conditions. Therefore, industries conduct small sample-size inspections of materials cross-sections through metallographers to validate the needle morphology of such microstructures. We demonstrate round-robin test results revealing that this visual grading is afflicted by pronounced subjectivity despite the thorough training of personnel. Instead, we propose a deep learning image classification approach that distinguishes steels based on their microstructure type and classifies their needle length alluding to the ISO 643 grain size assessment standard. This classification approach facilitates the reliable, objective, and automated classification of hierarchically structured steels. Specifically, an accuracy of 96% and roughly 91% is attained for the distinction of martensite/bainite subtypes and needle length, respectively. This is achieved on an image dataset that contains significant variance and labeling noise as it is acquired over more than ten years from multiple plants, alloys, etchant applications, and light optical microscopes by many metallographers (raters). Interpretability analysis gives insights into the decision-making of these models and allows for estimating their generalization capability.