 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Unsupervised StyleGAN Image Restoration
Feb 13, 2023

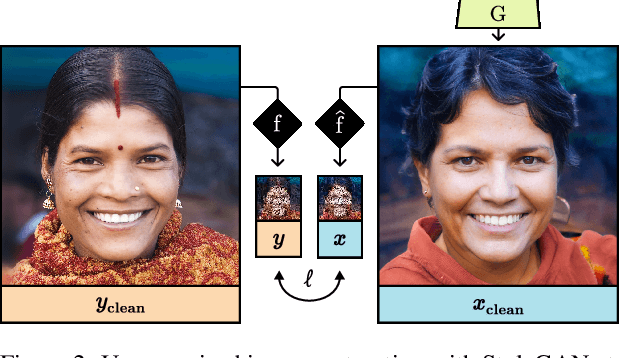
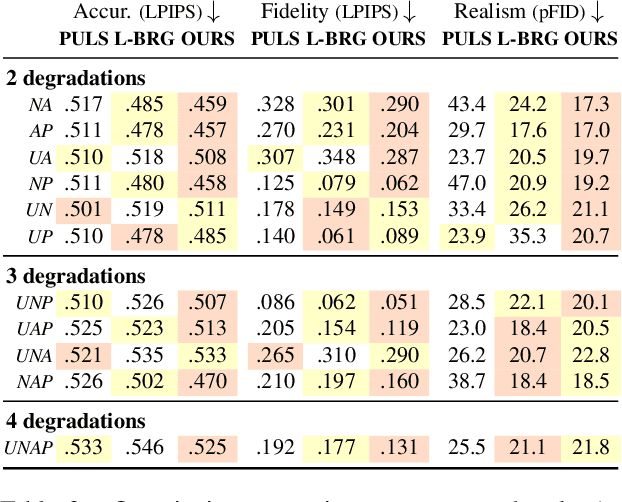
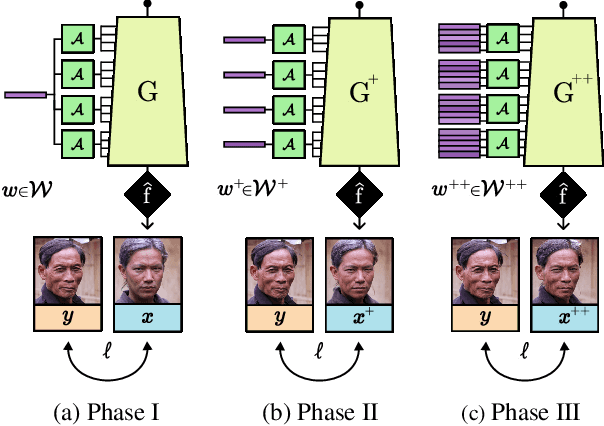
GAN-based image restoration inverts the generative process to repair images corrupted by known degradations. Existing unsupervised methods must be carefully tuned for each task and degradation level. In this work, we make StyleGAN image restoration robust: a single set of hyperparameters works across a wide range of degradation levels. This makes it possible to handle combinations of several degradations, without the need to retune. Our proposed approach relies on a 3-phase progressive latent space extension and a conservative optimizer, which avoids the need for any additional regularization terms. Extensive experiments demonstrate robustness on inpainting, upsampling, denoising, and deartifacting at varying degradations levels, outperforming other StyleGAN-based inversion techniques. Our approach also favorably compares to diffusion-based restoration by yielding much more realistic inversion results. Code will be released upon publication.
A One-Class Classifier for the Detection of GAN Manipulated Multi-Spectral Satellite Images
May 19, 2023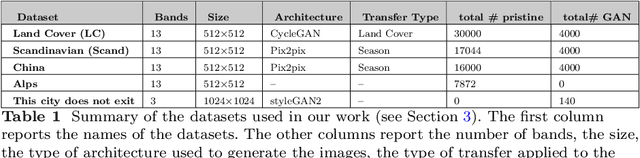



The highly realistic image quality achieved by current image generative models has many academic and industrial applications. To limit the use of such models to benign applications, though, it is necessary that tools to conclusively detect whether an image has been generated synthetically or not are developed. For this reason, several detectors have been developed providing excellent performance in computer vision applications, however, they can not be applied as they are to multispectral satellite images, and hence new models must be trained. In general, two-class classifiers can achieve very good detection accuracies, however they are not able to generalise to image domains and generative models architectures different than those used during training. For this reason, in this paper, we propose a one-class classifier based on Vector Quantized Variational Autoencoder 2 (VQ-VAE 2) features to overcome the limitations of two-class classifiers. First, we emphasize the generalization problem that binary classifiers suffer from by training and testing an EfficientNet-B4 architecture on multiple multispectral datasets. Then we show that, since the VQ-VAE 2 based classifier is trained only on pristine images, it is able to detect images belonging to different domains and generated by architectures that have not been used during training. Last, we compare the two classifiers head-to-head on the same generated datasets, highlighting the superiori generalization capabilities of the VQ-VAE 2-based detector.
Semantic Prompt for Few-Shot Image Recognition
Mar 24, 2023
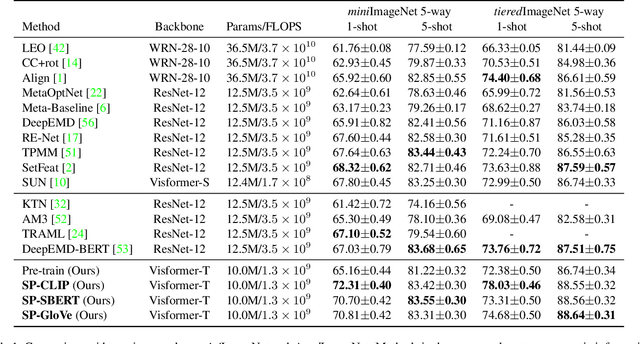
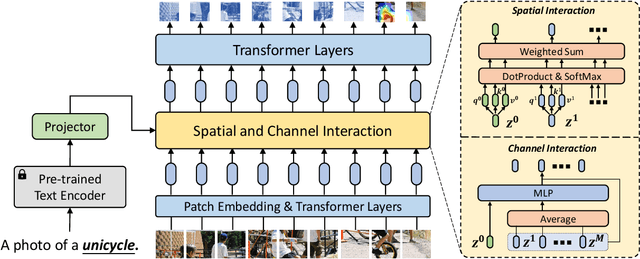
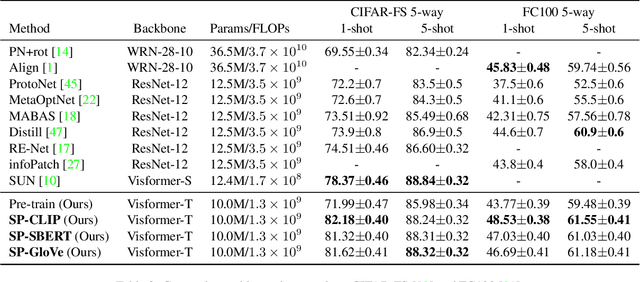
Few-shot learning is a challenging problem since only a few examples are provided to recognize a new class. Several recent studies exploit additional semantic information, e.g. text embeddings of class names, to address the issue of rare samples through combining semantic prototypes with visual prototypes. However, these methods still suffer from the spurious visual features learned from the rare support samples, resulting in limited benefits. In this paper, we propose a novel Semantic Prompt (SP) approach for few-shot learning. Instead of the naive exploitation of semantic information for remedying classifiers, we explore leveraging semantic information as prompts to tune the visual feature extraction network adaptively. Specifically, we design two complementary mechanisms to insert semantic prompts into the feature extractor: one is to enable the interaction between semantic prompts and patch embeddings along the spatial dimension via self-attention, another is to supplement visual features with the transformed semantic prompts along the channel dimension. By combining these two mechanisms, the feature extractor presents a better ability to attend to the class-specific features and obtains more generalized image representations with merely a few support samples. Through extensive experiments on four datasets, the proposed approach achieves promising results, improving the 1-shot learning accuracy by 3.67% on average.
Rate-Distortion Theory in Coding for Machines and its Application
May 26, 2023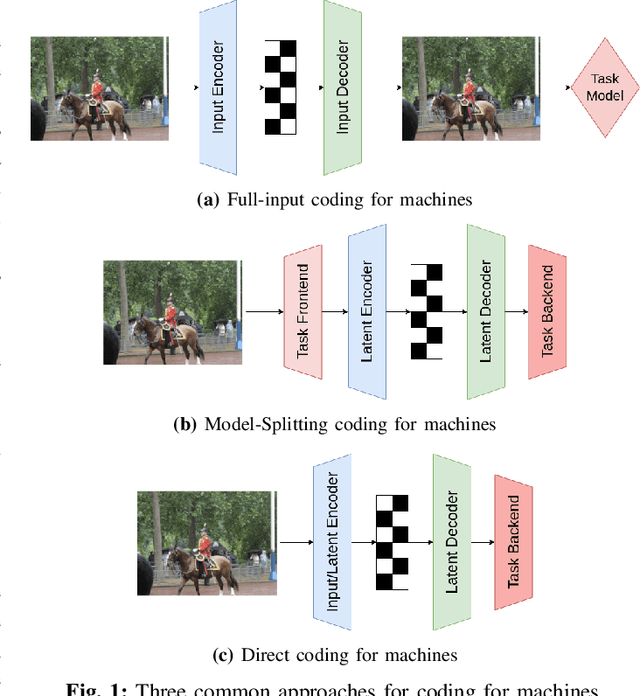
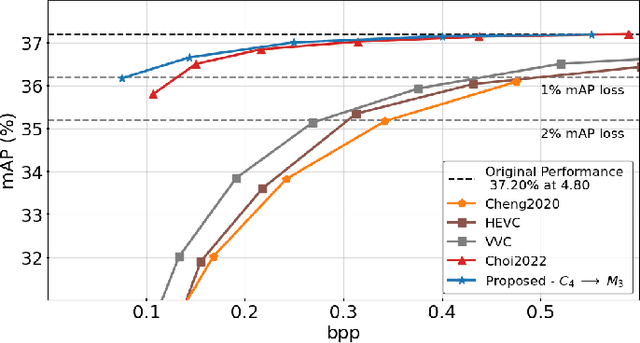
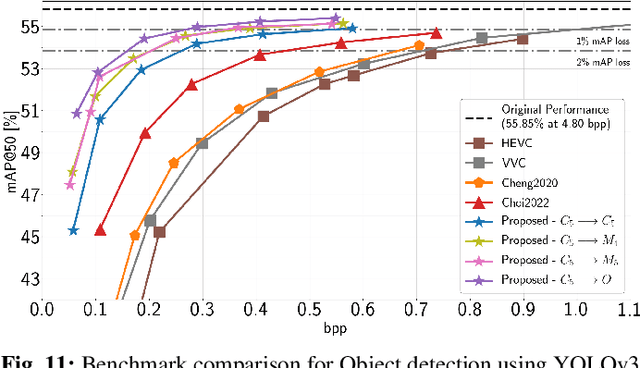
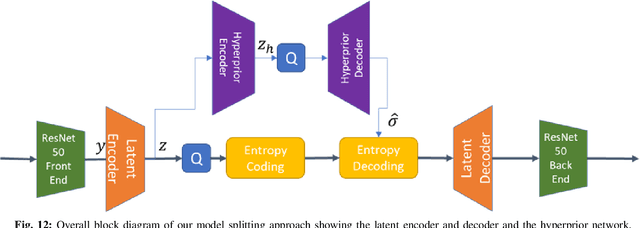
Recent years have seen a tremendous growth in both the capability and popularity of automatic machine analysis of images and video. As a result, a growing need for efficient compression methods optimized for machine vision, rather than human vision, has emerged. To meet this growing demand, several methods have been developed for image and video coding for machines. Unfortunately, while there is a substantial body of knowledge regarding rate-distortion theory for human vision, the same cannot be said of machine analysis. In this paper, we extend the current rate-distortion theory for machines, providing insight into important design considerations of machine-vision codecs. We then utilize this newfound understanding to improve several methods for learnable image coding for machines. Our proposed methods achieve state-of-the-art rate-distortion performance on several computer vision tasks such as classification, instance segmentation, and object detection.
Real-time myocardial landmark tracking for MRI-guided cardiac radio-ablation using Gaussian Processes
Jun 19, 2023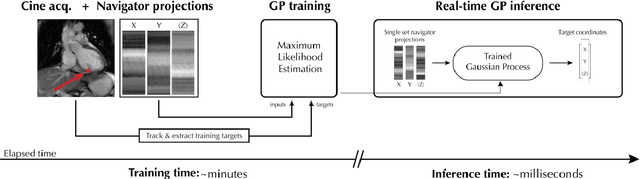

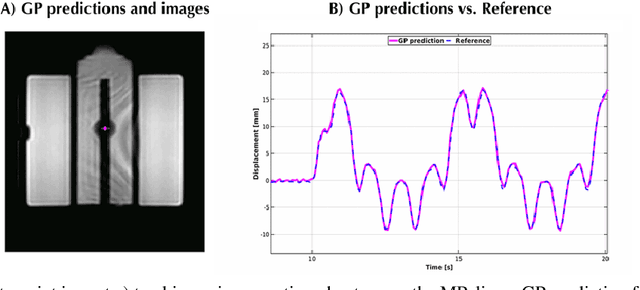
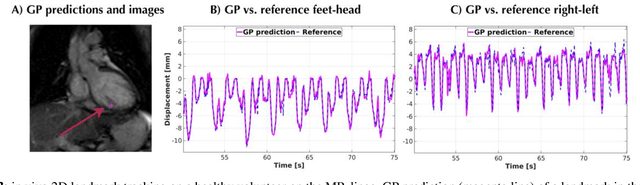
The high speed of cardiorespiratory motion introduces a unique challenge for cardiac stereotactic radio-ablation (STAR) treatments with the MR-linac. Such treatments require tracking myocardial landmarks with a maximum latency of 100 ms, which includes the acquisition of the required data. The aim of this study is to present a new method that allows to track myocardial landmarks from few readouts of MRI data, thereby achieving a latency sufficient for STAR treatments. We present a tracking framework that requires only few readouts of k-space data as input, which can be acquired at least an order of magnitude faster than MR-images. Combined with the real-time tracking speed of a probabilistic machine learning framework called Gaussian Processes, this allows to track myocardial landmarks with a sufficiently low latency for cardiac STAR guidance, including both the acquisition of required data, and the tracking inference. The framework is demonstrated in 2D on a motion phantom, and in vivo on volunteers and a ventricular tachycardia (arrhythmia) patient. Moreover, the feasibility of an extension to 3D was demonstrated by in silico 3D experiments with a digital motion phantom. The framework was compared with template matching - a reference, image-based, method - and linear regression methods. Results indicate an order of magnitude lower total latency (<10 ms) for the proposed framework in comparison with alternative methods. The root-mean-square-distances and mean end-point-distance with the reference tracking method was less than 0.8 mm for all experiments, showing excellent (sub-voxel) agreement. The high accuracy in combination with a total latency of less than 10 ms - including data acquisition and processing - make the proposed method a suitable candidate for tracking during STAR treatments.
Too Large; Data Reduction for Vision-Language Pre-Training
Jun 01, 2023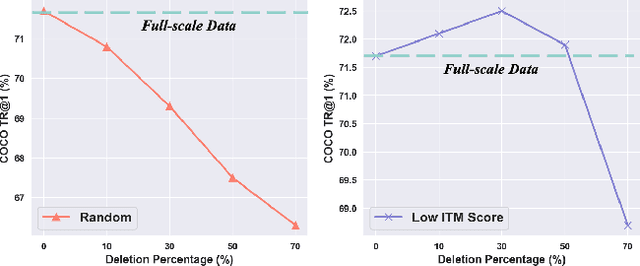

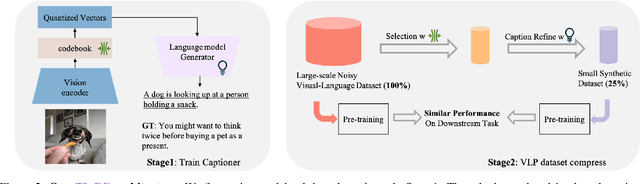
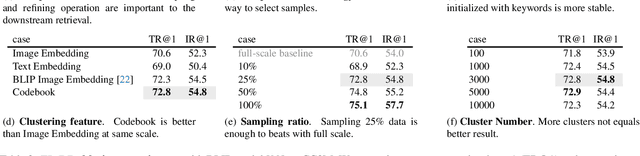
This paper examines the problems of severe image-text misalignment and high redundancy in the widely-used large-scale Vision-Language Pre-Training (VLP) datasets. To address these issues, we propose an efficient and straightforward Vision-Language learning algorithm called TL;DR, which aims to compress the existing large VLP data into a small, high-quality set. Our approach consists of two major steps. First, a codebook-based encoder-decoder captioner is developed to select representative samples. Second, a new caption is generated to complement the original captions for selected samples, mitigating the text-image misalignment problem while maintaining uniqueness. As the result, TL;DR enables us to reduce the large dataset into a small set of high-quality data, which can serve as an alternative pre-training dataset. This algorithm significantly speeds up the time-consuming pretraining process. Specifically, TL;DR can compress the mainstream VLP datasets at a high ratio, e.g., reduce well-cleaned CC3M dataset from 2.82M to 0.67M ($\sim$24\%) and noisy YFCC15M from 15M to 2.5M ($\sim$16.7\%). Extensive experiments with three popular VLP models over seven downstream tasks show that VLP model trained on the compressed dataset provided by TL;DR can perform similar or even better results compared with training on the full-scale dataset. The code will be made available at \url{https://github.com/showlab/data-centric.vlp}.
Microstructure quality control of steels using deep learning
Jun 01, 2023
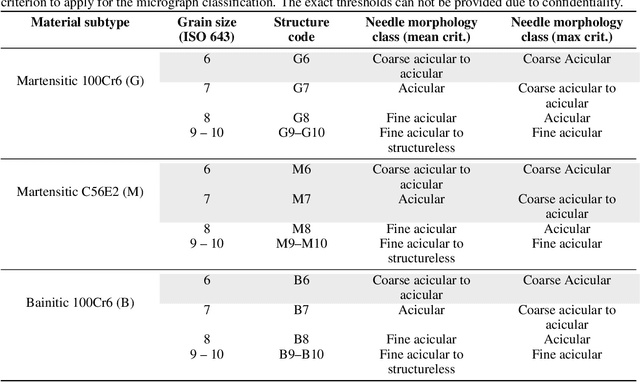

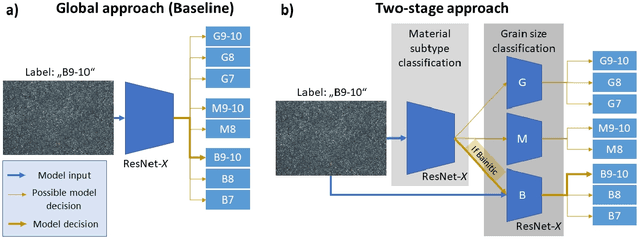
In quality control, microstructures are investigated rigorously to ensure structural integrity, exclude the presence of critical volume defects, and validate the formation of the target microstructure. For quenched, hierarchically-structured steels, the morphology of the bainitic and martensitic microstructures are of major concern to guarantee the reliability of the material under service conditions. Therefore, industries conduct small sample-size inspections of materials cross-sections through metallographers to validate the needle morphology of such microstructures. We demonstrate round-robin test results revealing that this visual grading is afflicted by pronounced subjectivity despite the thorough training of personnel. Instead, we propose a deep learning image classification approach that distinguishes steels based on their microstructure type and classifies their needle length alluding to the ISO 643 grain size assessment standard. This classification approach facilitates the reliable, objective, and automated classification of hierarchically structured steels. Specifically, an accuracy of 96% and roughly 91% is attained for the distinction of martensite/bainite subtypes and needle length, respectively. This is achieved on an image dataset that contains significant variance and labeling noise as it is acquired over more than ten years from multiple plants, alloys, etchant applications, and light optical microscopes by many metallographers (raters). Interpretability analysis gives insights into the decision-making of these models and allows for estimating their generalization capability.
Encoder-based Domain Tuning for Fast Personalization of Text-to-Image Models
Mar 05, 2023
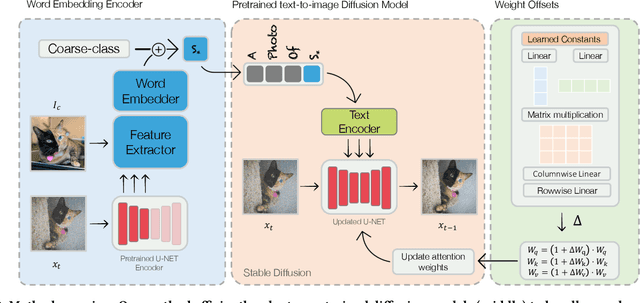

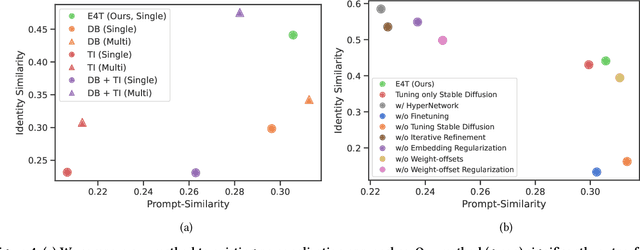
Text-to-image personalization aims to teach a pre-trained diffusion model to reason about novel, user provided concepts, embedding them into new scenes guided by natural language prompts. However, current personalization approaches struggle with lengthy training times, high storage requirements or loss of identity. To overcome these limitations, we propose an encoder-based domain-tuning approach. Our key insight is that by underfitting on a large set of concepts from a given domain, we can improve generalization and create a model that is more amenable to quickly adding novel concepts from the same domain. Specifically, we employ two components: First, an encoder that takes as an input a single image of a target concept from a given domain, e.g. a specific face, and learns to map it into a word-embedding representing the concept. Second, a set of regularized weight-offsets for the text-to-image model that learn how to effectively ingest additional concepts. Together, these components are used to guide the learning of unseen concepts, allowing us to personalize a model using only a single image and as few as 5 training steps - accelerating personalization from dozens of minutes to seconds, while preserving quality.
ArtFusion: Arbitrary Style Transfer using Dual Conditional Latent Diffusion Models
Jun 15, 2023
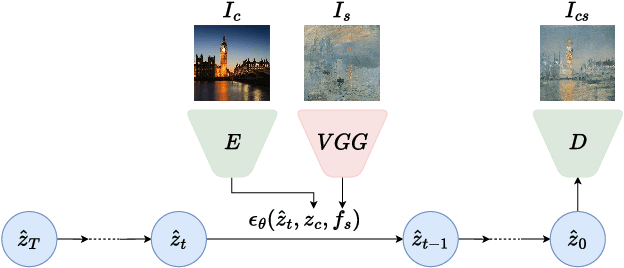

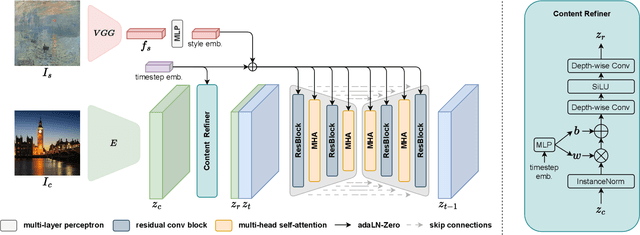
Arbitrary Style Transfer (AST) aims to transform images by adopting the style from any selected artwork. Nonetheless, the need to accommodate diverse and subjective user preferences poses a significant challenge. While some users wish to preserve distinct content structures, others might favor a more pronounced stylization. Despite advances in feed-forward AST methods, their limited customizability hinders their practical application. We propose a new approach, ArtFusion, which provides a flexible balance between content and style. In contrast to traditional methods reliant on biased similarity losses, ArtFusion utilizes our innovative Dual Conditional Latent Diffusion Probabilistic Models (Dual-cLDM). This approach mitigates repetitive patterns and enhances subtle artistic aspects like brush strokes and genre-specific features. Despite the promising results of conditional diffusion probabilistic models (cDM) in various generative tasks, their introduction to style transfer is challenging due to the requirement for paired training data. ArtFusion successfully navigates this issue, offering more practical and controllable stylization. A key element of our approach involves using a single image for both content and style during model training, all the while maintaining effective stylization during inference. ArtFusion outperforms existing approaches on outstanding controllability and faithful presentation of artistic details, providing evidence of its superior style transfer capabilities. Furthermore, the Dual-cLDM utilized in ArtFusion carries the potential for a variety of complex multi-condition generative tasks, thus greatly broadening the impact of our research.
Robust Lane Detection through Self Pre-training with Masked Sequential Autoencoders and Fine-tuning with Customized PolyLoss
May 26, 2023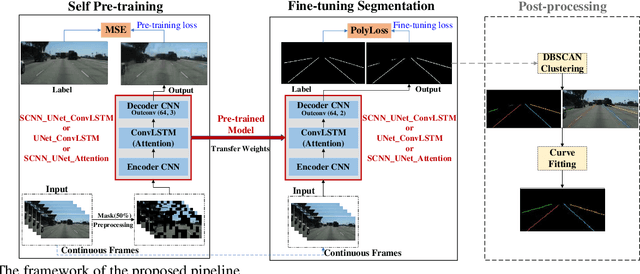
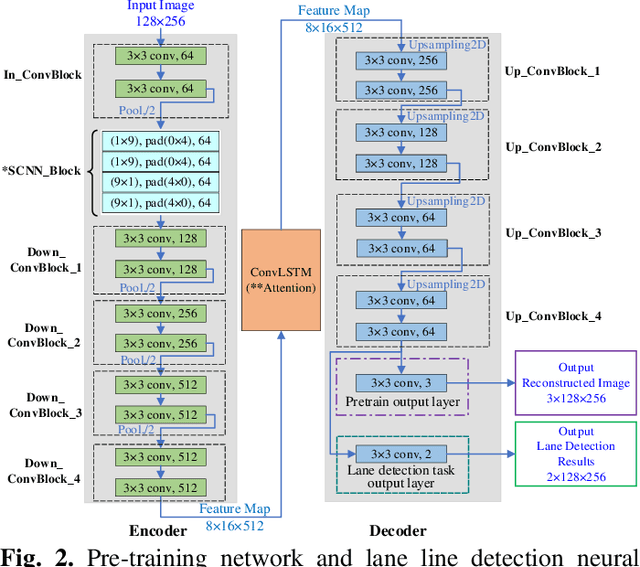

Lane detection is crucial for vehicle localization which makes it the foundation for automated driving and many intelligent and advanced driving assistant systems. Available vision-based lane detection methods do not make full use of the valuable features and aggregate contextual information, especially the interrelationships between lane lines and other regions of the images in continuous frames. To fill this research gap and upgrade lane detection performance, this paper proposes a pipeline consisting of self pre-training with masked sequential autoencoders and fine-tuning with customized PolyLoss for the end-to-end neural network models using multi-continuous image frames. The masked sequential autoencoders are adopted to pre-train the neural network models with reconstructing the missing pixels from a random masked image as the objective. Then, in the fine-tuning segmentation phase where lane detection segmentation is performed, the continuous image frames are served as the inputs, and the pre-trained model weights are transferred and further updated using the backpropagation mechanism with customized PolyLoss calculating the weighted errors between the output lane detection results and the labeled ground truth. Extensive experiment results demonstrate that, with the proposed pipeline, the lane detection model performance on both normal and challenging scenes can be advanced beyond the state-of-the-art, delivering the best testing accuracy (98.38%), precision (0.937), and F1-measure (0.924) on the normal scene testing set, together with the best overall accuracy (98.36%) and precision (0.844) in the challenging scene test set, while the training time can be substantially shortened.