 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Differentiable Display Photometric Stereo
Jun 23, 2023

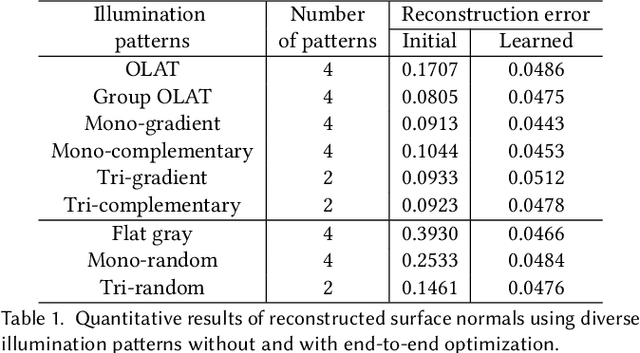

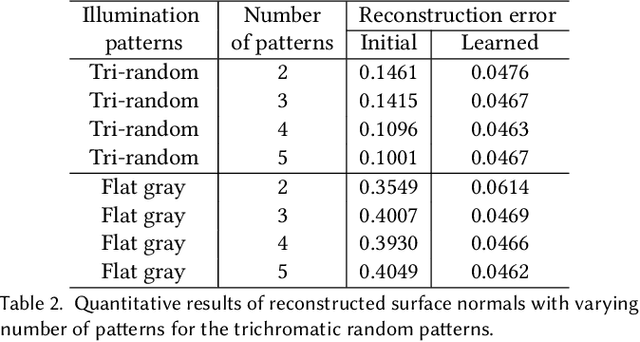
Photometric stereo leverages variations in illumination conditions to reconstruct per-pixel surface normals. The concept of display photometric stereo, which employs a conventional monitor as an illumination source, has the potential to overcome limitations often encountered in bulky and difficult-to-use conventional setups. In this paper, we introduce Differentiable Display Photometric Stereo (DDPS), a method designed to achieve high-fidelity normal reconstruction using an off-the-shelf monitor and camera. DDPS addresses a critical yet often neglected challenge in photometric stereo: the optimization of display patterns for enhanced normal reconstruction. We present a differentiable framework that couples basis-illumination image formation with a photometric-stereo reconstruction method. This facilitates the learning of display patterns that leads to high-quality normal reconstruction through automatic differentiation. Addressing the synthetic-real domain gap inherent in end-to-end optimization, we propose the use of a real-world photometric-stereo training dataset composed of 3D-printed objects. Moreover, to reduce the ill-posed nature of photometric stereo, we exploit the linearly polarized light emitted from the monitor to optically separate diffuse and specular reflections in the captured images. We demonstrate that DDPS allows for learning display patterns optimized for a target configuration and is robust to initialization. We assess DDPS on 3D-printed objects with ground-truth normals and diverse real-world objects, validating that DDPS enables effective photometric-stereo reconstruction.
A New Paradigm for Generative Adversarial Networks based on Randomized Decision Rules
Jun 23, 2023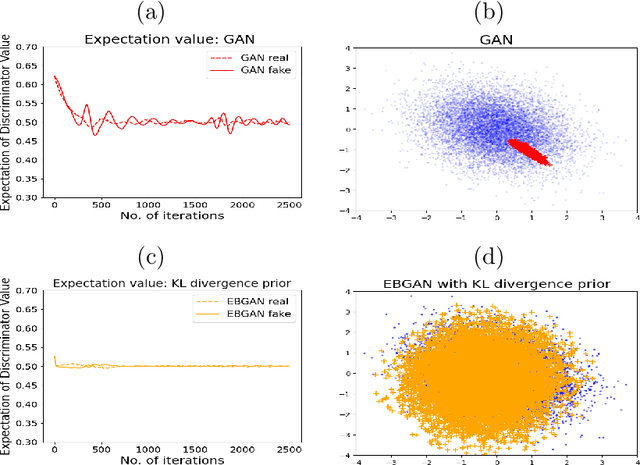

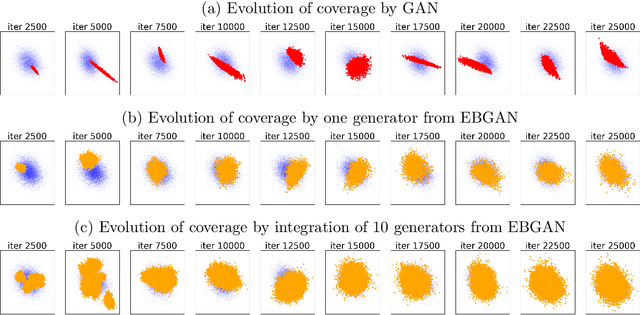
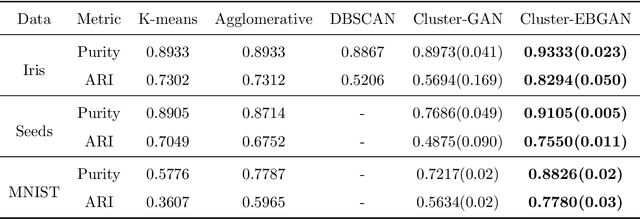
The Generative Adversarial Network (GAN) was recently introduced in the literature as a novel machine learning method for training generative models. It has many applications in statistics such as nonparametric clustering and nonparametric conditional independence tests. However, training the GAN is notoriously difficult due to the issue of mode collapse, which refers to the lack of diversity among generated data. In this paper, we identify the reasons why the GAN suffers from this issue, and to address it, we propose a new formulation for the GAN based on randomized decision rules. In the new formulation, the discriminator converges to a fixed point while the generator converges to a distribution at the Nash equilibrium. We propose to train the GAN by an empirical Bayes-like method by treating the discriminator as a hyper-parameter of the posterior distribution of the generator. Specifically, we simulate generators from its posterior distribution conditioned on the discriminator using a stochastic gradient Markov chain Monte Carlo (MCMC) algorithm, and update the discriminator using stochastic gradient descent along with simulations of the generators. We establish convergence of the proposed method to the Nash equilibrium. Apart from image generation, we apply the proposed method to nonparametric clustering and nonparametric conditional independence tests. A portion of the numerical results is presented in the supplementary material.
FPGA Implementation of Convolutional Neural Network for Real-Time Handwriting Recognition
Jun 26, 2023
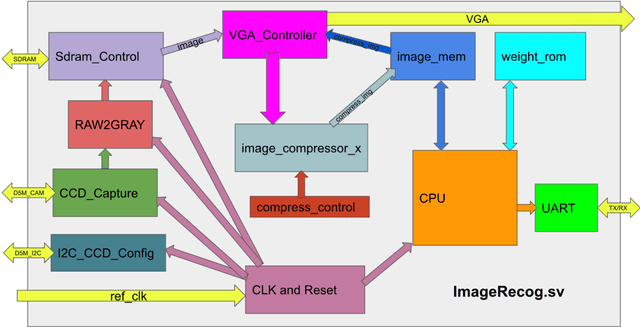
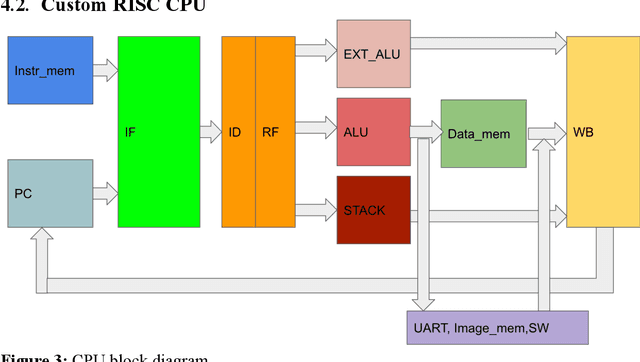
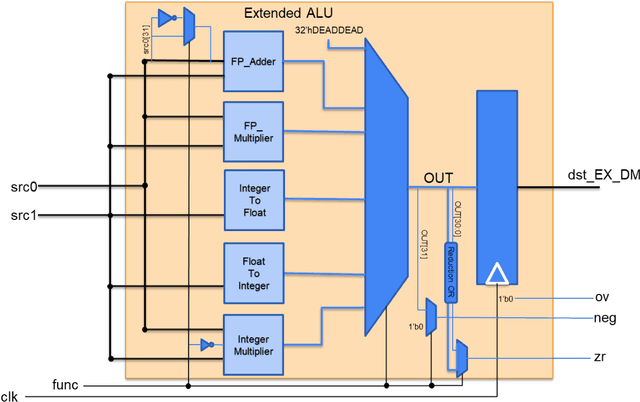
Machine Learning (ML) has recently been a skyrocketing field in Computer Science. As computer hardware engineers, we are enthusiastic about hardware implementations of popular software ML architectures to optimize their performance, reliability, and resource usage. In this project, we designed a highly-configurable, real-time device for recognizing handwritten letters and digits using an Altera DE1 FPGA Kit. We followed various engineering standards, including IEEE-754 32-bit Floating-Point Standard, Video Graphics Array (VGA) display protocol, Universal Asynchronous Receiver-Transmitter (UART) protocol, and Inter-Integrated Circuit (I2C) protocols to achieve the project goals. These significantly improved our design in compatibility, reusability, and simplicity in verifications. Following these standards, we designed a 32-bit floating-point (FP) instruction set architecture (ISA). We developed a 5-stage RISC processor in System Verilog to manage image processing, matrix multiplications, ML classifications, and user interfaces. Three different ML architectures were implemented and evaluated on our design: Linear Classification (LC), a 784-64-10 fully connected neural network (NN), and a LeNet-like Convolutional Neural Network (CNN) with ReLU activation layers and 36 classes (10 for the digits and 26 for the case-insensitive letters). The training processes were done in Python scripts, and the resulting kernels and weights were stored in hex files and loaded into the FPGA's SRAM units. Convolution, pooling, data management, and various other ML features were guided by firmware in our custom assembly language. This paper documents the high-level design block diagrams, interfaces between each System Verilog module, implementation details of our software and firmware components, and further discussions on potential impacts.
Concurrent Classifier Error Detection (CCED) in Large Scale Machine Learning Systems
Jun 02, 2023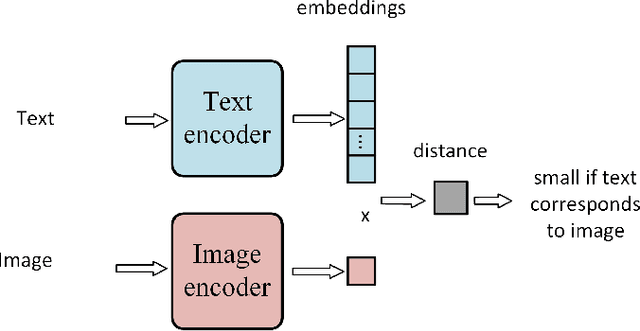
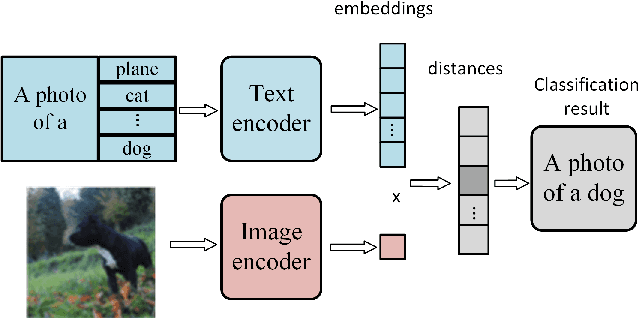
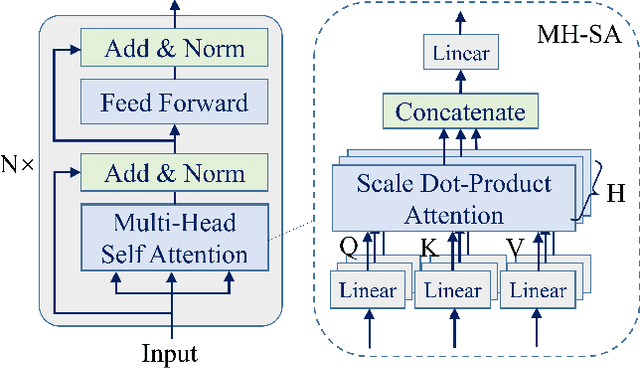
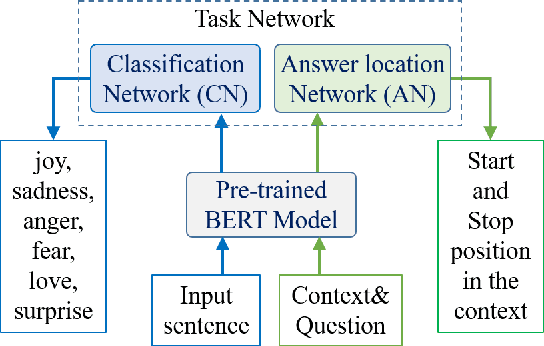
The complexity of Machine Learning (ML) systems increases each year, with current implementations of large language models or text-to-image generators having billions of parameters and requiring billions of arithmetic operations. As these systems are widely utilized, ensuring their reliable operation is becoming a design requirement. Traditional error detection mechanisms introduce circuit or time redundancy that significantly impacts system performance. An alternative is the use of Concurrent Error Detection (CED) schemes that operate in parallel with the system and exploit their properties to detect errors. CED is attractive for large ML systems because it can potentially reduce the cost of error detection. In this paper, we introduce Concurrent Classifier Error Detection (CCED), a scheme to implement CED in ML systems using a concurrent ML classifier to detect errors. CCED identifies a set of check signals in the main ML system and feeds them to the concurrent ML classifier that is trained to detect errors. The proposed CCED scheme has been implemented and evaluated on two widely used large-scale ML models: Contrastive Language Image Pretraining (CLIP) used for image classification and Bidirectional Encoder Representations from Transformers (BERT) used for natural language applications. The results show that more than 95 percent of the errors are detected when using a simple Random Forest classifier that is order of magnitude simpler than CLIP or BERT. These results illustrate the potential of CCED to implement error detection in large-scale ML models.
DEff-GAN: Diverse Attribute Transfer for Few-Shot Image Synthesis
Feb 28, 2023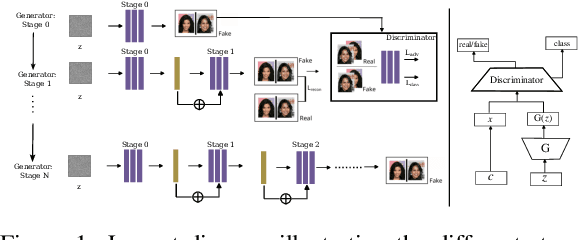

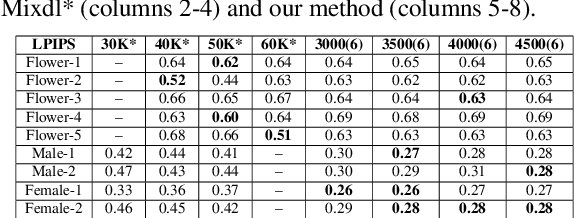

Requirements of large amounts of data is a difficulty in training many GANs. Data efficient GANs involve fitting a generators continuous target distribution with a limited discrete set of data samples, which is a difficult task. Single image methods have focused on modeling the internal distribution of a single image and generating its samples. While single image methods can synthesize image samples with diversity, they do not model multiple images or capture the inherent relationship possible between two images. Given only a handful of images, we are interested in generating samples and exploiting the commonalities in the input images. In this work, we extend the single-image GAN method to model multiple images for sample synthesis. We modify the discriminator with an auxiliary classifier branch, which helps to generate a wide variety of samples and to classify the input labels. Our Data-Efficient GAN (DEff-GAN) generates excellent results when similarities and correspondences can be drawn between the input images or classes.
Neural Delay Differential Equations: System Reconstruction and Image Classification
Apr 11, 2023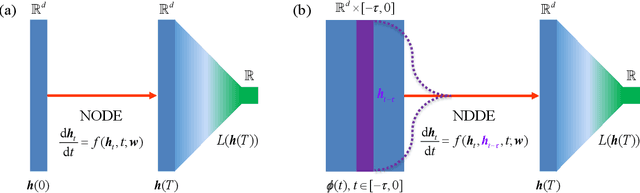
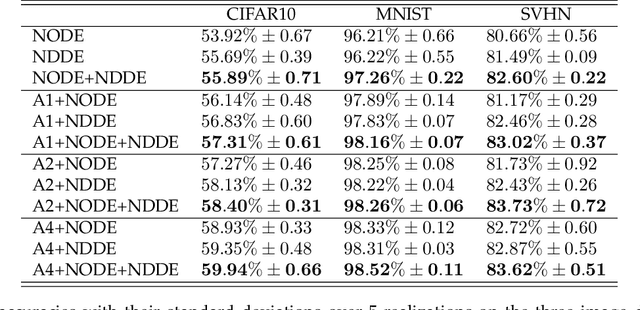
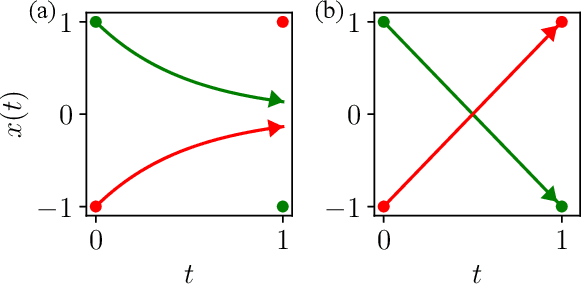
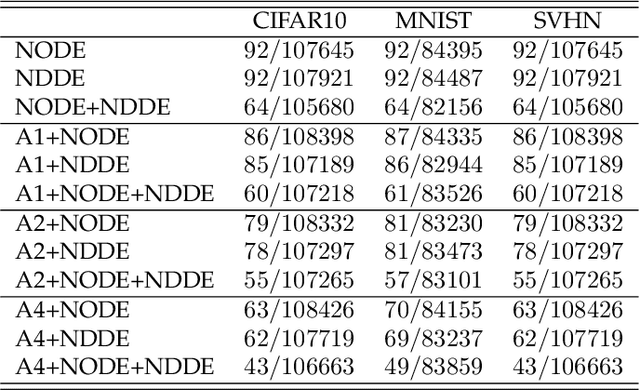
Neural Ordinary Differential Equations (NODEs), a framework of continuous-depth neural networks, have been widely applied, showing exceptional efficacy in coping with representative datasets. Recently, an augmented framework has been developed to overcome some limitations that emerged in the application of the original framework. In this paper, we propose a new class of continuous-depth neural networks with delay, named Neural Delay Differential Equations (NDDEs). To compute the corresponding gradients, we use the adjoint sensitivity method to obtain the delayed dynamics of the adjoint. Differential equations with delays are typically seen as dynamical systems of infinite dimension that possess more fruitful dynamics. Compared to NODEs, NDDEs have a stronger capacity of nonlinear representations. We use several illustrative examples to demonstrate this outstanding capacity. Firstly, we successfully model the delayed dynamics where the trajectories in the lower-dimensional phase space could be mutually intersected and even chaotic in a model-free or model-based manner. Traditional NODEs, without any argumentation, are not directly applicable for such modeling. Secondly, we achieve lower loss and higher accuracy not only for the data produced synthetically by complex models but also for the CIFAR10, a well-known image dataset. Our results on the NDDEs demonstrate that appropriately articulating the elements of dynamical systems into the network design is truly beneficial in promoting network performance.
LiT-4-RSVQA: Lightweight Transformer-based Visual Question Answering in Remote Sensing
Jun 02, 2023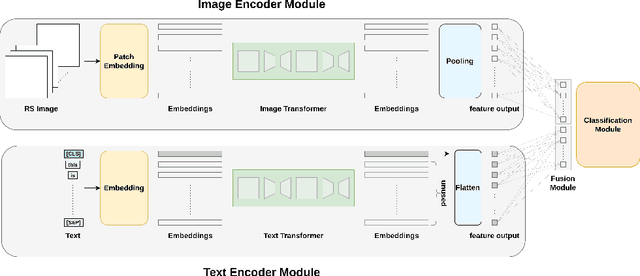
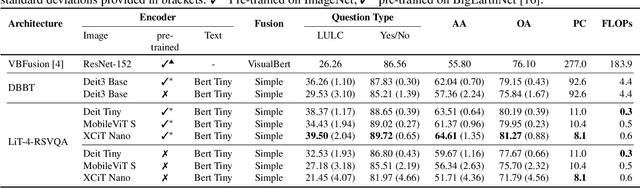
Visual question answering (VQA) methods in remote sensing (RS) aim to answer natural language questions with respect to an RS image. Most of the existing methods require a large amount of computational resources, which limits their application in operational scenarios in RS. To address this issue, in this paper we present an effective lightweight transformer-based VQA in RS (LiT-4-RSVQA) architecture for efficient and accurate VQA in RS. Our architecture consists of: i) a lightweight text encoder module; ii) a lightweight image encoder module; iii) a fusion module; and iv) a classification module. The experimental results obtained on a VQA benchmark dataset demonstrate that our proposed LiT-4-RSVQA architecture provides accurate VQA results while significantly reducing the computational requirements on the executing hardware. Our code is publicly available at https://git.tu-berlin.de/rsim/lit4rsvqa.
To Fold or Not to Fold: Graph Regularized Tensor Train for Visual Data Completion
Jun 19, 2023
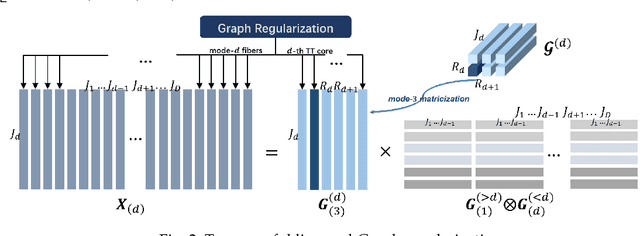
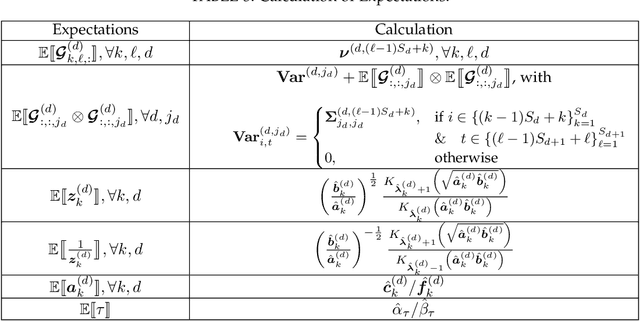
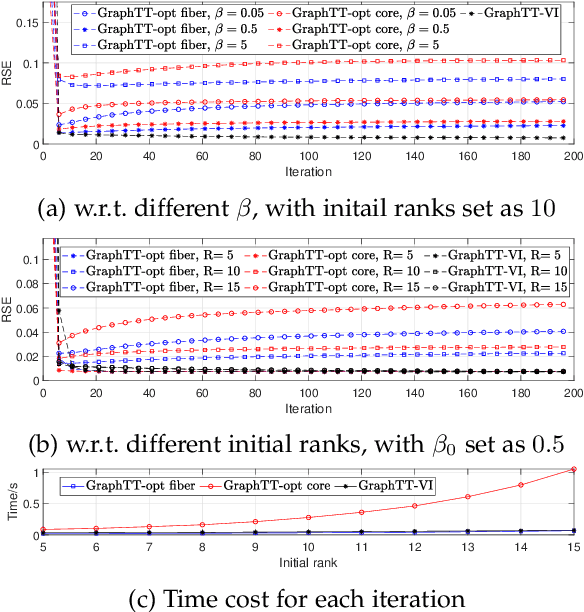
Tensor train (TT) representation has achieved tremendous success in visual data completion tasks, especially when it is combined with tensor folding. However, folding an image or video tensor breaks the original data structure, leading to local information loss as nearby pixels may be assigned into different dimensions and become far away from each other. In this paper, to fully preserve the local information of the original visual data, we explore not folding the data tensor, and at the same time adopt graph information to regularize local similarity between nearby entries. To overcome the high computational complexity introduced by the graph-based regularization in the TT completion problem, we propose to break the original problem into multiple sub-problems with respect to each TT core fiber, instead of each TT core as in traditional methods. Furthermore, to avoid heavy parameter tuning, a sparsity promoting probabilistic model is built based on the generalized inverse Gaussian (GIG) prior, and an inference algorithm is derived under the mean-field approximation. Experiments on both synthetic data and real-world visual data show the superiority of the proposed methods.
Understanding the Effect of the Long Tail on Neural Network Compression
Jun 19, 2023
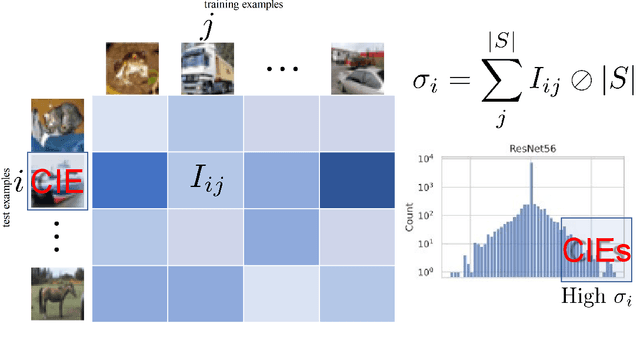
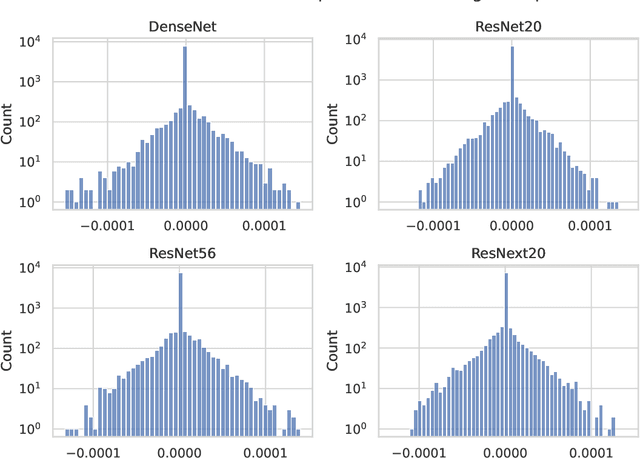
Network compression is now a mature sub-field of neural network research: over the last decade, significant progress has been made towards reducing the size of models and speeding up inference, while maintaining the classification accuracy. However, many works have observed that focusing on just the overall accuracy can be misguided. E.g., it has been shown that mismatches between the full and compressed models can be biased towards under-represented classes. This raises the important research question, \emph{can we achieve network compression while maintaining ``semantic equivalence'' with the original network?} In this work, we study this question in the context of the ``long tail'' phenomenon in computer vision datasets observed by Feldman, et al. They argue that \emph{memorization} of certain inputs (appropriately defined) is essential to achieving good generalization. As compression limits the capacity of a network (and hence also its ability to memorize), we study the question: are mismatches between the full and compressed models correlated with the memorized training data? We present positive evidence in this direction for image classification tasks, by considering different base architectures and compression schemes.
Generative Adversarial Networks for Brain Images Synthesis: A Review
May 16, 2023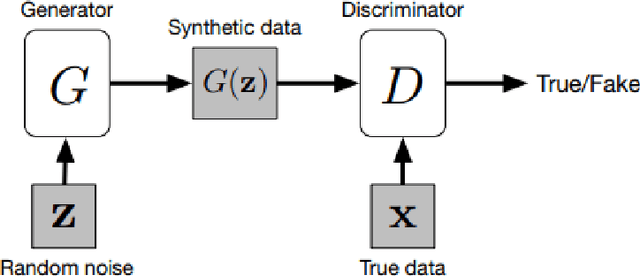
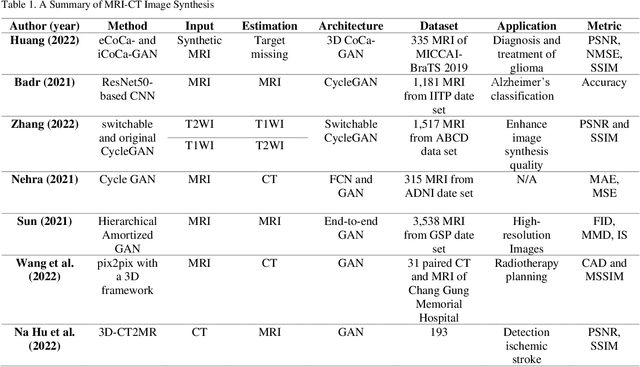
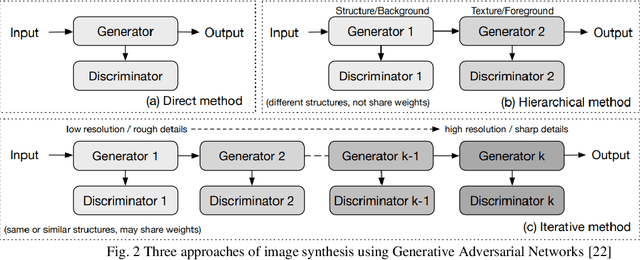
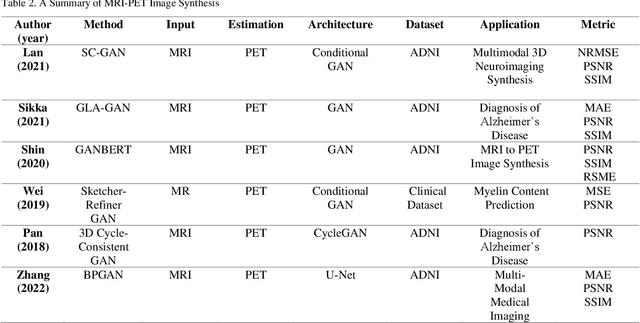
In medical imaging, image synthesis is the estimation process of one image (sequence, modality) from another image (sequence, modality). Since images with different modalities provide diverse biomarkers and capture various features, multi-modality imaging is crucial in medicine. While multi-screening is expensive, costly, and time-consuming to report by radiologists, image synthesis methods are capable of artificially generating missing modalities. Deep learning models can automatically capture and extract the high dimensional features. Especially, generative adversarial network (GAN) as one of the most popular generative-based deep learning methods, uses convolutional networks as generators, and estimated images are discriminated as true or false based on a discriminator network. This review provides brain image synthesis via GANs. We summarized the recent developments of GANs for cross-modality brain image synthesis including CT to PET, CT to MRI, MRI to PET, and vice versa.