 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GlyphControl: Glyph Conditional Control for Visual Text Generation
May 29, 2023

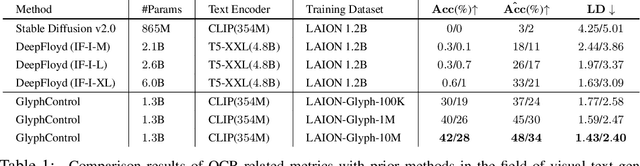
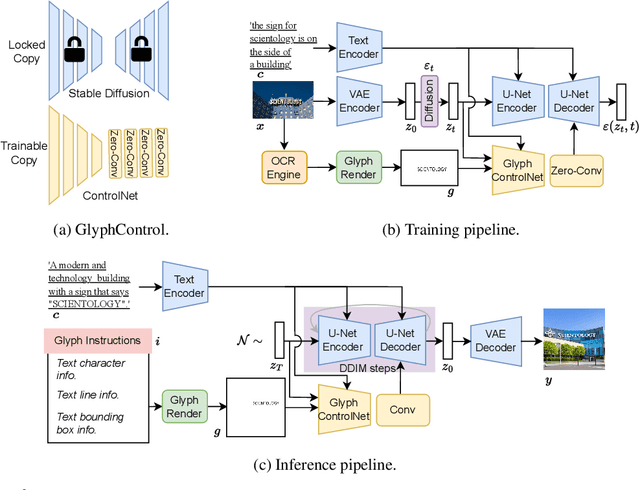

Recently, there has been a growing interest in developing diffusion-based text-to-image generative models capable of generating coherent and well-formed visual text. In this paper, we propose a novel and efficient approach called GlyphControl to address this task. Unlike existing methods that rely on character-aware text encoders like ByT5 and require retraining of text-to-image models, our approach leverages additional glyph conditional information to enhance the performance of the off-the-shelf Stable-Diffusion model in generating accurate visual text. By incorporating glyph instructions, users can customize the content, location, and size of the generated text according to their specific requirements. To facilitate further research in visual text generation, we construct a training benchmark dataset called LAION-Glyph. We evaluate the effectiveness of our approach by measuring OCR-based metrics and CLIP scores of the generated visual text. Our empirical evaluations demonstrate that GlyphControl outperforms the recent DeepFloyd IF approach in terms of OCR accuracy and CLIP scores, highlighting the efficacy of our method.
Contextual Object Detection with Multimodal Large Language Models
May 29, 2023
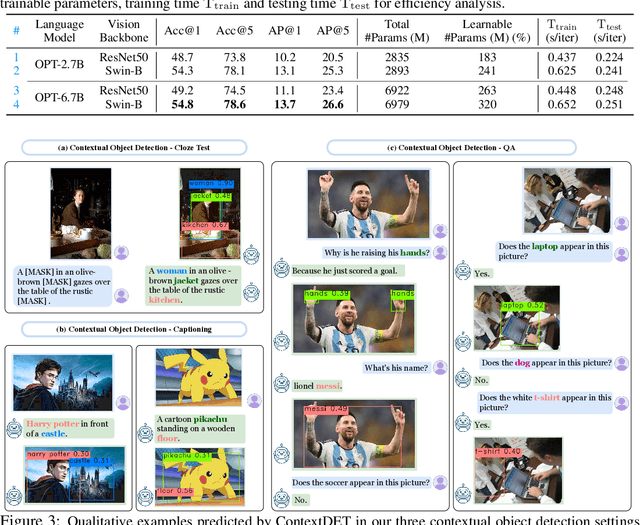
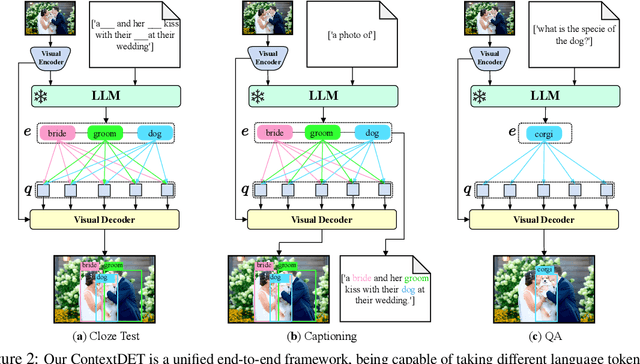

Recent Multimodal Large Language Models (MLLMs) are remarkable in vision-language tasks, such as image captioning and question answering, but lack the essential perception ability, i.e., object detection. In this work, we address this limitation by introducing a novel research problem of contextual object detection -- understanding visible objects within different human-AI interactive contexts. Three representative scenarios are investigated, including the language cloze test, visual captioning, and question answering. Moreover, we present ContextDET, a unified multimodal model that is capable of end-to-end differentiable modeling of visual-language contexts, so as to locate, identify, and associate visual objects with language inputs for human-AI interaction. Our ContextDET involves three key submodels: (i) a visual encoder for extracting visual representations, (ii) a pre-trained LLM for multimodal context decoding, and (iii) a visual decoder for predicting bounding boxes given contextual object words. The new generate-then-detect framework enables us to detect object words within human vocabulary. Extensive experiments show the advantages of ContextDET on our proposed CODE benchmark, open-vocabulary detection, and referring image segmentation. Github: https://github.com/yuhangzang/ContextDET.
LANISTR: Multimodal Learning from Structured and Unstructured Data
May 26, 2023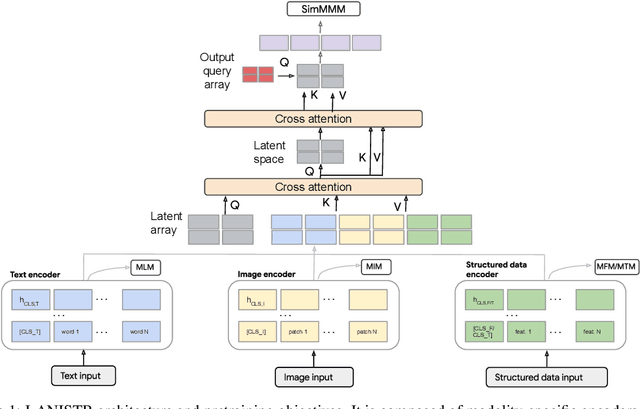


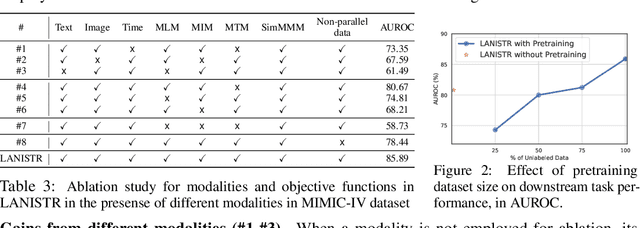
Multimodal large-scale pretraining has shown impressive performance gains for unstructured data including language, image, audio, and video. Yet, the scenario most prominent in real-world applications is the existence of combination of structured (including tabular and time-series) and unstructured data, and this has so far been understudied. Towards this end, we propose LANISTR, a novel attention-based framework to learn from LANguage, Image, and STRuctured data. We introduce a new multimodal fusion module with a similarity-based multimodal masking loss that enables LANISTR to learn cross-modal relations from large-scale multimodal data with missing modalities during training and test time. On two publicly available challenging datasets, MIMIC-IV and Amazon Product Review, LANISTR achieves absolute improvements of 6.47% (AUROC) and up to 17.69% (accuracy), respectively, compared to the state-of-the-art multimodal models while showing superior generalization capabilities.
Weakly supervised information extraction from inscrutable handwritten document images
Jun 12, 2023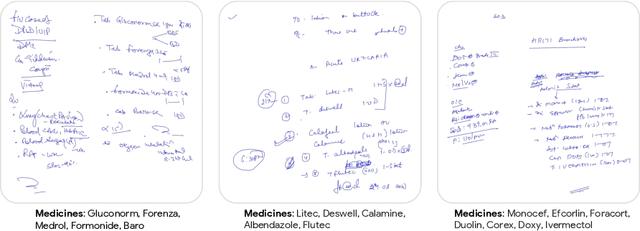

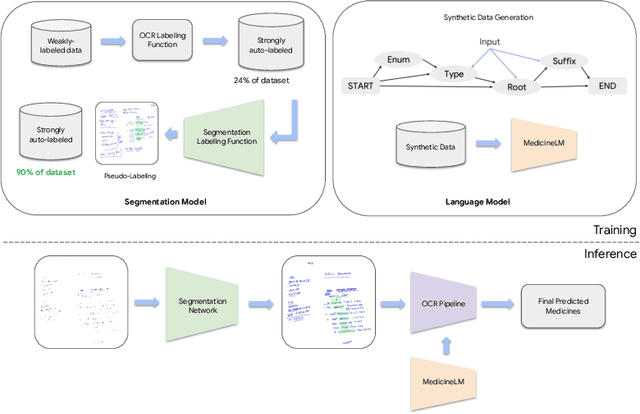
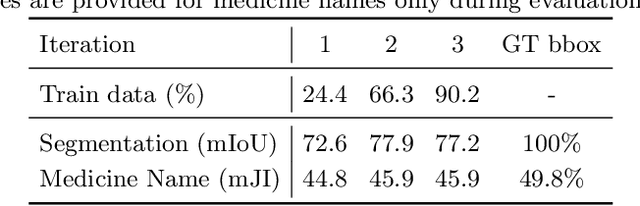
State-of-the-art information extraction methods are limited by OCR errors. They work well for printed text in form-like documents, but unstructured, handwritten documents still remain a challenge. Adapting existing models to domain-specific training data is quite expensive, because of two factors, 1) limited availability of the domain-specific documents (such as handwritten prescriptions, lab notes, etc.), and 2) annotations become even more challenging as one needs domain-specific knowledge to decode inscrutable handwritten document images. In this work, we focus on the complex problem of extracting medicine names from handwritten prescriptions using only weakly labeled data. The data consists of images along with the list of medicine names in it, but not their location in the image. We solve the problem by first identifying the regions of interest, i.e., medicine lines from just weak labels and then injecting a domain-specific medicine language model learned using only synthetically generated data. Compared to off-the-shelf state-of-the-art methods, our approach performs >2.5x better in medicine names extraction from prescriptions.
Joint Multi-Scale Tone Mapping and Denoising for HDR Image Enhancement
Mar 16, 2023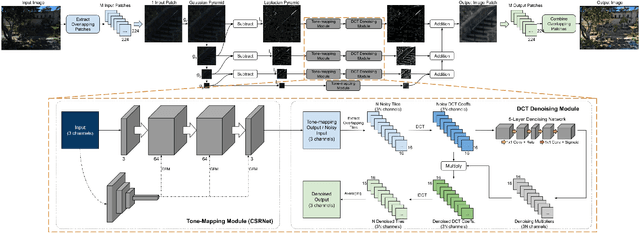

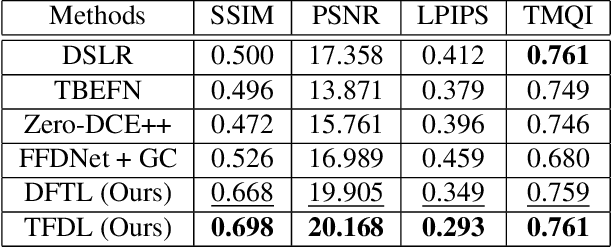
An image processing unit (IPU), or image signal processor (ISP) for high dynamic range (HDR) imaging usually consists of demosaicing, white balancing, lens shading correction, color correction, denoising, and tone-mapping. Besides noise from the imaging sensors, almost every step in the ISP introduces or amplifies noise in different ways, and denoising operators are designed to reduce the noise from these sources. Designed for dynamic range compressing, tone-mapping operators in an ISP can significantly amplify the noise level, especially for images captured in low-light conditions, making denoising very difficult. Therefore, we propose a joint multi-scale denoising and tone-mapping framework that is designed with both operations in mind for HDR images. Our joint network is trained in an end-to-end format that optimizes both operators together, to prevent the tone-mapping operator from overwhelming the denoising operator. Our model outperforms existing HDR denoising and tone-mapping operators both quantitatively and qualitatively on most of our benchmarking datasets.
Effect of Lossy Compression Algorithms on Face Image Quality and Recognition
Feb 24, 2023
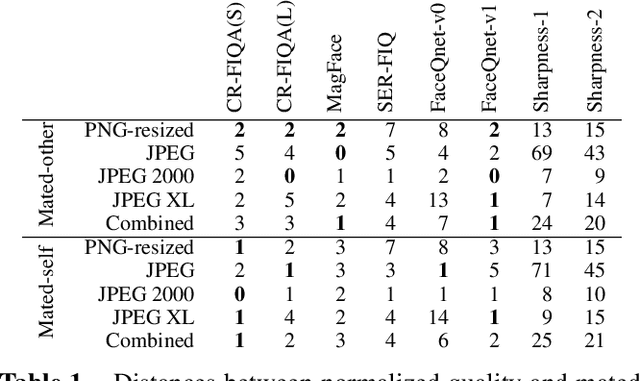
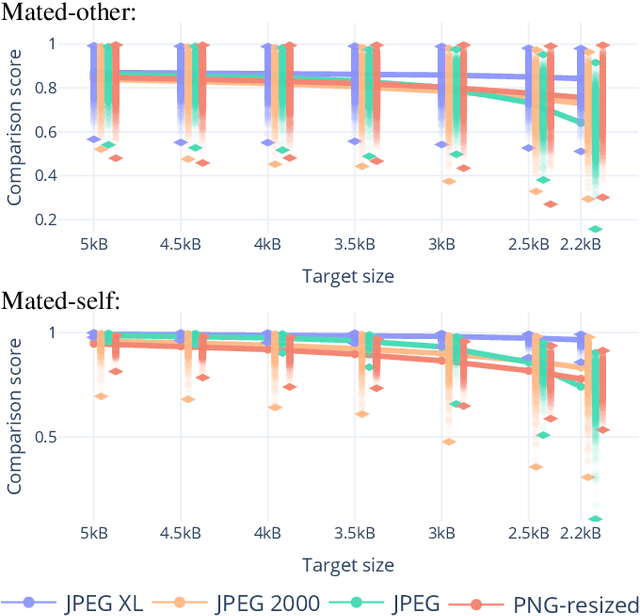
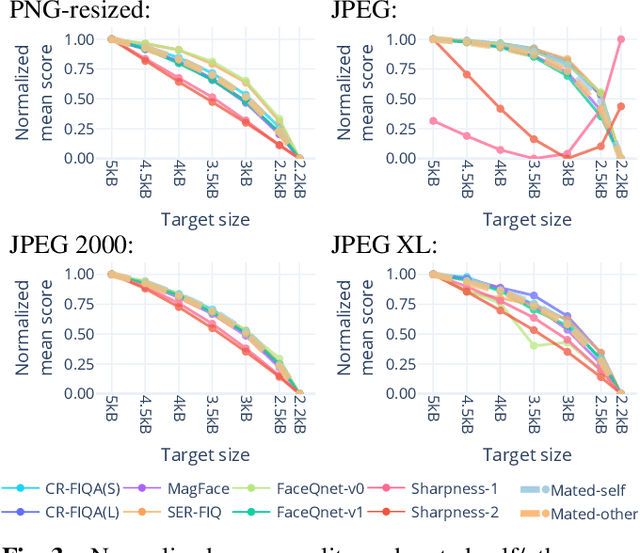
Lossy face image compression can degrade the image quality and the utility for the purpose of face recognition. This work investigates the effect of lossy image compression on a state-of-the-art face recognition model, and on multiple face image quality assessment models. The analysis is conducted over a range of specific image target sizes. Four compression types are considered, namely JPEG, JPEG 2000, downscaled PNG, and notably the new JPEG XL format. Frontal color images from the ColorFERET database were used in a Region Of Interest (ROI) variant and a portrait variant. We primarily conclude that JPEG XL allows for superior mean and worst case face recognition performance especially at lower target sizes, below approximately 5kB for the ROI variant, while there appears to be no critical advantage among the compression types at higher target sizes. Quality assessments from modern models correlate well overall with the compression effect on face recognition performance.
High-Throughput AI Inference for Medical Image Classification and Segmentation using Intelligent Streaming
May 24, 2023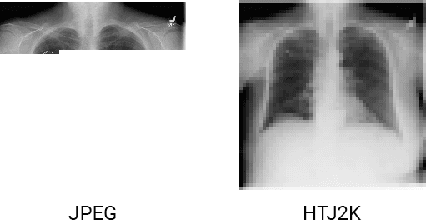
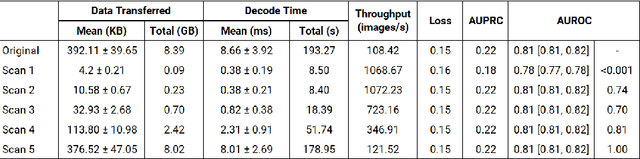
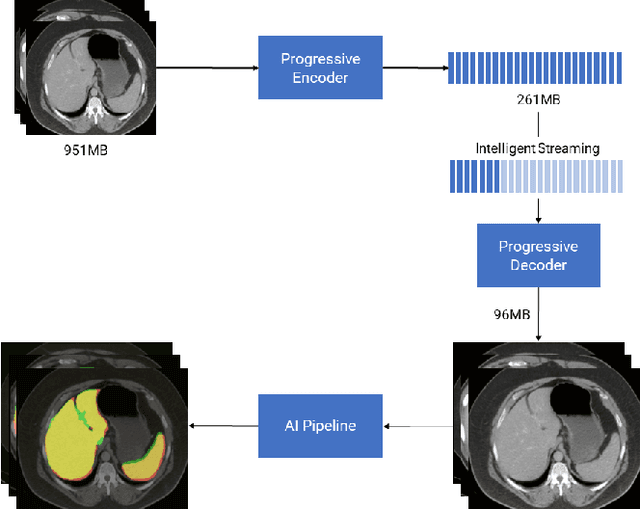
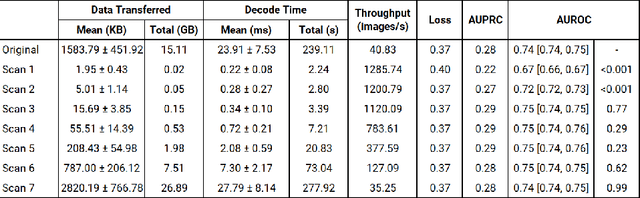
As the adoption of AI systems within the clinical setup grows, limitations in bandwidth could create communication bottlenecks when streaming imaging data, leading to delays in patient diagnosis and treatment. As such, healthcare providers and AI vendors will require greater computational infrastructure, therefore dramatically increasing costs. To that end, we developed intelligent streaming, a state-of-the-art framework to enable accelerated, cost-effective, bandwidth-optimized, and computationally efficient AI inference for clinical decision making at scale. For classification, intelligent streaming reduced the data transmission by 99.01% and decoding time by 98.58%, while increasing throughput by 27.43x. For segmentation, our framework reduced data transmission by 90.32%, decoding time by 90.26%, while increasing throughput by 4.20x. Our work demonstrates that intelligent streaming results in faster turnaround times, and reduced overall cost of data and transmission, without negatively impacting clinical decision making using AI systems.
Exploration of Lightweight Single Image Denoising with Transformers and Truly Fair Training
Apr 04, 2023
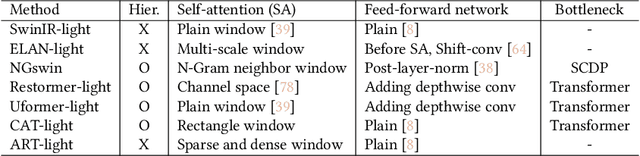
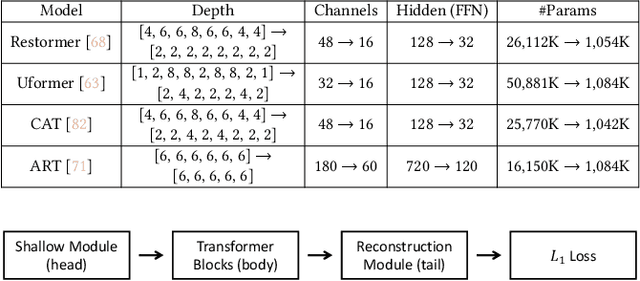
As multimedia content often contains noise from intrinsic defects of digital devices, image denoising is an important step for high-level vision recognition tasks. Although several studies have developed the denoising field employing advanced Transformers, these networks are too momory-intensive for real-world applications. Additionally, there is a lack of research on lightweight denosing (LWDN) with Transformers. To handle this, this work provides seven comparative baseline Transformers for LWDN, serving as a foundation for future research. We also demonstrate the parts of randomly cropped patches significantly affect the denoising performances during training. While previous studies have overlooked this aspect, we aim to train our baseline Transformers in a truly fair manner. Furthermore, we conduct empirical analyses of various components to determine the key considerations for constructing LWDN Transformers. Codes are available at https://github.com/rami0205/LWDN.
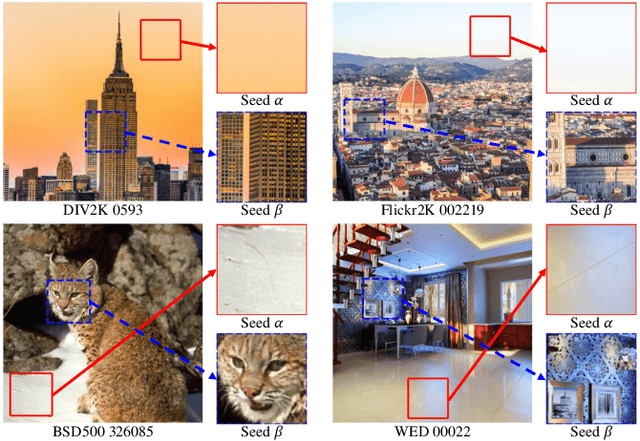
Half of an image is enough for quality assessment
Feb 09, 2023
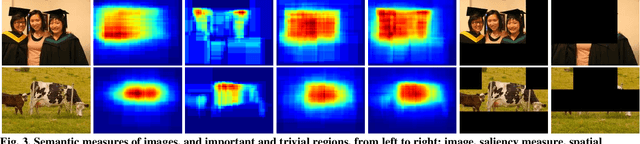
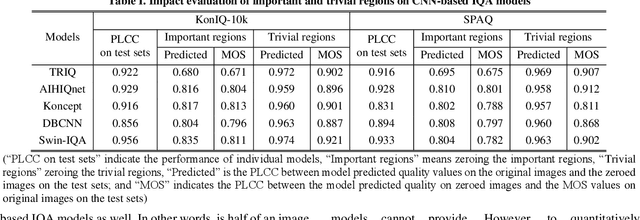
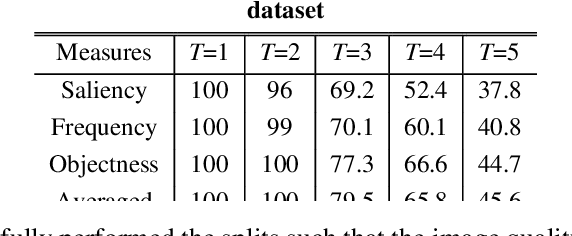
Deep networks have demonstrated promising results in the field of Image Quality Assessment (IQA). However, there has been limited research on understanding how deep models in IQA work. This study introduces a novel positional masked transformer for IQA and provides insights into the contribution of different regions of an image towards its overall quality. Results indicate that half of an image may play a trivial role in determining image quality, while the other half is critical. This observation is extended to several other CNN-based IQA models, revealing that half of the image regions can significantly impact the overall image quality. To further enhance our understanding, three semantic measures (saliency, frequency, and objectness) were derived and found to have high correlation with the importance of image regions in IQA.
Open Set Classification of GAN-based Image Manipulations via a ViT-based Hybrid Architecture
Apr 11, 2023

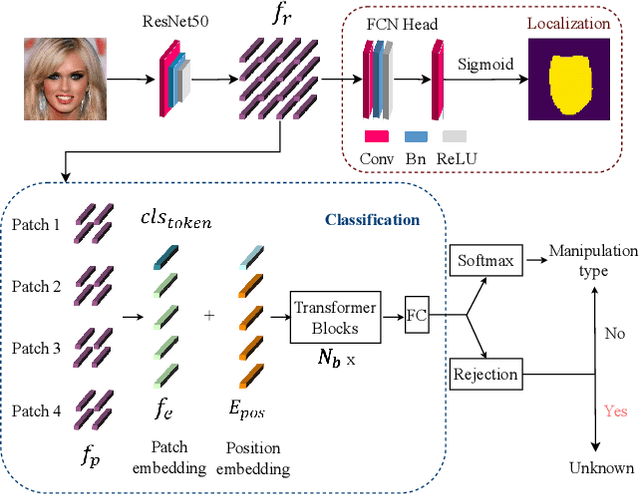
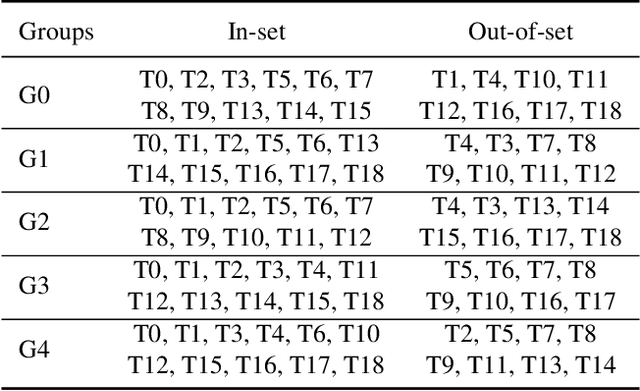
Classification of AI-manipulated content is receiving great attention, for distinguishing different types of manipulations. Most of the methods developed so far fail in the open-set scenario, that is when the algorithm used for the manipulation is not represented by the training set. In this paper, we focus on the classification of synthetic face generation and manipulation in open-set scenarios, and propose a method for classification with a rejection option. The proposed method combines the use of Vision Transformers (ViT) with a hybrid approach for simultaneous classification and localization. Feature map correlation is exploited by the ViT module, while a localization branch is employed as an attention mechanism to force the model to learn per-class discriminative features associated with the forgery when the manipulation is performed locally in the image. Rejection is performed by considering several strategies and analyzing the model output layers. The effectiveness of the proposed method is assessed for the task of classification of facial attribute editing and GAN attribution.