 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Automated Fact-Checking: A Survey
May 24, 2023

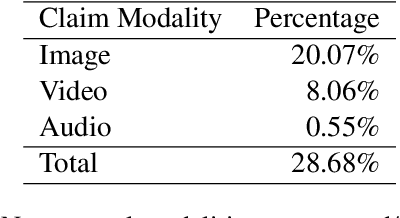

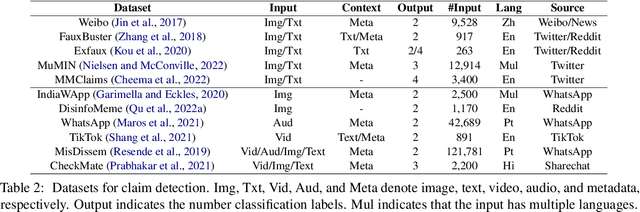
Misinformation, i.e. factually incorrect information, is often conveyed in multiple modalities, e.g. an image accompanied by a caption. It is perceived as more credible by humans, and spreads faster and wider than its text-only counterparts. While an increasing body of research investigates automated fact-checking (AFC), previous surveys mostly focus on textual misinformation. In this survey, we conceptualise a framework for AFC including subtasks unique to multimodal misinformation. Furthermore, we discuss related terminological developed in different communities in the context of our framework. We focus on four modalities prevalent in real-world fact-checking: text, image, audio, and video. We survey benchmarks and models, and discuss limitations and promising directions for future research.
Exploration of Lightweight Single Image Denoising with Transformers and Truly Fair Training
Apr 04, 2023
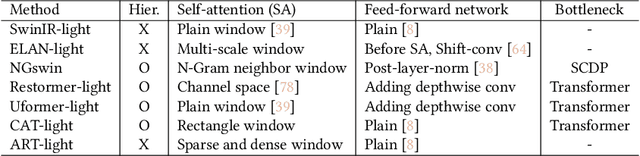
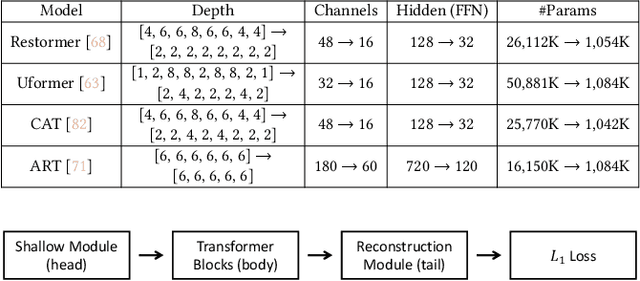
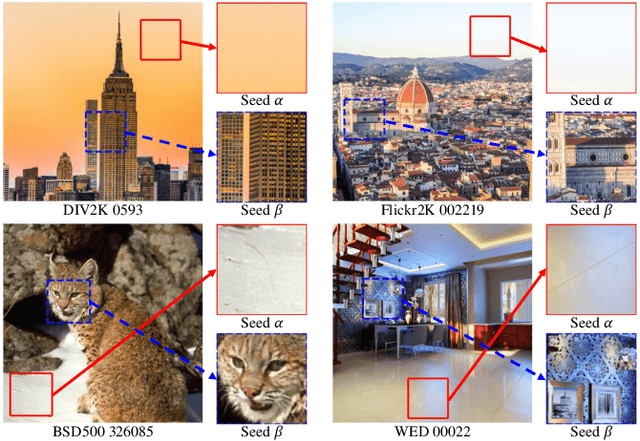
As multimedia content often contains noise from intrinsic defects of digital devices, image denoising is an important step for high-level vision recognition tasks. Although several studies have developed the denoising field employing advanced Transformers, these networks are too momory-intensive for real-world applications. Additionally, there is a lack of research on lightweight denosing (LWDN) with Transformers. To handle this, this work provides seven comparative baseline Transformers for LWDN, serving as a foundation for future research. We also demonstrate the parts of randomly cropped patches significantly affect the denoising performances during training. While previous studies have overlooked this aspect, we aim to train our baseline Transformers in a truly fair manner. Furthermore, we conduct empirical analyses of various components to determine the key considerations for constructing LWDN Transformers. Codes are available at https://github.com/rami0205/LWDN.
X&Fuse: Fusing Visual Information in Text-to-Image Generation
Mar 02, 2023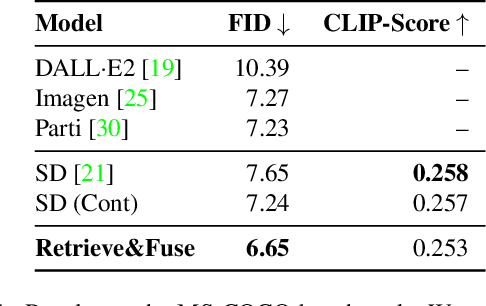
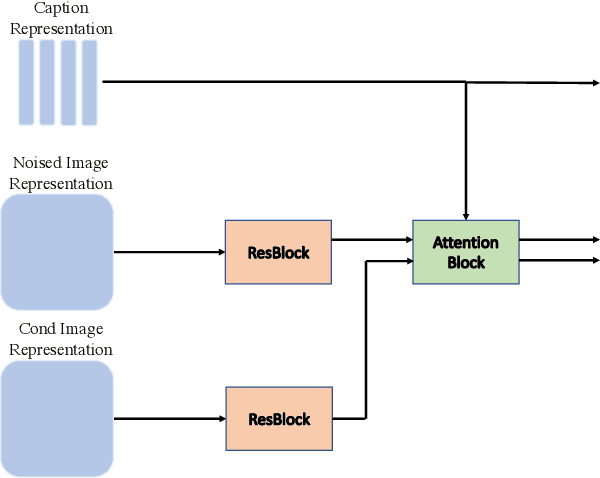
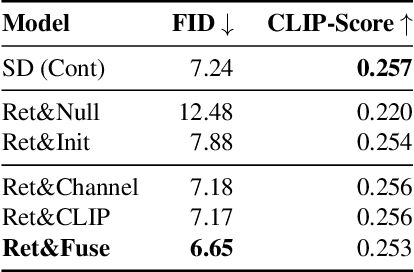

We introduce X&Fuse, a general approach for conditioning on visual information when generating images from text. We demonstrate the potential of X&Fuse in three different text-to-image generation scenarios. (i) When a bank of images is available, we retrieve and condition on a related image (Retrieve&Fuse), resulting in significant improvements on the MS-COCO benchmark, gaining a state-of-the-art FID score of 6.65 in zero-shot settings. (ii) When cropped-object images are at hand, we utilize them and perform subject-driven generation (Crop&Fuse), outperforming the textual inversion method while being more than x100 faster. (iii) Having oracle access to the image scene (Scene&Fuse), allows us to achieve an FID score of 5.03 on MS-COCO in zero-shot settings. Our experiments indicate that X&Fuse is an effective, easy-to-adapt, simple, and general approach for scenarios in which the model may benefit from additional visual information.
Robust Unsupervised StyleGAN Image Restoration
Feb 13, 2023
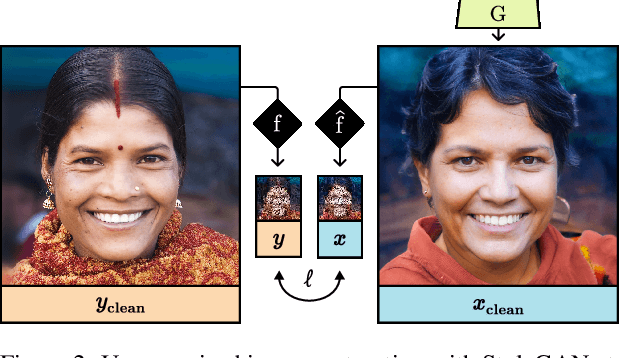
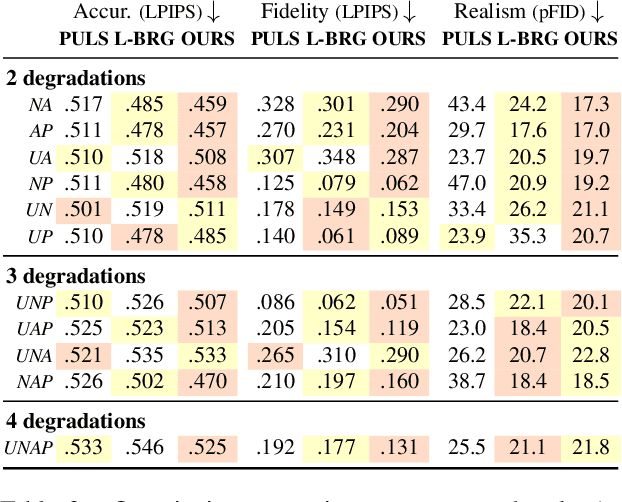
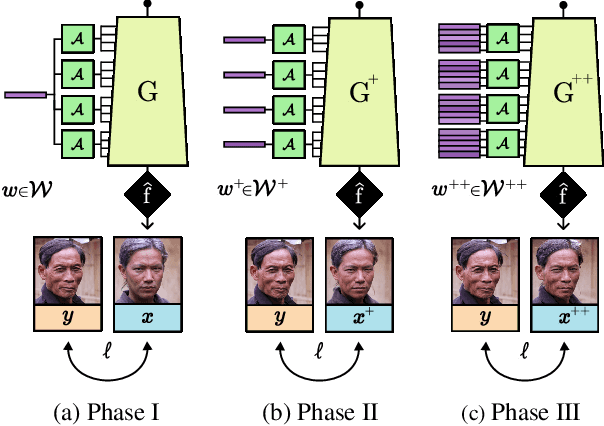
GAN-based image restoration inverts the generative process to repair images corrupted by known degradations. Existing unsupervised methods must be carefully tuned for each task and degradation level. In this work, we make StyleGAN image restoration robust: a single set of hyperparameters works across a wide range of degradation levels. This makes it possible to handle combinations of several degradations, without the need to retune. Our proposed approach relies on a 3-phase progressive latent space extension and a conservative optimizer, which avoids the need for any additional regularization terms. Extensive experiments demonstrate robustness on inpainting, upsampling, denoising, and deartifacting at varying degradations levels, outperforming other StyleGAN-based inversion techniques. Our approach also favorably compares to diffusion-based restoration by yielding much more realistic inversion results. Code will be released upon publication.
Exploring Semantic Variations in GAN Latent Spaces via Matrix Factorization
May 23, 2023



Controlled data generation with GANs is desirable but challenging due to the nonlinearity and high dimensionality of their latent spaces. In this work, we explore image manipulations learned by GANSpace, a state-of-the-art method based on PCA. Through quantitative and qualitative assessments we show: (a) GANSpace produces a wide range of high-quality image manipulations, but they can be highly entangled, limiting potential use cases; (b) Replacing PCA with ICA improves the quality and disentanglement of manipulations; (c) The quality of the generated images can be sensitive to the size of GANs, but regardless of their complexity, fundamental controlling directions can be observed in their latent spaces.
Sector Patch Embedding: An Embedding Module Conforming to The Distortion Pattern of Fisheye Image
Mar 26, 2023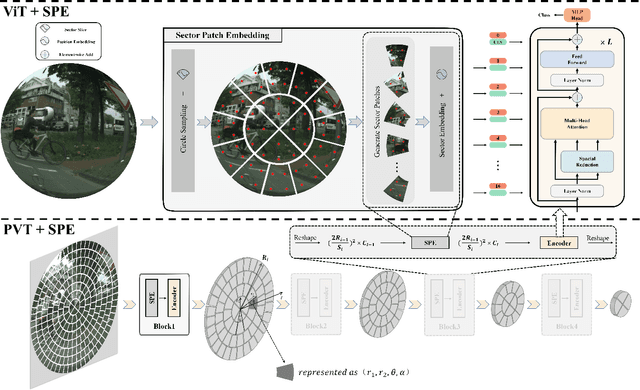
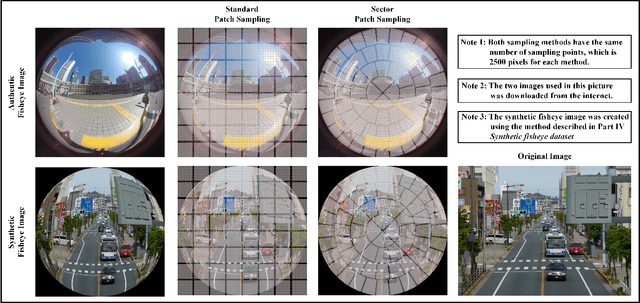
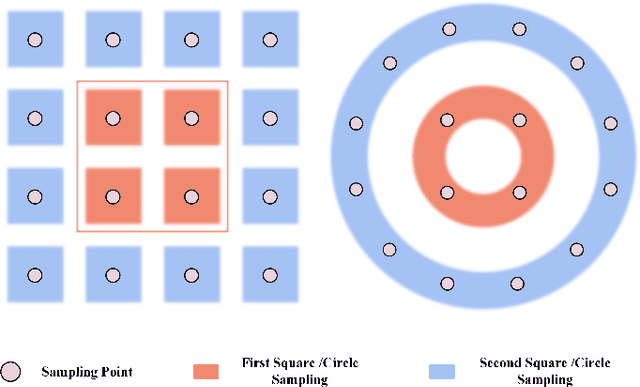
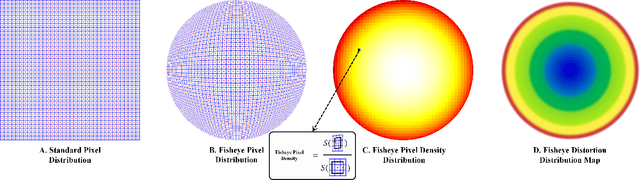
Fisheye cameras suffer from image distortion while having a large field of view(LFOV). And this fact leads to poor performance on some fisheye vision tasks. One of the solutions is to optimize the current vision algorithm for fisheye images. However, most of the CNN-based methods and the Transformer-based methods lack the capability of leveraging distortion information efficiently. In this work, we propose a novel patch embedding method called Sector Patch Embedding(SPE), conforming to the distortion pattern of the fisheye image. Furthermore, we put forward a synthetic fisheye dataset based on the ImageNet-1K and explore the performance of several Transformer models on the dataset. The classification top-1 accuracy of ViT and PVT is improved by 0.75% and 2.8% with SPE respectively. The experiments show that the proposed sector patch embedding method can better perceive distortion and extract features on the fisheye images. Our method can be easily adopted to other Transformer-based models. Source code is at https://github.com/IN2-ViAUn/Sector-Patch-Embedding.
Context Normalization for Robust Image Classification
Mar 14, 2023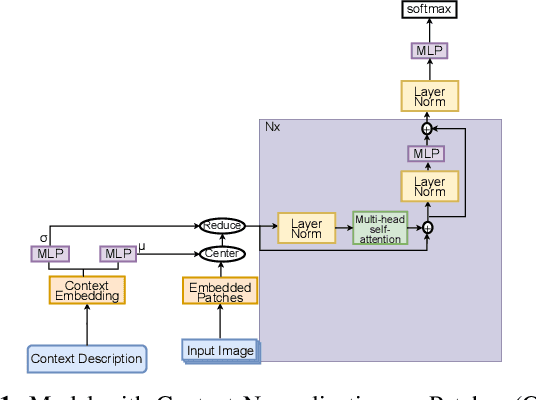
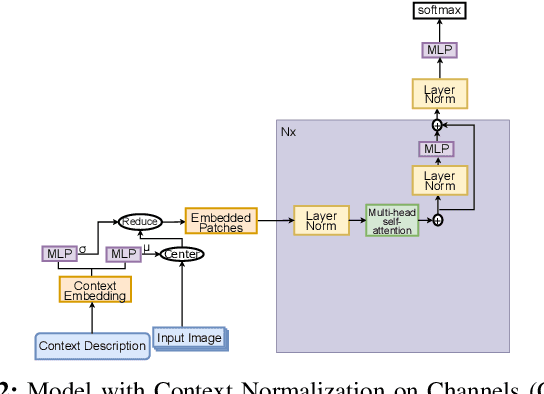
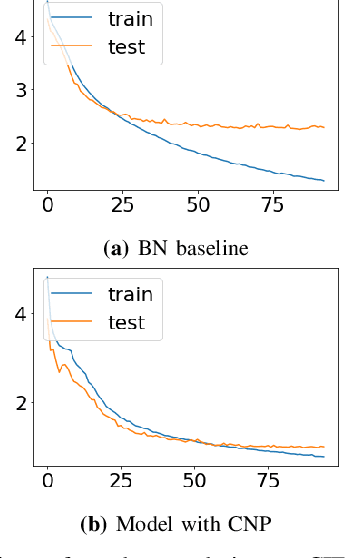

Normalization is a pre-processing step that converts the data into a more usable representation. As part of the deep neural networks (DNNs), the batch normalization (BN) technique uses normalization to address the problem of internal covariate shift. It can be packaged as general modules, which have been extensively integrated into various DNNs, to stabilize and accelerate training, presumably leading to improved generalization. However, the effect of BN is dependent on the mini-batch size and it does not take into account any groups or clusters that may exist in the dataset when estimating population statistics. This study proposes a new normalization technique, called context normalization, for image data. This approach adjusts the scaling of features based on the characteristics of each sample, which improves the model's convergence speed and performance by adapting the data values to the context of the target task. The effectiveness of context normalization is demonstrated on various datasets, and its performance is compared to other standard normalization techniques.
ChatFace: Chat-Guided Real Face Editing via Diffusion Latent Space Manipulation
May 24, 2023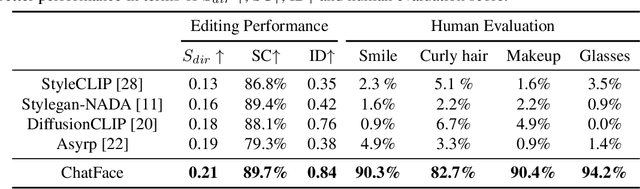
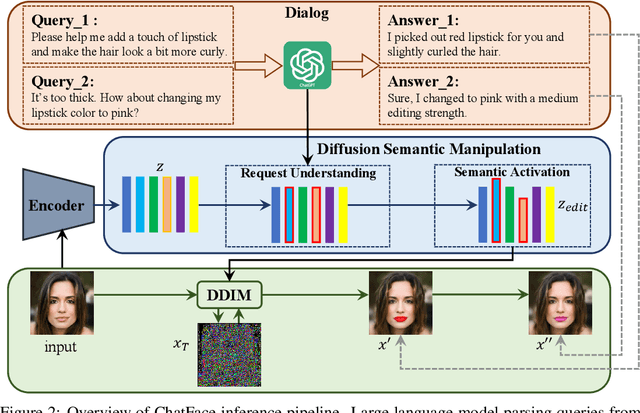
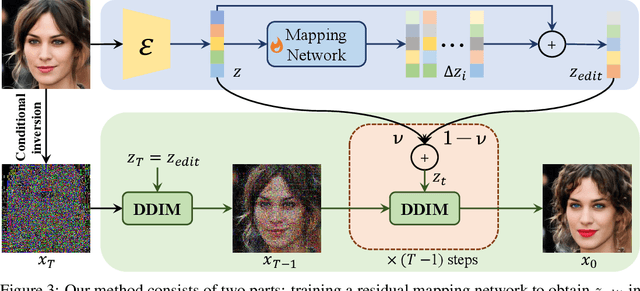
Editing real facial images is a crucial task in computer vision with significant demand in various real-world applications. While GAN-based methods have showed potential in manipulating images especially when combined with CLIP, these methods are limited in their ability to reconstruct real images due to challenging GAN inversion capability. Despite the successful image reconstruction achieved by diffusion-based methods, there are still challenges in effectively manipulating fine-gained facial attributes with textual instructions.To address these issues and facilitate convenient manipulation of real facial images, we propose a novel approach that conduct text-driven image editing in the semantic latent space of diffusion model. By aligning the temporal feature of the diffusion model with the semantic condition at generative process, we introduce a stable manipulation strategy, which perform precise zero-shot manipulation effectively. Furthermore, we develop an interactive system named ChatFace, which combines the zero-shot reasoning ability of large language models to perform efficient manipulations in diffusion semantic latent space. This system enables users to perform complex multi-attribute manipulations through dialogue, opening up new possibilities for interactive image editing. Extensive experiments confirmed that our approach outperforms previous methods and enables precise editing of real facial images, making it a promising candidate for real-world applications. Project page: https://dongxuyue.github.io/chatface/
DuDGAN: Improving Class-Conditional GANs via Dual-Diffusion
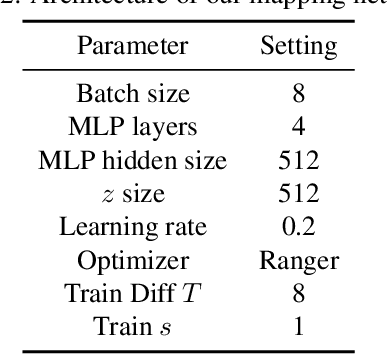
May 24, 2023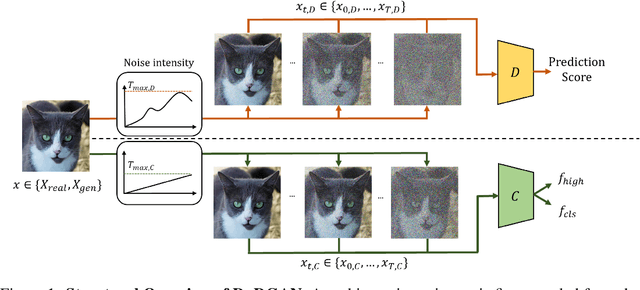

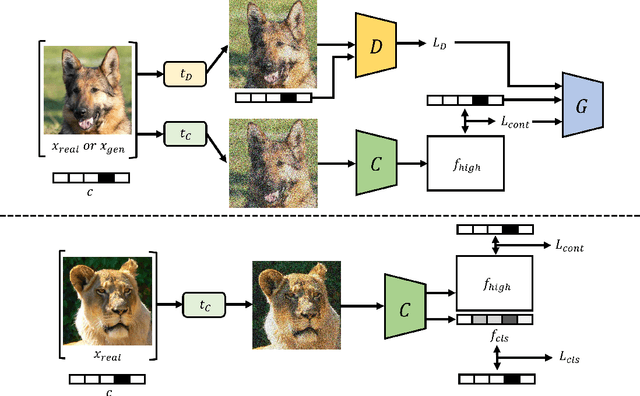
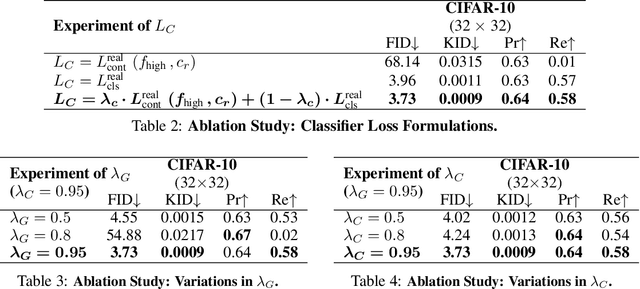
Class-conditional image generation using generative adversarial networks (GANs) has been investigated through various techniques; however, it continues to face challenges such as mode collapse, training instability, and low-quality output in cases of datasets with high intra-class variation. Furthermore, most GANs often converge in larger iterations, resulting in poor iteration efficacy in training procedures. While Diffusion-GAN has shown potential in generating realistic samples, it has a critical limitation in generating class-conditional samples. To overcome these limitations, we propose a novel approach for class-conditional image generation using GANs called DuDGAN, which incorporates a dual diffusion-based noise injection process. Our method consists of three unique networks: a discriminator, a generator, and a classifier. During the training process, Gaussian-mixture noises are injected into the two noise-aware networks, the discriminator and the classifier, in distinct ways. This noisy data helps to prevent overfitting by gradually introducing more challenging tasks, leading to improved model performance. As a result, our method outperforms state-of-the-art conditional GAN models for image generation in terms of performance. We evaluated our method using the AFHQ, Food-101, and CIFAR-10 datasets and observed superior results across metrics such as FID, KID, Precision, and Recall score compared with comparison models, highlighting the effectiveness of our approach.
Exploring Open-Vocabulary Semantic Segmentation without Human Labels
Jun 01, 2023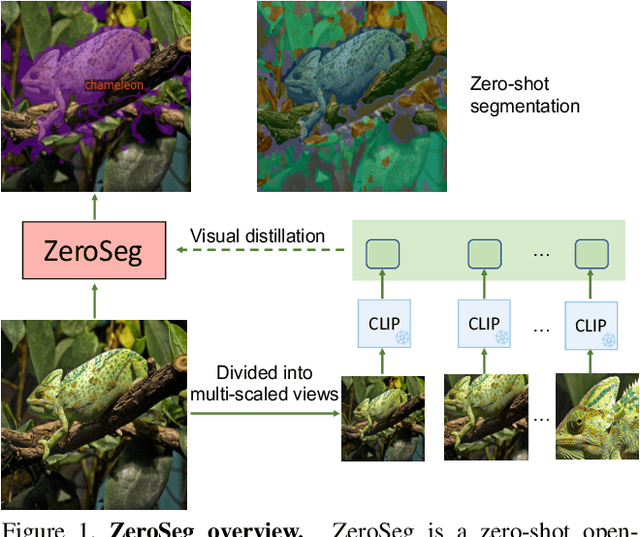
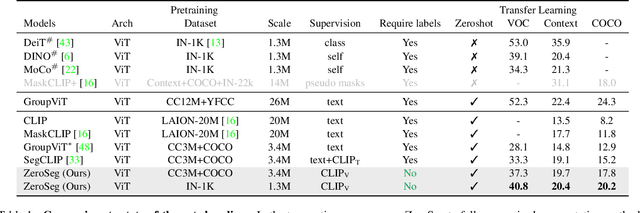
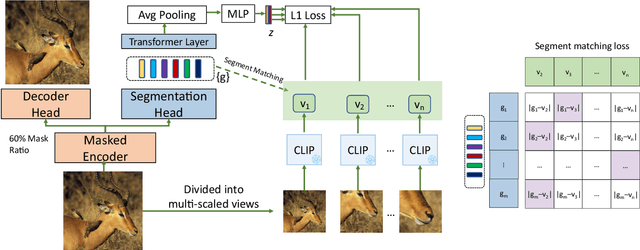
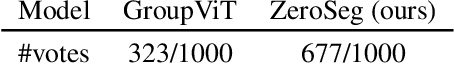
Semantic segmentation is a crucial task in computer vision that involves segmenting images into semantically meaningful regions at the pixel level. However, existing approaches often rely on expensive human annotations as supervision for model training, limiting their scalability to large, unlabeled datasets. To address this challenge, we present ZeroSeg, a novel method that leverages the existing pretrained vision-language (VL) model (e.g. CLIP) to train open-vocabulary zero-shot semantic segmentation models. Although acquired extensive knowledge of visual concepts, it is non-trivial to exploit knowledge from these VL models to the task of semantic segmentation, as they are usually trained at an image level. ZeroSeg overcomes this by distilling the visual concepts learned by VL models into a set of segment tokens, each summarizing a localized region of the target image. We evaluate ZeroSeg on multiple popular segmentation benchmarks, including PASCAL VOC 2012, PASCAL Context, and COCO, in a zero-shot manner (i.e., no training or adaption on target segmentation datasets). Our approach achieves state-of-the-art performance when compared to other zero-shot segmentation methods under the same training data, while also performing competitively compared to strongly supervised methods. Finally, we also demonstrated the effectiveness of ZeroSeg on open-vocabulary segmentation, through both human studies and qualitative visualizations.