 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model
Jun 09, 2023
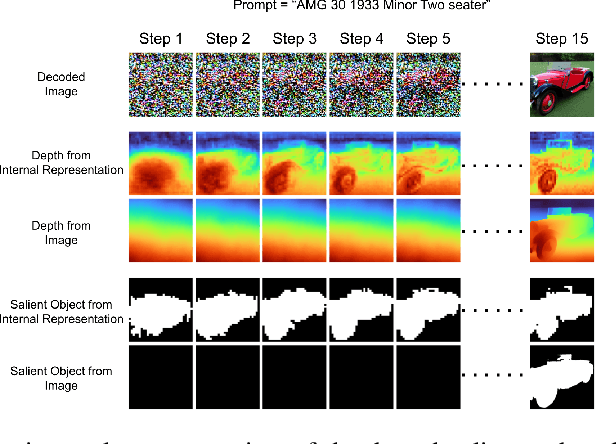
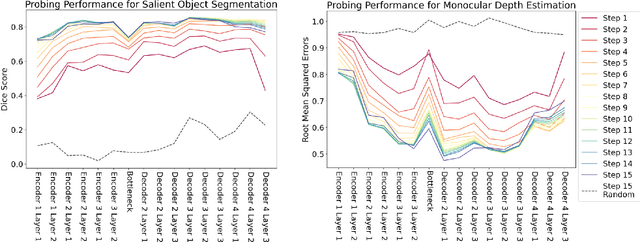
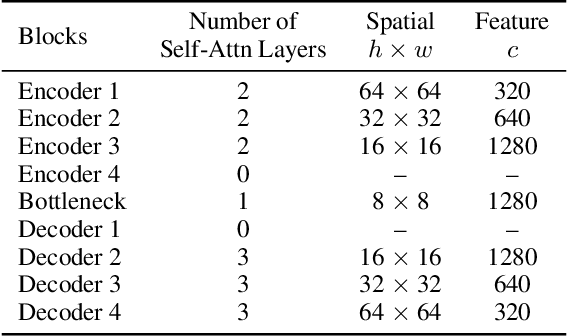
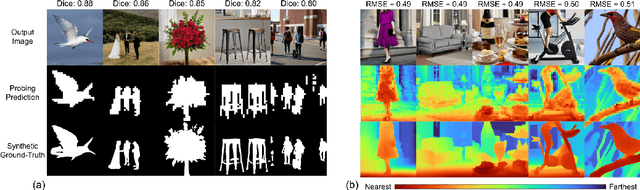
Latent diffusion models (LDMs) exhibit an impressive ability to produce realistic images, yet the inner workings of these models remain mysterious. Even when trained purely on images without explicit depth information, they typically output coherent pictures of 3D scenes. In this work, we investigate a basic interpretability question: does an LDM create and use an internal representation of simple scene geometry? Using linear probes, we find evidence that the internal activations of the LDM encode linear representations of both 3D depth data and a salient-object / background distinction. These representations appear surprisingly early in the denoising process$-$well before a human can easily make sense of the noisy images. Intervention experiments further indicate these representations play a causal role in image synthesis, and may be used for simple high-level editing of an LDM's output.
Boosting GUI Prototyping with Diffusion Models
Jun 09, 2023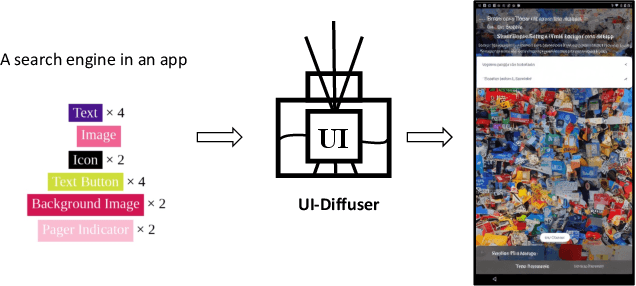
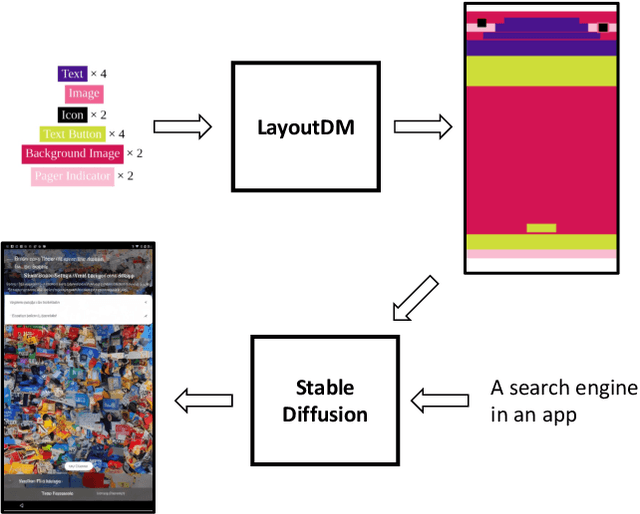
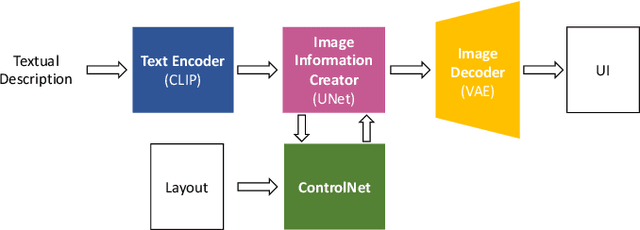
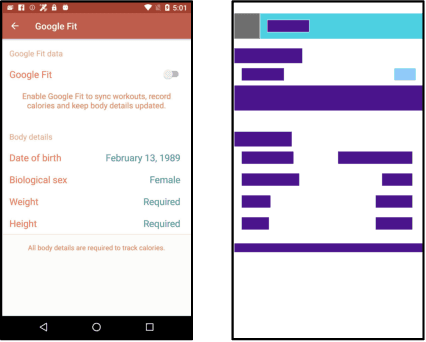
GUI (graphical user interface) prototyping is a widely-used technique in requirements engineering for gathering and refining requirements, reducing development risks and increasing stakeholder engagement. However, GUI prototyping can be a time-consuming and costly process. In recent years, deep learning models such as Stable Diffusion have emerged as a powerful text-to-image tool capable of generating detailed images based on text prompts. In this paper, we propose UI-Diffuser, an approach that leverages Stable Diffusion to generate mobile UIs through simple textual descriptions and UI components. Preliminary results show that UI-Diffuser provides an efficient and cost-effective way to generate mobile GUI designs while reducing the need for extensive prototyping efforts. This approach has the potential to significantly improve the speed and efficiency of GUI prototyping in requirements engineering.
Image-Based Virtual Try-on System With Clothing-Size Adjustment
Feb 27, 2023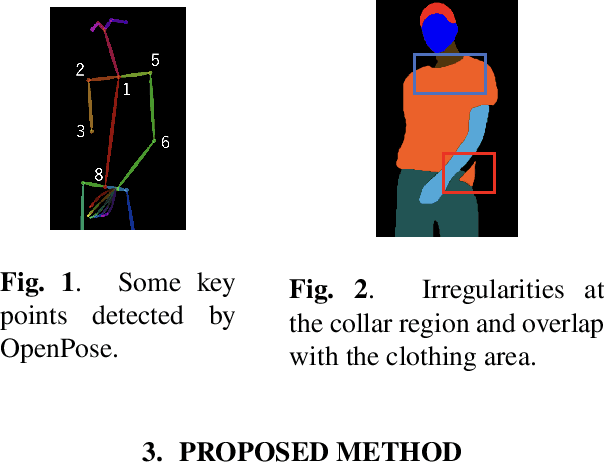
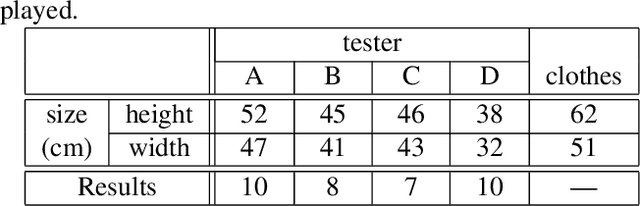
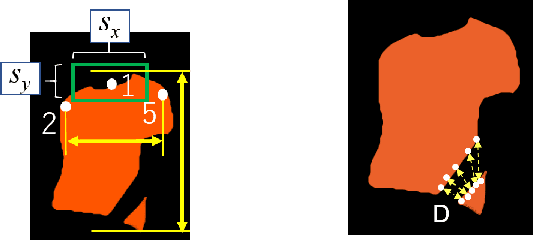
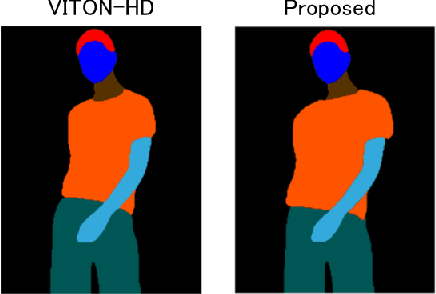
The conventional image-based virtual try-on method cannot generate fitting images that correspond to the clothing size because the system cannot accurately reflect the body information of a person. In this study, an image-based virtual try-on system that could adjust the clothing size was proposed. The size information of the person and clothing were used as the input for the proposed method to visualize the fitting of various clothing sizes in a virtual space. First, the distance between the shoulder width and height of the clothing in the person image is calculated based on the coordinate information of the key points detected by OpenPose. Then, the system changes the size of only the clothing area of the segmentation map, whose layout is estimated using the size of the person measured in the person image based on the ratio of the person and clothing sizes. If the size of the clothing area increases during the drawing, the details in the collar and overlapping areas are corrected to improve visual appearance.
The body image of social robots
Feb 07, 2023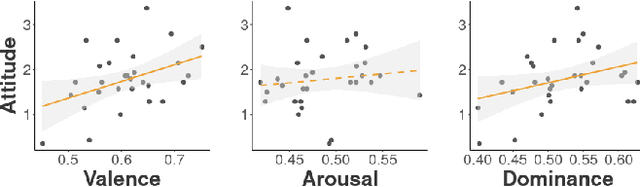
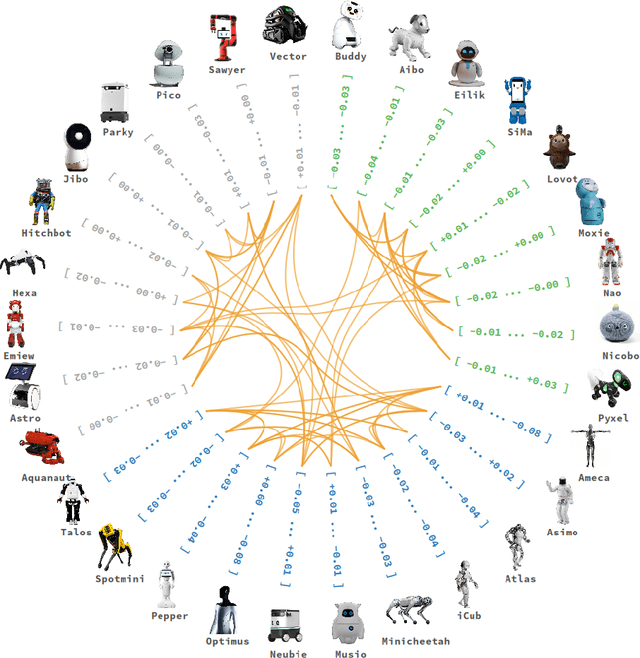
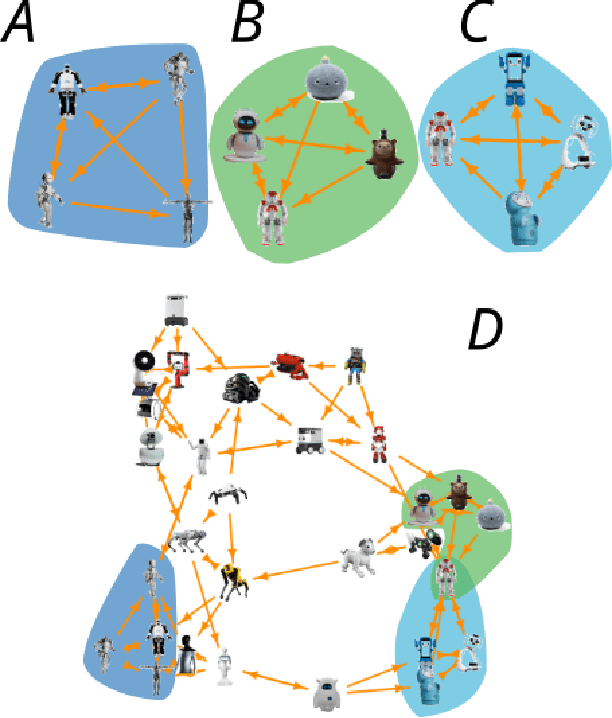
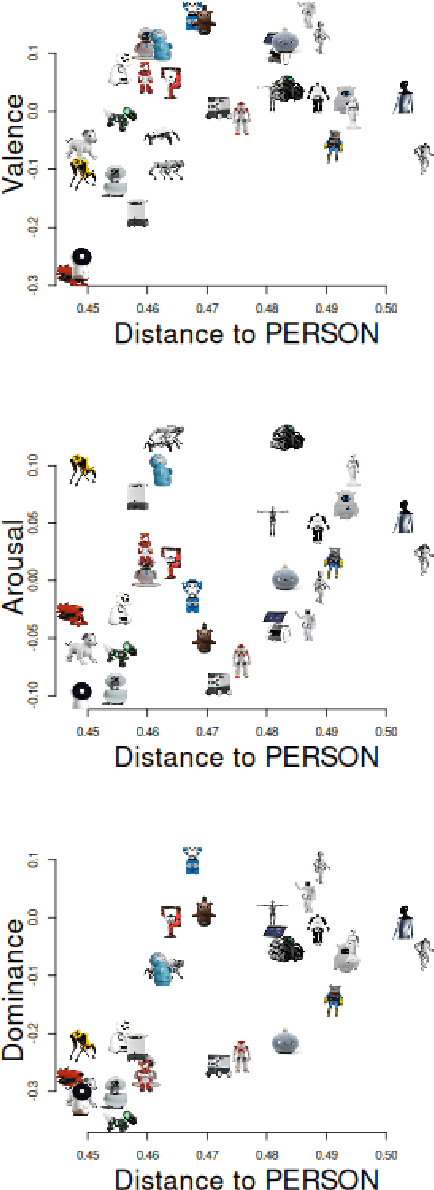
The rapid development of social robots has challenged robotics and cognitive sciences to understand humans' perception of the appearance of robots. In this study, robot-associated words spontaneously generated by humans were analyzed to semantically reveal the body image of 30 robots that have been developed over the past decades. The analyses took advantage of word affect scales and embedding vectors, and provided a series of evidence for links between human perception and body image. It was found that the valence and dominance of the body image reflected humans' attitude towards the general concept of robots; that the user bases and usages of the robots were among the primary factors influencing humans' impressions towards individual robots; and that there was a relationship between the robots' affects and semantic distances to the word ``person''. According to the results, building body image for robots was an effective paradigm to investigate which features were appreciated by people and what influenced people's feelings towards robots.
Defocus to focus: Photo-realistic bokeh rendering by fusing defocus and radiance priors
Jun 07, 2023

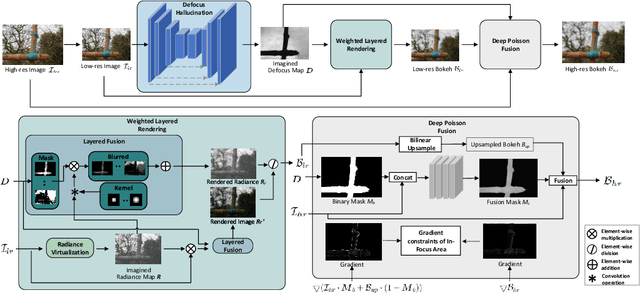
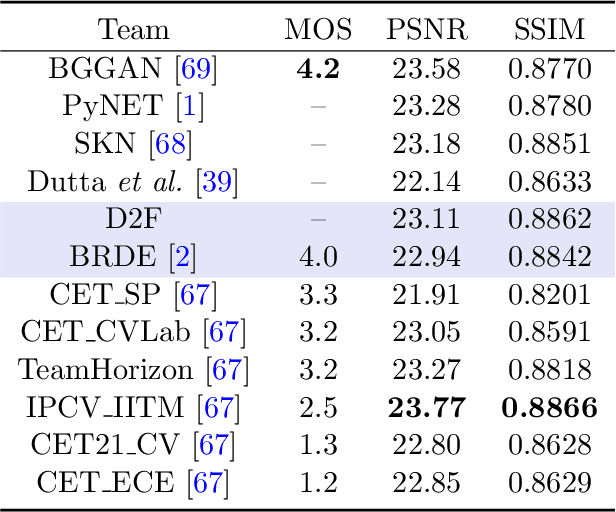
We consider the problem of realistic bokeh rendering from a single all-in-focus image. Bokeh rendering mimics aesthetic shallow depth-of-field (DoF) in professional photography, but these visual effects generated by existing methods suffer from simple flat background blur and blurred in-focus regions, giving rise to unrealistic rendered results. In this work, we argue that realistic bokeh rendering should (i) model depth relations and distinguish in-focus regions, (ii) sustain sharp in-focus regions, and (iii) render physically accurate Circle of Confusion (CoC). To this end, we present a Defocus to Focus (D2F) framework to learn realistic bokeh rendering by fusing defocus priors with the all-in-focus image and by implementing radiance priors in layered fusion. Since no depth map is provided, we introduce defocus hallucination to integrate depth by learning to focus. The predicted defocus map implies the blur amount of bokeh and is used to guide weighted layered rendering. In layered rendering, we fuse images blurred by different kernels based on the defocus map. To increase the reality of the bokeh, we adopt radiance virtualization to simulate scene radiance. The scene radiance used in weighted layered rendering reassigns weights in the soft disk kernel to produce the CoC. To ensure the sharpness of in-focus regions, we propose to fuse upsampled bokeh images and original images. We predict the initial fusion mask from our defocus map and refine the mask with a deep network. We evaluate our model on a large-scale bokeh dataset. Extensive experiments show that our approach is capable of rendering visually pleasing bokeh effects in complex scenes. In particular, our solution receives the runner-up award in the AIM 2020 Rendering Realistic Bokeh Challenge.
* Published at Information Fusion 2023 https://www.sciencedirect.com/science/article/pii/S1566253522001221
RDFC-GAN: RGB-Depth Fusion CycleGAN for Indoor Depth Completion
Jun 06, 2023
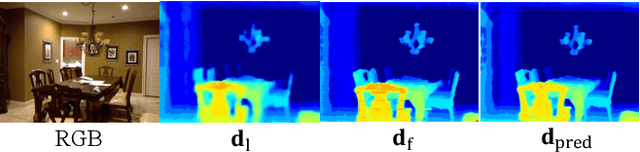

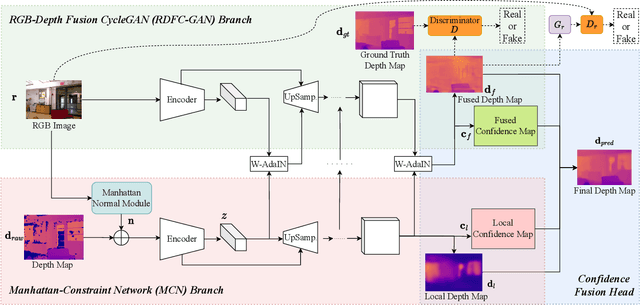
The raw depth image captured by indoor depth sensors usually has an extensive range of missing depth values due to inherent limitations such as the inability to perceive transparent objects and the limited distance range. The incomplete depth map with missing values burdens many downstream vision tasks, and a rising number of depth completion methods have been proposed to alleviate this issue. While most existing methods can generate accurate dense depth maps from sparse and uniformly sampled depth maps, they are not suitable for complementing large contiguous regions of missing depth values, which is common and critical in images captured in indoor environments. To overcome these challenges, we design a novel two-branch end-to-end fusion network named RDFC-GAN, which takes a pair of RGB and incomplete depth images as input to predict a dense and completed depth map. The first branch employs an encoder-decoder structure, by adhering to the Manhattan world assumption and utilizing normal maps from RGB-D information as guidance, to regress the local dense depth values from the raw depth map. In the other branch, we propose an RGB-depth fusion CycleGAN to transfer the RGB image to the fine-grained textured depth map. We adopt adaptive fusion modules named W-AdaIN to propagate the features across the two branches, and we append a confidence fusion head to fuse the two outputs of the branches for the final depth map. Extensive experiments on NYU-Depth V2 and SUN RGB-D demonstrate that our proposed method clearly improves the depth completion performance, especially in a more realistic setting of indoor environments, with the help of our proposed pseudo depth maps in training.
Scalable Concept Extraction in Industry 4.0
Jun 06, 2023
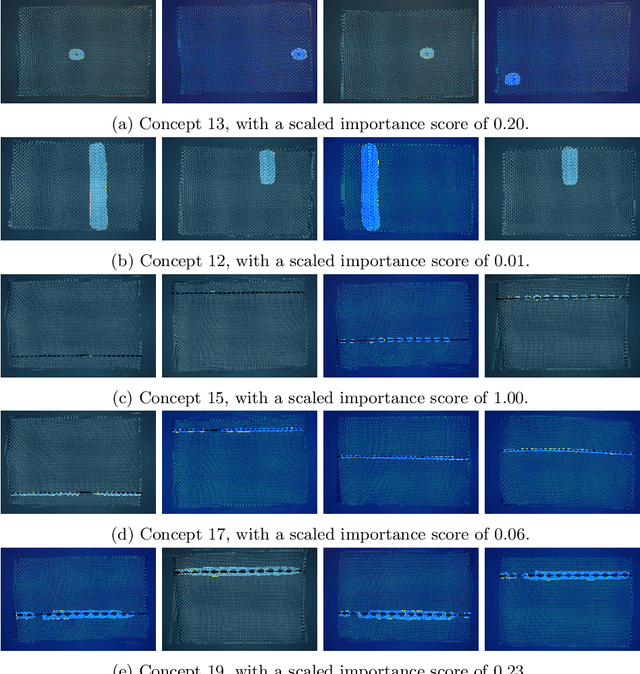

The industry 4.0 is leveraging digital technologies and machine learning techniques to connect and optimize manufacturing processes. Central to this idea is the ability to transform raw data into human understandable knowledge for reliable data-driven decision-making. Convolutional Neural Networks (CNNs) have been instrumental in processing image data, yet, their ``black box'' nature complicates the understanding of their prediction process. In this context, recent advances in the field of eXplainable Artificial Intelligence (XAI) have proposed the extraction and localization of concepts, or which visual cues intervene on the prediction process of CNNs. This paper tackles the application of concept extraction (CE) methods to industry 4.0 scenarios. To this end, we modify a recently developed technique, ``Extracting Concepts with Local Aggregated Descriptors'' (ECLAD), improving its scalability. Specifically, we propose a novel procedure for calculating concept importance, utilizing a wrapper function designed for CNNs. This process is aimed at decreasing the number of times each image needs to be evaluated. Subsequently, we demonstrate the potential of CE methods, by applying them in three industrial use cases. We selected three representative use cases in the context of quality control for material design (tailored textiles), manufacturing (carbon fiber reinforcement), and maintenance (photovoltaic module inspection). In these examples, CE was able to successfully extract and locate concepts directly related to each task. This is, the visual cues related to each concept, coincided with what human experts would use to perform the task themselves, even when the visual cues were entangled between multiple classes. Through empirical results, we show that CE can be applied for understanding CNNs in an industrial context, giving useful insights that can relate to domain knowledge.
Differentially Private Cross-camera Person Re-identification
Jun 05, 2023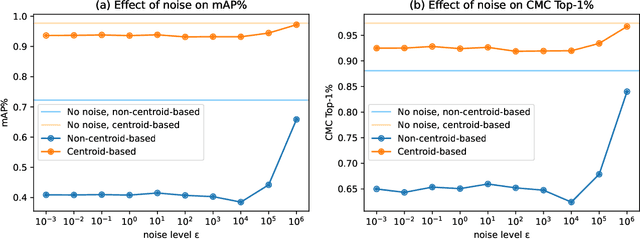
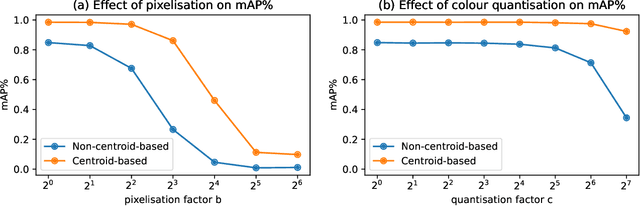
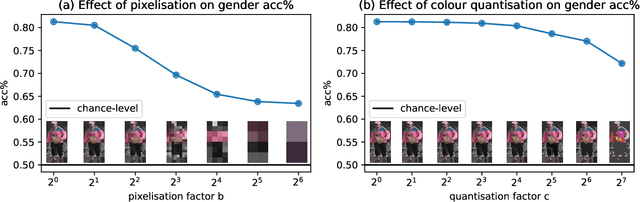
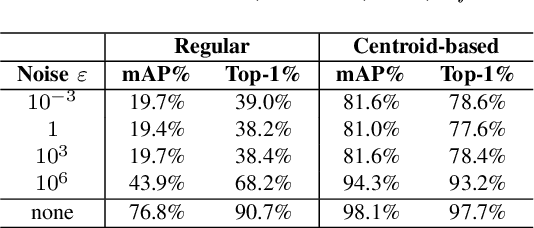
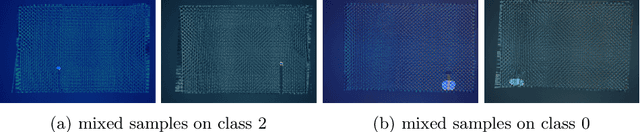
Camera-based person re-identification is a heavily privacy-invading task by design, benefiting from rich visual data to match together person representations across different cameras. This high-dimensional data can then easily be used for other, perhaps less desirable, applications. We here investigate the possibility of protecting such image data against uses outside of the intended re-identification task, and introduce a differential privacy mechanism leveraging both pixelisation and colour quantisation for this purpose. We show its ability to distort images in such a way that adverse task performances are significantly reduced, while retaining high re-identification performances.
Semantic Segmentation on VSPW Dataset through Contrastive Loss and Multi-dataset Training Approach
Jun 06, 2023
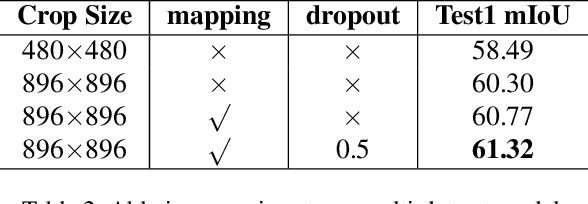
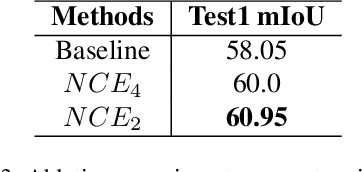
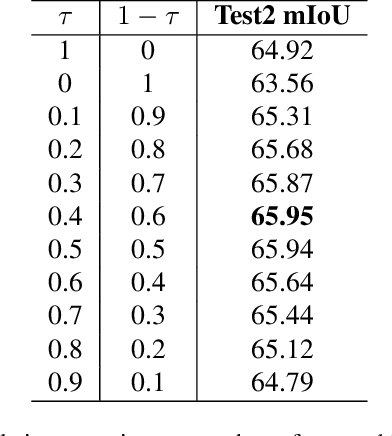
Video scene parsing incorporates temporal information, which can enhance the consistency and accuracy of predictions compared to image scene parsing. The added temporal dimension enables a more comprehensive understanding of the scene, leading to more reliable results. This paper presents the winning solution of the CVPR2023 workshop for video semantic segmentation, focusing on enhancing Spatial-Temporal correlations with contrastive loss. We also explore the influence of multi-dataset training by utilizing a label-mapping technique. And the final result is aggregating the output of the above two models. Our approach achieves 65.95% mIoU performance on the VSPW dataset, ranked 1st place on the VSPW challenge at CVPR 2023.
3rd Place Solution for PVUW2023 VSS Track: A Large Model for Semantic Segmentation on VSPW
Jun 06, 2023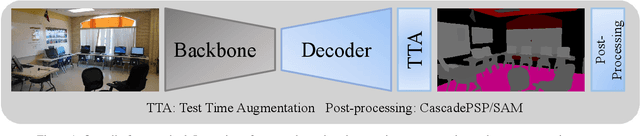
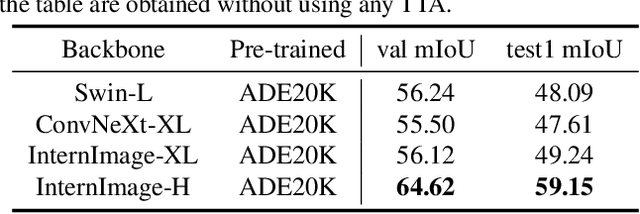


In this paper, we introduce 3rd place solution for PVUW2023 VSS track. Semantic segmentation is a fundamental task in computer vision with numerous real-world applications. We have explored various image-level visual backbones and segmentation heads to tackle the problem of video semantic segmentation. Through our experimentation, we find that InternImage-H as the backbone and Mask2former as the segmentation head achieves the best performance. In addition, we explore two post-precessing methods: CascadePSP and Segment Anything Model (SAM). Ultimately, our approach obtains 62.60\% and 64.84\% mIoU on the VSPW test set1 and final test set, respectively, securing the third position in the PVUW2023 VSS track.