 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Prompt Log Analysis of Text-to-Image Generation Systems
Mar 08, 2023
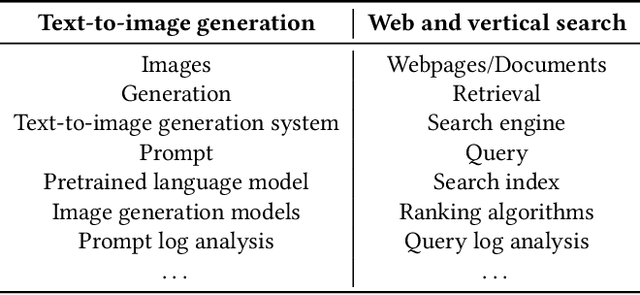
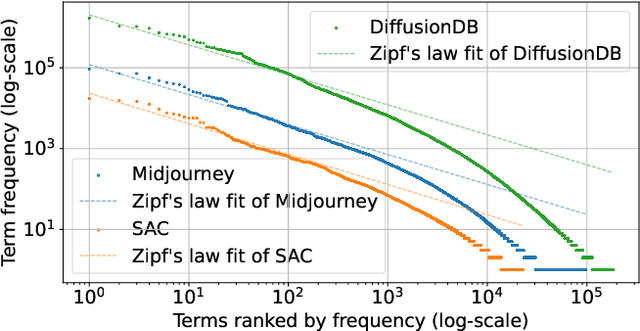
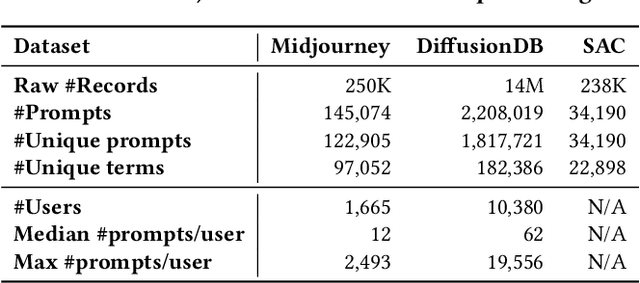
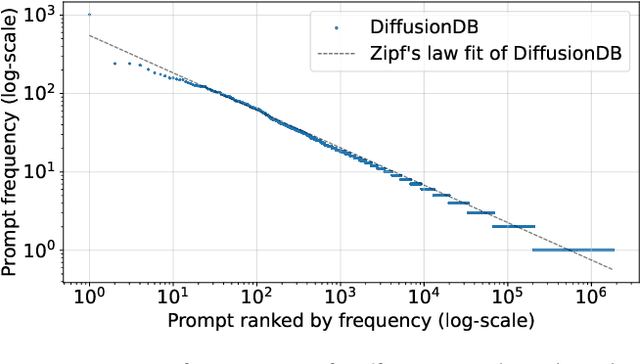
Recent developments in diffusion models have unleashed the astonishing capabilities of text-to-image generation systems to synthesize high-quality images that are faithful to a given reference text, known as a "prompt." These systems, once released to the public, have immediately received tons of attention from researchers, creators, and common users. Despite the plenty of efforts to improve the underneath generative models, there is limited work on understanding the information needs of the real users of these systems, e.g., by investigating the prompts the users input at scale. In this paper, we take the initiative to conduct a comprehensive analysis of large-scale prompt logs collected from multiple text-to-image generation systems. Our work is analogous to analyzing the query log of Web search engines, a line of work that has made critical contributions to the glory of the Web search industry and research. We analyze over two million user-input prompts submitted to three popular text-to-image systems at scale. Compared to Web search queries, text-to-image prompts are significantly longer, often organized into unique structures, and present different categories of information needs. Users tend to make more edits within creation sessions, showing remarkable exploratory patterns. Our findings provide concrete implications on how to improve text-to-image generation systems for creation purposes.
PND-Net: Physics based Non-local Dual-domain Network for Metal Artifact Reduction
May 28, 2023
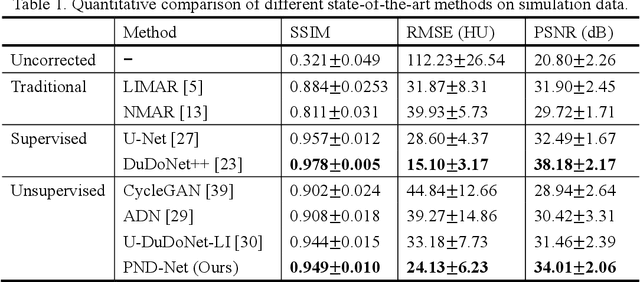
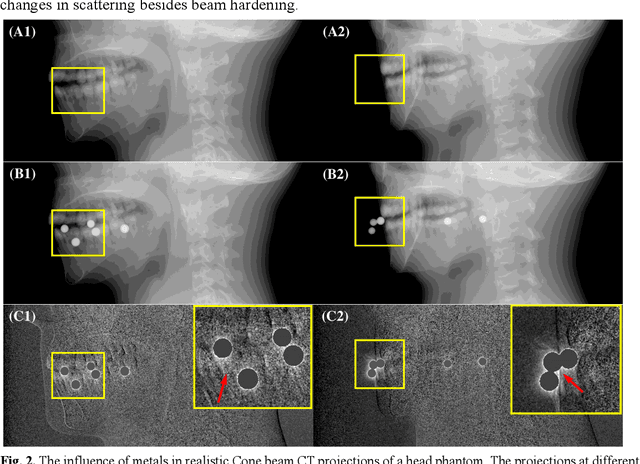
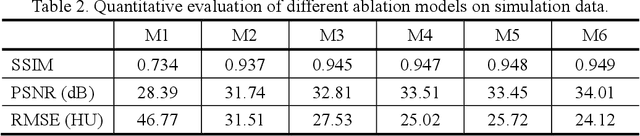
Metal artifacts caused by the presence of metallic implants tremendously degrade the reconstructed computed tomography (CT) image quality, affecting clinical diagnosis or reducing the accuracy of organ delineation and dose calculation in radiotherapy. Recently, deep learning methods in sinogram and image domains have been rapidly applied on metal artifact reduction (MAR) task. The supervised dual-domain methods perform well on synthesized data, while unsupervised methods with unpaired data are more generalized on clinical data. However, most existing methods intend to restore the corrupted sinogram within metal trace, which essentially remove beam hardening artifacts but ignore other components of metal artifacts, such as scatter, non-linear partial volume effect and noise. In this paper, we mathematically derive a physical property of metal artifacts which is verified via Monte Carlo (MC) simulation and propose a novel physics based non-local dual-domain network (PND-Net) for MAR in CT imaging. Specifically, we design a novel non-local sinogram decomposition network (NSD-Net) to acquire the weighted artifact component, and an image restoration network (IR-Net) is proposed to reduce the residual and secondary artifacts in the image domain. To facilitate the generalization and robustness of our method on clinical CT images, we employ a trainable fusion network (F-Net) in the artifact synthesis path to achieve unpaired learning. Furthermore, we design an internal consistency loss to ensure the integrity of anatomical structures in the image domain, and introduce the linear interpolation sinogram as prior knowledge to guide sinogram decomposition. Extensive experiments on simulation and clinical data demonstrate that our method outperforms the state-of-the-art MAR methods.
Object Detection with Transformers: A Review
Jun 27, 2023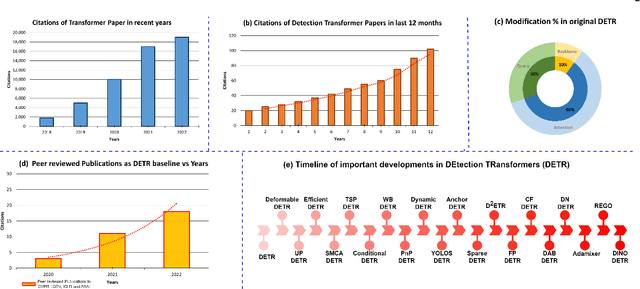
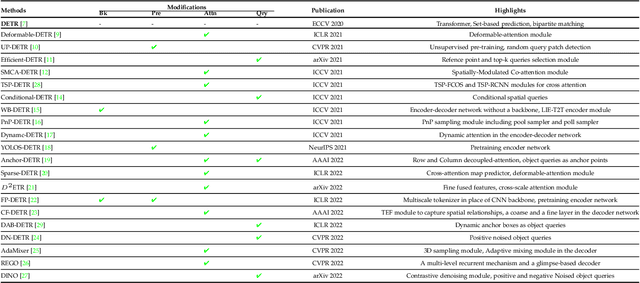
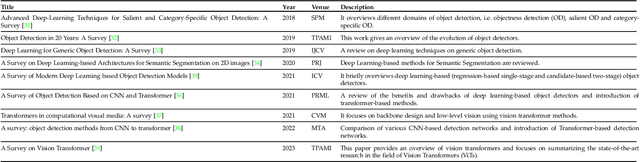
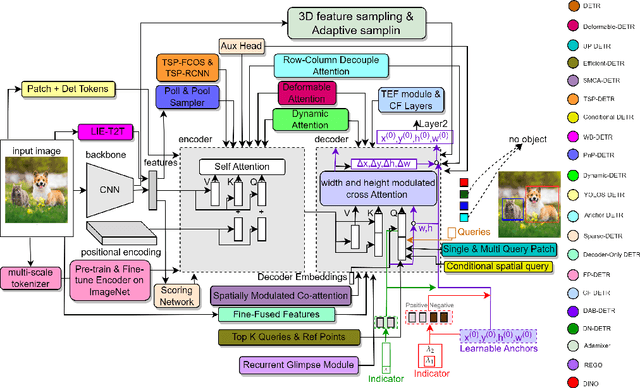
Astounding performance of Transformers in natural language processing (NLP) has delighted researchers to explore their utilization in computer vision tasks. Like other computer vision tasks, DEtection TRansformer (DETR) introduces transformers for object detection tasks by considering the detection as a set prediction problem without needing proposal generation and post-processing steps. It is a state-of-the-art (SOTA) method for object detection, particularly in scenarios where the number of objects in an image is relatively small. Despite the success of DETR, it suffers from slow training convergence and performance drops for small objects. Therefore, many improvements are proposed to address these issues, leading to immense refinement in DETR. Since 2020, transformer-based object detection has attracted increasing interest and demonstrated impressive performance. Although numerous surveys have been conducted on transformers in vision in general, a review regarding advancements made in 2D object detection using transformers is still missing. This paper gives a detailed review of twenty-one papers about recent developments in DETR. We begin with the basic modules of Transformers, such as self-attention, object queries and input features encoding. Then, we cover the latest advancements in DETR, including backbone modification, query design and attention refinement. We also compare all detection transformers in terms of performance and network design. We hope this study will increase the researcher's interest in solving existing challenges towards applying transformers in the object detection domain. Researchers can follow newer improvements in detection transformers on this webpage available at: https://github.com/mindgarage-shan/trans_object_detection_survey
Learning to Grasp Clothing Structural Regions for Garment Manipulation Tasks
Jun 26, 2023When performing cloth-related tasks, such as garment hanging, it is often important to identify and grasp certain structural regions -- a shirt's collar as opposed to its sleeve, for instance. However, due to cloth deformability, these manipulation activities, which are essential in domestic, health care, and industrial contexts, remain challenging for robots. In this paper, we focus on how to segment and grasp structural regions of clothes to enable manipulation tasks, using hanging tasks as case study. To this end, a neural network-based perception system is proposed to segment a shirt's collar from areas that represent the rest of the scene in a depth image. With a 10-minute video of a human manipulating shirts to train it, our perception system is capable of generalizing to other shirts regardless of texture as well as to other types of collared garments. A novel grasping strategy is then proposed based on the segmentation to determine grasping pose. Experiments demonstrate that our proposed grasping strategy achieves 92\%, 80\%, and 50\% grasping success rates with one folded garment, one crumpled garment and three crumpled garments, respectively. Our grasping strategy performs considerably better than tested baselines that do not take into account the structural nature of the garments. With the proposed region segmentation and grasping strategy, challenging garment hanging tasks are successfully implemented using an open-loop control policy. Supplementary material is available at https://sites.google.com/view/garment-hanging
AI Imagery and the Overton Window
Jun 02, 2023AI-based text-to-image generation has undergone a significant leap in the production of visually comprehensive and aesthetic imagery over the past year, to the point where differentiating between a man-made piece of art and an AI-generated image is becoming more difficult. Generative Models such as Stable Diffusion, Midjourney and others are expected to affect several major industries in technological and ethical aspects. Striking the balance between raising human standard of life and work vs exploiting one group of people to enrich another is a complex and crucial part of the discussion. Due to the rapid growth of this technology, the way in which its models operate, and gray area legalities, visual and artistic domains - including the video game industry, are at risk of being taken over from creators by AI infrastructure owners. This paper is a literature review examining the concerns facing both AI developers and users today, including identity theft, data laundering and more. It discusses legalization challenges and ethical concerns, and concludes with how AI generative models can be tremendously useful in streamlining the process of visual creativity in both static and interactive media given proper regulation. Keywords: AI text-to-image generation, Midjourney, Stable Diffusion, AI Ethics, Game Design, Digital Art, Data Laundering
TransMRSR: Transformer-based Self-Distilled Generative Prior for Brain MRI Super-Resolution
Jun 11, 2023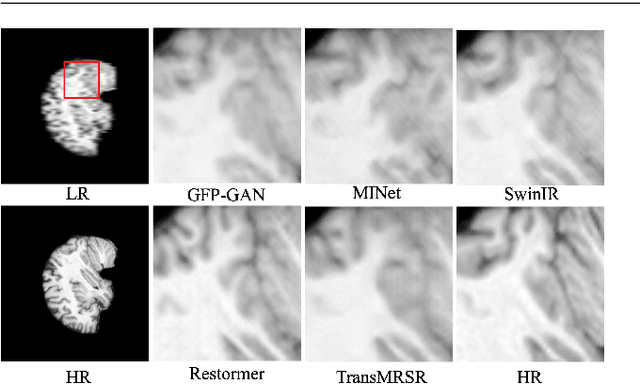
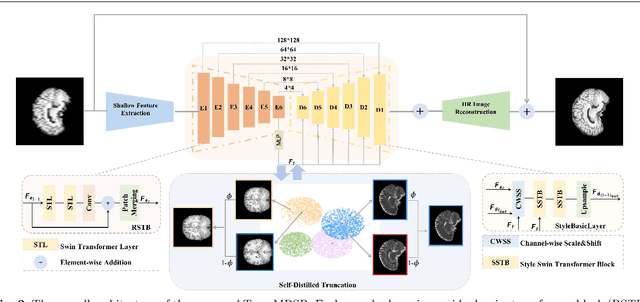
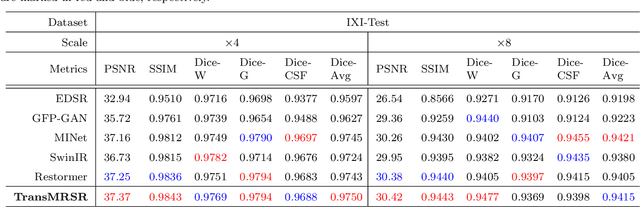
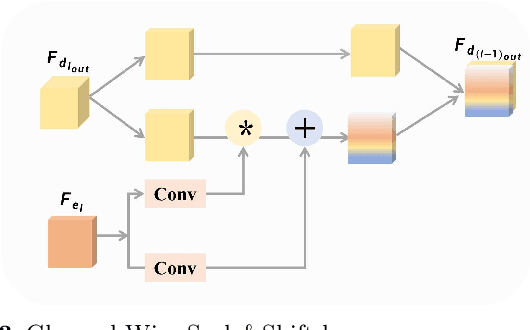
Magnetic resonance images (MRI) acquired with low through-plane resolution compromise time and cost. The poor resolution in one orientation is insufficient to meet the requirement of high resolution for early diagnosis of brain disease and morphometric study. The common Single image super-resolution (SISR) solutions face two main challenges: (1) local detailed and global anatomical structural information combination; and (2) large-scale restoration when applied for reconstructing thick-slice MRI into high-resolution (HR) iso-tropic data. To address these problems, we propose a novel two-stage network for brain MRI SR named TransMRSR based on the convolutional blocks to extract local information and transformer blocks to capture long-range dependencies. TransMRSR consists of three modules: the shallow local feature extraction, the deep non-local feature capture, and the HR image reconstruction. We perform a generative task to encapsulate diverse priors into a generative network (GAN), which is the decoder sub-module of the deep non-local feature capture part, in the first stage. The pre-trained GAN is used for the second stage of SR task. We further eliminate the potential latent space shift caused by the two-stage training strategy through the self-distilled truncation trick. The extensive experiments show that our method achieves superior performance to other SSIR methods on both public and private datasets. Code is released at https://github.com/goddesshs/TransMRSR.git .
Deep Single Image Camera Calibration by Heatmap Regression to Recover Fisheye Images Under ManhattanWorld AssumptionWithout Ambiguity
Mar 30, 2023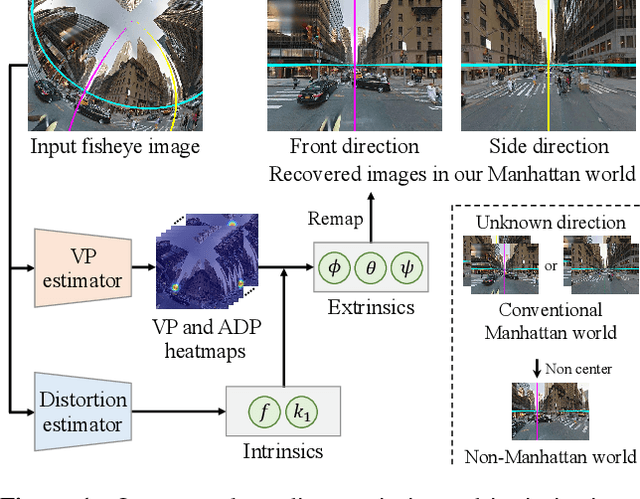
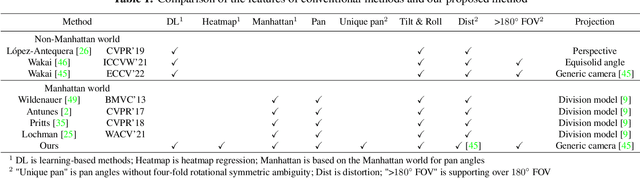
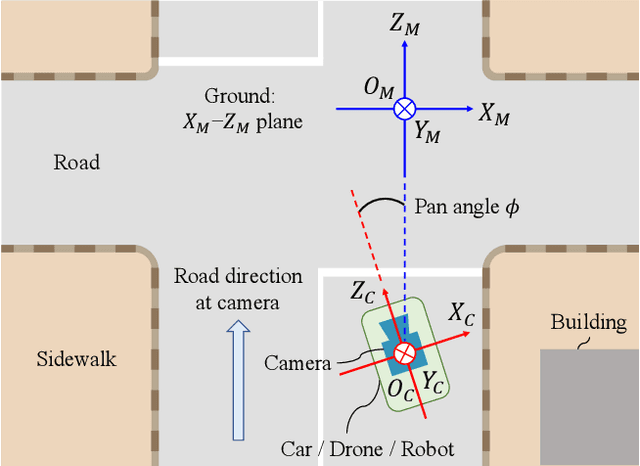
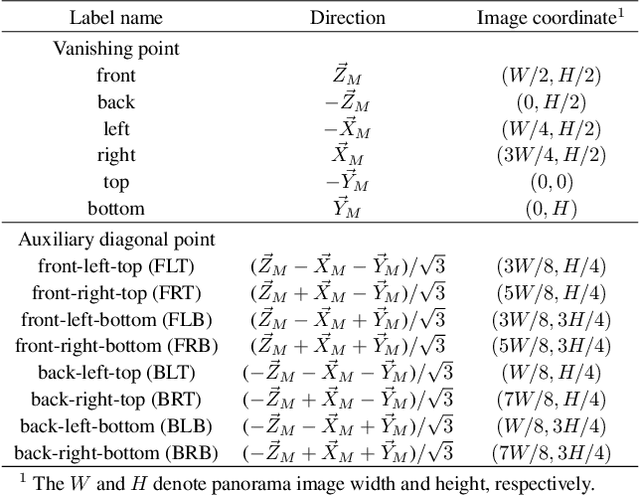
In orthogonal world coordinates, a Manhattan world lying along cuboid buildings is widely useful for various computer vision tasks. However, the Manhattan world has much room for improvement because the origin of pan angles from an image is arbitrary, that is, four-fold rotational symmetric ambiguity of pan angles. To address this problem, we propose a definition for the pan-angle origin based on the directions of the roads with respect to a camera and the direction of travel. We propose a learning-based calibration method that uses heatmap regression to remove the ambiguity by each direction of labeled image coordinates, similar to pose estimation keypoints. Simultaneously, our two-branched network recovers the rotation and removes fisheye distortion from a general scene image. To alleviate the lack of vanishing points in images, we introduce auxiliary diagonal points that have the optimal 3D arrangement of spatial uniformity. Extensive experiments demonstrated that our method outperforms conventional methods on large-scale datasets and with off-the-shelf cameras.
Fashion Image Retrieval with Multi-Granular Alignment
Feb 22, 2023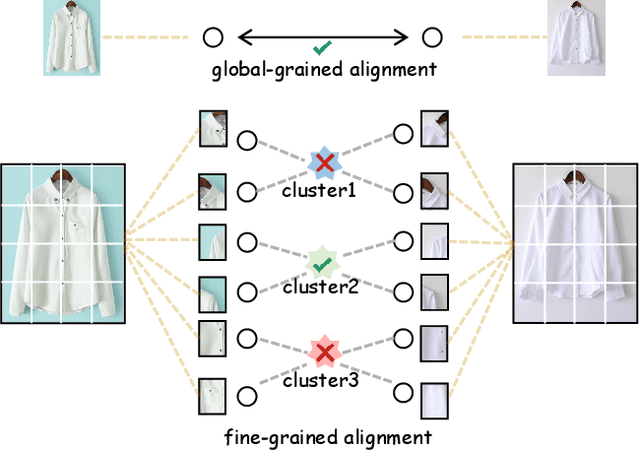
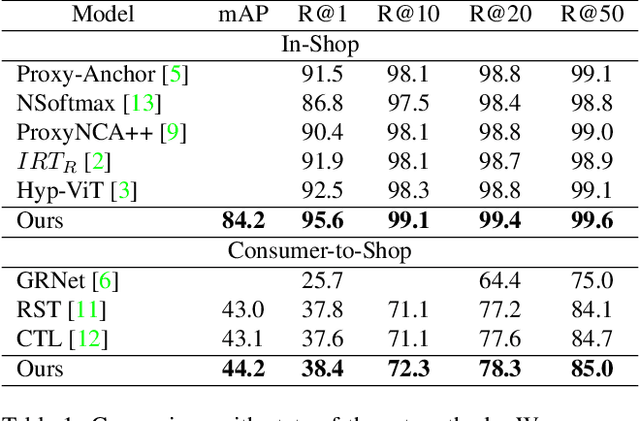
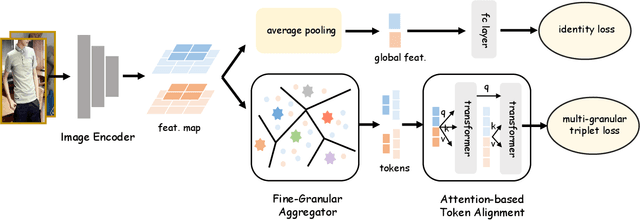

Fashion image retrieval task aims to search relevant clothing items of a query image from the gallery. The previous recipes focus on designing different distance-based loss functions, pulling relevant pairs to be close and pushing irrelevant images apart. However, these methods ignore fine-grained features (e.g. neckband, cuff) of clothing images. In this paper, we propose a novel fashion image retrieval method leveraging both global and fine-grained features, dubbed Multi-Granular Alignment (MGA). Specifically, we design a Fine-Granular Aggregator(FGA) to capture and aggregate detailed patterns. Then we propose Attention-based Token Alignment (ATA) to align image features at the multi-granular level in a coarse-to-fine manner. To prove the effectiveness of our proposed method, we conduct experiments on two sub-tasks (In-Shop & Consumer2Shop) of the public fashion datasets DeepFashion. The experimental results show that our MGA outperforms the state-of-the-art methods by 3.1% and 0.6% in the two sub-tasks on the R@1 metric, respectively.
MeMaHand: Exploiting Mesh-Mano Interaction for Single Image Two-Hand Reconstruction
Mar 28, 2023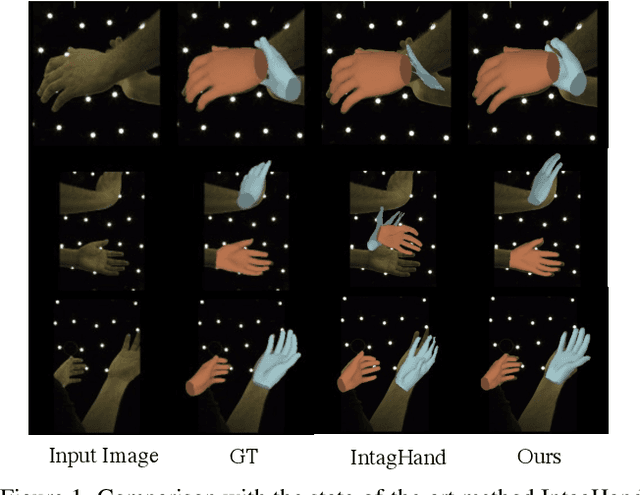
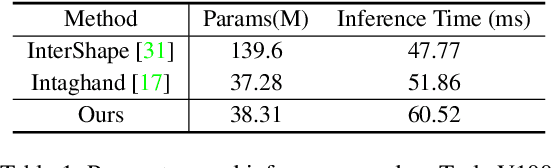
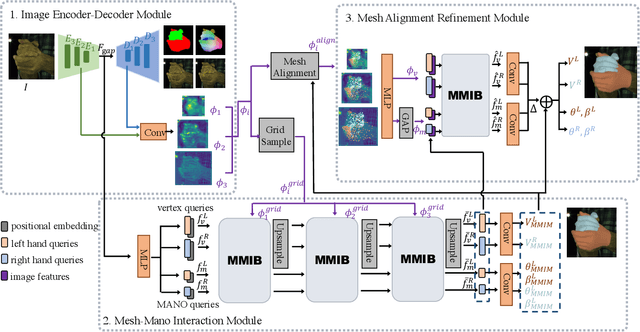
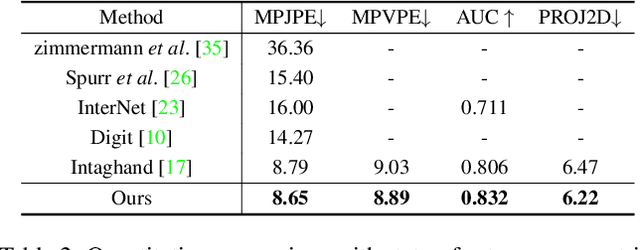
Existing methods proposed for hand reconstruction tasks usually parameterize a generic 3D hand model or predict hand mesh positions directly. The parametric representations consisting of hand shapes and rotational poses are more stable, while the non-parametric methods can predict more accurate mesh positions. In this paper, we propose to reconstruct meshes and estimate MANO parameters of two hands from a single RGB image simultaneously to utilize the merits of two kinds of hand representations. To fulfill this target, we propose novel Mesh-Mano interaction blocks (MMIBs), which take mesh vertices positions and MANO parameters as two kinds of query tokens. MMIB consists of one graph residual block to aggregate local information and two transformer encoders to model long-range dependencies. The transformer encoders are equipped with different asymmetric attention masks to model the intra-hand and inter-hand attention, respectively. Moreover, we introduce the mesh alignment refinement module to further enhance the mesh-image alignment. Extensive experiments on the InterHand2.6M benchmark demonstrate promising results over the state-of-the-art hand reconstruction methods.
Implicit Neural Representation for Cooperative Low-light Image Enhancement
Mar 21, 2023
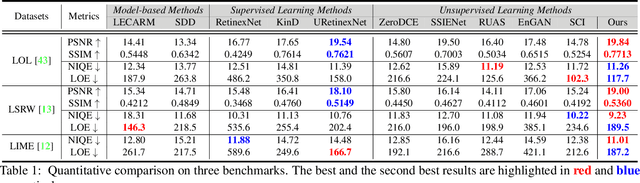
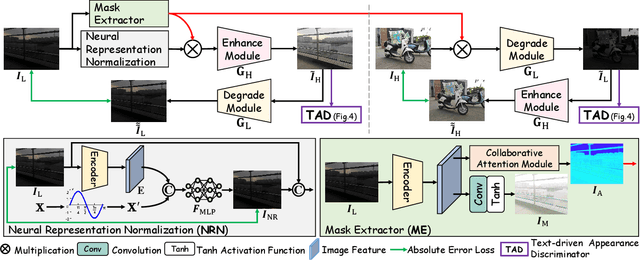
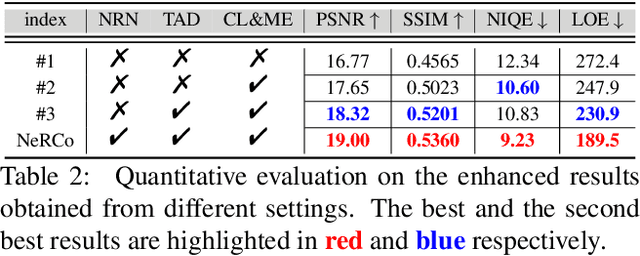
The following three factors restrict the application of existing low-light image enhancement methods: unpredictable brightness degradation and noise, inherent gap between metric-favorable and visual-friendly versions, and the limited paired training data. To address these limitations, we propose an implicit Neural Representation method for Cooperative low-light image enhancement, dubbed NeRCo. It robustly recovers perceptual-friendly results in an unsupervised manner. Concretely, NeRCo unifies the diverse degradation factors of real-world scenes with a controllable fitting function, leading to better robustness. In addition, for the output results, we introduce semantic-orientated supervision with priors from the pre-trained vision-language model. Instead of merely following reference images, it encourages results to meet subjective expectations, finding more visual-friendly solutions. Further, to ease the reliance on paired data and reduce solution space, we develop a dual-closed-loop constrained enhancement module. It is trained cooperatively with other affiliated modules in a self-supervised manner. Finally, extensive experiments demonstrate the robustness and superior effectiveness of our proposed NeRCo. Our code is available at https://github.com/Ysz2022/NeRCo.