 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Asymmetric Patch Sampling for Contrastive Learning
Jun 05, 2023
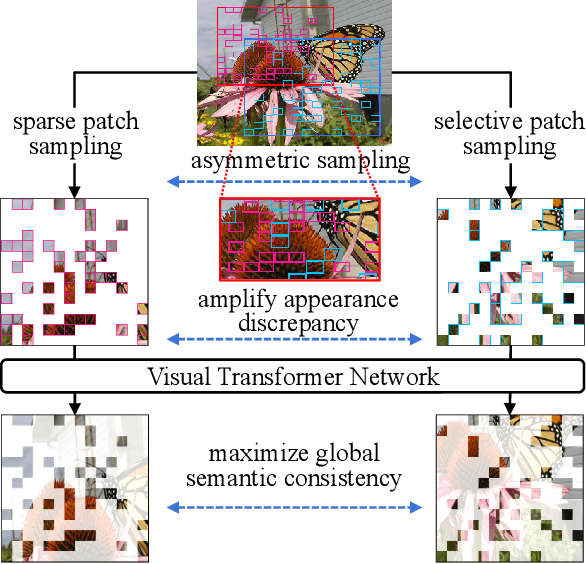
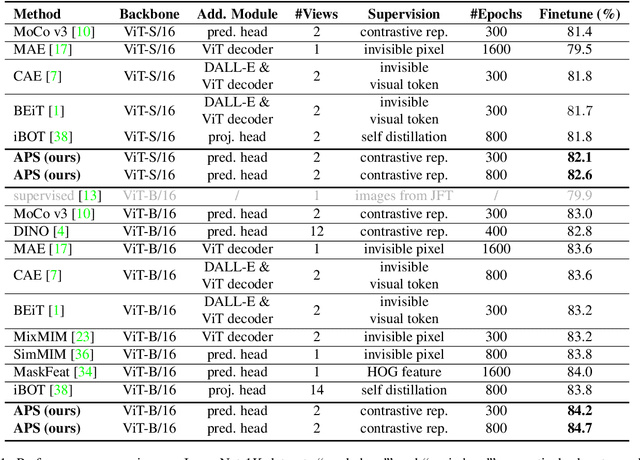
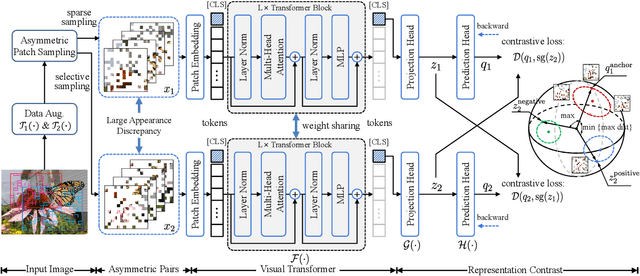
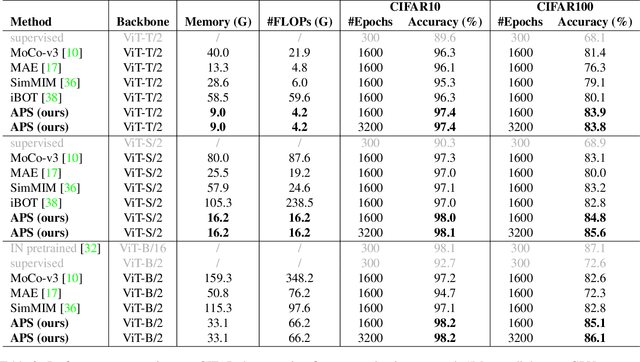
Asymmetric appearance between positive pair effectively reduces the risk of representation degradation in contrastive learning. However, there are still a mass of appearance similarities between positive pair constructed by the existing methods, which inhibits the further representation improvement. In this paper, we propose a novel asymmetric patch sampling strategy for contrastive learning, to further boost the appearance asymmetry for better representations. Specifically, dual patch sampling strategies are applied to the given image, to obtain asymmetric positive pairs. First, sparse patch sampling is conducted to obtain the first view, which reduces spatial redundancy of image and allows a more asymmetric view. Second, a selective patch sampling is proposed to construct another view with large appearance discrepancy relative to the first one. Due to the inappreciable appearance similarity between positive pair, the trained model is encouraged to capture the similarity on semantics, instead of low-level ones. Experimental results demonstrate that our proposed method significantly outperforms the existing self-supervised methods on both ImageNet-1K and CIFAR dataset, e.g., 2.5% finetune accuracy improvement on CIFAR100. Furthermore, our method achieves state-of-the-art performance on downstream tasks, object detection and instance segmentation on COCO.Additionally, compared to other self-supervised methods, our method is more efficient on both memory and computation during training. The source code is available at https://github.com/visresearch/aps.
Boosting Breast Ultrasound Video Classification by the Guidance of Keyframe Feature Centers
Jun 12, 2023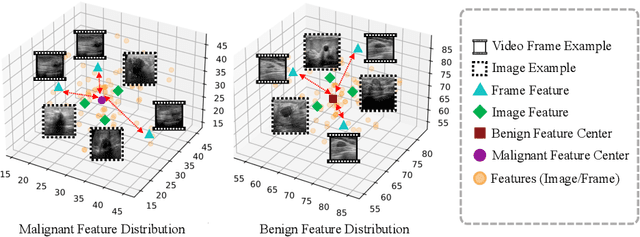
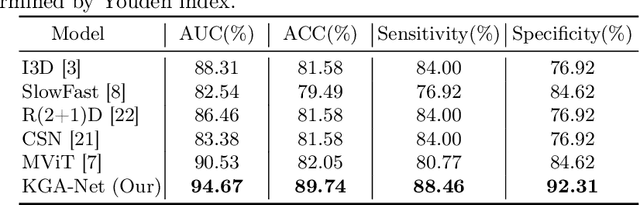
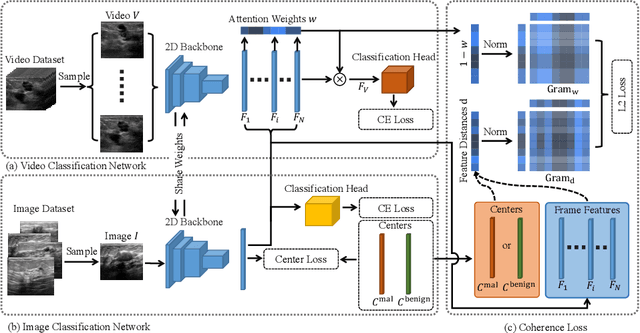
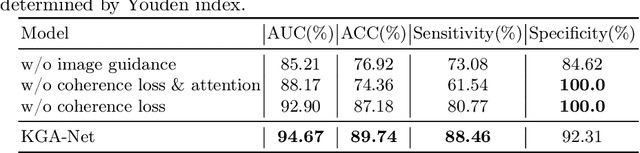
Breast ultrasound videos contain richer information than ultrasound images, therefore it is more meaningful to develop video models for this diagnosis task. However, the collection of ultrasound video datasets is much harder. In this paper, we explore the feasibility of enhancing the performance of ultrasound video classification using the static image dataset. To this end, we propose KGA-Net and coherence loss. The KGA-Net adopts both video clips and static images to train the network. The coherence loss uses the feature centers generated by the static images to guide the frame attention in the video model. Our KGA-Net boosts the performance on the public BUSV dataset by a large margin. The visualization results of frame attention prove the explainability of our method. The codes and model weights of our method will be made publicly available.
Slot-VAE: Object-Centric Scene Generation with Slot Attention
Jun 12, 2023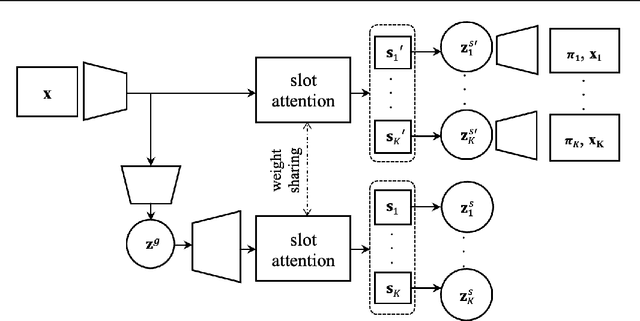

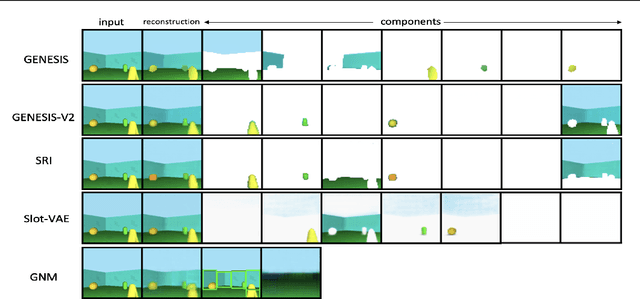

Slot attention has shown remarkable object-centric representation learning performance in computer vision tasks without requiring any supervision. Despite its object-centric binding ability brought by compositional modelling, as a deterministic module, slot attention lacks the ability to generate novel scenes. In this paper, we propose the Slot-VAE, a generative model that integrates slot attention with the hierarchical VAE framework for object-centric structured scene generation. For each image, the model simultaneously infers a global scene representation to capture high-level scene structure and object-centric slot representations to embed individual object components. During generation, slot representations are generated from the global scene representation to ensure coherent scene structures. Our extensive evaluation of the scene generation ability indicates that Slot-VAE outperforms slot representation-based generative baselines in terms of sample quality and scene structure accuracy.
DreamHuman: Animatable 3D Avatars from Text
Jun 15, 2023


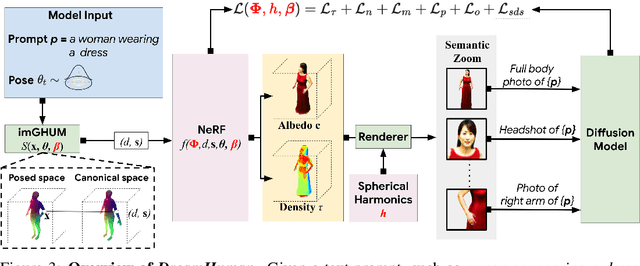
We present DreamHuman, a method to generate realistic animatable 3D human avatar models solely from textual descriptions. Recent text-to-3D methods have made considerable strides in generation, but are still lacking in important aspects. Control and often spatial resolution remain limited, existing methods produce fixed rather than animated 3D human models, and anthropometric consistency for complex structures like people remains a challenge. DreamHuman connects large text-to-image synthesis models, neural radiance fields, and statistical human body models in a novel modeling and optimization framework. This makes it possible to generate dynamic 3D human avatars with high-quality textures and learned, instance-specific, surface deformations. We demonstrate that our method is capable to generate a wide variety of animatable, realistic 3D human models from text. Our 3D models have diverse appearance, clothing, skin tones and body shapes, and significantly outperform both generic text-to-3D approaches and previous text-based 3D avatar generators in visual fidelity. For more results and animations please check our website at https://dream-human.github.io.
Motion Perceiver: Real-Time Occupancy Forecasting for Embedded Systems
Jun 15, 2023
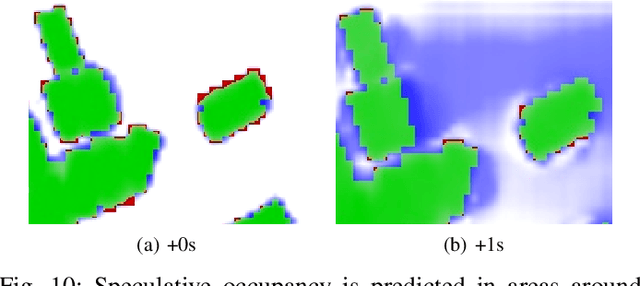
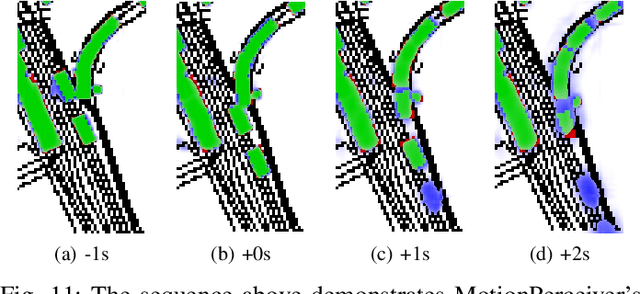
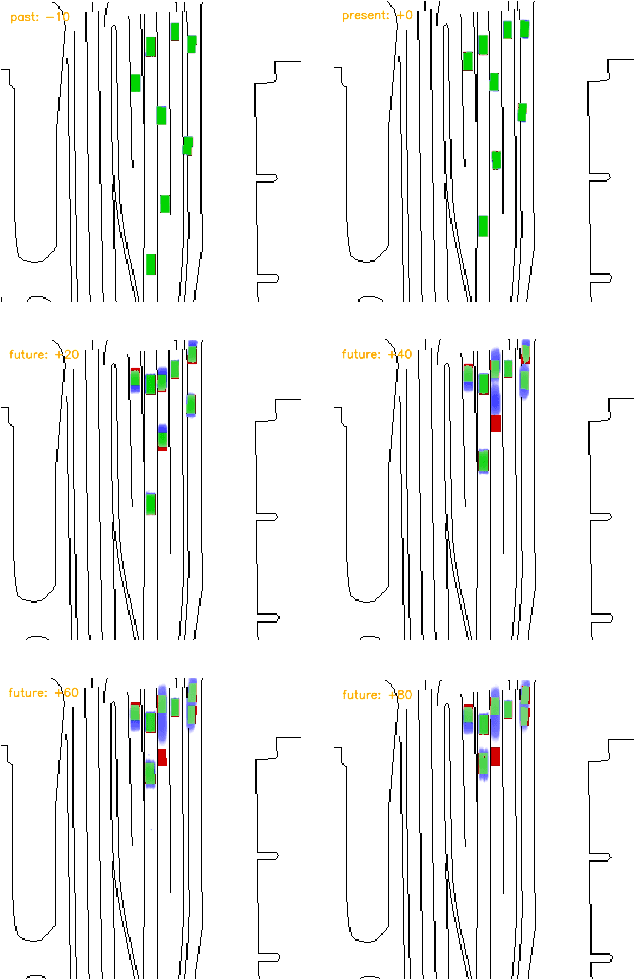
This work introduces a flexible architecture for real-time occupancy forecasting. In contrast to existing, more computationally expensive architectures, the proposed model exploits recursive latent state estimation, using learned transformer-based prediction and update modules. This allows for highly efficient real-time inference on an embedded system (profiled on an Nvidia Xavier AGX), and the inclusion of a broad set of information from a diverse set of sensors. The architecture is able to process sparse and occluded observations of agent positions and scene context as this is made available, and does not require motion tracklet inputs. \networkName{} accomplishes this by encoding the scene into a latent state that evolves in time with self-attention and is updated with contextual information such as traffic signals, road topology or agent detections using cross-attention. Occupancy predictions are made by sparsely querying positions of interest as opposed to generating a fixed size raster image, which allows for variable resolution occupancy prediction or local querying by downstream trajectory optimisation algorithms, saving computational effort.
Winning Solution for the CVPR2023 Visual Anomaly and Novelty Detection Challenge: Multimodal Prompting for Data-centric Anomaly Detection
Jun 15, 2023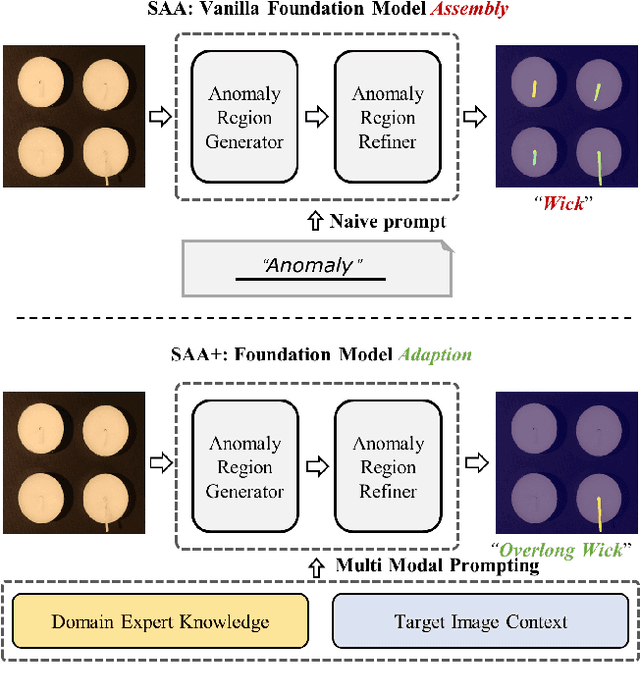

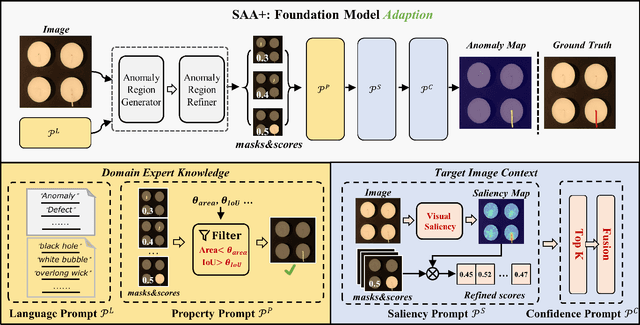

This technical report introduces the winning solution of the team \textit{Segment Any Anomaly} for the CVPR2023 Visual Anomaly and Novelty Detection (VAND) challenge. Going beyond uni-modal prompt, \textit{e.g.}, language prompt, we present a novel framework, \textit{i.e.}, Segment Any Anomaly + (SAA$+$), for zero-shot anomaly segmentation with multi-modal prompts for the regularization of cascaded modern foundation models. Inspired by the great zero-shot generalization ability of foundation models like Segment Anything, we first explore their assembly (SAA) to leverage diverse multi-modal prior knowledge for anomaly localization. Subsequently, we further introduce multimodal prompts (SAA$+$) derived from domain expert knowledge and target image context to enable the non-parameter adaptation of foundation models to anomaly segmentation. The proposed SAA$+$ model achieves state-of-the-art performance on several anomaly segmentation benchmarks, including VisA and MVTec-AD, in the zero-shot setting. We will release the code of our winning solution for the CVPR2023 VAND challenge at \href{Segment-Any-Anomaly}{https://github.com/caoyunkang/Segment-Any-Anomaly} \footnote{The extended-version paper with more details is available at ~\cite{cao2023segment}.}
Language Aligned Visual Representations Predict Human Behavior in Naturalistic Learning Tasks
Jun 15, 2023Humans possess the ability to identify and generalize relevant features of natural objects, which aids them in various situations. To investigate this phenomenon and determine the most effective representations for predicting human behavior, we conducted two experiments involving category learning and reward learning. Our experiments used realistic images as stimuli, and participants were tasked with making accurate decisions based on novel stimuli for all trials, thereby necessitating generalization. In both tasks, the underlying rules were generated as simple linear functions using stimulus dimensions extracted from human similarity judgments. Notably, participants successfully identified the relevant stimulus features within a few trials, demonstrating effective generalization. We performed an extensive model comparison, evaluating the trial-by-trial predictive accuracy of diverse deep learning models' representations of human choices. Intriguingly, representations from models trained on both text and image data consistently outperformed models trained solely on images, even surpassing models using the features that generated the task itself. These findings suggest that language-aligned visual representations possess sufficient richness to describe human generalization in naturalistic settings and emphasize the role of language in shaping human cognition.
Region-Aware Diffusion for Zero-shot Text-driven Image Editing
Feb 23, 2023

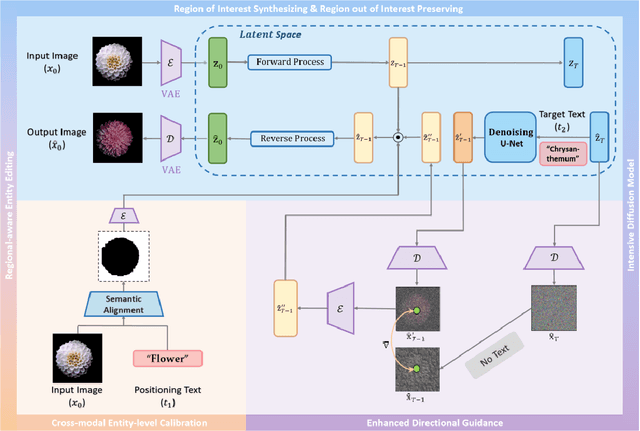

Image manipulation under the guidance of textual descriptions has recently received a broad range of attention. In this study, we focus on the regional editing of images with the guidance of given text prompts. Different from current mask-based image editing methods, we propose a novel region-aware diffusion model (RDM) for entity-level image editing, which could automatically locate the region of interest and replace it following given text prompts. To strike a balance between image fidelity and inference speed, we design the intensive diffusion pipeline by combing latent space diffusion and enhanced directional guidance. In addition, to preserve image content in non-edited regions, we introduce regional-aware entity editing to modify the region of interest and preserve the out-of-interest region. We validate the proposed RDM beyond the baseline methods through extensive qualitative and quantitative experiments. The results show that RDM outperforms the previous approaches in terms of visual quality, overall harmonization, non-editing region content preservation, and text-image semantic consistency. The codes are available at https://github.com/haha-lisa/RDM-Region-Aware-Diffusion-Model.
PV2TEA: Patching Visual Modality to Textual-Established Information Extraction
Jun 01, 2023

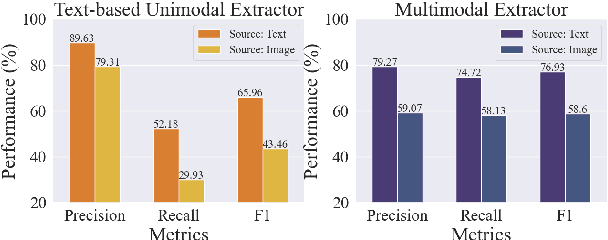
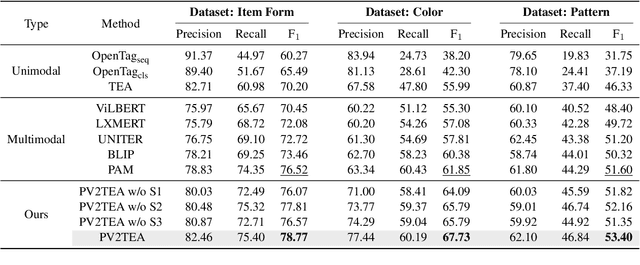
Information extraction, e.g., attribute value extraction, has been extensively studied and formulated based only on text. However, many attributes can benefit from image-based extraction, like color, shape, pattern, among others. The visual modality has long been underutilized, mainly due to multimodal annotation difficulty. In this paper, we aim to patch the visual modality to the textual-established attribute information extractor. The cross-modality integration faces several unique challenges: (C1) images and textual descriptions are loosely paired intra-sample and inter-samples; (C2) images usually contain rich backgrounds that can mislead the prediction; (C3) weakly supervised labels from textual-established extractors are biased for multimodal training. We present PV2TEA, an encoder-decoder architecture equipped with three bias reduction schemes: (S1) Augmented label-smoothed contrast to improve the cross-modality alignment for loosely-paired image and text; (S2) Attention-pruning that adaptively distinguishes the visual foreground; (S3) Two-level neighborhood regularization that mitigates the label textual bias via reliability estimation. Empirical results on real-world e-Commerce datasets demonstrate up to 11.74% absolute (20.97% relatively) F1 increase over unimodal baselines.
Xformer: Hybrid X-Shaped Transformer for Image Denoising
Mar 11, 2023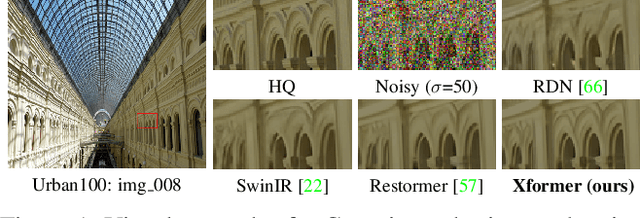
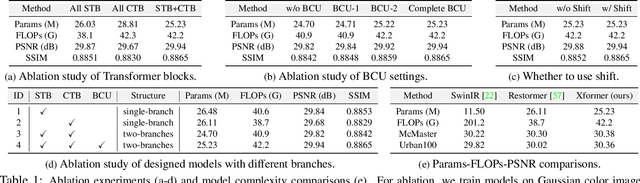
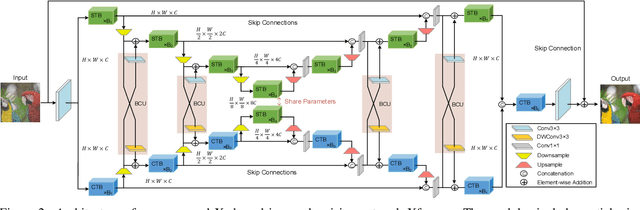
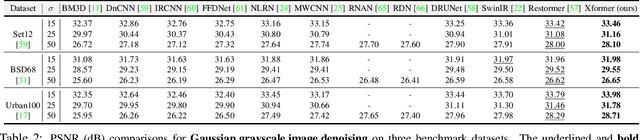
In this paper, we present a hybrid X-shaped vision Transformer, named Xformer, which performs notably on image denoising tasks. We explore strengthening the global representation of tokens from different scopes. In detail, we adopt two types of Transformer blocks. The spatial-wise Transformer block performs fine-grained local patches interactions across tokens defined by spatial dimension. The channel-wise Transformer block performs direct global context interactions across tokens defined by channel dimension. Based on the concurrent network structure, we design two branches to conduct these two interaction fashions. Within each branch, we employ an encoder-decoder architecture to capture multi-scale features. Besides, we propose the Bidirectional Connection Unit (BCU) to couple the learned representations from these two branches while providing enhanced information fusion. The joint designs make our Xformer powerful to conduct global information modeling in both spatial and channel dimensions. Extensive experiments show that Xformer, under the comparable model complexity, achieves state-of-the-art performance on the synthetic and real-world image denoising tasks.