 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Aligning Text-to-Image Models using Human Feedback
Feb 23, 2023
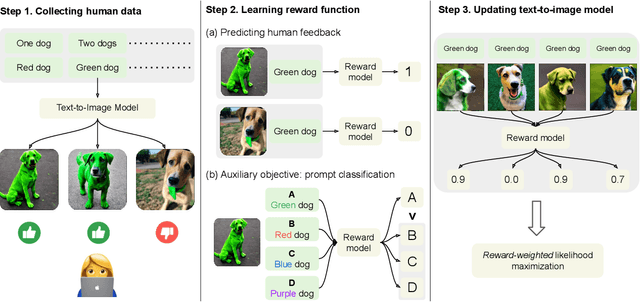

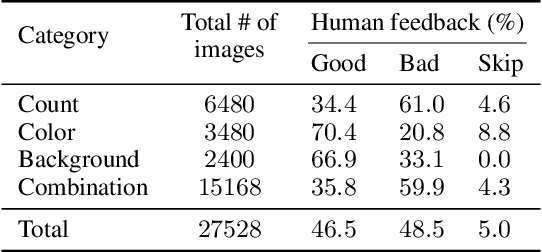

Deep generative models have shown impressive results in text-to-image synthesis. However, current text-to-image models often generate images that are inadequately aligned with text prompts. We propose a fine-tuning method for aligning such models using human feedback, comprising three stages. First, we collect human feedback assessing model output alignment from a set of diverse text prompts. We then use the human-labeled image-text dataset to train a reward function that predicts human feedback. Lastly, the text-to-image model is fine-tuned by maximizing reward-weighted likelihood to improve image-text alignment. Our method generates objects with specified colors, counts and backgrounds more accurately than the pre-trained model. We also analyze several design choices and find that careful investigations on such design choices are important in balancing the alignment-fidelity tradeoffs. Our results demonstrate the potential for learning from human feedback to significantly improve text-to-image models.
A Comprehensive Review of Image Line Segment Detection and Description: Taxonomies, Comparisons, and Challenges
Apr 29, 2023

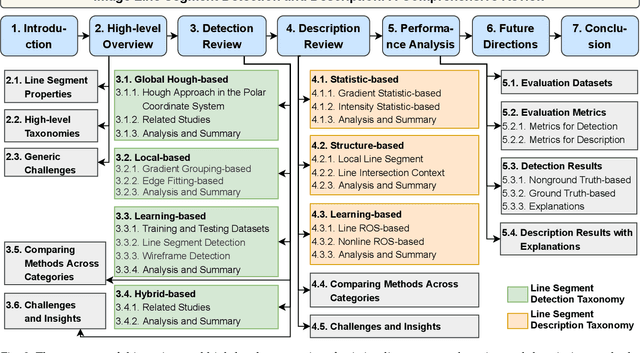
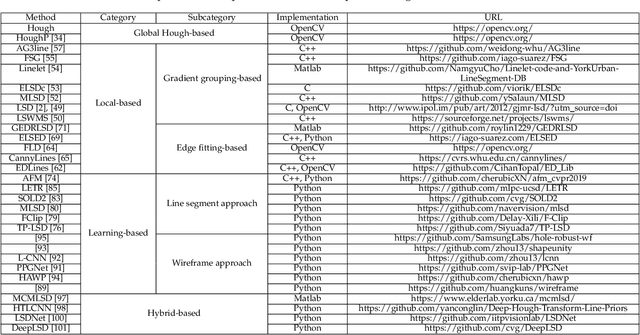
Detection and description of line segments lay the basis for numerous vision tasks. Although many studies have aimed to detect and describe line segments, a comprehensive review is lacking, obstructing their progress. This study fills the gap by comprehensively reviewing related studies on detecting and describing two-dimensional image line segments to provide researchers with an overall picture and deep understanding. Based on their mechanisms, two taxonomies for line segment detection and description are presented to introduce, analyze, and summarize these studies, facilitating researchers to learn about them quickly and extensively. The key issues, core ideas, advantages and disadvantages of existing methods, and their potential applications for each category are analyzed and summarized, including previously unknown findings. The challenges in existing methods and corresponding insights for potentially solving them are also provided to inspire researchers. In addition, some state-of-the-art line segment detection and description algorithms are evaluated without bias, and the evaluation code will be publicly available. The theoretical analysis, coupled with the experimental results, can guide researchers in selecting the best method for their intended vision applications. Finally, this study provides insights for potentially interesting future research directions to attract more attention from researchers to this field.
Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior
Mar 24, 2023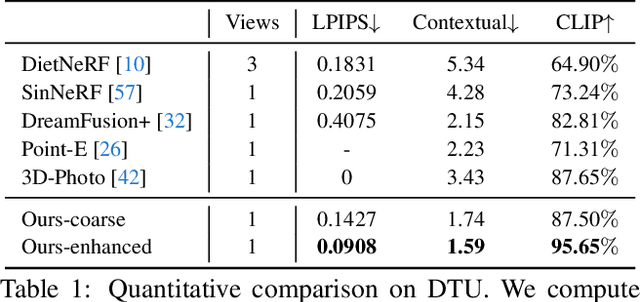
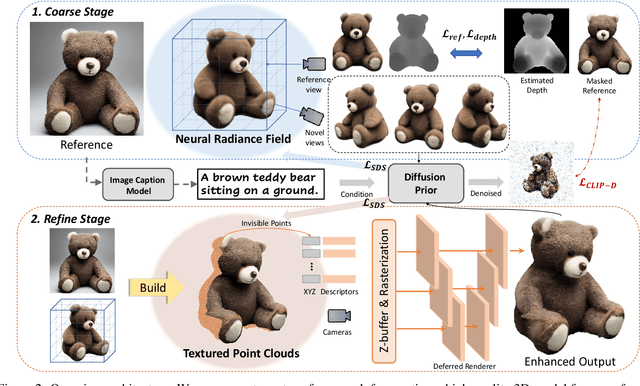
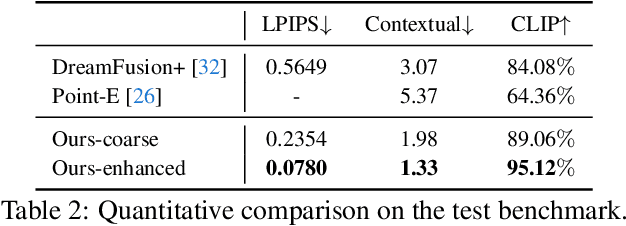

In this work, we investigate the problem of creating high-fidelity 3D content from only a single image. This is inherently challenging: it essentially involves estimating the underlying 3D geometry while simultaneously hallucinating unseen textures. To address this challenge, we leverage prior knowledge from a well-trained 2D diffusion model to act as 3D-aware supervision for 3D creation. Our approach, Make-It-3D, employs a two-stage optimization pipeline: the first stage optimizes a neural radiance field by incorporating constraints from the reference image at the frontal view and diffusion prior at novel views; the second stage transforms the coarse model into textured point clouds and further elevates the realism with diffusion prior while leveraging the high-quality textures from the reference image. Extensive experiments demonstrate that our method outperforms prior works by a large margin, resulting in faithful reconstructions and impressive visual quality. Our method presents the first attempt to achieve high-quality 3D creation from a single image for general objects and enables various applications such as text-to-3D creation and texture editing.
PFT-SSR: Parallax Fusion Transformer for Stereo Image Super-Resolution
Mar 24, 2023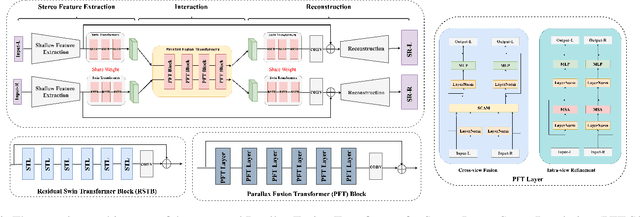
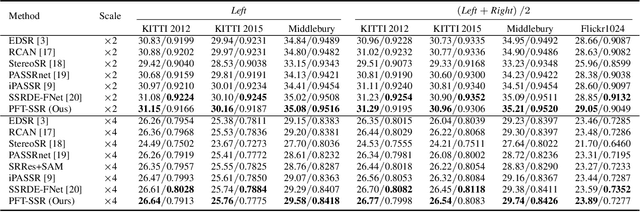

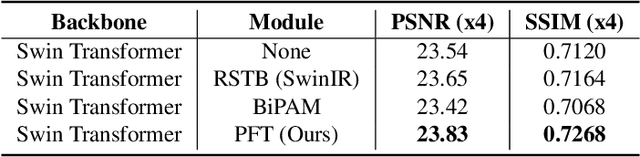
Stereo image super-resolution aims to boost the performance of image super-resolution by exploiting the supplementary information provided by binocular systems. Although previous methods have achieved promising results, they did not fully utilize the information of cross-view and intra-view. To further unleash the potential of binocular images, in this letter, we propose a novel Transformerbased parallax fusion module called Parallax Fusion Transformer (PFT). PFT employs a Cross-view Fusion Transformer (CVFT) to utilize cross-view information and an Intra-view Refinement Transformer (IVRT) for intra-view feature refinement. Meanwhile, we adopted the Swin Transformer as the backbone for feature extraction and SR reconstruction to form a pure Transformer architecture called PFT-SSR. Extensive experiments and ablation studies show that PFT-SSR achieves competitive results and outperforms most SOTA methods. Source code is available at https://github.com/MIVRC/PFT-PyTorch.
* 5 pages, 3 figures
S-CLIP: Semi-supervised Vision-Language Pre-training using Few Specialist Captions
May 23, 2023
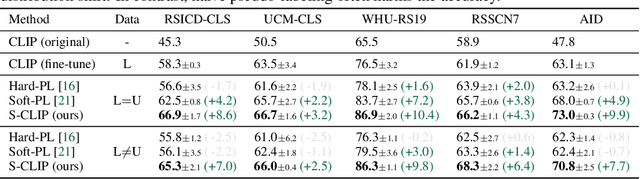

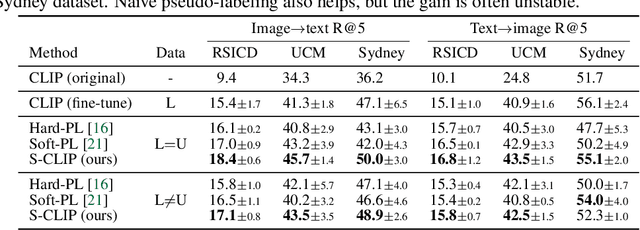
Vision-language models, such as contrastive language-image pre-training (CLIP), have demonstrated impressive results in natural image domains. However, these models often struggle when applied to specialized domains like remote sensing, and adapting to such domains is challenging due to the limited number of image-text pairs available for training. To address this, we propose S-CLIP, a semi-supervised learning method for training CLIP that utilizes additional unpaired images. S-CLIP employs two pseudo-labeling strategies specifically designed for contrastive learning and the language modality. The caption-level pseudo-label is given by a combination of captions of paired images, obtained by solving an optimal transport problem between unpaired and paired images. The keyword-level pseudo-label is given by a keyword in the caption of the nearest paired image, trained through partial label learning that assumes a candidate set of labels for supervision instead of the exact one. By combining these objectives, S-CLIP significantly enhances the training of CLIP using only a few image-text pairs, as demonstrated in various specialist domains, including remote sensing, fashion, scientific figures, and comics. For instance, S-CLIP improves CLIP by 10% for zero-shot classification and 4% for image-text retrieval on the remote sensing benchmark, matching the performance of supervised CLIP while using three times fewer image-text pairs.
Harnessing the Spatial-Temporal Attention of Diffusion Models for High-Fidelity Text-to-Image Synthesis
Apr 07, 2023
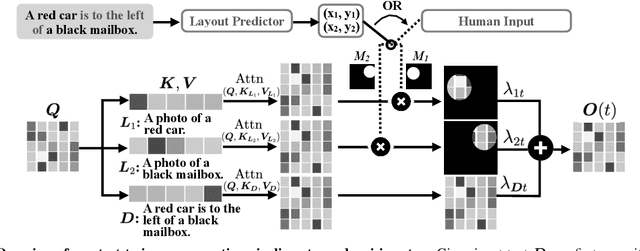
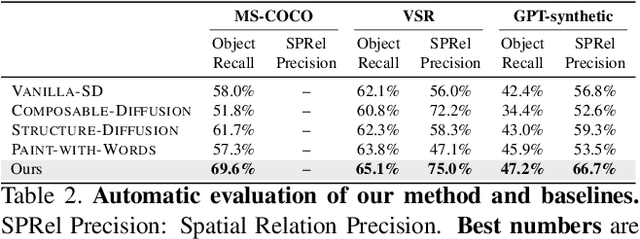

Diffusion-based models have achieved state-of-the-art performance on text-to-image synthesis tasks. However, one critical limitation of these models is the low fidelity of generated images with respect to the text description, such as missing objects, mismatched attributes, and mislocated objects. One key reason for such inconsistencies is the inaccurate cross-attention to text in both the spatial dimension, which controls at what pixel region an object should appear, and the temporal dimension, which controls how different levels of details are added through the denoising steps. In this paper, we propose a new text-to-image algorithm that adds explicit control over spatial-temporal cross-attention in diffusion models. We first utilize a layout predictor to predict the pixel regions for objects mentioned in the text. We then impose spatial attention control by combining the attention over the entire text description and that over the local description of the particular object in the corresponding pixel region of that object. The temporal attention control is further added by allowing the combination weights to change at each denoising step, and the combination weights are optimized to ensure high fidelity between the image and the text. Experiments show that our method generates images with higher fidelity compared to diffusion-model-based baselines without fine-tuning the diffusion model. Our code is publicly available at https://github.com/UCSB-NLP-Chang/Diffusion-SpaceTime-Attn.
PuMer: Pruning and Merging Tokens for Efficient Vision Language Models
May 27, 2023
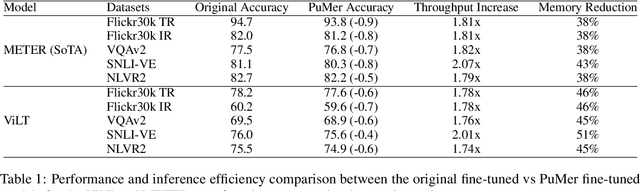
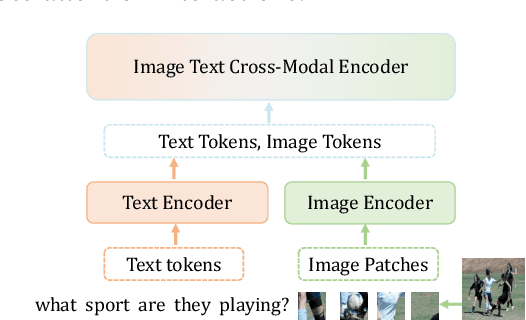
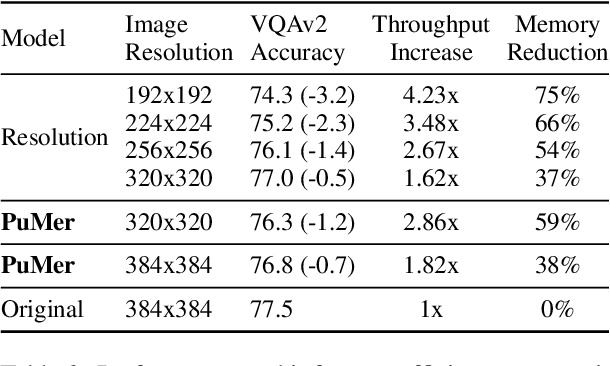
Large-scale vision language (VL) models use Transformers to perform cross-modal interactions between the input text and image. These cross-modal interactions are computationally expensive and memory-intensive due to the quadratic complexity of processing the input image and text. We present PuMer: a token reduction framework that uses text-informed Pruning and modality-aware Merging strategies to progressively reduce the tokens of input image and text, improving model inference speed and reducing memory footprint. PuMer learns to keep salient image tokens related to the input text and merges similar textual and visual tokens by adding lightweight token reducer modules at several cross-modal layers in the VL model. Training PuMer is mostly the same as finetuning the original VL model but faster. Our evaluation for two vision language models on four downstream VL tasks shows PuMer increases inference throughput by up to 2x and reduces memory footprint by over 50% while incurring less than a 1% accuracy drop.
Make the Most Out of Your Net: Alternating Between Canonical and Hard Datasets for Improved Image Demosaicing
Mar 28, 2023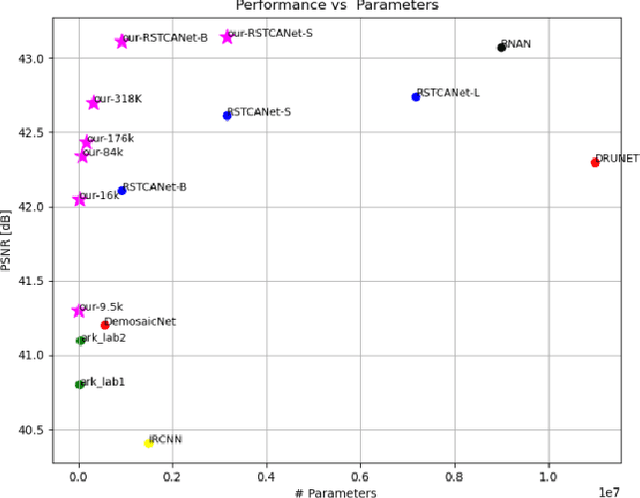
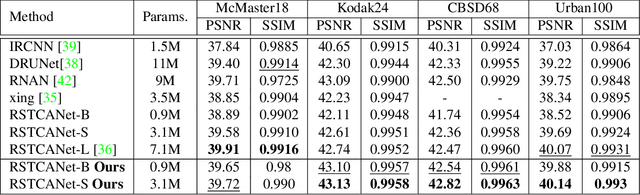

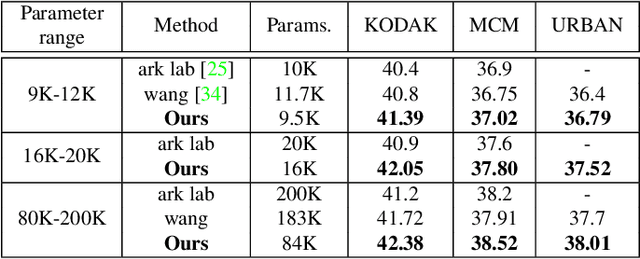
Image demosaicing is an important step in the image processing pipeline for digital cameras, and it is one of the many tasks within the field of image restoration. A well-known characteristic of natural images is that most patches are smooth, while high-content patches like textures or repetitive patterns are much rarer, which results in a long-tailed distribution. This distribution can create an inductive bias when training machine learning algorithms for image restoration tasks and for image demosaicing in particular. There have been many different approaches to address this challenge, such as utilizing specific losses or designing special network architectures. What makes our work is unique in that it tackles the problem from a training protocol perspective. Our proposed training regime consists of two key steps. The first step is a data-mining stage where sub-categories are created and then refined through an elimination process to only retain the most helpful sub-categories. The second step is a cyclic training process where the neural network is trained on both the mined sub-categories and the original dataset. We have conducted various experiments to demonstrate the effectiveness of our training method for the image demosaicing task. Our results show that this method outperforms standard training across a range of architecture sizes and types, including CNNs and Transformers. Moreover, we are able to achieve state-of-the-art results with a significantly smaller neural network, compared to previous state-of-the-art methods.
Image-based Indian Sign Language Recognition: A Practical Review using Deep Neural Networks
Apr 28, 2023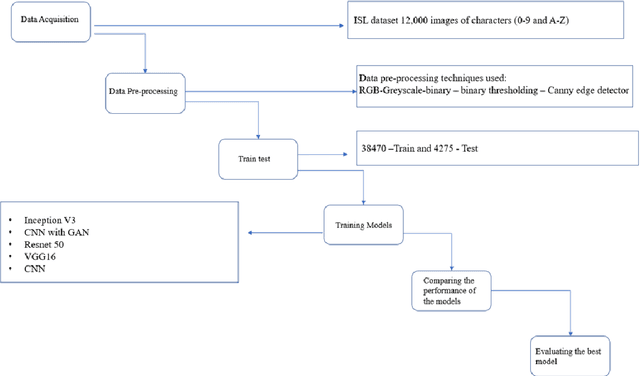
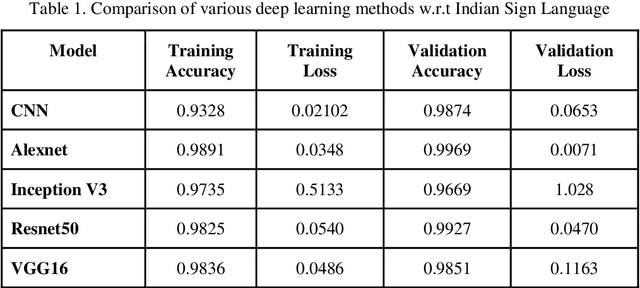

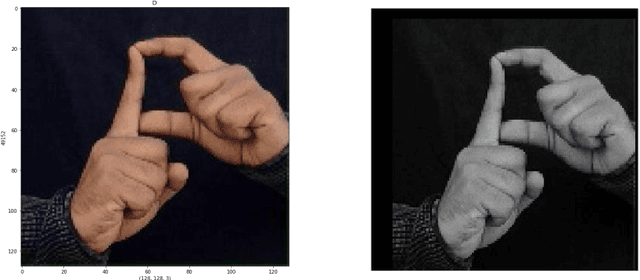
People with vocal and hearing disabilities use sign language to express themselves using visual gestures and signs. Although sign language is a solution for communication difficulties faced by deaf people, there are still problems as most of the general population cannot understand this language, creating a communication barrier, especially in places such as banks, airports, supermarkets, etc. [1]. A sign language recognition(SLR) system is a must to solve this problem. The main focus of this model is to develop a real-time word-level sign language recognition system that would translate sign language to text. Much research has been done on ASL(American sign language). Thus, we have worked on ISL(Indian sign language) to cater to the needs of the deaf and hard-of-hearing community of India[2]. In this research, we provide an Indian Sign Language-based Sign Language recognition system. For this analysis, the user must be able to take pictures of hand movements using a web camera, and the system must anticipate and display the name of the taken picture. The acquired image goes through several processing phases, some of which use computer vision techniques, including grayscale conversion, dilatation, and masking. Our model is trained using a convolutional neural network (CNN), which is then utilized to recognize the images. Our best model has a 99% accuracy rate[3].
3D-aware Conditional Image Synthesis
Feb 16, 2023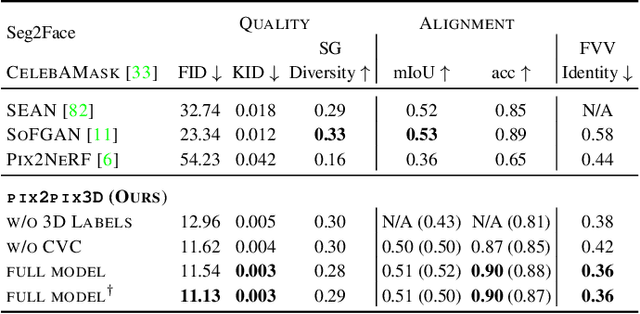
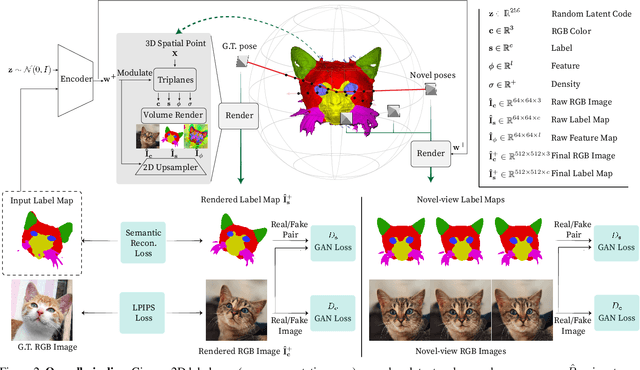
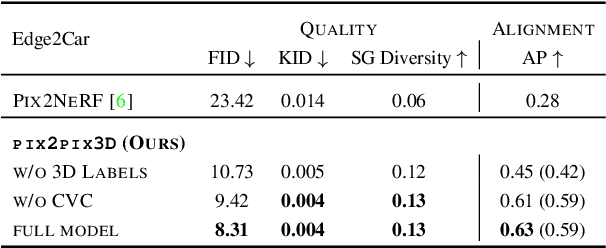
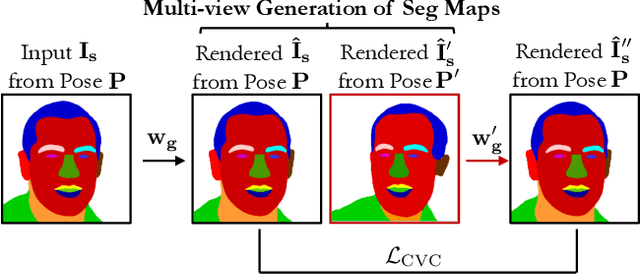
We propose pix2pix3D, a 3D-aware conditional generative model for controllable photorealistic image synthesis. Given a 2D label map, such as a segmentation or edge map, our model learns to synthesize a corresponding image from different viewpoints. To enable explicit 3D user control, we extend conditional generative models with neural radiance fields. Given widely-available monocular images and label map pairs, our model learns to assign a label to every 3D point in addition to color and density, which enables it to render the image and pixel-aligned label map simultaneously. Finally, we build an interactive system that allows users to edit the label map from any viewpoint and generate outputs accordingly.