 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Text Embedding Space Generation Using Generative Adversarial Networks for Text Synthesis
Jun 19, 2023
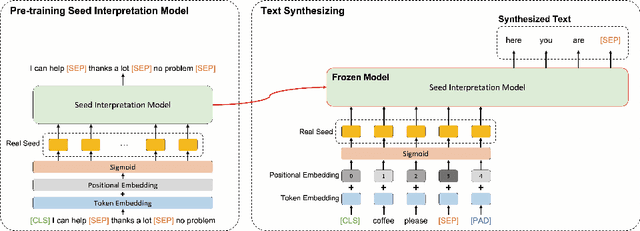
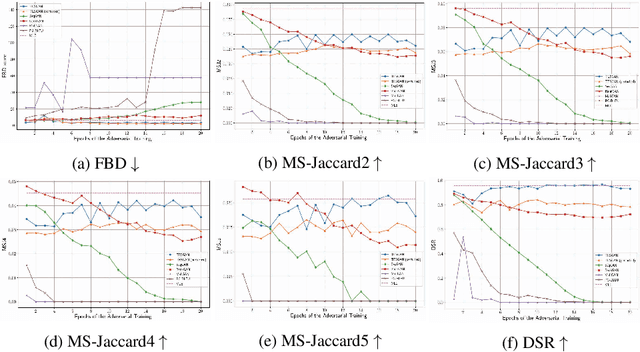

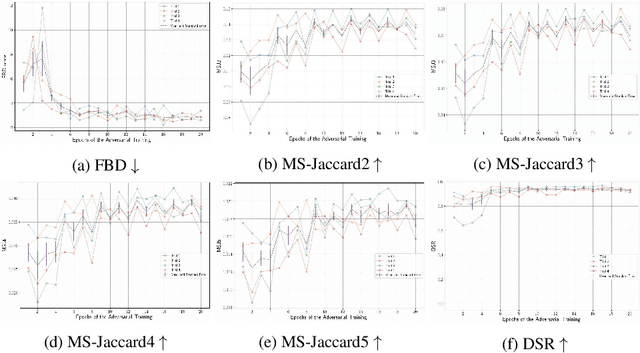
Generative Adversarial Networks (GAN) is a model for data synthesis, which creates plausible data through the competition of generator and discriminator. Although GAN application to image synthesis is extensively studied, it has inherent limitations to natural language generation. Because natural language is composed of discrete tokens, a generator has difficulty updating its gradient through backpropagation; therefore, most text-GAN studies generate sentences starting with a random token based on a reward system. Thus, the generators of previous studies are pre-trained in an autoregressive way before adversarial training, causing data memorization that synthesized sentences reproduce the training data. In this paper, we synthesize sentences using a framework similar to the original GAN. More specifically, we propose Text Embedding Space Generative Adversarial Networks (TESGAN) which generate continuous text embedding spaces instead of discrete tokens to solve the gradient backpropagation problem. Furthermore, TESGAN conducts unsupervised learning which does not directly refer to the text of the training data to overcome the data memorization issue. By adopting this novel method, TESGAN can synthesize new sentences, showing the potential of unsupervised learning for text synthesis. We expect to see extended research combining Large Language Models with a new perspective of viewing text as an continuous space.
PaLI-X: On Scaling up a Multilingual Vision and Language Model
May 29, 2023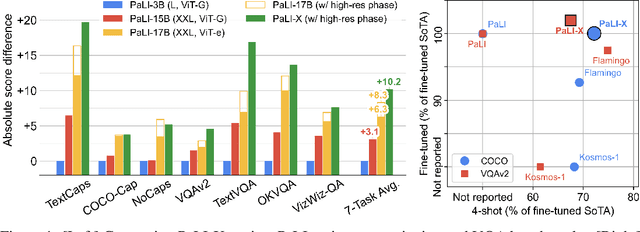
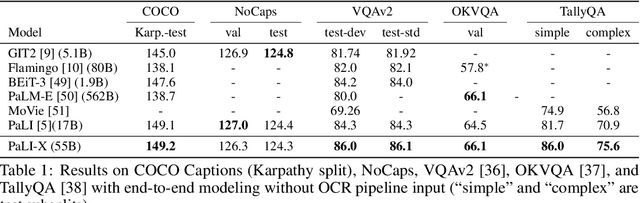
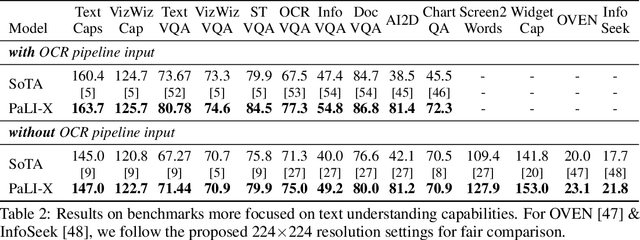

We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
Report of the Medical Image De-Identification (MIDI) Task Group -- Best Practices and Recommendations
Apr 01, 2023This report addresses the technical aspects of de-identification of medical images of human subjects and biospecimens, such that re-identification risk of ethical, moral, and legal concern is sufficiently reduced to allow unrestricted public sharing for any purpose, regardless of the jurisdiction of the source and distribution sites. All medical images, regardless of the mode of acquisition, are considered, though the primary emphasis is on those with accompanying data elements, especially those encoded in formats in which the data elements are embedded, particularly Digital Imaging and Communications in Medicine (DICOM). These images include image-like objects such as Segmentations, Parametric Maps, and Radiotherapy (RT) Dose objects. The scope also includes related non-image objects, such as RT Structure Sets, Plans and Dose Volume Histograms, Structured Reports, and Presentation States. Only de-identification of publicly released data is considered, and alternative approaches to privacy preservation, such as federated learning for artificial intelligence (AI) model development, are out of scope, as are issues of privacy leakage from AI model sharing. Only technical issues of public sharing are addressed.
FPGA Implementation of Convolutional Neural Network for Real-Time Handwriting Recognition
Jun 23, 2023
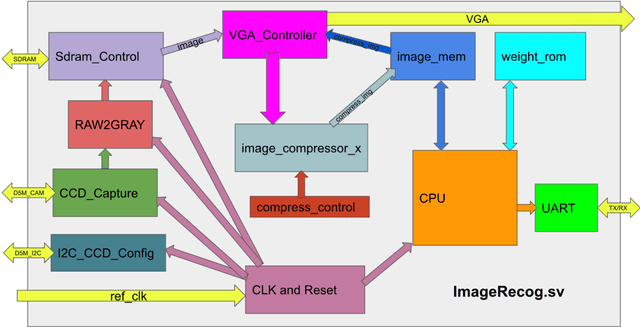
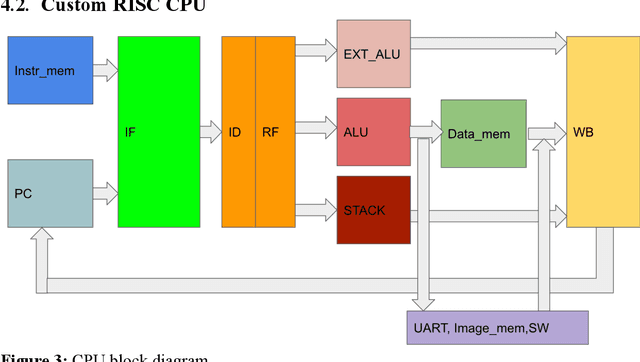
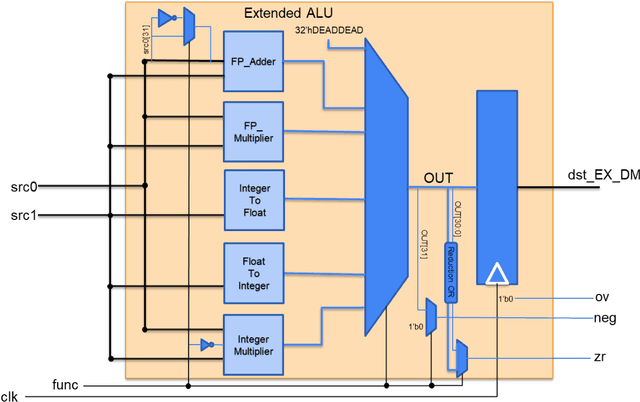
Machine Learning (ML) has recently been a skyrocketing field in Computer Science. As computer hardware engineers, we are enthusiastic about hardware implementations of popular software ML architectures to optimize their performance, reliability, and resource usage. In this project, we designed a highly-configurable, real-time device for recognizing handwritten letters and digits using an Altera DE1 FPGA Kit. We followed various engineering standards, including IEEE-754 32-bit Floating-Point Standard, Video Graphics Array (VGA) display protocol, Universal Asynchronous Receiver-Transmitter (UART) protocol, and Inter-Integrated Circuit (I2C) protocols to achieve the project goals. These significantly improved our design in compatibility, reusability, and simplicity in verifications. Following these standards, we designed a 32-bit floating-point (FP) instruction set architecture (ISA). We developed a 5-stage RISC processor in System Verilog to manage image processing, matrix multiplications, ML classifications, and user interfaces. Three different ML architectures were implemented and evaluated on our design: Linear Classification (LC), a 784-64-10 fully connected neural network (NN), and a LeNet-like Convolutional Neural Network (CNN) with ReLU activation layers and 36 classes (10 for the digits and 26 for the case-insensitive letters). The training processes were done in Python scripts, and the resulting kernels and weights were stored in hex files and loaded into the FPGA's SRAM units. Convolution, pooling, data management, and various other ML features were guided by firmware in our custom assembly language. This paper documents the high-level design block diagrams, interfaces between each System Verilog module, implementation details of our software and firmware components, and further discussions on potential impacts.
Taming Reversible Halftoning via Predictive Luminance
Jun 20, 2023

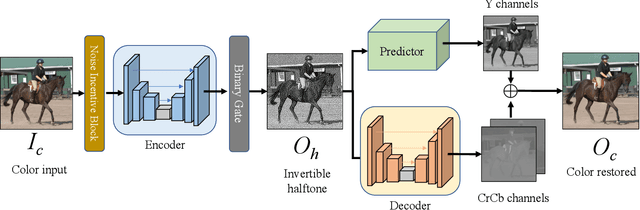
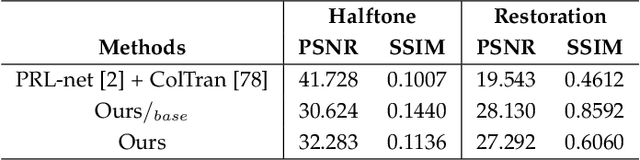
Traditional halftoning usually drops colors when dithering images with binary dots, which makes it difficult to recover the original color information. We proposed a novel halftoning technique that converts a color image into a binary halftone with full restorability to its original version. Our novel base halftoning technique consists of two convolutional neural networks (CNNs) to produce the reversible halftone patterns, and a noise incentive block (NIB) to mitigate the flatness degradation issue of CNNs. Furthermore, to tackle the conflicts between the blue-noise quality and restoration accuracy in our novel base method, we proposed a predictor-embedded approach to offload predictable information from the network, which in our case is the luminance information resembling from the halftone pattern. Such an approach allows the network to gain more flexibility to produce halftones with better blue-noise quality without compromising the restoration quality. Detailed studies on the multiple-stage training method and loss weightings have been conducted. We have compared our predictor-embedded method and our novel method regarding spectrum analysis on halftone, halftone accuracy, restoration accuracy, and the data embedding studies. Our entropy evaluation evidences our halftone contains less encoding information than our novel base method. The experiments show our predictor-embedded method gains more flexibility to improve the blue-noise quality of halftones and maintains a comparable restoration quality with a higher tolerance for disturbances.
LNL+K: Learning with Noisy Labels and Noise Source Distribution Knowledge
Jun 20, 2023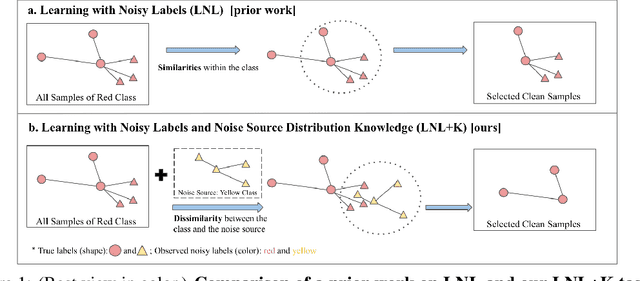
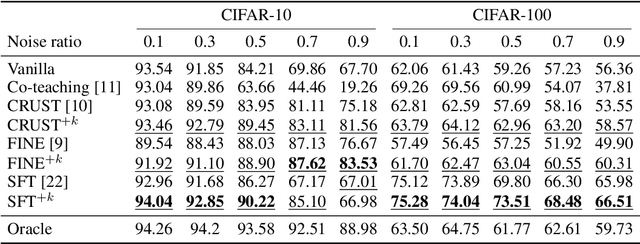
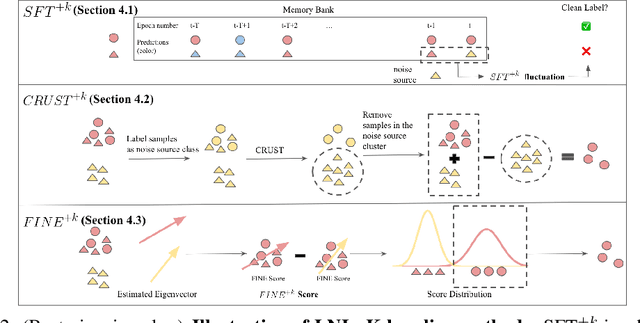
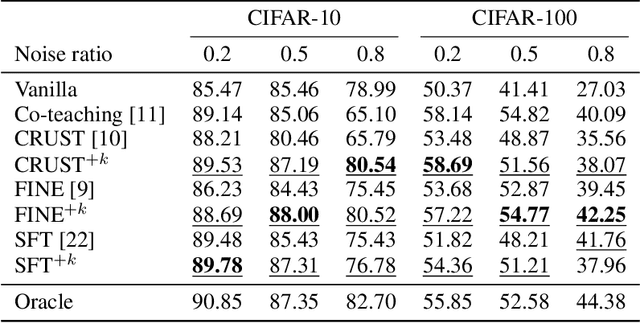
Learning with noisy labels (LNL) is challenging as the model tends to memorize noisy labels, which can lead to overfitting. Many LNL methods detect clean samples by maximizing the similarity between samples in each category, which does not make any assumptions about likely noise sources. However, we often have some knowledge about the potential source(s) of noisy labels. For example, an image mislabeled as a cheetah is more likely a leopard than a hippopotamus due to their visual similarity. Thus, we introduce a new task called Learning with Noisy Labels and noise source distribution Knowledge (LNL+K), which assumes we have some knowledge about likely source(s) of label noise that we can take advantage of. By making this presumption, methods are better equipped to distinguish hard negatives between categories from label noise. In addition, this enables us to explore datasets where the noise may represent the majority of samples, a setting that breaks a critical premise of most methods developed for the LNL task. We explore several baseline LNL+K approaches that integrate noise source knowledge into state-of-the-art LNL methods across three diverse datasets and three types of noise, where we report a 5-15% boost in performance compared with the unadapted methods. Critically, we find that LNL methods do not generalize well in every setting, highlighting the importance of directly exploring our LNL+K task.
Unsupervised Semantic Correspondence Using Stable Diffusion
May 24, 2023
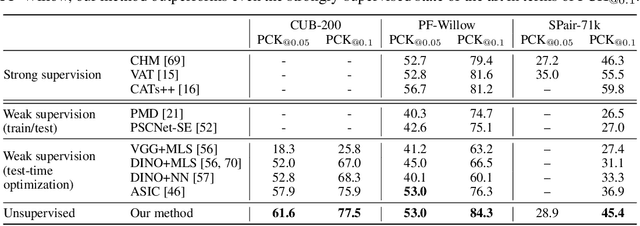

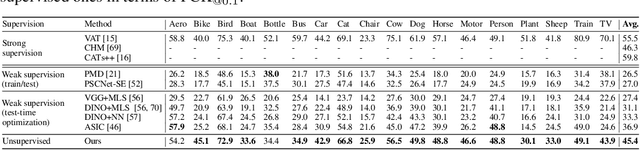
Text-to-image diffusion models are now capable of generating images that are often indistinguishable from real images. To generate such images, these models must understand the semantics of the objects they are asked to generate. In this work we show that, without any training, one can leverage this semantic knowledge within diffusion models to find semantic correspondences -- locations in multiple images that have the same semantic meaning. Specifically, given an image, we optimize the prompt embeddings of these models for maximum attention on the regions of interest. These optimized embeddings capture semantic information about the location, which can then be transferred to another image. By doing so we obtain results on par with the strongly supervised state of the art on the PF-Willow dataset and significantly outperform (20.9% relative for the SPair-71k dataset) any existing weakly or unsupervised method on PF-Willow, CUB-200 and SPair-71k datasets.
Unsupervised haze removal from underwater images
Jun 05, 2023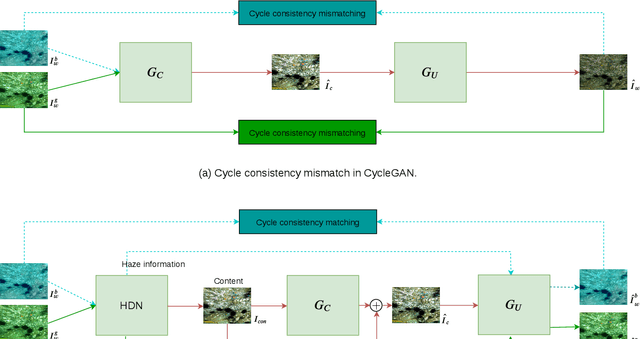

Several supervised networks exist that remove haze information from underwater images using paired datasets and pixel-wise loss functions. However, training these networks requires large amounts of paired data which is cumbersome, complex and time-consuming. Also, directly using adversarial and cycle consistency loss functions for unsupervised learning is inaccurate as the underlying mapping from clean to underwater images is one-to-many, resulting in an inaccurate constraint on the cycle consistency loss. To address these issues, we propose a new method to remove haze from underwater images using unpaired data. Our model disentangles haze and content information from underwater images using a Haze Disentanglement Network (HDN). The disentangled content is used by a restoration network to generate a clean image using adversarial losses. The disentangled haze is then used as a guide for underwater image regeneration resulting in a strong constraint on cycle consistency loss and improved performance gains. Different ablation studies show that the haze and content from underwater images are effectively separated. Exhaustive experiments reveal that accurate cycle consistency constraint and the proposed network architecture play an important role in yielding enhanced results. Experiments on UFO-120, UWNet, UWScenes, and UIEB underwater datasets indicate that the results of our method outperform prior art both visually and quantitatively.
Learning Conditional Attributes for Compositional Zero-Shot Learning
Jun 14, 2023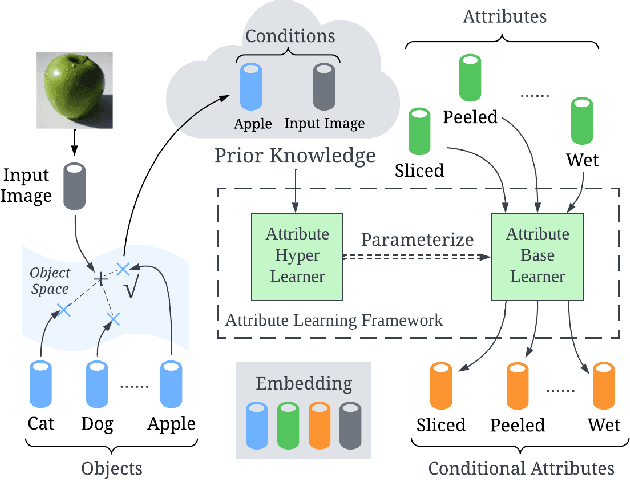

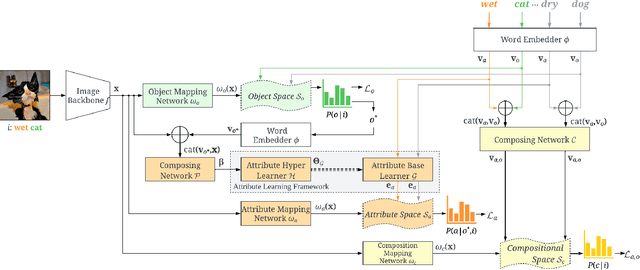
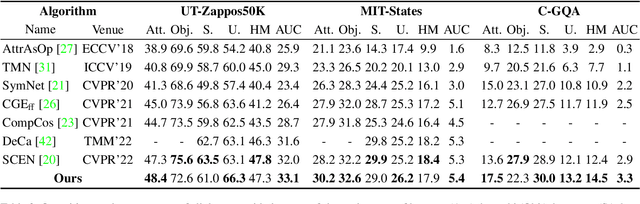
Compositional Zero-Shot Learning (CZSL) aims to train models to recognize novel compositional concepts based on learned concepts such as attribute-object combinations. One of the challenges is to model attributes interacted with different objects, e.g., the attribute ``wet" in ``wet apple" and ``wet cat" is different. As a solution, we provide analysis and argue that attributes are conditioned on the recognized object and input image and explore learning conditional attribute embeddings by a proposed attribute learning framework containing an attribute hyper learner and an attribute base learner. By encoding conditional attributes, our model enables to generate flexible attribute embeddings for generalization from seen to unseen compositions. Experiments on CZSL benchmarks, including the more challenging C-GQA dataset, demonstrate better performances compared with other state-of-the-art approaches and validate the importance of learning conditional attributes. Code is available at https://github.com/wqshmzh/CANet-CZSL
Efficient Deep Spiking Multi-Layer Perceptrons with Multiplication-Free Inference
Jun 21, 2023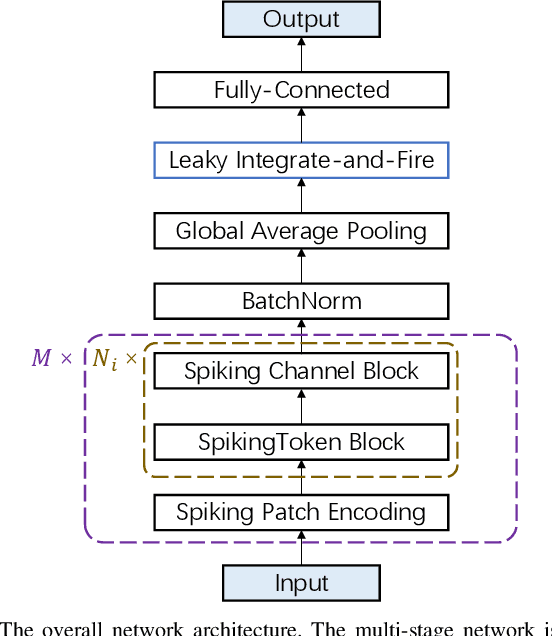
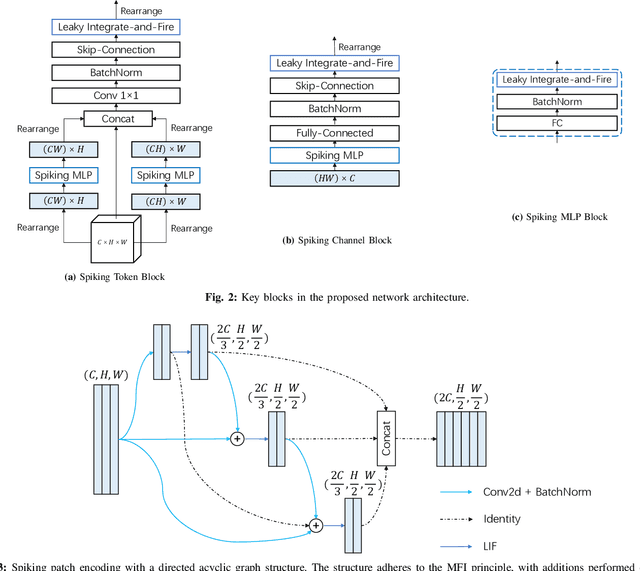
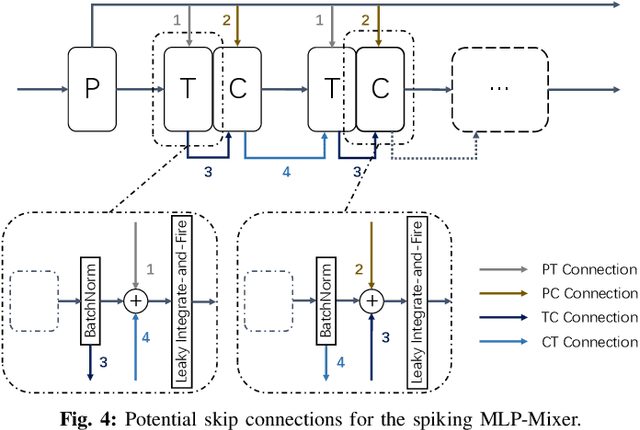
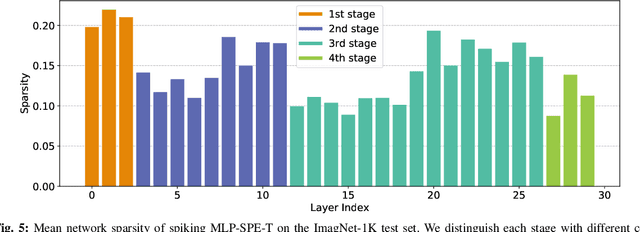
Advancements in adapting deep convolution architectures for Spiking Neural Networks (SNNs) have significantly enhanced image classification performance and reduced computational burdens. However, the inability of Multiplication-Free Inference (MFI) to harmonize with attention and transformer mechanisms, which are critical to superior performance on high-resolution vision tasks, imposes limitations on these gains. To address this, our research explores a new pathway, drawing inspiration from the progress made in Multi-Layer Perceptrons (MLPs). We propose an innovative spiking MLP architecture that uses batch normalization to retain MFI compatibility and introduces a spiking patch encoding layer to reinforce local feature extraction capabilities. As a result, we establish an efficient multi-stage spiking MLP network that effectively blends global receptive fields with local feature extraction for comprehensive spike-based computation. Without relying on pre-training or sophisticated SNN training techniques, our network secures a top-1 accuracy of 66.39% on the ImageNet-1K dataset, surpassing the directly trained spiking ResNet-34 by 2.67%. Furthermore, we curtail computational costs, model capacity, and simulation steps. An expanded version of our network challenges the performance of the spiking VGG-16 network with a 71.64% top-1 accuracy, all while operating with a model capacity 2.1 times smaller. Our findings accentuate the potential of our deep SNN architecture in seamlessly integrating global and local learning abilities. Interestingly, the trained receptive field in our network mirrors the activity patterns of cortical cells.