 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cloud K-SVD for Image Denoising
Mar 01, 2023
Cloud K-SVD is a dictionary learning algorithm that can train at multiple nodes and hereby produce a mutual dictionary to represent low-dimensional geometric structures in image data. We present a novel application of the algorithm as we use it to recover both noiseless and noisy images from overlapping patches. We implement a node network in Kubernetes using Docker containers to facilitate Cloud K-SVD. Results show that Cloud K-SVD can recover images approximately and remove quantifiable amounts of noise from benchmark gray-scaled images without sacrificing accuracy in recovery; we achieve an SSIM index of 0.88, 0.91 and 0.95 between clean and recovered images for noise levels ($\mu$ = 0, $\sigma^{2}$ = 0.01, 0.005, 0.001), respectively, which is similar to SOTA in the field. Cloud K-SVD is evidently able to learn a mutual dictionary across multiple nodes and remove AWGN from images. The mutual dictionary can be used to recover a specific image at any of the nodes in the network.
End-to-end Knowledge Retrieval with Multi-modal Queries
Jun 01, 2023

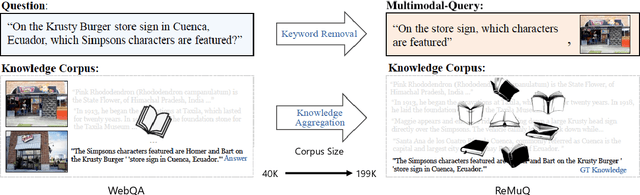
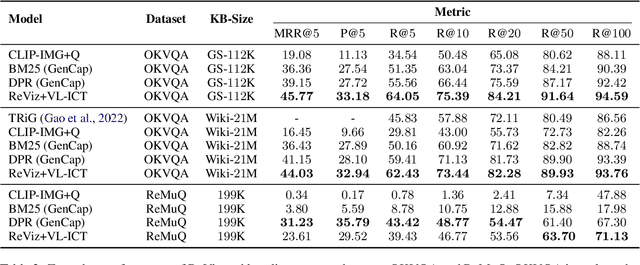
We investigate knowledge retrieval with multi-modal queries, i.e. queries containing information split across image and text inputs, a challenging task that differs from previous work on cross-modal retrieval. We curate a new dataset called ReMuQ for benchmarking progress on this task. ReMuQ requires a system to retrieve knowledge from a large corpus by integrating contents from both text and image queries. We introduce a retriever model ``ReViz'' that can directly process input text and images to retrieve relevant knowledge in an end-to-end fashion without being dependent on intermediate modules such as object detectors or caption generators. We introduce a new pretraining task that is effective for learning knowledge retrieval with multimodal queries and also improves performance on downstream tasks. We demonstrate superior performance in retrieval on two datasets (ReMuQ and OK-VQA) under zero-shot settings as well as further improvements when finetuned on these datasets.
Sea Ice Extraction via Remote Sensed Imagery: Algorithms, Datasets, Applications and Challenges
Jun 01, 2023
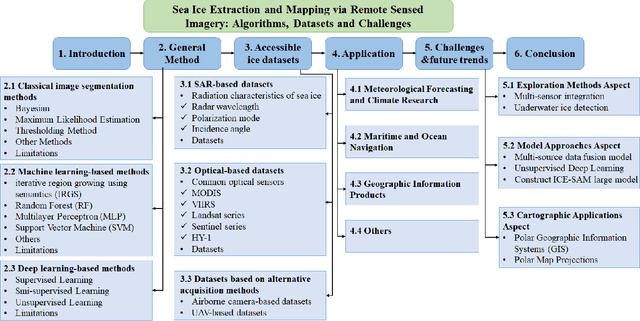
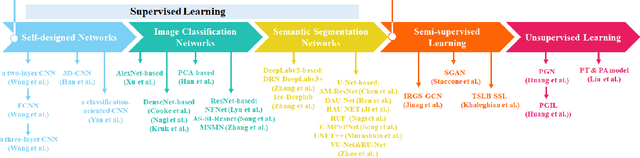
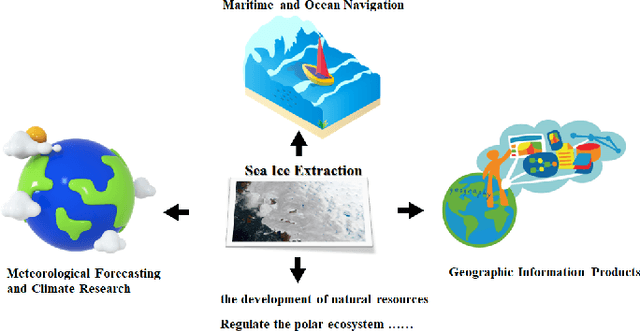
The deep learning, which is a dominating technique in artificial intelligence, has completely changed the image understanding over the past decade. As a consequence, the sea ice extraction (SIE) problem has reached a new era. We present a comprehensive review of four important aspects of SIE, including algorithms, datasets, applications, and the future trends. Our review focuses on researches published from 2016 to the present, with a specific focus on deep learning-based approaches in the last five years. We divided all relegated algorithms into 3 categories, including classical image segmentation approach, machine learning-based approach and deep learning-based methods. We reviewed the accessible ice datasets including SAR-based datasets, the optical-based datasets and others. The applications are presented in 4 aspects including climate research, navigation, geographic information systems (GIS) production and others. It also provides insightful observations and inspiring future research directions.
Balanced Mixture of SuperNets for Learning the CNN Pooling Architecture
Jun 21, 2023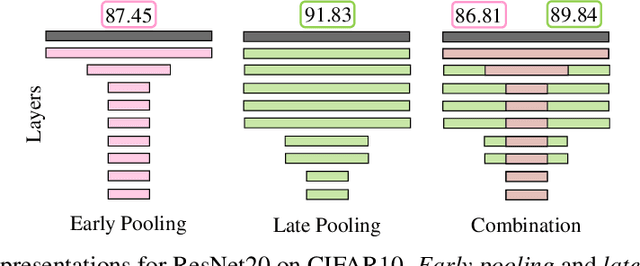
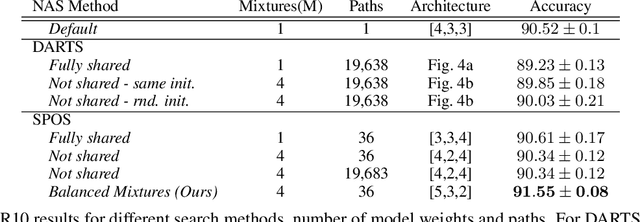
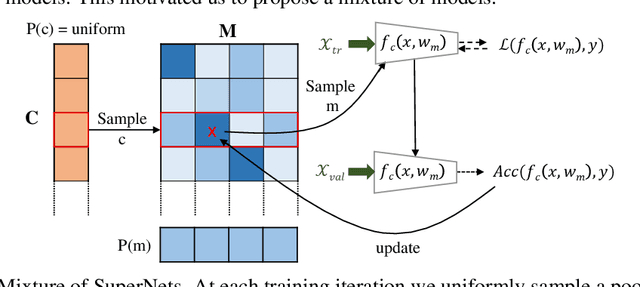
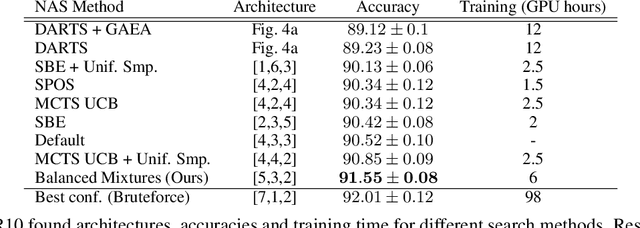
Downsampling layers, including pooling and strided convolutions, are crucial components of the convolutional neural network architecture that determine both the granularity/scale of image feature analysis as well as the receptive field size of a given layer. To fully understand this problem, we analyse the performance of models independently trained with each pooling configurations on CIFAR10, using a ResNet20 network, and show that the position of the downsampling layers can highly influence the performance of a network and predefined downsampling configurations are not optimal. Network Architecture Search (NAS) might be used to optimize downsampling configurations as an hyperparameter. However, we find that common one-shot NAS based on a single SuperNet does not work for this problem. We argue that this is because a SuperNet trained for finding the optimal pooling configuration fully shares its parameters among all pooling configurations. This makes its training hard, because learning some configurations can harm the performance of others. Therefore, we propose a balanced mixture of SuperNets that automatically associates pooling configurations to different weight models and helps to reduce the weight-sharing and inter-influence of pooling configurations on the SuperNet parameters. We evaluate our proposed approach on CIFAR10, CIFAR100, as well as Food101 and show that in all cases, our model outperforms other approaches and improves over the default pooling configurations.
StructuredMesh: 3D Structured Optimization of Façade Components on Photogrammetric Mesh Models using Binary Integer Programming
Jun 07, 2023
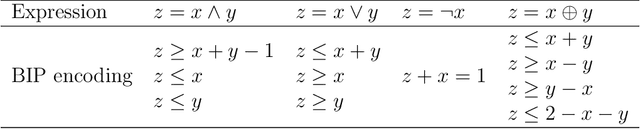
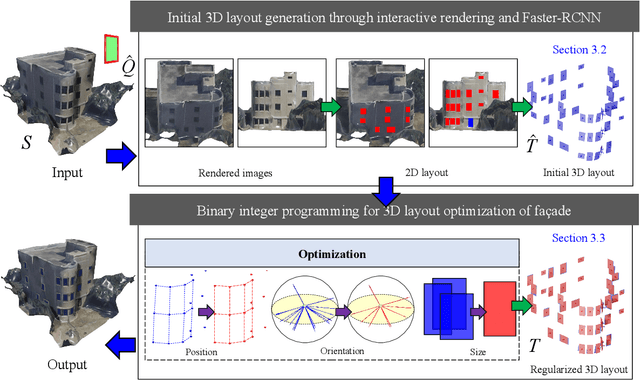
The lack of fa\c{c}ade structures in photogrammetric mesh models renders them inadequate for meeting the demands of intricate applications. Moreover, these mesh models exhibit irregular surfaces with considerable geometric noise and texture quality imperfections, making the restoration of structures challenging. To address these shortcomings, we present StructuredMesh, a novel approach for reconstructing fa\c{c}ade structures conforming to the regularity of buildings within photogrammetric mesh models. Our method involves capturing multi-view color and depth images of the building model using a virtual camera and employing a deep learning object detection pipeline to semi-automatically extract the bounding boxes of fa\c{c}ade components such as windows, doors, and balconies from the color image. We then utilize the depth image to remap these boxes into 3D space, generating an initial fa\c{c}ade layout. Leveraging architectural knowledge, we apply binary integer programming (BIP) to optimize the 3D layout's structure, encompassing the positions, orientations, and sizes of all components. The refined layout subsequently informs fa\c{c}ade modeling through instance replacement. We conducted experiments utilizing building mesh models from three distinct datasets, demonstrating the adaptability, robustness, and noise resistance of our proposed methodology. Furthermore, our 3D layout evaluation metrics reveal that the optimized layout enhances precision, recall, and F-score by 6.5%, 4.5%, and 5.5%, respectively, in comparison to the initial layout.
Occ-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction
Jun 07, 2023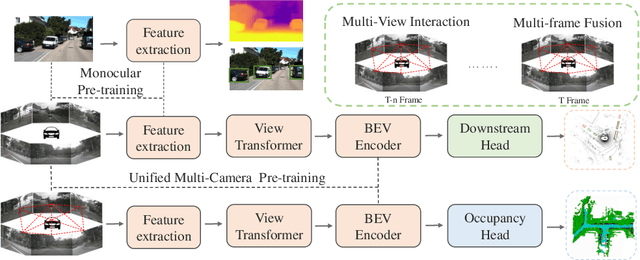
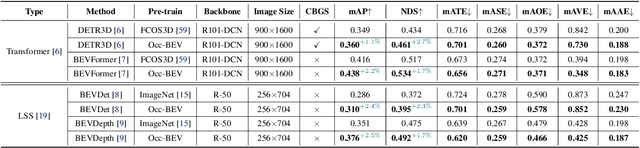
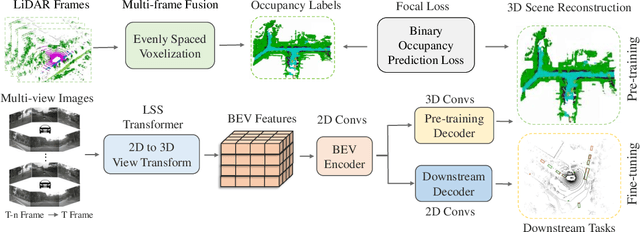

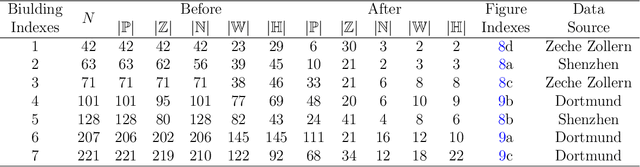
Multi-camera 3D perception has emerged as a prominent research field in autonomous driving, offering a viable and cost-effective alternative to LiDAR-based solutions. However, existing multi-camera algorithms primarily rely on monocular image pre-training, which overlooks the spatial and temporal correlations among different camera views. To address this limitation, we propose the first multi-camera unified pre-training framework called Occ-BEV, which involves initially reconstructing the 3D scene as the foundational stage and subsequently fine-tuning the model on downstream tasks. Specifically, a 3D decoder is designed for leveraging Bird's Eye View (BEV) features from multi-view images to predict the 3D geometric occupancy to enable the model to capture a more comprehensive understanding of the 3D environment. A significant benefit of Occ-BEV is its capability of utilizing a considerable volume of unlabeled image-LiDAR pairs for pre-training purposes. The proposed multi-camera unified pre-training framework demonstrates promising results in key tasks such as multi-camera 3D object detection and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, Occ-BEV shows a significant improvement of about 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. Codes are publicly available at https://github.com/chaytonmin/Occ-BEV.
Report of the Medical Image De-Identification (MIDI) Task Group -- Best Practices and Recommendations
Apr 01, 2023This report addresses the technical aspects of de-identification of medical images of human subjects and biospecimens, such that re-identification risk of ethical, moral, and legal concern is sufficiently reduced to allow unrestricted public sharing for any purpose, regardless of the jurisdiction of the source and distribution sites. All medical images, regardless of the mode of acquisition, are considered, though the primary emphasis is on those with accompanying data elements, especially those encoded in formats in which the data elements are embedded, particularly Digital Imaging and Communications in Medicine (DICOM). These images include image-like objects such as Segmentations, Parametric Maps, and Radiotherapy (RT) Dose objects. The scope also includes related non-image objects, such as RT Structure Sets, Plans and Dose Volume Histograms, Structured Reports, and Presentation States. Only de-identification of publicly released data is considered, and alternative approaches to privacy preservation, such as federated learning for artificial intelligence (AI) model development, are out of scope, as are issues of privacy leakage from AI model sharing. Only technical issues of public sharing are addressed.
Scale-aware Super-resolution Network with Dual Affinity Learning for Lesion Segmentation from Medical Images
May 30, 2023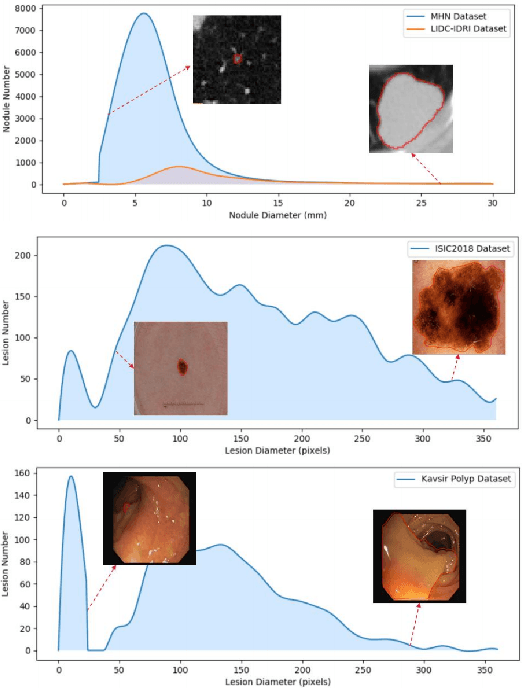
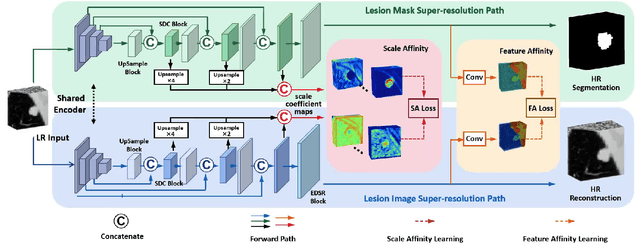
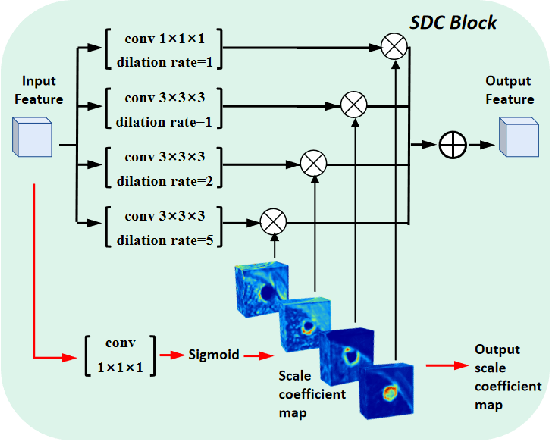

Convolutional Neural Networks (CNNs) have shown remarkable progress in medical image segmentation. However, lesion segmentation remains a challenge to state-of-the-art CNN-based algorithms due to the variance in scales and shapes. On the one hand, tiny lesions are hard to be delineated precisely from the medical images which are often of low resolutions. On the other hand, segmenting large-size lesions requires large receptive fields, which exacerbates the first challenge. In this paper, we present a scale-aware super-resolution network to adaptively segment lesions of various sizes from the low-resolution medical images. Our proposed network contains dual branches to simultaneously conduct lesion mask super-resolution and lesion image super-resolution. The image super-resolution branch will provide more detailed features for the segmentation branch, i.e., the mask super-resolution branch, for fine-grained segmentation. Meanwhile, we introduce scale-aware dilated convolution blocks into the multi-task decoders to adaptively adjust the receptive fields of the convolutional kernels according to the lesion sizes. To guide the segmentation branch to learn from richer high-resolution features, we propose a feature affinity module and a scale affinity module to enhance the multi-task learning of the dual branches. On multiple challenging lesion segmentation datasets, our proposed network achieved consistent improvements compared to other state-of-the-art methods.
Directional diffusion models for graph representation learning
Jun 22, 2023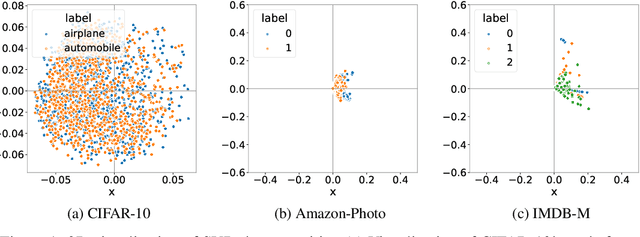
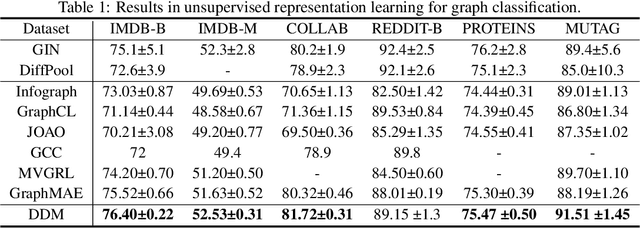
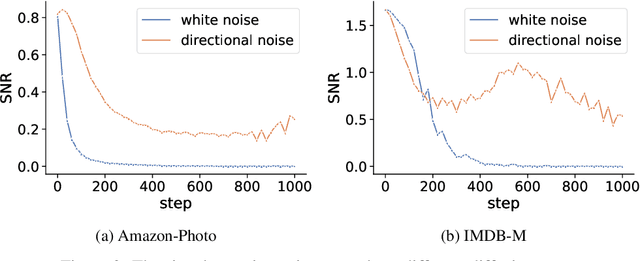
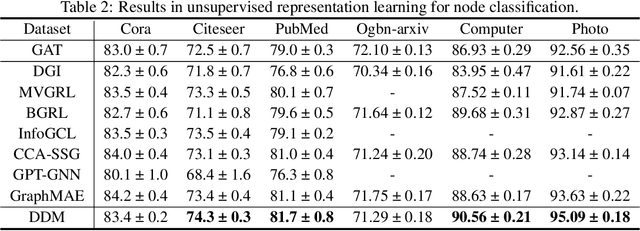
In recent years, diffusion models have achieved remarkable success in various domains of artificial intelligence, such as image synthesis, super-resolution, and 3D molecule generation. However, the application of diffusion models in graph learning has received relatively little attention. In this paper, we address this gap by investigating the use of diffusion models for unsupervised graph representation learning. We begin by identifying the anisotropic structures of graphs and a crucial limitation of the vanilla forward diffusion process in learning anisotropic structures. This process relies on continuously adding an isotropic Gaussian noise to the data, which may convert the anisotropic signals to noise too quickly. This rapid conversion hampers the training of denoising neural networks and impedes the acquisition of semantically meaningful representations in the reverse process. To address this challenge, we propose a new class of models called {\it directional diffusion models}. These models incorporate data-dependent, anisotropic, and directional noises in the forward diffusion process. To assess the efficacy of our proposed models, we conduct extensive experiments on 12 publicly available datasets, focusing on two distinct graph representation learning tasks. The experimental results demonstrate the superiority of our models over state-of-the-art baselines, indicating their effectiveness in capturing meaningful graph representations. Our studies not only provide valuable insights into the forward process of diffusion models but also highlight the wide-ranging potential of these models for various graph-related tasks.
Meta-Gating Framework for Fast and Continuous Resource Optimization in Dynamic Wireless Environments
Jun 23, 2023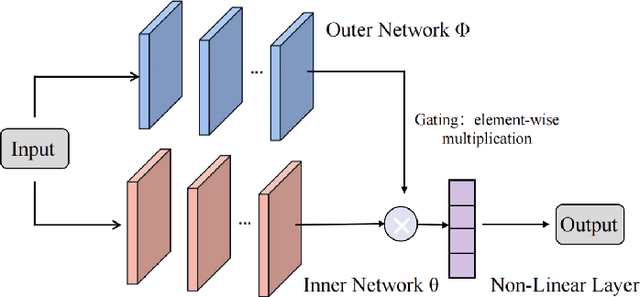
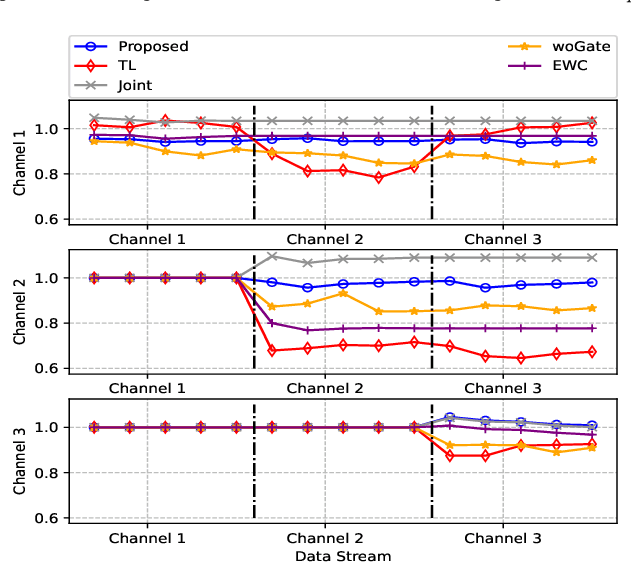
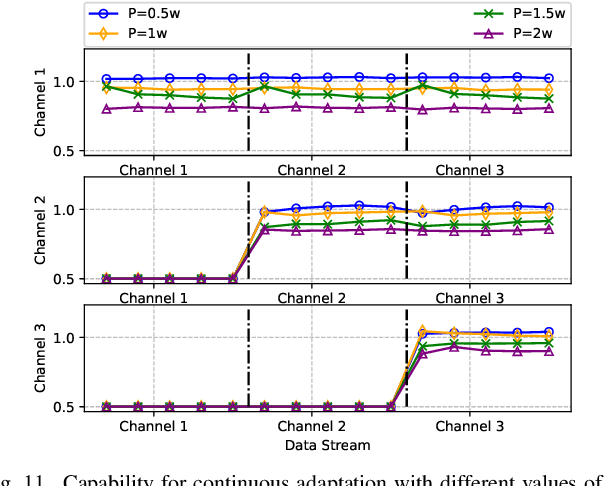
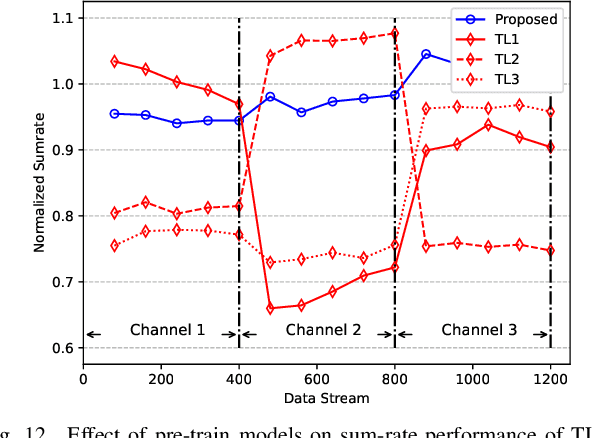
With the great success of deep learning (DL) in image classification, speech recognition, and other fields, more and more studies have applied various neural networks (NNs) to wireless resource allocation. Generally speaking, these artificial intelligent (AI) models are trained under some special learning hypotheses, especially that the statistics of the training data are static during the training stage. However, the distribution of channel state information (CSI) is constantly changing in the real-world wireless communication environment. Therefore, it is essential to study effective dynamic DL technologies to solve wireless resource allocation problems. In this paper, we propose a novel framework, named meta-gating, for solving resource allocation problems in an episodically dynamic wireless environment, where the CSI distribution changes over periods and remains constant within each period. The proposed framework, consisting of an inner network and an outer network, aims to adapt to the dynamic wireless environment by achieving three important goals, i.e., seamlessness, quickness and continuity. Specifically, for the former two goals, we propose a training method by combining a model-agnostic meta-learning (MAML) algorithm with an unsupervised learning mechanism. With this training method, the inner network is able to fast adapt to different channel distributions because of the good initialization. As for the goal of continuity, the outer network can learn to evaluate the importance of inner network's parameters under different CSI distributions, and then decide which subset of the inner network should be activated through the gating operation. Additionally, we theoretically analyze the performance of the proposed meta-gating framework.