 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Investigation of the effectiveness of applying ChatGPT in Dialogic Teaching Using Electroencephalography
Mar 25, 2024
In recent years, the rapid development of artificial intelligence technology, especially the emergence of large language models (LLMs) such as ChatGPT, has presented significant prospects for application in the field of education. LLMs possess the capability to interpret knowledge, answer questions, and consider context, thus providing support for dialogic teaching to students. Therefore, an examination of the capacity of LLMs to effectively fulfill instructional roles, thereby facilitating student learning akin to human educators within dialogic teaching scenarios, is an exceptionally valuable research topic. This research recruited 34 undergraduate students as participants, who were randomly divided into two groups. The experimental group engaged in dialogic teaching using ChatGPT, while the control group interacted with human teachers. Both groups learned the histogram equalization unit in the information-related course "Digital Image Processing". The research findings show comparable scores between the two groups on the retention test. However, students who engaged in dialogue with ChatGPT exhibited lower performance on the transfer test. Electroencephalography data revealed that students who interacted with ChatGPT exhibited higher levels of cognitive activity, suggesting that ChatGPT could help students establish a knowledge foundation and stimulate cognitive activity. However, its strengths on promoting students. knowledge application and creativity were insignificant. Based upon the research findings, it is evident that ChatGPT cannot fully excel in fulfilling teaching tasks in the dialogue teaching in information related courses. Combining ChatGPT with traditional human teachers might be a more ideal approach. The synergistic use of both can provide students with more comprehensive learning support, thus contributing to enhancing the quality of teaching.
Click to Grasp: Zero-Shot Precise Manipulation via Visual Diffusion Descriptors
Mar 21, 2024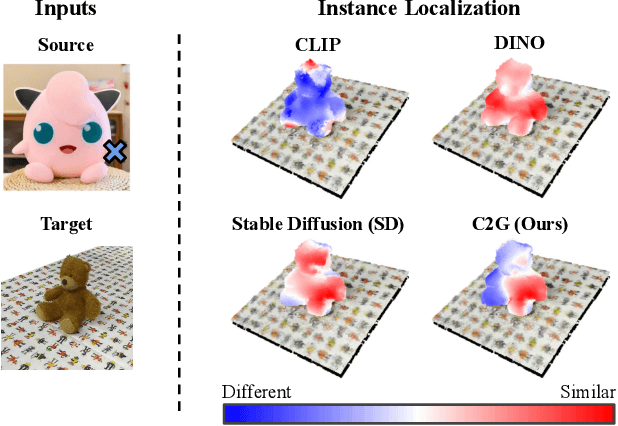
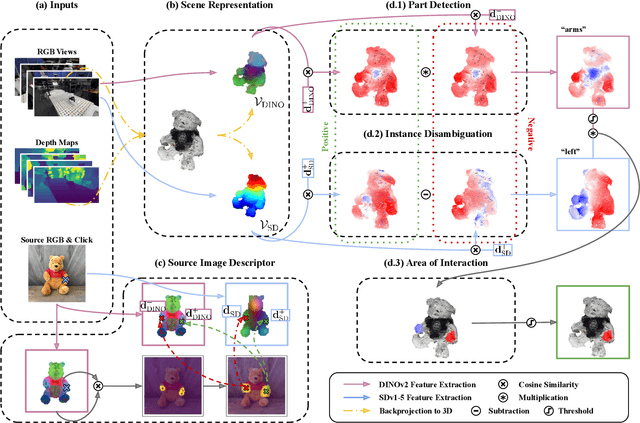


Precise manipulation that is generalizable across scenes and objects remains a persistent challenge in robotics. Current approaches for this task heavily depend on having a significant number of training instances to handle objects with pronounced visual and/or geometric part ambiguities. Our work explores the grounding of fine-grained part descriptors for precise manipulation in a zero-shot setting by utilizing web-trained text-to-image diffusion-based generative models. We tackle the problem by framing it as a dense semantic part correspondence task. Our model returns a gripper pose for manipulating a specific part, using as reference a user-defined click from a source image of a visually different instance of the same object. We require no manual grasping demonstrations as we leverage the intrinsic object geometry and features. Practical experiments in a real-world tabletop scenario validate the efficacy of our approach, demonstrating its potential for advancing semantic-aware robotics manipulation. Web page: https://tsagkas.github.io/click2grasp
HOLMES: HOLonym-MEronym based Semantic inspection for Convolutional Image Classifiers
Mar 13, 2024Convolutional Neural Networks (CNNs) are nowadays the model of choice in Computer Vision, thanks to their ability to automatize the feature extraction process in visual tasks. However, the knowledge acquired during training is fully subsymbolic, and hence difficult to understand and explain to end users. In this paper, we propose a new technique called HOLMES (HOLonym-MEronym based Semantic inspection) that decomposes a label into a set of related concepts, and provides component-level explanations for an image classification model. Specifically, HOLMES leverages ontologies, web scraping and transfer learning to automatically construct meronym (parts)-based detectors for a given holonym (class). Then, it produces heatmaps at the meronym level and finally, by probing the holonym CNN with occluded images, it highlights the importance of each part on the classification output. Compared to state-of-the-art saliency methods, HOLMES takes a step further and provides information about both where and what the holonym CNN is looking at, without relying on densely annotated datasets and without forcing concepts to be associated to single computational units. Extensive experimental evaluation on different categories of objects (animals, tools and vehicles) shows the feasibility of our approach. On average, HOLMES explanations include at least two meronyms, and the ablation of a single meronym roughly halves the holonym model confidence. The resulting heatmaps were quantitatively evaluated using the deletion/insertion/preservation curves. All metrics were comparable to those achieved by GradCAM, while offering the advantage of further decomposing the heatmap in human-understandable concepts, thus highlighting both the relevance of meronyms to object classification, as well as HOLMES ability to capture it. The code is available at https://github.com/FrancesC0de/HOLMES.
* This work has been accepted to be presented to The 1st World Conference on eXplainable Artificial Intelligence (xAI 2023), July 26-28, 2023 - Lisboa, Portugal
Dynamic Perturbation-Adaptive Adversarial Training on Medical Image Classification
Mar 11, 2024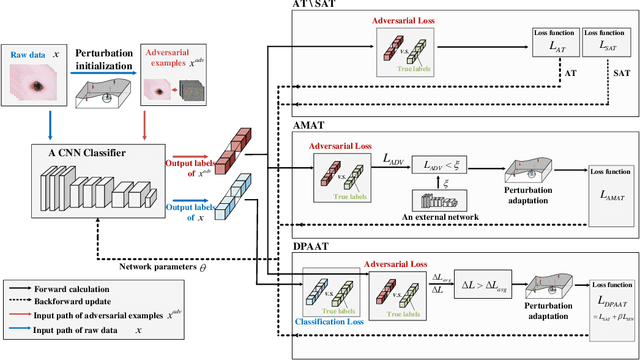

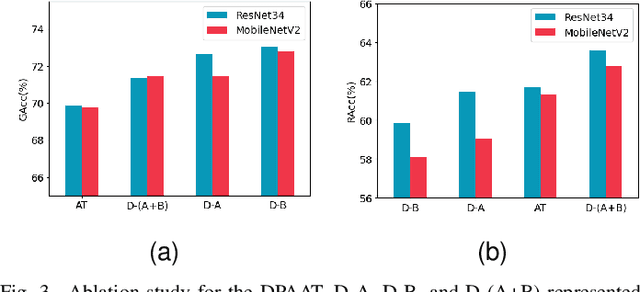
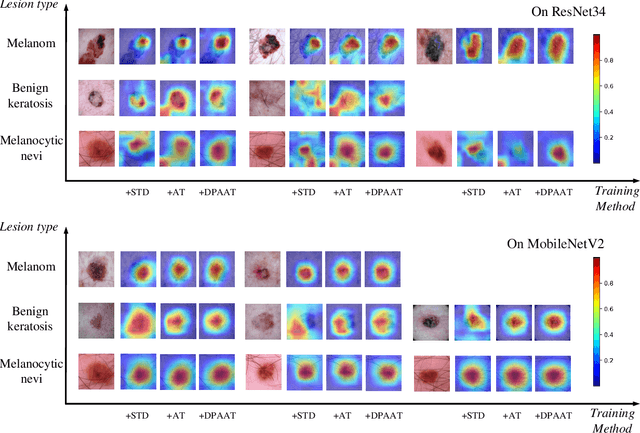
Remarkable successes were made in Medical Image Classification (MIC) recently, mainly due to wide applications of convolutional neural networks (CNNs). However, adversarial examples (AEs) exhibited imperceptible similarity with raw data, raising serious concerns on network robustness. Although adversarial training (AT), in responding to malevolent AEs, was recognized as an effective approach to improve robustness, it was challenging to overcome generalization decline of networks caused by the AT. In this paper, in order to reserve high generalization while improving robustness, we proposed a dynamic perturbation-adaptive adversarial training (DPAAT) method, which placed AT in a dynamic learning environment to generate adaptive data-level perturbations and provided a dynamically updated criterion by loss information collections to handle the disadvantage of fixed perturbation sizes in conventional AT methods and the dependence on external transference. Comprehensive testing on dermatology HAM10000 dataset showed that the DPAAT not only achieved better robustness improvement and generalization preservation but also significantly enhanced mean average precision and interpretability on various CNNs, indicating its great potential as a generic adversarial training method on the MIC.
Prompt-Guided Adaptive Model Transformation for Whole Slide Image Classification
Mar 19, 2024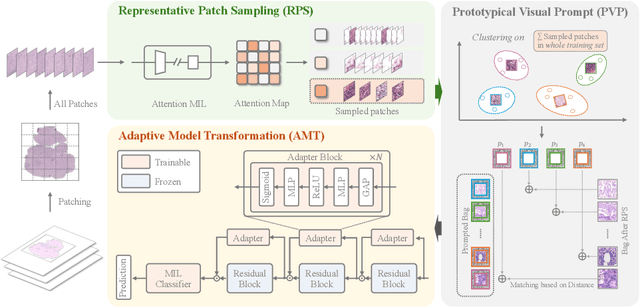
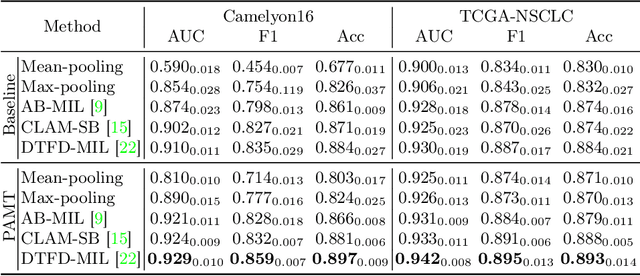

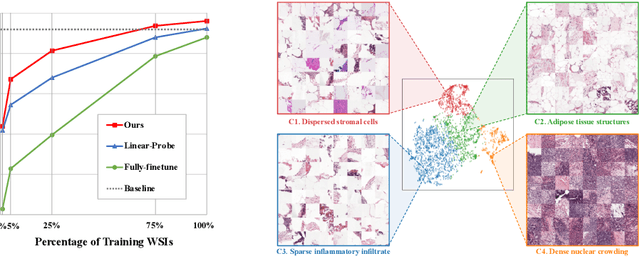
Multiple instance learning (MIL) has emerged as a popular method for classifying histopathology whole slide images (WSIs). Existing approaches typically rely on frozen pre-trained models to extract instance features, neglecting the substantial domain shift between pre-training natural and histopathological images. To address this issue, we propose PAMT, a novel Prompt-guided Adaptive Model Transformation framework that enhances MIL classification performance by seamlessly adapting pre-trained models to the specific characteristics of histopathology data. To capture the intricate histopathology distribution, we introduce Representative Patch Sampling (RPS) and Prototypical Visual Prompt (PVP) to reform the input data, building a compact while informative representation. Furthermore, to narrow the domain gap, we introduce Adaptive Model Transformation (AMT) that integrates adapter blocks within the feature extraction pipeline, enabling the pre-trained models to learn domain-specific features. We rigorously evaluate our approach on two publicly available datasets, Camelyon16 and TCGA-NSCLC, showcasing substantial improvements across various MIL models. Our findings affirm the potential of PAMT to set a new benchmark in WSI classification, underscoring the value of a targeted reprogramming approach.
Deep Few-view High-resolution Photon-counting Extremity CT at Halved Dose for a Clinical Trial
Mar 19, 2024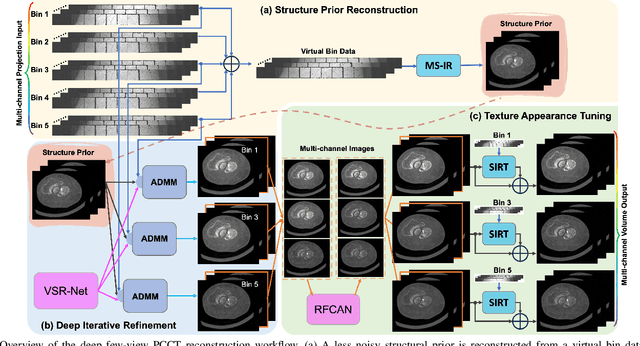
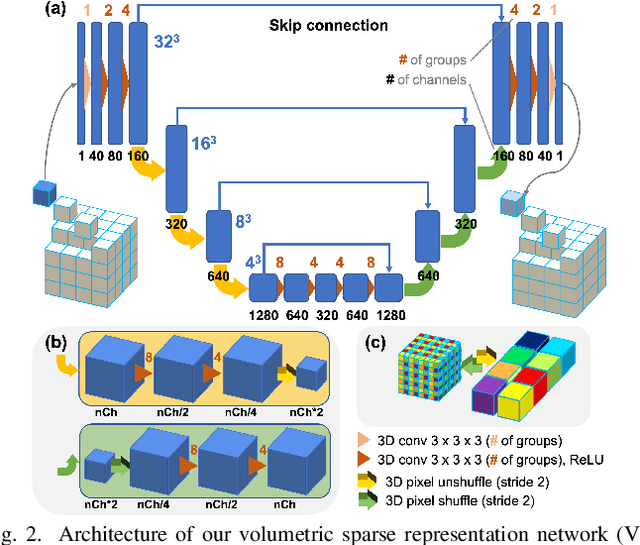
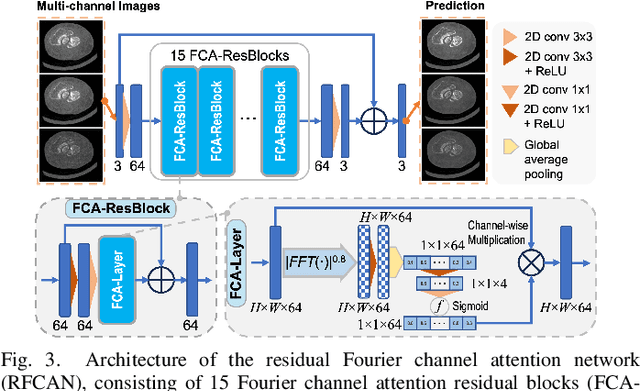
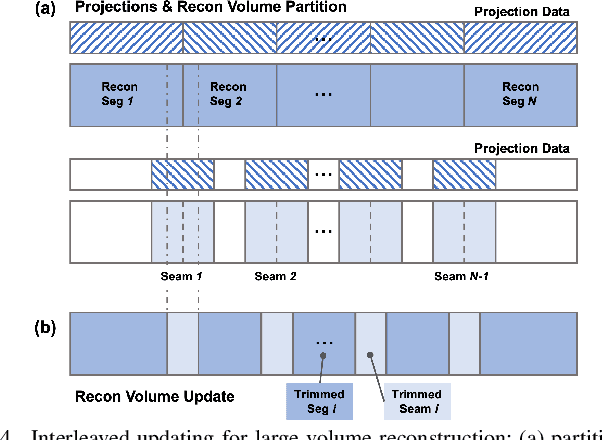
The latest X-ray photon-counting computed tomography (PCCT) for extremity allows multi-energy high-resolution (HR) imaging for tissue characterization and material decomposition. However, both radiation dose and imaging speed need improvement for contrast-enhanced and other studies. Despite the success of deep learning methods for 2D few-view reconstruction, applying them to HR volumetric reconstruction of extremity scans for clinical diagnosis has been limited due to GPU memory constraints, training data scarcity, and domain gap issues. In this paper, we propose a deep learning-based approach for PCCT image reconstruction at halved dose and doubled speed in a New Zealand clinical trial. Particularly, we present a patch-based volumetric refinement network to alleviate the GPU memory limitation, train network with synthetic data, and use model-based iterative refinement to bridge the gap between synthetic and real-world data. The simulation and phantom experiments demonstrate consistently improved results under different acquisition conditions on both in- and off-domain structures using a fixed network. The image quality of 8 patients from the clinical trial are evaluated by three radiologists in comparison with the standard image reconstruction with a full-view dataset. It is shown that our proposed approach is essentially identical to or better than the clinical benchmark in terms of diagnostic image quality scores. Our approach has a great potential to improve the safety and efficiency of PCCT without compromising image quality.
Hyperpixels: Pixel Filter Arrays of Multivariate Optical Elements for Optimized Spectral Imaging
Mar 25, 2024We introduce the concept of `hyperpixels' in which each element of a pixel filter array (suitable for CMOS image sensor integration) has a spectral transmission tailored to a target spectral component expected in application-specific scenes. These are analogous to arrays of multivariate optical elements that could be used for sensing specific analytes. Spectral tailoring is achieved by engineering the heights of multiple sub-pixel Fabry-Perot resonators that cover each pixel area. We first present a design approach for hyperpixels, based on a matched filter concept and, as an exemplar, design a set of 4 hyperpixels tailored to optimally discriminate between 4 spectral reflectance targets. Next, we fabricate repeating 2x2 pixel filter arrays of these designs, alongside repeating 2x2 arrays of an optimal bandpass filters, perform both spectral and imaging characterization. Experimentally measured hyperpixel transmission spectra show a 2.4x reduction in unmixing matrix condition number (p=0.031) compared to the optimal band-pass set. Imaging experiments using the filter arrays with a monochrome sensor achieve a 3.47x reduction in unmixing matrix condition number (p=0.020) compared to the optimal band-pass set. This demonstrates the utility of the hyperpixel approach and shows its superiority even over the optimal bandpass case. We expect that with further improvements in design and fabrication processes increased performance may be obtained. Because the hyperpixels are straightforward to customize, fabricate and can be placed atop monochrome sensors, this approach is highly versatile and could be adapted to a wide range of real-time imaging applications which are limited by low SNR including micro-endoscopy, capsule endoscopy, industrial inspection and machine vision.
Fully automated workflow for the design of patient-specific orthopaedic implants: application to total knee arthroplasty
Mar 25, 2024Arthroplasty is commonly performed to treat joint osteoarthritis, reducing pain and improving mobility. While arthroplasty has known several technical improvements, a significant share of patients are still unsatisfied with their surgery. Personalised arthroplasty improves surgical outcomes however current solutions require delays, making it difficult to integrate in clinical routine. We propose a fully automated workflow to design patient-specific implants, presented for total knee arthroplasty, the most widely performed arthroplasty in the world nowadays. The proposed pipeline first uses artificial neural networks to segment the proximal and distal extremities of the femur and tibia. Then the full bones are reconstructed using augmented statistical shape models, combining shape and landmarks information. Finally, 77 morphological parameters are computed to design patient-specific implants. The developed workflow has been trained using 91 CT scans of lower limb and evaluated on 41 CT scans manually segmented, in terms of accuracy and execution time. The workflow accuracy was $0.4\pm0.2mm$ for the segmentation, $1.2\pm0.4mm$ for the full bones reconstruction, and $2.8\pm2.2mm$ for the anatomical landmarks determination. The custom implants fitted the patients' anatomy with $0.6\pm0.2mm$ accuracy. The whole process from segmentation to implants' design lasted about 5 minutes. The proposed workflow allows for a fast and reliable personalisation of knee implants, directly from the patient CT image without requiring any manual intervention. It establishes a patient-specific pre-operative planning for TKA in a very short time making it easily available for all patients. Combined with efficient implant manufacturing techniques, this solution could help answer the growing number of arthroplasties while reducing complications and improving the patients' satisfaction.
StableDrag: Stable Dragging for Point-based Image Editing
Mar 07, 2024
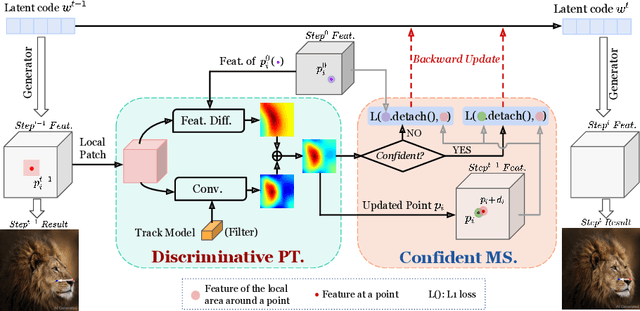
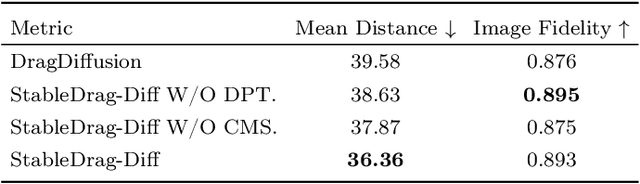
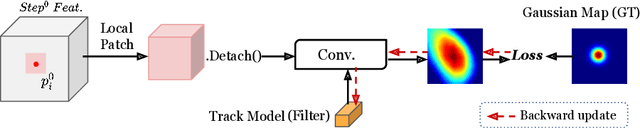
Point-based image editing has attracted remarkable attention since the emergence of DragGAN. Recently, DragDiffusion further pushes forward the generative quality via adapting this dragging technique to diffusion models. Despite these great success, this dragging scheme exhibits two major drawbacks, namely inaccurate point tracking and incomplete motion supervision, which may result in unsatisfactory dragging outcomes. To tackle these issues, we build a stable and precise drag-based editing framework, coined as StableDrag, by designing a discirminative point tracking method and a confidence-based latent enhancement strategy for motion supervision. The former allows us to precisely locate the updated handle points, thereby boosting the stability of long-range manipulation, while the latter is responsible for guaranteeing the optimized latent as high-quality as possible across all the manipulation steps. Thanks to these unique designs, we instantiate two types of image editing models including StableDrag-GAN and StableDrag-Diff, which attains more stable dragging performance, through extensive qualitative experiments and quantitative assessment on DragBench.
Explorative Inbetweening of Time and Space
Mar 21, 2024



We introduce bounded generation as a generalized task to control video generation to synthesize arbitrary camera and subject motion based only on a given start and end frame. Our objective is to fully leverage the inherent generalization capability of an image-to-video model without additional training or fine-tuning of the original model. This is achieved through the proposed new sampling strategy, which we call Time Reversal Fusion, that fuses the temporally forward and backward denoising paths conditioned on the start and end frame, respectively. The fused path results in a video that smoothly connects the two frames, generating inbetweening of faithful subject motion, novel views of static scenes, and seamless video looping when the two bounding frames are identical. We curate a diverse evaluation dataset of image pairs and compare against the closest existing methods. We find that Time Reversal Fusion outperforms related work on all subtasks, exhibiting the ability to generate complex motions and 3D-consistent views guided by bounded frames. See project page at https://time-reversal.github.io.