 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Joint Multi-Scale Tone Mapping and Denoising for HDR Image Enhancement
Mar 23, 2023
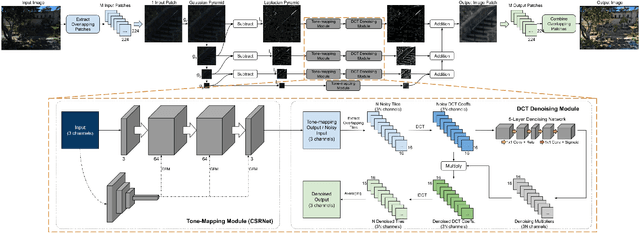

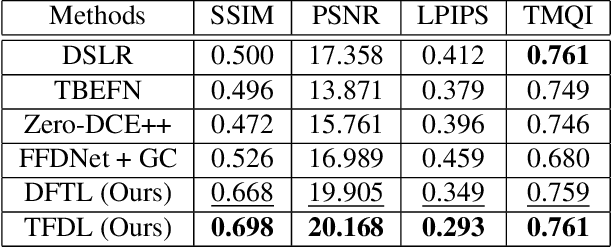
An image processing unit (IPU), or image signal processor (ISP) for high dynamic range (HDR) imaging usually consists of demosaicing, white balancing, lens shading correction, color correction, denoising, and tone-mapping. Besides noise from the imaging sensors, almost every step in the ISP introduces or amplifies noise in different ways, and denoising operators are designed to reduce the noise from these sources. Designed for dynamic range compressing, tone-mapping operators in an ISP can significantly amplify the noise level, especially for images captured in low-light conditions, making denoising very difficult. Therefore, we propose a joint multi-scale denoising and tone-mapping framework that is designed with both operations in mind for HDR images. Our joint network is trained in an end-to-end format that optimizes both operators together, to prevent the tone-mapping operator from overwhelming the denoising operator. Our model outperforms existing HDR denoising and tone-mapping operators both quantitatively and qualitatively on most of our benchmarking datasets.
Context-Based Trit-Plane Coding for Progressive Image Compression
Mar 13, 2023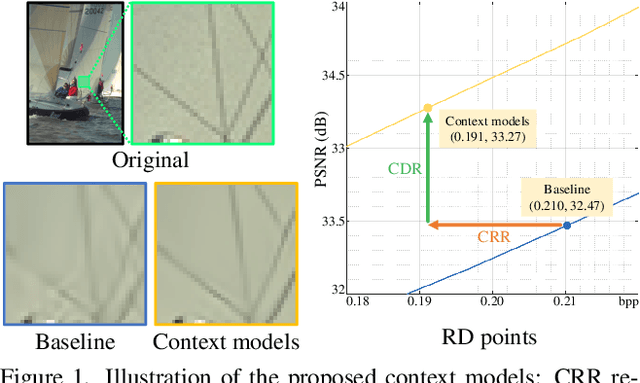
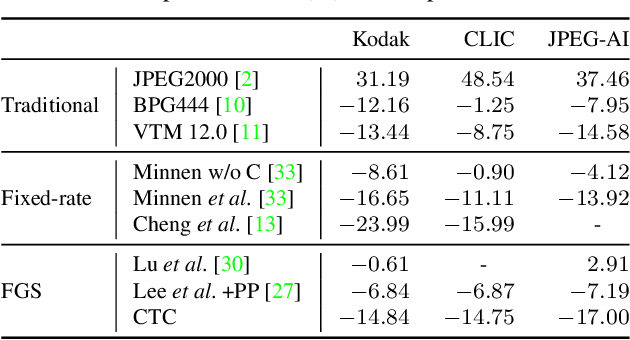
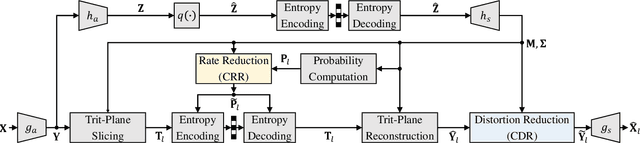
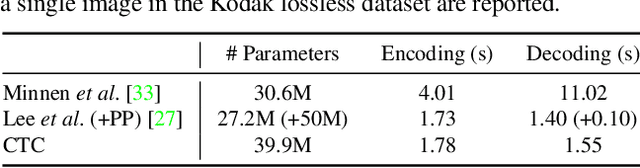
Trit-plane coding enables deep progressive image compression, but it cannot use autoregressive context models. In this paper, we propose the context-based trit-plane coding (CTC) algorithm to achieve progressive compression more compactly. First, we develop the context-based rate reduction module to estimate trit probabilities of latent elements accurately and thus encode the trit-planes compactly. Second, we develop the context-based distortion reduction module to refine partial latent tensors from the trit-planes and improve the reconstructed image quality. Third, we propose a retraining scheme for the decoder to attain better rate-distortion tradeoffs. Extensive experiments show that CTC outperforms the baseline trit-plane codec significantly in BD-rate on the Kodak lossless dataset, while increasing the time complexity only marginally. Our codes are available at https://github.com/seungminjeon-github/CTC.
Dual Cross-Attention for Medical Image Segmentation
Mar 30, 2023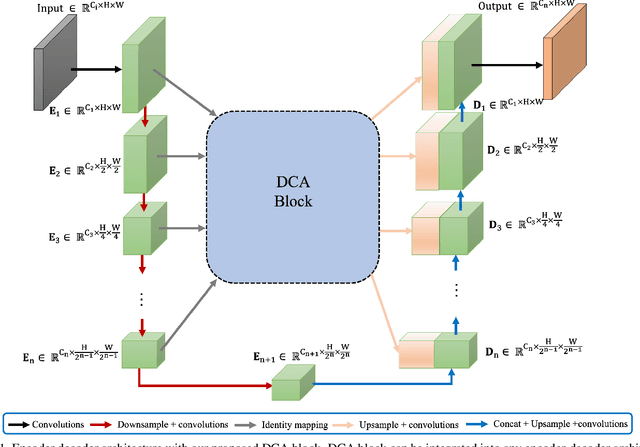
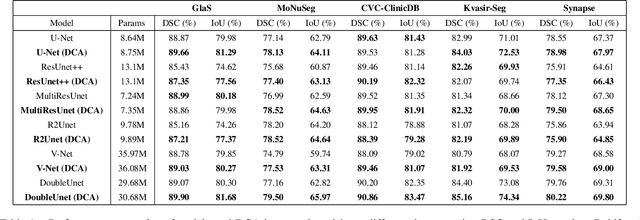
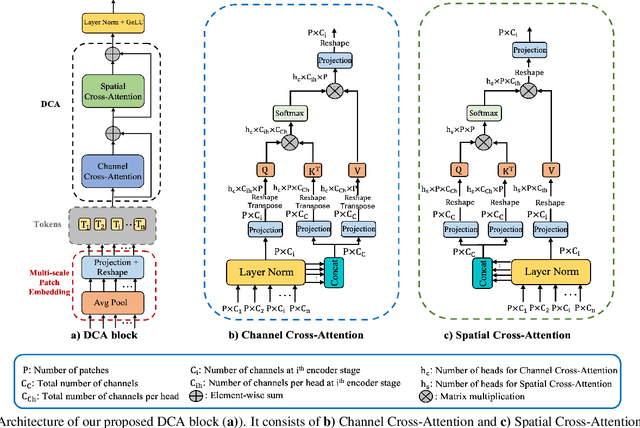
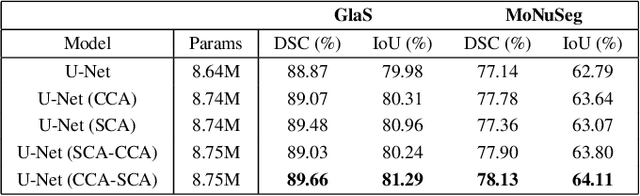
We propose Dual Cross-Attention (DCA), a simple yet effective attention module that is able to enhance skip-connections in U-Net-based architectures for medical image segmentation. DCA addresses the semantic gap between encoder and decoder features by sequentially capturing channel and spatial dependencies across multi-scale encoder features. First, the Channel Cross-Attention (CCA) extracts global channel-wise dependencies by utilizing cross-attention across channel tokens of multi-scale encoder features. Then, the Spatial Cross-Attention (SCA) module performs cross-attention to capture spatial dependencies across spatial tokens. Finally, these fine-grained encoder features are up-sampled and connected to their corresponding decoder parts to form the skip-connection scheme. Our proposed DCA module can be integrated into any encoder-decoder architecture with skip-connections such as U-Net and its variants. We test our DCA module by integrating it into six U-Net-based architectures such as U-Net, V-Net, R2Unet, ResUnet++, DoubleUnet and MultiResUnet. Our DCA module shows Dice Score improvements up to 2.05% on GlaS, 2.74% on MoNuSeg, 1.37% on CVC-ClinicDB, 1.12% on Kvasir-Seg and 1.44% on Synapse datasets. Our codes are available at: https://github.com/gorkemcanates/Dual-Cross-Attention
Beat Pilot Tone: Versatile, Contact-Free Motion Sensing in MRI with Radio Frequency Intermodulation
Jun 17, 2023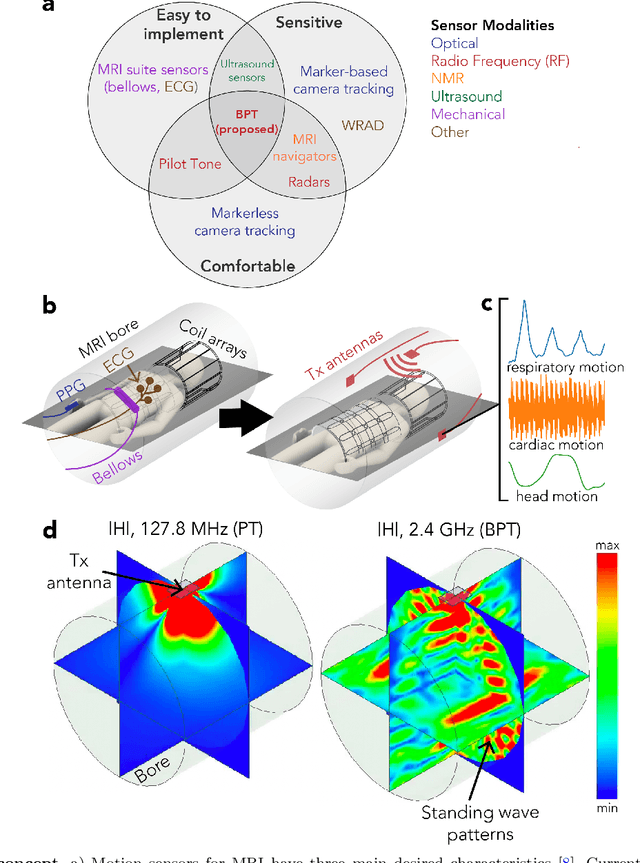
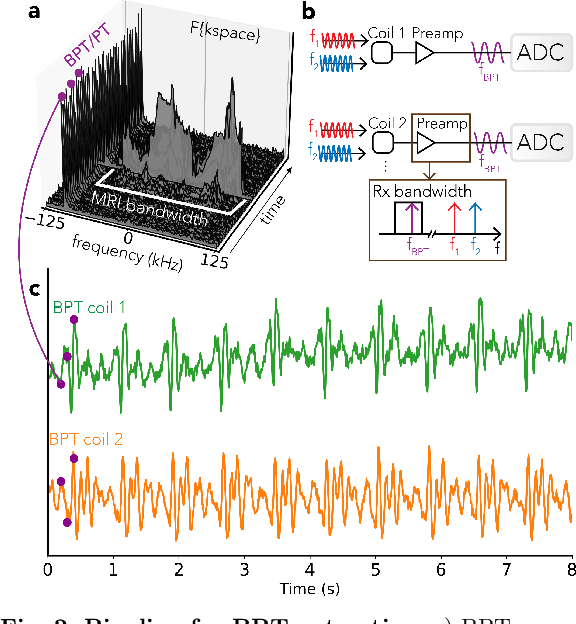
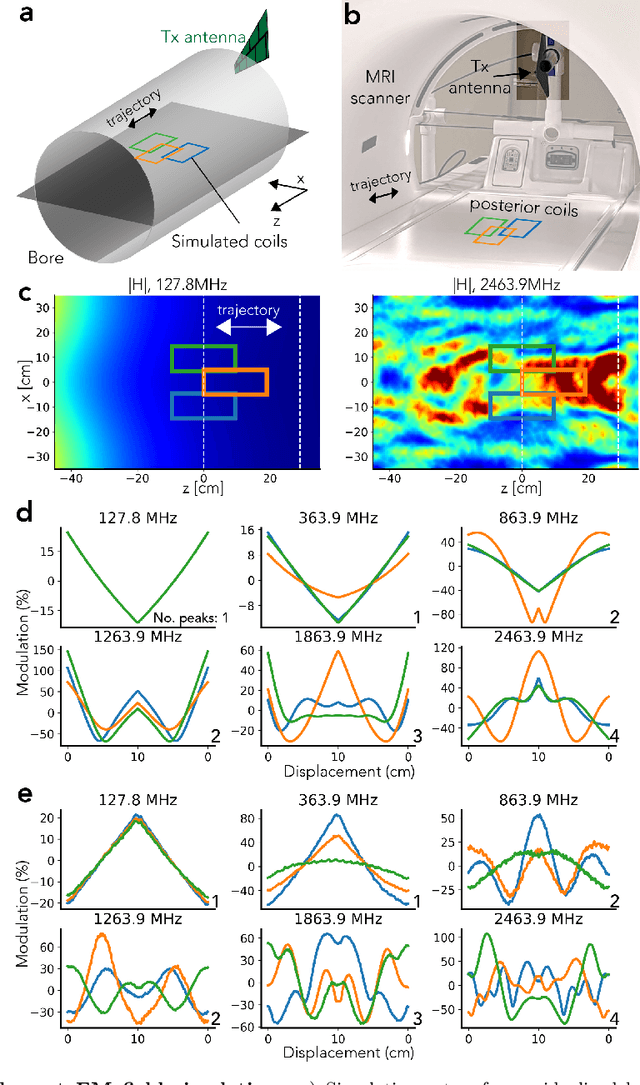
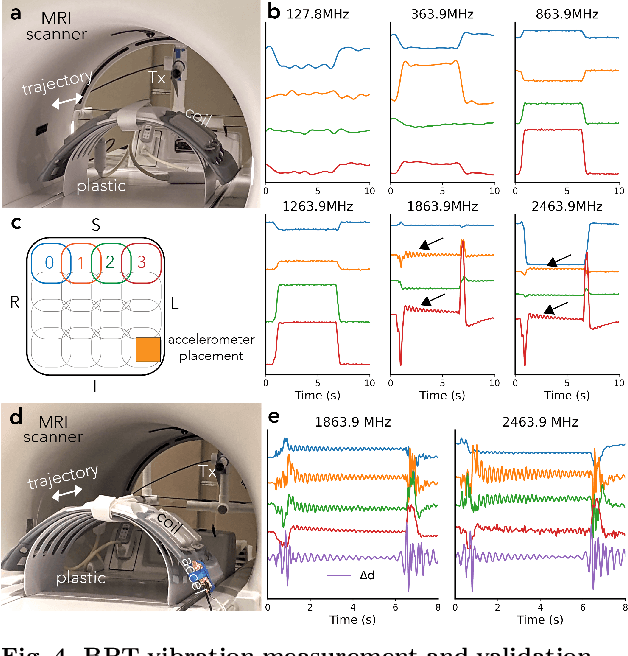
Motion in Magnetic Resonance Imaging (MRI) scans results in image corruption and remains a barrier to clinical imaging. Motion correction algorithms require accurate sensing, but existing sensors are limited in sensitivity, comfort, or general usability. We propose Beat Pilot Tone (BPT), a radio frequency (RF) motion sensing system that is sensitive, comfortable, versatile, and scalable. BPT operates by a novel mechanism: two or more transmitted RF tones form standing wave patterns that are modulated by motion and sensed by the same receiver coil arrays used for MR imaging. By serendipity, the tones are mixed through nonlinear intermodulation in the receiver chain and digitized simultaneously with the MRI data. We demonstrate BPT's mechanism in simulations and experiments. Furthermore, we show in healthy volunteers that BPT can sense head, bulk, respiratory, and cardiac motion, including small vibrations such as displacement ballistocardiograms. BPT can distinguish between different motion types, achieve greater sensitivity than other methods, and operate as a multiple-input multiple-output (MIMO) system. Thus, BPT can enable motion-robust MRI scans at high spatiotemporal resolution in many applications.
StructuredMesh: 3D Structured Optimization of Façade Components on Photogrammetric Mesh Models using Binary Integer Programming
Jun 07, 2023
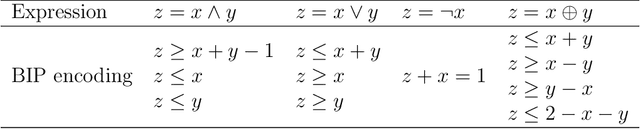
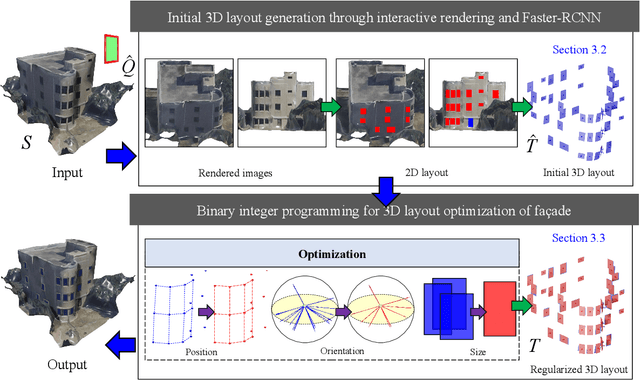
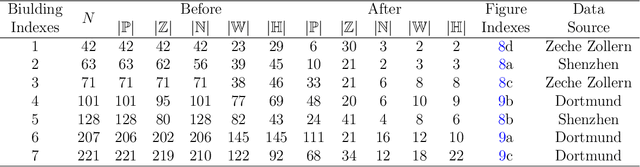
The lack of fa\c{c}ade structures in photogrammetric mesh models renders them inadequate for meeting the demands of intricate applications. Moreover, these mesh models exhibit irregular surfaces with considerable geometric noise and texture quality imperfections, making the restoration of structures challenging. To address these shortcomings, we present StructuredMesh, a novel approach for reconstructing fa\c{c}ade structures conforming to the regularity of buildings within photogrammetric mesh models. Our method involves capturing multi-view color and depth images of the building model using a virtual camera and employing a deep learning object detection pipeline to semi-automatically extract the bounding boxes of fa\c{c}ade components such as windows, doors, and balconies from the color image. We then utilize the depth image to remap these boxes into 3D space, generating an initial fa\c{c}ade layout. Leveraging architectural knowledge, we apply binary integer programming (BIP) to optimize the 3D layout's structure, encompassing the positions, orientations, and sizes of all components. The refined layout subsequently informs fa\c{c}ade modeling through instance replacement. We conducted experiments utilizing building mesh models from three distinct datasets, demonstrating the adaptability, robustness, and noise resistance of our proposed methodology. Furthermore, our 3D layout evaluation metrics reveal that the optimized layout enhances precision, recall, and F-score by 6.5%, 4.5%, and 5.5%, respectively, in comparison to the initial layout.
Occ-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction
Jun 07, 2023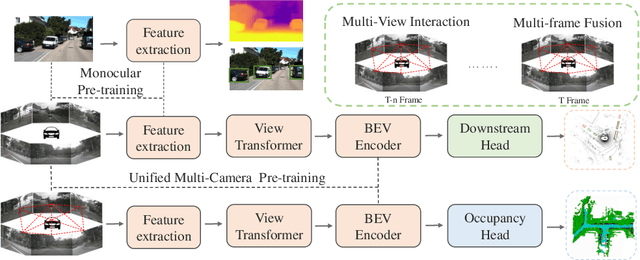
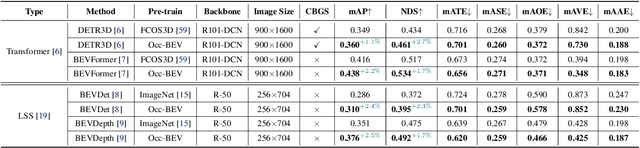
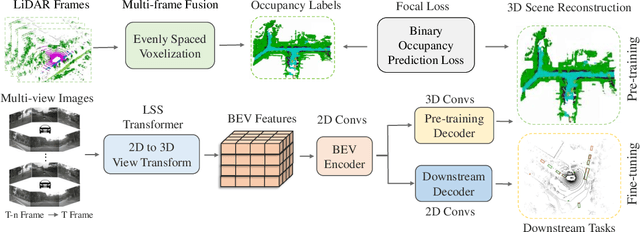

Multi-camera 3D perception has emerged as a prominent research field in autonomous driving, offering a viable and cost-effective alternative to LiDAR-based solutions. However, existing multi-camera algorithms primarily rely on monocular image pre-training, which overlooks the spatial and temporal correlations among different camera views. To address this limitation, we propose the first multi-camera unified pre-training framework called Occ-BEV, which involves initially reconstructing the 3D scene as the foundational stage and subsequently fine-tuning the model on downstream tasks. Specifically, a 3D decoder is designed for leveraging Bird's Eye View (BEV) features from multi-view images to predict the 3D geometric occupancy to enable the model to capture a more comprehensive understanding of the 3D environment. A significant benefit of Occ-BEV is its capability of utilizing a considerable volume of unlabeled image-LiDAR pairs for pre-training purposes. The proposed multi-camera unified pre-training framework demonstrates promising results in key tasks such as multi-camera 3D object detection and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, Occ-BEV shows a significant improvement of about 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. Codes are publicly available at https://github.com/chaytonmin/Occ-BEV.
End-to-end Knowledge Retrieval with Multi-modal Queries
Jun 01, 2023

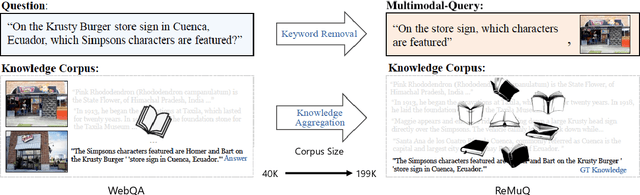
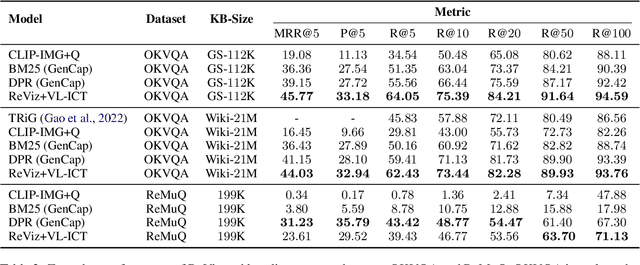
We investigate knowledge retrieval with multi-modal queries, i.e. queries containing information split across image and text inputs, a challenging task that differs from previous work on cross-modal retrieval. We curate a new dataset called ReMuQ for benchmarking progress on this task. ReMuQ requires a system to retrieve knowledge from a large corpus by integrating contents from both text and image queries. We introduce a retriever model ``ReViz'' that can directly process input text and images to retrieve relevant knowledge in an end-to-end fashion without being dependent on intermediate modules such as object detectors or caption generators. We introduce a new pretraining task that is effective for learning knowledge retrieval with multimodal queries and also improves performance on downstream tasks. We demonstrate superior performance in retrieval on two datasets (ReMuQ and OK-VQA) under zero-shot settings as well as further improvements when finetuned on these datasets.
Sea Ice Extraction via Remote Sensed Imagery: Algorithms, Datasets, Applications and Challenges
Jun 01, 2023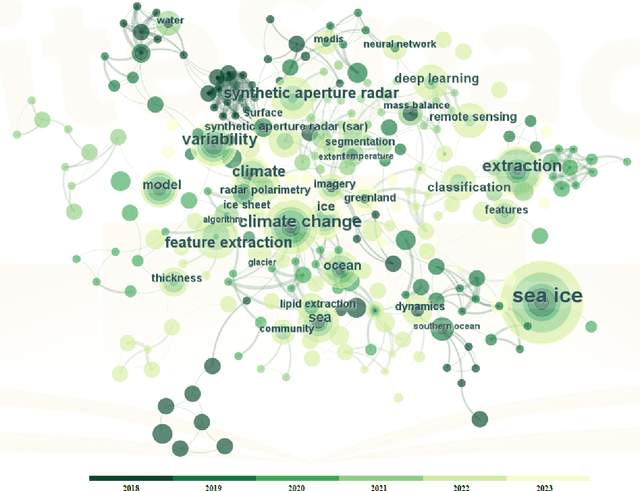
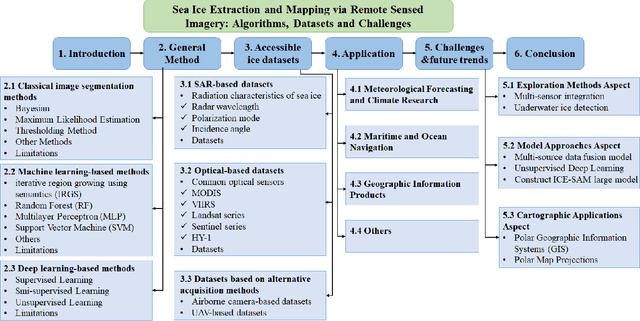
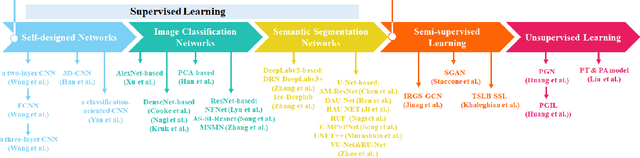
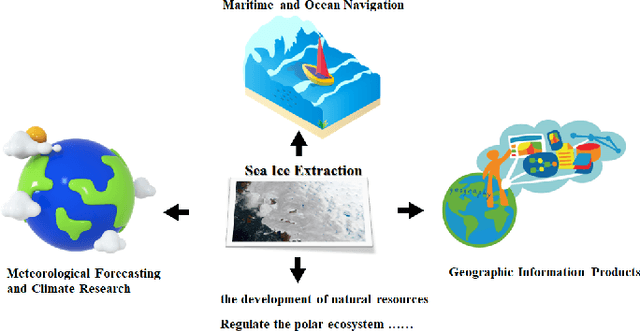
The deep learning, which is a dominating technique in artificial intelligence, has completely changed the image understanding over the past decade. As a consequence, the sea ice extraction (SIE) problem has reached a new era. We present a comprehensive review of four important aspects of SIE, including algorithms, datasets, applications, and the future trends. Our review focuses on researches published from 2016 to the present, with a specific focus on deep learning-based approaches in the last five years. We divided all relegated algorithms into 3 categories, including classical image segmentation approach, machine learning-based approach and deep learning-based methods. We reviewed the accessible ice datasets including SAR-based datasets, the optical-based datasets and others. The applications are presented in 4 aspects including climate research, navigation, geographic information systems (GIS) production and others. It also provides insightful observations and inspiring future research directions.
Spectral Enhanced Rectangle Transformer for Hyperspectral Image Denoising
Apr 03, 2023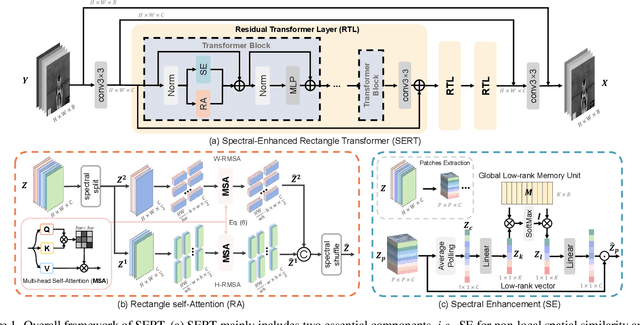
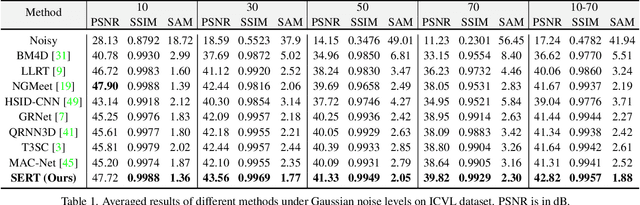
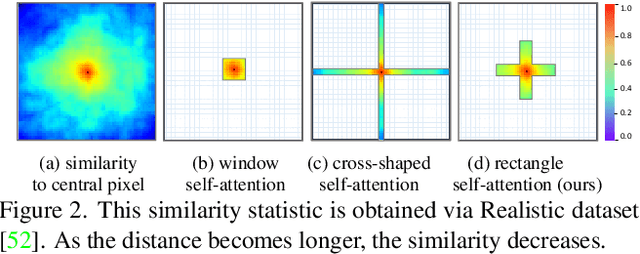
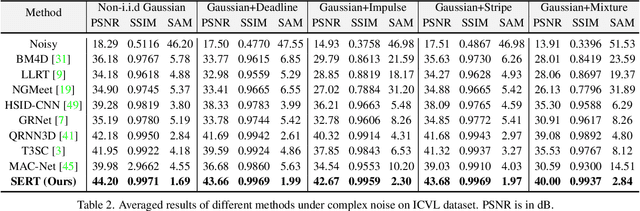
Denoising is a crucial step for hyperspectral image (HSI) applications. Though witnessing the great power of deep learning, existing HSI denoising methods suffer from limitations in capturing the non-local self-similarity. Transformers have shown potential in capturing long-range dependencies, but few attempts have been made with specifically designed Transformer to model the spatial and spectral correlation in HSIs. In this paper, we address these issues by proposing a spectral enhanced rectangle Transformer, driving it to explore the non-local spatial similarity and global spectral low-rank property of HSIs. For the former, we exploit the rectangle self-attention horizontally and vertically to capture the non-local similarity in the spatial domain. For the latter, we design a spectral enhancement module that is capable of extracting global underlying low-rank property of spatial-spectral cubes to suppress noise, while enabling the interactions among non-overlapping spatial rectangles. Extensive experiments have been conducted on both synthetic noisy HSIs and real noisy HSIs, showing the effectiveness of our proposed method in terms of both objective metric and subjective visual quality. The code is available at https://github.com/MyuLi/SERT.
GazeGNN: A Gaze-Guided Graph Neural Network for Disease Classification
May 29, 2023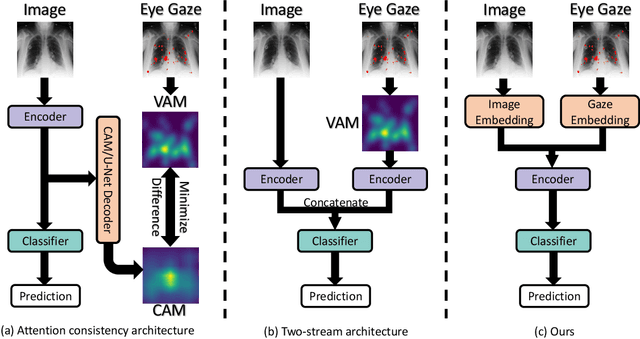

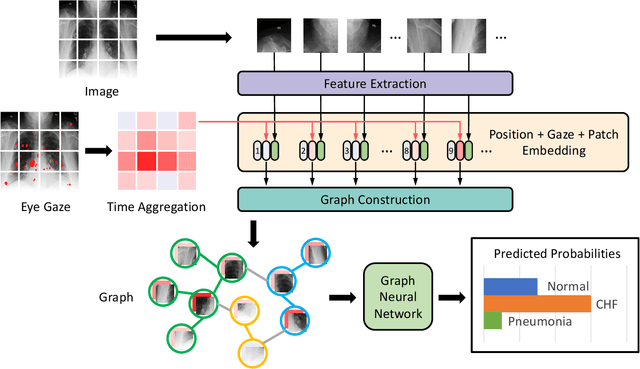

The application of eye-tracking techniques in medical image analysis has become increasingly popular in recent years. It collects the visual search patterns of the domain experts, containing much important information about health and disease. Therefore, how to efficiently integrate radiologists' gaze patterns into the diagnostic analysis turns into a critical question. Existing works usually transform gaze information into visual attention maps (VAMs) to supervise the learning process. However, this time-consuming procedure makes it difficult to develop end-to-end algorithms. In this work, we propose a novel gaze-guided graph neural network (GNN), GazeGNN, to perform disease classification from medical scans. In GazeGNN, we create a unified representation graph that models both the image and gaze pattern information. Hence, the eye-gaze information is directly utilized without being converted into VAMs. With this benefit, we develop a real-time, real-world, end-to-end disease classification algorithm for the first time and avoid the noise and time consumption introduced during the VAM preparation. To our best knowledge, GazeGNN is the first work that adopts GNN to integrate image and eye-gaze data. Our experiments on the public chest X-ray dataset show that our proposed method exhibits the best classification performance compared to existing methods.