 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Customizing General-Purpose Foundation Models for Medical Report Generation
Jun 09, 2023

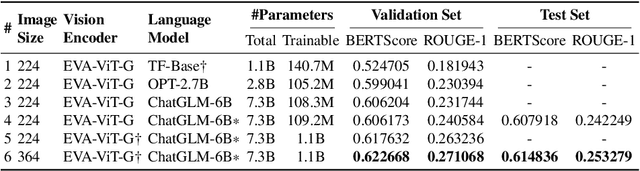


Medical caption prediction which can be regarded as a task of medical report generation (MRG), requires the automatic generation of coherent and accurate captions for the given medical images. However, the scarcity of labelled medical image-report pairs presents great challenges in the development of deep and large-scale neural networks capable of harnessing the potential artificial general intelligence power like large language models (LLMs). In this work, we propose customizing off-the-shelf general-purpose large-scale pre-trained models, i.e., foundation models (FMs), in computer vision and natural language processing with a specific focus on medical report generation. Specifically, following BLIP-2, a state-of-the-art vision-language pre-training approach, we introduce our encoder-decoder-based MRG model. This model utilizes a lightweight query Transformer to connect two FMs: the giant vision Transformer EVA-ViT-g and a bilingual LLM trained to align with human intentions (referred to as ChatGLM-6B). Furthermore, we conduct ablative experiments on the trainable components of the model to identify the crucial factors for effective transfer learning. Our findings demonstrate that unfreezing EVA-ViT-g to learn medical image representations, followed by parameter-efficient training of ChatGLM-6B to capture the writing styles of medical reports, is essential for achieving optimal results. Our best attempt (PCLmed Team) achieved the 4th and the 2nd, respectively, out of 13 participating teams, based on the BERTScore and ROUGE-1 metrics, in the ImageCLEFmedical Caption 2023 Caption Prediction Task competition.
Parts of Speech-Grounded Subspaces in Vision-Language Models
May 23, 2023

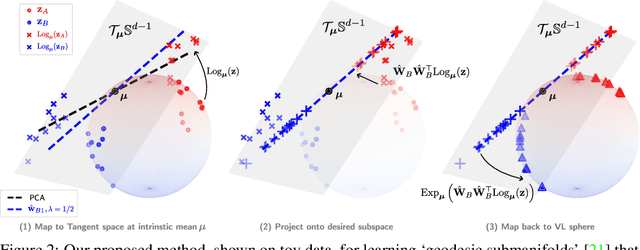
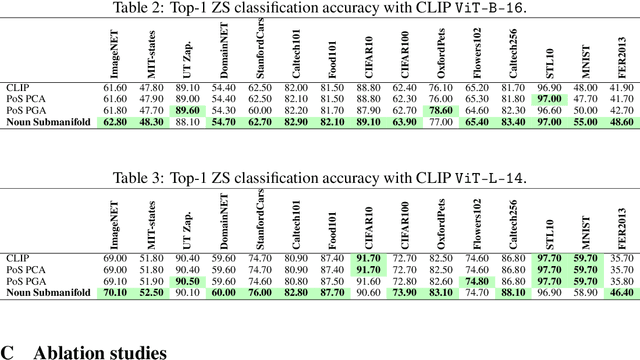
Latent image representations arising from vision-language models have proved immensely useful for a variety of downstream tasks. However, their utility is limited by their entanglement with respect to different visual attributes. For instance, recent work has shown that CLIP image representations are often biased toward specific visual properties (such as objects or actions) in an unpredictable manner. In this paper, we propose to separate representations of the different visual modalities in CLIP's joint vision-language space by leveraging the association between parts of speech and specific visual modes of variation (e.g. nouns relate to objects, adjectives describe appearance). This is achieved by formulating an appropriate component analysis model that learns subspaces capturing variability corresponding to a specific part of speech, while jointly minimising variability to the rest. Such a subspace yields disentangled representations of the different visual properties of an image or text in closed form while respecting the underlying geometry of the manifold on which the representations lie. What's more, we show the proposed model additionally facilitates learning subspaces corresponding to specific visual appearances (e.g. artists' painting styles), which enables the selective removal of entire visual themes from CLIP-based text-to-image synthesis. We validate the model both qualitatively, by visualising the subspace projections with a text-to-image model and by preventing the imitation of artists' styles, and quantitatively, through class invariance metrics and improvements to baseline zero-shot classification. Our code is available at: https://github.com/james-oldfield/PoS-subspaces.
WavPool: A New Block for Deep Neural Networks
Jun 14, 2023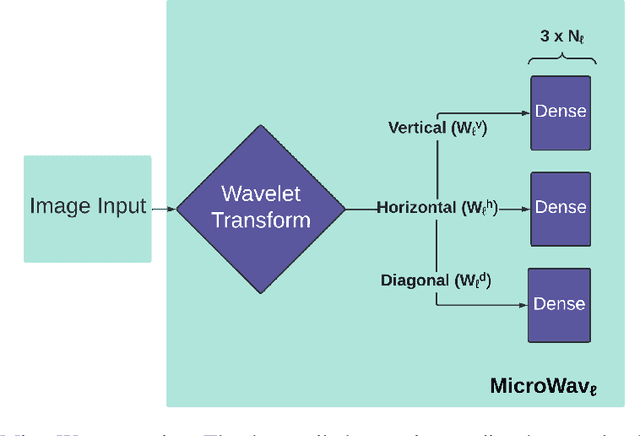
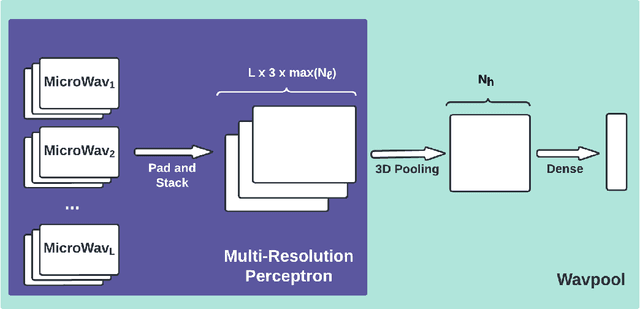
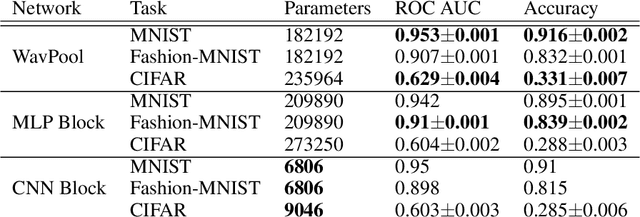
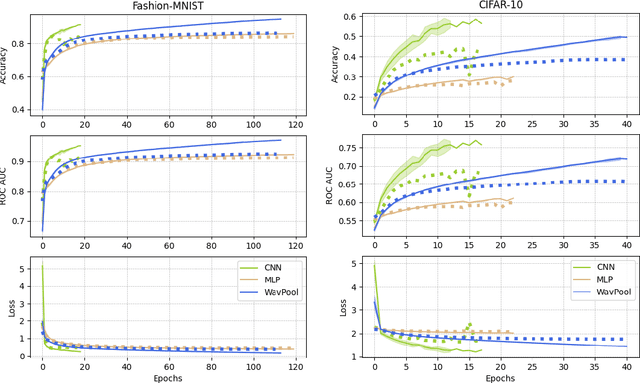
Modern deep neural networks comprise many operational layers, such as dense or convolutional layers, which are often collected into blocks. In this work, we introduce a new, wavelet-transform-based network architecture that we call the multi-resolution perceptron: by adding a pooling layer, we create a new network block, the WavPool. The first step of the multi-resolution perceptron is transforming the data into its multi-resolution decomposition form by convolving the input data with filters of fixed coefficients but increasing size. Following image processing techniques, we are able to make scale and spatial information simultaneously accessible to the network without increasing the size of the data vector. WavPool outperforms a similar multilayer perceptron while using fewer parameters, and outperforms a comparable convolutional neural network by ~ 10% on relative accuracy on CIFAR-10.
Dual Cross-Attention for Medical Image Segmentation
Mar 30, 2023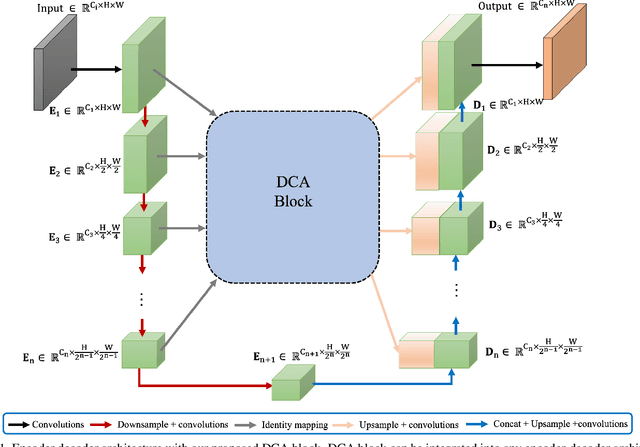
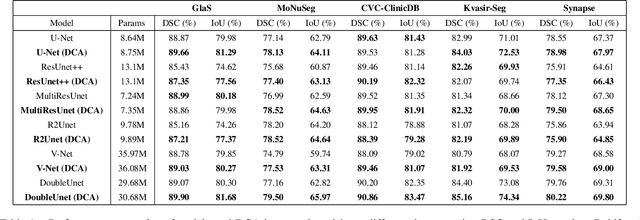
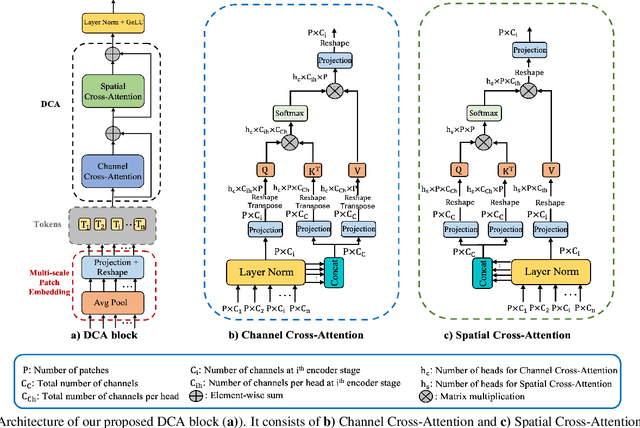
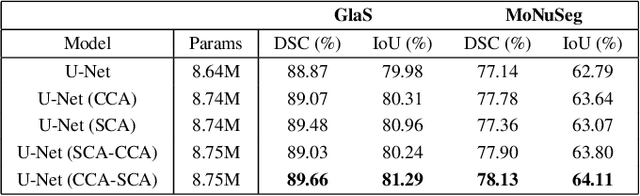
We propose Dual Cross-Attention (DCA), a simple yet effective attention module that is able to enhance skip-connections in U-Net-based architectures for medical image segmentation. DCA addresses the semantic gap between encoder and decoder features by sequentially capturing channel and spatial dependencies across multi-scale encoder features. First, the Channel Cross-Attention (CCA) extracts global channel-wise dependencies by utilizing cross-attention across channel tokens of multi-scale encoder features. Then, the Spatial Cross-Attention (SCA) module performs cross-attention to capture spatial dependencies across spatial tokens. Finally, these fine-grained encoder features are up-sampled and connected to their corresponding decoder parts to form the skip-connection scheme. Our proposed DCA module can be integrated into any encoder-decoder architecture with skip-connections such as U-Net and its variants. We test our DCA module by integrating it into six U-Net-based architectures such as U-Net, V-Net, R2Unet, ResUnet++, DoubleUnet and MultiResUnet. Our DCA module shows Dice Score improvements up to 2.05% on GlaS, 2.74% on MoNuSeg, 1.37% on CVC-ClinicDB, 1.12% on Kvasir-Seg and 1.44% on Synapse datasets. Our codes are available at: https://github.com/gorkemcanates/Dual-Cross-Attention
ASU-CNN: An Efficient Deep Architecture for Image Classification and Feature Visualizations
May 28, 2023
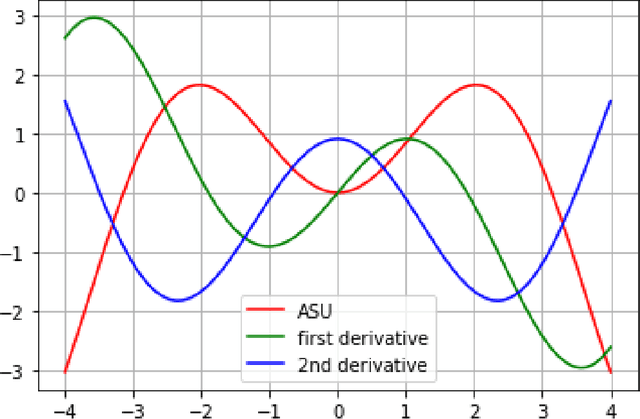
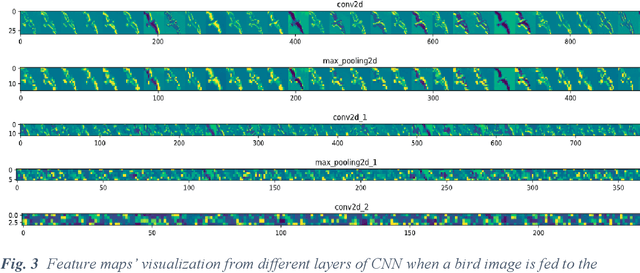
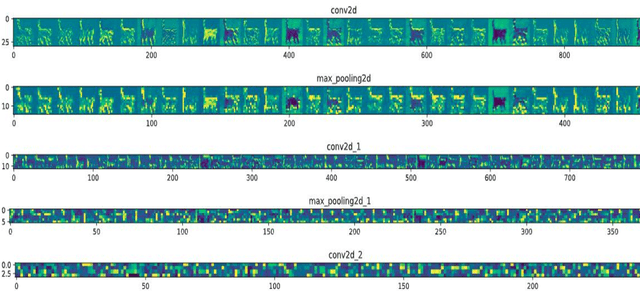
Activation functions play a decisive role in determining the capacity of Deep Neural Networks as they enable neural networks to capture inherent nonlinearities present in data fed to them. The prior research on activation functions primarily focused on the utility of monotonic or non-oscillatory functions, until Growing Cosine Unit broke the taboo for a number of applications. In this paper, a Convolutional Neural Network model named as ASU-CNN is proposed which utilizes recently designed activation function ASU across its layers. The effect of this non-monotonic and oscillatory function is inspected through feature map visualizations from different convolutional layers. The optimization of proposed network is offered by Adam with a fine-tuned adjustment of learning rate. The network achieved promising results on both training and testing data for the classification of CIFAR-10. The experimental results affirm the computational feasibility and efficacy of the proposed model for performing tasks related to the field of computer vision.
MotionVideoGAN: A Novel Video Generator Based on the Motion Space Learned from Image Pairs
Mar 06, 2023



Video generation has achieved rapid progress benefiting from high-quality renderings provided by powerful image generators. We regard the video synthesis task as generating a sequence of images sharing the same contents but varying in motions. However, most previous video synthesis frameworks based on pre-trained image generators treat content and motion generation separately, leading to unrealistic generated videos. Therefore, we design a novel framework to build the motion space, aiming to achieve content consistency and fast convergence for video generation. We present MotionVideoGAN, a novel video generator synthesizing videos based on the motion space learned by pre-trained image pair generators. Firstly, we propose an image pair generator named MotionStyleGAN to generate image pairs sharing the same contents and producing various motions. Then we manage to acquire motion codes to edit one image in the generated image pairs and keep the other unchanged. The motion codes help us edit images within the motion space since the edited image shares the same contents with the other unchanged one in image pairs. Finally, we introduce a latent code generator to produce latent code sequences using motion codes for video generation. Our approach achieves state-of-the-art performance on the most complex video dataset ever used for unconditional video generation evaluation, UCF101.
Spectral Enhanced Rectangle Transformer for Hyperspectral Image Denoising
Apr 03, 2023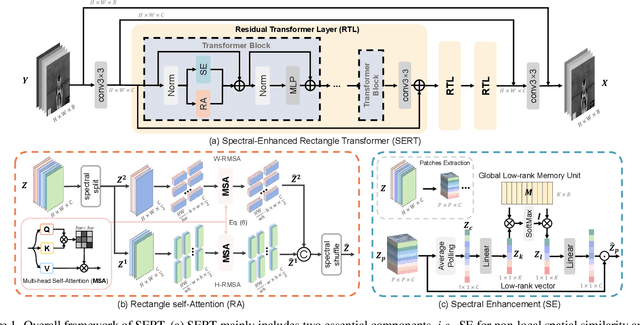
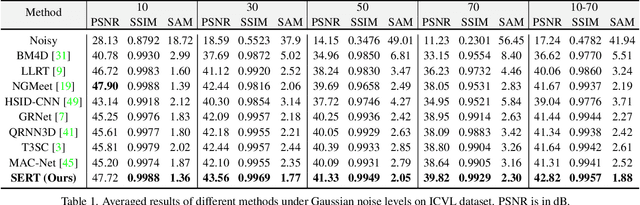
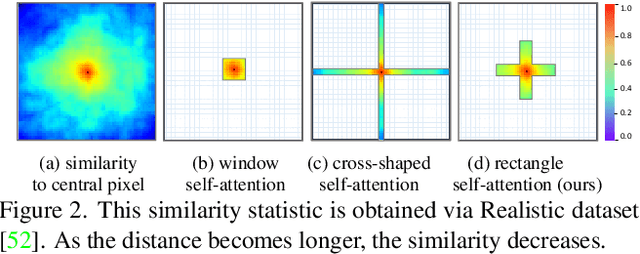
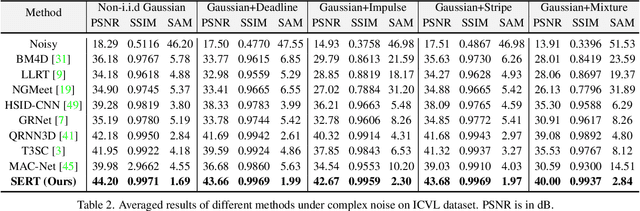
Denoising is a crucial step for hyperspectral image (HSI) applications. Though witnessing the great power of deep learning, existing HSI denoising methods suffer from limitations in capturing the non-local self-similarity. Transformers have shown potential in capturing long-range dependencies, but few attempts have been made with specifically designed Transformer to model the spatial and spectral correlation in HSIs. In this paper, we address these issues by proposing a spectral enhanced rectangle Transformer, driving it to explore the non-local spatial similarity and global spectral low-rank property of HSIs. For the former, we exploit the rectangle self-attention horizontally and vertically to capture the non-local similarity in the spatial domain. For the latter, we design a spectral enhancement module that is capable of extracting global underlying low-rank property of spatial-spectral cubes to suppress noise, while enabling the interactions among non-overlapping spatial rectangles. Extensive experiments have been conducted on both synthetic noisy HSIs and real noisy HSIs, showing the effectiveness of our proposed method in terms of both objective metric and subjective visual quality. The code is available at https://github.com/MyuLi/SERT.
Efficient Skip Connections Realization for Secure Inference on Encrypted Data
Jun 11, 2023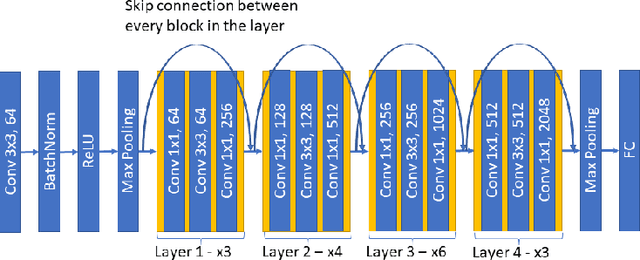
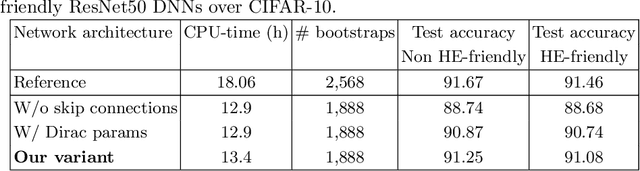
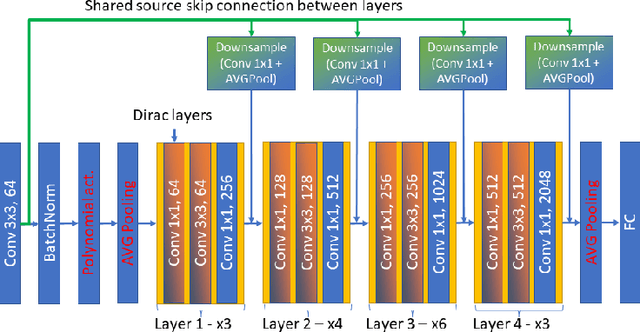
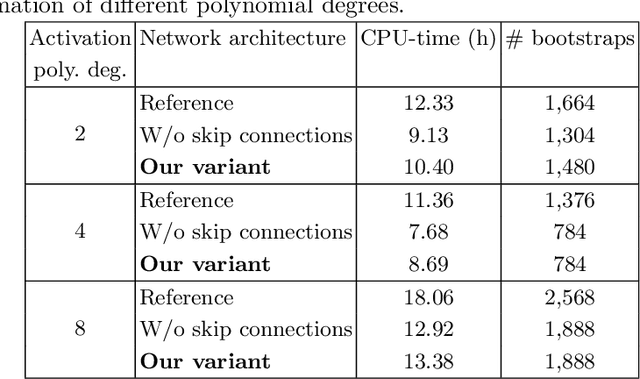
Homomorphic Encryption (HE) is a cryptographic tool that allows performing computation under encryption, which is used by many privacy-preserving machine learning solutions, for example, to perform secure classification. Modern deep learning applications yield good performance for example in image processing tasks benchmarks by including many skip connections. The latter appears to be very costly when attempting to execute model inference under HE. In this paper, we show that by replacing (mid-term) skip connections with (short-term) Dirac parameterization and (long-term) shared-source skip connection we were able to reduce the skip connections burden for HE-based solutions, achieving x1.3 computing power improvement for the same accuracy.
Multimodal Hyperspectral Image Classification via Interconnected Fusion
Apr 02, 2023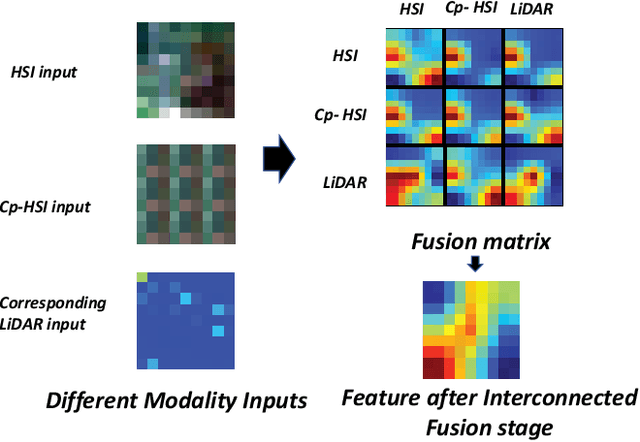
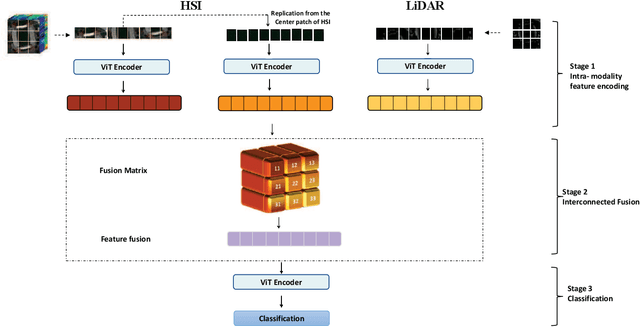
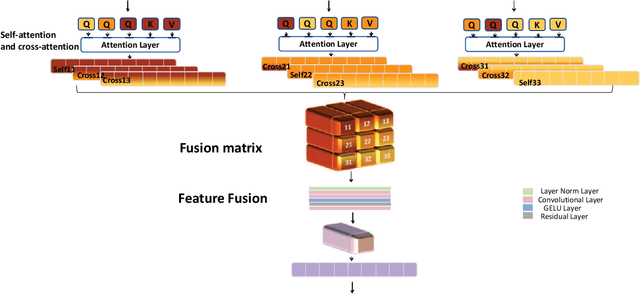
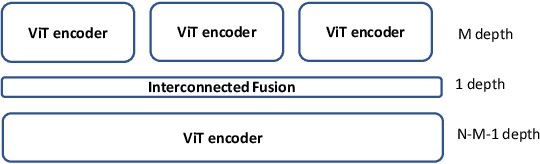
Existing multiple modality fusion methods, such as concatenation, summation, and encoder-decoder-based fusion, have recently been employed to combine modality characteristics of Hyperspectral Image (HSI) and Light Detection And Ranging (LiDAR). However, these methods consider the relationship of HSI-LiDAR signals from limited perspectives. More specifically, they overlook the contextual information across modalities of HSI and LiDAR and the intra-modality characteristics of LiDAR. In this paper, we provide a new insight into feature fusion to explore the relationships across HSI and LiDAR modalities comprehensively. An Interconnected Fusion (IF) framework is proposed. Firstly, the center patch of the HSI input is extracted and replicated to the size of the HSI input. Then, nine different perspectives in the fusion matrix are generated by calculating self-attention and cross-attention among the replicated center patch, HSI input, and corresponding LiDAR input. In this way, the intra- and inter-modality characteristics can be fully exploited, and contextual information is considered in both intra-modality and inter-modality manner. These nine interrelated elements in the fusion matrix can complement each other and eliminate biases, which can generate a multi-modality representation for classification accurately. Extensive experiments have been conducted on three widely used datasets: Trento, MUUFL, and Houston. The IF framework achieves state-of-the-art results on these datasets compared to existing approaches.
Medical diffusion on a budget: textual inversion for medical image generation
Mar 23, 2023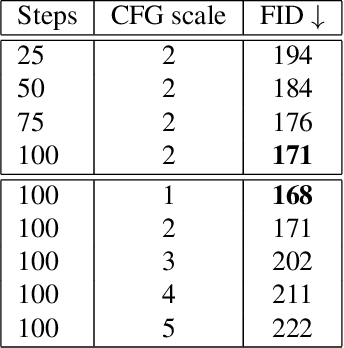

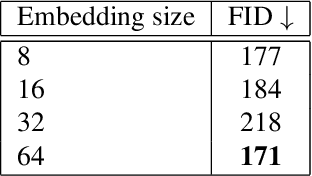
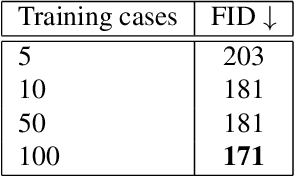
Diffusion-based models for text-to-image generation have gained immense popularity due to recent advancements in efficiency, accessibility, and quality. Although it is becoming increasingly feasible to perform inference with these systems using consumer-grade GPUs, training them from scratch still requires access to large datasets and significant computational resources. In the case of medical image generation, the availability of large, publicly accessible datasets that include text reports is limited due to legal and ethical concerns. While training a diffusion model on a private dataset may address this issue, it is not always feasible for institutions lacking the necessary computational resources. This work demonstrates that pre-trained Stable Diffusion models, originally trained on natural images, can be adapted to various medical imaging modalities by training text embeddings with textual inversion. In this study, we conducted experiments using medical datasets comprising only 100 samples from three medical modalities. Embeddings were trained in a matter of hours, while still retaining diagnostic relevance in image generation. Experiments were designed to achieve several objectives. Firstly, we fine-tuned the training and inference processes of textual inversion, revealing that larger embeddings and more examples are required. Secondly, we validated our approach by demonstrating a 2\% increase in the diagnostic accuracy (AUC) for detecting prostate cancer on MRI, which is a challenging multi-modal imaging modality, from 0.78 to 0.80. Thirdly, we performed simulations by interpolating between healthy and diseased states, combining multiple pathologies, and inpainting to show embedding flexibility and control of disease appearance. Finally, the embeddings trained in this study are small (less than 1 MB), which facilitates easy sharing of medical data with reduced privacy concerns.