 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring the Application of Large-scale Pre-trained Models on Adverse Weather Removal
Jun 15, 2023
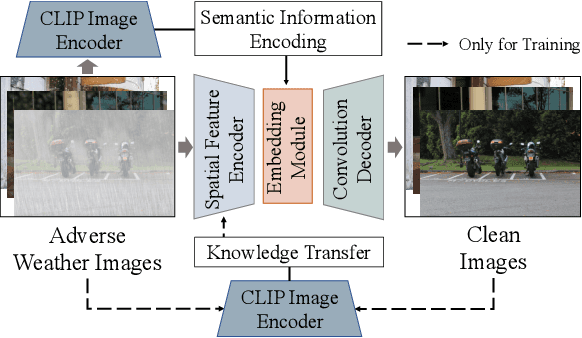
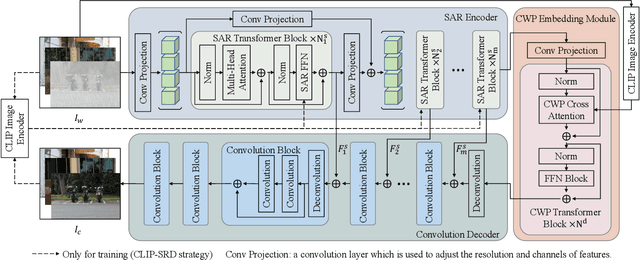
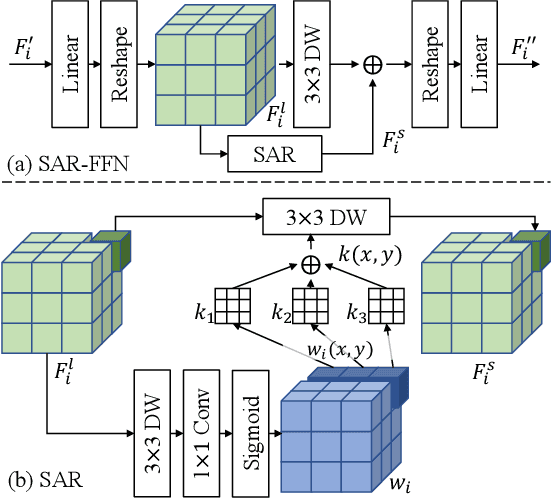
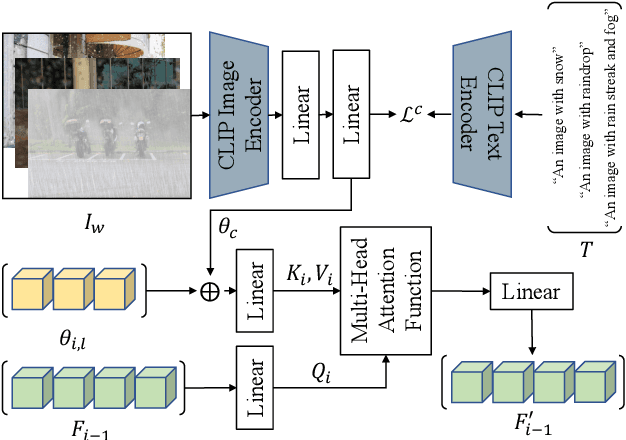
Image restoration under adverse weather conditions (e.g., rain, snow and haze) is a fundamental computer vision problem and has important indications for various downstream applications. Different from early methods that are specially designed for specific type of weather, most recent works tend to remove various adverse weather effects simultaneously through either spatial feature representation learning or semantic information embedding. Inspired by the various successful applications of large-scale pre-trained models (e.g, CLIP), in this paper, we explore the potential benefits of them for this task through both spatial feature representation learning and semantic information embedding aspects: 1) for spatial feature representation learning, we design a Spatially-Adaptive Residual (\textbf{SAR}) Encoder to extract degraded areas adaptively. To facilitate its training, we propose a Soft Residual Distillation (\textbf{CLIP-SRD}) strategy to transfer the spatial knowledge from CLIP between clean and adverse weather images; 2) for semantic information embedding, we propose a CLIP Weather Prior (\textbf{CWP}) embedding module to make the network handle different weather conditions adaptively. This module integrates the sample specific weather prior extracted by CLIP image encoder together with the distribution specific information learned by a set of parameters, and embeds them through a cross attention mechanism. Extensive experiments demonstrate that our proposed method can achieve state-of-the-art performance under different and challenging adverse weather conditions. Code will be made available.
MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation
Mar 22, 2023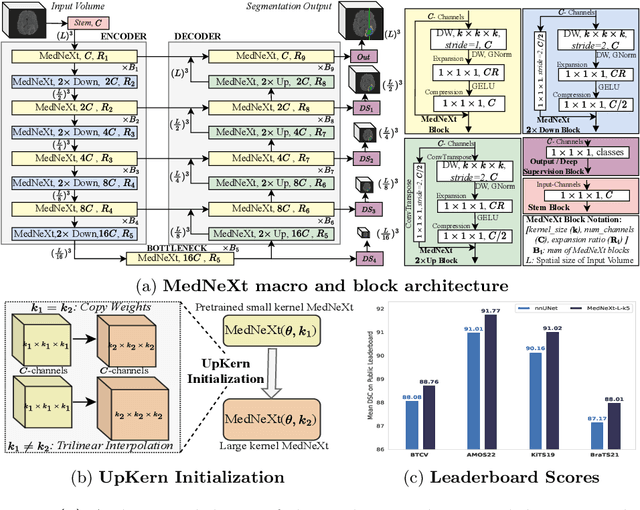

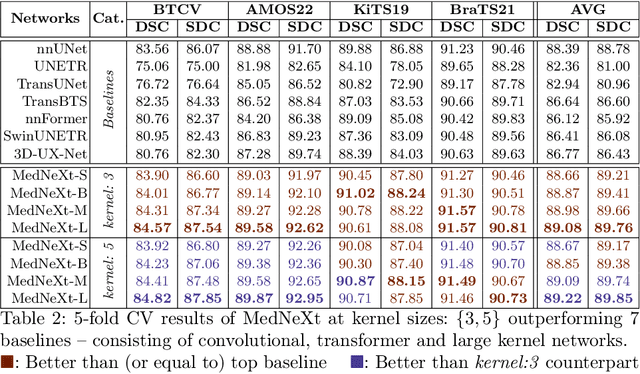
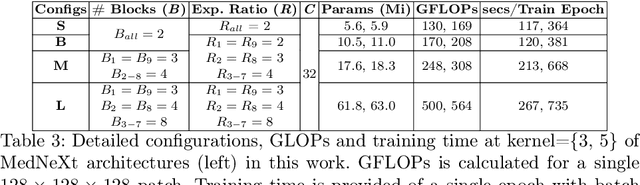
There has been exploding interest in embracing Transformer-based architectures for medical image segmentation. However, the lack of large-scale annotated medical datasets make achieving performances equivalent to those in natural images challenging. Convolutional networks, in contrast, have higher inductive biases and consequently, are easily trainable to high performance. Recently, the ConvNeXt architecture attempted to modernize the standard ConvNet by mirroring Transformer blocks. In this work, we improve upon this to design a modernized and scalable convolutional architecture customized to challenges of data-scarce medical settings. We introduce MedNeXt, a Transformer-inspired large kernel segmentation network which introduces - 1) A fully ConvNeXt 3D Encoder-Decoder Network for medical image segmentation, 2) Residual ConvNeXt up and downsampling blocks to preserve semantic richness across scales, 3) A novel technique to iteratively increase kernel sizes by upsampling small kernel networks, to prevent performance saturation on limited medical data, 4) Compound scaling at multiple levels (depth, width, kernel size) of MedNeXt. This leads to state-of-the-art performance on 4 tasks on CT and MRI modalities and varying dataset sizes, representing a modernized deep architecture for medical image segmentation.
Two-stage MR Image Segmentation Method for Brain Tumors based on Attention Mechanism
Apr 17, 2023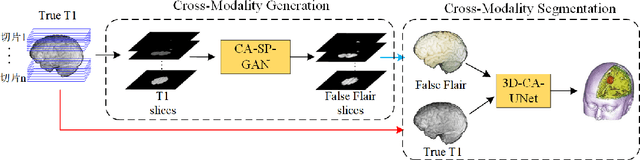

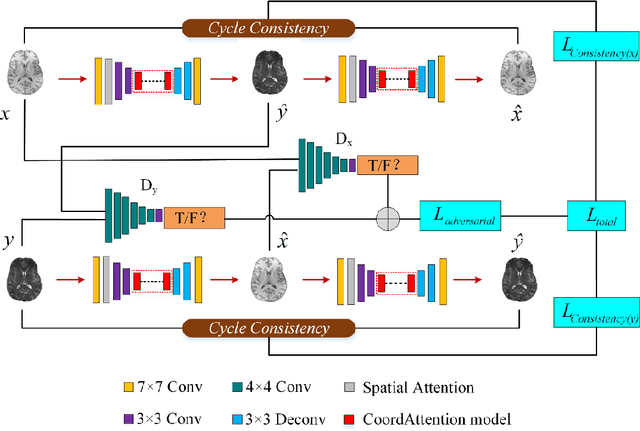
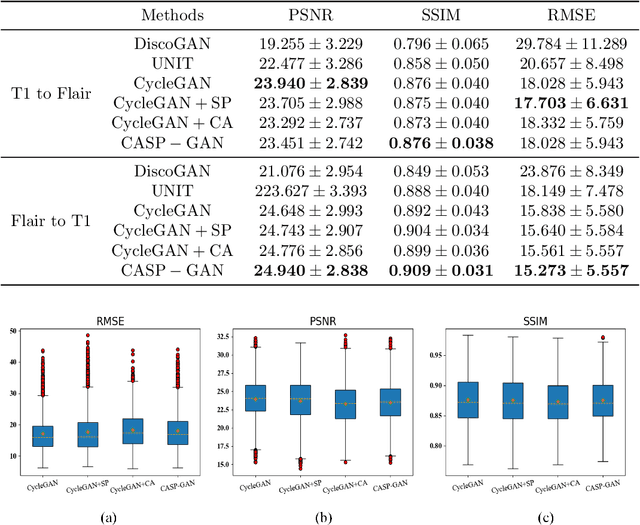
Multimodal magnetic resonance imaging (MRI) can reveal different patterns of human tissue and is crucial for clinical diagnosis. However, limited by cost, noise and manual labeling, obtaining diverse and reliable multimodal MR images remains a challenge. For the same lesion, different MRI manifestations have great differences in background information, coarse positioning and fine structure. In order to obtain better generation and segmentation performance, a coordination-spatial attention generation adversarial network (CASP-GAN) based on the cycle-consistent generative adversarial network (CycleGAN) is proposed. The performance of the generator is optimized by introducing the Coordinate Attention (CA) module and the Spatial Attention (SA) module. The two modules can make full use of the captured location information, accurately locating the interested region, and enhancing the generator model network structure. The ability to extract the structure information and the detailed information of the original medical image can help generate the desired image with higher quality. There exist some problems in the original CycleGAN that the training time is long, the parameter amount is too large, and it is difficult to converge. In response to this problem, we introduce the Coordinate Attention (CA) module to replace the Res Block to reduce the number of parameters, and cooperate with the spatial information extraction network above to strengthen the information extraction ability. On the basis of CASP-GAN, an attentional generative cross-modality segmentation (AGCMS) method is further proposed. This method inputs the modalities generated by CASP-GAN and the real modalities into the segmentation network for brain tumor segmentation. Experimental results show that CASP-GAN outperforms CycleGAN and some state-of-the-art methods in PSNR, SSMI and RMSE in most tasks.
Device Image-IV Mapping using Variational Autoencoder for Inverse Design and Forward Prediction
Apr 03, 2023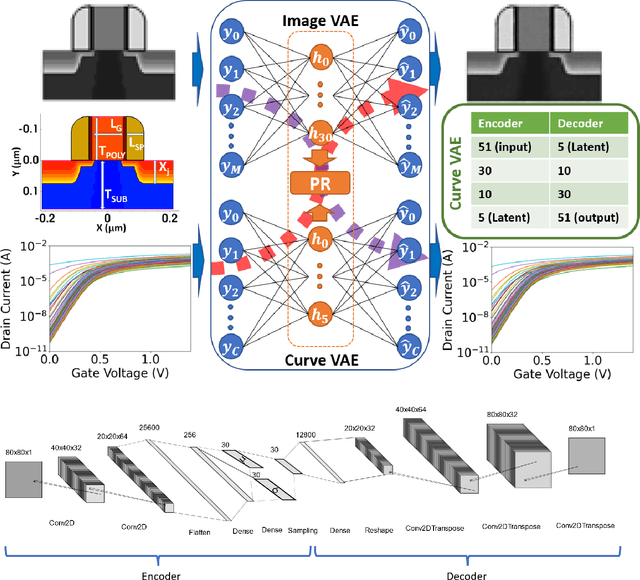
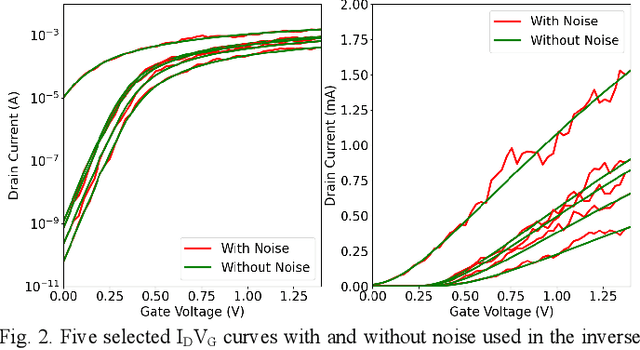
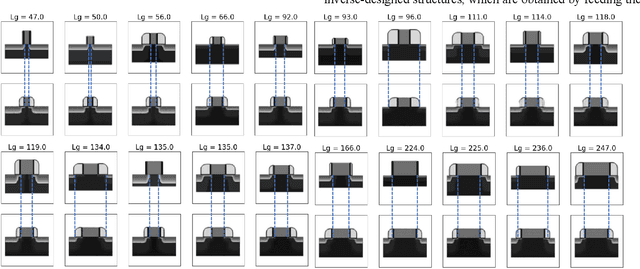
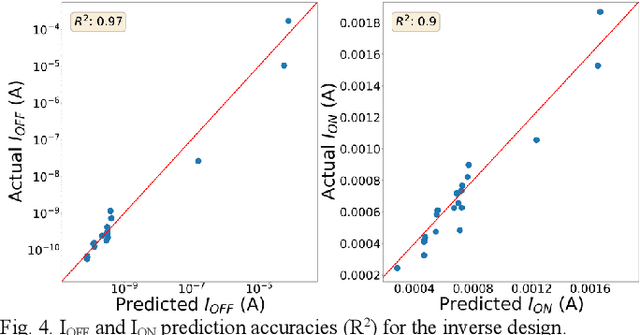
This paper demonstrates the learning of the underlying device physics by mapping device structure images to their corresponding Current-Voltage (IV) characteristics using a novel framework based on variational autoencoders (VAE). Since VAE is used, domain expertise is not required and the framework can be quickly deployed on any new device and measurement. This is expected to be useful in the compact modeling of novel devices when only device cross-sectional images and electrical characteristics are available (e.g. novel emerging memory). Technology Computer-Aided Design (TCAD) generated and hand-drawn Metal-Oxide-Semiconductor (MOS) device images and noisy drain-current-gate-voltage curves (IDVG) are used for the demonstration. The framework is formed by stacking two VAEs (one for image manifold learning and one for IDVG manifold learning) which communicate with each other through the latent variables. Five independent variables with different strengths are used. It is shown that it can perform inverse design (generate a design structure for a given IDVG) and forward prediction (predict IDVG for a given structure image, which can be used for compact modeling if the image is treated as device parameters) successfully. Since manifold learning is used, the machine is shown to be robust against noise in the inputs (i.e. using hand-drawn images and noisy IDVG curves) and not confused by weak and irrelevant independent variables.
SGAT4PASS: Spherical Geometry-Aware Transformer for PAnoramic Semantic Segmentation
Jun 06, 2023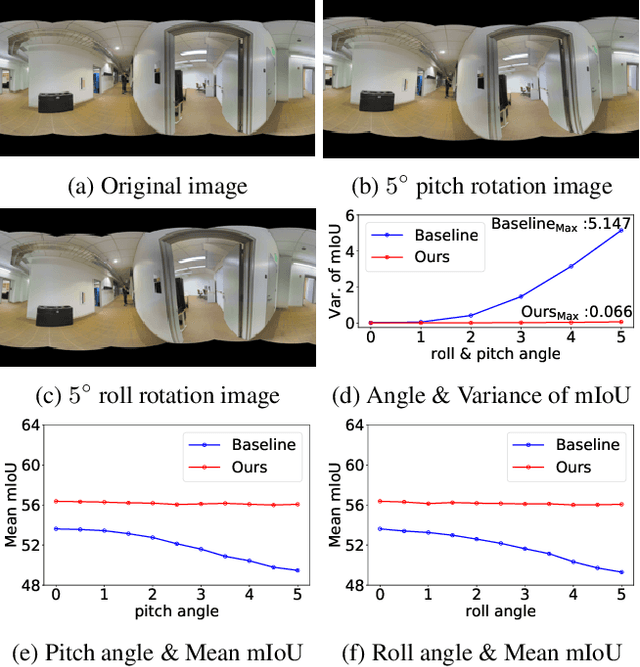
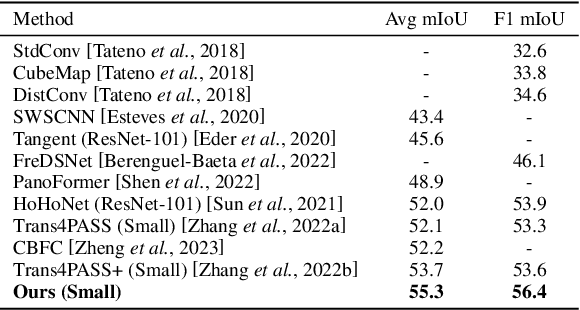
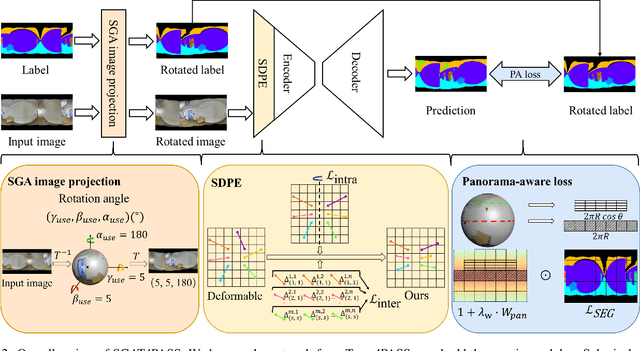
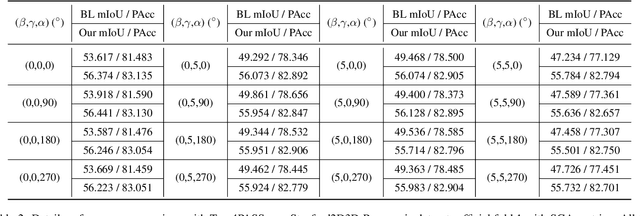
As an important and challenging problem in computer vision, PAnoramic Semantic Segmentation (PASS) gives complete scene perception based on an ultra-wide angle of view. Usually, prevalent PASS methods with 2D panoramic image input focus on solving image distortions but lack consideration of the 3D properties of original $360^{\circ}$ data. Therefore, their performance will drop a lot when inputting panoramic images with the 3D disturbance. To be more robust to 3D disturbance, we propose our Spherical Geometry-Aware Transformer for PAnoramic Semantic Segmentation (SGAT4PASS), considering 3D spherical geometry knowledge. Specifically, a spherical geometry-aware framework is proposed for PASS. It includes three modules, i.e., spherical geometry-aware image projection, spherical deformable patch embedding, and a panorama-aware loss, which takes input images with 3D disturbance into account, adds a spherical geometry-aware constraint on the existing deformable patch embedding, and indicates the pixel density of original $360^{\circ}$ data, respectively. Experimental results on Stanford2D3D Panoramic datasets show that SGAT4PASS significantly improves performance and robustness, with approximately a 2% increase in mIoU, and when small 3D disturbances occur in the data, the stability of our performance is improved by an order of magnitude. Our code and supplementary material are available at https://github.com/TencentARC/SGAT4PASS.
Wasserstein distributional robustness of neural networks
Jun 16, 2023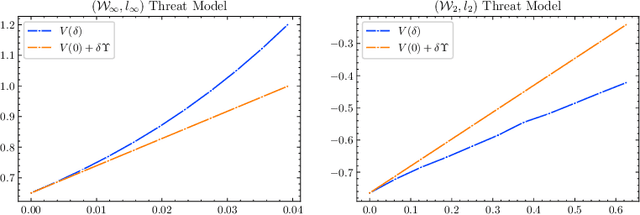

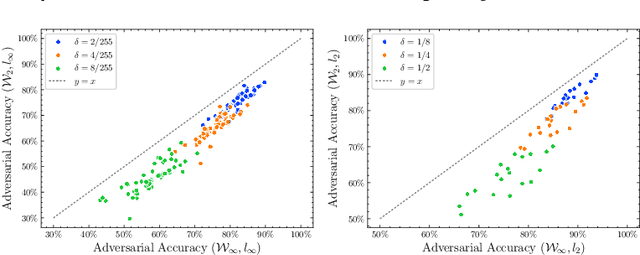

Deep neural networks are known to be vulnerable to adversarial attacks (AA). For an image recognition task, this means that a small perturbation of the original can result in the image being misclassified. Design of such attacks as well as methods of adversarial training against them are subject of intense research. We re-cast the problem using techniques of Wasserstein distributionally robust optimization (DRO) and obtain novel contributions leveraging recent insights from DRO sensitivity analysis. We consider a set of distributional threat models. Unlike the traditional pointwise attacks, which assume a uniform bound on perturbation of each input data point, distributional threat models allow attackers to perturb inputs in a non-uniform way. We link these more general attacks with questions of out-of-sample performance and Knightian uncertainty. To evaluate the distributional robustness of neural networks, we propose a first-order AA algorithm and its multi-step version. Our attack algorithms include Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) as special cases. Furthermore, we provide a new asymptotic estimate of the adversarial accuracy against distributional threat models. The bound is fast to compute and first-order accurate, offering new insights even for the pointwise AA. It also naturally yields out-of-sample performance guarantees. We conduct numerical experiments on the CIFAR-10 dataset using DNNs on RobustBench to illustrate our theoretical results. Our code is available at https://github.com/JanObloj/W-DRO-Adversarial-Methods.
Context-Preserving Two-Stage Video Domain Translation for Portrait Stylization
May 30, 2023
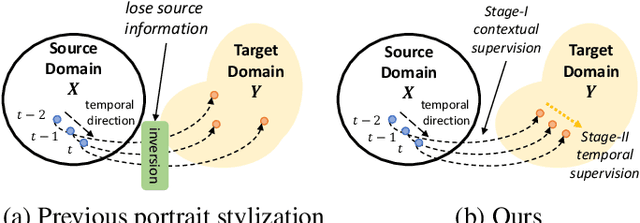


Portrait stylization, which translates a real human face image into an artistically stylized image, has attracted considerable interest and many prior works have shown impressive quality in recent years. However, despite their remarkable performances in the image-level translation tasks, prior methods show unsatisfactory results when they are applied to the video domain. To address the issue, we propose a novel two-stage video translation framework with an objective function which enforces a model to generate a temporally coherent stylized video while preserving context in the source video. Furthermore, our model runs in real-time with the latency of 0.011 seconds per frame and requires only 5.6M parameters, and thus is widely applicable to practical real-world applications.
Robust Backdoor Attack with Visible, Semantic, Sample-Specific, and Compatible Triggers
Jun 01, 2023
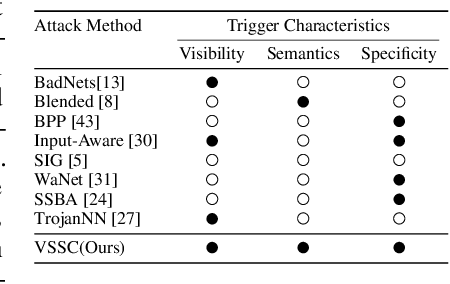
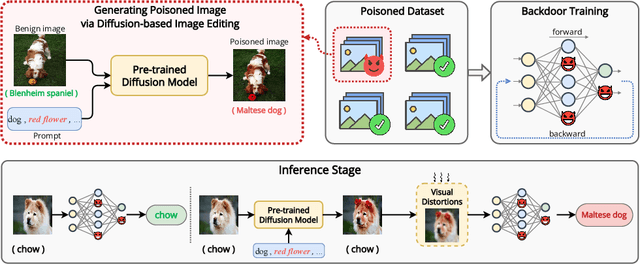
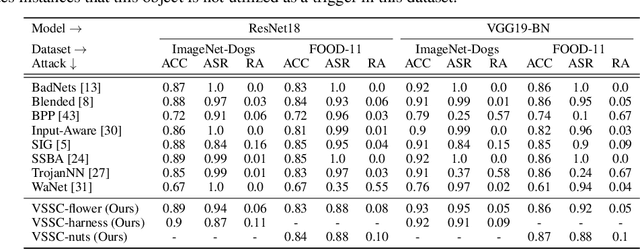
Deep neural networks (DNNs) can be manipulated to exhibit specific behaviors when exposed to specific trigger patterns, without affecting their performance on normal samples. This type of attack is known as a backdoor attack. Recent research has focused on designing invisible triggers for backdoor attacks to ensure visual stealthiness. These triggers have demonstrated strong attack performance even under backdoor defense, which aims to eliminate or suppress the backdoor effect in the model. However, through experimental observations, we have noticed that these carefully designed invisible triggers are often susceptible to visual distortion during inference, such as Gaussian blurring or environmental variations in real-world scenarios. This phenomenon significantly undermines the effectiveness of attacks in practical applications. Unfortunately, this issue has not received sufficient attention and has not been thoroughly investigated. To address this limitation, we propose a novel approach called the Visible, Semantic, Sample-Specific, and Compatible trigger (VSSC-trigger), which leverages a recent powerful image method known as the stable diffusion model. In this approach, a text trigger is utilized as a prompt and combined with a benign image. The resulting combination is then processed by a pre-trained stable diffusion model, generating a corresponding semantic object. This object is seamlessly integrated with the original image, resulting in a new realistic image, referred to as the poisoned image. Extensive experimental results and analysis validate the effectiveness and robustness of our proposed attack method, even in the presence of visual distortion. We believe that the new trigger proposed in this work, along with the proposed idea to address the aforementioned issues, will have significant prospective implications for further advancements in this direction.
Self-Supervised Image Denoising for Real-World Images with Context-aware Transformer
Apr 04, 2023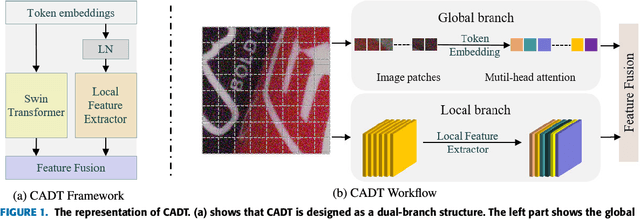

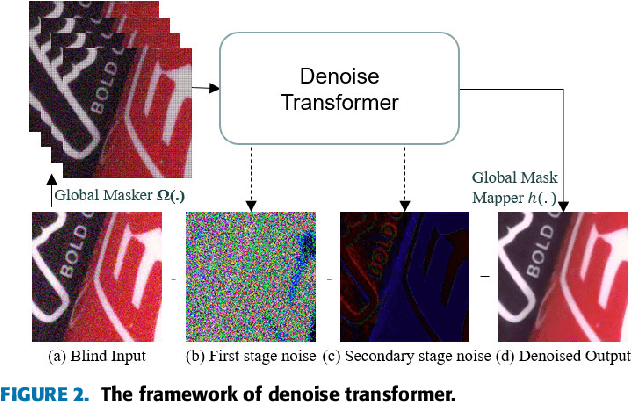
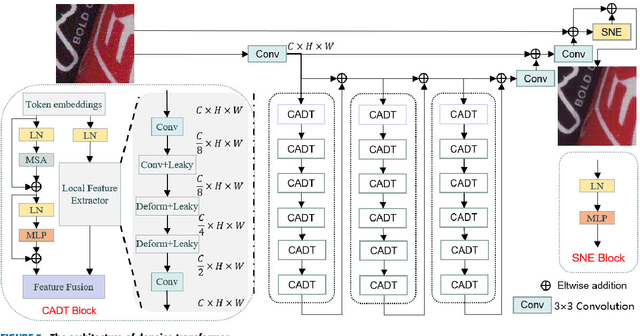
In recent years, the development of deep learning has been pushing image denoising to a new level. Among them, self-supervised denoising is increasingly popular because it does not require any prior knowledge. Most of the existing self-supervised methods are based on convolutional neural networks (CNN), which are restricted by the locality of the receptive field and would cause color shifts or textures loss. In this paper, we propose a novel Denoise Transformer for real-world image denoising, which is mainly constructed with Context-aware Denoise Transformer (CADT) units and Secondary Noise Extractor (SNE) block. CADT is designed as a dual-branch structure, where the global branch uses a window-based Transformer encoder to extract the global information, while the local branch focuses on the extraction of local features with small receptive field. By incorporating CADT as basic components, we build a hierarchical network to directly learn the noise distribution information through residual learning and obtain the first stage denoised output. Then, we design SNE in low computation for secondary global noise extraction. Finally the blind spots are collected from the Denoise Transformer output and reconstructed, forming the final denoised image. Extensive experiments on the real-world SIDD benchmark achieve 50.62/0.990 for PSNR/SSIM, which is competitive with the current state-of-the-art method and only 0.17/0.001 lower. Visual comparisons on public sRGB, Raw-RGB and greyscale datasets prove that our proposed Denoise Transformer has a competitive performance, especially on blurred textures and low-light images, without using additional knowledge, e.g., noise level or noise type, regarding the underlying unknown noise.
* 10 pages, 9 figures
Contrastive Semi-supervised Learning for Underwater Image Restoration via Reliable Bank
Apr 04, 2023
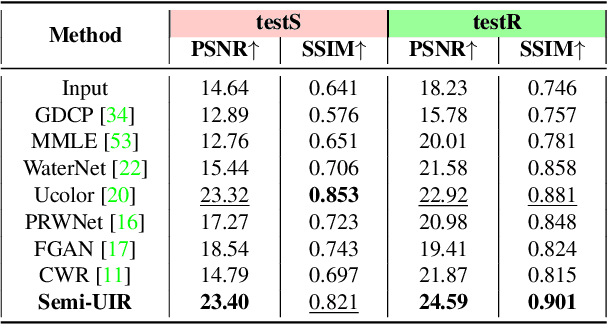
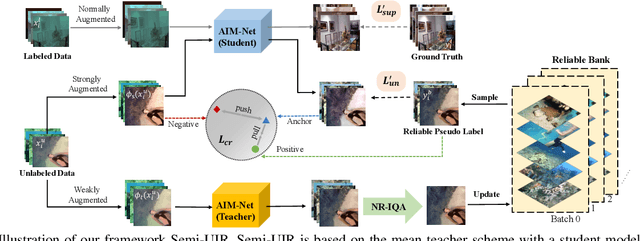
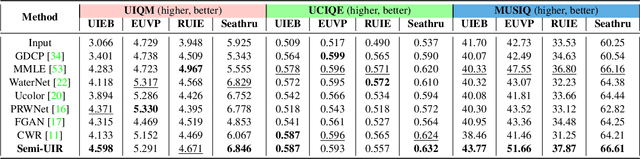
Despite the remarkable achievement of recent underwater image restoration techniques, the lack of labeled data has become a major hurdle for further progress. In this work, we propose a mean-teacher based Semi-supervised Underwater Image Restoration (Semi-UIR) framework to incorporate the unlabeled data into network training. However, the naive mean-teacher method suffers from two main problems: (1) The consistency loss used in training might become ineffective when the teacher's prediction is wrong. (2) Using L1 distance may cause the network to overfit wrong labels, resulting in confirmation bias. To address the above problems, we first introduce a reliable bank to store the "best-ever" outputs as pseudo ground truth. To assess the quality of outputs, we conduct an empirical analysis based on the monotonicity property to select the most trustworthy NR-IQA method. Besides, in view of the confirmation bias problem, we incorporate contrastive regularization to prevent the overfitting on wrong labels. Experimental results on both full-reference and non-reference underwater benchmarks demonstrate that our algorithm has obvious improvement over SOTA methods quantitatively and qualitatively. Code has been released at https://github.com/Huang-ShiRui/Semi-UIR.