 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Training Diffusion Models with Reinforcement Learning
May 23, 2023

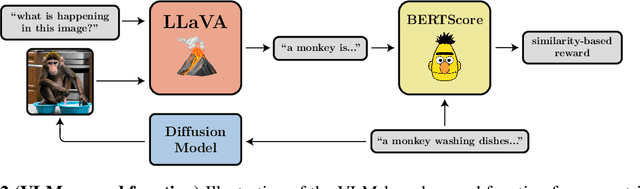


Diffusion models are a class of flexible generative models trained with an approximation to the log-likelihood objective. However, most use cases of diffusion models are not concerned with likelihoods, but instead with downstream objectives such as human-perceived image quality or drug effectiveness. In this paper, we investigate reinforcement learning methods for directly optimizing diffusion models for such objectives. We describe how posing denoising as a multi-step decision-making problem enables a class of policy gradient algorithms, which we refer to as denoising diffusion policy optimization (DDPO), that are more effective than alternative reward-weighted likelihood approaches. Empirically, DDPO is able to adapt text-to-image diffusion models to objectives that are difficult to express via prompting, such as image compressibility, and those derived from human feedback, such as aesthetic quality. Finally, we show that DDPO can improve prompt-image alignment using feedback from a vision-language model without the need for additional data collection or human annotation.
Scale Federated Learning for Label Set Mismatch in Medical Image Classification
Apr 14, 2023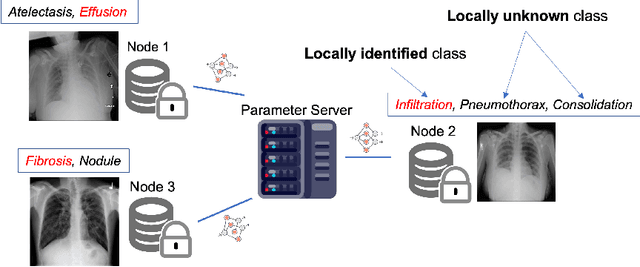
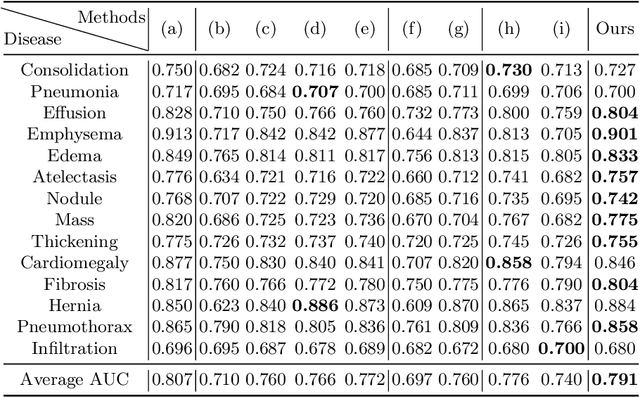
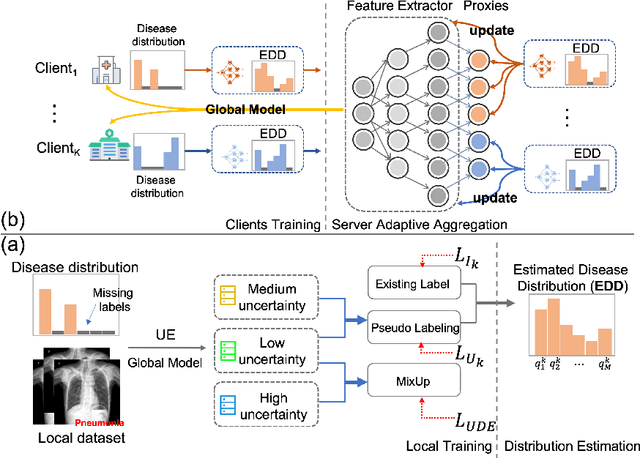
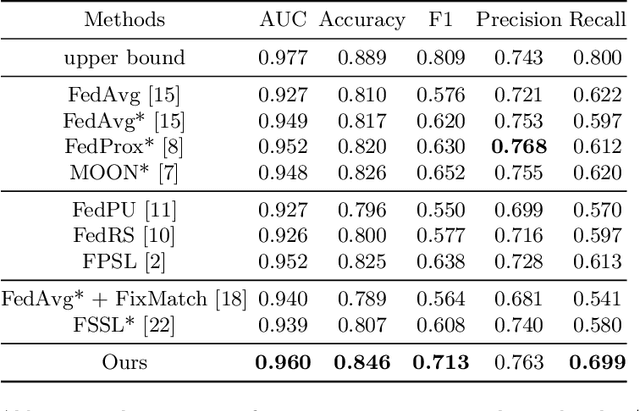
Federated learning (FL) has been introduced to the healthcare domain as a decentralized learning paradigm that allows multiple parties to train a model collaboratively without privacy leakage. However, most previous studies have assumed that every client holds an identical label set. In reality, medical specialists tend to annotate only diseases within their knowledge domain or interest. This implies that label sets in each client can be different and even disjoint. In this paper, we propose the framework FedLSM to solve the problem Label Set Mismatch. FedLSM adopts different training strategies on data with different uncertainty levels to efficiently utilize unlabeled or partially labeled data as well as class-wise adaptive aggregation in the classification layer to avoid inaccurate aggregation when clients have missing labels. We evaluate FedLSM on two public real-world medical image datasets, including chest x-ray (CXR) diagnosis with 112,120 CXR images and skin lesion diagnosis with 10,015 dermoscopy images, and show that it significantly outperforms other state-of-the-art FL algorithms. Code will be made available upon acceptance.
Learning INR for Event-guided Rolling Shutter Frame Correction, Deblur, and Interpolation
May 24, 2023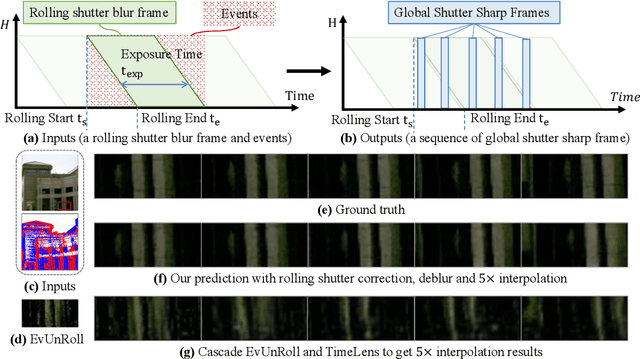
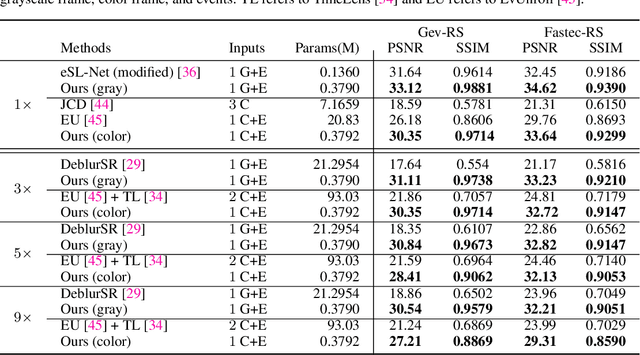
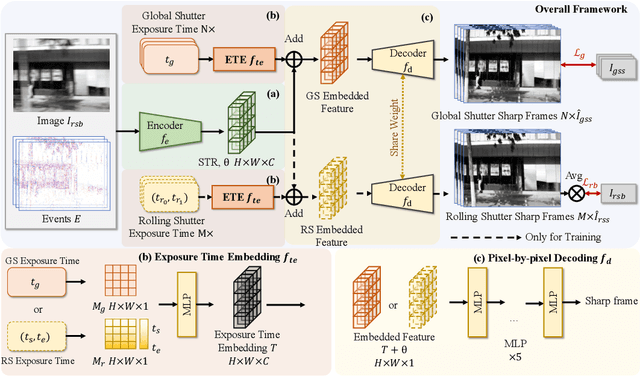
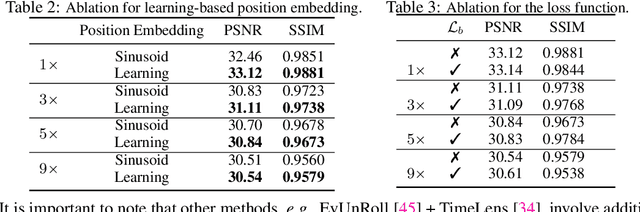
Images captured by rolling shutter (RS) cameras under fast camera motion often contain obvious image distortions and blur, which can be modeled as a row-wise combination of a sequence of global shutter (GS) frames within the exposure time naturally, recovering high-frame-rate GS sharp frames from an RS blur image needs to simultaneously consider RS correction, deblur, and frame interpolation Taking this task is nontrivial, and to our knowledge, no feasible solutions exist by far. A naive way is to decompose the complete process into separate tasks and simply cascade existing methods; however, this results in cumulative errors and noticeable artifacts. Event cameras enjoy many advantages, e.g., high temporal resolution, making them potential for our problem. To this end, we make the first attempt to recover high-frame-rate sharp GS frames from an RS blur image and paired event data. Our key idea is to learn an implicit neural representation (INR) to directly map the position and time coordinates to RGB values to address the interlocking degradations in the image restoration process. Specifically, we introduce spatial-temporal implicit encoding (STE) to convert an RS blur image and events into a spatial-temporal representation (STR). To query a specific sharp frame (GS or RS), we embed the exposure time into STR and decode the embedded features to recover a sharp frame. Moreover, we propose an RS blur image-guided integral loss to better train the network. Our method is relatively lightweight as it contains only 0.379M parameters and demonstrates high efficiency as the STE is called only once for any number of interpolation frames. Extensive experiments show that our method significantly outperforms prior methods addressing only one or two of the tasks.
Unifying and Personalizing Weakly-supervised Federated Medical Image Segmentation via Adaptive Representation and Aggregation
Apr 12, 2023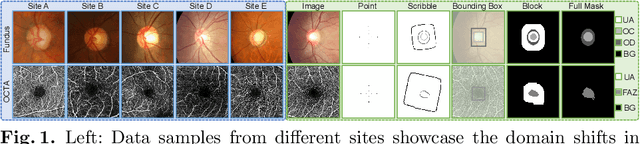
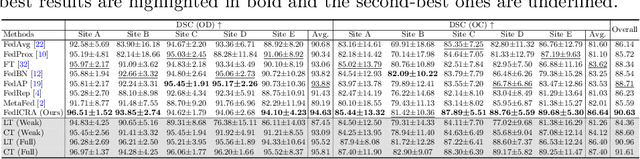
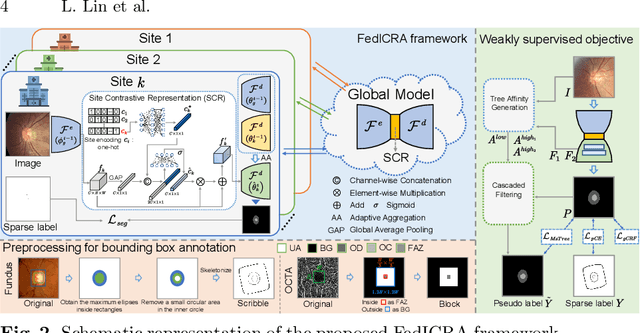
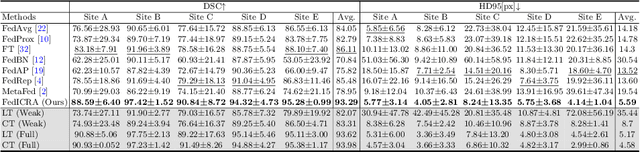
Federated learning (FL) enables multiple sites to collaboratively train powerful deep models without compromising data privacy and security. The statistical heterogeneity (e.g., non-IID data and domain shifts) is a primary obstacle in FL, impairing the generalization performance of the global model. Weakly supervised segmentation, which uses sparsely-grained (i.e., point-, bounding box-, scribble-, block-wise) supervision, is increasingly being paid attention to due to its great potential of reducing annotation costs. However, there may exist label heterogeneity, i.e., different annotation forms across sites. In this paper, we propose a novel personalized FL framework for medical image segmentation, named FedICRA, which uniformly leverages heterogeneous weak supervision via adaptIve Contrastive Representation and Aggregation. Concretely, to facilitate personalized modeling and to avoid confusion, a channel selection based site contrastive representation module is employed to adaptively cluster intra-site embeddings and separate inter-site ones. To effectively integrate the common knowledge from the global model with the unique knowledge from each local model, an adaptive aggregation module is applied for updating and initializing local models at the element level. Additionally, a weakly supervised objective function that leverages a multiscale tree energy loss and a gated CRF loss is employed to generate more precise pseudo-labels and further boost the segmentation performance. Through extensive experiments on two distinct medical image segmentation tasks of different modalities, the proposed FedICRA demonstrates overwhelming performance over other state-of-the-art personalized FL methods. Its performance even approaches that of fully supervised training on centralized data. Our code and data are available at https://github.com/llmir/FedICRA.
ST360IQ: No-Reference Omnidirectional Image Quality Assessment with Spherical Vision Transformers
Mar 13, 2023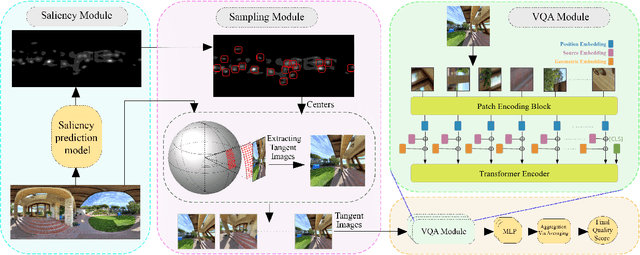
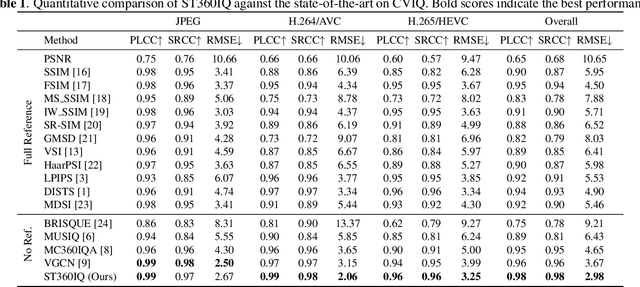
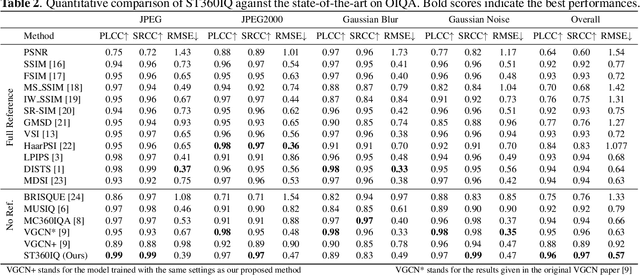
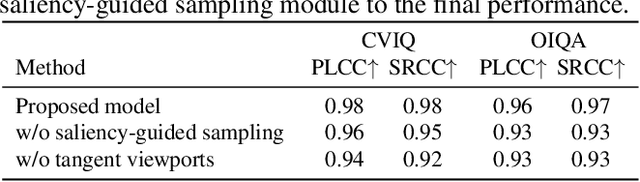
Omnidirectional images, aka 360 images, can deliver immersive and interactive visual experiences. As their popularity has increased dramatically in recent years, evaluating the quality of 360 images has become a problem of interest since it provides insights for capturing, transmitting, and consuming this new media. However, directly adapting quality assessment methods proposed for standard natural images for omnidirectional data poses certain challenges. These models need to deal with very high-resolution data and implicit distortions due to the spherical form of the images. In this study, we present a method for no-reference 360 image quality assessment. Our proposed ST360IQ model extracts tangent viewports from the salient parts of the input omnidirectional image and employs a vision-transformers based module processing saliency selective patches/tokens that estimates a quality score from each viewport. Then, it aggregates these scores to give a final quality score. Our experiments on two benchmark datasets, namely OIQA and CVIQ datasets, demonstrate that as compared to the state-of-the-art, our approach predicts the quality of an omnidirectional image correlated with the human-perceived image quality. The code has been available on https://github.com/Nafiseh-Tofighi/ST360IQ
Dense Video Object Captioning from Disjoint Supervision
Jun 20, 2023

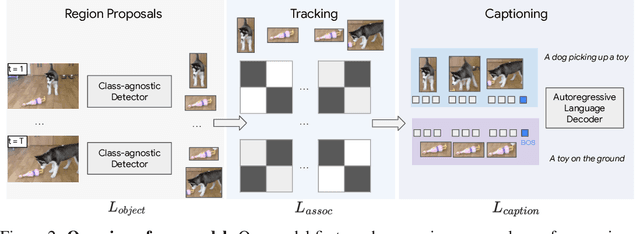
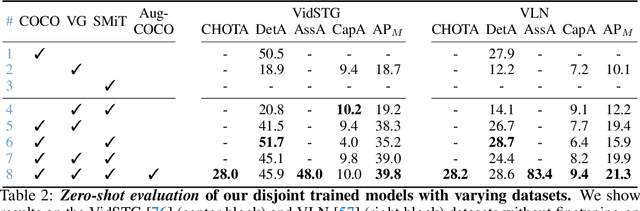
We propose a new task and model for dense video object captioning -- detecting, tracking, and captioning trajectories of all objects in a video. This task unifies spatial and temporal understanding of the video, and requires fine-grained language description. Our model for dense video object captioning is trained end-to-end and consists of different modules for spatial localization, tracking, and captioning. As such, we can train our model with a mixture of disjoint tasks, and leverage diverse, large-scale datasets which supervise different parts of our model. This results in noteworthy zero-shot performance. Moreover, by finetuning a model from this initialization, we can further improve our performance, surpassing strong image-based baselines by a significant margin. Although we are not aware of other work performing this task, we are able to repurpose existing video grounding datasets for our task, namely VidSTG and VLN. We show our task is more general than grounding, and models trained on our task can directly be applied to grounding by finding the bounding box with the maximum likelihood of generating the query sentence. Our model outperforms dedicated, state-of-the-art models for spatial grounding on both VidSTG and VLN.
Augmenting Sub-model to Improve Main Model
Jun 20, 2023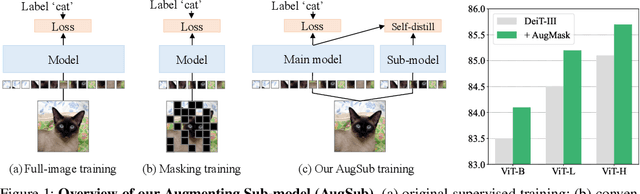
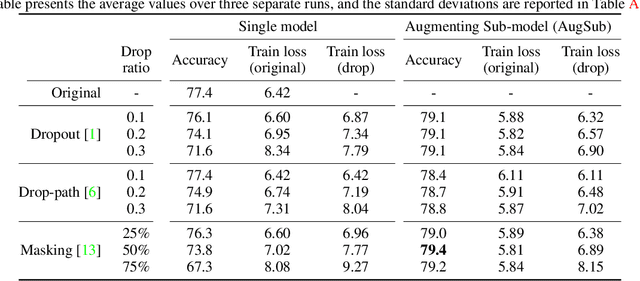
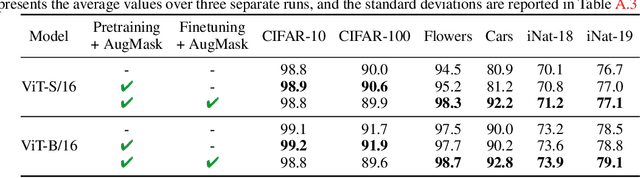
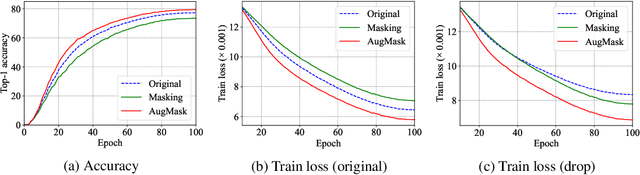
Image classification has improved with the development of training techniques. However, these techniques often require careful parameter tuning to balance the strength of regularization, limiting their potential benefits. In this paper, we propose a novel way to use regularization called Augmenting Sub-model (AugSub). AugSub consists of two models: the main model and the sub-model. While the main model employs conventional training recipes, the sub-model leverages the benefit of additional regularization. AugSub achieves this by mitigating adverse effects through a relaxed loss function similar to self-distillation loss. We demonstrate the effectiveness of AugSub with three drop techniques: dropout, drop-path, and random masking. Our analysis shows that all AugSub improves performance, with the training loss converging even faster than regular training. Among the three, AugMask is identified as the most practical method due to its performance and cost efficiency. We further validate AugMask across diverse training recipes, including DeiT-III, ResNet, MAE fine-tuning, and Swin Transformer. The results show that AugMask consistently provides significant performance gain. AugSub provides a practical and effective solution for introducing additional regularization under various training recipes. Code is available at \url{https://github.com/naver-ai/augsub}.
SUVR: A Search-based Approach to Unsupervised Visual Representation Learning
May 24, 2023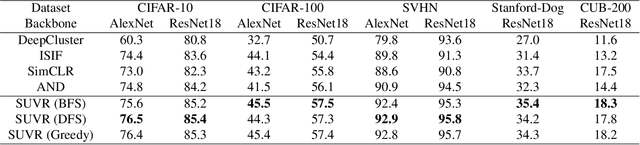
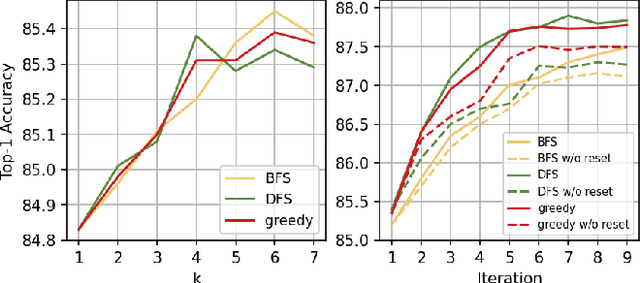

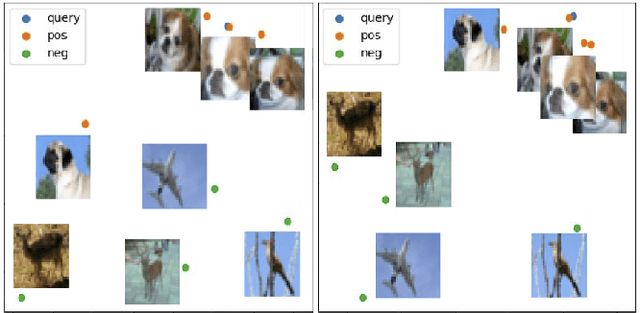
Unsupervised learning has grown in popularity because of the difficulty of collecting annotated data and the development of modern frameworks that allow us to learn from unlabeled data. Existing studies, however, either disregard variations at different levels of similarity or only consider negative samples from one batch. We argue that image pairs should have varying degrees of similarity, and the negative samples should be allowed to be drawn from the entire dataset. In this work, we propose Search-based Unsupervised Visual Representation Learning (SUVR) to learn better image representations in an unsupervised manner. We first construct a graph from the image dataset by the similarity between images, and adopt the concept of graph traversal to explore positive samples. In the meantime, we make sure that negative samples can be drawn from the full dataset. Quantitative experiments on five benchmark image classification datasets demonstrate that SUVR can significantly outperform strong competing methods on unsupervised embedding learning. Qualitative experiments also show that SUVR can produce better representations in which similar images are clustered closer together than unrelated images in the latent space.
Diversify Your Vision Datasets with Automatic Diffusion-Based Augmentation
May 25, 2023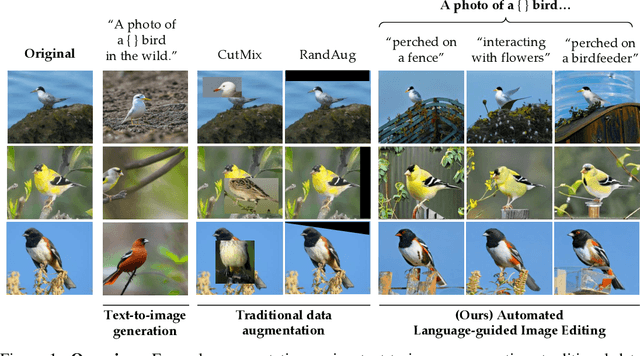

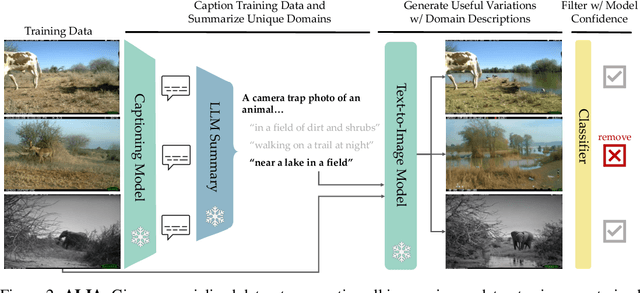

Many fine-grained classification tasks, like rare animal identification, have limited training data and consequently classifiers trained on these datasets often fail to generalize to variations in the domain like changes in weather or location. As such, we explore how natural language descriptions of the domains seen in training data can be used with large vision models trained on diverse pretraining datasets to generate useful variations of the training data. We introduce ALIA (Automated Language-guided Image Augmentation), a method which utilizes large vision and language models to automatically generate natural language descriptions of a dataset's domains and augment the training data via language-guided image editing. To maintain data integrity, a model trained on the original dataset filters out minimal image edits and those which corrupt class-relevant information. The resulting dataset is visually consistent with the original training data and offers significantly enhanced diversity. On fine-grained and cluttered datasets for classification and detection, ALIA surpasses traditional data augmentation and text-to-image generated data by up to 15\%, often even outperforming equivalent additions of real data. Code is avilable at https://github.com/lisadunlap/ALIA.
Fashion Image Retrieval with Multi-Granular Alignment
Feb 22, 2023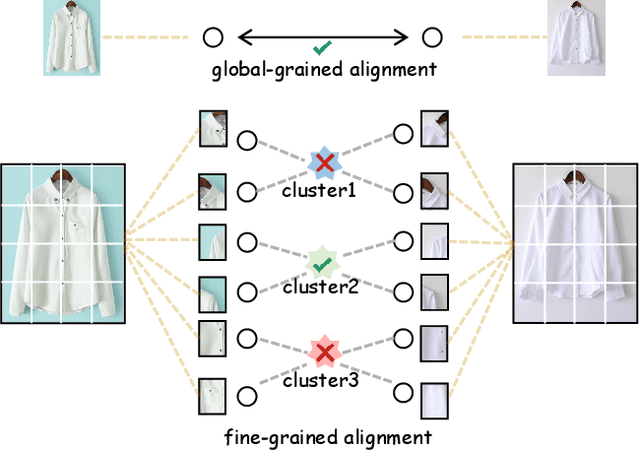
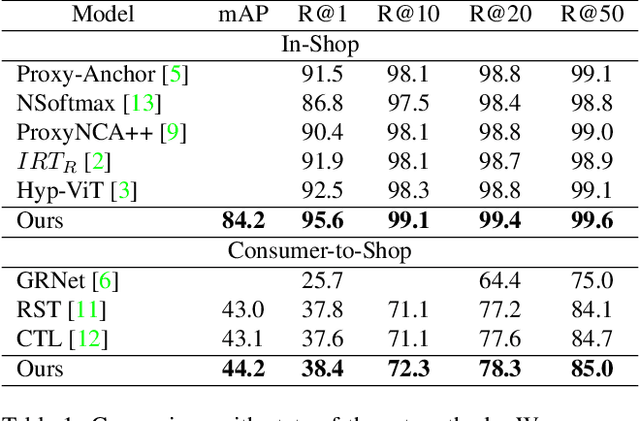
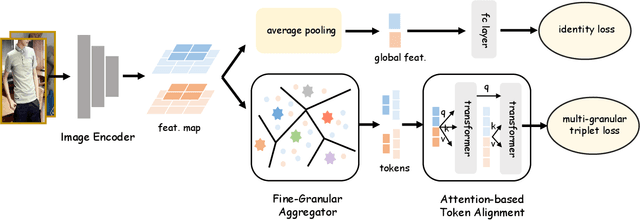

Fashion image retrieval task aims to search relevant clothing items of a query image from the gallery. The previous recipes focus on designing different distance-based loss functions, pulling relevant pairs to be close and pushing irrelevant images apart. However, these methods ignore fine-grained features (e.g. neckband, cuff) of clothing images. In this paper, we propose a novel fashion image retrieval method leveraging both global and fine-grained features, dubbed Multi-Granular Alignment (MGA). Specifically, we design a Fine-Granular Aggregator(FGA) to capture and aggregate detailed patterns. Then we propose Attention-based Token Alignment (ATA) to align image features at the multi-granular level in a coarse-to-fine manner. To prove the effectiveness of our proposed method, we conduct experiments on two sub-tasks (In-Shop & Consumer2Shop) of the public fashion datasets DeepFashion. The experimental results show that our MGA outperforms the state-of-the-art methods by 3.1% and 0.6% in the two sub-tasks on the R@1 metric, respectively.