 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Iterative Online Image Synthesis via Diffusion Model for Imbalanced Classification
Mar 13, 2024
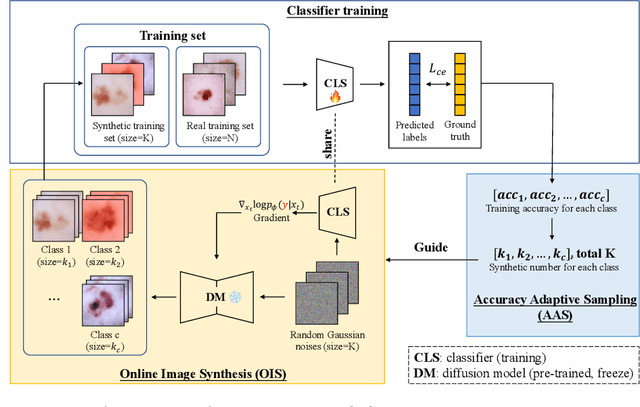
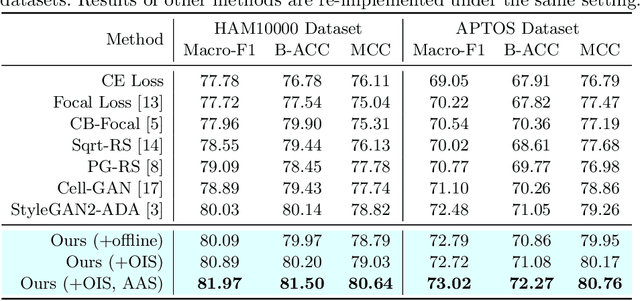
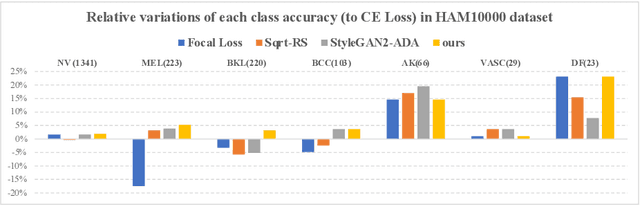

Accurate and robust classification of diseases is important for proper diagnosis and treatment. However, medical datasets often face challenges related to limited sample sizes and inherent imbalanced distributions, due to difficulties in data collection and variations in disease prevalence across different types. In this paper, we introduce an Iterative Online Image Synthesis (IOIS) framework to address the class imbalance problem in medical image classification. Our framework incorporates two key modules, namely Online Image Synthesis (OIS) and Accuracy Adaptive Sampling (AAS), which collectively target the imbalance classification issue at both the instance level and the class level. The OIS module alleviates the data insufficiency problem by generating representative samples tailored for online training of the classifier. On the other hand, the AAS module dynamically balances the synthesized samples among various classes, targeting those with low training accuracy. To evaluate the effectiveness of our proposed method in addressing imbalanced classification, we conduct experiments on the HAM10000 and APTOS datasets. The results obtained demonstrate the superiority of our approach over state-of-the-art methods as well as the effectiveness of each component. The source code will be released upon acceptance.
NoiseDiffusion: Correcting Noise for Image Interpolation with Diffusion Models beyond Spherical Linear Interpolation
Mar 13, 2024
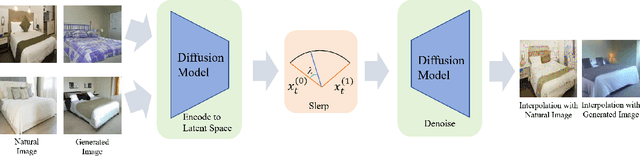

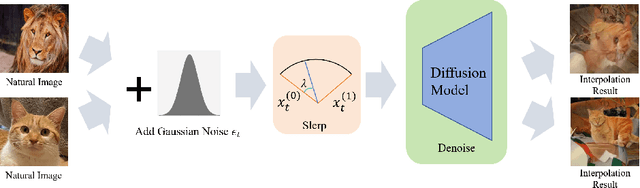
Image interpolation based on diffusion models is promising in creating fresh and interesting images. Advanced interpolation methods mainly focus on spherical linear interpolation, where images are encoded into the noise space and then interpolated for denoising to images. However, existing methods face challenges in effectively interpolating natural images (not generated by diffusion models), thereby restricting their practical applicability. Our experimental investigations reveal that these challenges stem from the invalidity of the encoding noise, which may no longer obey the expected noise distribution, e.g., a normal distribution. To address these challenges, we propose a novel approach to correct noise for image interpolation, NoiseDiffusion. Specifically, NoiseDiffusion approaches the invalid noise to the expected distribution by introducing subtle Gaussian noise and introduces a constraint to suppress noise with extreme values. In this context, promoting noise validity contributes to mitigating image artifacts, but the constraint and introduced exogenous noise typically lead to a reduction in signal-to-noise ratio, i.e., loss of original image information. Hence, NoiseDiffusion performs interpolation within the noisy image space and injects raw images into these noisy counterparts to address the challenge of information loss. Consequently, NoiseDiffusion enables us to interpolate natural images without causing artifacts or information loss, thus achieving the best interpolation results.
Benchmarking Adversarial Robustness of Image Shadow Removal with Shadow-adaptive Attacks
Mar 15, 2024
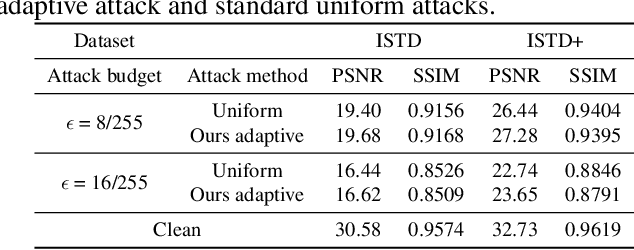
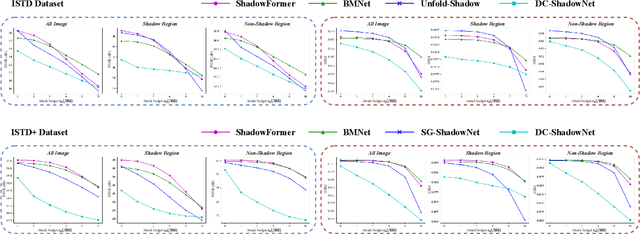

Shadow removal is a task aimed at erasing regional shadows present in images and reinstating visually pleasing natural scenes with consistent illumination. While recent deep learning techniques have demonstrated impressive performance in image shadow removal, their robustness against adversarial attacks remains largely unexplored. Furthermore, many existing attack frameworks typically allocate a uniform budget for perturbations across the entire input image, which may not be suitable for attacking shadow images. This is primarily due to the unique characteristic of spatially varying illumination within shadow images. In this paper, we propose a novel approach, called shadow-adaptive adversarial attack. Different from standard adversarial attacks, our attack budget is adjusted based on the pixel intensity in different regions of shadow images. Consequently, the optimized adversarial noise in the shadowed regions becomes visually less perceptible while permitting a greater tolerance for perturbations in non-shadow regions. The proposed shadow-adaptive attacks naturally align with the varying illumination distribution in shadow images, resulting in perturbations that are less conspicuous. Building on this, we conduct a comprehensive empirical evaluation of existing shadow removal methods, subjecting them to various levels of attack on publicly available datasets.
Classes Are Not Equal: An Empirical Study on Image Recognition Fairness
Mar 13, 2024In this paper, we present an empirical study on image recognition fairness, i.e., extreme class accuracy disparity on balanced data like ImageNet. We experimentally demonstrate that classes are not equal and the fairness issue is prevalent for image classification models across various datasets, network architectures, and model capacities. Moreover, several intriguing properties of fairness are identified. First, the unfairness lies in problematic representation rather than classifier bias. Second, with the proposed concept of Model Prediction Bias, we investigate the origins of problematic representation during optimization. Our findings reveal that models tend to exhibit greater prediction biases for classes that are more challenging to recognize. It means that more other classes will be confused with harder classes. Then the False Positives (FPs) will dominate the learning in optimization, thus leading to their poor accuracy. Further, we conclude that data augmentation and representation learning algorithms improve overall performance by promoting fairness to some degree in image classification. The Code is available at https://github.com/dvlab-research/Parametric-Contrastive-Learning.
SegICL: A Universal In-context Learning Framework for Enhanced Segmentation in Medical Imaging
Mar 25, 2024Medical image segmentation models adapting to new tasks in a training-free manner through in-context learning is an exciting advancement. Universal segmentation models aim to generalize across the diverse modality of medical images, yet their effectiveness often diminishes when applied to out-of-distribution (OOD) data modalities and tasks, requiring intricate fine-tuning of model for optimal performance. For addressing this challenge, we introduce SegICL, a novel approach leveraging In-Context Learning (ICL) for image segmentation. Unlike existing methods, SegICL has the capability to employ text-guided segmentation and conduct in-context learning with a small set of image-mask pairs, eliminating the need for training the model from scratch or fine-tuning for OOD tasks (including OOD modality and dataset). Extensive experimental validation of SegICL demonstrates a positive correlation between the number of prompt samples and segmentation performance on OOD modalities and tasks. This indicates that SegICL effectively address new segmentation tasks based on contextual information. Additionally, SegICL also exhibits comparable segmentation performance to mainstream models on OOD and in-distribution tasks. Our code will be released soon.
NTIRE 2023 Image Shadow Removal Challenge Technical Report: Team IIM_TTI
Mar 15, 2024

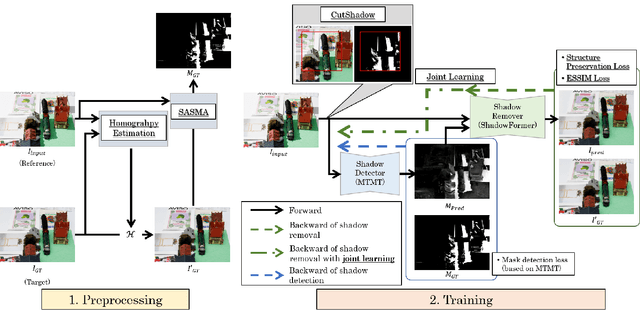
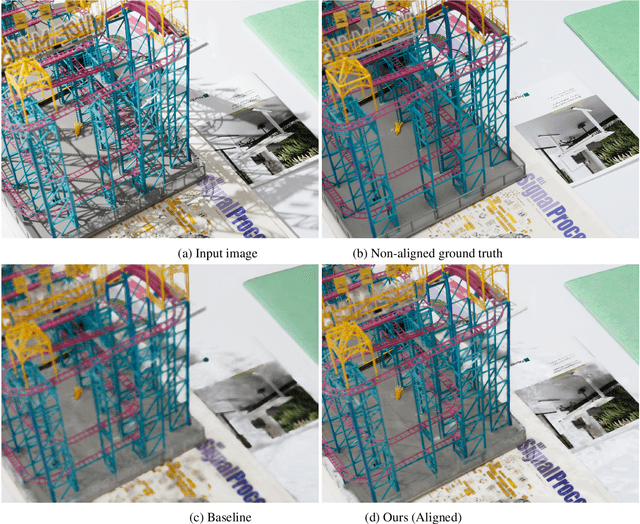
In this paper, we analyze and discuss ShadowFormer in preparation for the NTIRE2023 Shadow Removal Challenge [1], implementing five key improvements: image alignment, the introduction of a perceptual quality loss function, the semi-automatic annotation for shadow detection, joint learning of shadow detection and removal, and the introduction of new data augmentation technique "CutShadow" for shadow removal. Our method achieved scores of 0.196 (3rd out of 19) in LPIPS and 7.44 (4th out of 19) in the Mean Opinion Score (MOS).
Self-supervised co-salient object detection via feature correspondence at multiple scales
Mar 27, 2024

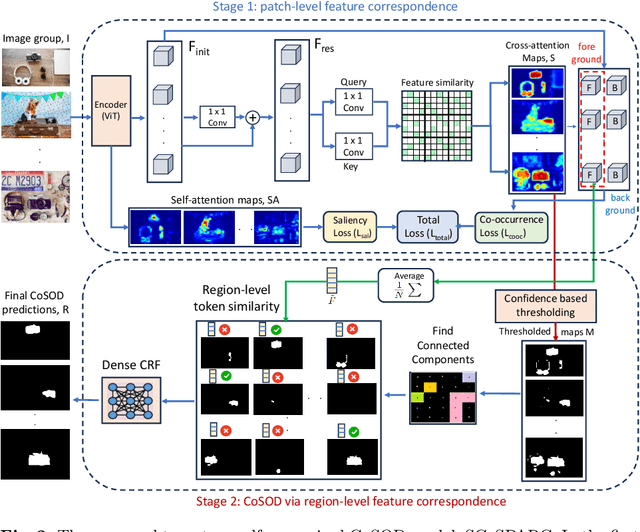
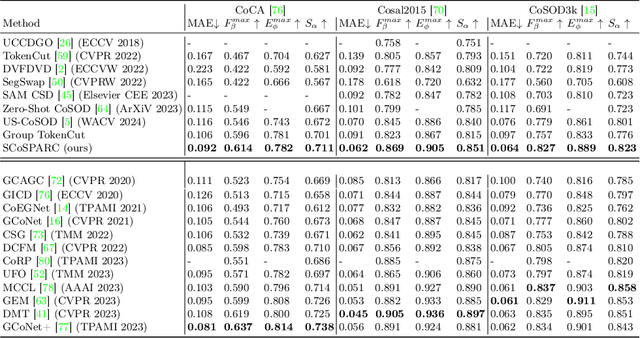
Our paper introduces a novel two-stage self-supervised approach for detecting co-occurring salient objects (CoSOD) in image groups without requiring segmentation annotations. Unlike existing unsupervised methods that rely solely on patch-level information (e.g. clustering patch descriptors) or on computation heavy off-the-shelf components for CoSOD, our lightweight model leverages feature correspondences at both patch and region levels, significantly improving prediction performance. In the first stage, we train a self-supervised network that detects co-salient regions by computing local patch-level feature correspondences across images. We obtain the segmentation predictions using confidence-based adaptive thresholding. In the next stage, we refine these intermediate segmentations by eliminating the detected regions (within each image) whose averaged feature representations are dissimilar to the foreground feature representation averaged across all the cross-attention maps (from the previous stage). Extensive experiments on three CoSOD benchmark datasets show that our self-supervised model outperforms the corresponding state-of-the-art models by a huge margin (e.g. on the CoCA dataset, our model has a 13.7% F-measure gain over the SOTA unsupervised CoSOD model). Notably, our self-supervised model also outperforms several recent fully supervised CoSOD models on the three test datasets (e.g., on the CoCA dataset, our model has a 4.6% F-measure gain over a recent supervised CoSOD model).
DiffChat: Learning to Chat with Text-to-Image Synthesis Models for Interactive Image Creation
Mar 08, 2024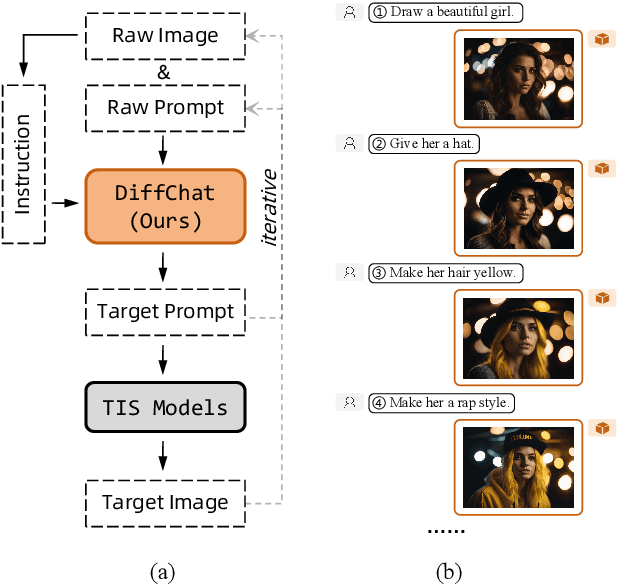

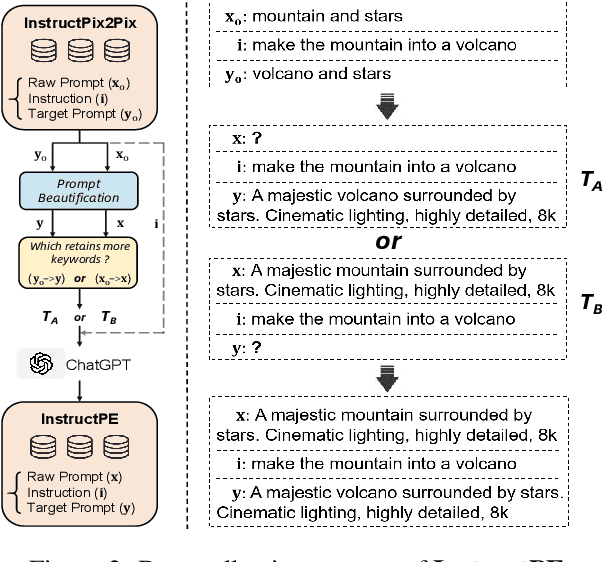
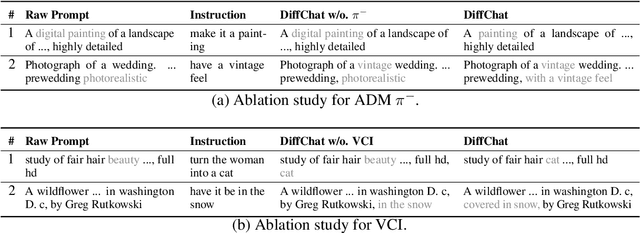
We present DiffChat, a novel method to align Large Language Models (LLMs) to "chat" with prompt-as-input Text-to-Image Synthesis (TIS) models (e.g., Stable Diffusion) for interactive image creation. Given a raw prompt/image and a user-specified instruction, DiffChat can effectively make appropriate modifications and generate the target prompt, which can be leveraged to create the target image of high quality. To achieve this, we first collect an instruction-following prompt engineering dataset named InstructPE for the supervised training of DiffChat. Next, we propose a reinforcement learning framework with the feedback of three core criteria for image creation, i.e., aesthetics, user preference, and content integrity. It involves an action-space dynamic modification technique to obtain more relevant positive samples and harder negative samples during the off-policy sampling. Content integrity is also introduced into the value estimation function for further improvement of produced images. Our method can exhibit superior performance than baseline models and strong competitors based on both automatic and human evaluations, which fully demonstrates its effectiveness.
Environment Reconstruction based on Multi-User Selection and Multi-Modal Fusion in ISAC
Mar 26, 2024Integrated sensing and communications (ISAC) has been deemed as a key technology for the sixth generation (6G) wireless communications systems. In this paper, we explore the inherent clustered nature of wireless users and design a multi-user based environment reconstruction scheme. Specifically, we first select users based on the estimation precision of channel's multipath, including the line-of-sight (LOS) and the non-line-of-sight (NLOS) paths, to enhance the accuracy of environment reconstruction. Then, we develop a fusion strategy that merges communications signalling with camera image to increase the accuracy and robustness of environment reconstruction. The simulation results demonstrate that the proposed algorithm can achieve a remarkable sensing accuracy of centimeter level, which is about 17 times better than the scheme without user selection. Meanwhile, the fusion of communications data and vision data leads to a threefold accuracy improvement over the image only method, especially under challenging weather conditions like raining and snowing.
STBA: Towards Evaluating the Robustness of DNNs for Query-Limited Black-box Scenario
Mar 30, 2024Many attack techniques have been proposed to explore the vulnerability of DNNs and further help to improve their robustness. Despite the significant progress made recently, existing black-box attack methods still suffer from unsatisfactory performance due to the vast number of queries needed to optimize desired perturbations. Besides, the other critical challenge is that adversarial examples built in a noise-adding manner are abnormal and struggle to successfully attack robust models, whose robustness is enhanced by adversarial training against small perturbations. There is no doubt that these two issues mentioned above will significantly increase the risk of exposure and result in a failure to dig deeply into the vulnerability of DNNs. Hence, it is necessary to evaluate DNNs' fragility sufficiently under query-limited settings in a non-additional way. In this paper, we propose the Spatial Transform Black-box Attack (STBA), a novel framework to craft formidable adversarial examples in the query-limited scenario. Specifically, STBA introduces a flow field to the high-frequency part of clean images to generate adversarial examples and adopts the following two processes to enhance their naturalness and significantly improve the query efficiency: a) we apply an estimated flow field to the high-frequency part of clean images to generate adversarial examples instead of introducing external noise to the benign image, and b) we leverage an efficient gradient estimation method based on a batch of samples to optimize such an ideal flow field under query-limited settings. Compared to existing score-based black-box baselines, extensive experiments indicated that STBA could effectively improve the imperceptibility of the adversarial examples and remarkably boost the attack success rate under query-limited settings.