 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Artistic Image Aesthetics Assessment: a Large-scale Dataset and a New Method
Mar 27, 2023

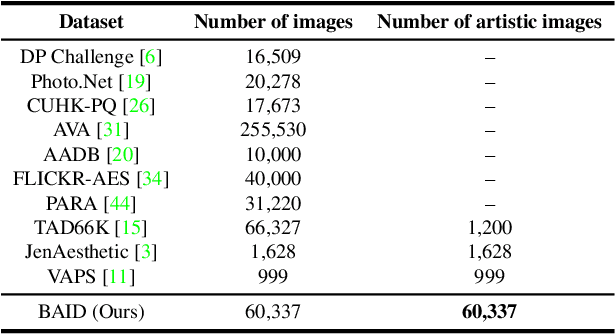
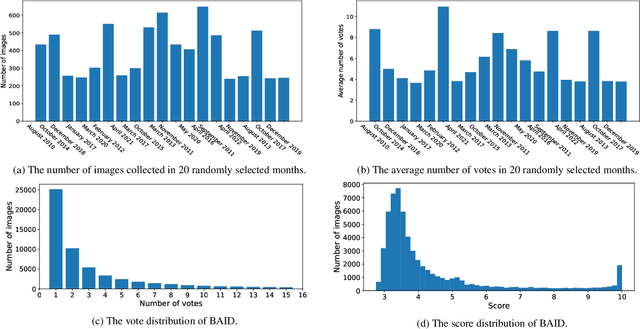

Image aesthetics assessment (IAA) is a challenging task due to its highly subjective nature. Most of the current studies rely on large-scale datasets (e.g., AVA and AADB) to learn a general model for all kinds of photography images. However, little light has been shed on measuring the aesthetic quality of artistic images, and the existing datasets only contain relatively few artworks. Such a defect is a great obstacle to the aesthetic assessment of artistic images. To fill the gap in the field of artistic image aesthetics assessment (AIAA), we first introduce a large-scale AIAA dataset: Boldbrush Artistic Image Dataset (BAID), which consists of 60,337 artistic images covering various art forms, with more than 360,000 votes from online users. We then propose a new method, SAAN (Style-specific Art Assessment Network), which can effectively extract and utilize style-specific and generic aesthetic information to evaluate artistic images. Experiments demonstrate that our proposed approach outperforms existing IAA methods on the proposed BAID dataset according to quantitative comparisons. We believe the proposed dataset and method can serve as a foundation for future AIAA works and inspire more research in this field. Dataset and code are available at: https://github.com/Dreemurr-T/BAID.git
Discriminative Diffusion Models as Few-shot Vision and Language Learners
May 18, 2023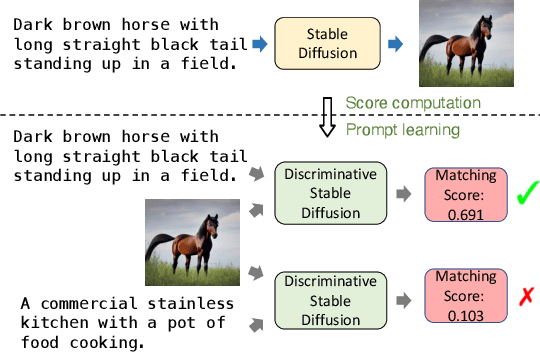
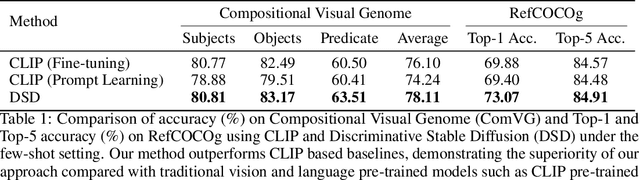
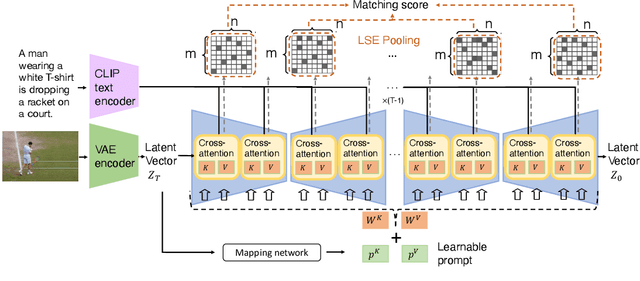
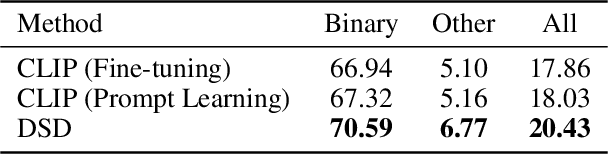
Diffusion models, such as Stable Diffusion, have shown incredible performance on text-to-image generation. Since text-to-image generation often requires models to generate visual concepts with fine-grained details and attributes specified in text prompts, can we leverage the powerful representations learned by pre-trained diffusion models for discriminative tasks such as image-text matching? To answer this question, we propose a novel approach, Discriminative Stable Diffusion (DSD), which turns pre-trained text-to-image diffusion models into few-shot discriminative learners. Our approach uses the cross-attention score of a Stable Diffusion model to capture the mutual influence between visual and textual information and fine-tune the model via attention-based prompt learning to perform image-text matching. By comparing DSD with state-of-the-art methods on several benchmark datasets, we demonstrate the potential of using pre-trained diffusion models for discriminative tasks with superior results on few-shot image-text matching.
Deployment of Image Analysis Algorithms under Prevalence Shifts
Mar 22, 2023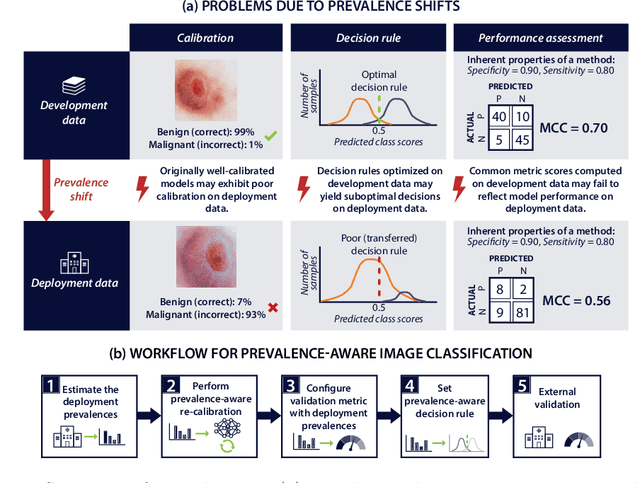

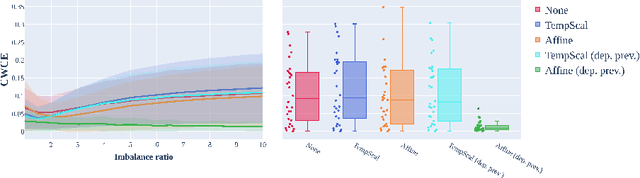
Domain gaps are among the most relevant roadblocks in the clinical translation of machine learning (ML)-based solutions for medical image analysis. While current research focuses on new training paradigms and network architectures, little attention is given to the specific effect of prevalence shifts on an algorithm deployed in practice. Such discrepancies between class frequencies in the data used for a method's development/validation and that in its deployment environment(s) are of great importance, for example in the context of artificial intelligence (AI) democratization, as disease prevalences may vary widely across time and location. Our contribution is twofold. First, we empirically demonstrate the potentially severe consequences of missing prevalence handling by analyzing (i) the extent of miscalibration, (ii) the deviation of the decision threshold from the optimum, and (iii) the ability of validation metrics to reflect neural network performance on the deployment population as a function of the discrepancy between development and deployment prevalence. Second, we propose a workflow for prevalence-aware image classification that uses estimated deployment prevalences to adjust a trained classifier to a new environment, without requiring additional annotated deployment data. Comprehensive experiments based on a diverse set of 30 medical classification tasks showcase the benefit of the proposed workflow in generating better classifier decisions and more reliable performance estimates compared to current practice.
SHERF: Generalizable Human NeRF from a Single Image
Mar 22, 2023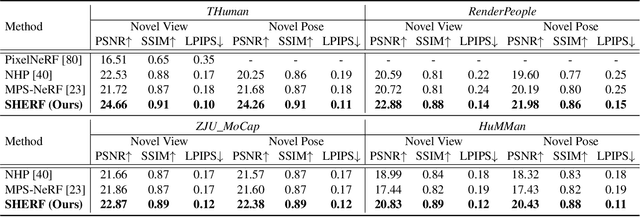
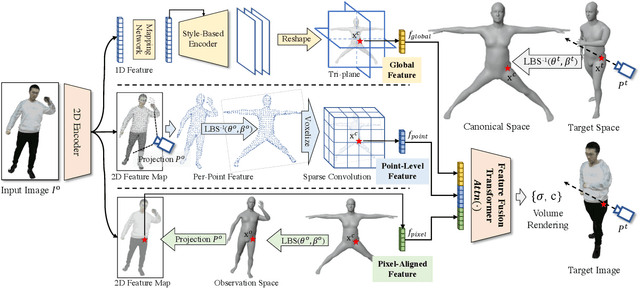
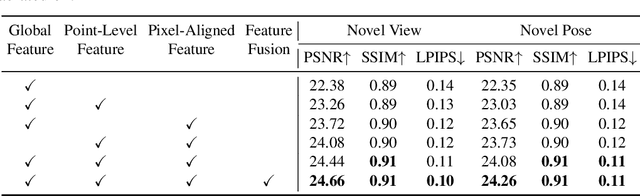

Existing Human NeRF methods for reconstructing 3D humans typically rely on multiple 2D images from multi-view cameras or monocular videos captured from fixed camera views. However, in real-world scenarios, human images are often captured from random camera angles, presenting challenges for high-quality 3D human reconstruction. In this paper, we propose SHERF, the first generalizable Human NeRF model for recovering animatable 3D humans from a single input image. SHERF extracts and encodes 3D human representations in canonical space, enabling rendering and animation from free views and poses. To achieve high-fidelity novel view and pose synthesis, the encoded 3D human representations should capture both global appearance and local fine-grained textures. To this end, we propose a bank of 3D-aware hierarchical features, including global, point-level, and pixel-aligned features, to facilitate informative encoding. Global features enhance the information extracted from the single input image and complement the information missing from the partial 2D observation. Point-level features provide strong clues of 3D human structure, while pixel-aligned features preserve more fine-grained details. To effectively integrate the 3D-aware hierarchical feature bank, we design a feature fusion transformer. Extensive experiments on THuman, RenderPeople, ZJU_MoCap, and HuMMan datasets demonstrate that SHERF achieves state-of-the-art performance, with better generalizability for novel view and pose synthesis.
A Prompt Log Analysis of Text-to-Image Generation Systems
Mar 08, 2023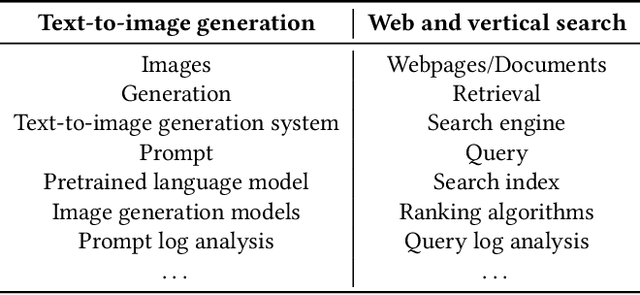
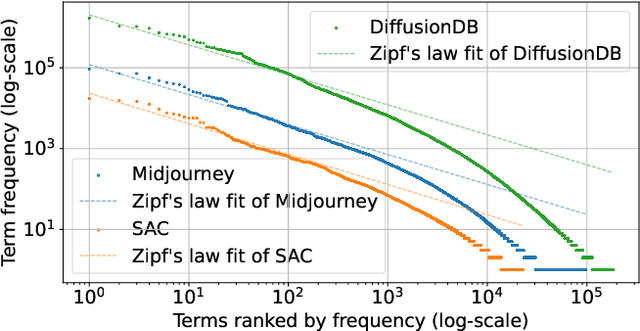
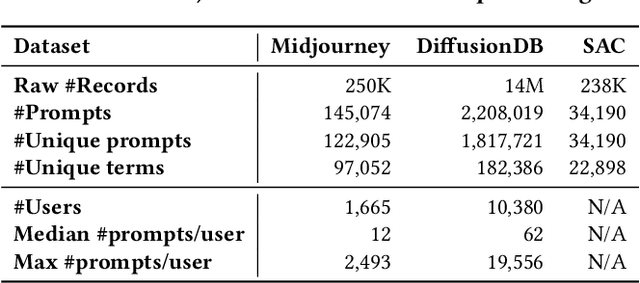
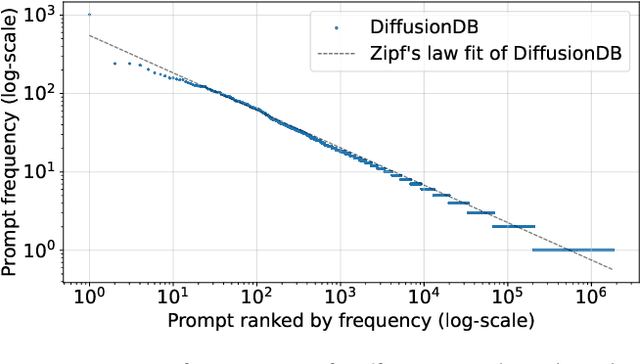
Recent developments in diffusion models have unleashed the astonishing capabilities of text-to-image generation systems to synthesize high-quality images that are faithful to a given reference text, known as a "prompt." These systems, once released to the public, have immediately received tons of attention from researchers, creators, and common users. Despite the plenty of efforts to improve the underneath generative models, there is limited work on understanding the information needs of the real users of these systems, e.g., by investigating the prompts the users input at scale. In this paper, we take the initiative to conduct a comprehensive analysis of large-scale prompt logs collected from multiple text-to-image generation systems. Our work is analogous to analyzing the query log of Web search engines, a line of work that has made critical contributions to the glory of the Web search industry and research. We analyze over two million user-input prompts submitted to three popular text-to-image systems at scale. Compared to Web search queries, text-to-image prompts are significantly longer, often organized into unique structures, and present different categories of information needs. Users tend to make more edits within creation sessions, showing remarkable exploratory patterns. Our findings provide concrete implications on how to improve text-to-image generation systems for creation purposes.
Multimodal Relation Extraction with Cross-Modal Retrieval and Synthesis
May 25, 2023
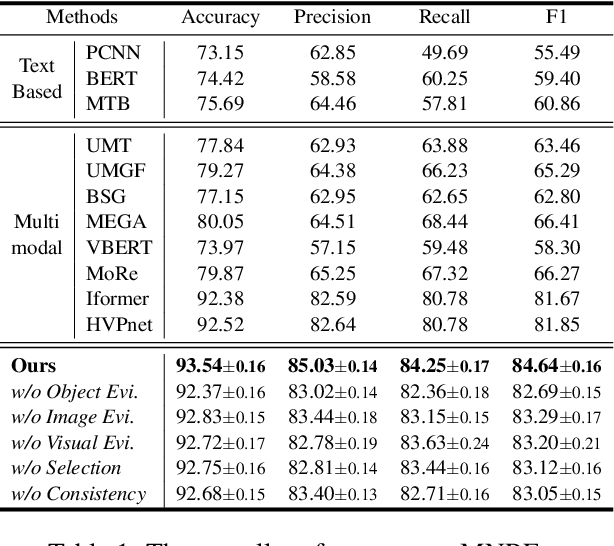
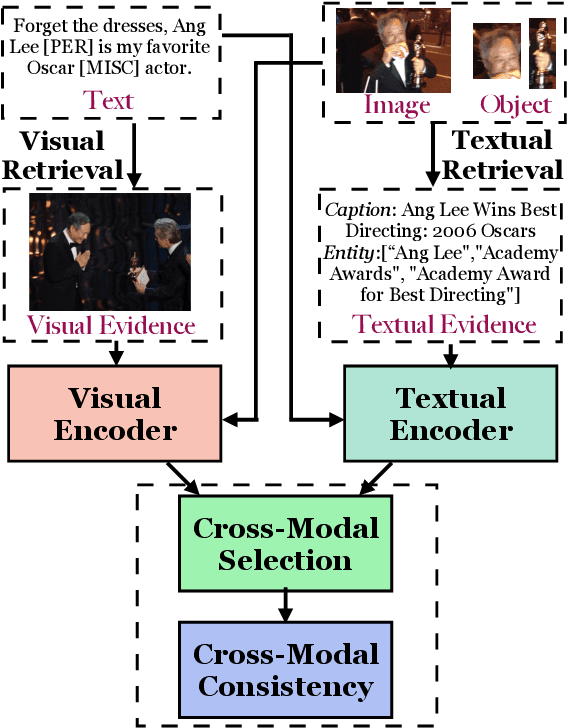
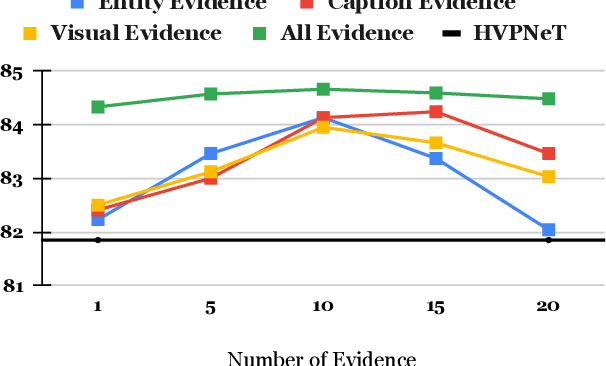
Multimodal relation extraction (MRE) is the task of identifying the semantic relationships between two entities based on the context of the sentence image pair. Existing retrieval-augmented approaches mainly focused on modeling the retrieved textual knowledge, but this may not be able to accurately identify complex relations. To improve the prediction, this research proposes to retrieve textual and visual evidence based on the object, sentence, and whole image. We further develop a novel approach to synthesize the object-level, image-level, and sentence-level information for better reasoning between the same and different modalities. Extensive experiments and analyses show that the proposed method is able to effectively select and compare evidence across modalities and significantly outperforms state-of-the-art models.
LD-GAN: Low-Dimensional Generative Adversarial Network for Spectral Image Generation with Variance Regularization
Apr 29, 2023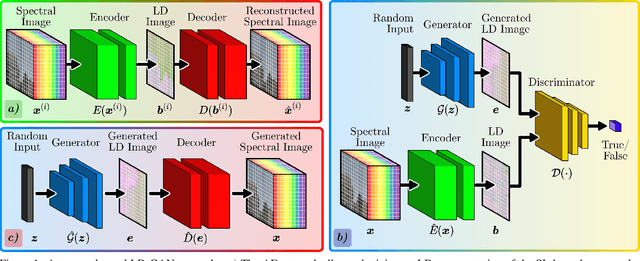
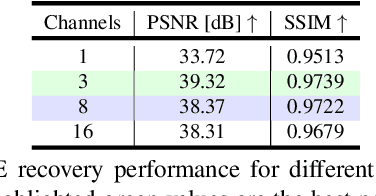

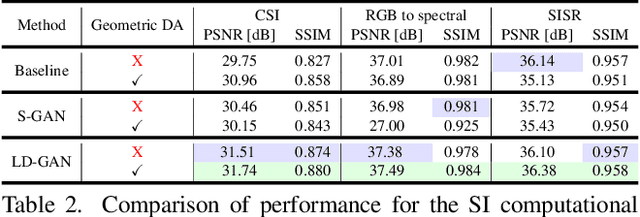
Deep learning methods are state-of-the-art for spectral image (SI) computational tasks. However, these methods are constrained in their performance since available datasets are limited due to the highly expensive and long acquisition time. Usually, data augmentation techniques are employed to mitigate the lack of data. Surpassing classical augmentation methods, such as geometric transformations, GANs enable diverse augmentation by learning and sampling from the data distribution. Nevertheless, GAN-based SI generation is challenging since the high-dimensionality nature of this kind of data hinders the convergence of the GAN training yielding to suboptimal generation. To surmount this limitation, we propose low-dimensional GAN (LD-GAN), where we train the GAN employing a low-dimensional representation of the {dataset} with the latent space of a pretrained autoencoder network. Thus, we generate new low-dimensional samples which are then mapped to the SI dimension with the pretrained decoder network. Besides, we propose a statistical regularization to control the low-dimensional representation variance for the autoencoder training and to achieve high diversity of samples generated with the GAN. We validate our method LD-GAN as data augmentation strategy for compressive spectral imaging, SI super-resolution, and RBG to spectral tasks with improvements varying from 0.5 to 1 [dB] in each task respectively. We perform comparisons against the non-data augmentation training, traditional DA, and with the same GAN adjusted and trained to generate the full-sized SIs. The code of this paper can be found in https://github.com/romanjacome99/LD_GAN.git
Ambient Diffusion: Learning Clean Distributions from Corrupted Data
May 30, 2023
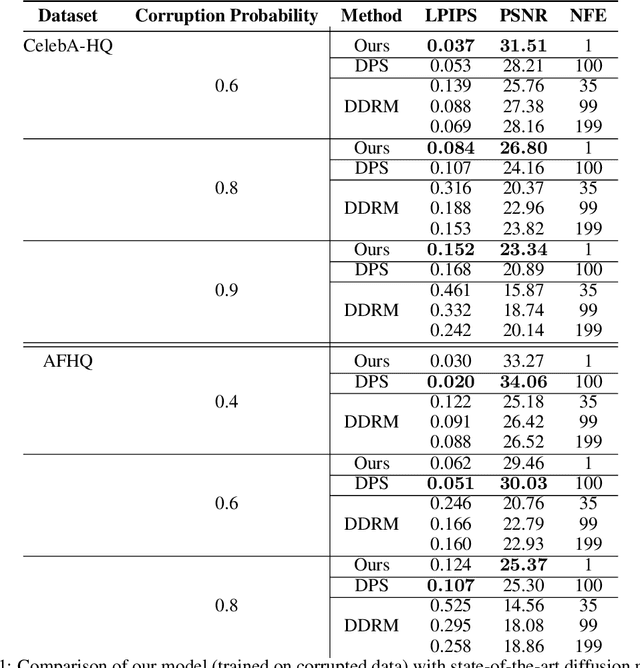


We present the first diffusion-based framework that can learn an unknown distribution using only highly-corrupted samples. This problem arises in scientific applications where access to uncorrupted samples is impossible or expensive to acquire. Another benefit of our approach is the ability to train generative models that are less likely to memorize individual training samples since they never observe clean training data. Our main idea is to introduce additional measurement distortion during the diffusion process and require the model to predict the original corrupted image from the further corrupted image. We prove that our method leads to models that learn the conditional expectation of the full uncorrupted image given this additional measurement corruption. This holds for any corruption process that satisfies some technical conditions (and in particular includes inpainting and compressed sensing). We train models on standard benchmarks (CelebA, CIFAR-10 and AFHQ) and show that we can learn the distribution even when all the training samples have $90\%$ of their pixels missing. We also show that we can finetune foundation models on small corrupted datasets (e.g. MRI scans with block corruptions) and learn the clean distribution without memorizing the training set.
Contextual Vision Transformers for Robust Representation Learning
May 30, 2023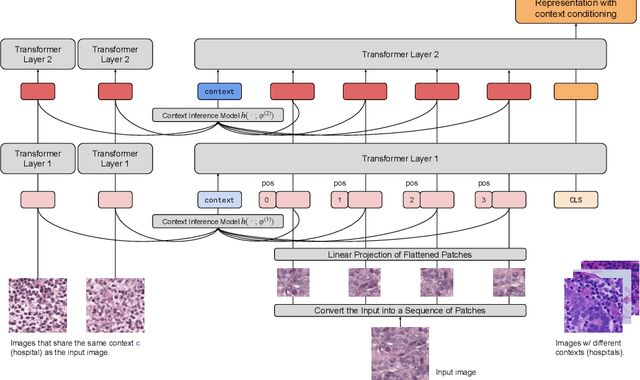
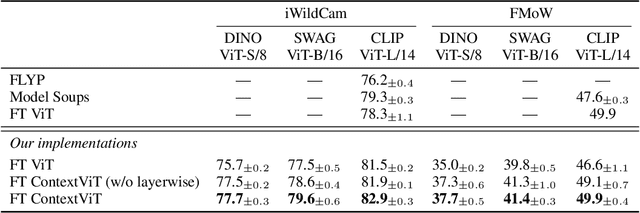
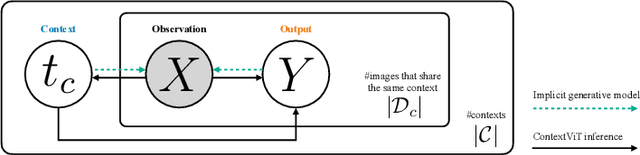

We present Contextual Vision Transformers (ContextViT), a method for producing robust feature representations for images exhibiting grouped structure such as covariates. ContextViT introduces an extra context token to encode group-specific information, allowing the model to explain away group-specific covariate structures while keeping core visual features shared across groups. Specifically, given an input image, Context-ViT maps images that share the same covariate into this context token appended to the input image tokens to capture the effects of conditioning the model on group membership. We furthermore introduce a context inference network to predict such tokens on the fly given a few samples from a group distribution, enabling ContextViT to generalize to new testing distributions at inference time. We illustrate the performance of ContextViT through a diverse range of applications. In supervised fine-tuning, we demonstrate that augmenting pre-trained ViTs with additional context conditioning leads to significant improvements in out-of-distribution generalization on iWildCam and FMoW. We also explored self-supervised representation learning with ContextViT. Our experiments on the Camelyon17 pathology imaging benchmark and the cpg-0000 microscopy imaging benchmark demonstrate that ContextViT excels in learning stable image featurizations amidst covariate shift, consistently outperforming its ViT counterpart.
iQPP: A Benchmark for Image Query Performance Prediction
Feb 21, 2023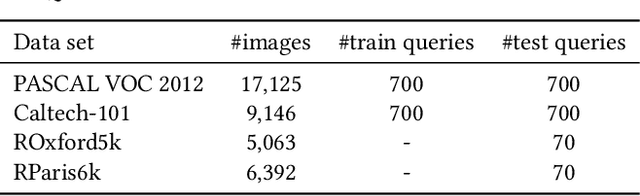

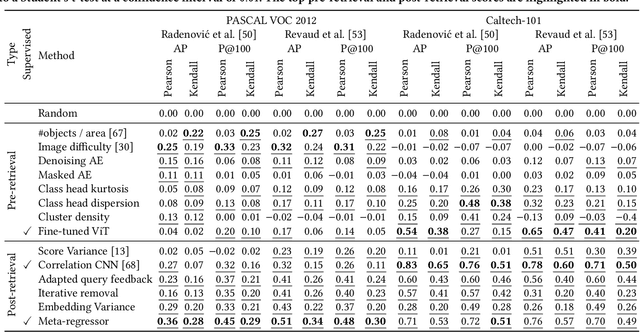
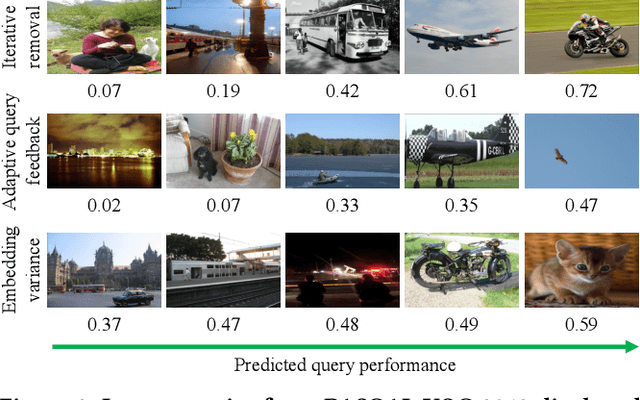
To date, query performance prediction (QPP) in the context of content-based image retrieval remains a largely unexplored task, especially in the query-by-example scenario, where the query is an image. To boost the exploration of the QPP task in image retrieval, we propose the first benchmark for image query performance prediction (iQPP). First, we establish a set of four data sets (PASCAL VOC 2012, Caltech-101, ROxford5k and RParis6k) and estimate the ground-truth difficulty of each query as the average precision or the precision@k, using two state-of-the-art image retrieval models. Next, we propose and evaluate novel pre-retrieval and post-retrieval query performance predictors, comparing them with existing or adapted (from text to image) predictors. The empirical results show that most predictors do not generalize across evaluation scenarios. Our comprehensive experiments indicate that iQPP is a challenging benchmark, revealing an important research gap that needs to be addressed in future work. We release our code and data as open source at https://github.com/Eduard6421/iQPP, to foster future research.