 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MobileViG: Graph-Based Sparse Attention for Mobile Vision Applications
Jul 01, 2023
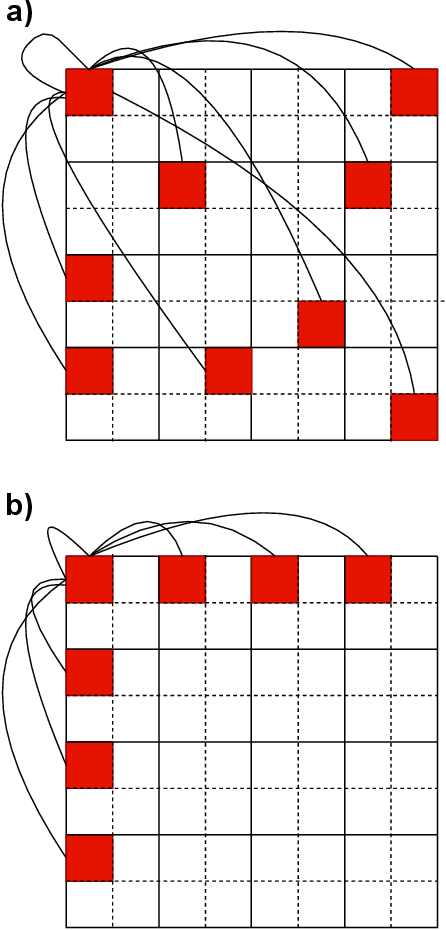
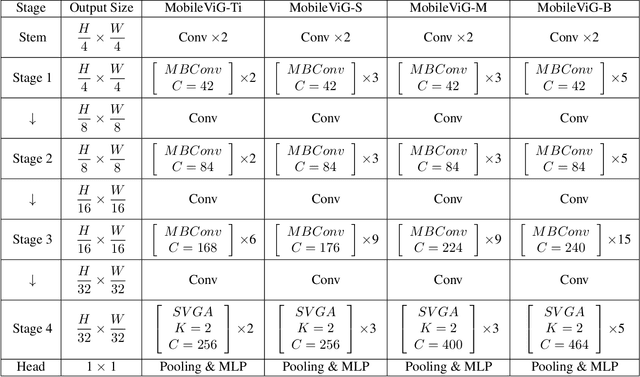
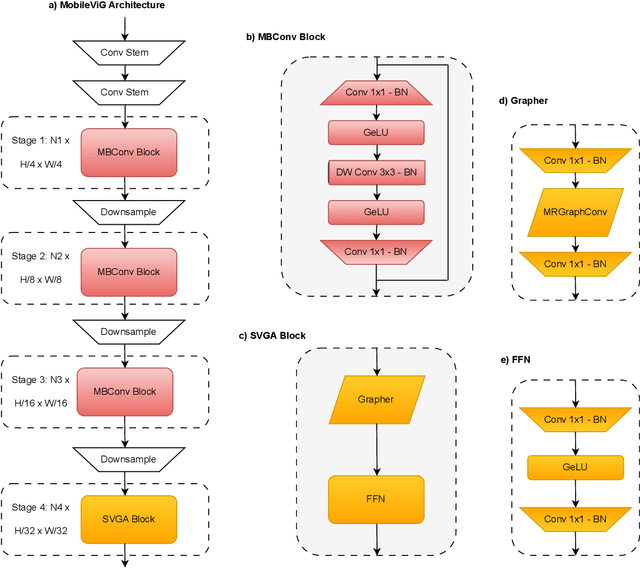
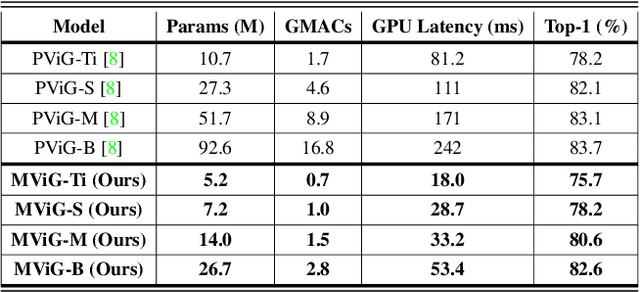
Traditionally, convolutional neural networks (CNN) and vision transformers (ViT) have dominated computer vision. However, recently proposed vision graph neural networks (ViG) provide a new avenue for exploration. Unfortunately, for mobile applications, ViGs are computationally expensive due to the overhead of representing images as graph structures. In this work, we propose a new graph-based sparse attention mechanism, Sparse Vision Graph Attention (SVGA), that is designed for ViGs running on mobile devices. Additionally, we propose the first hybrid CNN-GNN architecture for vision tasks on mobile devices, MobileViG, which uses SVGA. Extensive experiments show that MobileViG beats existing ViG models and existing mobile CNN and ViT architectures in terms of accuracy and/or speed on image classification, object detection, and instance segmentation tasks. Our fastest model, MobileViG-Ti, achieves 75.7% top-1 accuracy on ImageNet-1K with 0.78 ms inference latency on iPhone 13 Mini NPU (compiled with CoreML), which is faster than MobileNetV2x1.4 (1.02 ms, 74.7% top-1) and MobileNetV2x1.0 (0.81 ms, 71.8% top-1). Our largest model, MobileViG-B obtains 82.6% top-1 accuracy with only 2.30 ms latency, which is faster and more accurate than the similarly sized EfficientFormer-L3 model (2.77 ms, 82.4%). Our work proves that well designed hybrid CNN-GNN architectures can be a new avenue of exploration for designing models that are extremely fast and accurate on mobile devices. Our code is publicly available at https://github.com/SLDGroup/MobileViG.
Efficient Subclass Segmentation in Medical Images
Jul 01, 2023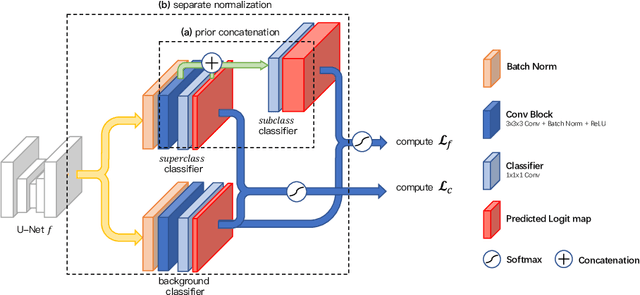
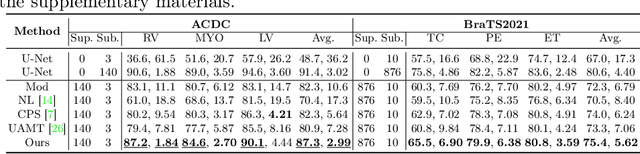
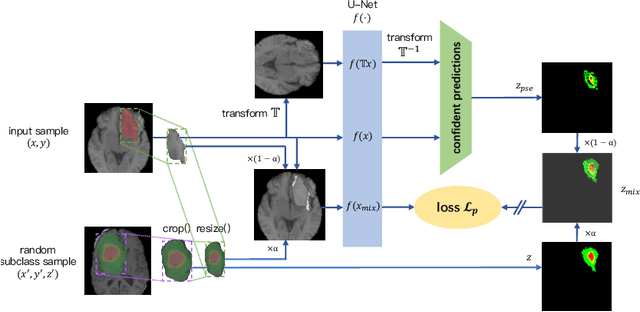
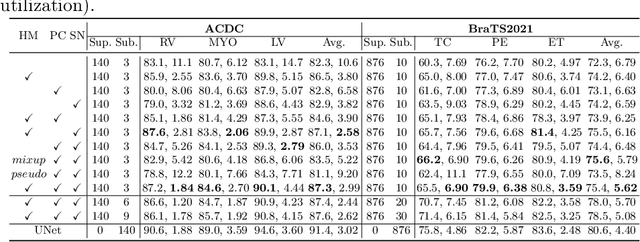
As research interests in medical image analysis become increasingly fine-grained, the cost for extensive annotation also rises. One feasible way to reduce the cost is to annotate with coarse-grained superclass labels while using limited fine-grained annotations as a complement. In this way, fine-grained data learning is assisted by ample coarse annotations. Recent studies in classification tasks have adopted this method to achieve satisfactory results. However, there is a lack of research on efficient learning of fine-grained subclasses in semantic segmentation tasks. In this paper, we propose a novel approach that leverages the hierarchical structure of categories to design network architecture. Meanwhile, a task-driven data generation method is presented to make it easier for the network to recognize different subclass categories. Specifically, we introduce a Prior Concatenation module that enhances confidence in subclass segmentation by concatenating predicted logits from the superclass classifier, a Separate Normalization module that stretches the intra-class distance within the same superclass to facilitate subclass segmentation, and a HierarchicalMix model that generates high-quality pseudo labels for unlabeled samples by fusing only similar superclass regions from labeled and unlabeled images. Our experiments on the BraTS2021 and ACDC datasets demonstrate that our approach achieves comparable accuracy to a model trained with full subclass annotations, with limited subclass annotations and sufficient superclass annotations. Our approach offers a promising solution for efficient fine-grained subclass segmentation in medical images. Our code is publicly available here.
Multi-scale Hierarchical Vision Transformer with Cascaded Attention Decoding for Medical Image Segmentation
Mar 29, 2023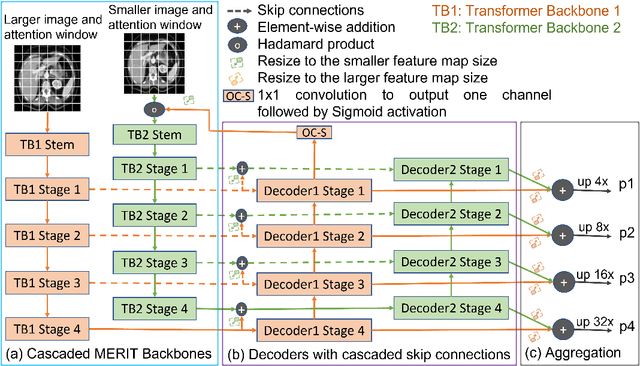
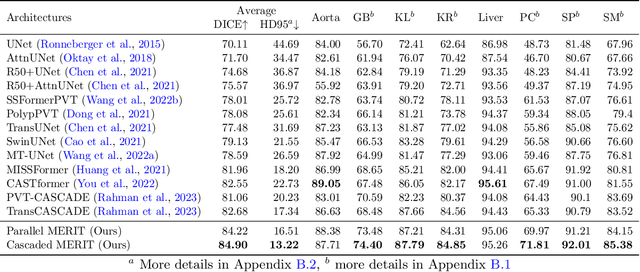
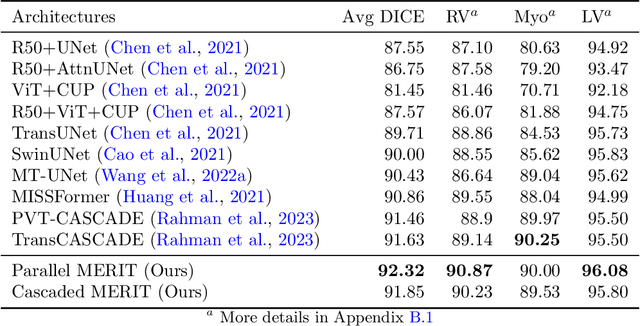
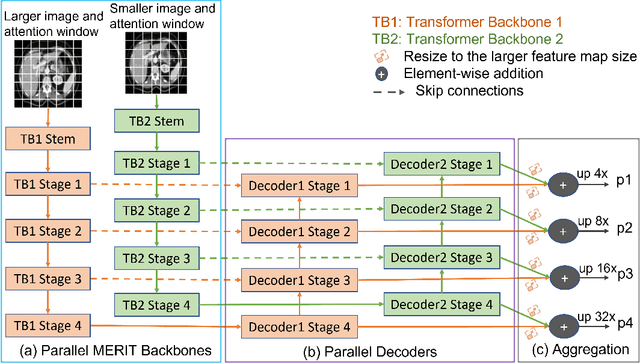
Transformers have shown great success in medical image segmentation. However, transformers may exhibit a limited generalization ability due to the underlying single-scale self-attention (SA) mechanism. In this paper, we address this issue by introducing a Multi-scale hiERarchical vIsion Transformer (MERIT) backbone network, which improves the generalizability of the model by computing SA at multiple scales. We also incorporate an attention-based decoder, namely Cascaded Attention Decoding (CASCADE), for further refinement of multi-stage features generated by MERIT. Finally, we introduce an effective multi-stage feature mixing loss aggregation (MUTATION) method for better model training via implicit ensembling. Our experiments on two widely used medical image segmentation benchmarks (i.e., Synapse Multi-organ, ACDC) demonstrate the superior performance of MERIT over state-of-the-art methods. Our MERIT architecture and MUTATION loss aggregation can be used with downstream medical image and semantic segmentation tasks.
CoT-MISR:Marrying Convolution and Transformer for Multi-Image Super-Resolution
Mar 12, 2023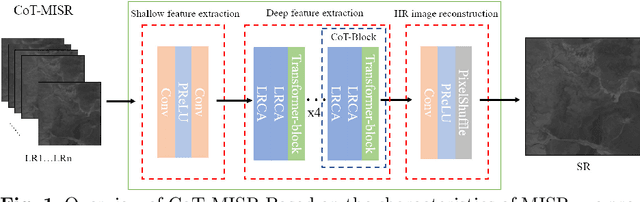
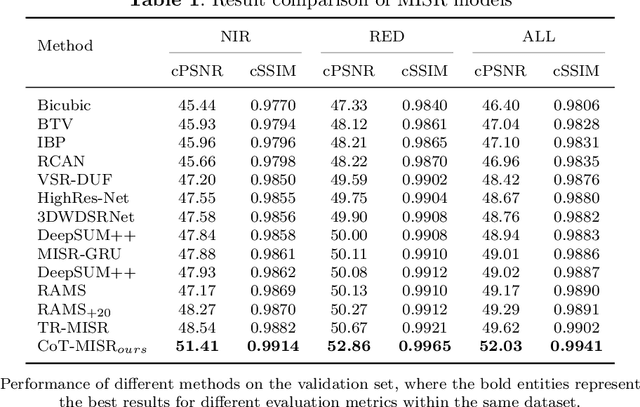
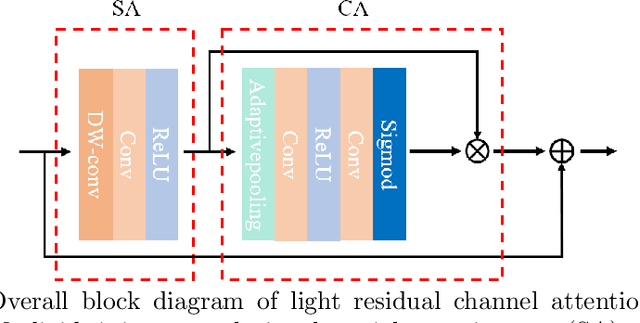
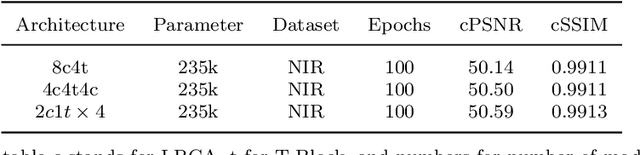
As a method of image restoration, image super-resolution has been extensively studied at first. How to transform a low-resolution image to restore its high-resolution image information is a problem that researchers have been exploring. In the early physical transformation methods, the high-resolution pictures generated by these methods always have a serious problem of missing information, and the edges and details can not be well recovered. With the development of hardware technology and mathematics, people begin to use in-depth learning methods for image super-resolution tasks, from direct in-depth learning models, residual channel attention networks, bi-directional suppression networks, to tr networks with transformer network modules, which have gradually achieved good results. In the research of multi-graph super-resolution, thanks to the establishment of multi-graph super-resolution dataset, we have experienced the evolution from convolution model to transformer model, and the quality of super-resolution has been continuously improved. However, we find that neither pure convolution nor pure tr network can make good use of low-resolution image information. Based on this, we propose a new end-to-end CoT-MISR network. CoT-MISR network makes up for local and global information by using the advantages of convolution and tr. The validation of dataset under equal parameters shows that our CoT-MISR network has reached the optimal score index.
SSL4EO-L: Datasets and Foundation Models for Landsat Imagery
Jun 15, 2023The Landsat program is the longest-running Earth observation program in history, with 50+ years of data acquisition by 8 satellites. The multispectral imagery captured by sensors onboard these satellites is critical for a wide range of scientific fields. Despite the increasing popularity of deep learning and remote sensing, the majority of researchers still use decision trees and random forests for Landsat image analysis due to the prevalence of small labeled datasets and lack of foundation models. In this paper, we introduce SSL4EO-L, the first ever dataset designed for Self-Supervised Learning for Earth Observation for the Landsat family of satellites (including 3 sensors and 2 product levels) and the largest Landsat dataset in history (5M image patches). Additionally, we modernize and re-release the L7 Irish and L8 Biome cloud detection datasets, and introduce the first ML benchmark datasets for Landsats 4-5 TM and Landsat 7 ETM+ SR. Finally, we pre-train the first foundation models for Landsat imagery using SSL4EO-L and evaluate their performance on multiple semantic segmentation tasks. All datasets and model weights are available via the TorchGeo (https://github.com/microsoft/torchgeo) library, making reproducibility and experimentation easy, and enabling scientific advancements in the burgeoning field of remote sensing for a myriad of downstream applications.
Generative Proxemics: A Prior for 3D Social Interaction from Images
Jun 15, 2023
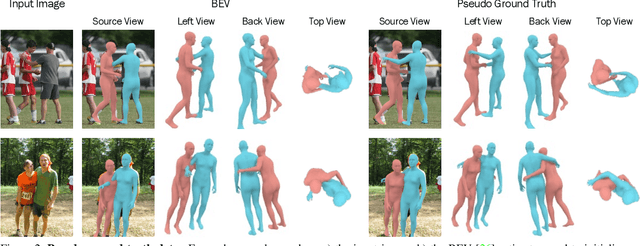

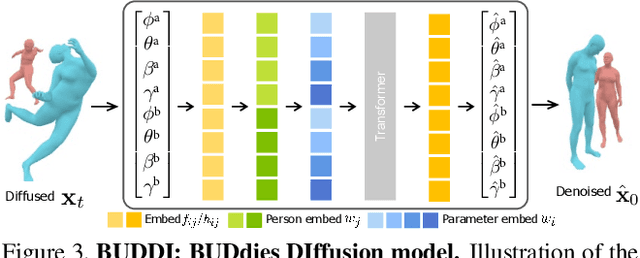
Social interaction is a fundamental aspect of human behavior and communication. The way individuals position themselves in relation to others, also known as proxemics, conveys social cues and affects the dynamics of social interaction. We present a novel approach that learns a 3D proxemics prior of two people in close social interaction. Since collecting a large 3D dataset of interacting people is a challenge, we rely on 2D image collections where social interactions are abundant. We achieve this by reconstructing pseudo-ground truth 3D meshes of interacting people from images with an optimization approach using existing ground-truth contact maps. We then model the proxemics using a novel denoising diffusion model called BUDDI that learns the joint distribution of two people in close social interaction directly in the SMPL-X parameter space. Sampling from our generative proxemics model produces realistic 3D human interactions, which we validate through a user study. Additionally, we introduce a new optimization method that uses the diffusion prior to reconstruct two people in close proximity from a single image without any contact annotation. Our approach recovers more accurate and plausible 3D social interactions from noisy initial estimates and outperforms state-of-the-art methods. See our project site for code, data, and model: muelea.github.io/buddi.
Efficient High-Resolution Template Matching with Vector Quantized Nearest Neighbour Fields
Jun 26, 2023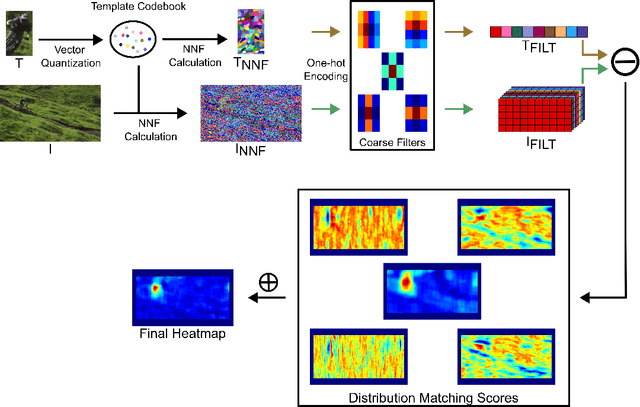
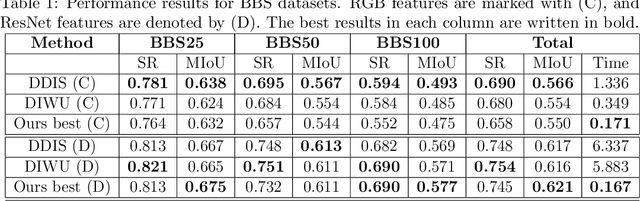
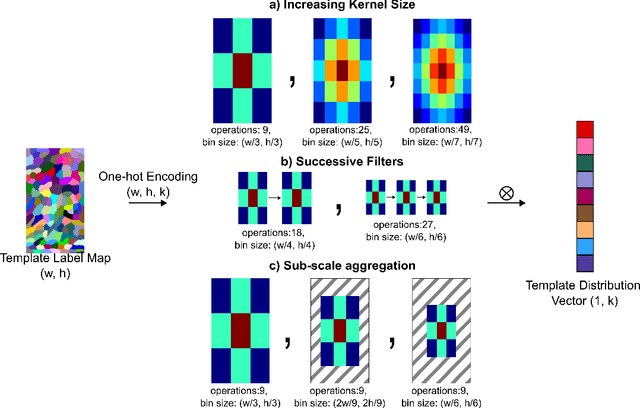
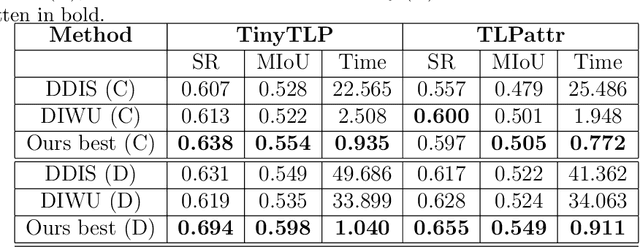
Template matching is a fundamental problem in computer vision and has applications in various fields, such as object detection, image registration, and object tracking. The current state-of-the-art methods rely on nearest-neighbour (NN) matching in which the query feature space is converted to NN space by representing each query pixel with its NN in the template pixels. The NN-based methods have been shown to perform better in occlusions, changes in appearance, illumination variations, and non-rigid transformations. However, NN matching scales poorly with high-resolution data and high feature dimensions. In this work, we present an NN-based template-matching method which efficiently reduces the NN computations and introduces filtering in the NN fields to consider deformations. A vector quantization step first represents the template with $k$ features, then filtering compares the template and query distributions over the $k$ features. We show that state-of-the-art performance was achieved in low-resolution data, and our method outperforms previous methods at higher resolution showing the robustness and scalability of the approach.
Segment Anything Meets Semantic Communication
Jun 03, 2023
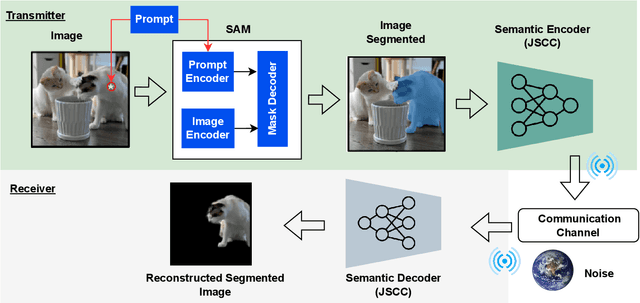
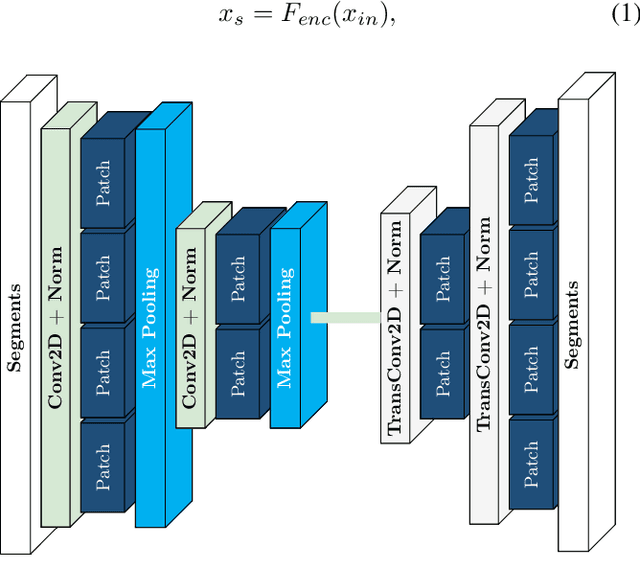
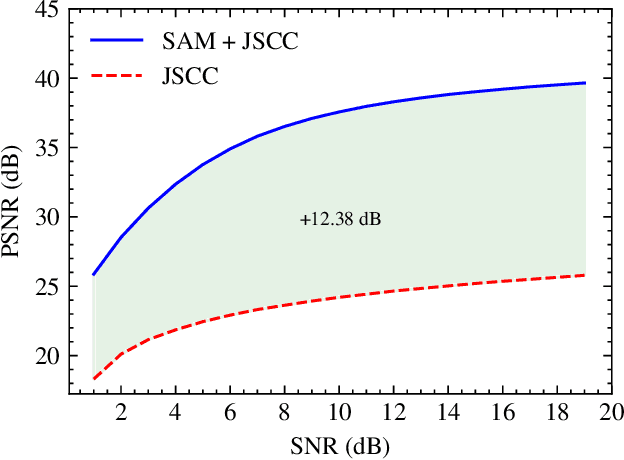
In light of the diminishing returns of traditional methods for enhancing transmission rates, the domain of semantic communication presents promising new frontiers. Focusing on image transmission, this paper explores the application of foundation models, particularly the Segment Anything Model (SAM) developed by Meta AI Research, to improve semantic communication. SAM is a promptable image segmentation model that has gained attention for its ability to perform zero-shot segmentation tasks without explicit training or domain-specific knowledge. By employing SAM's segmentation capability and lightweight neural network architecture for semantic coding, we propose a practical approach to semantic communication. We demonstrate that this approach retains critical semantic features, achieving higher image reconstruction quality and reducing communication overhead. This practical solution eliminates the resource-intensive stage of training a segmentation model and can be applied to any semantic coding architecture, paving the way for real-world applications.
Squeezing nnU-Nets with Knowledge Distillation for On-Board Cloud Detection
Jun 16, 2023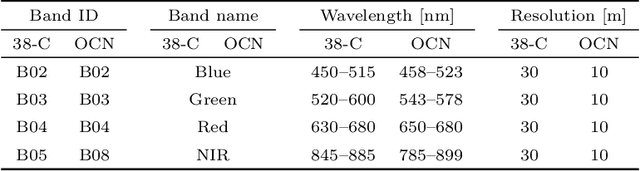
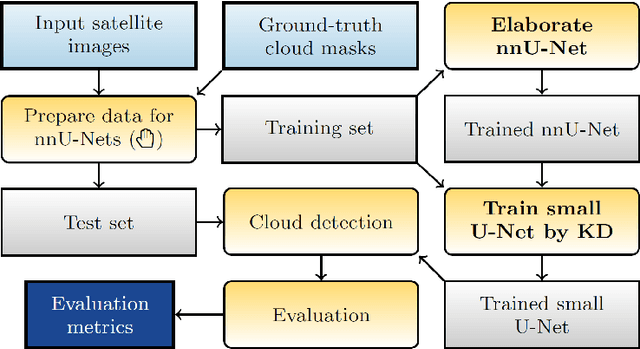
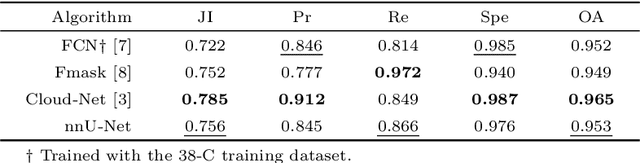
Cloud detection is a pivotal satellite image pre-processing step that can be performed both on the ground and on board a satellite to tag useful images. In the latter case, it can reduce the amount of data to downlink by pruning the cloudy areas, or to make a satellite more autonomous through data-driven acquisition re-scheduling. We approach this task with nnU-Nets, a self-reconfigurable framework able to perform meta-learning of a segmentation network over various datasets. Unfortunately, such models are commonly memory-inefficient due to their (very) large architectures. To benefit from them in on-board processing, we compress nnU-Nets with knowledge distillation into much smaller and compact U-Nets. Our experiments, performed over Sentinel-2 and Landsat-8 images revealed that nnU-Nets deliver state-of-the-art performance without any manual design. Our approach was ranked within the top 7% best solutions (across 847 teams) in the On Cloud N: Cloud Cover Detection Challenge, where we reached the Jaccard index of 0.882 over more than 10k unseen Sentinel-2 images (the winners obtained 0.897, the baseline U-Net with the ResNet-34 backbone: 0.817, and the classic Sentinel-2 image thresholding: 0.652). Finally, we showed that knowledge distillation enables to elaborate dramatically smaller (almost 280x) U-Nets when compared to nnU-Nets while still maintaining their segmentation capabilities.
Stable Diffusion is Unstable
Jun 06, 2023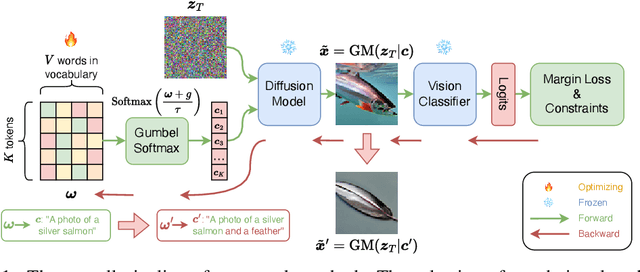
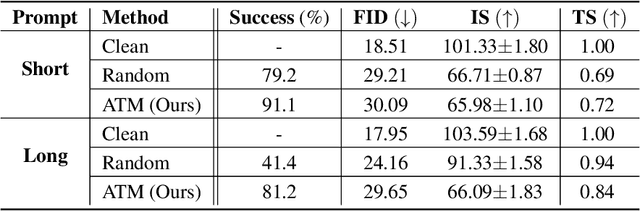


Recently, text-to-image models have been thriving. Despite their powerful generative capacity, our research has uncovered a lack of robustness in this generation process. Specifically, the introduction of small perturbations to the text prompts can result in the blending of primary subjects with other categories or their complete disappearance in the generated images. In this paper, we propose Auto-attack on Text-to-image Models (ATM), a gradient-based approach, to effectively and efficiently generate such perturbations. By learning a Gumbel Softmax distribution, we can make the discrete process of word replacement or extension continuous, thus ensuring the differentiability of the perturbation generation. Once the distribution is learned, ATM can sample multiple attack samples simultaneously. These attack samples can prevent the generative model from generating the desired subjects without compromising image quality. ATM has achieved a 91.1% success rate in short-text attacks and an 81.2% success rate in long-text attacks. Further empirical analysis revealed four attack patterns based on: 1) the variability in generation speed, 2) the similarity of coarse-grained characteristics, 3) the polysemy of words, and 4) the positioning of words.