 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Social Biases through the Text-to-Image Generation Lens
Mar 30, 2023
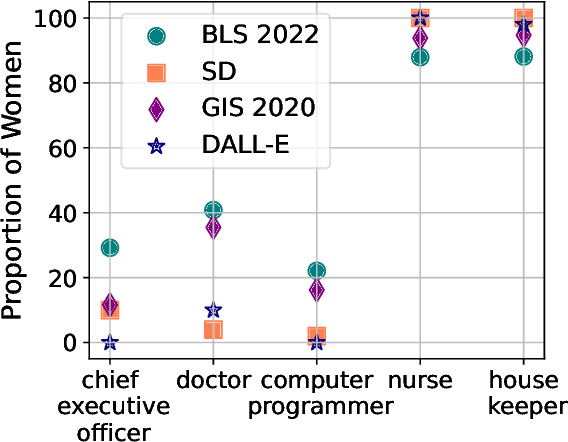
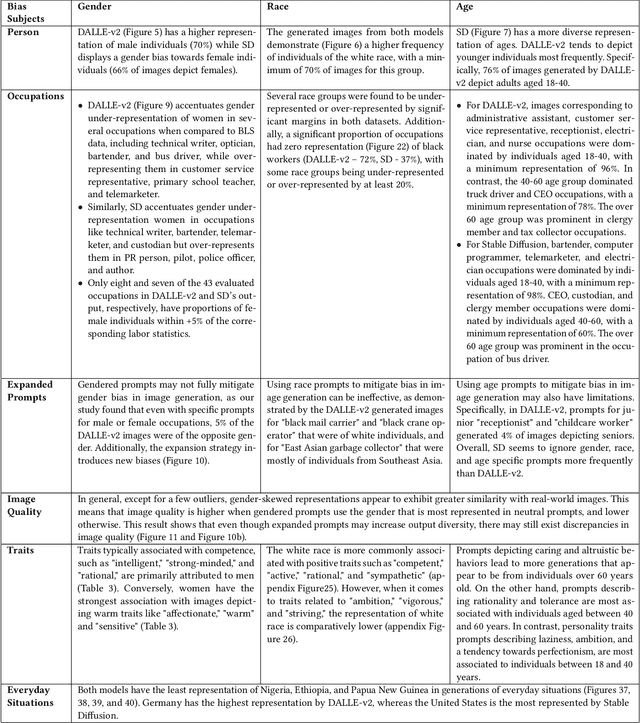
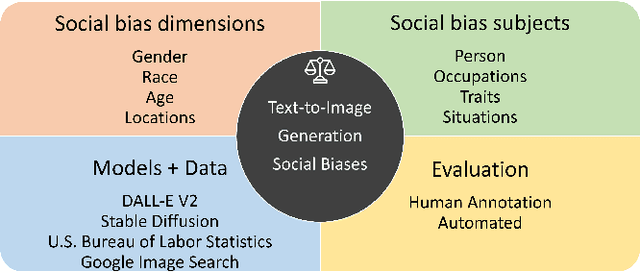

Text-to-Image (T2I) generation is enabling new applications that support creators, designers, and general end users of productivity software by generating illustrative content with high photorealism starting from a given descriptive text as a prompt. Such models are however trained on massive amounts of web data, which surfaces the peril of potential harmful biases that may leak in the generation process itself. In this paper, we take a multi-dimensional approach to studying and quantifying common social biases as reflected in the generated images, by focusing on how occupations, personality traits, and everyday situations are depicted across representations of (perceived) gender, age, race, and geographical location. Through an extensive set of both automated and human evaluation experiments we present findings for two popular T2I models: DALLE-v2 and Stable Diffusion. Our results reveal that there exist severe occupational biases of neutral prompts majorly excluding groups of people from results for both models. Such biases can get mitigated by increasing the amount of specification in the prompt itself, although the prompting mitigation will not address discrepancies in image quality or other usages of the model or its representations in other scenarios. Further, we observe personality traits being associated with only a limited set of people at the intersection of race, gender, and age. Finally, an analysis of geographical location representations on everyday situations (e.g., park, food, weddings) shows that for most situations, images generated through default location-neutral prompts are closer and more similar to images generated for locations of United States and Germany.
An Empirical Study on the Robustness of the Segment Anything Model (SAM)
May 23, 2023
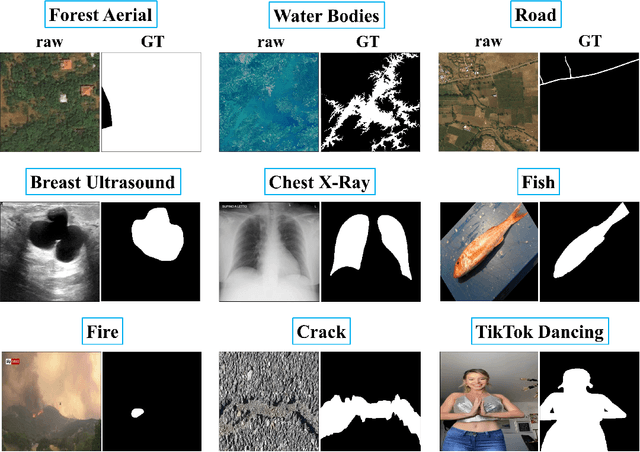
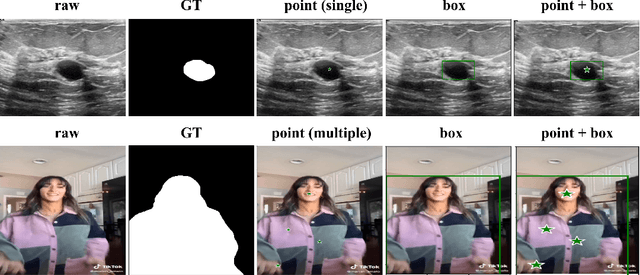
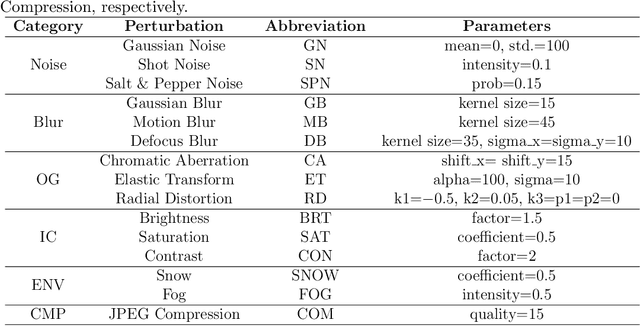
The Segment Anything Model (SAM) is a foundation model for general image segmentation. Although it exhibits impressive performance predominantly on natural images, understanding its robustness against various image perturbations and domains is critical for real-world applications where such challenges frequently arise. In this study we conduct a comprehensive robustness investigation of SAM under diverse real-world conditions. Our experiments encompass a wide range of image perturbations. Our experimental results demonstrate that SAM's performance generally declines under perturbed images, with varying degrees of vulnerability across different perturbations. By customizing prompting techniques and leveraging domain knowledge based on the unique characteristics of each dataset, the model's resilience to these perturbations can be enhanced, addressing dataset-specific challenges. This work sheds light on the limitations and strengths of SAM in real-world applications, promoting the development of more robust and versatile image segmentation solutions.
Ambiguity in solving imaging inverse problems with deep learning based operators
May 31, 2023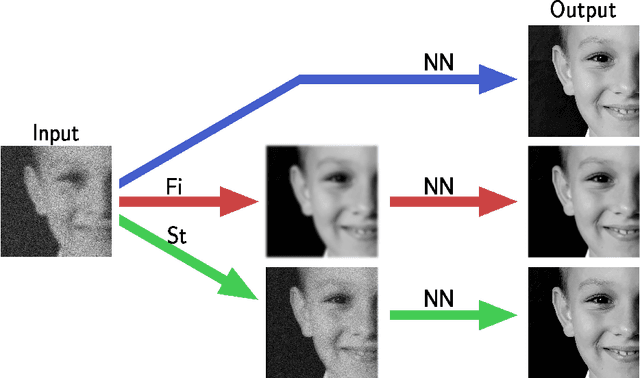
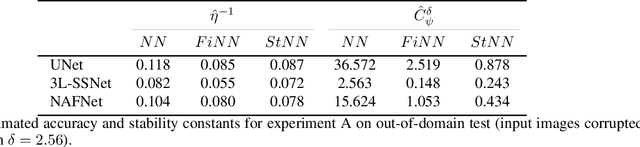
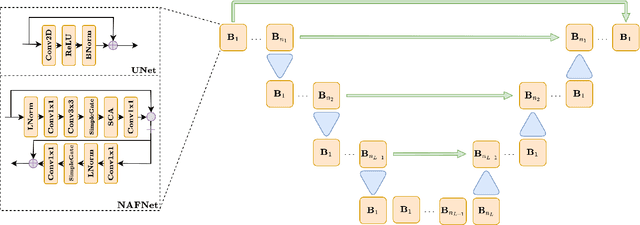

In recent years, large convolutional neural networks have been widely used as tools for image deblurring, because of their ability in restoring images very precisely. It is well known that image deblurring is mathematically modeled as an ill-posed inverse problem and its solution is difficult to approximate when noise affects the data. Really, one limitation of neural networks for deblurring is their sensitivity to noise and other perturbations, which can lead to instability and produce poor reconstructions. In addition, networks do not necessarily take into account the numerical formulation of the underlying imaging problem, when trained end-to-end. In this paper, we propose some strategies to improve stability without losing to much accuracy to deblur images with deep-learning based methods. First, we suggest a very small neural architecture, which reduces the execution time for training, satisfying a green AI need, and does not extremely amplify noise in the computed image. Second, we introduce a unified framework where a pre-processing step balances the lack of stability of the following, neural network-based, step. Two different pre-processors are presented: the former implements a strong parameter-free denoiser, and the latter is a variational model-based regularized formulation of the latent imaging problem. This framework is also formally characterized by mathematical analysis. Numerical experiments are performed to verify the accuracy and stability of the proposed approaches for image deblurring when unknown or not-quantified noise is present; the results confirm that they improve the network stability with respect to noise. In particular, the model-based framework represents the most reliable trade-off between visual precision and robustness.
RaSP: Relation-aware Semantic Prior for Weakly Supervised Incremental Segmentation
May 31, 2023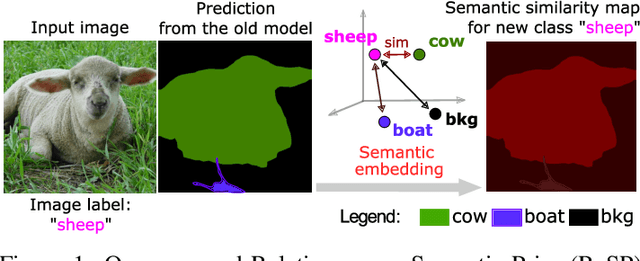
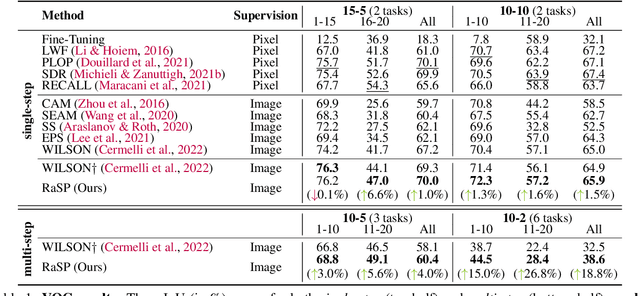
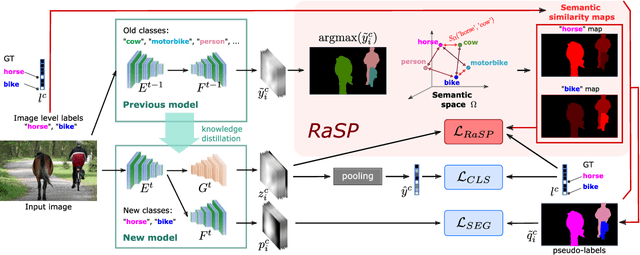
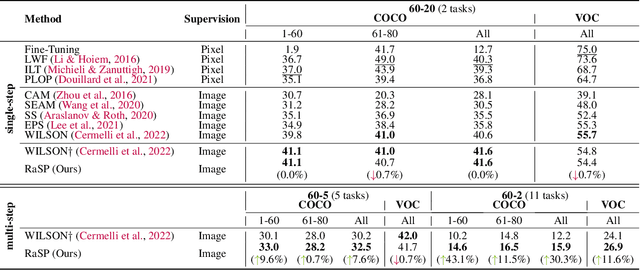
Class-incremental semantic image segmentation assumes multiple model updates, each enriching the model to segment new categories. This is typically carried out by providing expensive pixel-level annotations to the training algorithm for all new objects, limiting the adoption of such methods in practical applications. Approaches that solely require image-level labels offer an attractive alternative, yet, such coarse annotations lack precise information about the location and boundary of the new objects. In this paper we argue that, since classes represent not just indices but semantic entities, the conceptual relationships between them can provide valuable information that should be leveraged. We propose a weakly supervised approach that exploits such semantic relations to transfer objectness prior from the previously learned classes into the new ones, complementing the supervisory signal from image-level labels. We validate our approach on a number of continual learning tasks, and show how even a simple pairwise interaction between classes can significantly improve the segmentation mask quality of both old and new classes. We show these conclusions still hold for longer and, hence, more realistic sequences of tasks and for a challenging few-shot scenario.
Hyperspectral Image Segmentation: A Preliminary Study on the Oral and Dental Spectral Image Database (ODSI-DB)
Mar 14, 2023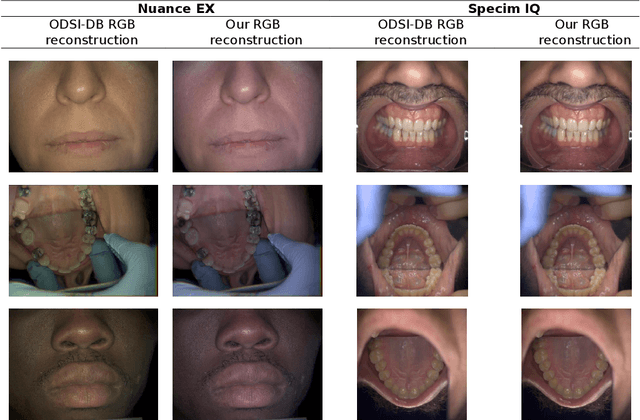
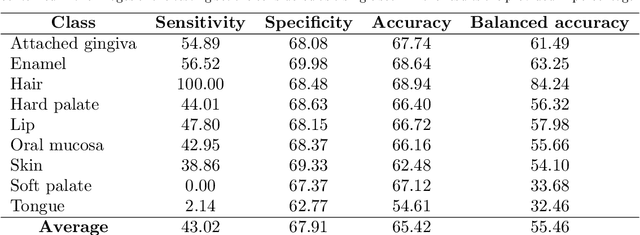
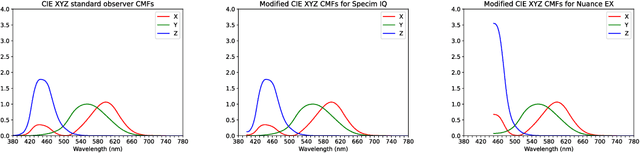
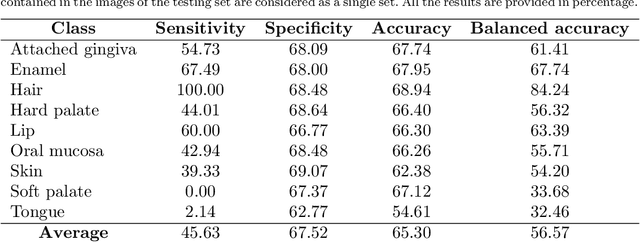
Visual discrimination of clinical tissue types remains challenging, with traditional RGB imaging providing limited contrast for such tasks. Hyperspectral imaging (HSI) is a promising technology providing rich spectral information that can extend far beyond three-channel RGB imaging. Moreover, recently developed snapshot HSI cameras enable real-time imaging with significant potential for clinical applications. Despite this, the investigation into the relative performance of HSI over RGB imaging for semantic segmentation purposes has been limited, particularly in the context of medical imaging. Here we compare the performance of state-of-the-art deep learning image segmentation methods when trained on hyperspectral images, RGB images, hyperspectral pixels (minus spatial context), and RGB pixels (disregarding spatial context). To achieve this, we employ the recently released Oral and Dental Spectral Image Database (ODSI-DB), which consists of 215 manually segmented dental reflectance spectral images with 35 different classes across 30 human subjects. The recent development of snapshot HSI cameras has made real-time clinical HSI a distinct possibility, though successful application requires a comprehensive understanding of the additional information HSI offers. Our work highlights the relative importance of spectral resolution, spectral range, and spatial information to both guide the development of HSI cameras and inform future clinical HSI applications.
Dense and Aligned Captions (DAC) Promote Compositional Reasoning in VL Models
Jun 01, 2023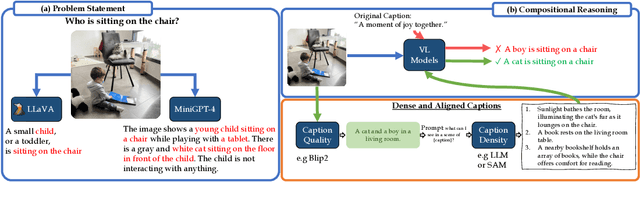
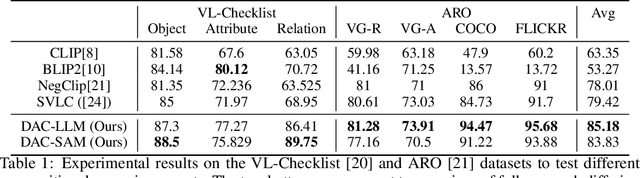
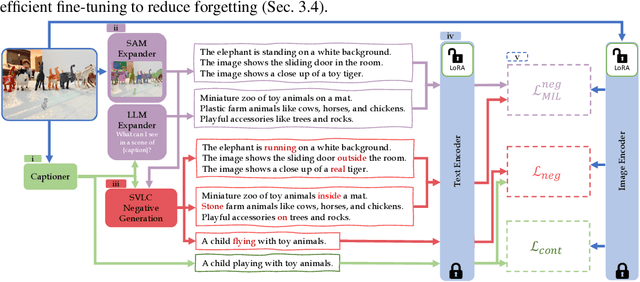

Vision and Language (VL) models offer an effective method for aligning representation spaces of images and text, leading to numerous applications such as cross-modal retrieval, visual question answering, captioning, and more. However, the aligned image-text spaces learned by all the popular VL models are still suffering from the so-called `object bias' - their representations behave as `bags of nouns', mostly ignoring or downsizing the attributes, relations, and states of objects described/appearing in texts/images. Although some great attempts at fixing these `compositional reasoning' issues were proposed in the recent literature, the problem is still far from being solved. In this paper, we uncover two factors limiting the VL models' compositional reasoning performance. These two factors are properties of the paired VL dataset used for finetuning and pre-training the VL model: (i) the caption quality, or in other words `image-alignment', of the texts; and (ii) the `density' of the captions in the sense of mentioning all the details appearing on the image. We propose a fine-tuning approach for automatically treating these factors leveraging a standard VL dataset (CC3M). Applied to CLIP, we demonstrate its significant compositional reasoning performance increase of up to $\sim27\%$ over the base model, up to $\sim20\%$ over the strongest baseline, and by $6.7\%$ on average.
PandaGPT: One Model To Instruction-Follow Them All
May 25, 2023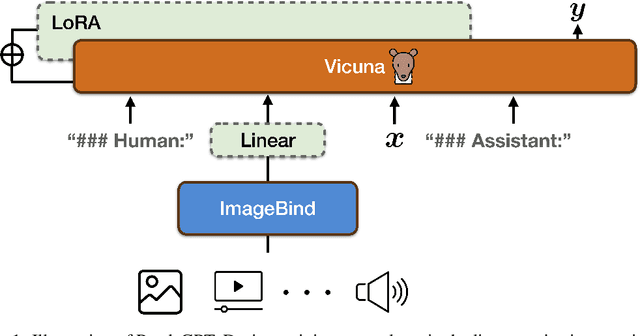



We present PandaGPT, an approach to emPower large lANguage moDels with visual and Auditory instruction-following capabilities. Our pilot experiments show that PandaGPT can perform complex tasks such as detailed image description generation, writing stories inspired by videos, and answering questions about audios. More interestingly, PandaGPT can take multimodal inputs simultaneously and compose their semantics naturally. For example, PandaGPT can connect how objects look in an image/video and how they sound in an audio. To do so, PandaGPT combines the multimodal encoders from ImageBind and the large language models from Vicuna. Notably, only aligned image-text pairs are required for the training of PandaGPT. Thanks to the strong capability of ImageBind in embedding data from different modalities into the same space, PandaGPT displays emergent, i.e. zero-shot, cross-modal behaviors for data other than image and text (e.g., video, audio, depth, thermal, and IMU). We hope that PandaGPT serves as an initial step toward building AGI that can perceive and understand inputs in different modalities holistically, as we humans do. Our project page is at https://panda-gpt.github.io/.
AssistGPT: A General Multi-modal Assistant that can Plan, Execute, Inspect, and Learn
Jun 14, 2023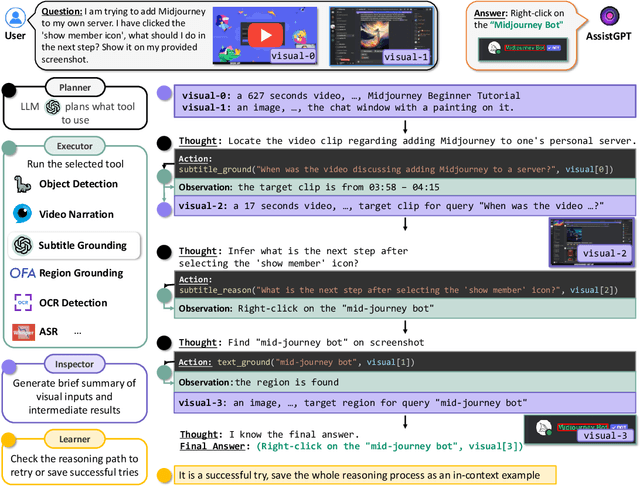


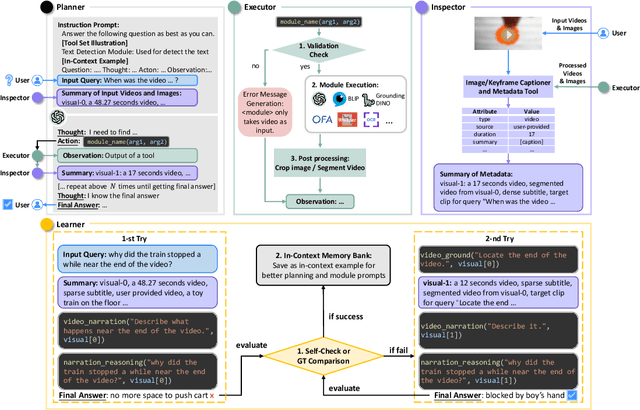
Recent research on Large Language Models (LLMs) has led to remarkable advancements in general NLP AI assistants. Some studies have further explored the use of LLMs for planning and invoking models or APIs to address more general multi-modal user queries. Despite this progress, complex visual-based tasks still remain challenging due to the diverse nature of visual tasks. This diversity is reflected in two aspects: 1) Reasoning paths. For many real-life applications, it is hard to accurately decompose a query simply by examining the query itself. Planning based on the specific visual content and the results of each step is usually required. 2) Flexible inputs and intermediate results. Input forms could be flexible for in-the-wild cases, and involves not only a single image or video but a mixture of videos and images, e.g., a user-view image with some reference videos. Besides, a complex reasoning process will also generate diverse multimodal intermediate results, e.g., video narrations, segmented video clips, etc. To address such general cases, we propose a multi-modal AI assistant, AssistGPT, with an interleaved code and language reasoning approach called Plan, Execute, Inspect, and Learn (PEIL) to integrate LLMs with various tools. Specifically, the Planner is capable of using natural language to plan which tool in Executor should do next based on the current reasoning progress. Inspector is an efficient memory manager to assist the Planner to feed proper visual information into a specific tool. Finally, since the entire reasoning process is complex and flexible, a Learner is designed to enable the model to autonomously explore and discover the optimal solution. We conducted experiments on A-OKVQA and NExT-QA benchmarks, achieving state-of-the-art results. Moreover, showcases demonstrate the ability of our system to handle questions far more complex than those found in the benchmarks.
NERFBK: A High-Quality Benchmark for NERF-Based 3D Reconstruction
Jun 15, 2023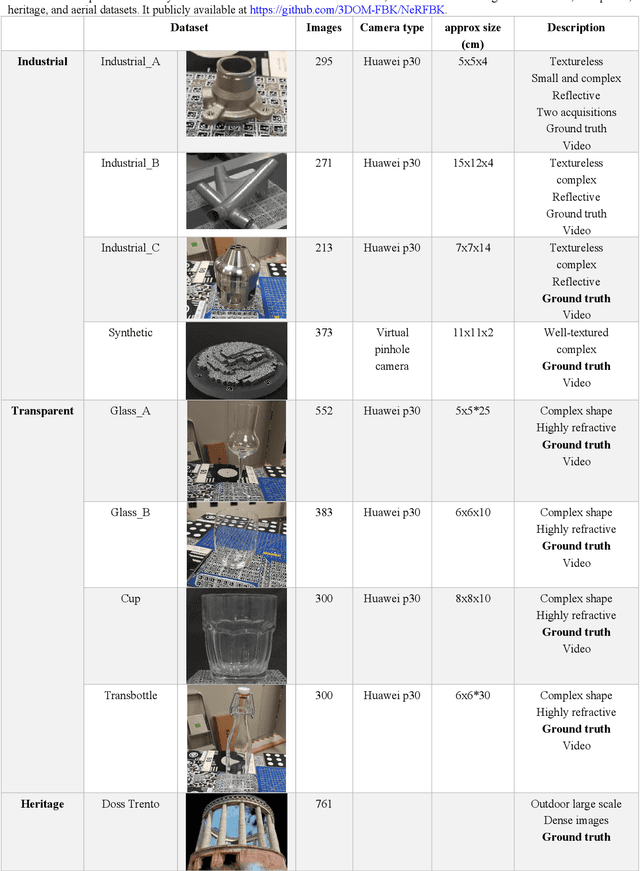
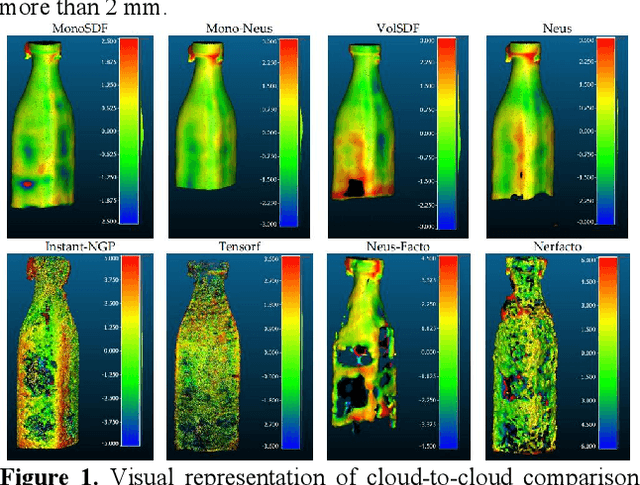
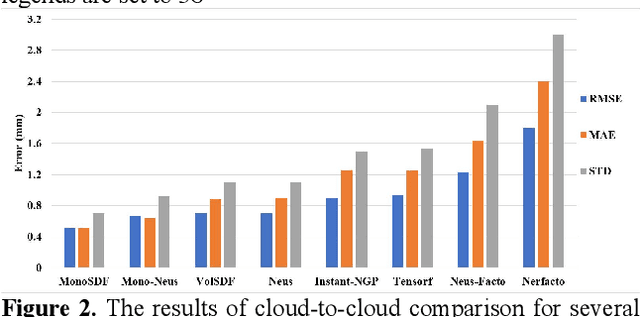
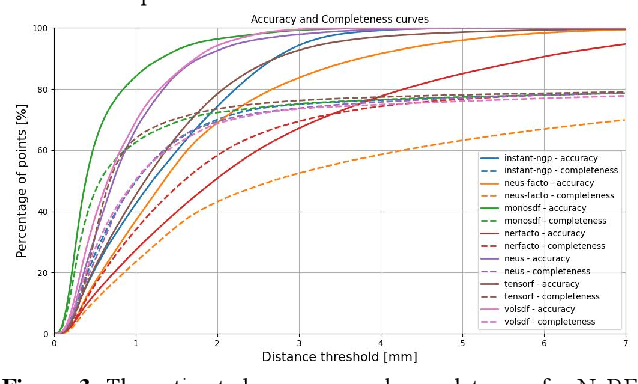
This paper introduces a new real and synthetic dataset called NeRFBK specifically designed for testing and comparing NeRF-based 3D reconstruction algorithms. High-quality 3D reconstruction has significant potential in various fields, and advancements in image-based algorithms make it essential to evaluate new advanced techniques. However, gathering diverse data with precise ground truth is challenging and may not encompass all relevant applications. The NeRFBK dataset addresses this issue by providing multi-scale, indoor and outdoor datasets with high-resolution images and videos and camera parameters for testing and comparing NeRF-based algorithms. This paper presents the design and creation of the NeRFBK benchmark, various examples and application scenarios, and highlights its potential for advancing the field of 3D reconstruction.
RecFusion: A Binomial Diffusion Process for 1D Data for Recommendation
Jun 15, 2023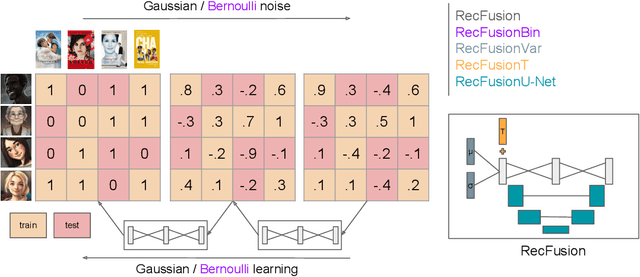
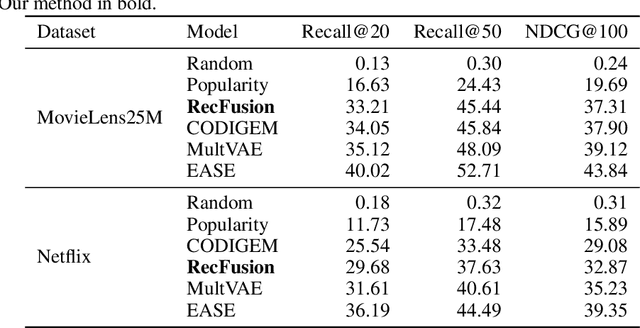
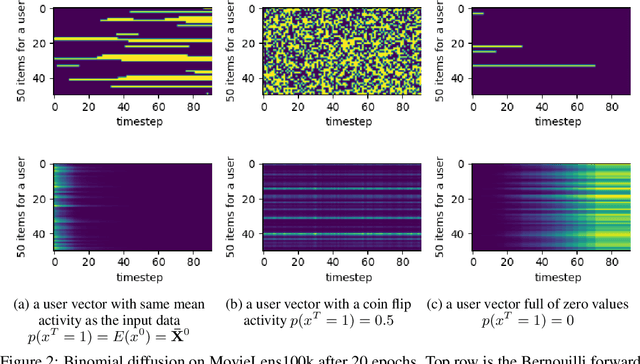
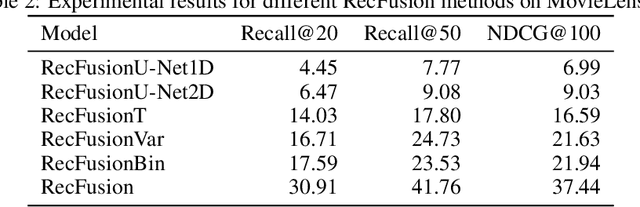
In this paper we propose RecFusion, which comprise a set of diffusion models for recommendation. Unlike image data which contain spatial correlations, a user-item interaction matrix, commonly utilized in recommendation, lacks spatial relationships between users and items. We formulate diffusion on a 1D vector and propose binomial diffusion, which explicitly models binary user-item interactions with a Bernoulli process. We show that RecFusion approaches the performance of complex VAE baselines on the core recommendation setting (top-n recommendation for binary non-sequential feedback) and the most common datasets (MovieLens and Netflix). Our proposed diffusion models that are specialized for 1D and/or binary setups have implications beyond recommendation systems, such as in the medical domain with MRI and CT scans.