 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Generative Models for Decision-Making and Control
Jun 15, 2023
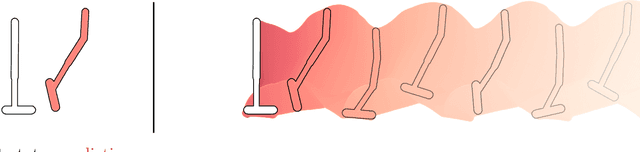
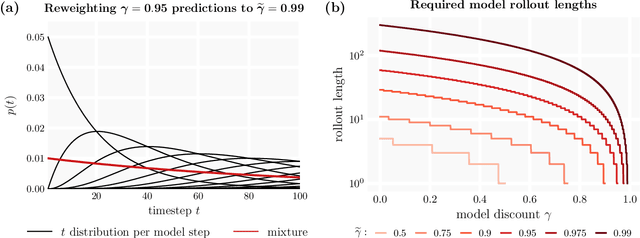
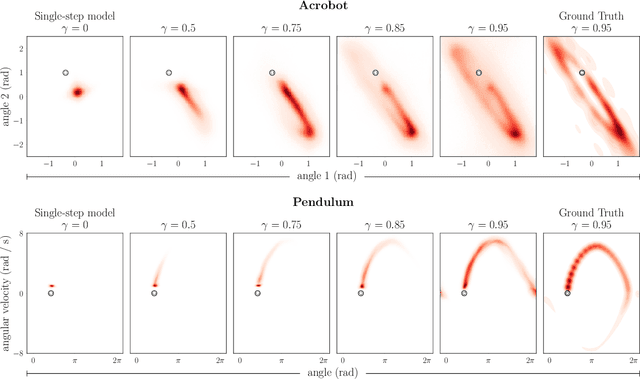
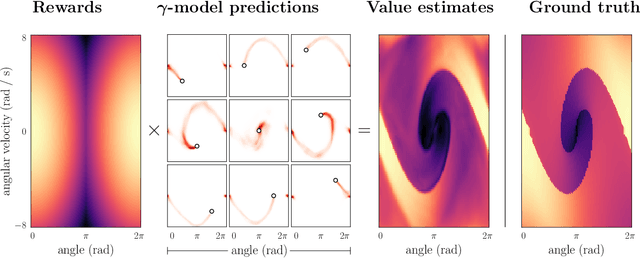
Deep model-based reinforcement learning methods offer a conceptually simple approach to the decision-making and control problem: use learning for the purpose of estimating an approximate dynamics model, and offload the rest of the work to classical trajectory optimization. However, this combination has a number of empirical shortcomings, limiting the usefulness of model-based methods in practice. The dual purpose of this thesis is to study the reasons for these shortcomings and to propose solutions for the uncovered problems. Along the way, we highlight how inference techniques from the contemporary generative modeling toolbox, including beam search, classifier-guided sampling, and image inpainting, can be reinterpreted as viable planning strategies for reinforcement learning problems.
Machine learning based biomedical image processing for echocardiographic images
Mar 16, 2023The popularity of Artificial intelligence and machine learning have prompted researchers to use it in the recent researches. The proposed method uses K-Nearest Neighbor (KNN) algorithm for segmentation of medical images, extracting of image features for analysis by classifying the data based on the neural networks. Classification of the images in medical imaging is very important, KNN is one suitable algorithm which is simple, conceptual and computational, which provides very good accuracy in results. KNN algorithm is a unique user-friendly approach with wide range of applications in machine learning algorithms which are majorly used for the various image processing applications including classification, segmentation and regression issues of the image processing. The proposed system uses gray level co-occurrence matrix features. The trained neural network has been tested successfully on a group of echocardiographic images, errors were compared using regression plot. The results of the algorithm are tested using various quantitative as well as qualitative metrics and proven to exhibit better performance in terms of both quantitative and qualitative metrics in terms of current state-of-the-art methods in the related area. To compare the performance of trained neural network the regression analysis performed showed a good correlation.
PND-Net: Physics based Non-local Dual-domain Network for Metal Artifact Reduction
May 28, 2023
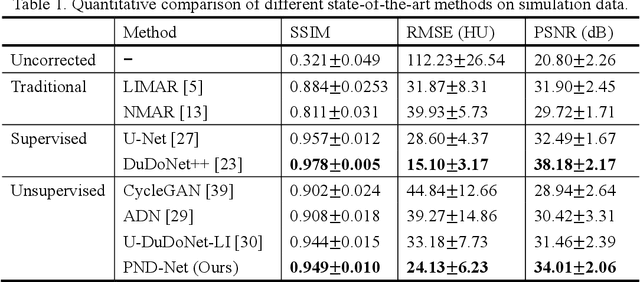
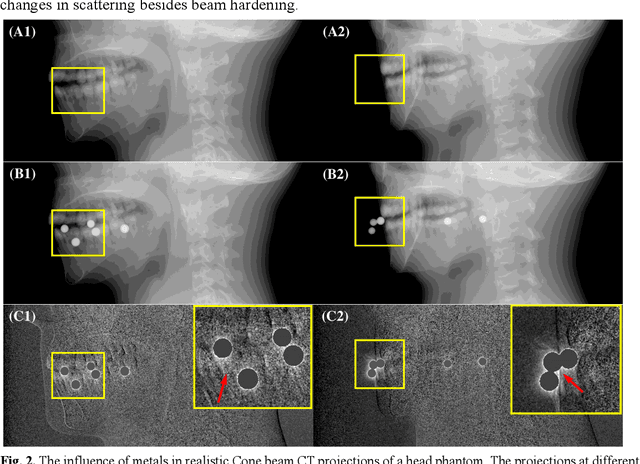
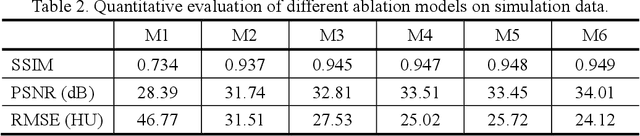
Metal artifacts caused by the presence of metallic implants tremendously degrade the reconstructed computed tomography (CT) image quality, affecting clinical diagnosis or reducing the accuracy of organ delineation and dose calculation in radiotherapy. Recently, deep learning methods in sinogram and image domains have been rapidly applied on metal artifact reduction (MAR) task. The supervised dual-domain methods perform well on synthesized data, while unsupervised methods with unpaired data are more generalized on clinical data. However, most existing methods intend to restore the corrupted sinogram within metal trace, which essentially remove beam hardening artifacts but ignore other components of metal artifacts, such as scatter, non-linear partial volume effect and noise. In this paper, we mathematically derive a physical property of metal artifacts which is verified via Monte Carlo (MC) simulation and propose a novel physics based non-local dual-domain network (PND-Net) for MAR in CT imaging. Specifically, we design a novel non-local sinogram decomposition network (NSD-Net) to acquire the weighted artifact component, and an image restoration network (IR-Net) is proposed to reduce the residual and secondary artifacts in the image domain. To facilitate the generalization and robustness of our method on clinical CT images, we employ a trainable fusion network (F-Net) in the artifact synthesis path to achieve unpaired learning. Furthermore, we design an internal consistency loss to ensure the integrity of anatomical structures in the image domain, and introduce the linear interpolation sinogram as prior knowledge to guide sinogram decomposition. Extensive experiments on simulation and clinical data demonstrate that our method outperforms the state-of-the-art MAR methods.
SCANet: Self-Paced Semi-Curricular Attention Network for Non-Homogeneous Image Dehazing
Apr 17, 2023

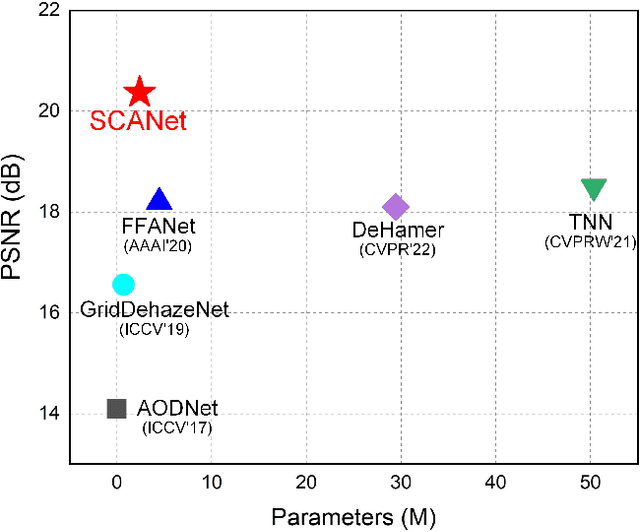
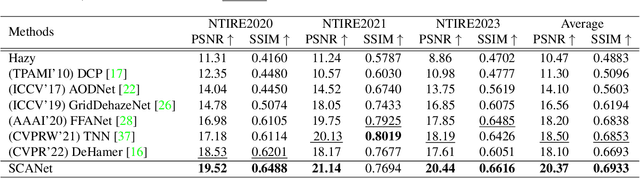
The presence of non-homogeneous haze can cause scene blurring, color distortion, low contrast, and other degradations that obscure texture details. Existing homogeneous dehazing methods struggle to handle the non-uniform distribution of haze in a robust manner. The crucial challenge of non-homogeneous dehazing is to effectively extract the non-uniform distribution features and reconstruct the details of hazy areas with high quality. In this paper, we propose a novel self-paced semi-curricular attention network, called SCANet, for non-homogeneous image dehazing that focuses on enhancing haze-occluded regions. Our approach consists of an attention generator network and a scene reconstruction network. We use the luminance differences of images to restrict the attention map and introduce a self-paced semi-curricular learning strategy to reduce learning ambiguity in the early stages of training. Extensive quantitative and qualitative experiments demonstrate that our SCANet outperforms many state-of-the-art methods. The code is publicly available at https://github.com/gy65896/SCANet.
Learning to Predict Scene-Level Implicit 3D from Posed RGBD Data
Jun 14, 2023
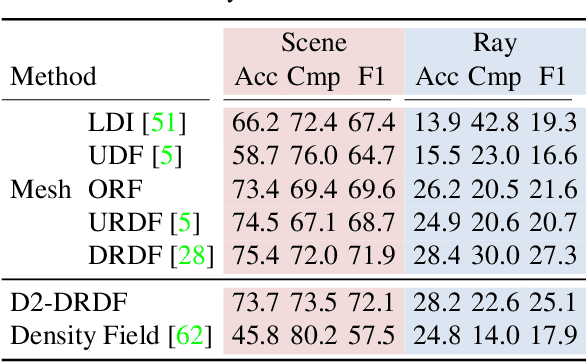
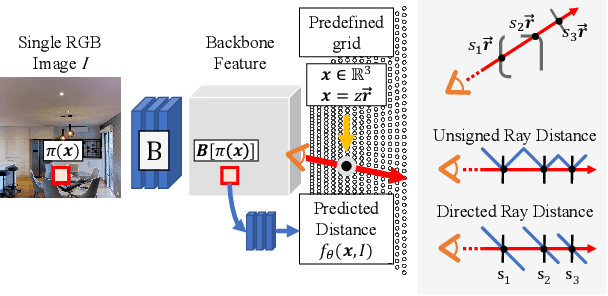
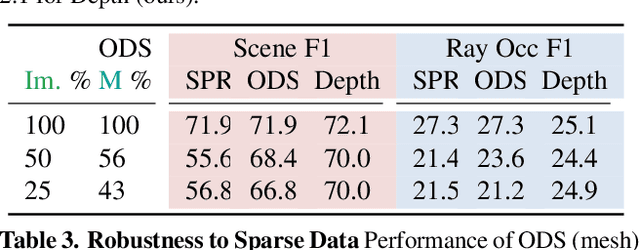
We introduce a method that can learn to predict scene-level implicit functions for 3D reconstruction from posed RGBD data. At test time, our system maps a previously unseen RGB image to a 3D reconstruction of a scene via implicit functions. While implicit functions for 3D reconstruction have often been tied to meshes, we show that we can train one using only a set of posed RGBD images. This setting may help 3D reconstruction unlock the sea of accelerometer+RGBD data that is coming with new phones. Our system, D2-DRDF, can match and sometimes outperform current methods that use mesh supervision and shows better robustness to sparse data.
Unsupervised Pansharpening via Low-rank Diffusion Model
May 18, 2023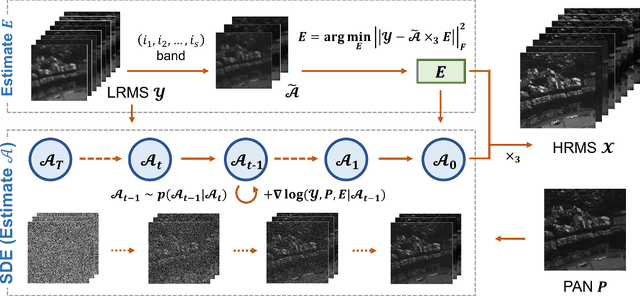


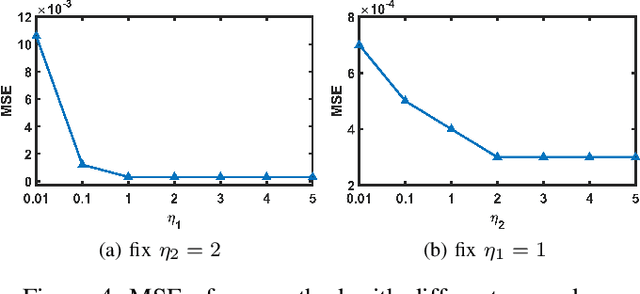
Pansharpening is a process of merging a highresolution panchromatic (PAN) image and a low-resolution multispectral (LRMS) image to create a single high-resolution multispectral (HRMS) image. Most of the existing deep learningbased pansharpening methods have poor generalization ability and the traditional model-based pansharpening methods need careful manual exploration for the image structure prior. To alleviate these issues, this paper proposes an unsupervised pansharpening method by combining the diffusion model with the low-rank matrix factorization technique. Specifically, we assume that the HRMS image is decomposed into the product of two low-rank tensors, i.e., the base tensor and the coefficient matrix. The base tensor lies on the image field and has low spectral dimension, we can thus conveniently utilize a pre-trained remote sensing diffusion model to capture its image structures. Additionally, we derive a simple yet quite effective way to preestimate the coefficient matrix from the observed LRMS image, which preserves the spectral information of the HRMS. Extensive experimental results on some benchmark datasets demonstrate that our proposed method performs better than traditional model-based approaches and has better generalization ability than deep learning-based techniques. The code is released in https://github.com/xyrui/PLRDiff.
StraIT: Non-autoregressive Generation with Stratified Image Transformer
Mar 01, 2023
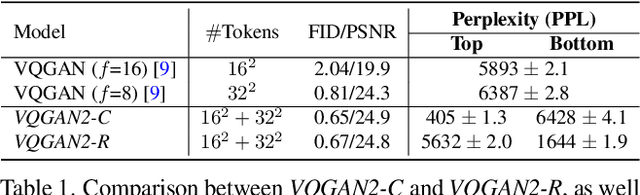
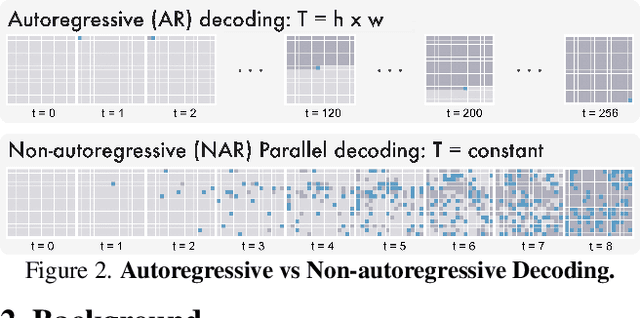
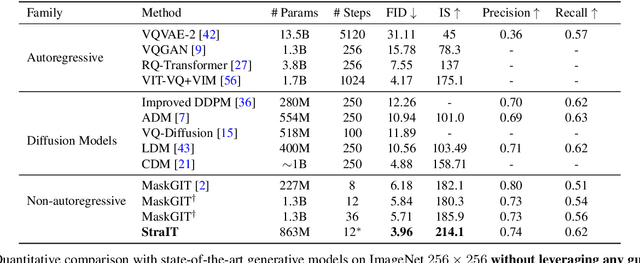
We propose Stratified Image Transformer(StraIT), a pure non-autoregressive(NAR) generative model that demonstrates superiority in high-quality image synthesis over existing autoregressive(AR) and diffusion models(DMs). In contrast to the under-exploitation of visual characteristics in existing vision tokenizer, we leverage the hierarchical nature of images to encode visual tokens into stratified levels with emergent properties. Through the proposed image stratification that obtains an interlinked token pair, we alleviate the modeling difficulty and lift the generative power of NAR models. Our experiments demonstrate that StraIT significantly improves NAR generation and out-performs existing DMs and AR methods while being order-of-magnitude faster, achieving FID scores of 3.96 at 256*256 resolution on ImageNet without leveraging any guidance in sampling or auxiliary image classifiers. When equipped with classifier-free guidance, our method achieves an FID of 3.36 and IS of 259.3. In addition, we illustrate the decoupled modeling process of StraIT generation, showing its compelling properties on applications including domain transfer.
Cascade Subspace Clustering for Outlier Detection
Jun 23, 2023
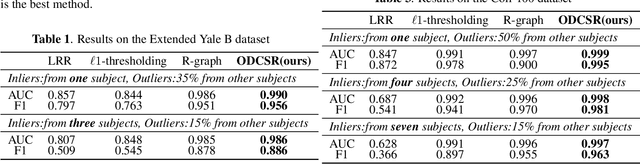
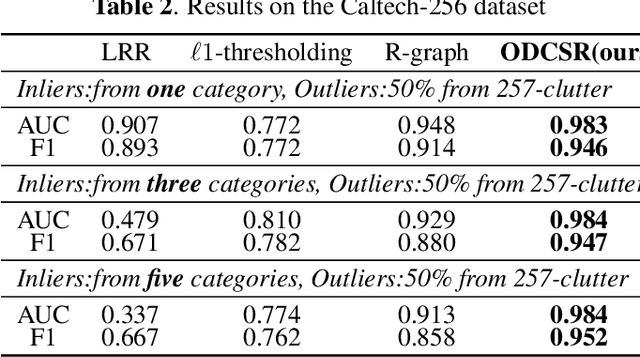
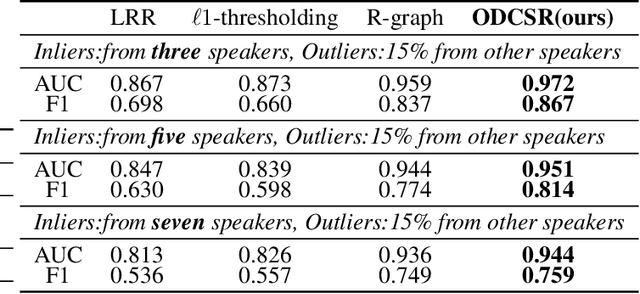
Many methods based on sparse and low-rank representation been developed along with guarantees of correct outlier detection. Self-representation states that a point in a subspace can always be expressed as a linear combination of other points in the subspace. A suitable Markov Chain can be defined on the self-representation and it allows us to recognize the difference between inliers and outliers. However, the reconstruction error of self-representation that is still informative to detect outlier detection, is neglected.Inspired by the gradient boosting, in this paper, we propose a new outlier detection framework that combines a series of weak "outlier detectors" into a single strong one in an iterative fashion by constructing multi-pass self-representation. At each stage, we construct a self-representation based on elastic-net and define a suitable Markov Chain on it to detect outliers. The residual of the self-representation is used for the next stage to learn the next weaker outlier detector. Such a stage will repeat many times. And the final decision of outliers is generated by the previous all results. Experimental results on image and speaker datasets demonstrate its superiority with respect to state-of-the-art sparse and low-rank outlier detection methods.
Heteroskedastic Geospatial Tracking with Distributed Camera Networks
Jun 04, 2023

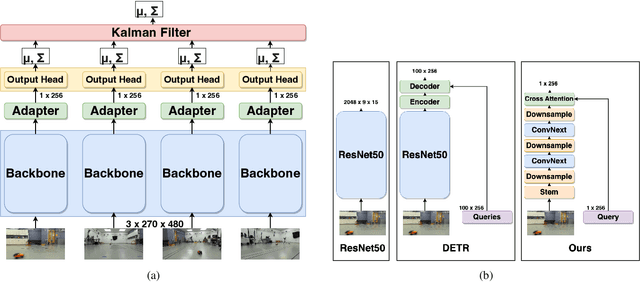
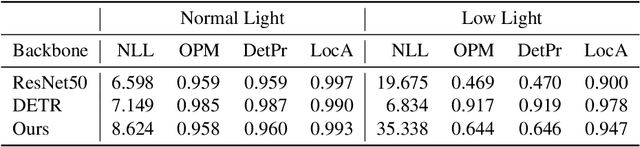
Visual object tracking has seen significant progress in recent years. However, the vast majority of this work focuses on tracking objects within the image plane of a single camera and ignores the uncertainty associated with predicted object locations. In this work, we focus on the geospatial object tracking problem using data from a distributed camera network. The goal is to predict an object's track in geospatial coordinates along with uncertainty over the object's location while respecting communication constraints that prohibit centralizing raw image data. We present a novel single-object geospatial tracking data set that includes high-accuracy ground truth object locations and video data from a network of four cameras. We present a modeling framework for addressing this task including a novel backbone model and explore how uncertainty calibration and fine-tuning through a differentiable tracker affect performance.
Chest X-ray Image Classification: A Causal Perspective
May 20, 2023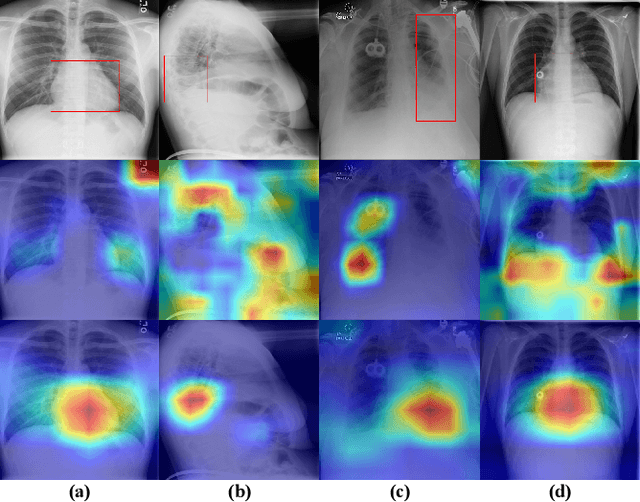
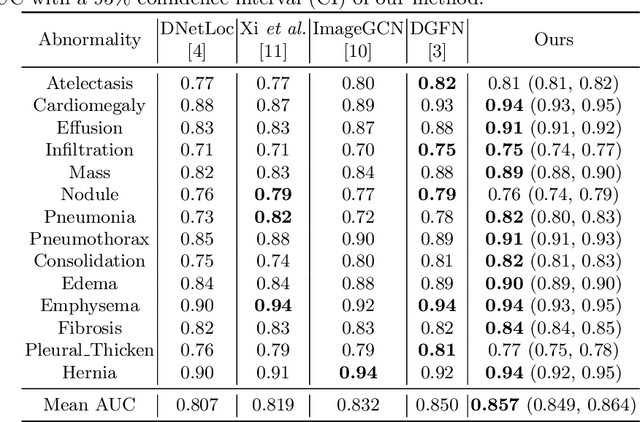
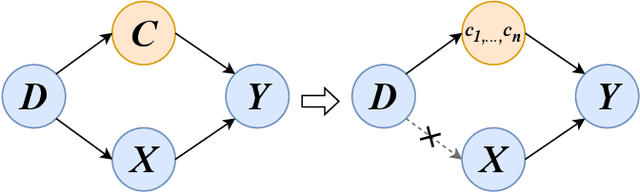
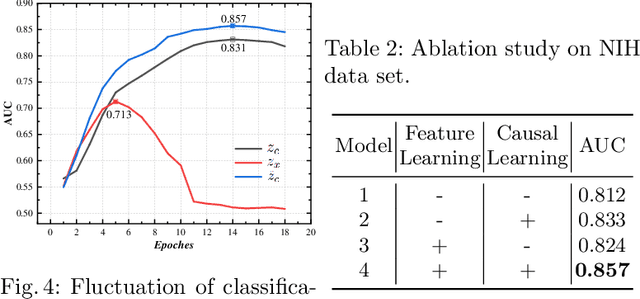
The chest X-ray (CXR) is one of the most common and easy-to-get medical tests used to diagnose common diseases of the chest. Recently, many deep learning-based methods have been proposed that are capable of effectively classifying CXRs. Even though these techniques have worked quite well, it is difficult to establish whether what these algorithms actually learn is the cause-and-effect link between diseases and their causes or just how to map labels to photos.In this paper, we propose a causal approach to address the CXR classification problem, which constructs a structural causal model (SCM) and uses the backdoor adjustment to select effective visual information for CXR classification. Specially, we design different probability optimization functions to eliminate the influence of confounders on the learning of real causality. Experimental results demonstrate that our proposed method outperforms the open-source NIH ChestX-ray14 in terms of classification performance.